maweigert / gputools Goto Github PK
View Code? Open in Web Editor NEWGPU accelerated image/volume processing in Python
License: BSD 3-Clause "New" or "Revised" License
GPU accelerated image/volume processing in Python
License: BSD 3-Clause "New" or "Revised" License



















































































































hey @maweigert, I can take care of getting it on conda-forge (useful if anything else on conda-forge wants to depend on this).
But it would be helpful if you added an sdist to your pypi distribution. Can you add python3 setup.py bdist_wheel sdist to your build_pypi script and update the twine upload dist/*whl to also upload the sdist as well?
We have some issues with our naive (non-parallel) integral image implementation in scikit-image. At the same time, we have many functions (template matching, thresholding) that depend on it, so it would be awesome to have a GPUtools implementation. (Ideally before March. ;) Here are some references for the implementation:
https://dspace.mit.edu/openaccess-disseminate/1721.1/71883
(note though that they use exclusive integral images while we use inclusive ones in skimage):
In [1]: from skimage.transform import integral_image
In [2]: import numpy as np
In [3]: integral_image(np.array([[4, 8, 0], [9, 8, 8]]))
Out[3]:
array([[ 4, 12, 12],
[13, 29, 37]])It might also turn out to be way more complicated in nD...
Other relevant paper:
python 2.7, Anaconda. There appears a problem when import gputools (pyopencl appears to work fine, at least upon running the example benchmark.py code). It appears some image3d_t image2d_t issue. Any insights very much appreciated.
Error below
WARNING:gputools.core.ocldevice | prefered platform/device (1/1) not available (device type = 4)
...choosing the best from the rest
<pyopencl.Device 'Quadro 600' on 'NVIDIA CUDA' at 0x4b8400>
Traceback (most recent call last):
File "C:\Users\kvisscher\My Documents\LiClipse Workspace\MyFirstPythonProject\benchmark.py", line 10, in
import gputools
File "C:\Users\kvisscher\AppData\Local\Continuum\Anaconda2\lib\site-packages\gputools_init_.py", line 16, in
from gputools.core.ocltypes import OCLArray, OCLImage
File "C:\Users\kvisscher\AppData\Local\Continuum\Anaconda2\lib\site-packages\gputools\core\ocltypes.py", line 330, in
OCLArray = _wrap_OCLArray(cl_array.Array)
File "C:\Users\kvisscher\AppData\Local\Continuum\Anaconda2\lib\site-packages\gputools\core\ocltypes.py", line 121, in _wrap_OCLArray
cls.resample_prog = OCLProgram(abspath("kernels/copy_resampled.cl"))
File "C:\Users\kvisscher\AppData\Local\Continuum\Anaconda2\lib\site-packages\gputools\core\oclprogram.py", line 40, in init
self.build(options = build_options)
File "C:\Users\kvisscher\AppData\Local\Continuum\Anaconda2\lib\site-packages\pyopencl_init.py", line 440, in build
options_bytes=options_bytes, source=self.source)
File "C:\Users\kvisscher\AppData\Local\Continuum\Anaconda2\lib\site-packages\pyopencl_init.py", line 475, in _build_and_catch_errors
raise err
pyopencl.cffi_cl.RuntimeError: clBuildProgram failed: BUILD_PROGRAM_FAILURE -
Build on <pyopencl.Device 'Quadro 600' on 'NVIDIA CUDA' at 0x4b8400>:
:114:16: error: passing 'attribute((address_space(16776963))) image3d_t' to parameter of incompatible type 'image2d_t'
write_imagef(dest,(int4)(i,j,k,0),val);
^~~~
cl_kernel.h:18597:46: note: passing argument to parameter 'image' here
void OVERLOADABLE write_imagef(image2d_t image, int2 coord, float4 val);
^
(options: -I "c:\users\kvisscher\appdata\local\continuum\anaconda2\lib\site-packages\pyopencl\cl")
(source saved as c:\users\kvissc~1\appdata\local\temp\tmpyyvnob.cl)
Right now, it is limited to kernels, that fit into constant memory. It would be cool, if it would work for larger kernels as well. I know, that as normal microscopy PSF most likely will always fit, but a lightfield PSF or volume registration methods would benefit from being able to use larger kernel.
Hi,
Thanks for building this great package.
Convolve seems to produce same output size as input size commonly referred as "same" convolution. Is there a way to perform convolution "valid" convolution where output size is shrinked?
I noticed that the sampler variable is used by fill_patch3 in conv_spatial3.cl but not by interpolate3, where it is instantiated but unused:
Is this intentional?
Hi, I am unable to install gputools with python 3.9.7.
Is there a plan to make gputools compatible for this?
When testing affine_transform and comparing it to scipy.ndimage transform I get the impression
that gputools swaps dimensions 0 and 2. This should become clearer when looking towards the end of this notebook:
https://github.com/VolkerH/affine_transform_debugging/blob/master/Affine_transform.ipynb
Trying to import gputools in a docker container and receiving the following error:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.8/dist-packages/gputools/__init__.py", line 11, in <module>
from gputools.utils.utils import pad_to_shape, pad_to_power2
File "/usr/local/lib/python3.8/dist-packages/gputools/utils/__init__.py", line 5, in <module>
from .histogram import histogram
File "/usr/local/lib/python3.8/dist-packages/gputools/utils/histogram.py", line 2, in <module>
from gputools.core.ocltypes import OCLArray, OCLProgram, get_device
File "/usr/local/lib/python3.8/dist-packages/gputools/core/ocltypes.py", line 377, in <module>
OCLArray = _wrap_OCLArray(cl_array.Array)
File "/usr/local/lib/python3.8/dist-packages/gputools/core/ocltypes.py", line 160, in _wrap_OCLArray
cls._resample_prog = OCLProgram(abspath("kernels/copy_resampled.cl"))
File "/usr/local/lib/python3.8/dist-packages/gputools/core/oclprogram.py", line 40, in __init__
self.build(options = build_options)
File "/usr/local/lib/python3.8/dist-packages/pyopencl/__init__.py", line 535, in build
self._prg, was_cached = self._build_and_catch_errors(
File "/usr/local/lib/python3.8/dist-packages/pyopencl/__init__.py", line 583, in _build_and_catch_errors
raise err
pyopencl._cl.RuntimeError: clBuildProgram failed: BUILD_PROGRAM_FAILURE - clBuildProgram failed: BUILD_PROGRAM_FAILURE - clBuildProgram failed: BUILD_PROGRAM_FAILURE
Build on <pyopencl.Device 'NVIDIA GeForce RTX 3050 Ti Laptop GPU' on 'NVIDIA CUDA' at 0x20fdbd0>:
(options: -I /usr/local/lib/python3.8/dist-packages/pyopencl/cl)
(source saved as /tmp/tmpbspr0uic.cl)
Dockerfile:
FROM tensorflow/tensorflow:2.11.0rc2-gpu
ARG NVIDIA_DRIVER_VERSION=515
RUN apt-get update && apt-get install -y --no-install-recommends \
ocl-icd-dev \
ocl-icd-opencl-dev \
opencl-headers \
clinfo \
libnvidia-compute-${NVIDIA_DRIVER_VERSION} \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
RUN python3 -m pip install --upgrade pip
RUN pip install stardist gputools edt
Any idea why the build is failing?
Hi Martin,
I was looking at the FFT-based implementation of RL-deconvolution in deconv_rl.py and noticed a few things.
hflip = h[::-1, ::-1] is needed. I'm also not sure whether it is correct, I assume for the 3D case this would have to be hflip = h[::-1, ::-1, ::-1]. Maybe you can explain.To address the first two points I have rewritten your code to test this. The rewritten code is here: https://github.com/VolkerH/Lattice_Lightsheet_Deskew_Deconv/blob/benchmarking/lls_dd/deconv_gputools_rewrite.py
I wasn't sure whether and if so how you would like to integrate this approach of setting up the decon first in gputools, otherwise I would have edited it there and created a pull request.
I have done some benchmarks comparing the rewritten code to the current implementation in gputools and to flowdec: VolkerH/Lattice_Lightsheet_Deskew_Deconv#21. Note that the iteration times are not purely deconvolution but also include IO and affine transforms. This adds plenty of overhead. Without this overhead the speed improvements are even more significant.
It appears there is a bug in
https://github.com/maweigert/gputools/blob/master/gputools/transforms/kernels/transformations.cl
When selecting nearest neighbour the preprocessor defines SAMPLERFILTER but what is needed is SAMPLER_FILTER. Credits to @jni for spotting this.

I've been testing convolve and comparing it to the ndimage implementation. Running the following code:
import gputools
import numpy as np
img = np.random.rand(10000, 10000)
kernel = np.ones((3, 3))
res = gputools.convolve(img, kernel)
Gives the error below. I assume this is due to my GPU not having enough space to store this array - is that correct? The array is around 762Mb, so I guess that might be too large?
---------------------------------------------------------------------------
LogicError Traceback (most recent call last)
<ipython-input-10-867ee5568ea6> in <module>()
----> 1 get_ipython().magic(u'timeit res = gputools.convolve(img, kernel)')
/Users/robin/.conda/envs/python2/lib/python2.7/site-packages/IPython/core/interactiveshell.pyc in magic(self, arg_s)
2305 magic_name, _, magic_arg_s = arg_s.partition(' ')
2306 magic_name = magic_name.lstrip(prefilter.ESC_MAGIC)
-> 2307 return self.run_line_magic(magic_name, magic_arg_s)
2308
2309 #-------------------------------------------------------------------------
/Users/robin/.conda/envs/python2/lib/python2.7/site-packages/IPython/core/interactiveshell.pyc in run_line_magic(self, magic_name, line)
2226 kwargs['local_ns'] = sys._getframe(stack_depth).f_locals
2227 with self.builtin_trap:
-> 2228 result = fn(*args,**kwargs)
2229 return result
2230
/Users/robin/.conda/envs/python2/lib/python2.7/site-packages/IPython/core/magics/execution.pyc in timeit(self, line, cell)
/Users/robin/.conda/envs/python2/lib/python2.7/site-packages/IPython/core/magic.pyc in <lambda>(f, *a, **k)
191 # but it's overkill for just that one bit of state.
192 def magic_deco(arg):
--> 193 call = lambda f, *a, **k: f(*a, **k)
194
195 if callable(arg):
/Users/robin/.conda/envs/python2/lib/python2.7/site-packages/IPython/core/magics/execution.pyc in timeit(self, line, cell)
1034 number = 1
1035 for _ in range(1, 10):
-> 1036 time_number = timer.timeit(number)
1037 worst_tuning = max(worst_tuning, time_number / number)
1038 if time_number >= 0.2:
/Users/robin/.conda/envs/python2/lib/python2.7/site-packages/IPython/core/magics/execution.pyc in timeit(self, number)
130 gc.disable()
131 try:
--> 132 timing = self.inner(it, self.timer)
133 finally:
134 if gcold:
<magic-timeit> in inner(_it, _timer)
/Users/robin/.conda/envs/python2/lib/python2.7/site-packages/gputools-0.1.1-py2.7.egg/gputools/convolve/convolve.pyc in convolve(data, h, res_g)
35 return _convolve_buf(data,h, res_g)
36 elif isinstance(data,np.ndarray) and isinstance(h,np.ndarray):
---> 37 return _convolve_np(data,h)
38
39 else:
/Users/robin/.conda/envs/python2/lib/python2.7/site-packages/gputools-0.1.1-py2.7.egg/gputools/convolve/convolve.pyc in _convolve_np(data, h)
50
51
---> 52 data_g = OCLArray.from_array(data.astype(np.float32, copy = False))
53 h_g = OCLArray.from_array(h.astype(np.float32, copy = False))
54
/Users/robin/.conda/envs/python2/lib/python2.7/site-packages/gputools-0.1.1-py2.7.egg/gputools/core/ocltypes.pyc in from_array(cls, arr, *args, **kwargs)
27 def from_array(cls,arr,*args, **kwargs):
28 queue = get_device().queue
---> 29 return cl_array.to_device(queue, arr,*args, **kwargs)
30 @classmethod
31 def empty(cls, shape, dtype = np.float32):
/Users/robin/.local/lib/python2.7/site-packages/pyopencl/array.pyc in to_device(queue, ary, allocator, async)
1676
1677 result = Array(queue, ary.shape, ary.dtype,
-> 1678 allocator=allocator, strides=ary.strides)
1679 result.set(ary, async=async)
1680 return result
/Users/robin/.local/lib/python2.7/site-packages/pyopencl/array.pyc in __init__(self, cqa, shape, dtype, order, allocator, data, offset, queue, strides, events)
564
565 self.base_data = cl.Buffer(
--> 566 context, cl.mem_flags.READ_WRITE, alloc_nbytes)
567 else:
568 self.base_data = self.allocator(alloc_nbytes)
LogicError: create_buffer failed: invalid buffer sizeHi,
I am using the gputools library in my project and I have a problem. When I try to render images with the nlm3 filter and the GPU does not support the amount of images, I get the error of the attached image. However, the GPU continues to process the images. Is there any solution to this problem (kill the process)?
Thanks!
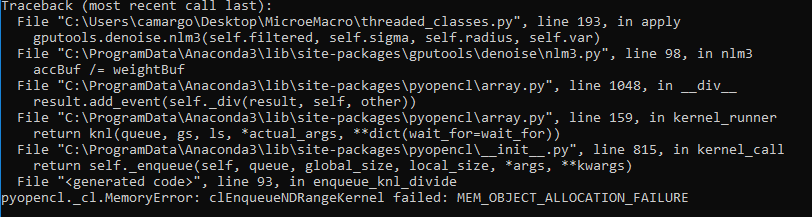
hello @maweigert , happy new year!
I was wondering your plans on the future of gputools. Are you planning to make new versions?
I found small incompatibilities with recent NumPy and some parts of the repo, like:
gputools/gputools/core/ocltypes.py
Line 29 in 4ca3b01
numpy>=1.24. I like to patch this, and I believe I can help with a couple more small items around the repo, like compatibility with different python versions and so.
I am happy to make PRs to this repo to help, or I can fork it if you are planning to archive this repository. Please advise me on what you like me to do.
I am trying to develop a 3D StarDist model using the Jupyter notebook however I realized my process is running in the CPU instead of the GPU making my the training process run forever. I realized I did not have gup_tools() installed but so far I have not been able to install it. I already try to install it using pip and the developmental version, also I try the troubleshooting suggestions downloading they suggested in the GitHub gputools website (I am not sure if I did this part correctly). Can you help me with what else I can do to run my process in my GPU?
In this case, I am running 3D StarDist without the augmentation process in order to save time during the training but I do not know if this is affecting the speed of the process. I am using the next configuration
conf = Config3D (
rays = rays,
grid = grid,
anisotropy = anisotropy,
use_gpu = use_gpu,
n_channel_in = n_channel,
# adjust for your data below (make patch size as large as possible)
train_patch_size = (48,96,96),
train_epochs = 200,
train_batch_size = 2,
)
My images are 2 fluorescence stacks of 85 images of size 340x310 pixels plus 2 of the demo images.
Thank you in advance.
when i use this api, it shows
"UserWarning: gputools.transform.affine: API change as of gputools>= 0.2.8: the inverse of the matrix is now used as in scipy.ndimage.affine_transform
"gputools.transform.affine: API change as of gputools>= 0.2.8: the inverse of the matrix is now used as in scipy.ndimage.affine_transform""
and the performance has no advantages which means that transforms.rotate does not make use of gpu.
where i am wrong?
I'm using gputools to do ndarray smoothing. After finished processing, I found the GPU still hold hundreds of MB memory. How can I release that part of memory appropriately?
Sample codes:
from gputools.convolve import median_filter
import numpy as np
array = np.random.randint(0, 2, (128, 128, 128))
smoothed_array = mediean_filter(array, size=5)A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.