isl-org / dpt Goto Github PK
View Code? Open in Web Editor NEWDense Prediction Transformers
License: MIT License
Dense Prediction Transformers
License: MIT License

















































































































































Hi authors,
Thanks for your code,
While running run_monodepth.py , I got this error "Unknown model (vit_base_resnet50_384)". I'm using conda environment and installed timm using pip. and the version of timm I'm using is 0.4.5.
I tested segmentation on Titan RTX and it outputs black mask with some white noises.
It seems that "optimize" option caused that problem.
The problem is solved by deleting 2 lines about "memory_format=torch.channels_last"
but I did not figure out the reason.
I'm trying to run convertantion, but having this error:
initialize
device: cuda
Traceback (most recent call last):
File "run_monodepth.py", line 245, in <module>
args.optimize,
File "run_monodepth.py", line 114, in run
model = torch.jit.script(model)
File "C:\Users\Ilya\anaconda3\lib\site-packages\torch\jit\_script.py", line 1097, in script
obj, torch.jit._recursive.infer_methods_to_compile
File "C:\Users\Ilya\anaconda3\lib\site-packages\torch\jit\_recursive.py", line 412, in create_script_module
return create_script_module_impl(nn_module, concrete_type, stubs_fn)
File "C:\Users\Ilya\anaconda3\lib\site-packages\torch\jit\_recursive.py", line 474, in create_script_module_impl
script_module = torch.jit.RecursiveScriptModule._construct(cpp_module, init_fn)
File "C:\Users\Ilya\anaconda3\lib\site-packages\torch\jit\_script.py", line 497, in _construct
init_fn(script_module)
File "C:\Users\Ilya\anaconda3\lib\site-packages\torch\jit\_recursive.py", line 452, in init_fn
scripted = create_script_module_impl(orig_value, sub_concrete_type, stubs_fn)
File "C:\Users\Ilya\anaconda3\lib\site-packages\torch\jit\_recursive.py", line 478, in create_script_module_impl
create_methods_and_properties_from_stubs(concrete_type, method_stubs, property_stubs)
File "C:\Users\Ilya\anaconda3\lib\site-packages\torch\jit\_recursive.py", line 355, in create_methods_and_properties_from_stubs
concrete_type._create_methods_and_properties(property_defs, property_rcbs, method_defs, method_rcbs, method_defaults)
File "C:\Users\Ilya\anaconda3\lib\site-packages\torch\jit\_recursive.py", line 820, in compile_unbound_method
create_methods_and_properties_from_stubs(concrete_type, (stub,), ())
File "C:\Users\Ilya\anaconda3\lib\site-packages\torch\jit\_recursive.py", line 355, in create_methods_and_properties_from_stubs
concrete_type._create_methods_and_properties(property_defs, property_rcbs, method_defs, method_rcbs, method_defaults)
RuntimeError:
Module 'VisionTransformer' has no attribute 'dist_token' :
File "D:\dev\Mars\DPT-dpt_scriptable\dpt\vit.py", line 274
x = self.model.patch_embed.proj(x).flatten(2).transpose(1, 2)
if hasattr(self.model, "dist_token") and self.model.dist_token is not None:
~~~~~~~~~~~~~~~~~~~~~ <--- HERE
cls_tokens = self.model.cls_token.expand(
B, -1, -1
'BackboneWrapper.forward_flex' is being compiled since it was called from 'BackboneWrapper.forward'
File "D:\dev\Mars\DPT-dpt_scriptable\dpt\vit.py", line 300
_, _, h, w = x.shape
layers = self.forward_flex(x)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
# HACK: this is to make TorchScript happy. Can't directly address modules,
I'm using models fromd dpt_scriptable branch.
I am trying to convert the DPT_Scriptable model to a coreML model but am unable to due to this error.
