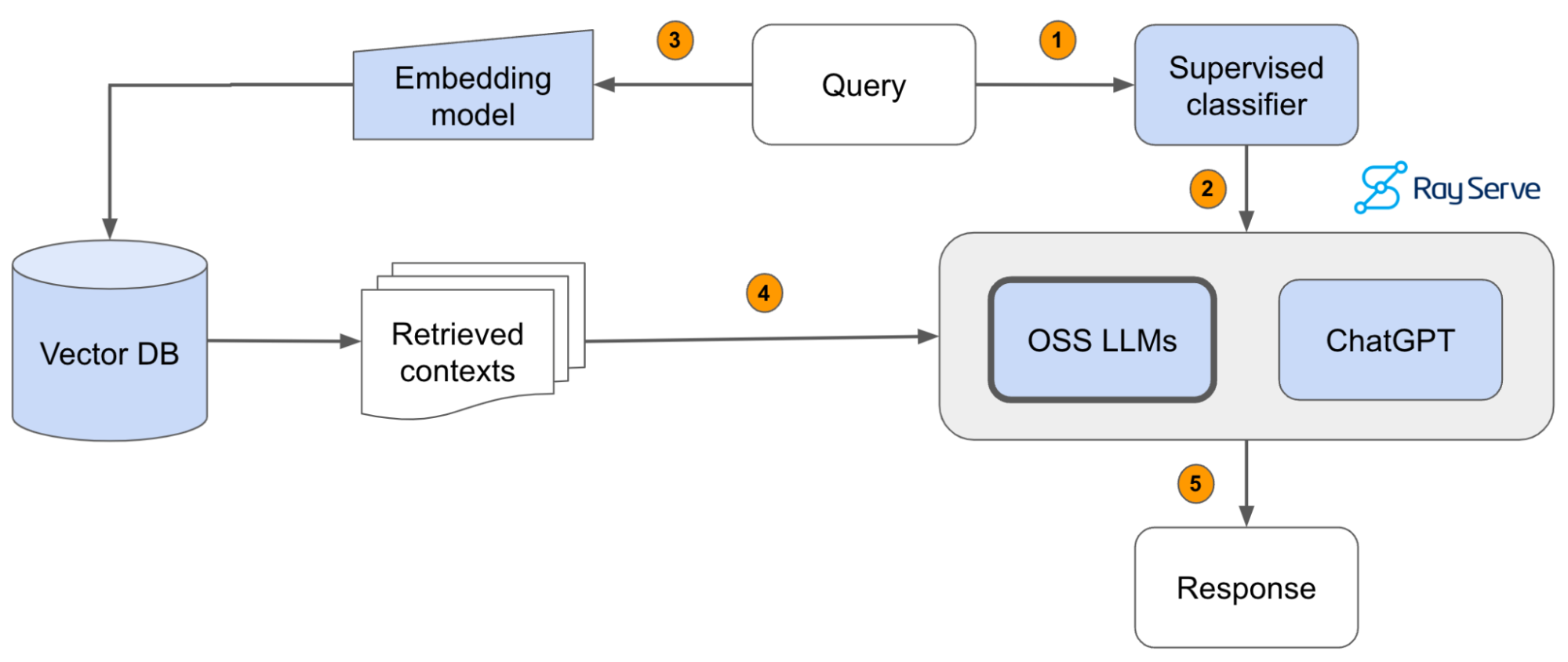
Got the error when I tried to embed chunks with openai embedding model. Made a tiny change in the code, which I embed sections instead of chunks as the section is small enough.
2024-01-09 16:14:42,335 INFO dataset.py:2383 -- Tip: Use `take_batch()` instead of `take() / show()` to return records in pandas or numpy batch format.
