openzim / zimit Goto Github PK
View Code? Open in Web Editor NEWMake a ZIM file from any Web site and surf offline!
License: GNU General Public License v3.0
Make a ZIM file from any Web site and surf offline!
License: GNU General Public License v3.0
We need to give the user a sense of the progression of the scraping. For this, the scraper needs to deliver information about it.
This ticket is not:
This ticket asks to offer any way to know for each dimension (running process) the number of items done (current progression offset), the overall number of item to do (maximum). I see for the moment 3 dimensions:
When stopping a running process, via KeyboardInterrupt or docker stop (basically same signal), the zimit process does stop but we're then forced to wait for 30s and then warc2zim is still called ; creating an incorrect ZIM file.
Correct behavior would be to only sleep if zimit is successful and otherwise exit directly, propagating the return code.
Scraping fondamentaux, I got a lot of timeouts on pages (169!) with the default 30s timeout.
@ikreymer could you please give us more details on the implication of timeout:
await page.goto(url, {waitUntil, timeout}); implies it's the time for the page to load (that's the default waitUntil value). Is this the time before the document loaded event?My initial though would be to use a large value here to capture long pages and other pages would still load and be processed fast.
ZIM:

Online:

My understanding was that if no custom favicon is given, the web site favicon will be taken and put to the ZIM favicon. This seems to be the right behaviour and this is what was happening with lesfondamentaux with previous scrape.
I have made a new scrape of lesfondamentaux (after having set custom title/description and change the default URL to https://lesfondamentaux.reseau-canope.fr/ in place of https://lesfondamentaux.reseau-canope.fr/accueil.html) this morning and there is no ZIM favicon anymore:
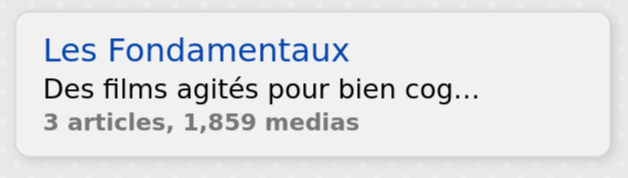
I don't know if there is a sporadic problem, a regression, a bug or a misunderstanding of me.
We shall be able to know whether the --limit information (that is passed to the crawler) has been hit or not.
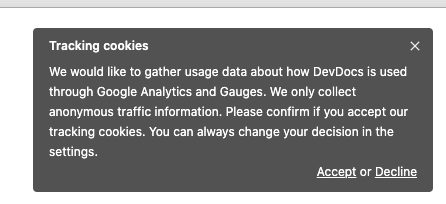
Seen on devdocs.io, a floating window warning the user that tracking cookies are being used.
https://developers.google.com/web/fundamentals/primers/service-workers mentions the need for https during deployment, but states:
During development you'll be able to use service worker through localhost,
Can we have such a development mode for use on a private lan?
Marking this as a bug although it's debatable :)
Since zimit drops to userland in its run script, both the node code and warc2zim are run in userspace. It means that with the current configuration of having /output mapped to the docker volume and using --output=/output, zimit user usually have no rights to create a file or folder inside /output.
This is worked around for nodejs by creating a temp folder and changing its ownership before switching user but doesn't apply to warc2zim.
We could either duplicate node behavior (create a /output/zim/ folder and owning it as zimit) or run as root but I think we cannot assume /output will be writable by zimit user.
Trying zimit on https://mesquartierschinois.wordpress.com returns a 16Mb file with the icon but that cannot be opened
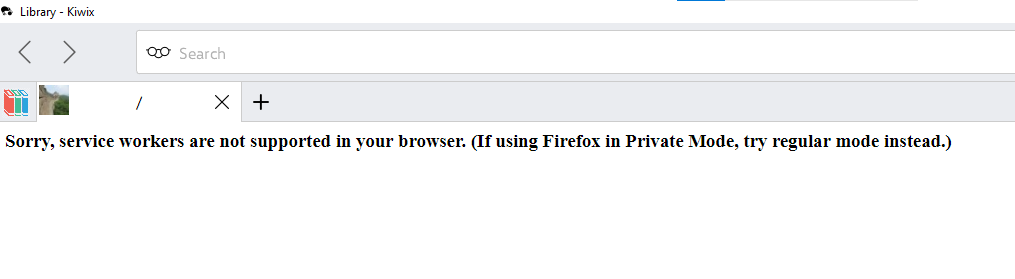
So I launched zimit onto a blog with 187 pages (zimit cutoff at 1,000). Yet I am returned with a zimfile that states 2k articles (see screenshot)

There certainly aren't 1'800 images in there, and as a matter of fact some of them are missing.