RuntimeError: NYI: Named tensors are not supported with the tracer
Script that I am running:-
`
model = DPTDepthModel(
path=model_path,
backbone="vitl16_384",
non_negative=True,
enable_attention_hooks=False,
)
model.to(device);
model.eval();
from DPT.util import io
img = io.read_image('/content/dog.jpg')
img_input = transform({"image": img})["image"]
sample = torch.from_numpy(img_input).to(device).unsqueeze(0)
sample = sample.to(memory_format=torch.channels_last)
tracedModel = torch.jit.trace(model.forward, example_inputs=sample);
`
Dear authors,
To my understanding, all ">" should be "<" in the tables describing depth estimation results.
BTW, thank you so much for the great work!
When I tried to train the model using using pytorch DDP, I got the error blow:

I'm a bit confused by the absolute numbers in Tables 2 and 3 in the arxiv release. should be a percentage of pixels out of 100 and lower should be better. However, the range of numbers in the tables is very low and the higher numbers are highlighted. Could you please clarify what the numbers represent?
Hi! Thanks again about your work!
Recently, I tried to check accuracy of pre-trained models on KITTI (Eigen split) and found that it is differ from paper results.

On this screenshoot you can see basic metrics used in depth prediction on Eigen split (files for split I take from this repo). For ground truth i used raw data from velodyne (used loader like this)
I hope, you can explain this results. Thanks!
Hi,
Thank you for your great work and for sharing the code.
I have a slight question on results on Pascal Context in Table. 5: It seems that the DPT-Hybrid model is firstly pre-trained on the ADE20K dataset then finetuned on Pascal Context, am I right?
Thanks.
I want to train your model.
When i didn't use nn.DataParallel then training is ok.
But, when i use nn.DataParallel i got this error.
RuntimeError: Expected tensor for argument #1 'input' to have the same device as tensor for argument #2 'weight'; but device 1 does not equal 0 (while checking arguments for cudnn_convolution)
I want to train with multi gpu. How can i do?
Thank you for such great software!
Do you have ideas on how to reduce the flickering effect between frames from the same video?
Hi, I was trying to use your code for training in another dataset for the depth prediction task. I noticed that during training I could not increase the batch size beyond 2. With a batch size of 2 and images of size 224x448 it takes almost 9GB of memory. Can you comment on the memory requirement? Like how did you train the model and how much memory it took? It will be really helpful if you can share some insights on training.
Thanks
Hi! Thanks for a great job. I'm trying to reconcile output from usual midas model and vt model, but have some problems. I need this for open3d visualization: usually a take inverse midas output and get normal 3d point clouds, but for vt this pipeline breakes.
Can you explain, please, how can i fix this? Thanks!
Could you share the weights of encoder pretrained on imagenet?
Thanks~
Hi, Thanks for sharing the code.
As per the paper, the features for ViT-large is taken from layers {5,12,18,24} whereas in the code it is actually taken from {6,12,18,24} (line 45, dpt/models.py). Kindly clarify the correct setting. Thanks.
Hi,
Thanks for your great paper. For the semantic segmentation model on ADE20K, you state the following:
"""Images are resized to 520 pixels side length.
We use random horizontal flipping and random rescaling in
the range ∈ (0.5, 2.0) for data augmentation. We train on
square random crops of size 480."""
I feel I must not understand the procedure as randomly scaling a 520-pixel length image between the range (.5, 2.0) will result in some images of side-length less than your random crop size of 480. Could you please clarify the order of operations and any missing detail here? Thank you!
Hi, I used your pre-trained model to obtain results for Kitti validation and the RMSE values are extremely high even after post-processing the depth results like you have done to visualize the images.
All the depth pixels are way higher than expected, plus I noticed an inverse relationship where the closer objects have a higher value than the farther ones.
I was hoping to get more insight from you on how to get the same RMSE values for Kitti as you have mentioned in your paper.
Hi authors,
i have some issue with the output image depth. After forward image in model , i have the final result is out.astype("unit16")
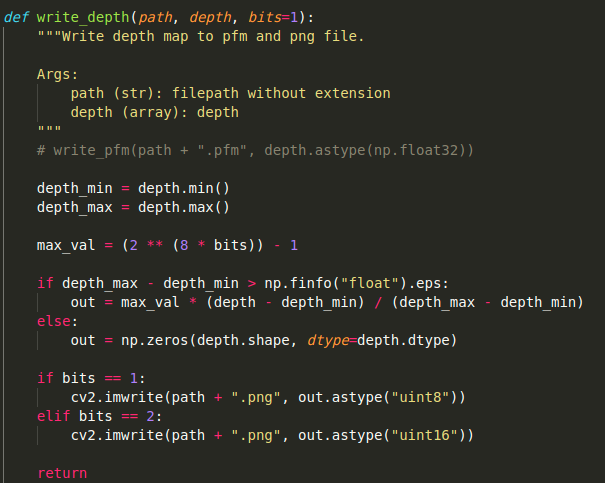
But i want to put the output in cv2.threshold(out,100,255,cv2.THRESH_TOZERO) but not working. And after checking the array of output , it is the array of value > 255 . So what should i do for this problem ?