2024-01-09 16:14:42,339 INFO streaming_executor.py:104 -- Executing DAG InputDataBuffer[Input] -> TaskPoolMapOperator[FlatMap(extract_spec_from_patent)] -> ActorPoolMapOperator[MapBatches(EmbedChunks)] -> LimitOperator[limit=1]
2024-01-09 16:14:42,340 INFO streaming_executor.py:105 -- Execution config: ExecutionOptions(resource_limits=ExecutionResources(cpu=None, gpu=None, object_store_memory=None), locality_with_output=False, preserve_order=False, actor_locality_enabled=True, verbose_progress=False)
2024-01-09 16:14:42,340 INFO streaming_executor.py:107 -- Tip: For detailed progress reporting, run `ray.data.DataContext.get_current().execution_options.verbose_progress = True`
2024-01-09 16:14:42,358 INFO actor_pool_map_operator.py:114 -- MapBatches(EmbedChunks): Waiting for 1 pool actors to start...
2024-01-09 16:14:47,419 ERROR serialization.py:406 -- Failed to unpickle serialized exception
Traceback (most recent call last):
File "python\ray\_raylet.pyx", line 347, in ray._raylet.StreamingObjectRefGenerator._next_sync
File "python\ray\_raylet.pyx", line 4643, in ray._raylet.CoreWorker.try_read_next_object_ref_stream
File "python\ray\_raylet.pyx", line 447, in ray._raylet.check_status
ray.exceptions.ObjectRefStreamEndOfStreamError
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\data\_internal\execution\interfaces\physical_operator.py", line 80, in on_data_ready
meta = ray.get(next(self._streaming_gen))
^^^^^^^^^^^^^^^^^^^^^^^^^
File "python\ray\_raylet.pyx", line 302, in ray._raylet.StreamingObjectRefGenerator.__next__
File "python\ray\_raylet.pyx", line 365, in ray._raylet.StreamingObjectRefGenerator._next_sync
StopIteration
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\exceptions.py", line 46, in from_ray_exception
return pickle.loads(ray_exception.serialized_exception)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: APIStatusError.__init__() missing 2 required keyword-only arguments: 'response' and 'body'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\_private\serialization.py", line 404, in deserialize_objects
obj = self._deserialize_object(data, metadata, object_ref)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\_private\serialization.py", line 293, in _deserialize_object
return RayError.from_bytes(obj)
^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\exceptions.py", line 40, in from_bytes
return RayError.from_ray_exception(ray_exception)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\exceptions.py", line 49, in from_ray_exception
raise RuntimeError(msg) from e
RuntimeError: Failed to unpickle serialized exception
2024-01-09 16:14:47,444 WARNING actor_pool_map_operator.py:271 -- To ensure full parallelization across an actor pool of size 1, the Dataset should consist of at least 1 distinct blocks. Consider increasing the parallelism when creating the Dataset.
(MapWorker(MapBatches(EmbedChunks)) pid=11460) C:\arrow\cpp\src\arrow\filesystem\s3fs.cc:2904: arrow::fs::FinalizeS3 was not called even though S3 was initialized. This could lead to a segmentation fault at exit
---------------------------------------------------------------------------
ObjectRefStreamEndOfStreamError Traceback (most recent call last)
File python\ray\_raylet.pyx:347, in ray._raylet.StreamingObjectRefGenerator._next_sync()
File python\ray\_raylet.pyx:4643, in ray._raylet.CoreWorker.try_read_next_object_ref_stream()
File python\ray\_raylet.pyx:447, in ray._raylet.check_status()
ObjectRefStreamEndOfStreamError:
During handling of the above exception, another exception occurred:
StopIteration Traceback (most recent call last)
File D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\data\_internal\execution\interfaces\physical_operator.py:80, in DataOpTask.on_data_ready(self, max_blocks_to_read)
79 try:
---> 80 meta = ray.get(next(self._streaming_gen))
81 except StopIteration:
82 # The generator should always yield 2 values (block and metadata)
83 # each time. If we get a StopIteration here, it means an error
(...)
86 # TODO(hchen): Ray Core should have a better interface for
87 # detecting and obtaining the exception.
