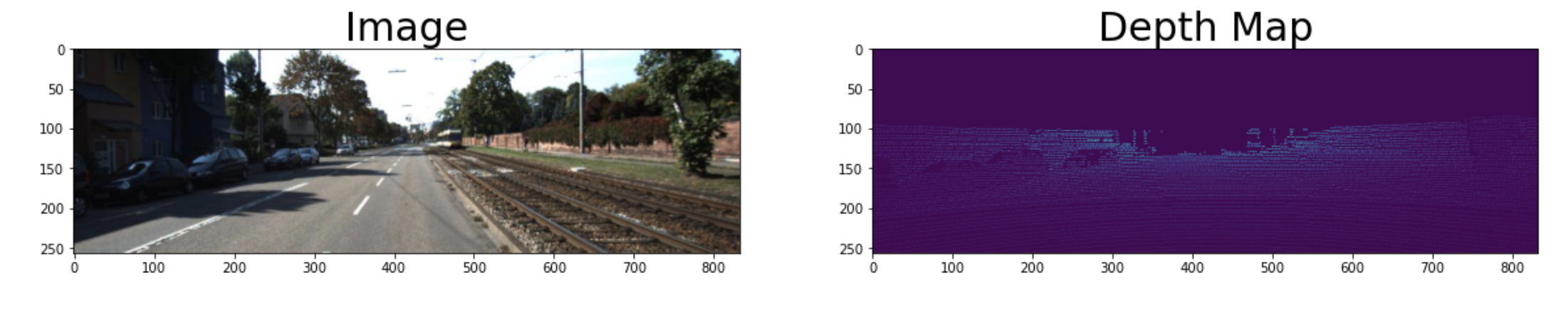
This repo provides the pytorch lightning implementation of SC-Depth (V1, V2, and V3) for self-supervised learning of monocular depth from video.
In the SC-DepthV1 (IJCV 2021 & NeurIPS 2019), we propose (i) geometry consistency loss for scale-consistent depth prediction over time and (ii) self-discovered mask for detecting and removing dynamic regions and occlusions during training towards higher accuracy. The predicted depth is sufficiently accurate and consistent for use in the ORB-SLAM2 system. The below video showcases the estimated depth in the form of pointcloud (top) and color map (bottom right).
In the SC-DepthV2 (TPMAI 2022), we prove that the large relative rotational motions in the hand-held camera captured videos is the main challenge for unsupervised monocular depth estimation in indoor scenes. Based on this findings, we propose auto-recitify network (ARN) to handle the large relative rotation between consecutive video frames. It is integrated into SC-DepthV1 and jointly trained with self-supervised losses, greatly boosting the performance.

In the SC-DepthV3 (TPAMI 2023), we propose a robust learning framework for accurate and sharp monocular depth estimation in (highly) dynamic scenes. As the photometric loss, which is the main loss in the self-supervised methods, is not valid in dynamic object regions and occlusion, previous methods show poor accuracy in dynamic scenes and blurred depth prediction at object boundaries. We propose to leverage an external pretrained depth estimation network for generating the single-image depth prior, based on which we propose effective losses to constrain self-supervised depth learning. The evaluation results on six challenging datasets including both static and dynamic scenes demonstrate the efficacy of the proposed method.