Hope to see yours answer!
hi,
I got this error when I ran run_segmentation.py, my environment is the same as mentioned in README.md and CUDA version is 10.2, this might be the problem, what the CUDA version did you use?
x = F.conv2d(x, self.get_weight(), self.bias, self.stride, self.padding, self.dilation, self.groups)
RuntimeError: CUDA error: CUBLAS_STATUS_EXECUTION_FAILED when calling `cublasGemmEx( handle, opa, opb, m, n, k, &falpha, a, CUDA_R_16F, lda, b, CUDA_R_16F, ldb, &fbeta, c, CUDA_R_16F, ldc, CUDA_R_32F, CUBLAS_GEMM_DFALT_TENSOR_OP)`
Hi,
I just clone repo, weight and some images from KITTI dataset (put it's to /input).

When I use command python run_monodepth.py -t dpt_hybrid_kitti follow error occurred:
python run_monodepth.py -t dpt_hybrid_kitti
initialize
device: cuda
/home/dkorshunov/anaconda3/envs/py37/lib/python3.7/site-packages/torch/nn/functional.py:718: UserWarning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (Triggered internally at /pytorch/c10/core/TensorImpl.h:1156.)
return torch.max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode)
start processing
processing input/2011_09_26_drive_0002_sync_0000000075.png (1/1)
/home/dkorshunov/anaconda3/envs/py37/lib/python3.7/site-packages/torch/nn/functional.py:3613: UserWarning: Default upsampling behavior when mode=bilinear is changed to align_corners=False since 0.4.0. Please specify align_corners=True if the old behavior is desired. See the documentation of nn.Upsample for details.
"See the documentation of nn.Upsample for details.".format(mode)
Traceback (most recent call last):
File "run_monodepth.py", line 237, in <module>
args.optimize,
File "run_monodepth.py", line 152, in run
prediction = model.forward(sample)
File "/media/data/experiments/DPT/dpt/models.py", line 115, in forward
inv_depth = super().forward(x).squeeze(dim=1)
File "/media/data/experiments/DPT/dpt/models.py", line 72, in forward
layer_1, layer_2, layer_3, layer_4 = forward_vit(self.pretrained, x)
File "/media/data/experiments/DPT/dpt/vit.py", line 107, in forward_vit
glob = pretrained.model.forward_flex(x)
File "/media/data/experiments/DPT/dpt/vit.py", line 175, in forward_flex
x = self.patch_embed.backbone(x)
File "/home/dkorshunov/anaconda3/envs/py37/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/home/dkorshunov/anaconda3/envs/py37/lib/python3.7/site-packages/timm/models/resnetv2.py", line 409, in forward
x = self.forward_features(x)
File "/home/dkorshunov/anaconda3/envs/py37/lib/python3.7/site-packages/timm/models/resnetv2.py", line 403, in forward_features
x = self.stem(x)
File "/home/dkorshunov/anaconda3/envs/py37/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/home/dkorshunov/anaconda3/envs/py37/lib/python3.7/site-packages/torch/nn/modules/container.py", line 139, in forward
input = module(input)
File "/home/dkorshunov/anaconda3/envs/py37/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/home/dkorshunov/anaconda3/envs/py37/lib/python3.7/site-packages/timm/models/layers/std_conv.py", line 70, in forward
self.weight.view(1, self.out_channels, -1), None, None,
RuntimeError: view size is not compatible with input tensor's size and stride (at least one dimension spans across two contiguous subspaces). Use .reshape(...) instead.Hi,
I want to visualize the attention map using your code.
If you input prediction and sample in the run_monodepth.py file, I encounter below error.
"Valueerror unsupported dtype"
How can I solve this?
Thank you.