File python\ray\_raylet.pyx:302, in ray._raylet.StreamingObjectRefGenerator.__next__()
File python\ray\_raylet.pyx:365, in ray._raylet.StreamingObjectRefGenerator._next_sync()
StopIteration:
During handling of the above exception, another exception occurred:
RaySystemError Traceback (most recent call last)
Cell In[23], line 2
1 # Sample
----> 2 sample = embedded_chunks.take(1)
3 print ("embedding size:", len(sample[0]["embeddings"]))
4 print (sample[0]["text"])
File D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\data\dataset.py:2390, in Dataset.take(self, limit)
2387 output = []
2389 limited_ds = self.limit(limit)
-> 2390 for row in limited_ds.iter_rows():
2391 output.append(row)
2392 if len(output) >= limit:
File D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\data\iterator.py:219, in DataIterator.iter_rows.<locals>._wrapped_iterator()
218 def _wrapped_iterator():
--> 219 for batch in batch_iterable:
220 batch = BlockAccessor.for_block(BlockAccessor.batch_to_block(batch))
221 for row in batch.iter_rows(public_row_format=True):
File D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\data\iterator.py:164, in DataIterator.iter_batches.<locals>._create_iterator()
159 time_start = time.perf_counter()
160 # Iterate through the dataset from the start each time
161 # _iterator_gen is called.
162 # This allows multiple iterations of the dataset without
163 # needing to explicitly call `iter_batches()` multiple times.
--> 164 block_iterator, stats, blocks_owned_by_consumer = self._to_block_iterator()
166 iterator = iter(
167 iter_batches(
168 block_iterator,
(...)
179 )
180 )
182 for batch in iterator:
File D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\data\_internal\iterator\iterator_impl.py:32, in DataIteratorImpl._to_block_iterator(self)
24 def _to_block_iterator(
25 self,
26 ) -> Tuple[
(...)
29 bool,
30 ]:
31 ds = self._base_dataset
---> 32 block_iterator, stats, executor = ds._plan.execute_to_iterator()
33 ds._current_executor = executor
34 return block_iterator, stats, False
File D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\data\_internal\plan.py:548, in ExecutionPlan.execute_to_iterator(self, allow_clear_input_blocks, force_read)
546 gen = iter(block_iter)
547 try:
--> 548 block_iter = itertools.chain([next(gen)], gen)
549 except StopIteration:
550 pass
File D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\data\_internal\execution\legacy_compat.py:54, in execute_to_legacy_block_iterator(executor, plan, allow_clear_input_blocks, dataset_uuid)
50 """Same as execute_to_legacy_bundle_iterator but returning blocks and metadata."""
51 bundle_iter = execute_to_legacy_bundle_iterator(
52 executor, plan, allow_clear_input_blocks, dataset_uuid
53 )
---> 54 for bundle in bundle_iter:
55 for block, metadata in bundle.blocks:
56 yield block, metadata
File D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\data\_internal\execution\interfaces\executor.py:37, in OutputIterator.__next__(self)
36 def __next__(self) -> RefBundle:
---> 37 return self.get_next()
File D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\data\_internal\execution\streaming_executor.py:141, in StreamingExecutor.execute.<locals>.StreamIterator.get_next(self, output_split_idx)
139 raise StopIteration
140 elif isinstance(item, Exception):
--> 141 raise item
142 else:
143 # Otherwise return a concrete RefBundle.
144 if self._outer._global_info:
File D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\data\_internal\execution\streaming_executor.py:201, in StreamingExecutor.run(self)
195 """Run the control loop in a helper thread.
196
197 Results are returned via the output node's outqueue.
198 """
199 try:
200 # Run scheduling loop until complete.
--> 201 while self._scheduling_loop_step(self._topology) and not self._shutdown:
202 pass
203 except Exception as e:
204 # Propagate it to the result iterator.
File D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\data\_internal\execution\streaming_executor.py:252, in StreamingExecutor._scheduling_loop_step(self, topology)
247 logger.get_logger().info("Scheduling loop step...")
249 # Note: calling process_completed_tasks() is expensive since it incurs
250 # ray.wait() overhead, so make sure to allow multiple dispatch per call for
251 # greater parallelism.
--> 252 process_completed_tasks(topology, self._backpressure_policies)
254 # Dispatch as many operators as we can for completed tasks.
255 limits = self._get_or_refresh_resource_limits()
File D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\data\_internal\execution\streaming_executor_state.py:365, in process_completed_tasks(topology, backpressure_policies)
363 state, task = active_tasks.pop(ref)
364 if isinstance(task, DataOpTask):
--> 365 num_blocks_read = task.on_data_ready(
366 max_blocks_to_read_per_op.get(state, None)
367 )
368 if state in max_blocks_to_read_per_op:
369 max_blocks_to_read_per_op[state] -= num_blocks_read
File D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\data\_internal\execution\interfaces\physical_operator.py:88, in DataOpTask.on_data_ready(self, max_blocks_to_read)
80 meta = ray.get(next(self._streaming_gen))
81 except StopIteration:
82 # The generator should always yield 2 values (block and metadata)
83 # each time. If we get a StopIteration here, it means an error
(...)
86 # TODO(hchen): Ray Core should have a better interface for
87 # detecting and obtaining the exception.
---> 88 ex = ray.get(block_ref)
89 self._task_done_callback()
90 raise ex
File D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\_private\auto_init_hook.py:24, in wrap_auto_init.<locals>.auto_init_wrapper(*args, **kwargs)
21 @wraps(fn)
22 def auto_init_wrapper(*args, **kwargs):
23 auto_init_ray()
---> 24 return fn(*args, **kwargs)
File D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\_private\client_mode_hook.py:103, in client_mode_hook.<locals>.wrapper(*args, **kwargs)
101 if func.__name__ != "init" or is_client_mode_enabled_by_default:
102 return getattr(ray, func.__name__)(*args, **kwargs)
--> 103 return func(*args, **kwargs)
File D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\_private\worker.py:2565, in get(object_refs, timeout)
2563 raise value.as_instanceof_cause()
2564 else:
-> 2565 raise value
2567 if is_individual_id:
2568 values = values[0]
RaySystemError: System error: Failed to unpickle serialized exception
traceback: Traceback (most recent call last):
File "python\ray\_raylet.pyx", line 347, in ray._raylet.StreamingObjectRefGenerator._next_sync
File "python\ray\_raylet.pyx", line 4643, in ray._raylet.CoreWorker.try_read_next_object_ref_stream
File "python\ray\_raylet.pyx", line 447, in ray._raylet.check_status
ray.exceptions.ObjectRefStreamEndOfStreamError
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\data\_internal\execution\interfaces\physical_operator.py", line 80, in on_data_ready
meta = ray.get(next(self._streaming_gen))
^^^^^^^^^^^^^^^^^^^^^^^^^
File "python\ray\_raylet.pyx", line 302, in ray._raylet.StreamingObjectRefGenerator.__next__
File "python\ray\_raylet.pyx", line 365, in ray._raylet.StreamingObjectRefGenerator._next_sync
StopIteration
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\exceptions.py", line 46, in from_ray_exception
return pickle.loads(ray_exception.serialized_exception)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: APIStatusError.__init__() missing 2 required keyword-only arguments: 'response' and 'body'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\_private\serialization.py", line 404, in deserialize_objects
obj = self._deserialize_object(data, metadata, object_ref)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\_private\serialization.py", line 293, in _deserialize_object
return RayError.from_bytes(obj)
^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\exceptions.py", line 40, in from_bytes
return RayError.from_ray_exception(ray_exception)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\exceptions.py", line 49, in from_ray_exception
raise RuntimeError(msg) from e
RuntimeError: Failed to unpickle serialized exception
2024-01-09 16:14:52,924 ERROR serialization.py:406 -- Failed to unpickle serialized exception
Traceback (most recent call last):
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\exceptions.py", line 46, in from_ray_exception
return pickle.loads(ray_exception.serialized_exception)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: APIStatusError.__init__() missing 2 required keyword-only arguments: 'response' and 'body'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\_private\serialization.py", line 404, in deserialize_objects
obj = self._deserialize_object(data, metadata, object_ref)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\_private\serialization.py", line 293, in _deserialize_object
return RayError.from_bytes(obj)
^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\exceptions.py", line 40, in from_bytes
return RayError.from_ray_exception(ray_exception)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\exceptions.py", line 49, in from_ray_exception
raise RuntimeError(msg) from e
RuntimeError: Failed to unpickle serialized exception
2024-01-09 16:14:52,924 ERROR worker.py:406 -- Unhandled error (suppress with 'RAY_IGNORE_UNHANDLED_ERRORS=1'): System error: Failed to unpickle serialized exception
traceback: Traceback (most recent call last):
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\exceptions.py", line 46, in from_ray_exception
return pickle.loads(ray_exception.serialized_exception)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: APIStatusError.__init__() missing 2 required keyword-only arguments: 'response' and 'body'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\_private\serialization.py", line 404, in deserialize_objects