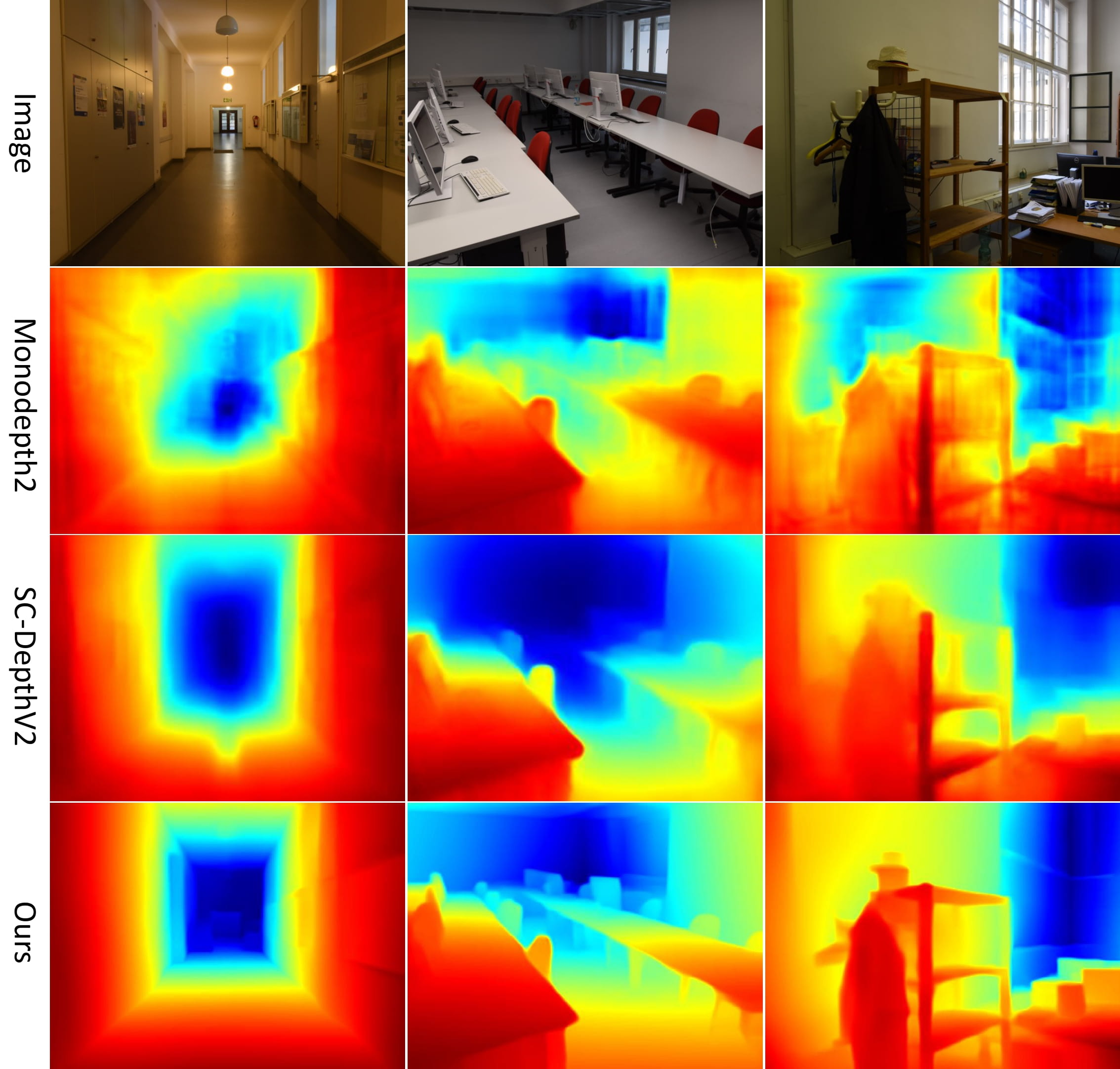
Qualitative depth estimation results: DDAD, BONN, TUM, IBIMS-1
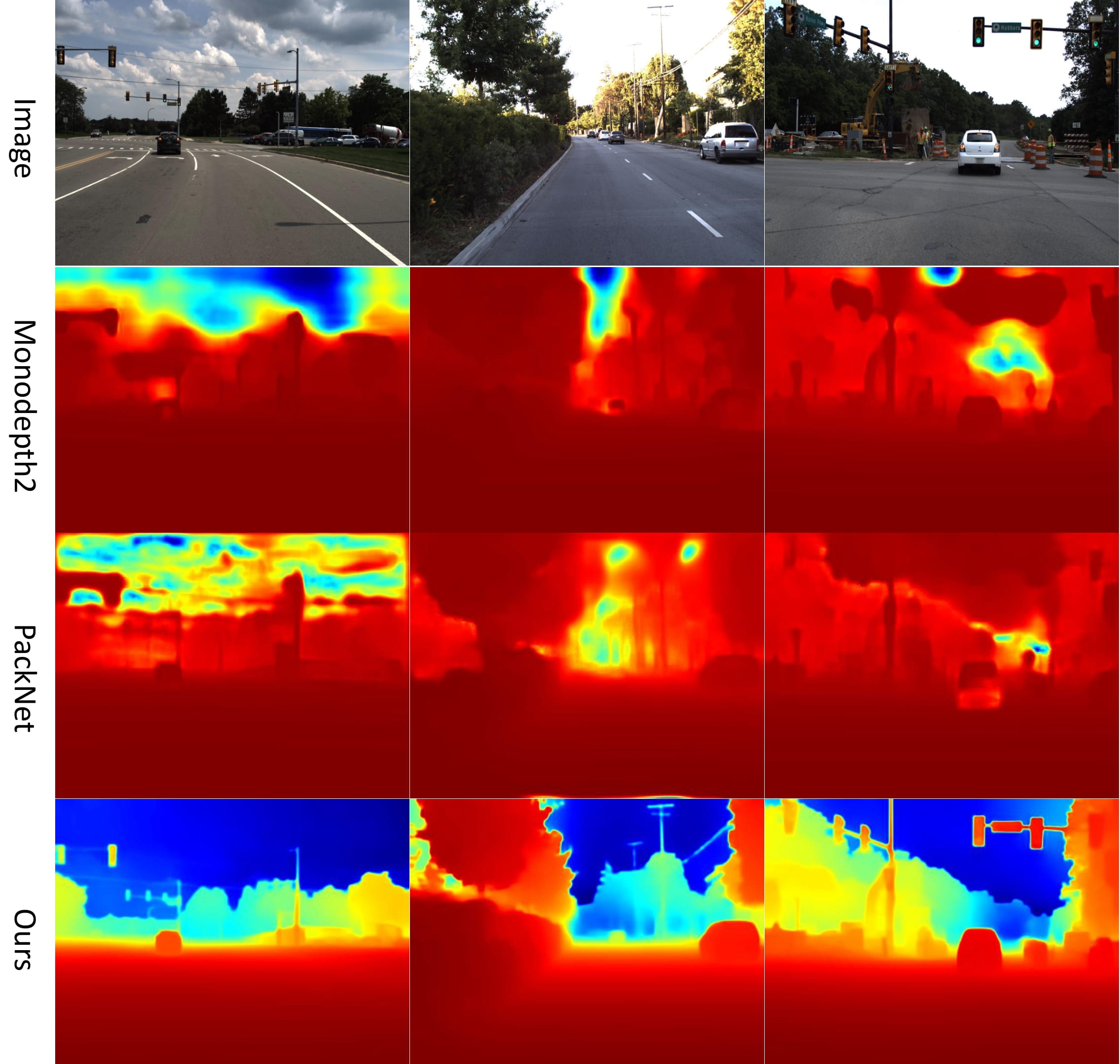

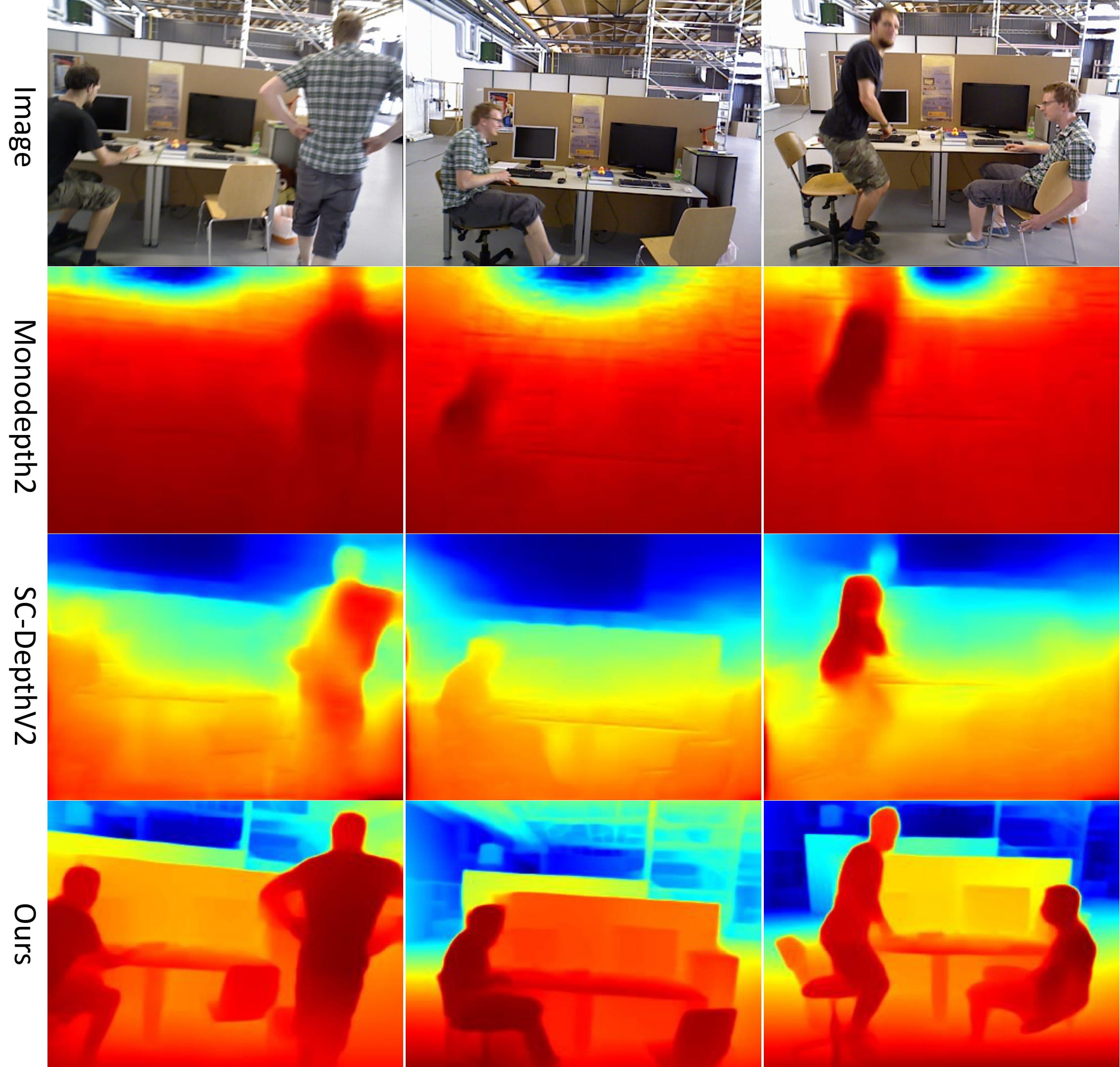
Demo Videos
ddad_video.mp4
bonn_video.mp4
tum_video.mp4
conda create -n sc_depth_env python=3.8
conda activate sc_depth_env
conda install pytorch torchvision pytorch-cuda=11.7 -c pytorch -c nvidia
pip install -r requirements.txt
We organize the video datasets into the following format for training and testing models:
Dataset
-Training
--Scene0000
---*.jpg (list of color images)
---cam.txt (3x3 camera intrinsic matrix)
---depth (a folder containing ground-truth depth maps, optional for validation)
---leres_depth (a folder containing psuedo-depth generated by LeReS, it is required for training SC-DepthV3)
--Scene0001
...
train.txt (containing training scene names)
val.txt (containing validation scene names)
-Testing
--color (containg testing images)
--depth (containg ground-truth depths)