https://github.com/webrecorder/ proposes a quality set of tools to scrape random Web sites. We should decide if it would make sense to reuse/patch them for the Zimit project.
First of all the constraints:
I believe this raises a few questions:
It seems as if there is a problem with launching chrome. I did use the --cap-add=SYS_ADMIN --cap-add=NET_ADMIN \ --shm-size=2gb flags. Puppeteer does mention that as of Chrome 65 this should not be necessary anymore and can be replaced with the --disable-dev-shm-usage flag. But this flag is apparently unknown by zimit.
[INFO] Arguments valid, no inputs to process. Exiting with error code 100
Crawl failed, ZIM creation skipped
Error: Unable to launch browser, error message: Failed to launch the browser process!
[1108/111448.101769:FATAL:zygote_host_impl_linux.cc(117)] No usable sandbox! Update your kernel or see https://chromium.googlesource.com/chromium/src/+/master/docs/linux/suid_sandbox_development.md for more information on developing with the SUID sandbox. If you want to live dangerously and need an immediate workaround, you can try using --no-sandbox.
I did try to run this on Synology DSM 6.2.3.
Hi Kiwix team, here's Dumbo with a trivial question.
I've just discovered the Zimit website, and it tells me that "If using Kiwix-Desktop, then you will need to configure it as a Kiwix-serve instance in the settings." So, my dumb question is: where are those settings? I have Kiwix-Desktop version 2.1.2 (2.1.6) for macOS, and I see no Settings or Preferences option in any menu.
Best regards, Stéphane
Using ; in any arg is considered a command line breaker and thus unusable. Using it is a valid use case for arguments such as title or description
Bellow is the list of root URLs to create and test ZIM files off, using zimit's core docker image.
Zimfarm recipes (with appropriate metadata) will be created for each. Original list is on zim-requests
http://bouquineux.com/
https://lesfondamentaux.reseau-canope.fr/accueil.html
http://www.manioc.org/
https://www.der-postillon.com/
https://edu.gcfglobal.org/en/topics/
https://cheatography.com/
https://stacks.math.columbia.edu/
https://africanstorybook.org/
https://devdocs.io/
https://developer.mozilla.org/en-US/
https://journals.openedition.org/bibnum/
https://www.lowtechmagazine.com/
https://www.musictheory.net/lessons
https://courses.lumenlearning.com/catalog/boundlesscourses
The crawling infrastructure is now generic enough and will be use to Webrecorder as part of next-generation Browsertrix Core setup, that runs in a single container. The component can move to the Webrecorder org and have its own Docker image.
This repo will simply inherit the base Docker image and add zimit.py and warc2zim, while the crawling will be maintained by Webrecorder and will be extended to support other use cases, of course making sure that the zimit use case still works.
It may make sense to add a simply integration test (perhaps of isago.ml?) to ensure that thing are working before updating the zimit image. The plan is as follows:
webrecorder/browsertrix-core docker image@rgaudin this is sort of what we discussed yesterday, let me know if you have any thoughts/concerns on this.
Please add a tag or field to the zim catalog which indicates whether https is required for the zim to work.
Ideally, only crawl HTML pages with puppeteer. For PDFs, maybe other static files, load directly via pywb proxy.
