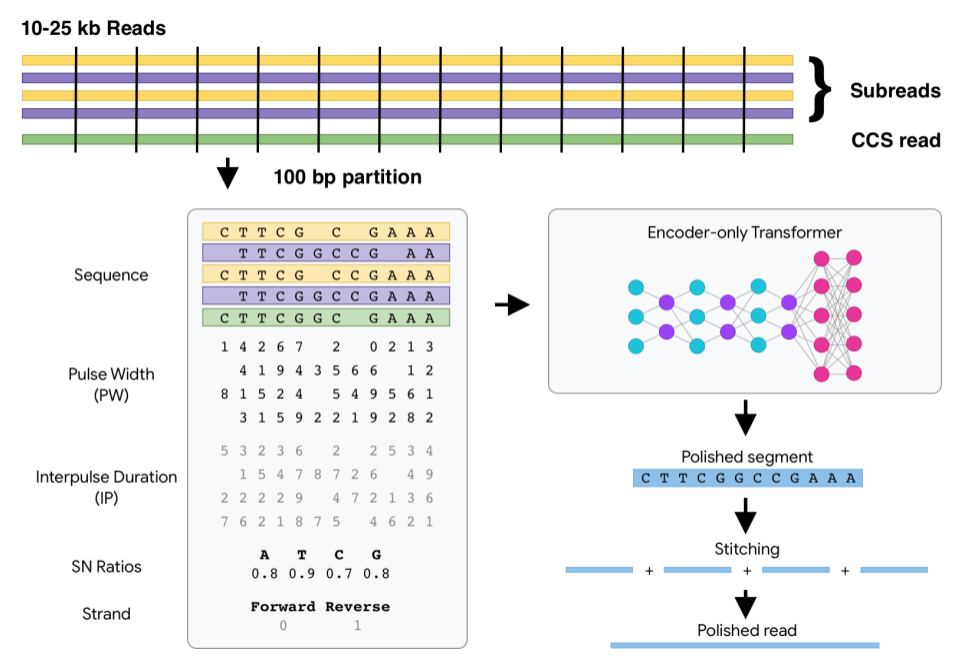
I am trying to install DeepConsensus on an HPC environment (no GPU) without root permissions, and without Docker/Singularity access. I am approaching this by making a deepconsensus venv and trying to install with a modified install script. I have done the following steps:
#!/bin/bash
# Copyright (c) 2021, Google Inc.
# All rights reserved.
#
# Redistribution and use in source and binary forms, with or without modification,
# are permitted provided that the following conditions are met:
#
# 1. Redistributions of source code must retain the above copyright notice, this
# list of conditions and the following disclaimer.
#
# 2. Redistributions in binary form must reproduce the above copyright notice,
# this list of conditions and the following disclaimer in the documentation
# and/or other materials provided with the distribution.
#
# 3. Neither the name of Google Inc. nor the names of its contributors
# may be used to endorse or promote products derived from this software without
# specific prior written permission.
#
# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
# ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
# WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR
# ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
# (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
# LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON
# ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
# (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
# SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
# Usage: source install.sh
#
# This script installs all the packages required to build DeepConsensus.
#
# This script will run as-is on Ubuntu 20.04.
#
# We also assume that apt-get is already installed and available.
function note_build_stage {
echo "========== [$(date)] Stage '${1}' starting"
}
# Update package list
################################################################################
# Install pip
################################################################################
python3 -m pip install --upgrade pip
# Update PATH so that newly installed pip is the one we actually use.
export PATH="$SCRATCH/venvs/deepconsensus_venv_1/bin:$PATH"
echo "$(pip --version)"
