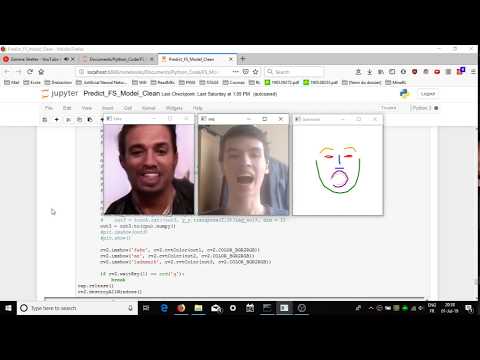
Seems like a mismatch between the pretrained model and the network architecture provided . Can u please check ?
Traceback (most recent call last):
File "/home/vishnu/Realistic-Neural-Talking-Head-Models/video_inference.py", line 35, in
G.load_state_dict(checkpoint['G_state_dict'])
File "/home/vishnu/miniconda3/envs/neural-talk/lib/python3.7/site-packages/torch/nn/modules/module.py", line 845, in load_state_dict
self.class.name, "\n\t".join(error_msgs)))
RuntimeError: Error(s) in loading state_dict for Generator:
Missing key(s) in state_dict: "conv2d.weight", "conv2d.bias".
Unexpected key(s) in state_dict: "resDown5.conv_l1.bias", "resDown5.conv_l1.weight_orig", "resDown5.conv_l1.weight_u", "resDown5.conv_l1.weight_v", "resDown5.conv_r1.bias", "resDown5.conv_r1.weight_orig", "resDown5.conv_r1.weight_u", "resDown5.conv_r1.weight_v", "resDown5.conv_r2.bias", "resDown5.conv_r2.weight_orig", "resDown5.conv_r2.weight_u", "resDown5.conv_r2.weight_v", "in5.weight", "in5.bias", "resDown6.conv_l1.bias", "resDown6.conv_l1.weight_orig", "resDown6.conv_l1.weight_u", "resDown6.conv_l1.weight_v", "resDown6.conv_r1.bias", "resDown6.conv_r1.weight_orig", "resDown6.conv_r1.weight_u", "resDown6.conv_r1.weight_v", "resDown6.conv_r2.bias", "resDown6.conv_r2.weight_orig", "resDown6.conv_r2.weight_u", "resDown6.conv_r2.weight_v", "in6.weight", "in6.bias", "resUp5.conv_l1.bias", "resUp5.conv_l1.weight_orig", "resUp5.conv_l1.weight_u", "resUp5.conv_l1.weight_v", "resUp5.conv_r1.bias", "resUp5.conv_r1.weight_orig", "resUp5.conv_r1.weight_u", "resUp5.conv_r1.weight_v", "resUp5.conv_r2.bias", "resUp5.conv_r2.weight_orig", "resUp5.conv_r2.weight_u", "resUp5.conv_r2.weight_v", "resUp6.conv_l1.bias", "resUp6.conv_l1.weight_orig", "resUp6.conv_l1.weight_u", "resUp6.conv_l1.weight_v", "resUp6.conv_r1.bias", "resUp6.conv_r1.weight_orig", "resUp6.conv_r1.weight_u", "resUp6.conv_r1.weight_v", "resUp6.conv_r2.bias", "resUp6.conv_r2.weight_orig", "resUp6.conv_r2.weight_u", "resUp6.conv_r2.weight_v".
size mismatch for p: copying a param with shape torch.Size([17158, 512]) from checkpoint, the shape in current model is torch.Size([13184, 512]).
size mismatch for psi: copying a param with shape torch.Size([17158, 1]) from checkpoint, the shape in current model is torch.Size([13184, 1]).
size mismatch for resUp1.conv_l1.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for resUp1.conv_l1.weight_orig: copying a param with shape torch.Size([512, 512, 1, 1]) from checkpoint, the shape in current model is torch.Size([256, 512, 1, 1]).
size mismatch for resUp1.conv_l1.weight_u: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for resUp1.conv_r1.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for resUp1.conv_r1.weight_orig: copying a param with shape torch.Size([512, 512, 3, 3]) from checkpoint, the shape in current model is torch.Size([256, 512, 3, 3]).
size mismatch for resUp1.conv_r1.weight_u: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for resUp1.conv_r2.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for resUp1.conv_r2.weight_orig: copying a param with shape torch.Size([512, 512, 3, 3]) from checkpoint, the shape in current model is torch.Size([256, 256, 3, 3]).
size mismatch for resUp1.conv_r2.weight_u: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for resUp1.conv_r2.weight_v: copying a param with shape torch.Size([4608]) from checkpoint, the shape in current model is torch.Size([2304]).
size mismatch for resUp2.conv_l1.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([128]).
