opendrivelab / persformer_3dlane Goto Github PK
View Code? Open in Web Editor NEW[ECCV2022 Oral] Perspective Transformer on 3D Lane Detection
License: Apache License 2.0
[ECCV2022 Oral] Perspective Transformer on 3D Lane Detection
License: Apache License 2.0




















































































































Hi there, thanks for your great work!
I trained with 4 card 3090 on Openlane dataset, set batch to 8. It takes about an hour for a epoch, I'm wondering if the time consuming is normal.
BW
Hi @zihanding819, I see you just updated eval_3D_lane.py to OpenLane v1.1, could you please also share the performance of Persformer on the updated version?
Dear author,
I want to know how to test my own images if there is no ground truth value of my images?
Thanks for opensource this outstanding working!
您好,感谢开源如此优秀的工作!请问一下怎么才能测试自己的图片呢?是必须要有图片的ground truth吗?如果没有的话怎么办呢?

I have setup the environment successfully, but when I run "python3 -m torch.distributed.launch --nproc_per_node 1 main_persformer.py --mod=PersFormer --batch_size=4 --nepochs=10" , it made an ImportError.
Could you please help me see how to solve it? very thanks!
Hello, when I use the weights you posted and use this command to infer, the error is as follows, what is the reason?

error:

and my data file structure is as follows:


persformer_openlane.py:
args.dataset_name = 'openlane'
args.dataset_dir = '/home/PersFormer_3DLane/openlane/images/validation/'
args.data_dir = '/home/PersFormer_3DLane/lane3d_300/'
Could you please release a pre-trained model based on OpenLanes dataset? Thanks very much!
Thanks for your work first!I follow the installation instruction in INSTALL.md, created virtual environment and install cuda as"pip3 install torch==1.8.1+cu111 torchvision==0.9.1+cu111 -f https://download.pytorch.org/whl/torch_stable.html".
Then I run the code“python -m torch.distributed.launch --nproc_per_node 1 main_persformer.py --mod=openlane --batch_size=8 --nepochs=100” to train ,I met a problem like this:


Could you please help me?
Hi:
I find one example of H_g2gflat:
[1, 0, 0, 0]
[0, 1, 0, 0]
[0, 0, 0.472, 0]
https://github.com/OpenPerceptionX/PersFormer_3DLane/blob/main/data/Load_Data.py#L417
but I cannot understand what's the scale(0.472) stand for
Thanks!
Thanks for your amazing job!
How can i output the id of the 3D lane?
for example,if there are four lanes, the model can output lane id like 0, 1, 2, 3.
waiting for your reply~
非常感谢可以开源如此优秀的工作,关于模型和数据集我有一些问题想请教:
1)数据集中2d坐标和3d坐标是不是不存在对应关系,我发现2d坐标数量和3d坐标数量不一致
2)模型输出的是世界坐标系吗,我看到代码中是相机坐标系的gt转换到世界坐标系后再和pred进行匹配https://github.com/OpenPerceptionX/OpenLane/blob/main/eval/LANE_evaluation/lane3d/eval_3D_lane.py#L311,
@hli2020 @dyfcalid @ChonghaoSima
https://github.com/OpenPerceptionX/PersFormer_3DLane/blob/main/models/PersFormer.py#L294
You don't predict pitch and height like 3d-LaneNet?
May I ask whether the camera height and pitch angle used in utils.py are passed in or obtained from the camera extrinsics?

