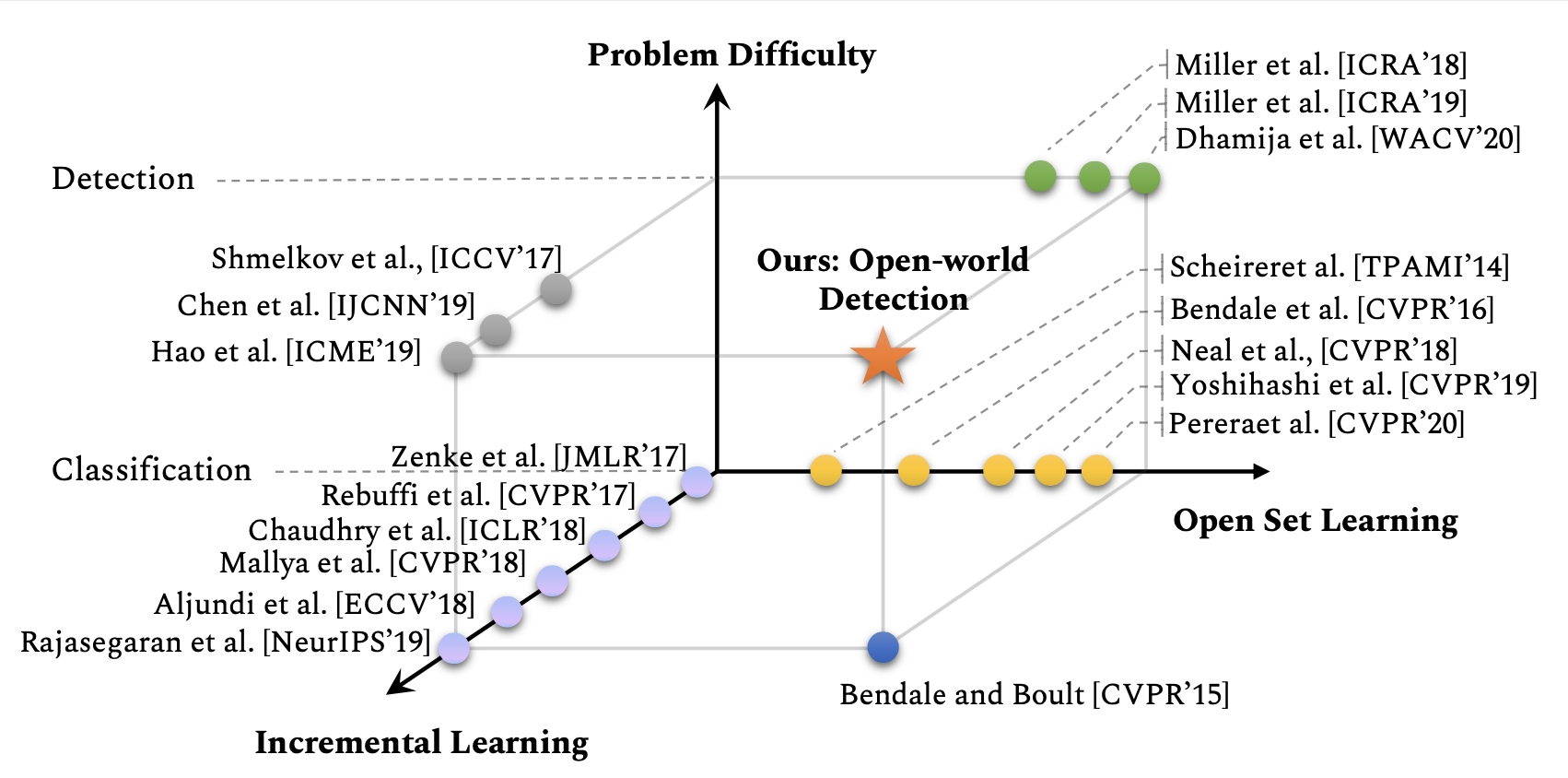
I can't reproduce t1 result in current version. I didn't change any code and data, and use the model_final in t1_clustering_with_save of backup_model to test(t1_val->t1_test). but my Wilderness Impact result is 0.049, and yours is 0.022 in your results folder.
Can anyone tell me why
my log:
[06/10 04:53:20] detectron2 INFO: Rank of current process: 0. World size: 4
[06/10 04:53:21] detectron2 INFO: Environment info:
sys.platform linux
Python 3.6.9 (default, Jul 17 2020, 12:50:27) [GCC 8.4.0]
numpy 1.19.5
detectron2 0.2.1 @/workspace/detectron2
Compiler GCC 7.5
CUDA compiler CUDA 10.1
detectron2 arch flags 6.1
DETECTRON2_ENV_MODULE
PyTorch 1.6.0 @/usr/local/lib/python3.6/dist-packages/torch
PyTorch debug build False
GPU available True
GPU 0,1,2,3,4,5,6,7 GeForce GTX 1080 Ti (arch=6.1)
CUDA_HOME /usr/local/cuda
Pillow 8.2.0
torchvision 0.7.0 @/usr/local/lib/python3.6/dist-packages/torchvision
torchvision arch flags 3.5, 5.0, 6.0, 7.0, 7.5
fvcore 0.1.1.dev200512
cv2 4.4.0
PyTorch built with:
- GCC 7.3
- C++ Version: 201402
- Intel(R) Math Kernel Library Version 2019.0.5 Product Build 20190808 for Intel(R) 64 architecture applications
- Intel(R) MKL-DNN v1.5.0 (Git Hash e2ac1fac44c5078ca927cb9b90e1b3066a0b2ed0)
- OpenMP 201511 (a.k.a. OpenMP 4.5)
- NNPACK is enabled
- CPU capability usage: AVX2
- CUDA Runtime 10.2
- NVCC architecture flags: -gencode;arch=compute_37,code=sm_37;-gencode;arch=compute_50,code=sm_50;-gencode;arch=compute_60,code=sm_60;-gencode;arch=compute_70,code=sm_70;-gencode;arch=compute_75,code=sm_75
- CuDNN 7.6.5
- Magma 2.5.2
- Build settings: BLAS=MKL, BUILD_TYPE=Release, CXX_FLAGS= -Wno-deprecated -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -DUSE_VULKAN_WRAPPER -O2 -fPIC -Wno-narrowing -Wall -Wextra -Werror=return-type -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wno-sign-compare -Wno-unused-parameter -Wno-unused-variable -Wno-unused-function -Wno-unused-result -Wno-unused-local-typedefs -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Wno-stringop-overflow, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, USE_CUDA=ON, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=ON, USE_MKLDNN=ON, USE_MPI=OFF, USE_NCCL=ON, USE_NNPACK=ON, USE_OPENMP=ON, USE_STATIC_DISPATCH=OFF,
[06/10 04:53:21] detectron2 INFO: Command line arguments: Namespace(config_file='./configs/OWOD/t1/t1_val.yaml', dist_url='tcp://127.0.0.1:52133', eval_only=False, machine_rank=0, num_gpus=4, num_machines=1, opts=['SOLVER.IMS_PER_BATCH', '4', 'SOLVER.BASE_LR', '0.01', 'OWOD.TEMPERATURE', '1.5', 'OUTPUT_DIR', './output/t1_final', 'MODEL.WEIGHTS', 'backup/t1_clustering_with_save/model_final.pth'], resume=False)
[06/10 04:53:21] detectron2 INFO: Contents of args.config_file=./configs/OWOD/t1/t1_val.yaml:
BASE: "../../Base-RCNN-C4-OWOD.yaml"
MODEL:
WEIGHTS: "/home/joseph/workspace/OWOD/output/t1_ft/model_final.pth"
DATASETS:
TRAIN: ('voc_coco_2007_val', ) # t1_voc_coco_2007_train, t1_voc_coco_2007_ft
TEST: ('voc_coco_2007_val', ) # voc_coco_2007_test
SOLVER:
STEPS: (12000, 16000)
MAX_ITER: 500
WARMUP_ITERS: 0
OUTPUT_DIR: "./output/temp_3"
OWOD:
PREV_INTRODUCED_CLS: 0
CUR_INTRODUCED_CLS: 20
COMPUTE_ENERGY: True
ENERGY_SAVE_PATH: 'energy'
SKIP_TRAINING_WHILE_EVAL: False
ENABLE_CLUSTERING: False
TEMPERATURE: 1.5
[06/10 04:53:21] detectron2 INFO: Running with full config:
CUDNN_BENCHMARK: False
DATALOADER:
ASPECT_RATIO_GROUPING: True
FILTER_EMPTY_ANNOTATIONS: True
NUM_WORKERS: 4
REPEAT_THRESHOLD: 0.0
SAMPLER_TRAIN: TrainingSampler
DATASETS:
PRECOMPUTED_PROPOSAL_TOPK_TEST: 1000
PRECOMPUTED_PROPOSAL_TOPK_TRAIN: 2000
PROPOSAL_FILES_TEST: ()
PROPOSAL_FILES_TRAIN: ()
TEST: ('voc_coco_2007_val',)
TRAIN: ('voc_coco_2007_val',)
GLOBAL:
HACK: 1.0
INPUT:
CROP:
ENABLED: False
SIZE: [0.9, 0.9]
TYPE: relative_range
FORMAT: BGR
MASK_FORMAT: polygon
MAX_SIZE_TEST: 1333
MAX_SIZE_TRAIN: 1333
MIN_SIZE_TEST: 800
MIN_SIZE_TRAIN: (480, 512, 544, 576, 608, 640, 672, 704, 736, 768, 800)
MIN_SIZE_TRAIN_SAMPLING: choice
RANDOM_FLIP: horizontal
MODEL:
ANCHOR_GENERATOR:
ANGLES: [[-90, 0, 90]]
ASPECT_RATIOS: [[0.5, 1.0, 2.0]]
NAME: DefaultAnchorGenerator
OFFSET: 0.0
SIZES: [[32, 64, 128, 256, 512]]
BACKBONE:
FREEZE_AT: 2
NAME: build_resnet_backbone
DEVICE: cuda
FPN:
FUSE_TYPE: sum
IN_FEATURES: []
NORM:
OUT_CHANNELS: 256
KEYPOINT_ON: False
LOAD_PROPOSALS: False
MASK_ON: False
META_ARCHITECTURE: GeneralizedRCNN
PANOPTIC_FPN:
COMBINE:
ENABLED: True
INSTANCES_CONFIDENCE_THRESH: 0.5
OVERLAP_THRESH: 0.5
STUFF_AREA_LIMIT: 4096
INSTANCE_LOSS_WEIGHT: 1.0
PIXEL_MEAN: [103.53, 116.28, 123.675]
PIXEL_STD: [1.0, 1.0, 1.0]
PROPOSAL_GENERATOR:
MIN_SIZE: 0
NAME: RPN
RESNETS:
DEFORM_MODULATED: False
DEFORM_NUM_GROUPS: 1
DEFORM_ON_PER_STAGE: [False, False, False, False]
DEPTH: 50
NORM: FrozenBN
NUM_GROUPS: 1
OUT_FEATURES: ['res4']
RES2_OUT_CHANNELS: 256
RES5_DILATION: 1
STEM_OUT_CHANNELS: 64
STRIDE_IN_1X1: True
WIDTH_PER_GROUP: 64
RETINANET:
BBOX_REG_LOSS_TYPE: smooth_l1
BBOX_REG_WEIGHTS: (1.0, 1.0, 1.0, 1.0)
FOCAL_LOSS_ALPHA: 0.25
FOCAL_LOSS_GAMMA: 2.0
IN_FEATURES: ['p3', 'p4', 'p5', 'p6', 'p7']
IOU_LABELS: [0, -1, 1]
IOU_THRESHOLDS: [0.4, 0.5]
NMS_THRESH_TEST: 0.5
NORM:
NUM_CLASSES: 80
NUM_CONVS: 4
PRIOR_PROB: 0.01
SCORE_THRESH_TEST: 0.05
SMOOTH_L1_LOSS_BETA: 0.1
TOPK_CANDIDATES_TEST: 1000
ROI_BOX_CASCADE_HEAD:
BBOX_REG_WEIGHTS: ((10.0, 10.0, 5.0, 5.0), (20.0, 20.0, 10.0, 10.0), (30.0, 30.0, 15.0, 15.0))
IOUS: (0.5, 0.6, 0.7)
ROI_BOX_HEAD:
BBOX_REG_LOSS_TYPE: smooth_l1
BBOX_REG_LOSS_WEIGHT: 1.0
BBOX_REG_WEIGHTS: (10.0, 10.0, 5.0, 5.0)
CLS_AGNOSTIC_BBOX_REG: False
CONV_DIM: 256
FC_DIM: 1024
NAME:
NORM:
NUM_CONV: 0
NUM_FC: 0
POOLER_RESOLUTION: 14
POOLER_SAMPLING_RATIO: 0
POOLER_TYPE: ROIAlignV2
SMOOTH_L1_BETA: 0.0
TRAIN_ON_PRED_BOXES: False
ROI_HEADS:
BATCH_SIZE_PER_IMAGE: 512
IN_FEATURES: ['res4']
IOU_LABELS: [0, 1]
IOU_THRESHOLDS: [0.5]
NAME: Res5ROIHeads
NMS_THRESH_TEST: 0.5
NUM_CLASSES: 81
POSITIVE_FRACTION: 0.25
PROPOSAL_APPEND_GT: True
SCORE_THRESH_TEST: 0.05
ROI_KEYPOINT_HEAD:
CONV_DIMS: (512, 512, 512, 512, 512, 512, 512, 512)
LOSS_WEIGHT: 1.0
MIN_KEYPOINTS_PER_IMAGE: 1
NAME: KRCNNConvDeconvUpsampleHead
NORMALIZE_LOSS_BY_VISIBLE_KEYPOINTS: True
NUM_KEYPOINTS: 17
POOLER_RESOLUTION: 14
POOLER_SAMPLING_RATIO: 0
POOLER_TYPE: ROIAlignV2
ROI_MASK_HEAD:
CLS_AGNOSTIC_MASK: False
CONV_DIM: 256
NAME: MaskRCNNConvUpsampleHead
NORM:
NUM_CONV: 0
POOLER_RESOLUTION: 14
POOLER_SAMPLING_RATIO: 0
POOLER_TYPE: ROIAlignV2
RPN:
BATCH_SIZE_PER_IMAGE: 256
BBOX_REG_LOSS_TYPE: smooth_l1
BBOX_REG_LOSS_WEIGHT: 1.0
BBOX_REG_WEIGHTS: (1.0, 1.0, 1.0, 1.0)
BOUNDARY_THRESH: -1
HEAD_NAME: StandardRPNHead
IN_FEATURES: ['res4']
IOU_LABELS: [0, -1, 1]
IOU_THRESHOLDS: [0.3, 0.7]
LOSS_WEIGHT: 1.0
NMS_THRESH: 0.7
POSITIVE_FRACTION: 0.5
POST_NMS_TOPK_TEST: 1000
POST_NMS_TOPK_TRAIN: 2000
PRE_NMS_TOPK_TEST: 6000
PRE_NMS_TOPK_TRAIN: 12000
SMOOTH_L1_BETA: 0.0
SEM_SEG_HEAD:
COMMON_STRIDE: 4
CONVS_DIM: 128
IGNORE_VALUE: 255
IN_FEATURES: ['p2', 'p3', 'p4', 'p5']
LOSS_WEIGHT: 1.0
NAME: SemSegFPNHead
NORM: GN
NUM_CLASSES: 54
WEIGHTS: backup/t1_clustering_with_save/model_final.pth
OUTPUT_DIR: ./output/t1_final
OWOD:
CLUSTERING:
ITEMS_PER_CLASS: 20
MARGIN: 10.0
MOMENTUM: 0.99
START_ITER: 1000
UPDATE_MU_ITER: 3000
Z_DIMENSION: 128
COMPUTE_ENERGY: True
CUR_INTRODUCED_CLS: 20
ENABLE_CLUSTERING: False
ENABLE_THRESHOLD_AUTOLABEL_UNK: True
ENABLE_UNCERTAINITY_AUTOLABEL_UNK: False
ENERGY_SAVE_PATH: energy
FEATURE_STORE_SAVE_PATH: feature_store
NUM_UNK_PER_IMAGE: 1
PREV_INTRODUCED_CLS: 0
SKIP_TRAINING_WHILE_EVAL: False
TEMPERATURE: 1.5
SEED: -1
SOLVER:
BASE_LR: 0.01
BIAS_LR_FACTOR: 1.0
CHECKPOINT_PERIOD: 5000
CLIP_GRADIENTS:
CLIP_TYPE: value
CLIP_VALUE: 1.0
ENABLED: False
NORM_TYPE: 2.0
GAMMA: 0.1
IMS_PER_BATCH: 4
LR_SCHEDULER_NAME: WarmupMultiStepLR
MAX_ITER: 500
MOMENTUM: 0.9
NESTEROV: False
REFERENCE_WORLD_SIZE: 0
STEPS: (12000, 16000)
WARMUP_FACTOR: 0.001
WARMUP_ITERS: 0
WARMUP_METHOD: linear
WEIGHT_DECAY: 0.0001
WEIGHT_DECAY_BIAS: 0.0001
WEIGHT_DECAY_NORM: 0.0
TEST:
AUG:
ENABLED: False
FLIP: True
MAX_SIZE: 4000
MIN_SIZES: (400, 500, 600, 700, 800, 900, 1000, 1100, 1200)
DETECTIONS_PER_IMAGE: 100
EVAL_PERIOD: 0
EXPECTED_RESULTS: []
KEYPOINT_OKS_SIGMAS: []
PRECISE_BN:
ENABLED: False
NUM_ITER: 200
VERSION: 2
VIS_PERIOD: 0
[06/10 04:53:21] detectron2 INFO: Full config saved to ./output/t1_final/config.yaml
[06/10 04:53:21] d2.utils.env INFO: Using a generated random seed 21659271
[06/10 04:53:22] d2.modeling.roi_heads.fast_rcnn INFO: Invalid class range: [20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79]
[06/10 04:53:22] d2.modeling.roi_heads.fast_rcnn INFO: Feature store not found in ./output/t1_final/feature_store/feat.pt. Creating new feature store.
[06/10 04:53:22] d2.engine.defaults INFO: Model:
GeneralizedRCNN(
(backbone): ResNet(
(stem): BasicStem(
(conv1): Conv2d(
3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
)
(res2): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv1): Conv2d(
64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
)
(res3): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv1): Conv2d(
256, 128, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(3): BottleneckBlock(
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
)
(res4): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
(conv1): Conv2d(
512, 256, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(3): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(4): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(5): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
)
)
(proposal_generator): RPN(
(rpn_head): StandardRPNHead(
(conv): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(objectness_logits): Conv2d(1024, 15, kernel_size=(1, 1), stride=(1, 1))
(anchor_deltas): Conv2d(1024, 60, kernel_size=(1, 1), stride=(1, 1))
)
(anchor_generator): DefaultAnchorGenerator(
(cell_anchors): BufferList()
)
)
(roi_heads): Res5ROIHeads(
(pooler): ROIPooler(
(level_poolers): ModuleList(
(0): ROIAlign(output_size=(14, 14), spatial_scale=0.0625, sampling_ratio=0, aligned=True)
)
)
(res5): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
(conv1): Conv2d(
1024, 512, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
)
(box_predictor): FastRCNNOutputLayers(
(cls_score): Linear(in_features=2048, out_features=82, bias=True)
(bbox_pred): Linear(in_features=2048, out_features=324, bias=True)
(hingeloss): HingeEmbeddingLoss()
)
)
)
[06/10 04:53:23] d2.data.build INFO: Removed 0 images with no usable annotations. 4000 images left.
[06/10 04:53:23] d2.data.build INFO: Known classes: range(0, 20)
[06/10 04:53:23] d2.data.build INFO: Labelling known instances the corresponding label, and unknown instances as unknown...
