simonalexanderson / stylegestures Goto Github PK
View Code? Open in Web Editor NEWLicense: Other
License: Other





















































































































I train 'style_gestures' with the challenge data in GENEA Workshop and use the provided data processing script to get the training input. The training loss decreases from tens to negative hundreds (80 -> -200) and the validation loss first decreases from tens to negative tens and then increase to thousands (80 -> -20 -> 10000).
I am not familiar with the flow-based model and do not know the correct training log. Could you provide your training log or a pretrained model? Thank you for your help! @simonalexanderson
Hi, thank you for providing the code, it really helps me a lot.
As proposed in the paper, four lower-level style attributes are discussed here. I wonder: 1. Why don't you use a four-dimensional vector 's_t' to control all four style attributes simultaneously; 2. Can I control a single style property with a multiple dimensional style input vector 's_t'?
Hey there,
Again, thank you very much for sharing your code ❤️
A batch size of 80 is the default for your model. @ghenter mentioned in issue #9 that you have run the GPU fairly to the maximum capacity in terms of memory during experiments in training of MoGlow/StyleGestures. Does this mean that you do not have experimented with batch sizes > 80 in early stages? And if you actually did experiment with bigger batch sizes, did you see some effect on the synthesized gestures in terms of humanlikeness and appropriateness?
Same question for batch sizes < 80: did you experiment with smaller batch sizes in early training stages? Any effects on quality of synthesized gestures?
A bit of background to this question: I forked your repository and for training I extended the input feature space with BERT feature vectors of the corresponding transcripts. The cluster on which I run the model training has a GPU memory capacity that forces me to use a batch size of approx. 10 because the BERT features actually need by some magnitudes more memory than the speech features.
The generated samples which result from training with this batch size look like being "fast-forwarded", so they move way faster than for example the generated samples which are generated with the original feature space (i.e., your code). Also the motion and poses are not really humanlike.
So in all my question is intended so that I get to know if there is something wrong with my code and concept or if these motion artifacts arise from the fact that I use a small batch size.
Looking forward to your reply. It would help me a great deal! =)
Best regards,
Stefan
Simon,
I am thinking the following code of trainer.py may have a problem ---
print(
f'Loss: {loss.item():.5f}/ Validation Loss: {loss_val:.5f} '
)
Here loss's value was updated per batch (it was not accumulated per batch), so here I guess the attention is to print out an average loss of the total train set, but it actually print out the loss of the last batch of each epoch,
Please let me know your thoughts, maybe I am wrong?
Have a nice day,
I print out the rightforehand rotation information of the trinity dataset bvh file, and found some really confused phenomenon. As the following image shows, when the X rotation reaches 90 degrees, the Z rotation and Y rotation will change suddenly from -180 or 180 to nearly 0. This looks quite like the so called "gimbal lock".
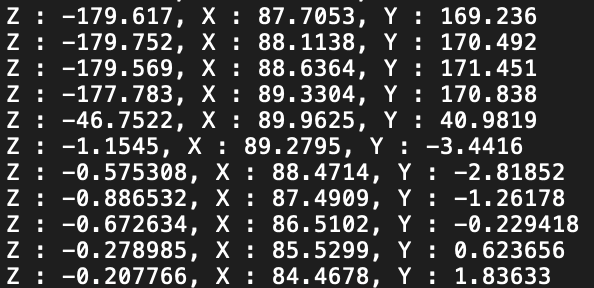
But will this kind of sudden change in data affect the performance of your model? I found my full-body model will output some samples will hands rotating unnaturally. But your full-body samples look quite well. Do you ever encounter this problem? If so, can you offer some advice?