Great work. I could not able to find the inference speed of PersFormer. How many FPS were you able run during inference and on what device?
The evaluation results include F-measure, Recall, x error, etc. Are these the results of 3d task? So how should I get the metrics for the 2d task?
Thanks for your wonderful work! I have some'questions when I read the code.Could u please help me out?
hi boss:
happened this error~
The training code crashes without an understandable error message:
proc_id: 5
world size: 6
local_rank: 5
proc_id: 3
world size: 6
local_rank: 3
proc_id: 1
world size: 6
local_rank: 1
proc_id: 4
world size: 6
local_rank: 4
proc_id: 2
world size: 6
local_rank: 2
proc_id: 0
world size: 6
local_rank: 0
Let's use 6 GPUs!
Loading Dataset ...
mean_cam_height 2.115622443531824, mean_cam_pitch 0.0
mean_cam_height 2.115622443531824, mean_cam_pitch 0.0
mean_cam_height 2.115622443531824, mean_cam_pitch 0.0
mean_cam_height 2.115622443531824, mean_cam_pitch 0.0
mean_cam_height 2.115622443531824, mean_cam_pitch 0.0
mean_cam_height 2.115622443531824, mean_cam_pitch 0.0
Killing subprocess 6040
Killing subprocess 6041
Killing subprocess 6042
Killing subprocess 6043
Killing subprocess 6044
Killing subprocess 6047
Traceback (most recent call last):
File "/root/anaconda3/envs/persformer/lib/python3.8/runpy.py", line 194, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/root/anaconda3/envs/persformer/lib/python3.8/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/root/anaconda3/envs/persformer/lib/python3.8/site-packages/torch/distributed/launch.py", line 340, in <module>
main()
File "/root/anaconda3/envs/persformer/lib/python3.8/site-packages/torch/distributed/launch.py", line 326, in main
sigkill_handler(signal.SIGTERM, None) # not coming back
File "/root/anaconda3/envs/persformer/lib/python3.8/site-packages/torch/distributed/launch.py", line 301, in sigkill_handler
raise subprocess.CalledProcessError(returncode=last_return_code, cmd=cmd)
subprocess.CalledProcessError: Command '['/root/anaconda3/envs/persformer/bin/python', '-u', 'main_persformer.py', '--local_rank=5', '--mod=FIRST_RUN', '--batch_size=24']' died with <Signals.SIGKILL: 9>.The run command I executed is python -m torch.distributed.launch --nproc_per_node 6 main_persformer.py --mod=FIRST_RUN --batch_size=24
Any idea?
Hello Author,
Thank you for the findings, I didn't find in the code the code to visualize the Openlane dataset during the evaluation, only the calculation of the precision.
There was an issue opened previously about the ref frame. Thanks for the detailed response on that. I just wanted to know What R_vg and R_gc mean. Could you please help me with this?

你好,比如想用nuscenes测试一下模型效果,推理时unit_update_projection_extrinsic函数的参数extrinsics,该怎么设定呢?
除了org_w,org_h,cam_height,pitch等参数,还有其他的参数吗
感谢~
I encountered this problem when I try to train on a single Gpu, please help me,Thank you :
python main_persformer.py --mod=kkk --batch_size=8 --nepochs=200
proc_id: None
world size: 1
local_rank: None
None
Traceback (most recent call last):
File "main_persformer.py", line 40, in
main()
File "main_persformer.py", line 30, in main
ddp_init(args)
File "/media/lee/PersFormer_3DLane-main/experiments/ddp.py", line 80, in ddp_init
setup_distributed(args)
File "/media/lee/PersFormer_3DLane-main/experiments/ddp.py", line 63, in setup_distributed
torch.cuda.set_device(args.gpu)
File "/media/lee/miniconda3/envs/cc/lib/python3.7/site-packages/torch/cuda/init.py", line 309, in set_device
device = _get_device_index(device)
File "/media/lee/miniconda3/envs/cc/lib/python3.7/site-packages/torch/cuda/_utils.py", line 34, in _get_device_index
return _torch_get_device_index(device, optional, allow_cpu)
File "/media/lee/miniconda3/envs/cc/lib/python3.7/site-packages/torch/_utils.py", line 514, in _get_device_index
'or an integer, but got:{}'.format(device))
ValueError: Expected a torch.device with a specified index or an integer, but got:None
Thank you so much for your publication.
I tried to training with Apollo dataset (standard group in data_splits).
I got the error of no label_list.
can you give me some guide to fix this error. Thank you.