# Install python packages used by DeepConsensus.
################################################################################
python3 -m pip install -r requirements.txt
python3 -m pip install "intel-tensorflow>=2.4.0,<=2.7.0"
(deepconsensus_venv_1) [labueg@login04 /lustre/fs5/vgl/scratch/labueg/deepconsensus]$ source install_edit.sh
Collecting pip
Using cached pip-22.1.2-py3-none-any.whl (2.1 MB)
Installing collected packages: pip
Attempting uninstall: pip
Found existing installation: pip 20.2.3
Uninstalling pip-20.2.3:
Successfully uninstalled pip-20.2.3
Successfully installed pip-22.1.2
pip 22.1.2 from /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages/pip (python 3.8)
Collecting numpy>=1.19
Using cached numpy-1.23.0-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (17.1 MB)
Collecting pandas>=1.1
Using cached pandas-1.4.3-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (11.7 MB)
Collecting tf-models-official<=2.7.0,>=2.4.0
Using cached tf_models_official-2.7.0-py2.py3-none-any.whl (1.8 MB)
Collecting ml_collections>=0.1.0
Using cached ml_collections-0.1.1.tar.gz (77 kB)
Preparing metadata (setup.py) ... done
Collecting absl-py>=0.13.0
Using cached absl_py-1.1.0-py3-none-any.whl (123 kB)
Collecting pysam
Using cached pysam-0.19.1.tar.gz (3.9 MB)
Preparing metadata (setup.py) ... done
Collecting python-dateutil>=2.8.1
Using cached python_dateutil-2.8.2-py2.py3-none-any.whl (247 kB)
Collecting pytz>=2020.1
Using cached pytz-2022.1-py2.py3-none-any.whl (503 kB)
Collecting py-cpuinfo>=3.3.0
Using cached py-cpuinfo-8.0.0.tar.gz (99 kB)
Preparing metadata (setup.py) ... done
Collecting opencv-python-headless
Using cached opencv_python_headless-4.6.0.66-cp36-abi3-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (48.3 MB)
Collecting tensorflow-datasets
Using cached tensorflow_datasets-4.6.0-py3-none-any.whl (4.3 MB)
Collecting gin-config
Using cached gin_config-0.5.0-py3-none-any.whl (61 kB)
Collecting tensorflow-hub>=0.6.0
Using cached tensorflow_hub-0.12.0-py2.py3-none-any.whl (108 kB)
Collecting tensorflow-text>=2.7.0
Using cached tensorflow_text-2.9.0-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (4.6 MB)
Collecting Cython
Using cached Cython-0.29.30-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.manylinux_2_24_x86_64.whl (1.9 MB)
Collecting oauth2client
Using cached oauth2client-4.1.3-py2.py3-none-any.whl (98 kB)
Collecting scipy>=0.19.1
Using cached scipy-1.8.1-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (41.6 MB)
Collecting six
Using cached six-1.16.0-py2.py3-none-any.whl (11 kB)
Collecting tensorflow-model-optimization>=0.4.1
Using cached tensorflow_model_optimization-0.7.2-py2.py3-none-any.whl (237 kB)
Collecting pycocotools
Using cached pycocotools-2.0.4-cp38-cp38-linux_x86_64.whl
Collecting kaggle>=1.3.9
Using cached kaggle-1.5.12.tar.gz (58 kB)
Preparing metadata (setup.py) ... done
Collecting tensorflow>=2.7.0
Using cached tensorflow-2.9.1-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (511.7 MB)
Collecting matplotlib
Using cached matplotlib-3.5.2-cp38-cp38-manylinux_2_5_x86_64.manylinux1_x86_64.whl (11.3 MB)
Collecting seqeval
Using cached seqeval-1.2.2.tar.gz (43 kB)
Preparing metadata (setup.py) ... done