[06/10 04:53:23] d2.data.build INFO: Distribution of instances among all 81 categories:
�[36m| category | #instances | category | #instances | category | #instances |
|:-------------:|:-------------|:-------------:|:-------------|:----------:|:-------------|
| aeroplane | 90 | bicycle | 215 | bird | 206 |
| boat | 165 | bottle | 1146 | bus | 157 |
| car | 1218 | cat | 174 | chair | 1531 |
| cow | 88 | diningtable | 693 | dog | 247 |
| horse | 105 | motorbike | 252 | person | 8393 |
| pottedplant | 314 | sheep | 163 | sofa | 258 |
| train | 86 | tvmonitor | 269 | truck | 0 |
| traffic light | 0 | fire hydrant | 0 | stop sign | 0 |
| parking meter | 0 | bench | 0 | elephant | 0 |
| bear | 0 | zebra | 0 | giraffe | 0 |
| backpack | 0 | umbrella | 0 | handbag | 0 |
| tie | 0 | suitcase | 0 | microwave | 0 |
| oven | 0 | toaster | 0 | sink | 0 |
| refrigerator | 0 | frisbee | 0 | skis | 0 |
| snowboard | 0 | sports ball | 0 | kite | 0 |
| baseball bat | 0 | baseball gl.. | 0 | skateboard | 0 |
| surfboard | 0 | tennis racket | 0 | banana | 0 |
| apple | 0 | sandwich | 0 | orange | 0 |
| broccoli | 0 | carrot | 0 | hot dog | 0 |
| pizza | 0 | donut | 0 | cake | 0 |
| bed | 0 | toilet | 0 | laptop | 0 |
| mouse | 0 | remote | 0 | keyboard | 0 |
| cell phone | 0 | book | 0 | clock | 0 |
| vase | 0 | scissors | 0 | teddy bear | 0 |
| hair drier | 0 | toothbrush | 0 | wine glass | 0 |
| cup | 0 | fork | 0 | knife | 0 |
| spoon | 0 | bowl | 0 | unknown | 12841 |
| | | | | | |
| total | 28611 | | | | |�[0m
[06/10 04:53:23] d2.data.build INFO: Number of datapoints: 4000
[06/10 04:53:23] d2.data.common INFO: Serializing 4000 elements to byte tensors and concatenating them all ...
[06/10 04:53:23] d2.data.common INFO: Serialized dataset takes 2.75 MiB
[06/10 04:53:23] d2.data.dataset_mapper INFO: Augmentations used in training: [ResizeShortestEdge(short_edge_length=(480, 512, 544, 576, 608, 640, 672, 704, 736, 768, 800), max_size=1333, sample_style='choice'), RandomFlip()]
[06/10 04:53:23] d2.data.build INFO: Using training sampler TrainingSampler
[06/10 04:53:25] fvcore.common.checkpoint INFO: Loading checkpoint from backup/t1_clustering_with_save/model_final.pth
[06/10 04:53:25] d2.engine.train_loop INFO: Starting training from iteration 0
[06/10 04:53:46] d2.utils.events INFO: eta: 0:05:19 iter: 19 total_loss: 1.153 loss_cls: 0.3643 loss_box_reg: 0.4349 loss_clustering: 0 loss_rpn_cls: 0.1931 loss_rpn_loc: 0.1566 time: 0.6630 data_time: 0.3892 lr: 0.01 max_mem: 2594M
[06/10 04:53:59] d2.utils.events INFO: eta: 0:05:08 iter: 39 total_loss: 1.092 loss_cls: 0.3092 loss_box_reg: 0.3235 loss_clustering: 0 loss_rpn_cls: 0.2272 loss_rpn_loc: 0.1761 time: 0.6681 data_time: 0.0038 lr: 0.01 max_mem: 2604M
[06/10 04:54:13] d2.utils.events INFO: eta: 0:04:55 iter: 59 total_loss: 0.992 loss_cls: 0.3279 loss_box_reg: 0.3103 loss_clustering: 0 loss_rpn_cls: 0.1988 loss_rpn_loc: 0.1696 time: 0.6689 data_time: 0.0038 lr: 0.01 max_mem: 2604M
[06/10 04:54:26] d2.utils.events INFO: eta: 0:04:42 iter: 79 total_loss: 1.105 loss_cls: 0.3057 loss_box_reg: 0.4032 loss_clustering: 0 loss_rpn_cls: 0.2088 loss_rpn_loc: 0.2044 time: 0.6695 data_time: 0.0037 lr: 0.01 max_mem: 2604M
[06/10 04:54:40] d2.utils.events INFO: eta: 0:04:28 iter: 99 total_loss: 1.016 loss_cls: 0.3093 loss_box_reg: 0.3395 loss_clustering: 0 loss_rpn_cls: 0.213 loss_rpn_loc: 0.1582 time: 0.6696 data_time: 0.0037 lr: 0.01 max_mem: 2604M
[06/10 04:54:53] d2.utils.events INFO: eta: 0:04:14 iter: 119 total_loss: 0.8104 loss_cls: 0.2401 loss_box_reg: 0.3092 loss_clustering: 0 loss_rpn_cls: 0.1662 loss_rpn_loc: 0.1155 time: 0.6685 data_time: 0.0036 lr: 0.01 max_mem: 2604M
[06/10 04:55:06] d2.utils.events INFO: eta: 0:04:01 iter: 139 total_loss: 0.9382 loss_cls: 0.2849 loss_box_reg: 0.3282 loss_clustering: 0 loss_rpn_cls: 0.1784 loss_rpn_loc: 0.1421 time: 0.6692 data_time: 0.0035 lr: 0.01 max_mem: 2604M
[06/10 04:55:20] d2.utils.events INFO: eta: 0:03:47 iter: 159 total_loss: 1.027 loss_cls: 0.2785 loss_box_reg: 0.3697 loss_clustering: 0 loss_rpn_cls: 0.1812 loss_rpn_loc: 0.1403 time: 0.6693 data_time: 0.0035 lr: 0.01 max_mem: 2604M
[06/10 04:55:33] d2.utils.events INFO: eta: 0:03:34 iter: 179 total_loss: 1.191 loss_cls: 0.3642 loss_box_reg: 0.4159 loss_clustering: 0 loss_rpn_cls: 0.1832 loss_rpn_loc: 0.1689 time: 0.6701 data_time: 0.0035 lr: 0.01 max_mem: 2643M
[06/10 04:55:47] d2.utils.events INFO: eta: 0:03:21 iter: 199 total_loss: 0.8851 loss_cls: 0.2851 loss_box_reg: 0.3336 loss_clustering: 0 loss_rpn_cls: 0.1789 loss_rpn_loc: 0.1395 time: 0.6696 data_time: 0.0035 lr: 0.01 max_mem: 2643M
[06/10 04:56:00] d2.utils.events INFO: eta: 0:03:07 iter: 219 total_loss: 0.9365 loss_cls: 0.2691 loss_box_reg: 0.3085 loss_clustering: 0 loss_rpn_cls: 0.1821 loss_rpn_loc: 0.1269 time: 0.6705 data_time: 0.0042 lr: 0.01 max_mem: 2643M
[06/10 04:56:14] d2.utils.events INFO: eta: 0:02:54 iter: 239 total_loss: 1.031 loss_cls: 0.2904 loss_box_reg: 0.3653 loss_clustering: 0 loss_rpn_cls: 0.1907 loss_rpn_loc: 0.1373 time: 0.6704 data_time: 0.0037 lr: 0.01 max_mem: 2643M
[06/10 04:56:27] d2.utils.events INFO: eta: 0:02:41 iter: 259 total_loss: 0.9676 loss_cls: 0.2808 loss_box_reg: 0.3114 loss_clustering: 0 loss_rpn_cls: 0.1994 loss_rpn_loc: 0.1527 time: 0.6703 data_time: 0.0038 lr: 0.01 max_mem: 2643M
[06/10 04:56:40] d2.utils.events INFO: eta: 0:02:27 iter: 279 total_loss: 1.04 loss_cls: 0.3054 loss_box_reg: 0.361 loss_clustering: 0 loss_rpn_cls: 0.1894 loss_rpn_loc: 0.1673 time: 0.6705 data_time: 0.0042 lr: 0.01 max_mem: 2643M
[06/10 04:56:54] d2.utils.events INFO: eta: 0:02:14 iter: 299 total_loss: 0.9006 loss_cls: 0.2546 loss_box_reg: 0.322 loss_clustering: 0 loss_rpn_cls: 0.1825 loss_rpn_loc: 0.1389 time: 0.6706 data_time: 0.0036 lr: 0.01 max_mem: 2643M
[06/10 04:57:07] d2.utils.events INFO: eta: 0:02:00 iter: 319 total_loss: 0.8975 loss_cls: 0.249 loss_box_reg: 0.3165 loss_clustering: 0 loss_rpn_cls: 0.1702 loss_rpn_loc: 0.1446 time: 0.6708 data_time: 0.0035 lr: 0.01 max_mem: 2643M
[06/10 04:57:21] d2.utils.events INFO: eta: 0:01:47 iter: 339 total_loss: 1.056 loss_cls: 0.2927 loss_box_reg: 0.3793 loss_clustering: 0 loss_rpn_cls: 0.1672 loss_rpn_loc: 0.1588 time: 0.6712 data_time: 0.0039 lr: 0.01 max_mem: 2643M
[06/10 04:57:34] d2.utils.events INFO: eta: 0:01:33 iter: 359 total_loss: 1.058 loss_cls: 0.3289 loss_box_reg: 0.3908 loss_clustering: 0 loss_rpn_cls: 0.1826 loss_rpn_loc: 0.1518 time: 0.6710 data_time: 0.0037 lr: 0.01 max_mem: 2643M
[06/10 04:57:48] d2.utils.events INFO: eta: 0:01:20 iter: 379 total_loss: 0.9792 loss_cls: 0.2812 loss_box_reg: 0.3731 loss_clustering: 0 loss_rpn_cls: 0.1841 loss_rpn_loc: 0.13 time: 0.6709 data_time: 0.0035 lr: 0.01 max_mem: 2643M
[06/10 04:58:01] d2.utils.events INFO: eta: 0:01:07 iter: 399 total_loss: 0.9255 loss_cls: 0.2702 loss_box_reg: 0.3482 loss_clustering: 0 loss_rpn_cls: 0.1869 loss_rpn_loc: 0.1336 time: 0.6710 data_time: 0.0038 lr: 0.01 max_mem: 2643M
[06/10 04:58:15] d2.utils.events INFO: eta: 0:00:53 iter: 419 total_loss: 0.989 loss_cls: 0.3231 loss_box_reg: 0.3238 loss_clustering: 0 loss_rpn_cls: 0.1602 loss_rpn_loc: 0.1629 time: 0.6715 data_time: 0.0037 lr: 0.01 max_mem: 2643M
[06/10 04:58:28] d2.utils.events INFO: eta: 0:00:40 iter: 439 total_loss: 1.009 loss_cls: 0.2952 loss_box_reg: 0.3646 loss_clustering: 0 loss_rpn_cls: 0.19 loss_rpn_loc: 0.1398 time: 0.6716 data_time: 0.0040 lr: 0.01 max_mem: 2643M
[06/10 04:58:42] d2.utils.events INFO: eta: 0:00:26 iter: 459 total_loss: 0.9227 loss_cls: 0.2407 loss_box_reg: 0.2804 loss_clustering: 0 loss_rpn_cls: 0.1958 loss_rpn_loc: 0.1823 time: 0.6716 data_time: 0.0036 lr: 0.01 max_mem: 2643M
[06/10 04:58:55] d2.utils.events INFO: eta: 0:00:13 iter: 479 total_loss: 0.9756 loss_cls: 0.2497 loss_box_reg: 0.3194 loss_clustering: 0 loss_rpn_cls: 0.1942 loss_rpn_loc: 0.1646 time: 0.6716 data_time: 0.0035 lr: 0.01 max_mem: 2643M
[06/10 04:59:09] fvcore.common.checkpoint INFO: Saving checkpoint to ./output/t1_final/model_final.pth
[06/10 04:59:09] d2.utils.events INFO: eta: 0:00:00 iter: 499 total_loss: 0.9712 loss_cls: 0.2922 loss_box_reg: 0.3268 loss_clustering: 0 loss_rpn_cls: 0.1927 loss_rpn_loc: 0.1722 time: 0.6716 data_time: 0.0036 lr: 0.01 max_mem: 2643M
[06/10 04:59:09] d2.engine.train_loop INFO: Going to analyse the energy files...