I run (moglow) [liu@no3@node02 StyleGestures]$ python train_moglow.py '/home/liu@no3/StyleGestures/hparams/locomotion.json' locomotion
File "train_moglow.py", line 49
trainer = Trainer(**built, data=data, log_dir=log_dir, hparams=hparams)
^
SyntaxError: invalid syntax
what was wrong?
thanks a lot。
I use pytorch1.5,python3.7
How to get the data set of the gesture synthesis ?
Could you explain how you transform the output data into .mp4 video?
Hi,
Thanks for sharing the code. the data we got from Trinity is fbx for motion and wav for audio. Is there any chance to get the data pre-processing code for fbx file?
Thanks
Hey and thanks in advance for the help!
What is the difference betweern timesteps and seqlen in this function?
concat_sequence on the motion_data(not the control or autoregressive) leaves the data "untouched". Is that supposed to happen?Hey everyone,
Thank you for this repository and sharing your code, it indeed produces great results.
After training your model, I've came across an issue concerning a mismatch between the length of the input audio file and the synthesized gesture sequence. The synthesized gesture sequence is 20 frames shorter than it should be, at least this is the result which I've got when I imported both the wav and bvh file into Blender and let them play alongside.
You should be able to reproduce this error with the following steps:
TestSeq001.wav in test_audio folder and generating a gesture sequence based on this input2331 frames) and the the file TestSeq001.bvh from the [zenodo repository with your submitted bvh files for the GENEA challenge] (https://zenodo.org/record/4088324) which has 2351 frames (Cond_SC should be correct, right?)For me, about a second (=20 frames) of the animation was missing. I'd be happy if you have a look into this and tell me if you can reproduce this error, so I know if the problem is only on my end or not.
Thank you in advance!
Regards,
Stefan
Hi,
Thank you very much for open source your code. I can get reasonable results when I train with the single gpu. But when I use multiple gpus to train the model with exactly same data and batch size, the results I get is very jittering. Just like a fast forward playing mode. Do you happen to know this issue? Does that mean your training code doesn't support multiple gpu for training ?
Thank
Hi, thank you for providing the code, it really helps me a lot.
As proposed in the paper, four lower-level style attributes are discussed here. I wonder: 1. Why don't you use a four-dimensional vector 's_t' to control all four style attributes simultaneously; 2. Can I control a single style property with a multiple dimensional style input vector 's_t'?
Dear Simon,
I am reading your code of preprocessing. I have two questions in my mind about "RootTransfomer" ---
1> There are three kinds of transformations,hip-centric is clear, and in your paper, I saw some description about "pos_rot_deltas", but what is "abdolute_translation_deltas" please? Could you give some description here? Thanks!
To my humble understanding, I guess "abdolute_translation_deltas" only try to introduce some features on body movement without any feature on body rotation? But "pos_rot_deltas" try to cover both movement and rotation, is that correct?
2> In your paper, you mentioned that, you have two models, one is FB-U, the other is FB-C. My question is where I can find a example code for you to construct the control vector?
Thanks for your sharing,
Kelvin
The link https://kth.box.com/s/quh3rwwl2hedwo32cdg1kq7pff04fjdf .It showed that: This shared file or folder link has been removed or is unavailable to you when I click in.
Hello,
can you provide a pre-trained model?
Thank you!
Hi, Thank you for publishing the code, it is really helpful to me.
I have a question about LSTM cell.
When I debug the affine coupling layer, the input shape of each LSTM cell is a (batch size, 70, feature) during the training, and the input shape is a (batch size, 1, feature) during the generating sample data.
In my knowledge, definition of LSTM input is a (batch size, sequence length, feature), and it means that we use 70 LSTM cells for training and we use a single cell for generating sample.
I suppose that LSTM input will be same both foward and reverse flow.
I am a beginner about Deep-learning framework, Could you tell me it is right or not which I understand?
Thank you
Taeil Jin
Line 326 in a759935
This is the curve when I use two different data sets for training, and the parameters are the same. It can be roughly seen that the loss in Figure 1 will be lower than that in Figure 2, which can indicate that the performance of the first trained model will be better?
