
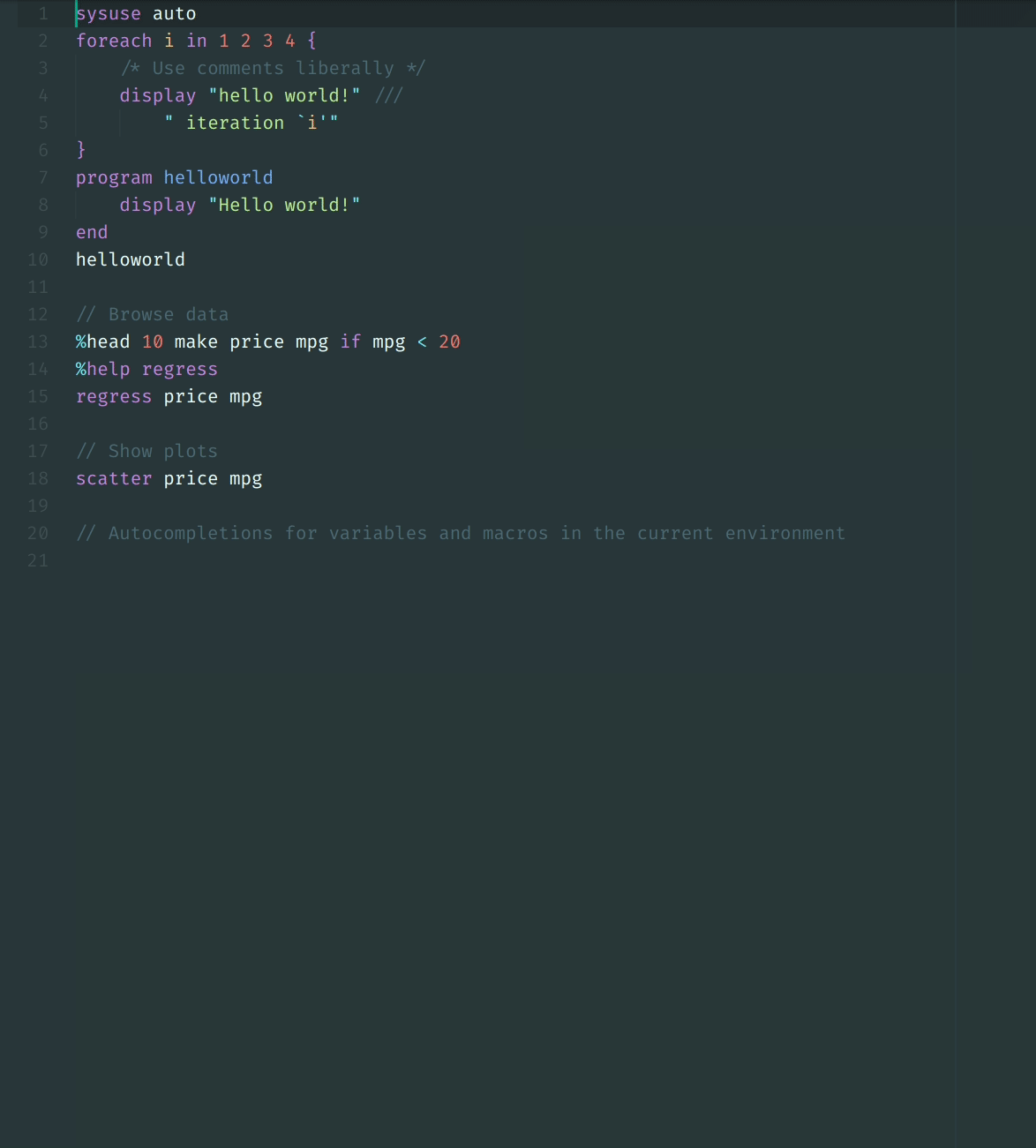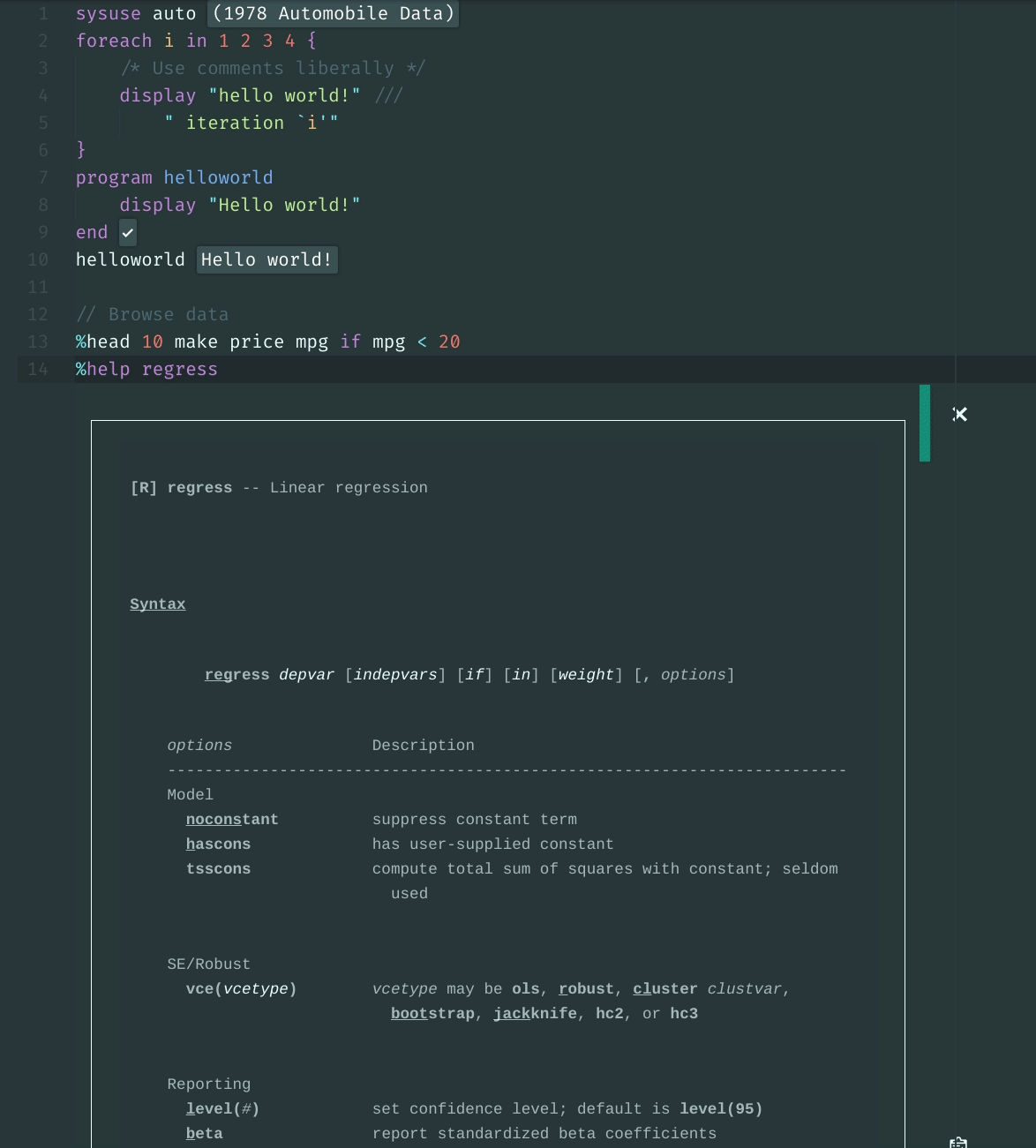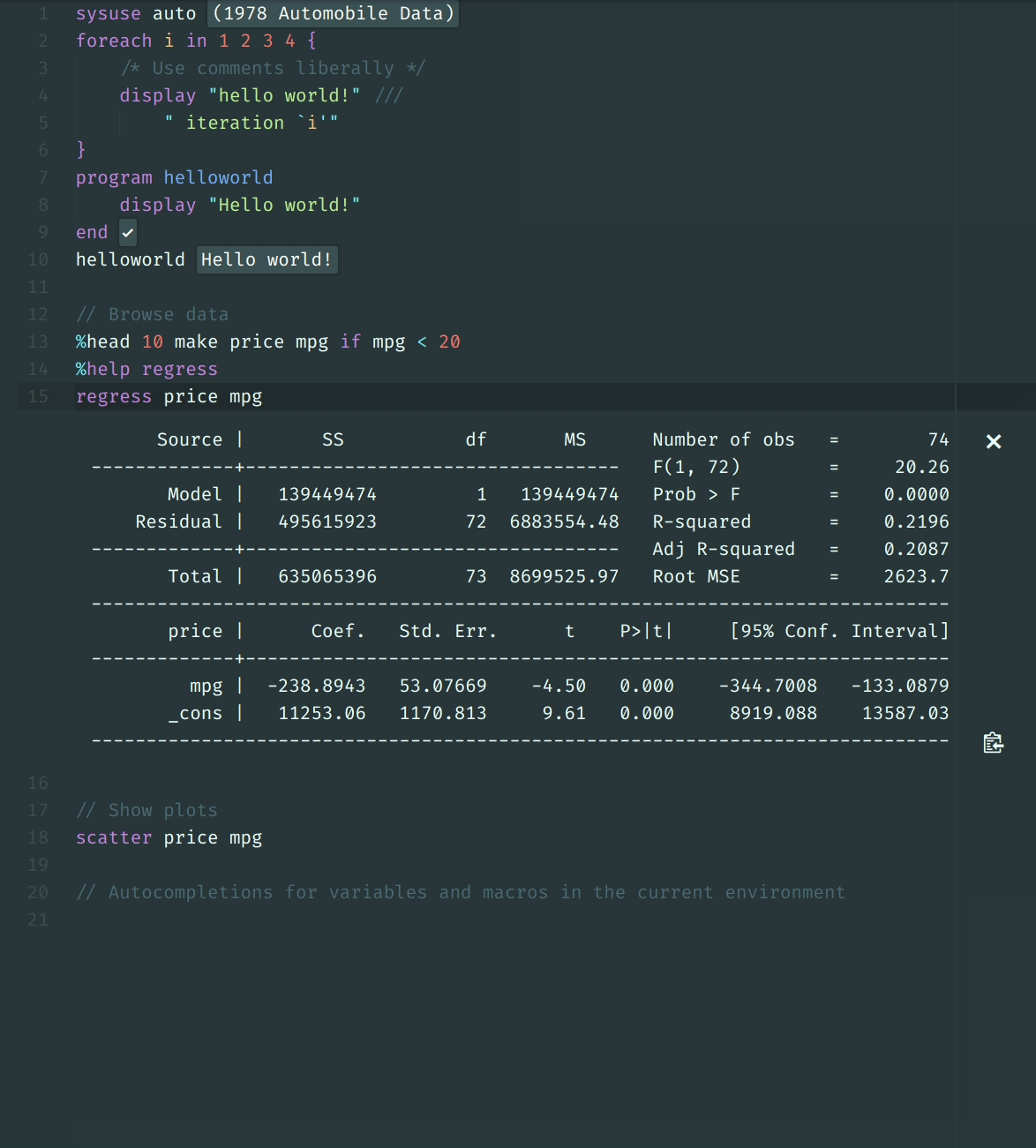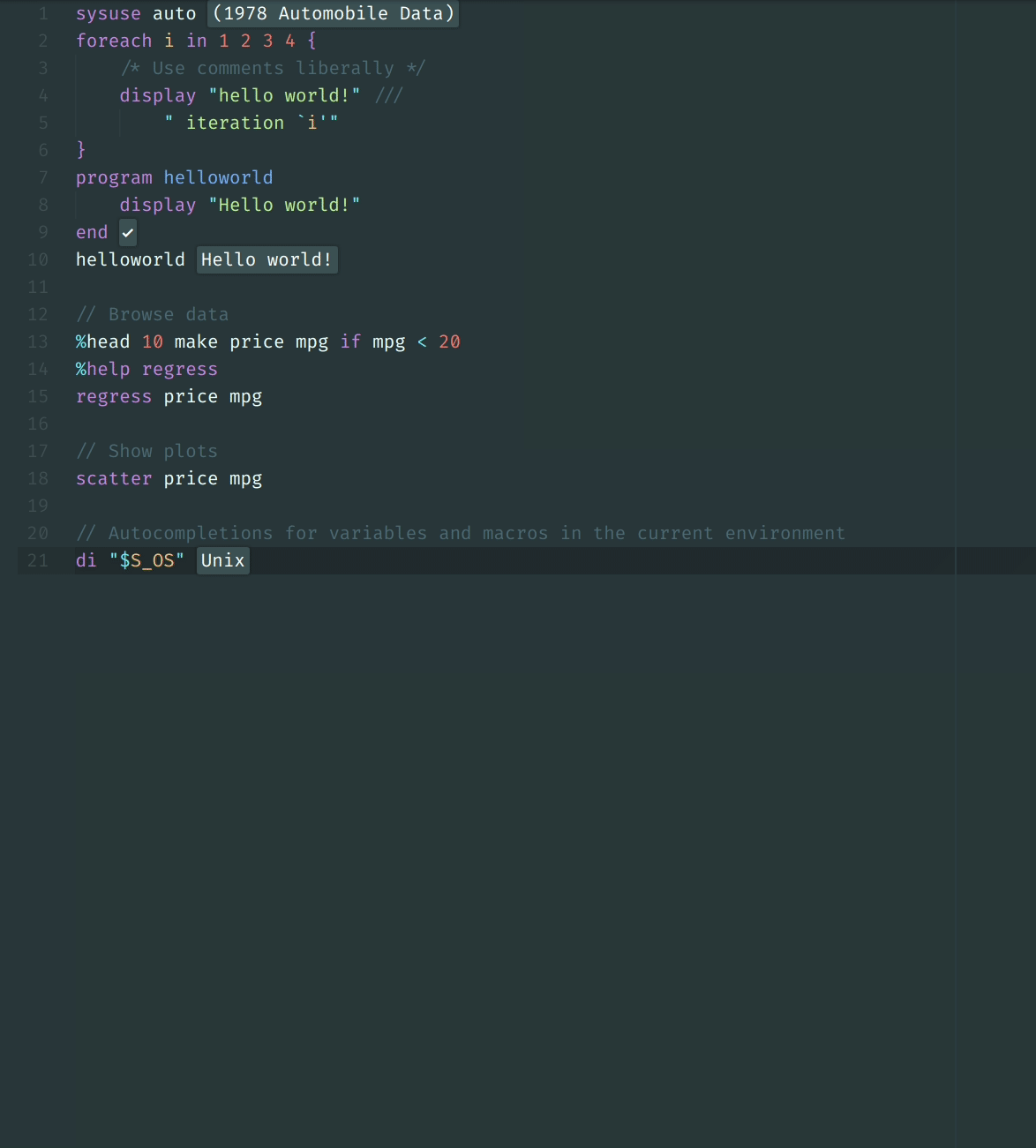
stata_kernel is a Jupyter kernel for Stata; It works on Windows, macOS, and
Linux.
To see an example Jupyter Notebook, click here.
For documentation and more information, see: https://kylebarron.dev/stata_kernel
A Jupyter kernel for Stata. Works with Windows, macOS, and Linux.
Home Page: https://kylebarron.dev/stata_kernel/
License: GNU General Public License v3.0
stata_kernel is a Jupyter kernel for Stata; It works on Windows, macOS, and
Linux.
To see an example Jupyter Notebook, click here.
For documentation and more information, see: https://kylebarron.dev/stata_kernel