--seg_mask (containing semantic segmentation masks for depth evaluation on dynamic/static regions)
We provide pre-processed datasets:
We provide a bash script ("scripts/run_train.sh"), which shows how to train on kitti, nyu, and datasets. Generally, you need edit the config file (e.g., "configs/v1/kitti.txt") based on your devices and run
python train.py --config $CONFIG --dataset_dir $DATASETThen you can start a tensorboard session in this folder by running
tensorboard --logdir=ckpts/By opening https://localhost:6006 on your browser, you can watch the training progress.
You need re-organize your own video datasets according to the above mentioned format for training. Then, you may meet three problems: (1) no ground-truth depth for validation; (2) hard to choose an appropriate frame rate (FPS) to subsample videos; (3) no pseudo-depth for training V3.
Add "--val_mode photo" in the training script or the configure file, which uses the photometric loss for validation.
python train.py --config $CONFIG --dataset_dir $DATASET --val_mode photoWe provide a script ("generate_valid_frame_index.py"), which computes and saves a "frame_index.txt" in each training scene. It uses the opencv-based optical flow method to compute the camera shift in consecutive frames. You might need to change the parameters for detecting sufficient keypoints in your images if necessary (usually you do not need). Once you prepare your dataset as the above-mentioned format, you can call it by running
python generate_valid_frame_index.py --dataset_dir $DATASETThen, you can add "--use_frame_index" in the training script or the configure file to train models on the filtered frames.
python train.py --config $CONFIG --dataset_dir $DATASET --use_frame_indexWe use the LeReS to generate pseudo-depth in this project. You need to install it and generate pseudo-depth for your own images (the pseudo-depth for standard datasets have been provided above). More specifically, you can refer to the code in this line for saving the pseudo-depth.