Hello, I am trying to reproduce this project, but some problems have occurred during the process. Could you provide a pre trained model? Thanks a lot!
Hello, I hope I'm not disturbing you. My questions are as follows.
First, I notice that when the global steps reach the number of 'plot_gap', the model will sample some '.bvh' files. How can I find the corresponding audio files? I supposed that the corresponding audio files should be in the 'visualization_dev' or 'visualization_test' folder, but the quantity of the audio files in these folders is both different with the quantity of output '.bvh' files. How can I find the corresponding audio clips of the output 'bvh' files?
Seconde, I find that, in 'trinity.py', the 'test_input_20fps.npz' and the 'test_output_20fps.npz' files which were processed in 'prepare_datasets.py', were not used. It seems that I haven't found the files were used in other places. The files are must be useful in the overlooked place. Can you give me some guidances to help me resolve this confusion?
I would be grateful if you could give me some help. I am looking forward to hearing from you!
Best wishes for you!
Hello,
What`s the python version about this project?
Thank you!
Dear Simon,
Today I spend some time to set up the training environment of gesture model building. Thanks for your work, my job is running now (python3 train_moglow.py 'hparams/preferred/style_gestures.json' trinity)
epoch 175
100%|██████████| 105/105 [01:22<00:00, 1.27it/s]
Loss: -193.54697/ Validation Loss: -7.10412
epoch 176
100%|██████████| 105/105 [01:23<00:00, 1.25it/s]
Loss: -192.43456/ Validation Loss: -10.91878
epoch 177
100%|██████████| 105/105 [01:23<00:00, 1.26it/s]
Loss: -194.91096/ Validation Loss: -10.91878
epoch 178
One silly question ---
Where I can find the intermediate model please? I went to "StyleGestures/results/GENEA/log_20210104_1349/checkpoints", but there is not any file.
Thanks!
Kelvin
Hi, I have set up the environment and run the project, however, the default cuda version in the style_gestures.json is 7.
I intent to switch the version to 10.2 or 11.3, but, after i change the setting in the json, like this cuda=11.3, it showed an error ,which show below:
ValueError: invalid literal for int() with base 10
And i change the 11.3 to 11 in json, it showed that:
Failed to find any valid gpu in ['cuda:11'], use cpu.
What`s that bug?
Thank you!
Hello, I received this message during operation: unable to allocate 8.94 gib for an array with shape (54440, 70, 10, 63) and data type float32. How much memory do I need to run?
Hi,
Thanks for your nice work. The network's output is world positions about joints, I'm wondering is there a way to convert to BVH format? Because rotation info is quite useful for some applications. Thanks!
Hi, Thanks for sharing this great project.
I training by follow command only by CPU on Ubuntu18 (no GPU).
python train_moglow.py 'hparams/style_gestures.json' trinity
My question is, 96GB memory run out. Training process will killed by OS. It seems memory leak happed during training process, Could help verify, Thanks!
Hello,
can you provide a download link to the required training data?
Unfortunately, I can not find it.
Thank you
I found in motion/motion_data.py
the code "data[:,inds,:].reshape((nn, L, seqlen*n_feats))" consumes a lot of memory. When the code is called, my internal memory explodes. My inernal memory is about 16G. Is there any solution for me other than extend extra memory because I dou't have enough money at all.
In addition ,I found the codes use too many "array.copy()" which I think it's unnecessary and consumes a lot of memory.
Thanks a lot!
I downloaded the https://kth-my.sharepoint.com/:f:/g/personal/simonal_ug_kth_se/EuzCqSiScf5EvwWgZJ8EZ3wB24oPsKca9klzGzxzV-4N6g?e=BG1ELf and running the training code found that the dimensions of the test set and training set are inconsistent .
input_data: (13710, 80, 66)
test_data: (31, 100, 66)
It seems that the updated link in readme has again expired...
It would be very helpful if you could again update the download link!
Thanks!