![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")


























































































































This file should have a class that accepts an unmodified input string and returns a list of run-able code blocks. In general each item of the list should be a single line of Stata code, except when that line of Stata code would not return to a dot prompt.
class CodeManager(object):
def __init__(self, code):
self.input = code
self.tokens = self.tokenize_code()
def tokenize_code(self):
# Do tokenizing with Pygments
# Return a list of tokens
def is_complete(self):
# Analyze tokens
# Determine if all of input is complete.
# Return simple True/False
def completions(self, cursor_pos):
# Unclear whether it's necessary to tokenize the code for this.
# Return dict with correct Jupyter message
def tokens_to_lines():
# Form logical code chunks from tokens
# This should also remove comments
# Returns a list of code chunks that are safe to run in the consoleBasically have two sections of the lexer. One for ; and one for cr
The do_is_complete function prevents the Jupyter kernel from sending input until there's a valid, complete chunk of code. But when Atom sends code, there's no way to probe for more user input, so the selection goes directly to do_execute. Because of this, I can't assume that the code sent to do_execute is necessarily complete, and I need to check.
Can I import some from IPython directly? Like %time?


. .

The specific issue here is that strings are tokenized differently than text. With my current code joining method, I was thinking there would be two different Token types, Token.Text and Token.MatchingBracket.Other, where the latter is a contiguous set of tokens that comprise a block (and which thus must be sent all at once).
Obviously I forgot that I had also defined the token type Token.Literal.String. Since this is a different name than the earlier two token types, the loop parsed it into a different line.
I need to leave the string token type so that it catches comments, and also within blocks:

This is the part where it's superbly annoying that there isn't a way with Pygments to show the entire token stack. It only shows the topmost token, so I can't see (I don't think) that above the Token.Literal.String.Double is inside a Token.MatchingBracket.Other.
I think the main way to solve this is to set the token name for strings that occur within a block to Token.MatchingBracket.Other
With the current expect regex, some commands, notably shell fail. This is because there are some escape codes that are caught in the output, and so there isn't a \r\n\r\n ..
With the expect regex being \r\n ., I see:

Mkdocs 1.0!
Add a note to readme about di _n(2) ". " messing it up. Think if there's a way to get pexpect to sync up. Maybe keep looking for \r\n\. with a .5 sec timeout and return when you get one or two timeouts in a row.
When I type exit, it seems pexpect is waiting for some response when there will never be one
From program or program define until end, there should be line continuations

disp "Sup?", _request(what_is_up)
pause on
program foo
pause
disp "bar"
end
foo
`local'
$globalEach of the 4 examples above messes up the kernel because the prompt changes.
Name: stata-kernel
Version: 1.1.0
Summary: A Jupyter kernel for Stata. Works with Windows, macOS, and Linux. Preserves program state.
Home-page: https://github.com/kylebarron/stata_kernel
Author: Kyle Barron
Author-email: [email protected]
License: GPLv3
Location: /usr/lib/python3.6/site-packages
Requires: jupyter-client, IPython, ipykernel, python-dateutil, pexpect
Required-by:
Helpful example from here
https://ipython-books.github.io/16-creating-a-simple-kernel-for-jupyter/
If I have a local in my environment named x and set to 5, and I send
x
to Stata,
which program then by matching against program dir.di `local'. Might also do this for r-class or e-class?Note: Add check_env flag to run function so that I only check environment when needed.
Make sure this is an option in the configuration file
First of all, awesome work! I will try this kernel out on my Linux workstation soon and let you know if I run into any issues.
I have been doing a little bit of research into Windows support but it seems that the Windows version does not have an interactive console mode (only the full GUI version or the console batch mode). It does appear that it is possible to install Stata without GUI, but I have not been able to get this to work yet (e.g. https://www.stata.com/support/faqs/windows/install-from-command-line/).
Another option would be to include Stata Automation integration for Windows users (like I did with ipystata). I can probably add this for you once I get back from holiday in a couple of weeks.
I will also definitely consider adding similar Linux (and MacOS) functionality into ipystata, by the looks of it this approach using pexpect seems to work nicely.
# Your code here[this should explain why the current behaviour is a problem and why the expected output is a better solution.]
Note: Many problems can be resolved by simply upgrading medicare_utils to the latest version. Before submitting, please check if that solution works for you.
Change python code to stata
I suspect that the nomsg parameter was added with the most recent version Stata (i.e. 15).
When trying to execute code using Stata 14 I get an error:

stata_kernel/stata_kernel/kernel.py
Line 297 in 2d408bc
At least windows, test Mac