size mismatch for resUp2.conv_l1.weight_orig: copying a param with shape torch.Size([512, 512, 1, 1]) from checkpoint, the shape in current model is torch.Size([128, 256, 1, 1]).
size mismatch for resUp2.conv_l1.weight_u: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([128]).
size mismatch for resUp2.conv_l1.weight_v: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for resUp2.conv_r1.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([128]).
size mismatch for resUp2.conv_r1.weight_orig: copying a param with shape torch.Size([512, 512, 3, 3]) from checkpoint, the shape in current model is torch.Size([128, 256, 3, 3]).
size mismatch for resUp2.conv_r1.weight_u: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([128]).
size mismatch for resUp2.conv_r1.weight_v: copying a param with shape torch.Size([4608]) from checkpoint, the shape in current model is torch.Size([2304]).
size mismatch for resUp2.conv_r2.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([128]).
size mismatch for resUp2.conv_r2.weight_orig: copying a param with shape torch.Size([512, 512, 3, 3]) from checkpoint, the shape in current model is torch.Size([128, 128, 3, 3]).
size mismatch for resUp2.conv_r2.weight_u: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([128]).
size mismatch for resUp2.conv_r2.weight_v: copying a param with shape torch.Size([4608]) from checkpoint, the shape in current model is torch.Size([1152]).
size mismatch for resUp3.conv_l1.bias: copying a param with shape torch.Size([256]) from checkpoint, the shape in current model is torch.Size([64]).
size mismatch for resUp3.conv_l1.weight_orig: copying a param with shape torch.Size([256, 512, 1, 1]) from checkpoint, the shape in current model is torch.Size([64, 128, 1, 1]).
size mismatch for resUp3.conv_l1.weight_u: copying a param with shape torch.Size([256]) from checkpoint, the shape in current model is torch.Size([64]).
size mismatch for resUp3.conv_l1.weight_v: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([128]).
size mismatch for resUp3.conv_r1.bias: copying a param with shape torch.Size([256]) from checkpoint, the shape in current model is torch.Size([64]).
size mismatch for resUp3.conv_r1.weight_orig: copying a param with shape torch.Size([256, 512, 3, 3]) from checkpoint, the shape in current model is torch.Size([64, 128, 3, 3]).
size mismatch for resUp3.conv_r1.weight_u: copying a param with shape torch.Size([256]) from checkpoint, the shape in current model is torch.Size([64]).
size mismatch for resUp3.conv_r1.weight_v: copying a param with shape torch.Size([4608]) from checkpoint, the shape in current model is torch.Size([1152]).
size mismatch for resUp3.conv_r2.bias: copying a param with shape torch.Size([256]) from checkpoint, the shape in current model is torch.Size([64]).
size mismatch for resUp3.conv_r2.weight_orig: copying a param with shape torch.Size([256, 256, 3, 3]) from checkpoint, the shape in current model is torch.Size([64, 64, 3, 3]).
size mismatch for resUp3.conv_r2.weight_u: copying a param with shape torch.Size([256]) from checkpoint, the shape in current model is torch.Size([64]).
size mismatch for resUp3.conv_r2.weight_v: copying a param with shape torch.Size([2304]) from checkpoint, the shape in current model is torch.Size([576]).
size mismatch for resUp4.conv_l1.bias: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([32]).
size mismatch for resUp4.conv_l1.weight_orig: copying a param with shape torch.Size([128, 256, 1, 1]) from checkpoint, the shape in current model is torch.Size([32, 64, 1, 1]).
size mismatch for resUp4.conv_l1.weight_u: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([32]).
size mismatch for resUp4.conv_l1.weight_v: copying a param with shape torch.Size([256]) from checkpoint, the shape in current model is torch.Size([64]).
size mismatch for resUp4.conv_r1.bias: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([32]).
size mismatch for resUp4.conv_r1.weight_orig: copying a param with shape torch.Size([128, 256, 3, 3]) from checkpoint, the shape in current model is torch.Size([32, 64, 3, 3]).
size mismatch for resUp4.conv_r1.weight_u: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([32]).
size mismatch for resUp4.conv_r1.weight_v: copying a param with shape torch.Size([2304]) from checkpoint, the shape in current model is torch.Size([576]).
size mismatch for resUp4.conv_r2.bias: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([32]).
size mismatch for resUp4.conv_r2.weight_orig: copying a param with shape torch.Size([128, 128, 3, 3]) from checkpoint, the shape in current model is torch.Size([32, 32, 3, 3]).
size mismatch for resUp4.conv_r2.weight_u: copying a param with shape torch.Size([128]) from checkpoint, the shape in current model is torch.Size([32]).
size mismatch for resUp4.conv_r2.weight_v: copying a param with shape torch.Size([1152]) from checkpoint, the shape in current model is torch.Size([288]).