[06/10 04:59:09] d2.engine.train_loop INFO: Temperature value: 1.5
[06/10 04:59:09] d2.engine.train_loop INFO: Analysing 0 / 2000
[06/10 04:59:20] d2.engine.train_loop INFO: Analysing 100 / 2000
[06/10 04:59:25] d2.engine.train_loop INFO: Analysing 200 / 2000
[06/10 04:59:29] d2.engine.train_loop INFO: Analysing 300 / 2000
[06/10 04:59:33] d2.engine.train_loop INFO: Analysing 400 / 2000
[06/10 04:59:38] d2.engine.train_loop INFO: Analysing 500 / 2000
[06/10 04:59:43] d2.engine.train_loop INFO: Analysing 600 / 2000
[06/10 04:59:47] d2.engine.train_loop INFO: Analysing 700 / 2000
[06/10 04:59:51] d2.engine.train_loop INFO: Analysing 800 / 2000
[06/10 04:59:56] d2.engine.train_loop INFO: Analysing 900 / 2000
[06/10 05:00:00] d2.engine.train_loop INFO: Analysing 1000 / 2000
[06/10 05:00:04] d2.engine.train_loop INFO: Analysing 1100 / 2000
[06/10 05:00:08] d2.engine.train_loop INFO: Analysing 1200 / 2000
[06/10 05:00:12] d2.engine.train_loop INFO: Analysing 1300 / 2000
[06/10 05:00:16] d2.engine.train_loop INFO: Analysing 1400 / 2000
[06/10 05:00:20] d2.engine.train_loop INFO: Analysing 1500 / 2000
[06/10 05:00:24] d2.engine.train_loop INFO: Analysing 1600 / 2000
[06/10 05:00:29] d2.engine.train_loop INFO: Analysing 1700 / 2000
[06/10 05:00:33] d2.engine.train_loop INFO: Analysing 1800 / 2000
[06/10 05:00:37] d2.engine.train_loop INFO: Analysing 1900 / 2000
[06/10 05:00:41] d2.engine.train_loop INFO: len(unk): 48098
[06/10 05:00:41] d2.engine.train_loop INFO: len(known): 74915
[06/10 05:00:41] d2.engine.train_loop INFO: Fitting Weibull distribution...
[06/10 05:00:43] d2.engine.train_loop INFO: --- 1.760291576385498 seconds ---
[06/10 05:00:45] d2.engine.train_loop INFO: --- 2.2597241401672363 seconds ---
[06/10 05:00:45] d2.engine.train_loop INFO: Pickling the parameters to ./output/t1_final/energy_dist_20.pkl
[06/10 05:00:45] d2.engine.train_loop INFO: Plotting the computed energy values...
[06/10 05:00:47] d2.engine.hooks INFO: Overall training speed: 498 iterations in 0:05:34 (0.6716 s / it)
[06/10 05:00:47] d2.engine.hooks INFO: Total training time: 0:07:13 (0:01:38 on hooks)
[06/10 05:03:48] detectron2 INFO: Rank of current process: 0. World size: 4
[06/10 05:03:49] detectron2 INFO: Environment info:
sys.platform linux
Python 3.6.9 (default, Jul 17 2020, 12:50:27) [GCC 8.4.0]
numpy 1.19.5
detectron2 0.2.1 @/workspace/detectron2
Compiler GCC 7.5
CUDA compiler CUDA 10.1
detectron2 arch flags 6.1
DETECTRON2_ENV_MODULE
PyTorch 1.6.0 @/usr/local/lib/python3.6/dist-packages/torch
PyTorch debug build False
GPU available True
GPU 0,1,2,3,4,5,6,7 GeForce GTX 1080 Ti (arch=6.1)
CUDA_HOME /usr/local/cuda
Pillow 8.2.0
torchvision 0.7.0 @/usr/local/lib/python3.6/dist-packages/torchvision
torchvision arch flags 3.5, 5.0, 6.0, 7.0, 7.5
fvcore 0.1.1.dev200512
cv2 4.4.0
PyTorch built with:
- GCC 7.3
- C++ Version: 201402
- Intel(R) Math Kernel Library Version 2019.0.5 Product Build 20190808 for Intel(R) 64 architecture applications
- Intel(R) MKL-DNN v1.5.0 (Git Hash e2ac1fac44c5078ca927cb9b90e1b3066a0b2ed0)
- OpenMP 201511 (a.k.a. OpenMP 4.5)
- NNPACK is enabled
- CPU capability usage: AVX2
- CUDA Runtime 10.2
- NVCC architecture flags: -gencode;arch=compute_37,code=sm_37;-gencode;arch=compute_50,code=sm_50;-gencode;arch=compute_60,code=sm_60;-gencode;arch=compute_70,code=sm_70;-gencode;arch=compute_75,code=sm_75
- CuDNN 7.6.5
- Magma 2.5.2
- Build settings: BLAS=MKL, BUILD_TYPE=Release, CXX_FLAGS= -Wno-deprecated -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -DUSE_VULKAN_WRAPPER -O2 -fPIC -Wno-narrowing -Wall -Wextra -Werror=return-type -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wno-sign-compare -Wno-unused-parameter -Wno-unused-variable -Wno-unused-function -Wno-unused-result -Wno-unused-local-typedefs -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Wno-stringop-overflow, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, USE_CUDA=ON, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=ON, USE_MKLDNN=ON, USE_MPI=OFF, USE_NCCL=ON, USE_NNPACK=ON, USE_OPENMP=ON, USE_STATIC_DISPATCH=OFF,
[06/10 05:03:49] detectron2 INFO: Command line arguments: Namespace(config_file='./configs/OWOD/t1/t1_test.yaml', dist_url='tcp://127.0.0.1:49152', eval_only=True, machine_rank=0, num_gpus=4, num_machines=1, opts=['SOLVER.IMS_PER_BATCH', '4', 'SOLVER.BASE_LR', '0.005', 'OUTPUT_DIR', './output/t1_final', 'MODEL.WEIGHTS', 'backup/t1_clustering_with_save/model_final.pth'], resume=False)
[06/10 05:03:49] detectron2 INFO: Contents of args.config_file=./configs/OWOD/t1/t1_test.yaml:
BASE: "../../Base-RCNN-C4-OWOD.yaml"
MODEL:
WEIGHTS: "/home/joseph/workspace/OWOD/output/t1_ft/model_final.pth"
ROI_HEADS:
NMS_THRESH_TEST: 0.4
TEST:
DETECTIONS_PER_IMAGE: 50
DATASETS:
TRAIN: ('t1_voc_coco_2007_train', ) # t1_voc_coco_2007_train, t1_voc_coco_2007_ft
TEST: ('voc_coco_2007_test', ) # voc_coco_2007_test
SOLVER:
STEPS: (12000, 16000)
MAX_ITER: 18000
WARMUP_ITERS: 100
OUTPUT_DIR: "./output/temp_3"
OWOD:
PREV_INTRODUCED_CLS: 0
CUR_INTRODUCED_CLS: 20
[06/10 05:03:49] detectron2 INFO: Running with full config:
CUDNN_BENCHMARK: False
DATALOADER:
ASPECT_RATIO_GROUPING: True
FILTER_EMPTY_ANNOTATIONS: True
NUM_WORKERS: 4
REPEAT_THRESHOLD: 0.0
SAMPLER_TRAIN: TrainingSampler
DATASETS:
PRECOMPUTED_PROPOSAL_TOPK_TEST: 1000
PRECOMPUTED_PROPOSAL_TOPK_TRAIN: 2000
PROPOSAL_FILES_TEST: ()
PROPOSAL_FILES_TRAIN: ()
TEST: ('voc_coco_2007_test',)
TRAIN: ('t1_voc_coco_2007_train',)
GLOBAL:
HACK: 1.0
INPUT:
CROP:
ENABLED: False
SIZE: [0.9, 0.9]
TYPE: relative_range
FORMAT: BGR
MASK_FORMAT: polygon
MAX_SIZE_TEST: 1333
MAX_SIZE_TRAIN: 1333
MIN_SIZE_TEST: 800
MIN_SIZE_TRAIN: (480, 512, 544, 576, 608, 640, 672, 704, 736, 768, 800)
MIN_SIZE_TRAIN_SAMPLING: choice
RANDOM_FLIP: horizontal
MODEL:
ANCHOR_GENERATOR:
ANGLES: [[-90, 0, 90]]
ASPECT_RATIOS: [[0.5, 1.0, 2.0]]
NAME: DefaultAnchorGenerator
OFFSET: 0.0
SIZES: [[32, 64, 128, 256, 512]]
BACKBONE:
FREEZE_AT: 2
NAME: build_resnet_backbone
DEVICE: cuda
FPN:
FUSE_TYPE: sum
IN_FEATURES: []
NORM:
OUT_CHANNELS: 256
KEYPOINT_ON: False
LOAD_PROPOSALS: False
MASK_ON: False
META_ARCHITECTURE: GeneralizedRCNN
PANOPTIC_FPN:
COMBINE:
ENABLED: True
INSTANCES_CONFIDENCE_THRESH: 0.5