Collecting tensorflow-addons
Using cached tensorflow_addons-0.17.1-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (1.1 MB)
Collecting pyyaml>=5.1
Using cached PyYAML-6.0-cp38-cp38-manylinux_2_5_x86_64.manylinux1_x86_64.manylinux_2_12_x86_64.manylinux2010_x86_64.whl (701 kB)
Collecting google-api-python-client>=1.6.7
Using cached google_api_python_client-2.51.0-py2.py3-none-any.whl (8.6 MB)
Collecting psutil>=5.4.3
Using cached psutil-5.9.1-cp38-cp38-manylinux_2_12_x86_64.manylinux2010_x86_64.manylinux_2_17_x86_64.manylinux2014_x86_64.whl (284 kB)
Collecting sacrebleu
Using cached sacrebleu-2.1.0-py3-none-any.whl (92 kB)
Collecting Pillow
Using cached Pillow-9.1.1-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (3.1 MB)
Collecting sentencepiece
Using cached sentencepiece-0.1.96-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (1.2 MB)
Collecting tf-slim>=1.1.0
Using cached tf_slim-1.1.0-py2.py3-none-any.whl (352 kB)
Collecting contextlib2
Using cached contextlib2-21.6.0-py2.py3-none-any.whl (13 kB)
Collecting google-api-core!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.0,<3.0.0dev,>=1.31.5
Using cached google_api_core-2.8.2-py3-none-any.whl (114 kB)
Collecting google-auth-httplib2>=0.1.0
Using cached google_auth_httplib2-0.1.0-py2.py3-none-any.whl (9.3 kB)
Collecting google-auth<3.0.0dev,>=1.16.0
Using cached google_auth-2.8.0-py2.py3-none-any.whl (164 kB)
Collecting httplib2<1dev,>=0.15.0
Using cached httplib2-0.20.4-py3-none-any.whl (96 kB)
Collecting uritemplate<5,>=3.0.1
Using cached uritemplate-4.1.1-py2.py3-none-any.whl (10 kB)
Collecting certifi
Using cached certifi-2022.6.15-py3-none-any.whl (160 kB)
Collecting requests
Using cached requests-2.28.0-py3-none-any.whl (62 kB)
Collecting tqdm
Using cached tqdm-4.64.0-py2.py3-none-any.whl (78 kB)
Collecting python-slugify
Using cached python_slugify-6.1.2-py2.py3-none-any.whl (9.4 kB)
Collecting urllib3
Using cached urllib3-1.26.9-py2.py3-none-any.whl (138 kB)
Collecting grpcio<2.0,>=1.24.3
Using cached grpcio-1.47.0-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (4.5 MB)
Collecting tensorboard<2.10,>=2.9
Using cached tensorboard-2.9.1-py3-none-any.whl (5.8 MB)
Collecting tensorflow-io-gcs-filesystem>=0.23.1
Using cached tensorflow_io_gcs_filesystem-0.26.0-cp38-cp38-manylinux_2_12_x86_64.manylinux2010_x86_64.whl (2.4 MB)
Collecting libclang>=13.0.0
Using cached libclang-14.0.1-py2.py3-none-manylinux1_x86_64.whl (14.5 MB)
Collecting protobuf<3.20,>=3.9.2
Using cached protobuf-3.19.4-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (1.1 MB)
Collecting keras-preprocessing>=1.1.1
Using cached Keras_Preprocessing-1.1.2-py2.py3-none-any.whl (42 kB)
Collecting opt-einsum>=2.3.2
Using cached opt_einsum-3.3.0-py3-none-any.whl (65 kB)
Collecting google-pasta>=0.1.1
Using cached google_pasta-0.2.0-py3-none-any.whl (57 kB)
Collecting flatbuffers<2,>=1.12
Using cached flatbuffers-1.12-py2.py3-none-any.whl (15 kB)
Collecting h5py>=2.9.0
Using cached h5py-3.7.0-cp38-cp38-manylinux_2_12_x86_64.manylinux2010_x86_64.whl (4.5 MB)
Collecting gast<=0.4.0,>=0.2.1
Using cached gast-0.4.0-py3-none-any.whl (9.8 kB)
Collecting wrapt>=1.11.0
