![]()

Quick links: Documentation | Installation | R examples | Python examples
Get all the goodies of UpSetR, but with full extensibility of ggplot2.
Click here to display the source code
library(ggplot2)
library(ComplexUpset)
if(!require(ggplot2movies)) install.packages('ggplot2movies')
movies = ggplot2movies::movies
genres = c('Action', 'Animation', 'Comedy', 'Drama', 'Documentary', 'Romance')
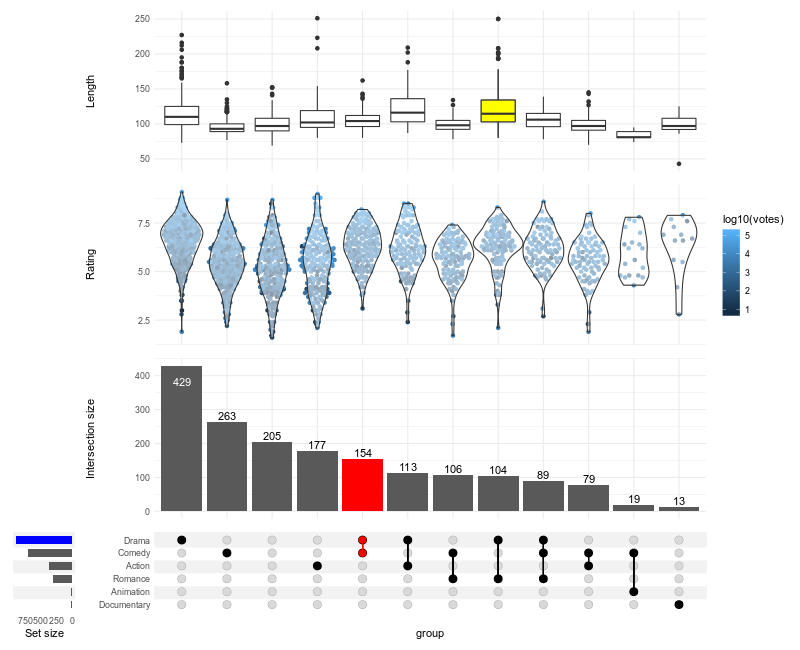
upset(
movies,
genres,
annotations = list(
'Length'=ggplot(mapping=aes(x=intersection, y=length)) + geom_boxplot(),
'Rating'=ggplot(mapping=aes(x=intersection, y=rating))
# if you do not want to install ggbeeswarm, you can use geom_jitter
+ ggbeeswarm::geom_quasirandom(aes(color=log10(votes)))
+ geom_violin(width=1.1, alpha=0.5)
),
queries=list(
upset_query(
intersect=c('Drama', 'Comedy'),
color='red',
fill='red',
only_components=c('intersections_matrix', 'Intersection size')
),
upset_query(
set='Drama',
fill='blue'
),
upset_query(
intersect=c('Romance', 'Drama'),
fill='yellow',
only_components=c('Length')
)
),
min_size=10,
width_ratio=0.1
)The full list of examples is available in the documentation; it also contains instructions for the use from Python.
To get the most recent version, open R and run:
if(!require(devtools)) install.packages("devtools")
devtools::install_github("krassowski/complex-upset")Alternatively, to get a stable CRAN release (which may be one version behind at times):
install.packages('ComplexUpset')Or, if you use conda/mamba:
conda install -c conda-forge r-complexupset- UpSetR is a powerful tool and the pioneer in the UpSet visualisations; it was not designed to be extended with ggplot components. Unfortunately, the repository is no longer active (for two years now).
- ggupset uses scales to convert a single plot to upsets plots, e.g. with
scale_x_upset- a really nice approach, recommended for simple ggplot. - a cowplot-based upset was demonstrated in an online publication, however cowplot (a great tool at the time) got superseded by even greater tool: patchwork, which is what is used by ComplexUpset.
- ComplexHeatmap also offers a way to generate UpSet plots with annotations; while not ggplot2-centered, it provides extensive customization options, with a clear API. It may be the best choice if you already use it for heatmaps.
Use whichever tool you find the most useful for your particular use. The rational of making this repository public is not only to share the code, but also to demonstrate how simple it is now to create complex visualisations with patchwork (without the need to learn the ggplot internals).
For the interactive use, check out the VCG/upset. Regardless of the tool chosen, you may want to cite (Lex et al, 2014) when using UpSet plots, especially in fields still dominated by Venn diagrams.
Here are example publications and preprints including figures generated with this library:
- Martín-Martín et al. (2020). Google Scholar, Microsoft Academic, Scopus, Dimensions, Web of Science, and OpenCitations’ COCI: a multidisciplinary comparison of coverage via citations, Scientometrics: Figure 2
- Krassowski et al. (2020). Analyses for "State of the field in multi-omics research: from computational needs to data mining and sharing, Frontiers in Genetics: Figure 5
- Green et al. (2020). Metabolic correlates of late midlife cognitive function: findings from the 1946 British Birth Cohort, medRxiv: Figure 2
- McDaniel et al. (2020). Metabolic differentiation of co-occurring Accumulibacter clades revealed through genome-resolved metatranscriptomics, bioRxiv Figure 3
- Kozlowski et al. (2020). Transposable Elements are an evolutionary force shaping genomic plasticity in the parthenogenetic root-knot nematode Meloidogyne incognita, bioRxiv: Figure 7
- Swamy et al. (2020). A long read optimized de novo transcriptome pipeline reveals novel ocular developmentally regulated gene isoforms and disease targets, bioRxiv: Figure 4
The list is not meant to be exhaustive, but representative of applications to different fields, and of different usage ideas. You are welcome to add your own publication by suggesting an edit.
The unit tests are run with testhat, and the visual "doppelganger" tests use vdiffr.
The test cases for visual tests are auto-generated from the examples in the documentation; after changing or adding an example, please run:
scripts/prepare_for_tests.shto generate updated test cases, andscripts/manage_visual_tests.shto validate the generated images.
Originally developed in course of a DPhil programme in Women's & Reproductive Health at OxfordNuffieldWRH.