OVERLAP_THRESH: 0.5
STUFF_AREA_LIMIT: 4096
INSTANCE_LOSS_WEIGHT: 1.0
PIXEL_MEAN: [103.53, 116.28, 123.675]
PIXEL_STD: [1.0, 1.0, 1.0]
PROPOSAL_GENERATOR:
MIN_SIZE: 0
NAME: RPN
RESNETS:
DEFORM_MODULATED: False
DEFORM_NUM_GROUPS: 1
DEFORM_ON_PER_STAGE: [False, False, False, False]
DEPTH: 50
NORM: FrozenBN
NUM_GROUPS: 1
OUT_FEATURES: ['res4']
RES2_OUT_CHANNELS: 256
RES5_DILATION: 1
STEM_OUT_CHANNELS: 64
STRIDE_IN_1X1: True
WIDTH_PER_GROUP: 64
RETINANET:
BBOX_REG_LOSS_TYPE: smooth_l1
BBOX_REG_WEIGHTS: (1.0, 1.0, 1.0, 1.0)
FOCAL_LOSS_ALPHA: 0.25
FOCAL_LOSS_GAMMA: 2.0
IN_FEATURES: ['p3', 'p4', 'p5', 'p6', 'p7']
IOU_LABELS: [0, -1, 1]
IOU_THRESHOLDS: [0.4, 0.5]
NMS_THRESH_TEST: 0.5
NORM:
NUM_CLASSES: 80
NUM_CONVS: 4
PRIOR_PROB: 0.01
SCORE_THRESH_TEST: 0.05
SMOOTH_L1_LOSS_BETA: 0.1
TOPK_CANDIDATES_TEST: 1000
ROI_BOX_CASCADE_HEAD:
BBOX_REG_WEIGHTS: ((10.0, 10.0, 5.0, 5.0), (20.0, 20.0, 10.0, 10.0), (30.0, 30.0, 15.0, 15.0))
IOUS: (0.5, 0.6, 0.7)
ROI_BOX_HEAD:
BBOX_REG_LOSS_TYPE: smooth_l1
BBOX_REG_LOSS_WEIGHT: 1.0
BBOX_REG_WEIGHTS: (10.0, 10.0, 5.0, 5.0)
CLS_AGNOSTIC_BBOX_REG: False
CONV_DIM: 256
FC_DIM: 1024
NAME:
NORM:
NUM_CONV: 0
NUM_FC: 0
POOLER_RESOLUTION: 14
POOLER_SAMPLING_RATIO: 0
POOLER_TYPE: ROIAlignV2
SMOOTH_L1_BETA: 0.0
TRAIN_ON_PRED_BOXES: False
ROI_HEADS:
BATCH_SIZE_PER_IMAGE: 512
IN_FEATURES: ['res4']
IOU_LABELS: [0, 1]
IOU_THRESHOLDS: [0.5]
NAME: Res5ROIHeads
NMS_THRESH_TEST: 0.4
NUM_CLASSES: 81
POSITIVE_FRACTION: 0.25
PROPOSAL_APPEND_GT: True
SCORE_THRESH_TEST: 0.05
ROI_KEYPOINT_HEAD:
CONV_DIMS: (512, 512, 512, 512, 512, 512, 512, 512)
LOSS_WEIGHT: 1.0
MIN_KEYPOINTS_PER_IMAGE: 1
NAME: KRCNNConvDeconvUpsampleHead
NORMALIZE_LOSS_BY_VISIBLE_KEYPOINTS: True
NUM_KEYPOINTS: 17
POOLER_RESOLUTION: 14
POOLER_SAMPLING_RATIO: 0
POOLER_TYPE: ROIAlignV2
ROI_MASK_HEAD:
CLS_AGNOSTIC_MASK: False
CONV_DIM: 256
NAME: MaskRCNNConvUpsampleHead
NORM:
NUM_CONV: 0
POOLER_RESOLUTION: 14
POOLER_SAMPLING_RATIO: 0
POOLER_TYPE: ROIAlignV2
RPN:
BATCH_SIZE_PER_IMAGE: 256
BBOX_REG_LOSS_TYPE: smooth_l1
BBOX_REG_LOSS_WEIGHT: 1.0
BBOX_REG_WEIGHTS: (1.0, 1.0, 1.0, 1.0)
BOUNDARY_THRESH: -1
HEAD_NAME: StandardRPNHead
IN_FEATURES: ['res4']
IOU_LABELS: [0, -1, 1]
IOU_THRESHOLDS: [0.3, 0.7]
LOSS_WEIGHT: 1.0
NMS_THRESH: 0.7
POSITIVE_FRACTION: 0.5
POST_NMS_TOPK_TEST: 1000
POST_NMS_TOPK_TRAIN: 2000
PRE_NMS_TOPK_TEST: 6000
PRE_NMS_TOPK_TRAIN: 12000
SMOOTH_L1_BETA: 0.0
SEM_SEG_HEAD:
COMMON_STRIDE: 4
CONVS_DIM: 128
IGNORE_VALUE: 255
IN_FEATURES: ['p2', 'p3', 'p4', 'p5']
LOSS_WEIGHT: 1.0
NAME: SemSegFPNHead
NORM: GN
NUM_CLASSES: 54
WEIGHTS: backup/t1_clustering_with_save/model_final.pth
OUTPUT_DIR: ./output/t1_final
OWOD:
CLUSTERING:
ITEMS_PER_CLASS: 20
MARGIN: 10.0
MOMENTUM: 0.99
START_ITER: 1000
UPDATE_MU_ITER: 3000
Z_DIMENSION: 128
COMPUTE_ENERGY: False
CUR_INTRODUCED_CLS: 20
ENABLE_CLUSTERING: True
ENABLE_THRESHOLD_AUTOLABEL_UNK: True
ENABLE_UNCERTAINITY_AUTOLABEL_UNK: False
ENERGY_SAVE_PATH:
FEATURE_STORE_SAVE_PATH: feature_store
NUM_UNK_PER_IMAGE: 1
PREV_INTRODUCED_CLS: 0
SKIP_TRAINING_WHILE_EVAL: False
TEMPERATURE: 1.5
SEED: -1
SOLVER:
BASE_LR: 0.005
BIAS_LR_FACTOR: 1.0
CHECKPOINT_PERIOD: 5000
CLIP_GRADIENTS:
CLIP_TYPE: value
CLIP_VALUE: 1.0
ENABLED: False
NORM_TYPE: 2.0
GAMMA: 0.1
IMS_PER_BATCH: 4
LR_SCHEDULER_NAME: WarmupMultiStepLR
MAX_ITER: 18000
MOMENTUM: 0.9
NESTEROV: False
REFERENCE_WORLD_SIZE: 0
STEPS: (12000, 16000)
WARMUP_FACTOR: 0.001
WARMUP_ITERS: 100
WARMUP_METHOD: linear
WEIGHT_DECAY: 0.0001
WEIGHT_DECAY_BIAS: 0.0001
WEIGHT_DECAY_NORM: 0.0
TEST:
AUG:
ENABLED: False
FLIP: True
MAX_SIZE: 4000
MIN_SIZES: (400, 500, 600, 700, 800, 900, 1000, 1100, 1200)
DETECTIONS_PER_IMAGE: 50
EVAL_PERIOD: 0
EXPECTED_RESULTS: []
KEYPOINT_OKS_SIGMAS: []
PRECISE_BN:
ENABLED: False
NUM_ITER: 200
VERSION: 2
VIS_PERIOD: 0
[06/10 05:03:49] detectron2 INFO: Full config saved to ./output/t1_final/config.yaml
[06/10 05:03:49] d2.utils.env INFO: Using a generated random seed 49800563
[06/10 05:03:50] d2.modeling.roi_heads.fast_rcnn INFO: Invalid class range: [20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79]
[06/10 05:03:50] d2.modeling.roi_heads.fast_rcnn INFO: Feature store not found in ./output/t1_final/feature_store/feat.pt. Creating new feature store.
[06/10 05:03:50] d2.engine.defaults INFO: Model:
GeneralizedRCNN(
(backbone): ResNet(
(stem): BasicStem(
(conv1): Conv2d(
3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
)
(res2): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv1): Conv2d(
64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
)
(res3): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv1): Conv2d(
256, 128, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(3): BottleneckBlock(
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
)
(res4): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
(conv1): Conv2d(
512, 256, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(3): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(4): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(5): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
)
)
(proposal_generator): RPN(
(rpn_head): StandardRPNHead(
(conv): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(objectness_logits): Conv2d(1024, 15, kernel_size=(1, 1), stride=(1, 1))
(anchor_deltas): Conv2d(1024, 60, kernel_size=(1, 1), stride=(1, 1))
)
(anchor_generator): DefaultAnchorGenerator(
(cell_anchors): BufferList()
)
)
(roi_heads): Res5ROIHeads(
(pooler): ROIPooler(
(level_poolers): ModuleList(
(0): ROIAlign(output_size=(14, 14), spatial_scale=0.0625, sampling_ratio=0, aligned=True)
)
)
(res5): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
(conv1): Conv2d(
1024, 512, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
)
(box_predictor): FastRCNNOutputLayers(
(cls_score): Linear(in_features=2048, out_features=82, bias=True)
(bbox_pred): Linear(in_features=2048, out_features=324, bias=True)
(hingeloss): HingeEmbeddingLoss()
)
)
)
[06/10 05:03:50] fvcore.common.checkpoint INFO: Loading checkpoint from backup/t1_clustering_with_save/model_final.pth
[06/10 05:03:52] d2.data.build INFO: Known classes: range(0, 20)
[06/10 05:03:52] d2.data.build INFO: Labelling known instances the corresponding label, and unknown instances as unknown...