Using cached wrapt-1.14.1-cp38-cp38-manylinux_2_5_x86_64.manylinux1_x86_64.manylinux_2_17_x86_64.manylinux2014_x86_64.whl (81 kB)
Collecting packaging
Using cached packaging-21.3-py3-none-any.whl (40 kB)
Collecting tensorflow-estimator<2.10.0,>=2.9.0rc0
Using cached tensorflow_estimator-2.9.0-py2.py3-none-any.whl (438 kB)
Requirement already satisfied: setuptools in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from tensorflow>=2.7.0->tf-models-official<=2.7.0,>=2.4.0->-r requirements.txt (line 3)) (49.2.1)
Collecting keras<2.10.0,>=2.9.0rc0
Using cached keras-2.9.0-py2.py3-none-any.whl (1.6 MB)
Collecting astunparse>=1.6.0
Using cached astunparse-1.6.3-py2.py3-none-any.whl (12 kB)
Collecting termcolor>=1.1.0
Using cached termcolor-1.1.0.tar.gz (3.9 kB)
Preparing metadata (setup.py) ... done
Collecting typing-extensions>=3.6.6
Using cached typing_extensions-4.2.0-py3-none-any.whl (24 kB)
Collecting dm-tree~=0.1.1
Using cached dm_tree-0.1.7-cp38-cp38-manylinux_2_12_x86_64.manylinux2010_x86_64.whl (142 kB)
Collecting kiwisolver>=1.0.1
Using cached kiwisolver-1.4.3-cp38-cp38-manylinux_2_5_x86_64.manylinux1_x86_64.whl (1.2 MB)
Collecting pyparsing>=2.2.1
Using cached pyparsing-3.0.9-py3-none-any.whl (98 kB)
Collecting cycler>=0.10
Using cached cycler-0.11.0-py3-none-any.whl (6.4 kB)
Collecting fonttools>=4.22.0
Using cached fonttools-4.33.3-py3-none-any.whl (930 kB)
Collecting pyasn1-modules>=0.0.5
Using cached pyasn1_modules-0.2.8-py2.py3-none-any.whl (155 kB)
Collecting pyasn1>=0.1.7
Using cached pyasn1-0.4.8-py2.py3-none-any.whl (77 kB)
Collecting rsa>=3.1.4
Using cached rsa-4.8-py3-none-any.whl (39 kB)
Collecting colorama
Using cached colorama-0.4.5-py2.py3-none-any.whl (16 kB)
Collecting regex
Using cached regex-2022.6.2-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (764 kB)
Collecting portalocker
Using cached portalocker-2.4.0-py2.py3-none-any.whl (16 kB)
Collecting tabulate>=0.8.9
Using cached tabulate-0.8.10-py3-none-any.whl (29 kB)
Collecting scikit-learn>=0.21.3
Using cached scikit_learn-1.1.1-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (31.2 MB)
Collecting typeguard>=2.7
Using cached typeguard-2.13.3-py3-none-any.whl (17 kB)
Collecting toml
Using cached toml-0.10.2-py2.py3-none-any.whl (16 kB)
Collecting etils[epath]
Using cached etils-0.6.0-py3-none-any.whl (98 kB)
Collecting importlib-resources
Using cached importlib_resources-5.8.0-py3-none-any.whl (28 kB)
Collecting promise
Using cached promise-2.3.tar.gz (19 kB)
Preparing metadata (setup.py) ... done
Collecting tensorflow-metadata
Using cached tensorflow_metadata-1.9.0-py3-none-any.whl (51 kB)
Collecting dill
Using cached dill-0.3.5.1-py2.py3-none-any.whl (95 kB)
Collecting wheel<1.0,>=0.23.0
Using cached wheel-0.37.1-py2.py3-none-any.whl (35 kB)
Collecting googleapis-common-protos<2.0dev,>=1.56.2
Using cached googleapis_common_protos-1.56.3-py2.py3-none-any.whl (211 kB)
Collecting cachetools<6.0,>=2.0.0
Using cached cachetools-5.2.0-py3-none-any.whl (9.3 kB)
Collecting idna<4,>=2.5
Using cached idna-3.3-py3-none-any.whl (61 kB)
Collecting charset-normalizer~=2.0.0
Using cached charset_normalizer-2.0.12-py3-none-any.whl (39 kB)
Collecting joblib>=1.0.0
Using cached joblib-1.1.0-py2.py3-none-any.whl (306 kB)