thanks for your work! I am getting a memory leak while training.
I strictly follow the installation instruction in docs/INSTALL.md, and train the model using the following script:
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node 4 main_persformer.py --mod=persformer --batch_size=2 --nepochs=40
However, the memory consumption (system memory instead of cuda memory) gradually increases during training, and finally takes all the memory.
Does this problem occur with you?
请问单张图像推理应修改哪些地方?
感谢开源以及优秀的论文
thanks for your work! I have some problems in training.
i train the model with“ python3 -m torch.distributed.launch --nproc_per_node=4 main_persformer.py --mod=PersFormer --batch_size=4 --nepochs=10”
However,it can’t work.

actually,I follow the installation instruction in INSTALL.md, created virtual environment,and install cuda10.1 as“conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cudatoolkit=10.1 -c pytorch”.
During the creation of the environment,i use“conda install -c conda-forge cudatoolkit-dev” to solve the CUDA_HOME error,and set protobuf==3.20.1.
What do I need to do to solve this problem?
cam_extrinsics[:3, :3] = np.matmul(np.matmul(
np.matmul(np.linalg.inv(R_vg), cam_extrinsics[:3, :3]),
R_vg), R_gc)
https://github.com/OpenPerceptionX/PersFormer_3DLane/blob/main/data/Load_Data.py#L349
Thanks!
Hi! I'm curious about the GPU usage of this model when training, because when I'm training there is a strange error
RuntimeError: CUDA error: CUBLAS_STATUS_EXECUTION_FAILED when calling `cublasSgemm( handle, opa, opb, m, n, k, &alpha, a, lda, b, ldb, &beta, c, ldc)`
When I use batch size 2, the error would raise at https://github.com/OpenPerceptionX/PersFormer_3DLane/blob/081e8058af935e546a6beb067bc4d9185dae41dd/models/networks/Lane2D.py#L200-L201
BUT When I use batch size 1, the above line can run normally, but the error would show at
https://github.com/OpenPerceptionX/PersFormer_3DLane/blob/6df8402e9be926e1d6927b716b69898ddf833fae/models/PersFormer.py#L114
SO I think it might be the problem of the memory issues, and my GPU memory is about 12G.
Can anyone tell me how much memory does PersFormer would consume?
Hi, thanks for your nice paper. Could you please share the code related to the 3d lane generation pipeline? This was used for the ground truth if I understood correctly?

Hello,do you have your own code for car detection?
Hi, could you please let me know the resolution of your BEV image in meters? I know it is w=128, h=208, but I want to know this in meters. Alternatively, please direct me to the part of the code where I can extract this information. Thank you! :)
Thanks for the wonderful work. However, it seems some details are missing in the evaluation metrics represented in the paper. What is the standard for calculating F-score, by adjusting the score threshold to get the highest F-score, or calculating under a fixed precision, such as F-score at Precision=95%? By adjusting precision, one could get different F-scores, which leads to difficulties for comparing between different methods. Besides, could you kindly provide the precision and recall for the represented F-score in Table 4?
Hello: I see in your code that the extrinsics read directly from the JSON file cannot be used directly to projecting coordinate (u; v) in the front-view to the corresponding point in BEV by (u, v, 1) = K(intrinsics)·E(extrinsics)· (x, y, z, 1), but needs to be transformed first:

Then take the inverse of it:

Why is it needed this extra transformation for the external parameter? Why not just put the transformed external parameters in the JSON file?
In addition, I would like to ask you another question. If I want to get the coordinates in the camera coordinate system, can I directly use the transformed E· (x, y, z, 1) to get the coordinates?
Looking forward to your answer ~ thank you very much
started training using python main_persformer.py --mod=test --batch_size=8 --nepochs=100
and python -m torch.distributed.launch --nproc_per_node 1 main_persformer.py --mod=test --batch_size=8 --nepochs=100
Had the following problem
Let's use 1 GPUs!
Loading Dataset ...
Discarding images:
0
use default sampler
Traceback (most recent call last):
File "main_persformer.py", line 40, in <module>
main()
File "main_persformer.py", line 32, in main
runner = Runner(args)
File "/home/almon/personal_repos/Camera/lane/PersFormer_3DLane/experiments/runner.py", line 66, in __init__
self.train_dataset, self.train_loader, self.train_sampler = self._get_train_dataset()
File "/home/almon/personal_repos/Camera/lane/PersFormer_3DLane/experiments/runner.py", line 529, in _get_train_dataset
train_loader, train_sampler = get_loader(train_dataset, args)
ValueError: too many values to unpack (expected 2)
For the config:
I made the following changes:
args.dataset_dir = '/mnt/0cb7d5a4-6618-47e1-b81a-2315ebd35b37/data/openlane/dataset/images/'
args.data_dir = '/mnt/0cb7d5a4-6618-47e1-b81a-2315ebd35b37/data/openlane/dataset/lane3d_1000/'
# ddp related
args.dist = False
args.sync_bn = False
args.no_3d = True
args.proc_id = 0
args.distributed = False
args.gpu = 0
My dataset directory is shown below:

I tried the following debugging:
print("===> Training set size: {}".format(len(train_dataset)))
print("===> args: {}".format(args))
train_loader, train_sampler = get_loader(train_dataset, args)
and returned
===> Training set size: 157848
===> args: Namespace(K=array([[1000., 0., 960.],
[ 0., 1000., 640.],
[ 0., 0., 1.]]), S=72, T_0=500, T_max=8, T_mult=1, _2d_prob_loss_weight=0.0, _2d_reg_loss_weight=0.0, _2d_vis_loss_weight=0.0, _3d_prob_loss_weight=0.0, _3d_reg_loss_weight=0.0, _3d_vis_loss_weight=0.0, _seg_loss_weight=0.0, anchor_feat_channels=64, anchor_grid_x=array([[-10. , -10. , -10. , ..., -10. ,
-10. , -10. ],
[ -8.66666667, -8.66666667, -8.66666667, ..., -8.66666667,
-8.66666667, -8.66666667],
[ -7.33333333, -7.33333333, -7.33333333, ..., -7.33333333,
-7.33333333, -7.33333333],
...,
[ 8.13333333, 10.13333333, 12.13333333, ..., 30.13333333,
38.13333333, 46.13333333],
[ 9.46666667, 11.46666667, 13.46666667, ..., 31.46666667,
39.46666667, 47.46666667],
[ 10.8 , 12.8 , 14.8 , ..., 32.8 ,
40.8 , 48.8 ]]), anchor_y_steps=array([ 5, 10, 15, 20, 30, 40, 50, 60, 80, 100]), batch_norm=True, batch_size=8, cam_height=1.55, channels_in=3, clip_grad_norm=35.0, cls_loss_weight=1.0, conf_th=0.1, crop_y=0, cudnn=True, data_dir='/mnt/0cb7d5a4-6618-47e1-b81a-2315ebd35b37/data/openlane/dataset/lane3d_1000/', dataset_dir='/mnt/0cb7d5a4-6618-47e1-b81a-2315ebd35b37/data/openlane/dataset/images/', dataset_name='openlane', dist=False, distributed=False, encoder='EfficientNet-B3', eta_min=1e-05, evaluate=False, evaluate_case=False, feature_channels=128, fix_cam=False, fmap_mapping_interp_index=array([[[ 0, 0],
[ 0, 0],
[ 0, 0],
...,
[ 0, 0],
[ 0, 0],
[ 0, 0]],
[[ 0, 0],
[ 0, 0],
[ 0, 0],
...,
[ 0, 0],
[ 0, 0],
[ 0, 0]],
[[ 0, 0],
[ 0, 0],
[ 0, 0],
...,
[ 0, 0],
[ 0, 0],
[ 0, 0]],
...,
[[ 0, 0],
[ 0, 1],
[ 1, 2],
...,
[ 0, 0],
[ 0, 0],
[ 0, 0]],
[[ 0, 0],
[ 0, 1],
[ 1, 2],
...,
[ 0, 0],
[ 0, 0],
[ 0, 0]],
[[ 0, 0],
[ 0, 1],
[ 1, 2],
...,
[14, 15],
[ 0, 0],
[ 0, 0]]]), fmap_mapping_interp_weight=array([[[0. , 0. ],
[0. , 0. ],
[0. , 0. ],
...,
[0. , 0. ],
[0. , 0. ],
[0. , 0. ]],
[[0. , 0. ],
[0. , 0. ],
[0. , 0. ],
...,
[0. , 0. ],
[0. , 0. ],
[0. , 0. ]],
[[0. , 0. ],
[0. , 0. ],
[0. , 0. ],
...,
[0. , 0. ],
[0. , 0. ],
[0. , 0. ]],
...,
[[0. , 0. ],
[0.92307692, 0.07692308],
[0.92307692, 0.07692308],
...,
[0. , 0. ],
[0. , 0. ],
[0. , 0. ]],
[[0. , 0. ],
[0.61538462, 0.38461538],
[0.61538462, 0.38461538],
...,
[0. , 0. ],
[0. , 0. ],
[0. , 0. ]],
[[0. , 0. ],
[0.30769231, 0.69230769],
[0.30769231, 0.69230769],
...,
[0.76923077, 0.23076923],
[0. , 0. ],
[0. , 0. ]]]), gamma=0.1, gpu=0, im_anchor_angles=[array([13.38774168, 15.35622435, 17.98113487, 21.63719831, 27.02231477,
35.52769327, 13.78622136, 15.8795232 , 18.69578452, 22.66332033,
28.59283131, 38.11915612, 13.01126367, 14.86556104, 17.31749166,
20.69604962, 25.60419655, 33.22746829, 14.20864731, 16.43872893,
19.46730566, 23.78571073, 30.33891954, 41.04801986, 12.65504408,
14.40463831, 16.69974282, 19.83018921, 24.31883021, 31.17829495,
15.13430285, 17.68020515, 21.20902922, 26.37446808, 34.47194144,
48.12916757, 11.99726763, 13.56201687, 15.58458742, 18.29213003,
22.08213108, 27.70021836]), array([144.47230673, 152.97768523, 158.36280169, 162.01886513,
164.64377565, 166.61225832, 146.77253171, 154.39580345,
159.30395038, 162.68250834, 165.13443896, 166.98873633,
141.88084388, 151.40716869, 157.33667967, 161.30421548,
164.1204768 , 166.21377864, 148.82170505, 155.68116979,
160.16981079, 163.30025718, 165.59536169, 167.34495592,
138.95198014, 149.66108046, 156.21428927, 160.53269434,
163.56127107, 165.79135269, 152.29978164, 157.91786892,
161.70786997, 164.41541258, 166.43798313, 168.00273237,
131.87083243, 145.52805856, 153.62553192, 158.79097078,
162.31979485, 164.86569715]), array([ 49.95934314, 74.35227124, 105.64772876, 130.04065686,
54.463179 , 81.24205062, 112.10451174, 134.01977512,
45.98022488, 67.89548826, 98.75794938, 125.536821 ,