Dear,
May I ask you a question. How to make own datasets as the format as Trinity Speech-Gesture Dataset.
I found that when I use my pertained model to synthesize new gesture following the guidance, there is only the bvh output, how can I get the paired audio data ?
Hello Simon Alexanderson:
I am glad to communicate with you! I come from Communication University of Zhejiang, China.
I am quite interested in the research in the field of gesture generation for virtual Human , but I just started to set foot in this field.
Could you please tell me what materials ,papers ,journal or books you can recommend to help me get started?
Thank you !
Best,
ZhangFan
Hi!
Does the non-commercial limit apply to only the code or does it extend to trained models (on own dataset)? For example if we ship a product that only has the final trained model on our dataset?
If the limit extends to trained models is a commercial license possible?
I've run the trinity dataset and generated some samples, and everything looks fine.😆 However the bvh files are fixed with 380 frames(19seconds), while my input test data are more than one minute. Hopefully there's a way to set the frames automatically.
hello , sorry to trouble you again.I have read your anther paper of Moglow, I try to reproduce the results but I can't figure out what the original input data is. For example, you generate gestures by audio then the main input data is audio.
The paper name is "MoGlow: Probabilistic and controllable motion synthesis using normalising flows ". It seems to be a autogressive model totally with locomotion?
Hi Smion,
I am trying to build a baseline system (GRU model) following your paper, my initial implementation generated pose which is very dynamic (arms move quickly in large scale in my upper body model; body turn around quickly in a crazy manner in my full-body model). I am guessing maybe it is because I have over-trained the model. So I started to look into your experiments detail in your paper (table below)

In my case, I am using uni-direction GRU with 2 layer and 512 hidden_size, my batch_size is 80 and num_batches is 80000, and in terms of # of epoches, it is 1213 epoches, but seems you only run 50 epoches, I am wondering what is the reason for you to only run 50 epoches for your LSTM baseline? How many batch-steps does "50 epoches" equal to in your case? Did you also experience over-train as I did if you run more epoches?
I will test your setting also (unidirection LSTM with 1 layer and 350 hidden size) and run less epoches (say 50) and let you know the result. But I am curious the logic of your setting. Appreciated.
Thanks!
Kelvin
What is the concrete version of python and cudnn that you did't give in the .yml ?
Could I train the model with only one rtx 2080Ti?
Really amazing job!!
thanks for the amazing work!
What GPU model and how many GPU did you use for your training? And how long did it take?
thanks for sharing!
A stupid question, I want to test the generated effect, where is the code of inference, and is there a pre-trained model?
Dear author,
thanks for your great contribution.
Do you have any idea for applying the output file(.bvh) to 3D model file(.3ds) ?
Thanks in advance.
OS: ubuntu 16.04
python: 3.7
pytorch: 1.6.0+cu101
CUDA: 10.1
got the error when calling on plot_animation to generate sample
the saved result in .npz format seems normal
please how to debug~
generate_sample writing:results/locomotion/log_20200804_1919/sampled_0_temp100_0k_0.mp4 Traceback (most recent call last): File "train_moglow.py", line 61, in <module> trainer.generate_sample(eps_std=temp, counter=i) File "/home/david/Documents/StyleGestures/glow/trainer.py", line 142, in generate_sample self.data.save_animation(control_all[:,:(n_timesteps-n_lookahead),:], sampled_all, os.path.join(self.log_dir, f'sampled_{counter}_temp{str(int(eps_std*100))}_{str(self.global_step//1000)}k')) File "/home/david/Documents/StyleGestures/motion/datasets/locomotion.py", line 124, in save_animation plot_animation(anim_clip[i,self.seqlen:,:], parents, filename_, fps=self.frame_rate, axis_scale=60) File "/home/david/Documents/StyleGestures/visualization/plot_animation.py", line 76, in plot_animation ani.save(filename, fps=fps, bitrate=13934) File "/home/david/virtualenv/py37/lib/python3.7/site-packages/matplotlib/animation.py", line 1120, in save anim._init_draw() # Clear the initial frame File "/home/david/virtualenv/py37/lib/python3.7/site-packages/matplotlib/animation.py", line 1695, in _init_draw self._draw_frame(next(self.new_frame_seq())) File "/home/david/virtualenv/py37/lib/python3.7/site-packages/matplotlib/animation.py", line 1718, in _draw_frame self._drawn_artists = self._func(framedata, *self._args) File "/home/david/Documents/StyleGestures/visualization/plot_animation.py", line 64, in animate [ joints[i,j,1], joints[i,parents[j],1]]) File "/home/david/virtualenv/py37/lib/python3.7/site-packages/mpl_toolkits/mplot3d/art3d.py", line 143, in set_3d_properties zs = np.broadcast_to(zs, xs.shape) AttributeError: 'list' object has no attribute 'shape'
Hi, thanks for your great work.