Sorry
I observed that you have used mean = [0.5,0.5,0.5] and std = [0.5, 0.5, 0.5] for normalizing images for all the transformer based models. It is different from the Imagent normalization value. Are these models not pre-trained on Imagenet?
Thank you for sharing the code and model.
What the finetune model (on KITTI or NYU)'s output, inverse depth, actual depth with metric, or depth with unknown scale?
And for the normal model, it will output inverse depth?
I converted model using dpt_scriptable branch,
like this:
model.eval()
if optimize == True and device == torch.device("cuda"):
model = torch.jit.script(model)
model = model.to(memory_format=torch.channels_last)
model = model.half()
model.to(device)
model.save(model_path[:-3] + ".torchscript.pt")
then I tried to using it in C++, loading Mat image and converting it to PyTorch:
cv::Mat ch_first = data.clone();
if (data.type() != CV_32FC3) cout << "wrong type" << endl;
float* feed_data = (float*)data.data;
float* ch_first_data = (float*)ch_first.data;
for (int p = 0; p < (int)data.total(); ++p)
{
// R
ch_first_data[p] = feed_data[p * 3];
// G
ch_first_data[p + (int)data.total()] = feed_data[p * 3 + 1];
// B
ch_first_data[p + 2 * (int)data.total()] = feed_data[p * 3 + 2];
}
torch::Tensor image_input = torch::from_blob((float*)ch_first.data, { 1, data.rows, data.cols, 3 });
image_input = image_input.toType(torch::kFloat16);
image_input = image_input.to((*device));
auto net_out = module.forward({ image_input });
data height is 384 and width is 672. In for Im just unpacking values from OpenCV byte order to pytorch byte order.
And in forward function I recieve exception:
KernelBase.dll!00007ffcea784f99() Unknown
vcruntime140d.dll!00007ffc5afab460() Unknown
> torch_cpu.dll!torch::jit::InterpreterStateImpl::handleError(const torch::jit::ExceptionMessage & msg, bool is_jit_exception, c10::NotImplementedError * not_implemented_error) Line 665 C++
torch_cpu.dll!`torch::jit::InterpreterStateImpl::runImpl'::`1'::catch$81() Line 639 C++
[External Code]
torch_cpu.dll!torch::jit::InterpreterStateImpl::runImpl(std::vector<c10::IValue,std::allocator<c10::IValue>> & stack) Line 251 C++
torch_cpu.dll!torch::jit::InterpreterStateImpl::run(std::vector<c10::IValue,std::allocator<c10::IValue>> & stack) Line 728 C++
torch_cpu.dll!torch::jit::InterpreterState::run(std::vector<c10::IValue,std::allocator<c10::IValue>> & stack) Line 841 C++
torch_cpu.dll!torch::jit::GraphExecutorImplBase::run(std::vector<c10::IValue,std::allocator<c10::IValue>> & stack) Line 544 C++
torch_cpu.dll!torch::jit::GraphExecutor::run(std::vector<c10::IValue,std::allocator<c10::IValue>> & inputs) Line 767 C++
torch_cpu.dll!torch::jit::GraphFunction::run(std::vector<c10::IValue,std::allocator<c10::IValue>> & stack) Line 36 C++
torch_cpu.dll!torch::jit::GraphFunction::operator()(std::vector<c10::IValue,std::allocator<c10::IValue>> stack, const std::unordered_map<std::string,c10::IValue,std::hash<std::string>,std::equal_to<std::string>,std::allocator<std::pair<std::string const ,c10::IValue>>> & kwargs) Line 53 C++
torch_cpu.dll!torch::jit::Method::operator()(std::vector<c10::IValue,std::allocator<c10::IValue>> stack, const std::unordered_map<std::string,c10::IValue,std::hash<std::string>,std::equal_to<std::string>,std::allocator<std::pair<std::string const ,c10::IValue>>> & kwargs) Line 225 C++
torch_cpu.dll!torch::jit::Module::forward(std::vector<c10::IValue,std::allocator<c10::IValue>> inputs) Line 114 C++
pytorch_test.exe!main() Line 128 C++
I connected source file for debugging and got exception string:
The following operation failed in the TorchScript interpreter.