Besides, it is also possible to use other state-of-the-art monocular depth estimation models to generate psuedo-depth, such as DPT.
You need uncompress and put it into "ckpts" folder. Then you can run "scripts/run_test.sh" or "scripts/run_inference.sh" with the pretrained model.
For v1, we provide models trained on KITTI and DDAD.
For v2, we provide models trained on NYUv2.
For v3, we provide models trained on KITTI, NYUv2, DDAD, BONN, and TUM.
We provide the script ("scripts/run_test.sh"), which shows how to test on kitti, nyu, and ddad datasets. The script only evaluates depth accuracy on full images. See the next section for an evaluation of depth estimation on dynamic/static regions, separately.
python test.py --config $CONFIG --dataset_dir $DATASET --ckpt_path $CKPT
A simple demo is given here. You can put your images in "demo/input/" folder and run
python inference.py --config configs/v3/nyu.txt \
--input_dir demo/input/ \
--output_dir demo/output/ \
--ckpt_path ckpts/nyu_scv3/epoch=93-val_loss=0.1384.ckpt \
--save-vis --save-depthYou will see the results saved in "demo/output/" folder.
You need to use ("scripts/run_inference.sh") firstly to save the predicted depth, and then you can use the ("scripts/run_evaluation.sh") for doing evaluation. A demo on DDAD dataset is provided in these files. Generally, you need do
python inference.py --config $YOUR_CONFIG \
--input_dir $TESTING_IMAGE_FOLDER \
--output_dir $RESULTS_FOLDER \
--ckpt_path $YOUR_CKPT \
--save-vis --save-depthpython eval_depth.py \
--dataset $DATASET_FOLDER \
--pred_depth=$RESULTS_FOLDER \
--gt_depth=$GT_FOLDER \
--seg_mask=$SEG_MASK_FOLDERUnsupervised Scale-consistent Depth Learning from Video (IJCV 2021)
Jia-Wang Bian, Huangying Zhan, Naiyan Wang, Zhichao Li, Le Zhang, Chunhua Shen, Ming-Ming Cheng, Ian Reid
[paper]
@article{bian2021ijcv,
title={Unsupervised Scale-consistent Depth Learning from Video},
author={Bian, Jia-Wang and Zhan, Huangying and Wang, Naiyan and Li, Zhichao and Zhang, Le and Shen, Chunhua and Cheng, Ming-Ming and Reid, Ian},
journal= {International Journal of Computer Vision (IJCV)},
year={2021}
}
which is an extension of the previous conference version:
Unsupervised Scale-consistent Depth and Ego-motion Learning from Monocular Video (NeurIPS 2019)
Jia-Wang Bian, Zhichao Li, Naiyan Wang, Huangying Zhan, Chunhua Shen, Ming-Ming Cheng, Ian Reid
[paper]
@inproceedings{bian2019neurips,
title={Unsupervised Scale-consistent Depth and Ego-motion Learning from Monocular Video},
author={Bian, Jiawang and Li, Zhichao and Wang, Naiyan and Zhan, Huangying and Shen, Chunhua and Cheng, Ming-Ming and Reid, Ian},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year={2019}
}
Auto-Rectify Network for Unsupervised Indoor Depth Estimation (TPAMI 2022)
Jia-Wang Bian, Huangying Zhan, Naiyan Wang, Tat-Jun Chin, Chunhua Shen, Ian Reid
[paper]
@article{bian2021tpami,
title={Auto-Rectify Network for Unsupervised Indoor Depth Estimation},
author={Bian, Jia-Wang and Zhan, Huangying and Wang, Naiyan and Chin, Tat-Jin and Shen, Chunhua and Reid, Ian},
journal= {IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year={2021}
}
SC-DepthV3: Robust Self-supervised Monocular Depth Estimation for Dynamic Scenes (TPAMI 2023)
Libo Sun*, Jia-Wang Bian*, Huangying Zhan, Wei Yin, Ian Reid, Chunhua Shen
[paper]
* denotes equal contribution and joint first author
@article{sc_depthv3,
title={SC-DepthV3: Robust Self-supervised Monocular Depth Estimation for Dynamic Scenes},
author={Sun, Libo and Bian, Jia-Wang and Zhan, Huangying and Yin, Wei and Reid, Ian and Shen, Chunhua},
journal= {IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year={2023}
}