Collecting threadpoolctl>=2.0.0
Using cached threadpoolctl-3.1.0-py3-none-any.whl (14 kB)
Collecting werkzeug>=1.0.1
Using cached Werkzeug-2.1.2-py3-none-any.whl (224 kB)
Collecting tensorboard-data-server<0.7.0,>=0.6.0
Using cached tensorboard_data_server-0.6.1-py3-none-manylinux2010_x86_64.whl (4.9 MB)
Collecting markdown>=2.6.8
Using cached Markdown-3.3.7-py3-none-any.whl (97 kB)
Collecting google-auth-oauthlib<0.5,>=0.4.1
Using cached google_auth_oauthlib-0.4.6-py2.py3-none-any.whl (18 kB)
Collecting tensorboard-plugin-wit>=1.6.0
Using cached tensorboard_plugin_wit-1.8.1-py3-none-any.whl (781 kB)
Collecting zipp
Using cached zipp-3.8.0-py3-none-any.whl (5.4 kB)
Collecting text-unidecode>=1.3
Using cached text_unidecode-1.3-py2.py3-none-any.whl (78 kB)
Collecting requests-oauthlib>=0.7.0
Using cached requests_oauthlib-1.3.1-py2.py3-none-any.whl (23 kB)
Collecting importlib-metadata>=4.4
Using cached importlib_metadata-4.12.0-py3-none-any.whl (21 kB)
Collecting oauthlib>=3.0.0
Using cached oauthlib-3.2.0-py3-none-any.whl (151 kB)
Using legacy 'setup.py install' for ml_collections, since package 'wheel' is not installed.
Using legacy 'setup.py install' for pysam, since package 'wheel' is not installed.
Using legacy 'setup.py install' for kaggle, since package 'wheel' is not installed.
Using legacy 'setup.py install' for py-cpuinfo, since package 'wheel' is not installed.
Using legacy 'setup.py install' for seqeval, since package 'wheel' is not installed.
Using legacy 'setup.py install' for termcolor, since package 'wheel' is not installed.
Using legacy 'setup.py install' for promise, since package 'wheel' is not installed.
Installing collected packages: text-unidecode, termcolor, tensorboard-plugin-wit, sentencepiece, pytz, pysam, pyasn1, py-cpuinfo, libclang, keras, gin-config, flatbuffers, dm-tree, zipp, wrapt, wheel, werkzeug, urllib3, uritemplate, typing-extensions, typeguard, tqdm, toml, threadpoolctl, tensorflow-io-gcs-filesystem, tensorflow-estimator, tensorboard-data-server, tabulate, six, rsa, regex, pyyaml, python-slugify, pyparsing, pyasn1-modules, psutil, protobuf, portalocker, Pillow, oauthlib, numpy, kiwisolver, joblib, idna, gast, fonttools, etils, dill, Cython, cycler, contextlib2, colorama, charset-normalizer, certifi, cachetools, absl-py, tf-slim, tensorflow-model-optimization, tensorflow-hub, scipy, sacrebleu, requests, python-dateutil, promise, packaging, opt-einsum, opencv-python-headless, ml_collections, keras-preprocessing, importlib-resources, importlib-metadata, httplib2, h5py, grpcio, googleapis-common-protos, google-pasta, google-auth, astunparse, tensorflow-metadata, tensorflow-addons, scikit-learn, requests-oauthlib, pandas, oauth2client, matplotlib, markdown, kaggle, google-auth-httplib2, google-api-core, tensorflow-datasets, seqeval, pycocotools, google-auth-oauthlib, google-api-python-client, tensorboard, tensorflow, tensorflow-text, tf-models-official
Running setup.py install for termcolor ... done
Running setup.py install for pysam ... done
Running setup.py install for py-cpuinfo ... done
Running setup.py install for promise ... done
Running setup.py install for ml_collections ... done
Running setup.py install for kaggle ... done