Traceback of TorchScript, serialized code (most recent call last):
File "code/__torch__/dpt/models.py", line 14, in forward
def forward(self: __torch__.dpt.models.DPTDepthModel,
x: Tensor) -> Tensor:
inv_depth = torch.squeeze((self).forward_features(x, ), 1)
~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
if self.invert:
depth = torch.add(torch.mul(inv_depth, self.scale), self.shift)
File "code/__torch__/dpt/models.py", line 28, in forward_features
def forward_features(self: __torch__.dpt.models.DPTDepthModel,
x: Tensor) -> Tensor:
layer_1, layer_2, layer_3, layer_4, = (self.pretrained).forward(x, )
~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
layer_1_rn = (self.scratch.layer1_rn).forward(layer_1, )
layer_2_rn = (self.scratch.layer2_rn).forward(layer_2, )
File "code/__torch__/dpt/vit.py", line 22, in forward
x: Tensor) -> Tuple[Tensor, Tensor, Tensor, Tensor]:
_0, _1, h, w, = torch.size(x)
layers = (self).forward_flex(x, )
~~~~~~~~~~~~~~~~~~ <--- HERE
layer_1, layer_2, layer_3, layer_4, = layers
layer_10 = (self.readout_oper1).forward(layer_1, )
File "code/__torch__/dpt/vit.py", line 54, in forward_flex
_15 = torch.floordiv(H, (self.patch_size)[1])
_16 = torch.floordiv(W, (self.patch_size)[0])
pos_embed = (self)._resize_pos_embed(_14, _15, _16, )
~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
B0 = (torch.size(x))[0]
_17 = (self.model.patch_embed.proj).forward(x, )
File "code/__torch__/dpt/vit.py", line 220, in _resize_pos_embed
_68 = torch.reshape(posemb_grid, [1, gs_old, gs_old, -1])
posemb_grid0 = torch.permute(_68, [0, 3, 1, 2])
posemb_grid1 = _67(posemb_grid0, [gs_h, gs_w], None, "bilinear", False, None, )
~~~ <--- HERE
_69 = torch.permute(posemb_grid1, [0, 2, 3, 1])
posemb_grid2 = torch.reshape(_69, [1, torch.mul(gs_h, gs_w), -1])
File "code/__torch__/torch/nn/functional/___torch_mangle_25.py", line 256, in interpolate
ops.prim.RaiseException("AssertionError: ")
align_corners6 = _25
_81 = torch.upsample_bilinear2d(input, output_size2, align_corners6, scale_factors5)
~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
_79 = _81
else:
Traceback of TorchScript, original code (most recent call last):
File "D:\dev\Mars\DPT-dpt_scriptable\dpt\models.py", line 114, in forward
def forward(self, x):
inv_depth = self.forward_features(x).squeeze(dim=1)
~~~~~~~~~~~~~~~~~~~~~ <--- HERE
if self.invert:
File "D:\dev\Mars\DPT-dpt_scriptable\dpt\vit.py", line 302, in forward
_, _, h, w = x.shape
layers = self.forward_flex(x)
~~~~~~~~~~~~~~~~~ <--- HERE
# HACK: this is to make TorchScript happy. Can't directly address modules,
File "D:\dev\Mars\DPT-dpt_scriptable\dpt\vit.py", line 259, in forward_flex
B, _, H, W = x.shape
pos_embed = self._resize_pos_embed(
~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
self.model.pos_embed,
int(H // self.patch_size[1]),
File "D:\dev\Mars\DPT-dpt_scriptable\dpt\vit.py", line 247, in _resize_pos_embed
posemb_grid = posemb_grid.reshape(1, gs_old, gs_old, -1).permute(0, 3, 1, 2)
posemb_grid = F.interpolate(
~~~~~~~~~~~~~ <--- HERE
posemb_grid, size=[gs_h, gs_w], mode="bilinear", align_corners=False
)
File "C:\Users\Ilya\anaconda3\envs\np\lib\site-packages\torch\nn\functional.py", line 3709, in interpolate
if input.dim() == 4 and mode == "bilinear":
assert align_corners is not None
return torch._C._nn.upsample_bilinear2d(input, output_size, align_corners, scale_factors)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
if input.dim() == 5 and mode == "trilinear":
assert align_corners is not None
RuntimeError: Input and output sizes should be greater than 0, but got input (H: 24, W: 24) output (H: 42, W: 0)
It seems something wrong with input size? Should it be 384x384? I am not sure what is wrong
I don't quite follow how the Readout Token is generated (either from reading the paper or from the code). All the other tokens make sense (one per patch), but I don't get where Readout comes from.