[06/10 05:03:53] d2.data.build INFO: Distribution of instances among all 81 categories:
�[36m| category | #instances | category | #instances | category | #instances |
|:-------------:|:-------------|:-------------:|:-------------|:----------:|:-------------|
| aeroplane | 361 | bicycle | 700 | bird | 800 |
| boat | 607 | bottle | 2339 | bus | 429 |
| car | 3463 | cat | 522 | chair | 3996 |
| cow | 392 | diningtable | 1477 | dog | 697 |
| horse | 455 | motorbike | 587 | person | 18378 |
| pottedplant | 1043 | sheep | 387 | sofa | 686 |
| train | 385 | tvmonitor | 683 | truck | 0 |
| traffic light | 0 | fire hydrant | 0 | stop sign | 0 |
| parking meter | 0 | bench | 0 | elephant | 0 |
| bear | 0 | zebra | 0 | giraffe | 0 |
| backpack | 0 | umbrella | 0 | handbag | 0 |
| tie | 0 | suitcase | 0 | microwave | 0 |
| oven | 0 | toaster | 0 | sink | 0 |
| refrigerator | 0 | frisbee | 0 | skis | 0 |
| snowboard | 0 | sports ball | 0 | kite | 0 |
| baseball bat | 0 | baseball gl.. | 0 | skateboard | 0 |
| surfboard | 0 | tennis racket | 0 | banana | 0 |
| apple | 0 | sandwich | 0 | orange | 0 |
| broccoli | 0 | carrot | 0 | hot dog | 0 |
| pizza | 0 | donut | 0 | cake | 0 |
| bed | 0 | toilet | 0 | laptop | 0 |
| mouse | 0 | remote | 0 | keyboard | 0 |
| cell phone | 0 | book | 0 | clock | 0 |
| vase | 0 | scissors | 0 | teddy bear | 0 |
| hair drier | 0 | toothbrush | 0 | wine glass | 0 |
| cup | 0 | fork | 0 | knife | 0 |
| spoon | 0 | bowl | 0 | unknown | 23320 |
| | | | | | |
| total | 61707 | | | | |�[0m
[06/10 05:03:53] d2.data.build INFO: Number of datapoints: 10246
[06/10 05:03:53] d2.data.common INFO: Serializing 10246 elements to byte tensors and concatenating them all ...
[06/10 05:03:53] d2.data.common INFO: Serialized dataset takes 6.34 MiB
[06/10 05:03:53] d2.data.dataset_mapper INFO: Augmentations used in training: [ResizeShortestEdge(short_edge_length=(800, 800), max_size=1333, sample_style='choice')]
[06/10 05:03:53] d2.evaluation.pascal_voc_evaluation INFO: Loading energy distribution from ./output/t1_final/energy_dist_20.pkl
[06/10 05:03:53] d2.evaluation.evaluator INFO: Start inference on 2562 images
[06/10 05:04:03] d2.evaluation.evaluator INFO: Inference done 11/2562. 0.1747 s / img. ETA=0:07:47
[06/10 05:04:08] d2.evaluation.evaluator INFO: Inference done 39/2562. 0.1739 s / img. ETA=0:07:40
[06/10 05:04:13] d2.evaluation.evaluator INFO: Inference done 65/2562. 0.1783 s / img. ETA=0:07:50
[06/10 05:04:18] d2.evaluation.evaluator INFO: Inference done 93/2562. 0.1777 s / img. ETA=0:07:45
[06/10 05:04:24] d2.evaluation.evaluator INFO: Inference done 116/2562. 0.1843 s / img. ETA=0:07:59
[06/10 05:04:29] d2.evaluation.evaluator INFO: Inference done 141/2562. 0.1866 s / img. ETA=0:08:00
[06/10 05:04:34] d2.evaluation.evaluator INFO: Inference done 167/2562. 0.1859 s / img. ETA=0:07:53
[06/10 05:04:39] d2.evaluation.evaluator INFO: Inference done 190/2562. 0.1894 s / img. ETA=0:07:56
[06/10 05:04:44] d2.evaluation.evaluator INFO: Inference done 216/2562. 0.1889 s / img. ETA=0:07:49
[06/10 05:04:49] d2.evaluation.evaluator INFO: Inference done 244/2562. 0.1876 s / img. ETA=0:07:39
[06/10 05:04:54] d2.evaluation.evaluator INFO: Inference done 269/2562. 0.1880 s / img. ETA=0:07:35
[06/10 05:05:00] d2.evaluation.evaluator INFO: Inference done 295/2562. 0.1886 s / img. ETA=0:07:31
[06/10 05:05:05] d2.evaluation.evaluator INFO: Inference done 319/2562. 0.1895 s / img. ETA=0:07:28
[06/10 05:05:10] d2.evaluation.evaluator INFO: Inference done 346/2562. 0.1888 s / img. ETA=0:07:21
[06/10 05:05:15] d2.evaluation.evaluator INFO: Inference done 371/2562. 0.1895 s / img. ETA=0:07:17
[06/10 05:05:20] d2.evaluation.evaluator INFO: Inference done 399/2562. 0.1881 s / img. ETA=0:07:08
[06/10 05:05:25] d2.evaluation.evaluator INFO: Inference done 424/2562. 0.1890 s / img. ETA=0:07:05
[06/10 05:05:30] d2.evaluation.evaluator INFO: Inference done 450/2562. 0.1892 s / img. ETA=0:07:00
[06/10 05:05:35] d2.evaluation.evaluator INFO: Inference done 478/2562. 0.1882 s / img. ETA=0:06:52
[06/10 05:05:41] d2.evaluation.evaluator INFO: Inference done 506/2562. 0.1875 s / img. ETA=0:06:45
[06/10 05:05:46] d2.evaluation.evaluator INFO: Inference done 534/2562. 0.1868 s / img. ETA=0:06:38
[06/10 05:05:51] d2.evaluation.evaluator INFO: Inference done 561/2562. 0.1865 s / img. ETA=0:06:32
[06/10 05:05:56] d2.evaluation.evaluator INFO: Inference done 587/2562. 0.1865 s / img. ETA=0:06:27
[06/10 05:06:01] d2.evaluation.evaluator INFO: Inference done 613/2562. 0.1868 s / img. ETA=0:06:22
[06/10 05:06:06] d2.evaluation.evaluator INFO: Inference done 639/2562. 0.1868 s / img. ETA=0:06:17
[06/10 05:06:11] d2.evaluation.evaluator INFO: Inference done 666/2562. 0.1866 s / img. ETA=0:06:11
[06/10 05:06:17] d2.evaluation.evaluator INFO: Inference done 692/2562. 0.1866 s / img. ETA=0:06:06
[06/10 05:06:22] d2.evaluation.evaluator INFO: Inference done 715/2562. 0.1875 s / img. ETA=0:06:03
[06/10 05:06:27] d2.evaluation.evaluator INFO: Inference done 741/2562. 0.1876 s / img. ETA=0:05:58
[06/10 05:06:32] d2.evaluation.evaluator INFO: Inference done 766/2562. 0.1879 s / img. ETA=0:05:54
[06/10 05:06:37] d2.evaluation.evaluator INFO: Inference done 792/2562. 0.1879 s / img. ETA=0:05:49
[06/10 05:06:42] d2.evaluation.evaluator INFO: Inference done 818/2562. 0.1879 s / img. ETA=0:05:44
[06/10 05:06:47] d2.evaluation.evaluator INFO: Inference done 842/2562. 0.1884 s / img. ETA=0:05:40
[06/10 05:06:53] d2.evaluation.evaluator INFO: Inference done 868/2562. 0.1886 s / img. ETA=0:05:35
[06/10 05:06:58] d2.evaluation.evaluator INFO: Inference done 893/2562. 0.1888 s / img. ETA=0:05:30
[06/10 05:07:03] d2.evaluation.evaluator INFO: Inference done 918/2562. 0.1890 s / img. ETA=0:05:25
[06/10 05:07:08] d2.evaluation.evaluator INFO: Inference done 944/2562. 0.1889 s / img. ETA=0:05:20
[06/10 05:07:13] d2.evaluation.evaluator INFO: Inference done 969/2562. 0.1892 s / img. ETA=0:05:16
[06/10 05:07:18] d2.evaluation.evaluator INFO: Inference done 996/2562. 0.1890 s / img. ETA=0:05:10
[06/10 05:07:23] d2.evaluation.evaluator INFO: Inference done 1022/2562. 0.1890 s / img. ETA=0:05:05
[06/10 05:07:29] d2.evaluation.evaluator INFO: Inference done 1050/2562. 0.1887 s / img. ETA=0:04:59
[06/10 05:07:34] d2.evaluation.evaluator INFO: Inference done 1076/2562. 0.1888 s / img. ETA=0:04:54
[06/10 05:07:39] d2.evaluation.evaluator INFO: Inference done 1101/2562. 0.1890 s / img. ETA=0:04:49
[06/10 05:07:44] d2.evaluation.evaluator INFO: Inference done 1129/2562. 0.1886 s / img. ETA=0:04:43
[06/10 05:07:49] d2.evaluation.evaluator INFO: Inference done 1155/2562. 0.1886 s / img. ETA=0:04:38
[06/10 05:07:54] d2.evaluation.evaluator INFO: Inference done 1182/2562. 0.1884 s / img. ETA=0:04:32
[06/10 05:07:59] d2.evaluation.evaluator INFO: Inference done 1206/2562. 0.1886 s / img. ETA=0:04:28
[06/10 05:08:04] d2.evaluation.evaluator INFO: Inference done 1232/2562. 0.1886 s / img. ETA=0:04:22
[06/10 05:08:09] d2.evaluation.evaluator INFO: Inference done 1257/2562. 0.1887 s / img. ETA=0:04:18
[06/10 05:08:14] d2.evaluation.evaluator INFO: Inference done 1282/2562. 0.1887 s / img. ETA=0:04:13
[06/10 05:08:20] d2.evaluation.evaluator INFO: Inference done 1307/2562. 0.1890 s / img. ETA=0:04:08
[06/10 05:08:25] d2.evaluation.evaluator INFO: Inference done 1332/2562. 0.1891 s / img. ETA=0:04:03
[06/10 05:08:30] d2.evaluation.evaluator INFO: Inference done 1355/2562. 0.1897 s / img. ETA=0:03:59
[06/10 05:08:35] d2.evaluation.evaluator INFO: Inference done 1377/2562. 0.1902 s / img. ETA=0:03:56