Running setup.py install for seqeval ... done
Successfully installed Cython-0.29.30 Pillow-9.1.1 absl-py-1.1.0 astunparse-1.6.3 cachetools-5.2.0 certifi-2022.6.15 charset-normalizer-2.0.12 colorama-0.4.5 contextlib2-21.6.0 cycler-0.11.0 dill-0.3.5.1 dm-tree-0.1.7 etils-0.6.0 flatbuffers-1.12 fonttools-4.33.3 gast-0.4.0 gin-config-0.5.0 google-api-core-2.8.2 google-api-python-client-2.51.0 google-auth-2.8.0 google-auth-httplib2-0.1.0 google-auth-oauthlib-0.4.6 google-pasta-0.2.0 googleapis-common-protos-1.56.3 grpcio-1.47.0 h5py-3.7.0 httplib2-0.20.4 idna-3.3 importlib-metadata-4.12.0 importlib-resources-5.8.0 joblib-1.1.0 kaggle-1.5.12 keras-2.9.0 keras-preprocessing-1.1.2 kiwisolver-1.4.3 libclang-14.0.1 markdown-3.3.7 matplotlib-3.5.2 ml_collections-0.1.1 numpy-1.23.0 oauth2client-4.1.3 oauthlib-3.2.0 opencv-python-headless-4.6.0.66 opt-einsum-3.3.0 packaging-21.3 pandas-1.4.3 portalocker-2.4.0 promise-2.3 protobuf-3.19.4 psutil-5.9.1 py-cpuinfo-8.0.0 pyasn1-0.4.8 pyasn1-modules-0.2.8 pycocotools-2.0.4 pyparsing-3.0.9 pysam-0.19.1 python-dateutil-2.8.2 python-slugify-6.1.2 pytz-2022.1 pyyaml-6.0 regex-2022.6.2 requests-2.28.0 requests-oauthlib-1.3.1 rsa-4.8 sacrebleu-2.1.0 scikit-learn-1.1.1 scipy-1.8.1 sentencepiece-0.1.96 seqeval-1.2.2 six-1.16.0 tabulate-0.8.10 tensorboard-2.9.1 tensorboard-data-server-0.6.1 tensorboard-plugin-wit-1.8.1 tensorflow-2.9.1 tensorflow-addons-0.17.1 tensorflow-datasets-4.6.0 tensorflow-estimator-2.9.0 tensorflow-hub-0.12.0 tensorflow-io-gcs-filesystem-0.26.0 tensorflow-metadata-1.9.0 tensorflow-model-optimization-0.7.2 tensorflow-text-2.9.0 termcolor-1.1.0 text-unidecode-1.3 tf-models-official-2.7.0 tf-slim-1.1.0 threadpoolctl-3.1.0 toml-0.10.2 tqdm-4.64.0 typeguard-2.13.3 typing-extensions-4.2.0 uritemplate-4.1.1 urllib3-1.26.9 werkzeug-2.1.2 wheel-0.37.1 wrapt-1.14.1 zipp-3.8.0
Collecting intel-tensorflow<=2.7.0,>=2.4.0
Using cached intel_tensorflow-2.7.0-cp38-cp38-manylinux2010_x86_64.whl (186.4 MB)
Requirement already satisfied: absl-py>=0.4.0 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from intel-tensorflow<=2.7.0,>=2.4.0) (1.1.0)
Requirement already satisfied: flatbuffers<3.0,>=1.12 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from intel-tensorflow<=2.7.0,>=2.4.0) (1.12)
Requirement already satisfied: google-pasta>=0.1.1 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from intel-tensorflow<=2.7.0,>=2.4.0) (0.2.0)
Requirement already satisfied: numpy>=1.14.5 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from intel-tensorflow<=2.7.0,>=2.4.0) (1.23.0)
Requirement already satisfied: grpcio<2.0,>=1.24.3 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from intel-tensorflow<=2.7.0,>=2.4.0) (1.47.0)
Collecting tensorflow-estimator<2.8,~=2.7.0rc0
Using cached tensorflow_estimator-2.7.0-py2.py3-none-any.whl (463 kB)
Requirement already satisfied: six>=1.12.0 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from intel-tensorflow<=2.7.0,>=2.4.0) (1.16.0)
Requirement already satisfied: protobuf>=3.9.2 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from intel-tensorflow<=2.7.0,>=2.4.0) (3.19.4)
Requirement already satisfied: opt-einsum>=2.3.2 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from intel-tensorflow<=2.7.0,>=2.4.0) (3.3.0)