Hello,
are there any plans to provide the pre-trained models in .onnx format ?
Thank you!
HI, I go through your paper it open new way to use transformer in depth estimation. have you compare DPT result with state of art Monocular depth estimation network Monodepth2?
In the paper, depths are showed as red when is near, and black when in far, how can I replicate the papers result? (color).
Thank for sharing this research and the models.
I am interested in a tensorflow lite version of this model.I appreciate if you can share it in case you have it. I would like to test it on a device with very little resources.
I made a webcam interface based on run_seg and run_mono, I am wondering is there any method that can make both model run at the same time?
Dear author,
Many thanks for your impressive work which enlightens me a lot!
Great as the result is, the model ussally uses vit-base or vit-large or vit-hybrid and the size is large.
I am wondering whether have you tried to train a model with smaller size? Like vit-small or vit-tiny? I want to train a smaller size model myself, but the result is quite disappointing.
sill have issue with depth as sill flick in the background of images and a lot of background nose
I try to trace "dpt_hybrid_midas" by calling
torch.jit.trace(model, example_input)
However, it failed with error messages below.
Any pointer on how to do it properly?
/usr/local/lib/python3.9/dist-packages/torch/_tensor.py:575: UserWarning: floor_divide is deprecated, and will be removed in a future version of pytorch. It currently rounds toward 0 (like the 'trunc' function NOT 'floor'). This results in incorrect rounding for negative values.
To keep the current behavior, use torch.div(a, b, rounding_mode='trunc'), or for actual floor division, use torch.div(a, b, rounding_mode='floor'). (Triggered internally at /pytorch/aten/src/ATen/native/BinaryOps.cpp:467.)
return torch.floor_divide(self, other)
/mnt/data/git/DPT/dpt/vit.py:154: TracerWarning: Using len to get tensor shape might cause the trace to be incorrect. Recommended usage would be tensor.shape[0]. Passing a tensor of different shape might lead to errors or silently give incorrect results.
gs_old = int(math.sqrt(len(posemb_grid)))
/usr/local/lib/python3.9/dist-packages/torch/nn/functional.py:3609: UserWarning: Default upsampling behavior when mode=bilinear is changed to align_corners=False since 0.4.0. Please specify align_corners=True if the old behavior is desired. See the documentation of nn.Upsample for details.
warnings.warn(
Traceback (most recent call last):
File "/mnt/data/git/DPT/export_model.py", line 112, in
convert(in_model_path, out_model_path)
File "/mnt/data/git/DPT/export_model.py", line 64, in convert
sm = torch.jit.trace(model, example_input)
File "/usr/local/lib/python3.9/dist-packages/torch/jit/_trace.py", line 735, in trace
return trace_module(
File "/usr/local/lib/python3.9/dist-packages/torch/jit/_trace.py", line 952, in trace_module
module._c._create_method_from_trace(
File "/usr/local/lib/python3.9/dist-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.9/dist-packages/torch/nn/modules/module.py", line 1039, in _slow_forward
result = self.forward(*input, **kwargs)
File "/mnt/data/git/DPT/dpt/models.py", line 115, in forward
inv_depth = super().forward(x).squeeze(dim=1)
File "/mnt/data/git/DPT/dpt/models.py", line 72, in forward
layer_1, layer_2, layer_3, layer_4 = forward_vit(self.pretrained, x)
File "/mnt/data/git/DPT/dpt/vit.py", line 120, in forward_vit
nn.Unflatten(
File "/usr/local/lib/python3.9/dist-packages/torch/nn/modules/flatten.py", line 102, in init
self._require_tuple_int(unflattened_size)
File "/usr/local/lib/python3.9/dist-packages/torch/nn/modules/flatten.py", line 125, in _require_tuple_int
raise TypeError("unflattened_size must be tuple of ints, " +
TypeError: unflattened_size must be tuple of ints, but found element of type Tensor at pos 0
Hi! I look through some discussions in the MiDaS repo's issue and summarize the steps to obtain absolute depth from the estimated dense inverse depth. Am I right?
Step 0: Run SfM to get some sparse 3D points with correct absolute depth, e.g. (x1,y1,d1), ..., (xn,yn,dn)
Step 1: Inverse the 3rd dimension to get 3D points with correct inverse depth, e.g. (x1,y1,1/d1), ..., (xn,yn,1/dn)
Step 2: Run DPT model to estimate the dense inverse depth map D
Step 3: Compute scale S and shift T to Align D with {(x1,y1,1/d1), ..., (xn,yn,1/dn)}
Step 4: Output 1/(SxD+T) as the depth
@ranftlr
I try to script "dpt_hybrid-midas-d889a10e.pt" by calling torch.jit.script(model).
But I had trouble trying to convert it .
Could you help me?Thank you.
Traceback (most recent call last):
File "E:/xidian/depth/DPT-main/dpt/convert.py", line 23, in
traced_script_module = torch.jit.script(model)
File "D:\Anaconda\envs\DPT\lib\site-packages\torch\jit_script.py", line 943, in script
obj, torch.jit._recursive.infer_methods_to_compile
File "D:\Anaconda\envs\DPT\lib\site-packages\torch\jit_recursive.py", line 391, in create_script_module
return create_script_module_impl(nn_module, concrete_type, stubs_fn)
File "D:\Anaconda\envs\DPT\lib\site-packages\torch\jit_recursive.py", line 448, in create_script_module_impl
script_module = torch.jit.RecursiveScriptModule._construct(cpp_module, init_fn)
File "D:\Anaconda\envs\DPT\lib\site-packages\torch\jit_script.py", line 391, in _construct
init_fn(script_module)
File "D:\Anaconda\envs\DPT\lib\site-packages\torch\jit_recursive.py", line 428, in init_fn
scripted = create_script_module_impl(orig_value, sub_concrete_type, stubs_fn)
File "D:\Anaconda\envs\DPT\lib\site-packages\torch\jit_recursive.py", line 448, in create_script_module_impl
script_module = torch.jit.RecursiveScriptModule._construct(cpp_module, init_fn)
File "D:\Anaconda\envs\DPT\lib\site-packages\torch\jit_script.py", line 391, in _construct
init_fn(script_module)
File "D:\Anaconda\envs\DPT\lib\site-packages\torch\jit_recursive.py", line 428, in init_fn
scripted = create_script_module_impl(orig_value, sub_concrete_type, stubs_fn)
File "D:\Anaconda\envs\DPT\lib\site-packages\torch\jit_recursive.py", line 448, in create_script_module_impl
script_module = torch.jit.RecursiveScriptModule._construct(cpp_module, init_fn)
File "D:\Anaconda\envs\DPT\lib\site-packages\torch\jit_script.py", line 391, in _construct
init_fn(script_module)
File "D:\Anaconda\envs\DPT\lib\site-packages\torch\jit_recursive.py", line 428, in init_fn
scripted = create_script_module_impl(orig_value, sub_concrete_type, stubs_fn)
File "D:\Anaconda\envs\DPT\lib\site-packages\torch\jit_recursive.py", line 448, in create_script_module_impl
script_module = torch.jit.RecursiveScriptModule._construct(cpp_module, init_fn)
File "D:\Anaconda\envs\DPT\lib\site-packages\torch\jit_script.py", line 391, in _construct
init_fn(script_module)
File "D:\Anaconda\envs\DPT\lib\site-packages\torch\jit_recursive.py", line 428, in init_fn
scripted = create_script_module_impl(orig_value, sub_concrete_type, stubs_fn)
File "D:\Anaconda\envs\DPT\lib\site-packages\torch\jit_recursive.py", line 448, in create_script_module_impl
script_module = torch.jit.RecursiveScriptModule._construct(cpp_module, init_fn)
File "D:\Anaconda\envs\DPT\lib\site-packages\torch\jit_script.py", line 391, in _construct
init_fn(script_module)
File "D:\Anaconda\envs\DPT\lib\site-packages\torch\jit_recursive.py", line 428, in init_fn
scripted = create_script_module_impl(orig_value, sub_concrete_type, stubs_fn)
File "D:\Anaconda\envs\DPT\lib\site-packages\torch\jit_recursive.py", line 448, in create_script_module_impl
script_module = torch.jit.RecursiveScriptModule._construct(cpp_module, init_fn)
File "D:\Anaconda\envs\DPT\lib\site-packages\torch\jit_script.py", line 391, in _construct
init_fn(script_module)
File "D:\Anaconda\envs\DPT\lib\site-packages\torch\jit_recursive.py", line 428, in init_fn
scripted = create_script_module_impl(orig_value, sub_concrete_type, stubs_fn)
File "D:\Anaconda\envs\DPT\lib\site-packages\torch\jit_recursive.py", line 455, in create_script_module_impl
create_hooks_from_stubs(concrete_type, hook_stubs, pre_hook_stubs)
File "D:\Anaconda\envs\DPT\lib\site-packages\torch\jit_recursive.py", line 344, in create_hooks_from_stubs
concrete_type._create_hooks(hook_defs, hook_rcbs, pre_hook_defs, pre_hook_rcbs)
RuntimeError: Hook 'hook' on module 'ResNetStage' expected the input argument to be typed as a Tuple but found type: 'Tensor' instead.