59.53524673, 88.39554646, 118.02173207, 137.52859198,
42.47140802, 61.97826793, 91.60445354, 120.46475327,
71.42127671, 102.63034064, 128.10669722, 143.35910639,
36.64089361, 51.89330278, 77.36965936, 108.57872329])], im_anchor_origins=[array([0.65867168, 0.68308271, 0.71637048, 0.76445281, 0.84001075,
0.97601505, 0.64653957, 0.66989249, 0.7020996 , 0.74937436,
0.8255192 , 0.96860456, 0.67009707, 0.69539032, 0.72951963,
0.77809521, 0.85275164, 0.98220179, 0.63363307, 0.65572118,
0.68655705, 0.73262052, 0.80888955, 0.95956738, 0.68087574,
0.70690103, 0.74167431, 0.7904974 , 0.86404105, 0.98744479,
0.60518009, 0.62396225, 0.65091057, 0.69283017, 0.76699562,
0.93386788, 0.70070079, 0.72782252, 0.76341979, 0.81220123,
0.88315605, 0.99584901]), array([0.97601505, 0.84001075, 0.76445281, 0.71637048, 0.68308271,
0.65867168, 0.98220179, 0.85275164, 0.77809521, 0.72951963,
0.69539032, 0.67009707, 0.96860456, 0.8255192 , 0.74937436,
0.7020996 , 0.66989249, 0.64653957, 0.98744479, 0.86404105,
0.7904974 , 0.74167431, 0.70690103, 0.68087574, 0.95956738,
0.80888955, 0.73262052, 0.68655705, 0.65572118, 0.63363307,
0.99584901, 0.88315605, 0.81220123, 0.76341979, 0.72782252,
0.70070079, 0.93386788, 0.76699562, 0.69283017, 0.65091057,
0.62396225, 0.60518009]), array([0.18488391, 0.3949613 , 0.6050387 , 0.81511609, 0.18006799,
0.39014538, 0.60022278, 0.81030017, 0.18969983, 0.39977722,
0.60985462, 0.81993201, 0.17525207, 0.38532946, 0.59540686,
0.80548425, 0.19451575, 0.40459314, 0.61467054, 0.82474793,
0.16562023, 0.37569762, 0.58577501, 0.79585241, 0.20414759,
0.41422499, 0.62430238, 0.83437977])], ipm_h=208, ipm_w=128, lane_width=2, learnable_weight_on=True, learning_rate=0.0002, local_rank=None, loss_att_weight=100.0, loss_dist=[10.0, 4.0, 1.0], loss_seg_weight=0.0, loss_threshold=100000.0, lr_decay=False, lr_decay_iters=10, lr_policy='cosine', match_dist_thre_3d=2.0, max_lanes=20, mod='bruce_persformer_2d_only', nepochs=100, new_match=False, nhead=8, niter=900, niter_decay=400, nms_thres=45.0, nms_thres_3d=1.0, no_3d=True, no_centerline=True, no_cuda=False, no_tb=False, npoints=8, num_att=3, num_category=21, num_class=2, num_proj=4, num_y_steps=10, nworkers=4, optimizer='adam', org_h=1280, org_w=1920, pitch=3, port=29666, position_embedding='learned', pred_cam=False, pretrained=False, print_freq=10, prob_th=0.5, proc_id=0, reg_vis_loss_weight=1.0, resize_h=360, resize_w=480, resume='', save_freq=50, save_json_path='/home/almon/personal_repos/Camera/lane/PersFormer_3DLane/data_splits/openlane', save_path='/home/almon/personal_repos/Camera/lane/PersFormer_3DLane/data_splits/openlane/bruce_persformer_2d_only', save_prefix='/home/almon/personal_repos/Camera/lane/PersFormer_3DLane/data_splits', seg_start_epoch=1, start_epoch=0, sync_bn=False, test_mode=False, top_view_region=array([[-10, 103],
[ 10, 103],
[-10, 3],
[ 10, 3]]), use_att=True, use_default_anchor=False, use_fpn=False, use_memcache=False, use_proj=True, use_slurm=False, use_top_pathway=False, vgg_mean=[0.485, 0.456, 0.406], vgg_std=[0.229, 0.224, 0.225], vis_th=0.1, weight_decay=0.001, weight_init='normal', world_size=1, y_ref=5)
Discarding images:
0
use default sampler
Traceback (most recent call last):
File "main_persformer.py", line 40, in <module>
main()
File "main_persformer.py", line 32, in main
runner = Runner(args)
File "/home/almon/personal_repos/Camera/lane/PersFormer_3DLane/experiments/runner.py", line 66, in __init__
self.train_dataset, self.train_loader, self.train_sampler = self._get_train_dataset()
File "/home/almon/personal_repos/Camera/lane/PersFormer_3DLane/experiments/runner.py", line 531, in _get_train_dataset
train_loader, train_sampler = get_loader(train_dataset, args)
非常抱歉再次打扰你们。我尝试将gt作为预测样例来评价测试指标。具体的做法是这样的, 先将gt的格式转换成pred的格式,然后再在使用eval_3D_lane.py来测试,其中--dataset_dir的输入是原始标注,--pred-dir的输入是将gt转换成pred格式的输入。
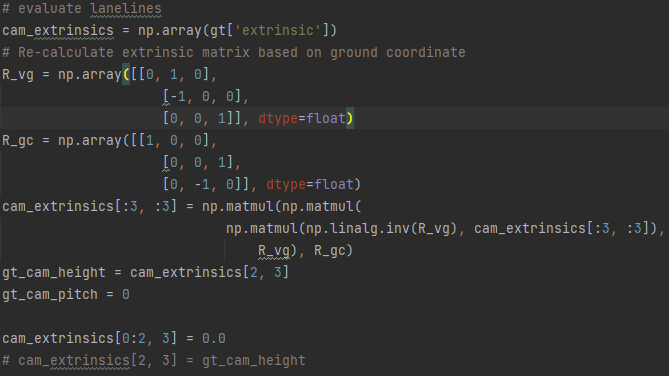
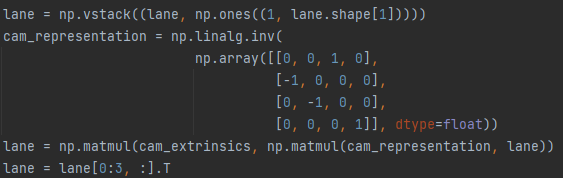
此外,再将gt的格式转换到pred的格式时,我按照上图方式将gt坐标从相机坐标系转换到世界坐标系,测试结果如下:

测试的f1=74%,之后我使用了标注中的vis属性,剔除了vis=false的点,但是f1也只提升到86%,我想问一下,我是在转换过程中缺少了一些关键步骤吗,如果使用gt去测试gt,按道理说f1应该达到99%以上才合理。希望可以得到您的帮助。
@dyfcalid
As mentioned in this issue, ONCE dataset doesn't release camera extrinsics.
How to train Persformer on ONCE and reproduce your latest results?
thank you for your share, but I find that the github code is not consistant with paper.
such as, "Unifying anchor design in 2D and 3D. We first put curated anchors (red) in the BEV space (left), then project them to the front view (right). Offset xi k and ui k (dashed line) are predicted to match ground truth (yellow and green) to anchors. The correspondence is thus built, and features are optimized together“
the code predicting lane length using the laneatt old method, which predict the start ration, but paper uses the lane visible for each row??
我留意到各个版本的论文中报道的F1score 不一致,请问是具体做了什么改进呢?
https://arxiv.org/pdf/2203.11089v1.pdf Table 2 47.8
https://arxiv.org/pdf/2203.11089v2.pdf Table 2 47.8
https://arxiv.org/pdf/2203.11089v3.pdf Table 2 50.5
请问下论文中使用的openlane3D相关实验使用的是300还是1000目录下的数据呢
I cannot understand the details about transformations, I think the formulation wants to get E_g2c. so, why not use 'R_gv@E' instead of 'inv(R_vg)@ E @R_vg@R_gc'?
which is the correct coordinate system for 3d lane points?


