jcjohnson / pytorch-examples Goto Github PK
View Code? Open in Web Editor NEWSimple examples to introduce PyTorch
License: MIT License
Simple examples to introduce PyTorch
License: MIT License












































































































































































































According to a very recent version of pytorch, this would cause the following error: 'NoneType' object has no attribute 'data'.
Maybe we should zero the gradients after running the backward pass now.
a s s
a s s
a s s
I am gonna step on the ass
toniiiiiiiiIIIIIIIiiiiiiiiiiiiigHT I'll TryYYyyyyyyyYYYyyyyYYyy
To be ur LovRrrRRRrrrrrrrrrr
I was going through the PyTorch documentation on the webpage:
https://pytorch.org/tutorials/beginner/pytorch_with_examples.html#tensors
First of all, thanks a lot for the brilliant tutorial. @jcjohnson
I noticed some typing errors, and thought I should bring it to your notice.
# dtype = torch.device("cuda:0") # Uncomment this to run on GPU
This is a line which is repeated several times throughout the tutorial on the aforementioned web page, and hence might be confusing for newbies like me. I think the correct should be
# device = torch.device("cuda:0") # Uncomment this to run on GPU
Thanks,
Rajat Chhabra
The backward function receives the gradient of the output Tensors with respect to some scalar value.
What is this scalar value? What does it represent in the computational graph?
Hey @jcjohnson, sorry for opening an issue here, didn't know how to reach You without e-mailing on Your Stanford inbox.
I haven't used torch or Lua, but I remember some of my friends talking about your implementation of char-rnn in Lua. They said it was super fast.
I'm wondering if it is possible to do something like that in PyTorch? Or the speed was thanks to Lua's JIT compiler, and Python interpreter will simply incur too much overhead? In general, do You think PyTorch is suitable for applications with lots of small computations (char-lvl, pixel-lvl stuff)?
Hi!
I'm trying to run the code in file tensor/two_layer_net_tensor.py which looks similar to this at the beginning
import torch
# dtype = torch.FloatTensor
dtype = torch.cuda.FloatTensor # Uncomment this to run on GPU
print('pass1')
# N is batch size; D_in is input dimension;
The code works fine when my dtype is torch.FloatTensor, but when I run it on GPU it gets stuck at h = x.mm(w1). I verified that print(torch.cuda.is_available()) returns true, which means GPU functionality is working fine so I'm at a loss as to what the issue is.
Need help.
And Thank You @jcjohnson for this super helpful write-up!!
when it says:
"after backpropagation x.grad will be another Tensor holding the gradient of x with respect to some scalar value."
it should be
"after backpropagation x.grad will be another Tensor holding the gradient of some scalar value with respect to x."
Sorry for this issue. It was a mistake.
I'd recommend actually using the mean squared error for all these examples. These lines in particular are very misleading to someone not familiar with PyTorch loss function params:
# The nn package also contains definitions of popular loss functions; in this
# case we will use Mean Squared Error (MSE) as our loss function.
loss_fn = torch.nn.MSELoss(size_average=False)
Calling this the popular MSE loss function is confusing at best. At the very least, you should make note of what the size_average=False parameter is doing, i.e. no longer making it a MSE! That is a SE sum. New and potential PyTorch users are likely using these examples to compare to Tensorflow, and it is extremely easy to become frustrated when your losses which you think are MSE are ending up way larger compared to the same model running in TF. It's also easy to become frustrated when you start hitting NAN values a lot easier with large datasets.
Other than that, I loved the examples. An excellent introduction to an amazing package.
self.saved_tensors in custom backward function doesn't work hence cannot compute backward using the subclass method
已经解决了win10下的训练自己的数据问题,加Q群857449786 注明pytorch examples 共同研究
# dtype = torch.device("cuda:0") # Uncomment this to run on GPU
should be
# device = torch.device("cuda:0") # Uncomment this to run on GPU
In Warm-up exercises using Numpy and PyTorch, corresponding to lines
y_pred = h_relu.dot(w2) and
y_pred = h_relu.mm(w2) respectively,
I am unable to understand why activation function is not applied to the output neuron to produce the final output? In both the examples, h_relu corresponds to the activation function on the hidden layer. Need some understanding on why this activation function is missing on outputs.
I'm sorry to open an issue here,but I want to raise a problem in the part:"PyTorch: Defining new autograd functions",the problem is that
Below class ReLu, function backward, here is a code :input,=self.saved_tensors, when I move the "," behind "input", and run the code "loss.backward()"below,I get an error:
File "/home/ry-feng/anaconda3/envs/python36/lib/python3.6/site-packages/torch/autograd/variable.py", line 146, in backward
self._execution_engine.run_backward((self,), (gradient,), retain_variables)
File "", line 8, in backward
TypeError: '<' not supported between instances of 'tuple' and 'int'
When I add "," ,the program can run normally, I don't know what cause this problem, I hope I could get some help from you, thanks a lot.