I tracked your latest update and faced some problems, maybe they were bugs or my mistake:
Hi, thank you for providing the code, it really helps a lot.
The problem(possible) lies here.
Line 110 in a759935
Since the coupling layer is applied to each time step, i.e., on input tensor of size (N, C, T), the Jacobian of this operation should be a partitioned matrix, which is a diagonal matrix of diag(s), where s is the scale matrix.
As a result, the determinant of the Jacobian shoule be det(s)^T, the log-det should be T*log(det(s)).
Thus, the first part of the code above thops.sum(torch.log(scale), dim=[1, 2]) should be timed with T.
The possible effect might be that the weight matrix for focasting hidden state of LSTM wouldn't well trained, since the amplitude of the loss on all timesteps was shrinked unexpectly.
Dear sir:
Im reading your code about the StyleGestures, i met a problem with the code in motion_data.py, I could not understand why need to swap the self.x and sefl.conds axes:
self.x = np.swapaxes(self.x, 1, 2)
self.cond = np.swapaxes(self.cond, 1, 2)
I thought that the shape of the x and cond is [batch, seqLength, features] before swap, why need to swap the seqLength and features?
as i know the LSTM`s default order is [seqLength, batch, features].
Could you explain more detail to me?
Hi, Thanks for your amazing job, it is really helpful to me.
I have a question about the distribution of the latent random variable Z.
In this work, Z ~N(0,1), how can i use other distributions like N(μ, σ)?
hello, when i run command python prepare_datasets.py , it's seem not work, cand not find sav file? so how to resolve it ? tks.
python prepare_datasets.py
['NaturalTalking_04.bvh', 'NaturalTalking_11.bvh', 'NaturalTalking_23.bvh', 'NaturalTalking_05.bvh', 'NaturalTalking_19.bvh', 'NaturalTalking_15.bvh', 'NaturalTalking_08.bvh', 'NaturalTalking_01.bvh', 'NaturalTalking_07.bvh', 'NaturalTalking_18.bvh', 'NaturalTalking_22.bvh', 'NaturalTalking_16.bvh', 'NaturalTalking_26.bvh', 'NaturalTalking_30.bvh', 'NaturalTalking_27.bvh', 'NaturalTalking_12.bvh', 'NaturalTalking_14.bvh', 'NaturalTalking_02.bvh', 'NaturalTalking_25.bvh', 'NaturalTalking_10.bvh', 'NaturalTalking_17.bvh', 'NaturalTalking_13.bvh', 'NaturalTalking_21.bvh']
Found speech features. skipping processing...
Found motion features. skipping processing...
Traceback (most recent call last):
File "prepare_datasets.py", line 215, in
copyfile(os.path.join(motion_path, 'data_pipe.sav'), os.path.join(processed_dir,f'data_pipe_{fps}fps.sav'))
File "/home/user/miniconda2/envs/py383/lib/python3.8/shutil.py", line 261, in copyfile
with open(src, 'rb') as fsrc, open(dst, 'wb') as fdst:
FileNotFoundError: [Errno 2] No such file or directory: '../data/trinity/processed/features_20fps/joint_rot/data_pipe.sav'
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.