[06/10 05:08:40] d2.evaluation.evaluator INFO: Inference done 1399/2562. 0.1906 s / img. ETA=0:03:52
[06/10 05:08:45] d2.evaluation.evaluator INFO: Inference done 1427/2562. 0.1903 s / img. ETA=0:03:46
[06/10 05:08:51] d2.evaluation.evaluator INFO: Inference done 1453/2562. 0.1902 s / img. ETA=0:03:41
[06/10 05:08:56] d2.evaluation.evaluator INFO: Inference done 1482/2562. 0.1899 s / img. ETA=0:03:34
[06/10 05:09:01] d2.evaluation.evaluator INFO: Inference done 1507/2562. 0.1899 s / img. ETA=0:03:29
[06/10 05:09:06] d2.evaluation.evaluator INFO: Inference done 1533/2562. 0.1899 s / img. ETA=0:03:24
[06/10 05:09:11] d2.evaluation.evaluator INFO: Inference done 1558/2562. 0.1900 s / img. ETA=0:03:19
[06/10 05:09:16] d2.evaluation.evaluator INFO: Inference done 1587/2562. 0.1895 s / img. ETA=0:03:13
[06/10 05:09:21] d2.evaluation.evaluator INFO: Inference done 1612/2562. 0.1897 s / img. ETA=0:03:08
[06/10 05:09:26] d2.evaluation.evaluator INFO: Inference done 1639/2562. 0.1895 s / img. ETA=0:03:03
[06/10 05:09:31] d2.evaluation.evaluator INFO: Inference done 1664/2562. 0.1895 s / img. ETA=0:02:58
[06/10 05:09:36] d2.evaluation.evaluator INFO: Inference done 1691/2562. 0.1894 s / img. ETA=0:02:52
[06/10 05:09:42] d2.evaluation.evaluator INFO: Inference done 1718/2562. 0.1892 s / img. ETA=0:02:47
[06/10 05:09:47] d2.evaluation.evaluator INFO: Inference done 1742/2562. 0.1896 s / img. ETA=0:02:42
[06/10 05:09:52] d2.evaluation.evaluator INFO: Inference done 1765/2562. 0.1899 s / img. ETA=0:02:38
[06/10 05:09:57] d2.evaluation.evaluator INFO: Inference done 1790/2562. 0.1899 s / img. ETA=0:02:33
[06/10 05:10:02] d2.evaluation.evaluator INFO: Inference done 1815/2562. 0.1900 s / img. ETA=0:02:28
[06/10 05:10:07] d2.evaluation.evaluator INFO: Inference done 1840/2562. 0.1901 s / img. ETA=0:02:23
[06/10 05:10:13] d2.evaluation.evaluator INFO: Inference done 1865/2562. 0.1902 s / img. ETA=0:02:18
[06/10 05:10:18] d2.evaluation.evaluator INFO: Inference done 1893/2562. 0.1899 s / img. ETA=0:02:13
[06/10 05:10:23] d2.evaluation.evaluator INFO: Inference done 1921/2562. 0.1897 s / img. ETA=0:02:07
[06/10 05:10:28] d2.evaluation.evaluator INFO: Inference done 1945/2562. 0.1899 s / img. ETA=0:02:02
[06/10 05:10:33] d2.evaluation.evaluator INFO: Inference done 1973/2562. 0.1897 s / img. ETA=0:01:57
[06/10 05:10:38] d2.evaluation.evaluator INFO: Inference done 1998/2562. 0.1898 s / img. ETA=0:01:52
[06/10 05:10:43] d2.evaluation.evaluator INFO: Inference done 2027/2562. 0.1895 s / img. ETA=0:01:46
[06/10 05:10:49] d2.evaluation.evaluator INFO: Inference done 2052/2562. 0.1896 s / img. ETA=0:01:41
[06/10 05:10:54] d2.evaluation.evaluator INFO: Inference done 2078/2562. 0.1896 s / img. ETA=0:01:36
[06/10 05:10:59] d2.evaluation.evaluator INFO: Inference done 2103/2562. 0.1896 s / img. ETA=0:01:31
[06/10 05:11:04] d2.evaluation.evaluator INFO: Inference done 2127/2562. 0.1898 s / img. ETA=0:01:26
[06/10 05:11:09] d2.evaluation.evaluator INFO: Inference done 2150/2562. 0.1901 s / img. ETA=0:01:22
[06/10 05:11:14] d2.evaluation.evaluator INFO: Inference done 2175/2562. 0.1901 s / img. ETA=0:01:17
[06/10 05:11:19] d2.evaluation.evaluator INFO: Inference done 2203/2562. 0.1899 s / img. ETA=0:01:11
[06/10 05:11:24] d2.evaluation.evaluator INFO: Inference done 2227/2562. 0.1901 s / img. ETA=0:01:06
[06/10 05:11:29] d2.evaluation.evaluator INFO: Inference done 2253/2562. 0.1900 s / img. ETA=0:01:01
[06/10 05:11:34] d2.evaluation.evaluator INFO: Inference done 2280/2562. 0.1899 s / img. ETA=0:00:56
[06/10 05:11:40] d2.evaluation.evaluator INFO: Inference done 2306/2562. 0.1899 s / img. ETA=0:00:50
[06/10 05:11:45] d2.evaluation.evaluator INFO: Inference done 2330/2562. 0.1901 s / img. ETA=0:00:46
[06/10 05:11:50] d2.evaluation.evaluator INFO: Inference done 2355/2562. 0.1901 s / img. ETA=0:00:41
[06/10 05:11:55] d2.evaluation.evaluator INFO: Inference done 2382/2562. 0.1900 s / img. ETA=0:00:35
[06/10 05:12:00] d2.evaluation.evaluator INFO: Inference done 2406/2562. 0.1901 s / img. ETA=0:00:31
[06/10 05:12:05] d2.evaluation.evaluator INFO: Inference done 2433/2562. 0.1901 s / img. ETA=0:00:25
[06/10 05:12:10] d2.evaluation.evaluator INFO: Inference done 2458/2562. 0.1901 s / img. ETA=0:00:20
[06/10 05:12:15] d2.evaluation.evaluator INFO: Inference done 2484/2562. 0.1900 s / img. ETA=0:00:15
[06/10 05:12:20] d2.evaluation.evaluator INFO: Inference done 2507/2562. 0.1902 s / img. ETA=0:00:10
[06/10 05:12:26] d2.evaluation.evaluator INFO: Inference done 2533/2562. 0.1902 s / img. ETA=0:00:05
[06/10 05:12:31] d2.evaluation.evaluator INFO: Inference done 2558/2562. 0.1903 s / img. ETA=0:00:00
[06/10 05:12:32] d2.evaluation.evaluator INFO: Total inference time: 0:08:30.307989 (0.199573 s / img per device, on 4 devices)
[06/10 05:12:32] d2.evaluation.evaluator INFO: Total inference pure compute time: 0:08:06 (0.190421 s / img per device, on 4 devices)
[06/10 05:13:33] d2.evaluation.pascal_voc_evaluation INFO: Evaluating voc_coco_2007_test using 2012 metric. Note that results do not use the official Matlab API.
[06/10 05:13:33] d2.evaluation.pascal_voc_evaluation INFO: aeroplane has 1990 predictions.
[06/10 05:13:35] d2.evaluation.pascal_voc_evaluation INFO: bicycle has 2569 predictions.
[06/10 05:13:36] d2.evaluation.pascal_voc_evaluation INFO: bird has 3305 predictions.
[06/10 05:13:36] d2.evaluation.pascal_voc_evaluation INFO: boat has 4130 predictions.
[06/10 05:13:37] d2.evaluation.pascal_voc_evaluation INFO: bottle has 6446 predictions.
[06/10 05:13:37] d2.evaluation.pascal_voc_evaluation INFO: bus has 2355 predictions.
[06/10 05:13:38] d2.evaluation.pascal_voc_evaluation INFO: car has 9965 predictions.
[06/10 05:13:39] d2.evaluation.pascal_voc_evaluation INFO: cat has 1828 predictions.
[06/10 05:13:39] d2.evaluation.pascal_voc_evaluation INFO: chair has 16460 predictions.
[06/10 05:13:40] d2.evaluation.pascal_voc_evaluation INFO: cow has 2310 predictions.
[06/10 05:13:41] d2.evaluation.pascal_voc_evaluation INFO: diningtable has 5626 predictions.
[06/10 05:13:41] d2.evaluation.pascal_voc_evaluation INFO: dog has 2851 predictions.
[06/10 05:13:42] d2.evaluation.pascal_voc_evaluation INFO: horse has 2374 predictions.
[06/10 05:13:42] d2.evaluation.pascal_voc_evaluation INFO: motorbike has 2080 predictions.
[06/10 05:13:43] d2.evaluation.pascal_voc_evaluation INFO: person has 44151 predictions.
[06/10 05:13:46] d2.evaluation.pascal_voc_evaluation INFO: pottedplant has 6559 predictions.
[06/10 05:13:47] d2.evaluation.pascal_voc_evaluation INFO: sheep has 2258 predictions.
[06/10 05:13:47] d2.evaluation.pascal_voc_evaluation INFO: sofa has 4422 predictions.
[06/10 05:13:48] d2.evaluation.pascal_voc_evaluation INFO: train has 2554 predictions.
[06/10 05:13:48] d2.evaluation.pascal_voc_evaluation INFO: tvmonitor has 3943 predictions.
[06/10 05:13:49] d2.evaluation.pascal_voc_evaluation INFO: truck has 1 predictions.
[06/10 05:13:49] d2.evaluation.pascal_voc_evaluation INFO: traffic light has 1 predictions.
[06/10 05:13:49] d2.evaluation.pascal_voc_evaluation INFO: fire hydrant has 1 predictions.
[06/10 05:13:50] d2.evaluation.pascal_voc_evaluation INFO: stop sign has 1 predictions.
[06/10 05:13:50] d2.evaluation.pascal_voc_evaluation INFO: parking meter has 1 predictions.
[06/10 05:13:50] d2.evaluation.pascal_voc_evaluation INFO: bench has 1 predictions.
[06/10 05:13:50] d2.evaluation.pascal_voc_evaluation INFO: elephant has 1 predictions.
[06/10 05:13:51] d2.evaluation.pascal_voc_evaluation INFO: bear has 1 predictions.
[06/10 05:13:51] d2.evaluation.pascal_voc_evaluation INFO: zebra has 1 predictions.
[06/10 05:13:51] d2.evaluation.pascal_voc_evaluation INFO: giraffe has 1 predictions.
[06/10 05:13:52] d2.evaluation.pascal_voc_evaluation INFO: backpack has 1 predictions.
[06/10 05:13:52] d2.evaluation.pascal_voc_evaluation INFO: umbrella has 1 predictions.
[06/10 05:13:52] d2.evaluation.pascal_voc_evaluation INFO: handbag has 1 predictions.
[06/10 05:13:53] d2.evaluation.pascal_voc_evaluation INFO: tie has 1 predictions.
[06/10 05:13:53] d2.evaluation.pascal_voc_evaluation INFO: suitcase has 1 predictions.
[06/10 05:13:53] d2.evaluation.pascal_voc_evaluation INFO: microwave has 1 predictions.
[06/10 05:13:53] d2.evaluation.pascal_voc_evaluation INFO: oven has 1 predictions.
[06/10 05:13:54] d2.evaluation.pascal_voc_evaluation INFO: toaster has 1 predictions.
[06/10 05:13:54] d2.evaluation.pascal_voc_evaluation INFO: sink has 1 predictions.
[06/10 05:13:54] d2.evaluation.pascal_voc_evaluation INFO: refrigerator has 1 predictions.
[06/10 05:13:55] d2.evaluation.pascal_voc_evaluation INFO: frisbee has 1 predictions.
[06/10 05:13:55] d2.evaluation.pascal_voc_evaluation INFO: skis has 1 predictions.
[06/10 05:13:55] d2.evaluation.pascal_voc_evaluation INFO: snowboard has 1 predictions.
[06/10 05:13:55] d2.evaluation.pascal_voc_evaluation INFO: sports ball has 1 predictions.
[06/10 05:13:56] d2.evaluation.pascal_voc_evaluation INFO: kite has 1 predictions.
[06/10 05:13:56] d2.evaluation.pascal_voc_evaluation INFO: baseball bat has 1 predictions.
[06/10 05:13:56] d2.evaluation.pascal_voc_evaluation INFO: baseball glove has 1 predictions.
[06/10 05:13:57] d2.evaluation.pascal_voc_evaluation INFO: skateboard has 1 predictions.
[06/10 05:13:57] d2.evaluation.pascal_voc_evaluation INFO: surfboard has 1 predictions.
[06/10 05:13:57] d2.evaluation.pascal_voc_evaluation INFO: tennis racket has 1 predictions.
[06/10 05:13:58] d2.evaluation.pascal_voc_evaluation INFO: banana has 1 predictions.
[06/10 05:13:58] d2.evaluation.pascal_voc_evaluation INFO: apple has 1 predictions.
[06/10 05:13:58] d2.evaluation.pascal_voc_evaluation INFO: sandwich has 1 predictions.
[06/10 05:13:59] d2.evaluation.pascal_voc_evaluation INFO: orange has 1 predictions.
[06/10 05:13:59] d2.evaluation.pascal_voc_evaluation INFO: broccoli has 1 predictions.
[06/10 05:13:59] d2.evaluation.pascal_voc_evaluation INFO: carrot has 1 predictions.
[06/10 05:14:00] d2.evaluation.pascal_voc_evaluation INFO: hot dog has 1 predictions.
[06/10 05:14:00] d2.evaluation.pascal_voc_evaluation INFO: pizza has 1 predictions.
[06/10 05:14:00] d2.evaluation.pascal_voc_evaluation INFO: donut has 1 predictions.
[06/10 05:14:01] d2.evaluation.pascal_voc_evaluation INFO: cake has 1 predictions.
[06/10 05:14:01] d2.evaluation.pascal_voc_evaluation INFO: bed has 1 predictions.
[06/10 05:14:01] d2.evaluation.pascal_voc_evaluation INFO: toilet has 1 predictions.
[06/10 05:14:02] d2.evaluation.pascal_voc_evaluation INFO: laptop has 1 predictions.
[06/10 05:14:02] d2.evaluation.pascal_voc_evaluation INFO: mouse has 1 predictions.
[06/10 05:14:02] d2.evaluation.pascal_voc_evaluation INFO: remote has 1 predictions.
[06/10 05:14:02] d2.evaluation.pascal_voc_evaluation INFO: keyboard has 1 predictions.
[06/10 05:14:03] d2.evaluation.pascal_voc_evaluation INFO: cell phone has 1 predictions.
[06/10 05:14:03] d2.evaluation.pascal_voc_evaluation INFO: book has 1 predictions.
[06/10 05:14:03] d2.evaluation.pascal_voc_evaluation INFO: clock has 1 predictions.
[06/10 05:14:04] d2.evaluation.pascal_voc_evaluation INFO: vase has 1 predictions.
[06/10 05:14:04] d2.evaluation.pascal_voc_evaluation INFO: scissors has 1 predictions.
[06/10 05:14:04] d2.evaluation.pascal_voc_evaluation INFO: teddy bear has 1 predictions.
[06/10 05:14:05] d2.evaluation.pascal_voc_evaluation INFO: hair drier has 1 predictions.
[06/10 05:14:05] d2.evaluation.pascal_voc_evaluation INFO: toothbrush has 1 predictions.
[06/10 05:14:05] d2.evaluation.pascal_voc_evaluation INFO: wine glass has 1 predictions.
[06/10 05:14:06] d2.evaluation.pascal_voc_evaluation INFO: cup has 1 predictions.
[06/10 05:14:06] d2.evaluation.pascal_voc_evaluation INFO: fork has 1 predictions.
[06/10 05:14:06] d2.evaluation.pascal_voc_evaluation INFO: knife has 1 predictions.
[06/10 05:14:07] d2.evaluation.pascal_voc_evaluation INFO: spoon has 1 predictions.
[06/10 05:14:07] d2.evaluation.pascal_voc_evaluation INFO: bowl has 1 predictions.
[06/10 05:14:07] d2.evaluation.pascal_voc_evaluation INFO: unknown has 32573 predictions.
[06/10 05:14:09] d2.evaluation.pascal_voc_evaluation INFO: Wilderness Impact: {0.1: {50: 0.015074211502782932}, 0.2: {50: 0.022118742724097785}, 0.3: {50: 0.03910034602076124}, 0.4: {50: 0.05038959819752159}, 0.5: {50: 0.049498067919281956}, 0.6: {50: 0.04874401462169388}, 0.7: {50: 0.04493868016351956}, 0.8: {50: 0.04991488217901622}, 0.9: {50: 0.055984794253412656}}
[06/10 05:14:10] d2.evaluation.pascal_voc_evaluation INFO: avg_precision: {0.1: {50: 0.060781120363826324}, 0.2: {50: 0.060781120363826324}, 0.3: {50: 0.060781120363826324}, 0.4: {50: 0.060781120363826324}, 0.5: {50: 0.060781120363826324}, 0.6: {50: 0.060781120363826324}, 0.7: {50: 0.060781120363826324}, 0.8: {50: 0.060781120363826324}, 0.9: {50: 0.060781120363826324}}
[06/10 05:14:10] d2.evaluation.pascal_voc_evaluation INFO: Absolute OSE (total_num_unk_det_as_known): {50: 7259.0}
[06/10 05:14:10] d2.evaluation.pascal_voc_evaluation INFO: total_num_unk 23320
[06/10 05:14:10] d2.evaluation.pascal_voc_evaluation INFO: ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor', 'truck', 'traffic light', 'fire hydrant', 'stop sign', 'parking meter', 'bench', 'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'frisbee', 'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket', 'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'bed', 'toilet', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'unknown']
[06/10 05:14:10] d2.evaluation.pascal_voc_evaluation INFO: AP50: ['79.5', '56.5', '58.3', '42.9', '24.0', '71.7', '54.4', '80.8', '20.3', '70.0', '16.0', '77.7', '80.3', '66.9', '46.7', '30.6', '67.4', '48.0', '76.4', '56.8', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '1.2']
[06/10 05:14:10] d2.evaluation.pascal_voc_evaluation INFO: Precisions50: ['15.3', '17.1', '14.9', '7.8', '13.5', '14.4', '21.4', '25.5', '8.3', '11.7', '9.6', '21.1', '16.2', '20.6', '26.0', '9.1', '11.8', '9.2', '12.8', '12.5', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '6.1']
[06/10 05:14:10] d2.evaluation.pascal_voc_evaluation INFO: Recall50: ['90.1', '67.3', '71.2', '66.5', '40.1', '86.6', '66.5', '91.0', '39.7', '85.7', '38.7', '90.9', '92.6', '77.7', '64.2', '63.7', '82.7', '73.9', '89.0', '77.6', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '0.0', '8.5']
[06/10 05:14:10] d2.evaluation.pascal_voc_evaluation INFO: Current class AP50: 56.26823138862905
[06/10 05:14:10] d2.evaluation.pascal_voc_evaluation INFO: Current class Precisions50: 14.939950796347716
[06/10 05:14:10] d2.evaluation.pascal_voc_evaluation INFO: Current class Recall50: 72.77744750787848
[06/10 05:14:10] d2.evaluation.pascal_voc_evaluation INFO: Known AP50: 56.26823138862905
[06/10 05:14:10] d2.evaluation.pascal_voc_evaluation INFO: Known Precisions50: 14.939950796347716
[06/10 05:14:10] d2.evaluation.pascal_voc_evaluation INFO: Known Recall50: 72.77744750787848
[06/10 05:14:10] d2.evaluation.pascal_voc_evaluation INFO: Unknown AP50: 1.1656362823677229
[06/10 05:14:10] d2.evaluation.pascal_voc_evaluation INFO: Unknown Precisions50: 6.072514045375004
[06/10 05:14:10] d2.evaluation.pascal_voc_evaluation INFO: Unknown Recall50: 8.481989708404802
[06/10 05:14:10] d2.engine.defaults INFO: Evaluation results for voc_coco_2007_test in csv format:
[06/10 05:14:10] d2.evaluation.testing INFO: copypaste: Task: bbox
[06/10 05:14:10] d2.evaluation.testing INFO: copypaste: AP,AP50
[06/10 05:14:10] d2.evaluation.testing INFO: copypaste: 13.9078,13.9078