In Autograd:
If x is a Tensor that has x.requires_grad=True then x.grad is another Tensor holding the gradient of x with respect to some scalar value.
should be
If x is a Tensor that has x.requires_grad=True then x.grad is another Tensor holding the gradient of scalar (usually loss) with respect to x.
Hey @jcjohnson, first of all thank you for these, eternally thankful...
The issue-
4th paragraph Pytorch:Autograd -
"for example we usually don't want to backpropagate through the weight update steps when training a neural network"
This should be done when the network is being evaluated too right? At that time we don't want extra memory to be used(to keep track) if we aren't going to update the weights
When you compute loss, why don't you divide by a batch size to get mean squared error?
In the backprop for the warm up example, to obtain the grad_w2, why is h_relu.T is required. when the derivative of dY_pred/dW2 = h_relu and DLoss/DY_pred = 2(y_pred - y), from chain rule, we obtain Dloss/Dw2 as h_relu * 2(y_pred - y) not h_relu.T * 2 (y_pred - y).
Can you explain why it is h_relu.T ???
Shouldn't w2.t() below be grad_w2 instead ? Thanks.
grad_y_pred = 2.0 * (y_pred - y)
grad_w2 = h_relu.t().mm(grad_y_pred)
grad_h_relu = grad_y_pred.mm(w2.t())
Why do we need to call the clamp function on the prediction for the first layer?
When running the beginning autograd code on the ReadMe intro, I'm getting:
w1.grad.data.zero_()
AttributeError: 'NoneType' object has no attribute 'data'
I'm using PyTorch Version: 0.1.12_2 and python 2.7