Requirement already satisfied: tensorboard~=2.6 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from intel-tensorflow<=2.7.0,>=2.4.0) (2.9.1)
Requirement already satisfied: h5py>=2.9.0 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from intel-tensorflow<=2.7.0,>=2.4.0) (3.7.0)
Requirement already satisfied: wheel<1.0,>=0.32.0 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from intel-tensorflow<=2.7.0,>=2.4.0) (0.37.1)
Requirement already satisfied: termcolor>=1.1.0 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from intel-tensorflow<=2.7.0,>=2.4.0) (1.1.0)
Requirement already satisfied: gast<0.5.0,>=0.2.1 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from intel-tensorflow<=2.7.0,>=2.4.0) (0.4.0)
Requirement already satisfied: libclang>=9.0.1 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from intel-tensorflow<=2.7.0,>=2.4.0) (14.0.1)
Requirement already satisfied: wrapt>=1.11.0 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from intel-tensorflow<=2.7.0,>=2.4.0) (1.14.1)
Requirement already satisfied: astunparse>=1.6.0 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from intel-tensorflow<=2.7.0,>=2.4.0) (1.6.3)
Requirement already satisfied: keras-preprocessing>=1.1.1 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from intel-tensorflow<=2.7.0,>=2.4.0) (1.1.2)
Collecting keras<2.8,>=2.7.0rc0
Using cached keras-2.7.0-py2.py3-none-any.whl (1.3 MB)
Requirement already satisfied: typing-extensions>=3.6.6 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from intel-tensorflow<=2.7.0,>=2.4.0) (4.2.0)
Requirement already satisfied: tensorflow-io-gcs-filesystem>=0.21.0 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from intel-tensorflow<=2.7.0,>=2.4.0) (0.26.0)
Requirement already satisfied: markdown>=2.6.8 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from tensorboard~=2.6->intel-tensorflow<=2.7.0,>=2.4.0) (3.3.7)
Requirement already satisfied: requests<3,>=2.21.0 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from tensorboard~=2.6->intel-tensorflow<=2.7.0,>=2.4.0) (2.28.0)
Requirement already satisfied: setuptools>=41.0.0 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from tensorboard~=2.6->intel-tensorflow<=2.7.0,>=2.4.0) (49.2.1)
Requirement already satisfied: tensorboard-data-server<0.7.0,>=0.6.0 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from tensorboard~=2.6->intel-tensorflow<=2.7.0,>=2.4.0) (0.6.1)
Requirement already satisfied: tensorboard-plugin-wit>=1.6.0 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from tensorboard~=2.6->intel-tensorflow<=2.7.0,>=2.4.0) (1.8.1)
Requirement already satisfied: werkzeug>=1.0.1 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from tensorboard~=2.6->intel-tensorflow<=2.7.0,>=2.4.0) (2.1.2)
Requirement already satisfied: google-auth-oauthlib<0.5,>=0.4.1 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from tensorboard~=2.6->intel-tensorflow<=2.7.0,>=2.4.0) (0.4.6)
Requirement already satisfied: google-auth<3,>=1.6.3 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from tensorboard~=2.6->intel-tensorflow<=2.7.0,>=2.4.0) (2.8.0)