This error occured while scripting the forward hook 'hook' on module ResNetStage. If you did not want to script this hook remove it from the original NN module before scripting. This hook was expected to have the following signature: hook(self, input: Tuple[Tensor], output: Tensor). The type of the output arg is the returned type from either the forward method or the previous hook if it exists. Note that hooks can return anything, but if the hook is on a submodule the outer module is expecting the same return type as the submodule's forward.
hows the inference speed compares to monodepth2 in terms of same accuracy?
Dear authors,
While reading your great work, I recognized that there are typical typo in page 4 (l = {5, 12, 18, 24}). Maybe 5 needs to be 6 comparing with the provided code ?
Anyway, thank you for bringing transformer to the image regression community !
"We employ a cross-entropy loss and add an auxiliary output head together with an auxiliary loss to the output of the penultimate fusion layer."
According to your paper,the resolution of the auxiliary output is one-fourth of the input image. Do you upsample the auxiliary output to input?How do you design the auxiliary loss?
Dear Author:
thank u for the excellent works.
when i run the code run_segmentation.pytest on CPU there are some problem :
/home/mrzhao/anaconda3/envs/DPT/lib/python3.7/site-packages/torch/nn/functional.py:3455: UserWarning: Default upsampling behavior when mode=bilinear is changed to align_corners=False since 0.4.0. Please specify align_corners=True if the old behavior is desired. See the documentation of nn.Upsample for details.
"See the documentation of nn.Upsample for details.".format(mode)
Segmentation fault (core dumped)
and I change the code align_corners=False to align_corners=True.
but it not working.
(test with cuda is good)
so ,what should i do to solve this problem;
Hey. I wanted to finetune the DPT-Large model on my smaller dataset. Is the code for finetuning available or will it be released with the training code?
Thank you so much for your great work!!!
But sorry for asking silly questions:
In the paper, you show the average testing speed for an image with DPT-Large is around 35ms, which is very promising!

But when using your online DPT-Large App to test the depth prediction performance, it usually takes even longer than 30 seconds to estimate one image's depth info. Is it just because of the bad internet connection?
Meanwhile, it seems your trained model for the DPT-Large depth prediction network has a relatively big size (around 1.3G), which specific technique help accelerate the inference?
Sorry for so many questions and look forward to your reply!
Hi, in the paper, you have mentioned the third variant of the DPT model, i.e. DPT-Base. Could you also share the weights for the Base model as well? Thanks.
Hello!
Is it possible to mask input image for gpt? For example, I want to mask some trademarks, because I thinks, that this thing may influence on final depth map. Thanks!
I've seen few issues where people were trying to train the network, but cant find any training code. Is there anything available? I'm interested in loss function, pipeline for data and depth preparation for loss function, it seems rather complicated from reading the paper.
I have a question for your run_segmentation.py.
Looking at the structure of the DPT model, the foward returns five outputs.
[out, layer1, layer2, layer3, layer4]
In run_segmentation.py, insert a sample into the model and enter the above-mentioned type of list as out.
After that, Torch.nn.functional.If you put it in the interpolate, you will encounter the following error.
AttributeError: 'list' object has no attribute 'dim'
How do you solve it?
@ranftlr @dvdhfnr I updated the vit models on timm master, no pypi update yet but there will be a small breakage when I do. I tried to keep everything compat with downstream uses like this but ran into one issue.
At https://github.com/intel-isl/DPT/blob/main/dpt/vit.py#L181-L191
if hasattr(self, "dist_token"):
should be changed to
if getattr(self, "dist_token", None) is not None:
I merged the distilled and normal model class so that torchscript works for both (torchscript doesn't work well with inheritence). torchscript also likes None values as sentinels for non-used modules, so I couldn't leave it out entirely when not in use.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.