I try to install pytorch and after days of trying Im here with a big, big problem. I read a lot of articles of "how to install pytorch" I try to install with pip install but dont work for me and after I install it with Anaconda, but in anaconda is pytorch install, when I type: conda list, he is there like this form: pytorch 1.0.1 py3.7_cuda100_cudnn7_1 pytorch, I have python 3.7, when I run a code with import torch this show me a message like this:
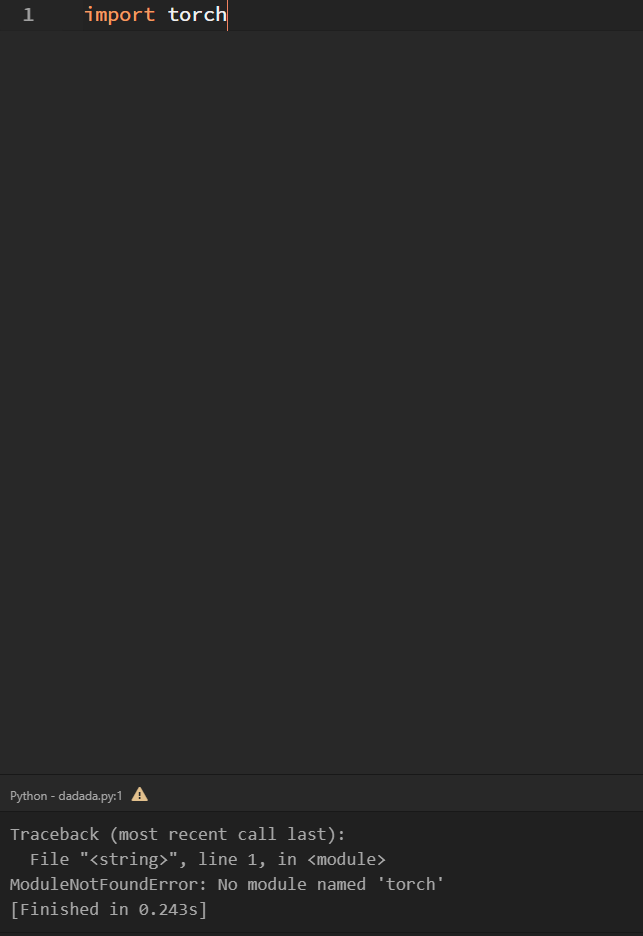
And when i try to import torch in python 3.7:
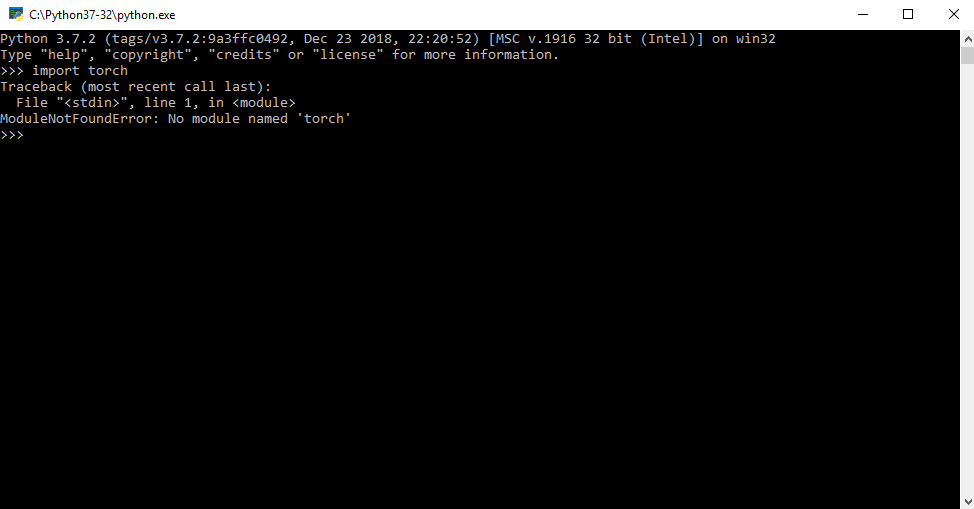
Pip install error:
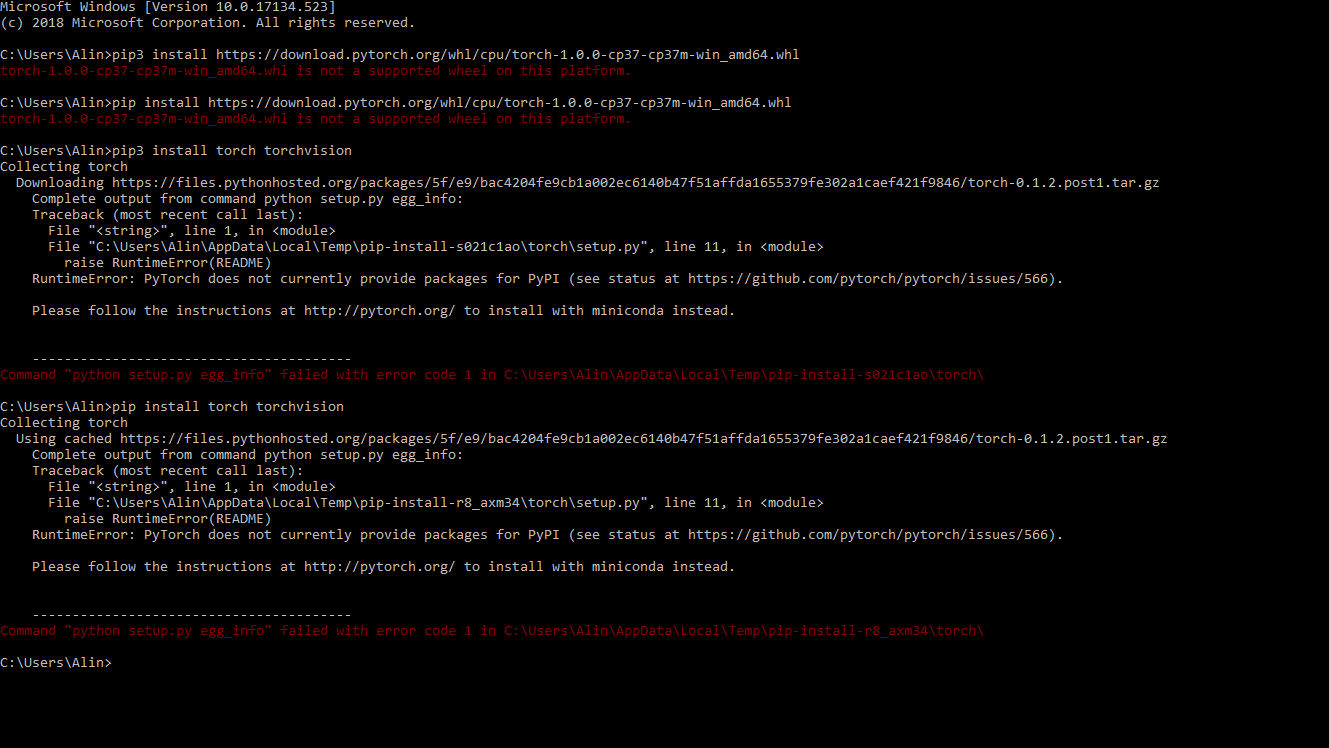
How to pass this errors? Please Help, thx.
Corresponding to the line
model.zero_grad() in the
section "nn", I want to understand why do we need to make gradients zero before the backward pass?
Theoretically, isnt the backward pass supposed to utilize existing gradients to correct the weights? How setting them zero should help?
I cannot understand the 41-43 line.Can someone explain it?
# Backprop to compute gradients of w1 and w2 with respect to loss
grad_y_pred = 2.0 * (y_pred - y)
grad_w2 = h_relu.T.dot(grad_y_pred)
Thanks a lot for your amazing examples!
I find that in the examples using nn module the learning_rate is 1e-4, while without the nn module the learning_rate is 1e-6.
I did not figure out the reason why those examples using nn require larger learning_rate🙁
In the first example:
Backprop to compute gradients of w1 and w2 with respect to loss
should be
Backprop to compute gradient of loss with respect to w1 and w2
Thank you for the nice write-up!
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.