# Your code here[this should explain why the current behaviour is a problem and why the expected output is a better solution.]
Note: Many problems can be resolved by simply upgrading medicare_utils to the latest version. Before submitting, please check if that solution works for you.
See #22.
If I use just \r\n\. as the regex, if I run di ". text", pexpect gets confused because it's looking for the next linesep + dot + space as the prompt, but the first one it finds is the result, and not the next line prompt. I believe all prompts have a full empty line before them, so I made \r\n\r\n\. the regex to find the dot prompt, but this failed on Linux on my machine whenever it did a shell command. !ls would have the \x1b ANSI escape code returned from the shell, and wouldn't match the double linesep. The lookbehind instead of just matching them leaves an extra newline between results. Otherwise the next row of [2]: would be right up against [1]:
No, exit doesn't work. This is because pexpect is waiting for a response from the spawned Stata console, but that has already closed. I need to figure out how to fix this. See #7
I plan to refactor the code a good amount. I'd say the code is relatively clean for having written it quickly, but I want to step back a minute and try to think through an optimal structure for the package. I'm thinking of moving all the code that deals with validating input into a code_manager.py file (see #32 for initial thoughts). Hopefully that will parse input and not send code to Stata unless it's sure that it can be run safely (once I turn off the timeout option, things will run forever if invalid input is sent to the console). Ideally this would also use tokens for autocompletions, though I'll probably put that into a separate file.
Then a separate run.py file for sending the validated code to Stata and retrieving output. I'm happy to have devised a function that allows me to abstract the differences between sending code with Windows Automation vs Mac Applescript. But there's still differences on each platform with retrieving output. There are some issues with retrieving graphs, especially, and apparently Stata 14 doesn't export SVG?

Is your feature request related to a problem? Please describe.
Keyboard interrupts (Ctrl+C) should be supported whenever possible. In the console version of Stata this is akin to hitting the "break" button. This is generally useful but would also help with a common mistake (that at least I make): Sometimes I put a command that would have Stata printing stuff to the console for several minutes, and Ctrl+C is very helpful to break that.
Describe the solution you'd like
The following works for me in run_shell but I haven't tested it too thoroughly.
for line in lines:
try:
self.child.sendline(line)
self.child.expect('(?<=(\r\n)|(\x1b=))\r\n\. ', timeout=20)
except KeyboardInterrupt:
self.child.send('\003')
self.child.expect('(?<=(\r\n)|(\x1b=))\r\n\. ', timeout=20)Describe alternatives you've considered
N/A
Additional context
N/A
@mcaceresb You made a simple Stata benchmarking script didn't you?

A current issue is that log files from DoCommandAsync might have different starting positions based on whether the previous command was a DoCommand or a DoCommandAsync. Consider always running a DoCommandAsync with di "flush log" first.
It might be worth mentioning that in the mean time (since our last chat about it at the end of 2017) I have managed to get my (admittedly hacky) Stata syntax highlighting working again in the Jupyter Notebook.
The codemirror file is here: https://github.com/TiesdeKok/ipystata/blob/49acff7e13716d7baa7cf43be1b6b7c6cef9fc0c/ipystata/stata.js
I linked it to the %%stata magic but I am sure you can also just apply to an entire kernel.
See these lines of code (link):
if config.enable_syntax_highlight:
# Enable the stata syntax highlighting:
#js = "IPython.CodeCell.config_defaults.highlight_modes['magic_stata'] = {'reg':[/^%%stata/]};"
js = """require(['notebook/js/codecell'], function(codecell) {
codecell.CodeCell.options_default.highlight_modes['magic_stata'] = {'reg':[/^%%stata/]} ;
Jupyter.notebook.events.one('kernel_ready.Kernel', function(){
Jupyter.notebook.get_cells().map(function(cell){
if (cell.cell_type == 'code'){ cell.auto_highlight(); } }) ;
});
});"""
display.display_javascript(js, raw=True)
In IPython, there's
%config InlineBackend.figure_format = 'svg'
Make something similar for Stata. I.e.
%config figure_format = 'svg'
This should have the same options that are available in the global configuration file. This should set also set platform-specific defaults during the install script.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.