thanks!
Hi there, thanks for your excellent paper and work. I meet a bug when I use your code to train the model on Apollo dataset:
AttributeError: 'LaneDataset' object has no attribute '_label_list'
I saw in Load_data.py when dataset is OpenLane the self._label_list will be inited in a function but when dataset is Apollo, there is no init. Could you offer a solution? Thanks a lot!
Hi, I am not able to find the checkpoint file for the neural network tho. Has anyone been able to locate it?
In OpenLane 2D Lane Detection evaluation, which value of lane width and iou threshold you took to get benchmark results? 30 & 0.5 ?
hi, the range used in your work is 103m. I wonder how did you choose this number ?
We used the best trained model provided in the article for testing, but the weight of the model was loaded incorrectly. The reason seems to be that the keys of the model parameters don't match, that is, the model parameters don't match. However, the hyperparameters I used have always been the hyperparameters in the code and haven't been changed. The error results are as follows:
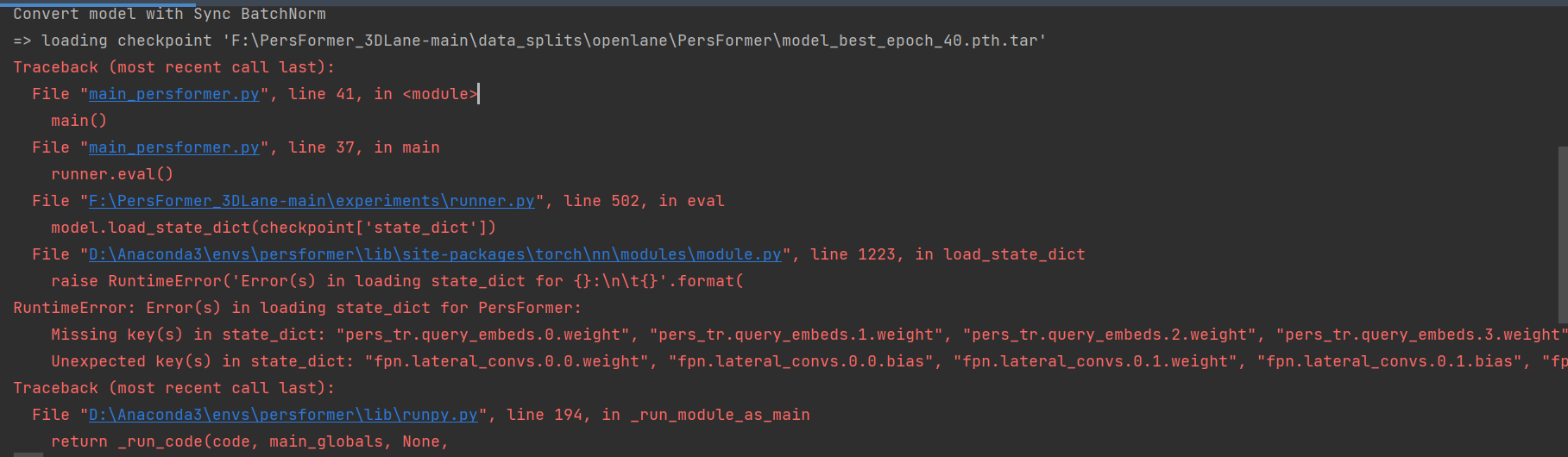
Hi, thanks for your sharing. I run the code for training, but do not get the results reported in your paper. Could you provide your training setting? Currently, I use your training script to train with batch_size=2 & gpu=4.
hello!I want to test single picture and visualize the result, can you offer relative code? Thank you!
我们需要怎么处理数据才能训练Gen_LaneNet呢?希望得到大佬的指导,我看你们也进行过对比实验,谢谢啊
# transformation from apollo camera to openlane camera code used for?cam_extrinsics[0:2, 3] = 0.0 used for?Is it possible to inference on a video? Or image by image only?
Should we mask out invisible points on bev seg maps?

num_y_steps is not defined in args. What is it number?
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.