obj = self._deserialize_object(data, metadata, object_ref)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\_private\serialization.py", line 293, in _deserialize_object
return RayError.from_bytes(obj)
^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\exceptions.py", line 40, in from_bytes
return RayError.from_ray_exception(ray_exception)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\exceptions.py", line 49, in from_ray_exception
raise RuntimeError(msg) from e
RuntimeError: Failed to unpickle serialized exception
2024-01-09 16:14:52,924 ERROR serialization.py:406 -- Failed to unpickle serialized exception
Traceback (most recent call last):
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\exceptions.py", line 46, in from_ray_exception
return pickle.loads(ray_exception.serialized_exception)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: APIStatusError.__init__() missing 2 required keyword-only arguments: 'response' and 'body'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\_private\serialization.py", line 404, in deserialize_objects
obj = self._deserialize_object(data, metadata, object_ref)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\_private\serialization.py", line 293, in _deserialize_object
return RayError.from_bytes(obj)
^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\exceptions.py", line 40, in from_bytes
return RayError.from_ray_exception(ray_exception)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\exceptions.py", line 49, in from_ray_exception
raise RuntimeError(msg) from e
RuntimeError: Failed to unpickle serialized exception
2024-01-09 16:14:52,931 ERROR worker.py:406 -- Unhandled error (suppress with 'RAY_IGNORE_UNHANDLED_ERRORS=1'): System error: Failed to unpickle serialized exception
traceback: Traceback (most recent call last):
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\exceptions.py", line 46, in from_ray_exception
return pickle.loads(ray_exception.serialized_exception)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: APIStatusError.__init__() missing 2 required keyword-only arguments: 'response' and 'body'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\_private\serialization.py", line 404, in deserialize_objects
obj = self._deserialize_object(data, metadata, object_ref)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\_private\serialization.py", line 293, in _deserialize_object
return RayError.from_bytes(obj)
^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\exceptions.py", line 40, in from_bytes
return RayError.from_ray_exception(ray_exception)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\exceptions.py", line 49, in from_ray_exception
raise RuntimeError(msg) from e
RuntimeError: Failed to unpickle serialized exception
2024-01-09 16:14:52,932 ERROR serialization.py:406 -- Failed to unpickle serialized exception
Traceback (most recent call last):
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\exceptions.py", line 46, in from_ray_exception
return pickle.loads(ray_exception.serialized_exception)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: APIStatusError.__init__() missing 2 required keyword-only arguments: 'response' and 'body'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\_private\serialization.py", line 404, in deserialize_objects
obj = self._deserialize_object(data, metadata, object_ref)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\_private\serialization.py", line 293, in _deserialize_object
return RayError.from_bytes(obj)
^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\exceptions.py", line 40, in from_bytes
return RayError.from_ray_exception(ray_exception)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\exceptions.py", line 49, in from_ray_exception
raise RuntimeError(msg) from e
RuntimeError: Failed to unpickle serialized exception
2024-01-09 16:14:52,936 ERROR worker.py:406 -- Unhandled error (suppress with 'RAY_IGNORE_UNHANDLED_ERRORS=1'): System error: Failed to unpickle serialized exception
traceback: Traceback (most recent call last):
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\exceptions.py", line 46, in from_ray_exception
return pickle.loads(ray_exception.serialized_exception)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: APIStatusError.__init__() missing 2 required keyword-only arguments: 'response' and 'body'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\_private\serialization.py", line 404, in deserialize_objects
obj = self._deserialize_object(data, metadata, object_ref)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\_private\serialization.py", line 293, in _deserialize_object
return RayError.from_bytes(obj)
^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\exceptions.py", line 40, in from_bytes
return RayError.from_ray_exception(ray_exception)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\Users\JIA\miniconda3\envs\patrag\Lib\site-packages\ray\exceptions.py", line 49, in from_ray_exception
raise RuntimeError(msg) from e
RuntimeError: Failed to unpickle serialized exception