Most ZIMs created with zimit raise a lot of errors from zimcheck due to duplicate content. For some like journals.openeditions, it generates a 1.4GB large zimcheck log…
Taking a quick look at those logs, I've identified several common scenarios:
URLs that return nothing or close to nothing are likely to clash with each other. It's clearly visible for ad-related requests with are mostly unique due to tracking IDs but don't serve any content
stats.g.doubleclick.net/j/collect?t=dc&aip=1&_r=3&v=1&_v=j86&tid=UA-605379-1&cid=1706321979.1602606428&jid=1297879906&gjid=1029232721&_gid=1576942764.1602606428&_u=YGBAgEABAAAAAE~&z=1259133512 (idx 430) and stats.g.doubleclick.net/j/collect?t=dc&aip=1&_r=3&v=1&_v=j86&tid=UA-605379-5&cid=1706321979.1602606428&jid=1274727808&gjid=439935886&_gid=1576942764.1602606428&_u=YGDAgEABAAAAAE~&z=1784451389 (idx 435)
The content of those 2 URLs is 1. In this ZIM, there are about a thousand occurrences of those.
Another example, is with google analytics
www.google-analytics.com/collect?v=1&_v=j86&a=1124483121&t=pageview&_s=1&dl=https%3A%2F%2Fedu.gcfglobal.org%2Fen%2Ftopics%2Fmath%2F&dp=%2Fen%2Ftopics%2Fmath%2F&ul=en-us&de=UTF-8&dt=Free%20Math%20Tutorials%20at%20GCFGlobal&sd=24-bit&sr=800x600&vp=800x600&je=0&_u=QCCAgEAB~&jid=1596307224&gjid=5366868&cid=1706321979.1602606428&tid=UA-605379-5&_gid=1576942764.1602606428&z=1957848174 (idx 470) and www.google-analytics.com/collect?v=1&_v=j86&a=1747573734&t=pageview&_s=1&dl=https%3A%2F%2Fedu.gcfglobal.org%2Fen%2Ftopics%2Foffice2000%2F&dp=%2Fen%2Ftopics%2Foffice2000%2F&ul=en-us&de=UTF-8&dt=Free%20Office%202000%20Tutorials%20at%20GCFGlobal&sd=24-bit&sr=800x600&vp=800x600&je=0&_u=QCCAgEAB~&jid=264127233&gjid=379906133&cid=1706321979.1602606428&tid=UA-605379-5&_gid=1576942764.1602606428&z=552815020 (idx 485)
This is a small GIF image.
Ads being useless everywhere we could consider using blacklists from adblock to filter those out.
edu.gcfglobal.org/en/topics/computers/images/social/facebook_icon.svg (idx 55) and edu.gcfglobal.org/en/topics/word/images/social/facebook_icon.svg (idx 343)
In this example, the source website duplicates the same content (happens on all the social media logos) at different locations.
One clue from our side is that they have identical Etags.
Note: there might be legit (actually the opposite) duplicates in those zim files but it would be hidden by this ocean of meaningless ones.
@kelson42 should we do anything about those at this point? Identifying duplicates on dynamic content is a complicated cross-scraper topic.
As per ads-related duplicates, I think that's something we could do in the future. Should I open a ticket?
Here's the beginning of zimcheck output for lowtechmag:
[INFO] Checking zim file lowtechmagazine.com_en_all_2020-10.zim
[INFO] Verifying Internal Checksum..
[INFO] Internal checksum found correct
[INFO] Searching for metadata entries..
[INFO] Searching for Favicon..
[INFO] Searching for main page..
[INFO] Verifying Articles' content..
[INFO] Searching for redundant articles..
Verifying Similar Articles for redundancies..
[ERROR] Missing mainpage :
[ERROR] Invalid internal links found :
Is this a recipe issue? how?
CDN hosted resources are apparently not captured
Capturing https://isago.ml/ I get the following
Failed to load resource: http://localhost:9999/isago.ml_2020-09/A/isagoml_2020-09/mp_/https://maxcdn.bootstrapcdn.com/bootstrap/4.0.0/css/bootstrap.min.css the server responded with a status of 404 (Not Found)
When using --title "Les fondamentaux" for instance, the actual param sent to warc2zim would be "Les".
Concerns all params.
We need to setup a custom browser agent and share the following info:
This could be added the the Standard Chrome User-Agent
The site is a SPA, with no unique URLs for the storybooks, making it difficult to capture.
However, the site does have downloadble pdfs/epubs.
Capturing https://wiki.openzim.org/ with youzim.it works, but most of the pictures don't display properly:

All of them return the following error:
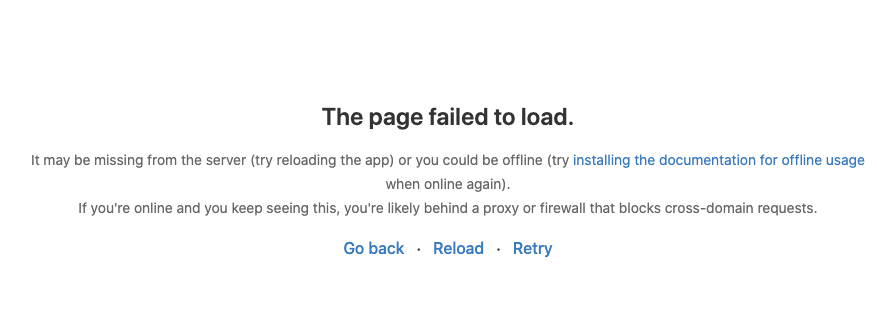
(to be clear on the source website they are fully available)
I just zimmed up a wordpress blog with 186 articles (cutoff at 1,000) and about 500 images (https://mesquartierschinois.wordpress.com). Standard, free wordpress, ie no funky extension added.
I would say 10-20% of images are still missing.
It works, a version version should be released which means:
manioc's last run has many pylibzim warnings regarding duplicate URL
Impossible to add H/www.manioc.org/export_ris.php?reference=http:
dirent's title to add is : www.manioc.org/export_ris.php?reference=http:
existing dirent's title is : www.manioc.org/export_ris.php?reference=http:
Given the URL that is shown, it looks like the actual urls have been stripped which would explain why it didn't just trigger a revisit record.
We need a spider to crawl a whole web site and write a WARC file able later to produce a ZIM file with a similar look & feel like the original.
This spider should ideally:
Exactly like in warc2zim
@Stamimail commented on Sep 29, 2017, 2:51 PM UTC:
@mossroy
Sorry for not having programming knowledge...
Although,
If there is no good solution to have the offline wikipedia in browser like the online wikipedia, perhaps it is the time to make a new technology. It seems it is Mozilla job.
Currently a user that wants to download a website uses HTTrack or wget etc.
But here we are talking about websites (not only wikipedia) that want to let the user take their website with him, for offline use.
The browser should think it is connected to far server but really is connected to a file on the local system.
Other extensions of Firfox like "Thumbnail Zoom Plus" (For image and img links zooming) also should work, when this ZIM (Website File) is loadead to browser.
This Website File could contains Whole website or parts of it, like a book in Wikisource.
This issue was moved by kelson42 from kiwix/kiwix-js#307.
When using an URL such as https://isago.ml, zimit is happy and captures it but warc2zim is not as it can't find such a URL in WARC files. Obviously, the actual URL in WARC is https://isago.ml/ (trailing slash).
We cannot fail after capture on such scenario. We could either fail early (I don't recommend) or be smarter and just append the trailing slash to the warc2zim argument if it's missing.
But this is part of the Zimfarm UI options. See https://farm.openzim.org/pipeline/15502f736370cfd45e0e0df5/debug
A white padding of a few pixels height, quite visible. Tested with Firefox.
See here:
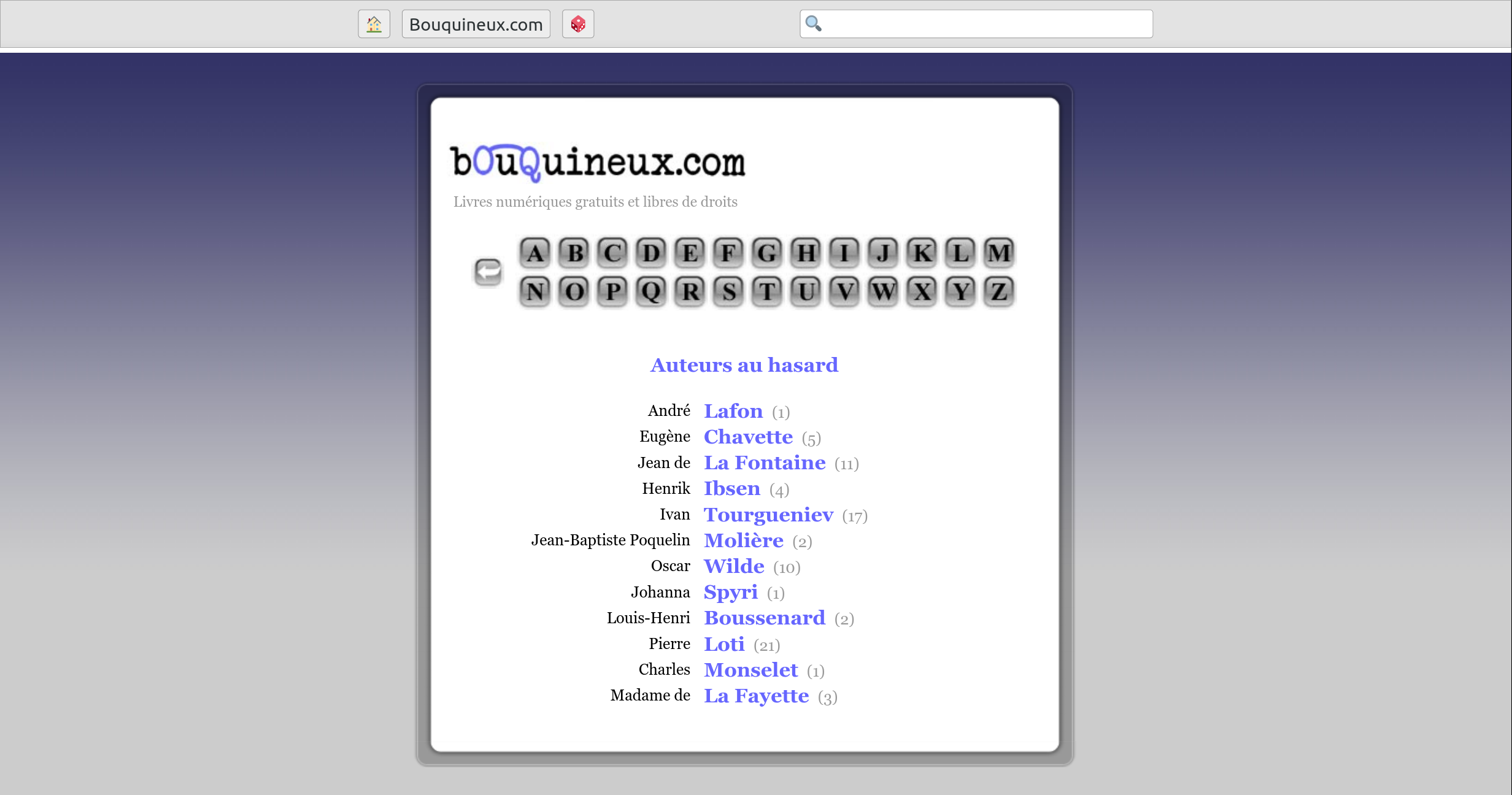
This is ugly, unecessary and does not appear with other ZIM files. It should be removed.
Ensure embedded videos are capture (video tag, youtube) are captured if encountered on the page.
I believe we should allow the scraping of insecure websites (mostly self-signed and expired certificates) as we won't have control on the target websites.
HTML Check error FetchError: request to https://isago.ml/ failed, reason: certificate has expired
at ClientRequest.<anonymous> (/app/node_modules/node-fetch/lib/index.js:1461:11)
at ClientRequest.emit (events.js:315:20)ng for 502.0 ms)
at TLSSocket.socketErrorListener (_http_client.js:426:9)
at TLSSocket.emit (events.js:315:20)
at emitErrorNT (internal/streams/destroy.js:92:8)
at emitErrorAndCloseNT (internal/streams/destroy.js:60:3)
at processTicksAndRejections (internal/process/task_queues.js:84:21) {
type: 'system',
errno: 'CERT_HAS_EXPIRED',
code: 'CERT_HAS_EXPIRED'
}
Load timeout for https://isago.ml/
Many sites include search, or sort options that can result in 'crawler traps'. Some common ways to avoid this is by specifying regexes to exclude, eg. --exclude "\"\?q=\""
Add a list of default patterns to be excluded to avoid having to specify for every site..
Looks like in-frame favicon are never reported to the host frame, rendering them useless. I know that this is an expected behavior of the replayer so something might be broken.
Probably tied to #18
It's currently impossible to set multiple tags on a ZIM:
warc2zim's multiple --tags param is not allowed; separator in single --tags string is evaluated as a command line terminationwarc2zim: error: argument --tags: expected one argument
Invalid warc2zim params, warc2zim exited with: 2
If the ZIM we made so far with warc2zim work on Android with Kiwix, the layout is not adatped. We should probably have an option to specify which kind of display resolution browsertrix should use. Per default we probably should have a mobile (which one exactly?) screen resolution.
Site is a SPA, though pages do have unique links. May be possible to archive with custom behavior. Needs further investigation.
Using the docker image, a failure in warc2zim will not be propagated as you can see on this zimfarm run.
Actually, I'm pretty sure that an error in zimit code wouldn't be propagated either ; but maybe it should be fixed at both locations…
Taking this opportunity to request that we switch from an entrypoint without a CMD to a CMD (possibly without an entrypoint). I see no reason to use the entrypoint at the moment and it prevents doing stuff like docker run openzim/zimit warc2zim --help
I built edu.gcfglobal.org_en_all_2020-12 using the command from https://farm.openzim.org/recipes/edu.gcfglobal.org_en, namely
docker run -v /my-path:/output:rw --name zimit_edu.gcfglobal.org_en --detach --cpu-shares 3072 --memory-swappiness 0 --memory 4294967296 --shm-size 4294967296 --cap-add SYS_ADMIN --cap-add NET_ADMIN openzim/zimit:dev zimit --exclude="(\?q=|/signin)" --lang="eng" --name="edu.gcfglobal.org_en_all" --output="/output" --scope="https://edu.gcfglobal.org/en/" --url="https://edu.gcfglobal.org/en/topics/" --verbose --workers="6" --title="200+ Free Tutorials" --description="Tutorials in technology, reading, math, career & more" --favicon="https://sites.google.com/site/tricountyassistivetechnology/life-skills/gcflearnfree.jpg" --adminEmail="[email protected]"
The zim built with no complaints
I deployed it at http://iiab.me/kiwix/edu.gcfglobal.org_en_all_2020-12/A/index.html on kiwix-serve version 3.1.2 x86. Search returns results, but access to a page yields
This page must be loaded via an HTTPS URL to support service workers.
We don't really want https for offline servers as self signed certs give scary messages to users. Is this a requirement?
This behaviour is seen on edu.gcfglobal.org : when I click on any link the pages appear blank. If I hit "refresh" then the page appears normally.
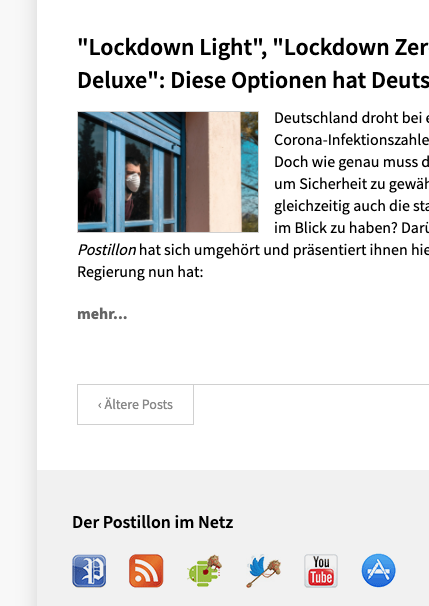
Seen on https://tukasu.ml/der-postillon.com_fr_all_2020-10
At the bottom of the page there is a link to older posts (Ältere Posts) from the landing page which returns an error when clicked on: Sorry, the url https://www.der-postillon.com/search?updated-max=2020-10-27T17:15:00%2B01:00&max-results=12 is not found on this server
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