Requirement already satisfied: cachetools<6.0,>=2.0.0 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from google-auth<3,>=1.6.3->tensorboard~=2.6->intel-tensorflow<=2.7.0,>=2.4.0) (5.2.0)
Requirement already satisfied: rsa<5,>=3.1.4 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from google-auth<3,>=1.6.3->tensorboard~=2.6->intel-tensorflow<=2.7.0,>=2.4.0) (4.8)
Requirement already satisfied: pyasn1-modules>=0.2.1 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from google-auth<3,>=1.6.3->tensorboard~=2.6->intel-tensorflow<=2.7.0,>=2.4.0) (0.2.8)
Requirement already satisfied: requests-oauthlib>=0.7.0 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from google-auth-oauthlib<0.5,>=0.4.1->tensorboard~=2.6->intel-tensorflow<=2.7.0,>=2.4.0) (1.3.1)
Requirement already satisfied: importlib-metadata>=4.4 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from markdown>=2.6.8->tensorboard~=2.6->intel-tensorflow<=2.7.0,>=2.4.0) (4.12.0)
Requirement already satisfied: charset-normalizer~=2.0.0 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from requests<3,>=2.21.0->tensorboard~=2.6->intel-tensorflow<=2.7.0,>=2.4.0) (2.0.12)
Requirement already satisfied: certifi>=2017.4.17 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from requests<3,>=2.21.0->tensorboard~=2.6->intel-tensorflow<=2.7.0,>=2.4.0) (2022.6.15)
Requirement already satisfied: urllib3<1.27,>=1.21.1 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from requests<3,>=2.21.0->tensorboard~=2.6->intel-tensorflow<=2.7.0,>=2.4.0) (1.26.9)
Requirement already satisfied: idna<4,>=2.5 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from requests<3,>=2.21.0->tensorboard~=2.6->intel-tensorflow<=2.7.0,>=2.4.0) (3.3)
Requirement already satisfied: zipp>=0.5 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from importlib-metadata>=4.4->markdown>=2.6.8->tensorboard~=2.6->intel-tensorflow<=2.7.0,>=2.4.0) (3.8.0)
Requirement already satisfied: pyasn1<0.5.0,>=0.4.6 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from pyasn1-modules>=0.2.1->google-auth<3,>=1.6.3->tensorboard~=2.6->intel-tensorflow<=2.7.0,>=2.4.0) (0.4.8)
Requirement already satisfied: oauthlib>=3.0.0 in /lustre/fs5/vgl/scratch/labueg/venvs/deepconsensus_venv_1/lib/python3.8/site-packages (from requests-oauthlib>=0.7.0->google-auth-oauthlib<0.5,>=0.4.1->tensorboard~=2.6->intel-tensorflow<=2.7.0,>=2.4.0) (3.2.0)
Installing collected packages: tensorflow-estimator, keras, intel-tensorflow
Attempting uninstall: tensorflow-estimator
Found existing installation: tensorflow-estimator 2.9.0
Uninstalling tensorflow-estimator-2.9.0:
Successfully uninstalled tensorflow-estimator-2.9.0
Attempting uninstall: keras
Found existing installation: keras 2.9.0
Uninstalling keras-2.9.0:
Successfully uninstalled keras-2.9.0
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
tensorflow 2.9.1 requires keras<2.10.0,>=2.9.0rc0, but you have keras 2.7.0 which is incompatible.
tensorflow 2.9.1 requires tensorflow-estimator<2.10.0,>=2.9.0rc0, but you have tensorflow-estimator 2.7.0 which is incompatible.
Successfully installed intel-tensorflow-2.7.0 keras-2.7.0 tensorflow-estimator-2.7.0
There is this exception in the output, which leads me to think the installation failed: