trivadis / plsql-formatter-settings Goto Github PK
View Code? Open in Web Editor NEWPL/SQL & SQL formatter settings based on the Trivadis PL/SQL & SQL Coding Guidelines
License: Apache License 2.0
PL/SQL & SQL formatter settings based on the Trivadis PL/SQL & SQL Coding Guidelines
License: Apache License 2.0
![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")















































































































Passing "default" will load the default Arbori program.
BEGIN
return;
END;
/
I think return is a keyword and should be uppercased.
Tests currently use library form SQL Developer and SQLcl. Simplify it to use libraries from SQLcl only. Update README accordingly. Rename directory from "sqldev" to "tests".
Hi,
Setting - coma before.
Subselect in select statement is badly formated. The same select with setting coma after is formated correctly.
Example:
SELECT table_name
,(
SELECT COUNT(1)
FROM user_indexes i
WHERE i.table_name = t.table_name
)
,t.BLOCKS
FROM user_tables t;Thank you very much for fix it.
The idea is to find all SQL code blocks in Markdown files
```sql (optionally with whitespace between the last backtick and sql) and```and format them with the chosen settings.
I see two options to implement that feature
.md file extension to the default list of files to be processed and hard-code the behavior for the processing of .md files.mext=) to identify markdown file extensions. Only files with these extensions are processed as markdown files. The default file extensions could be .markdown, .mdown, .mkdn, .md(see https://github.com/github/markup#markups). So, to avoid the processing of markdown files mext= (empty list) must be passed. To process markdown files only ext= must be passed.In both cases markdown files are processed by default. I'm in favor of option two, because it's more flexible.
Default settings beside
The formatting result is
BEGIN
FOR rec IN (
SELECT r.country_region AS region
,p.prod_category
,SUM(s.amount_sold) AS amount_sold
FROM sales s
JOIN products p
ON p.prod_id = s.prod_id
JOIN customers cust
ON cust.cust_id = s.cust_id
JOIN times t
ON t.time_id = s.time_id
JOIN countries r
ON r.country_id = cust.country_id
WHERE calendar_year = 2000
GROUP BY r.country_region
,p.prod_category
ORDER BY r.country_region
,p.prod_category
) LOOP
IF rec.region = 'Asia' THEN
IF rec.prod_category = 'Hardware' THEN
/* print only one line for demo purposes */
sys.dbms_output.put_line('Amount: ' || rec.amount_sold);
END IF;
END IF;
END LOOP;
END;
/Expected is:
BEGIN
FOR rec IN (
SELECT r.country_region AS region
,p.prod_category
,SUM(s.amount_sold) AS amount_sold
FROM sales s
JOIN products p
ON p.prod_id = s.prod_id
JOIN customers cust
ON cust.cust_id = s.cust_id
JOIN times t
ON t.time_id = s.time_id
JOIN countries r
ON r.country_id = cust.country_id
WHERE calendar_year = 2000
GROUP BY r.country_region
,p.prod_category
ORDER BY r.country_region
,p.prod_category
) LOOP
IF rec.region = 'Asia' THEN
IF rec.prod_category = 'Hardware' THEN
/* print only one line for demo purposes */
sys.dbms_output.put_line('Amount: ' || rec.amount_sold);
END IF;
END IF;
END LOOP;
END;
/Hi Philipp,
thanks for your great blog and sharing your code on SQL Developer formatting.
I have an issue with this configuration. All blank lines before comments will be doubled after formatting.
Example:
CREATE OR REPLACE PACKAGE test_formatting AS
/* Tow line before this comment will result in four lines */
FUNCTION foo (
p_bar VARCHAR2
) RETURN NUMBER;
END test_formatting;
After format I got this result:
CREATE OR REPLACE PACKAGE test_formatting AS
/* Tow line before this comment will result in four lines */
FUNCTION foo (
p_bar VARCHAR2
) RETURN NUMBER;
END test_formatting;
I tried this with SQL Developer 19.4 (64-bit, Java 1.8.0_221) on Windows 10.
Regards,
Markus
Hi again, @PhilippSalvisberg :)
my settings:

SQL Source before formatting:
DECLARE
TYPE arr IS
VARRAY(20) OF VARCHAR2(1) NOT NULL;
-- array of all key prefixes that can be ordered (based on this we decide whether to also update ordering table or not)
my_arr arr := arr(
'a',
'b',
'c',
'd',
'e'
);
BEGIN
NULL;
END;
/
CREATE OR REPLACE PACKAGE BODY my_pkg AS
TYPE arr IS
VARRAY(20) OF VARCHAR2(1) NOT NULL;
my_arr arr := arr(
'a',
'b',
'c',
'd',
'e'
);
END;
/After formatting 4 times:
DECLARE
TYPE arr IS
VARRAY(20) OF VARCHAR2(1) NOT NULL;
-- array of all key prefixes that can be ordered (based on this we decide whether to also update ordering table or not)
my_arr arr := arr(
'a',
'b',
'c',
'd',
'e'
);
BEGIN
NULL;
END;
/
CREATE OR REPLACE PACKAGE BODY my_pkg AS
TYPE arr IS
VARRAY(20) OF VARCHAR2(1) NOT NULL;
my_arr arr := arr(
'a',
'b',
'c',
'd',
'e'
);
END;
/Expected result:
DECLARE
TYPE arr IS
VARRAY(20) OF VARCHAR2(1) NOT NULL;
-- array of all key prefixes that can be ordered (based on this we decide whether to also update ordering table or not)
my_arr arr := arr(
'a',
'b',
'c',
'd',
'e'
);
BEGIN
NULL;
END;
/
CREATE OR REPLACE PACKAGE BODY my_pkg AS
TYPE arr IS
VARRAY(20) OF VARCHAR2(1) NOT NULL;
my_arr arr := arr(
'a',
'b',
'c',
'd',
'e'
);
END;
/So am I missing some formatter settings or is this a bug?
After some additional testing, I'm observing the multi-time indentation (i.e. each time I format) of the line when that line is preceeded by a comment
Before-after comparison:

The following error is thrown under "certain" conditions when processing SQLcl scripts:
Sep 20, 2020 1:07:59 PM oracle.dbtools.raptor.newscriptrunner.ScriptExecutor run
SEVERE: jdk.scripting.nashorn/jdk.nashorn.internal.runtime.ECMAErrors.error(ECMAErrors.java:57)
<eval>:413 TypeError: Cannot read property "equalsIgnoreCase" from undefined
at jdk.scripting.nashorn/jdk.nashorn.internal.runtime.ECMAErrors.error(ECMAErrors.java:57)
at jdk.scripting.nashorn/jdk.nashorn.internal.runtime.ECMAErrors.typeError(ECMAErrors.java:213)
at jdk.scripting.nashorn/jdk.nashorn.internal.runtime.ECMAErrors.typeError(ECMAErrors.java:185)
at jdk.scripting.nashorn/jdk.nashorn.internal.runtime.ECMAErrors.typeError(ECMAErrors.java:172)
at jdk.scripting.nashorn/jdk.nashorn.internal.runtime.Undefined.get(Undefined.java:161)
at jdk.scripting.nashorn.scripts/jdk.nashorn.internal.scripts.Script$Recompilation$37$18504AAA$\^eval\_.registerTvdFormat#handleEvent(<eval>:413)
at jdk.nashorn.javaadapters.oracle_dbtools_raptor_newscriptrunner_CommandListener.handleEvent(Unknown Source)
at oracle.dbtools.raptor.newscriptrunner.CommandRegistry.fireListeners(CommandRegistry.java:346)
at oracle.dbtools.raptor.newscriptrunner.ScriptRunner.run(ScriptRunner.java:226)
at oracle.dbtools.raptor.newscriptrunner.ScriptExecutor.run(ScriptExecutor.java:344)
at oracle.dbtools.raptor.newscriptrunner.ScriptExecutor.run(ScriptExecutor.java:227)
at oracle.dbtools.raptor.newscriptrunner.SQLPLUS.runExecuteFile(SQLPLUS.java:3904)
at oracle.dbtools.raptor.newscriptrunner.SQLPLUS.run(SQLPLUS.java:213)
at oracle.dbtools.raptor.newscriptrunner.ScriptRunner.runSQLPLUS(ScriptRunner.java:425)
at oracle.dbtools.raptor.newscriptrunner.ScriptRunner.run(ScriptRunner.java:262)
at oracle.dbtools.raptor.newscriptrunner.ScriptExecutor.run(ScriptExecutor.java:344)
at oracle.dbtools.raptor.newscriptrunner.ScriptExecutor.run(ScriptExecutor.java:227)
at oracle.dbtools.raptor.scriptrunner.cmdline.SqlCli.runFile(SqlCli.java:795)
at oracle.dbtools.raptor.scriptrunner.cmdline.SqlCli.handleAtFiles(SqlCli.java:773)
at oracle.dbtools.raptor.scriptrunner.cmdline.SqlCli.main(SqlCli.java:495)
the relevant code in format.js on line 413 is
if (args[0].equalsIgnoreCase("tvdformat")) {
So it looks like args[0] can be undefined. This should be checked to avoid this error.
I get following block post formatting it:
declare
l_value varchar2(4000);
begin
select /*+ parallel(pd, 4) */ some_quite_long_function_name(another_long_function_name(first_Column_id
|| another_Column_id
|| third_Column_id
|| fourth_column_id
|| fifth_column
|| another_column))
into l_checksum
from my_table_data pd;
end;
/
But I would expect to get something more like below.
The problems that I see are:
See this video from Kevlin. It explains good code style nicely.
I think it would be much more consistent, maintainable and easy to read like below:
declare
l_value varchar2(4000);
begin
select /*+ parallel(pd, 4) */
some_quite_long_function_name(
another_long_function_name(
first_Column_id
|| another_Column_id
|| third_Column_id
|| fourth_column_id
|| fifth_column
|| another_column
)
)
into l_checksum
from my_table_data pd;
end;
/
This was mentioned by Kevlin Henney in one of his talks.
Default settings beside:
The formatting result is:
BEGIN
FOR rec IN (
SELECT r.country_region AS region,
p.prod_category,
SUM(s.amount_sold) AS amount_sold
FROM sales s
JOIN products p
ON p.prod_id = s.prod_id
JOIN customers cust
ON cust.cust_id = s.cust_id
JOIN times t
ON t.time_id = s.time_id
JOIN countries r
ON r.country_id = cust.country_id
WHERE calendar_year = 2000
GROUP BY r.country_region,
p.prod_category
ORDER BY r.country_region,
p.prod_category
) LOOP
IF rec.region = 'Asia' THEN
IF rec.prod_category = 'Hardware' THEN
/* print only one line for demo purposes */
sys.dbms_output.put_line('Amount: ' || rec.amount_sold);
END IF;
END IF;
END LOOP;
END;
/expected is (alias s is position on the same column as p, cust, t and r):
BEGIN
FOR rec IN (
SELECT r.country_region AS region,
p.prod_category,
SUM(s.amount_sold) AS amount_sold
FROM sales s
JOIN products p
ON p.prod_id = s.prod_id
JOIN customers cust
ON cust.cust_id = s.cust_id
JOIN times t
ON t.time_id = s.time_id
JOIN countries r
ON r.country_id = cust.country_id
WHERE calendar_year = 2000
GROUP BY r.country_region,
p.prod_category
ORDER BY r.country_region,
p.prod_category
) LOOP
IF rec.region = 'Asia' THEN
IF rec.prod_category = 'Hardware' THEN
/* print only one line for demo purposes */
sys.dbms_output.put_line('Amount: ' || rec.amount_sold);
END IF;
END IF;
END LOOP;
END;
/Settings:

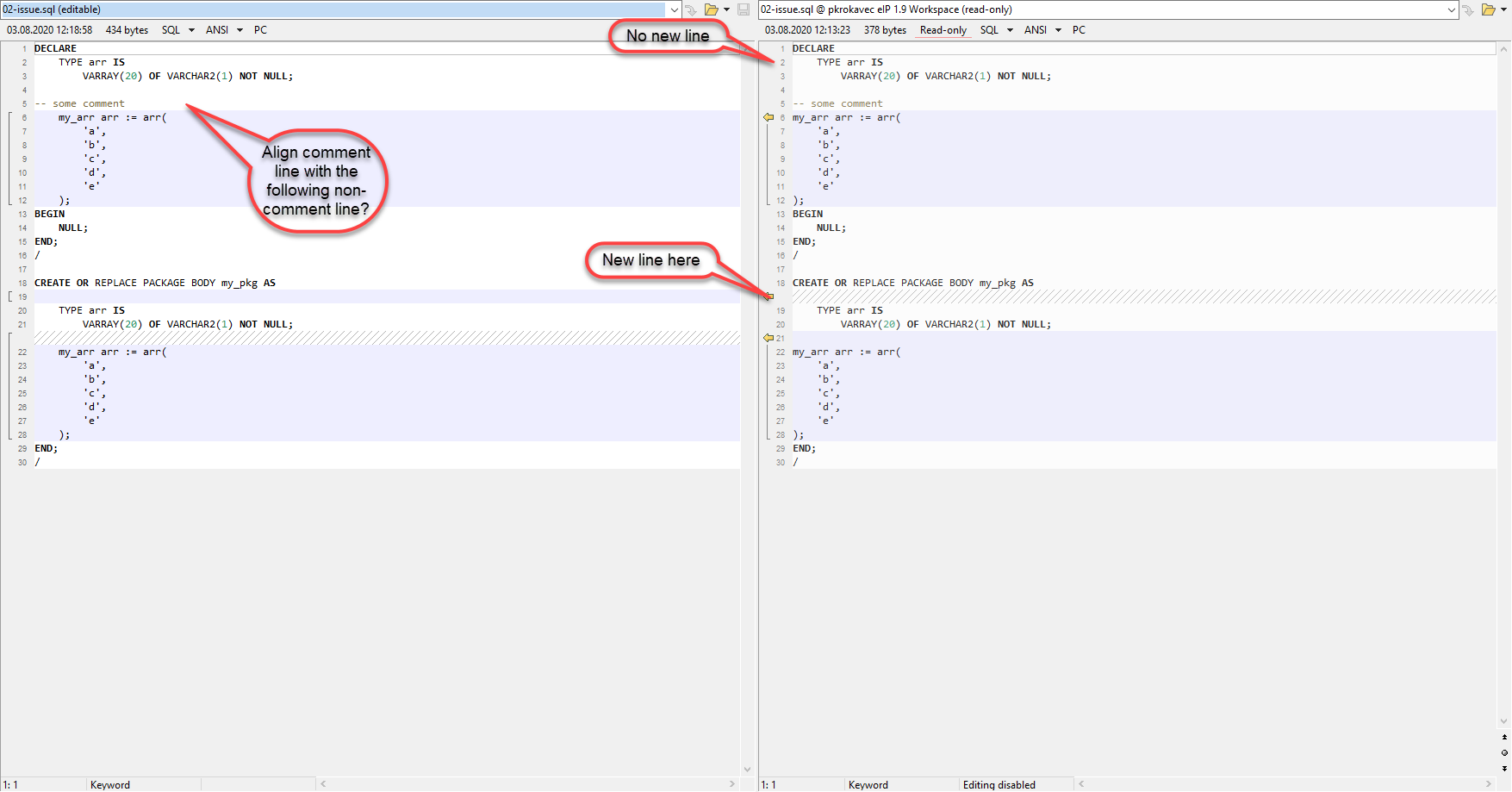
Source:
DECLARE
TYPE arr IS
VARRAY(20) OF VARCHAR2(1) NOT NULL;
-- some comment
my_arr arr := arr(
'a',
'b',
'c',
'd',
'e'
);
BEGIN
NULL;
END;
/
CREATE OR REPLACE PACKAGE BODY my_pkg AS
TYPE arr IS
VARRAY(20) OF VARCHAR2(1) NOT NULL;
my_arr arr := arr(
'a',
'b',
'c',
'd',
'e'
);
END;
/Before/After comparison:
For some reason, the formatter removes all empty lines in code.
Code before foramtting:
create or replace package body ut_teamcity_reporter_helper is
/*
utPLSQL - Version 3
Copyright 2016 - 2019 utPLSQL Project
Licensed under the Apache License, Version 2.0 (the "License"):
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
*/
subtype t_prop_index is varchar2(2000 char);
type t_props is table of varchar2(32767) index by t_prop_index;
function escape_value(a_value in varchar2) return varchar2 is
begin
return translate(regexp_replace(a_value, q'/(\'|\||\[|\]|/' || chr(13) || '|' || chr(10) || ')', '|\1'),chr(13)||chr(10),'rn');
end;
function message(a_command in varchar2, a_props t_props default cast(null as t_props)) return varchar2 is
l_message varchar2(32767);
l_index t_prop_index;
l_value varchar2(32767);
l_max_len binary_integer := 2000;
begin
l_message := '##teamcity[' || a_command || ' timestamp=''' ||
regexp_replace(to_char(systimestamp, 'YYYY-MM-DD"T"HH24:MI:ss.FF3TZHTZM'), '(\.\d{3})\d+(\+)', '\1\2') || '''';
l_index := a_props.first;
while l_index is not null loop
if a_props(l_index) is not null then
l_value := escape_value(a_props(l_index));
if length(l_value) > l_max_len then
l_value := substr(l_value,1,l_max_len-7)||escape_value('[...]');
end if;
l_message := l_message || ' ' || l_index || '=''' || l_value || '''';
end if;
l_index := a_props.next(l_index);
end loop;
l_message := l_message || ']';
return l_message;
end message;
function test_suite_started(a_suite_name varchar2, a_flow_id varchar2 default null) return varchar2 is
l_props t_props;
begin
l_props('name') := a_suite_name;
l_props('flowId') := a_flow_id;
return message('testSuiteStarted', l_props);
end;
function test_suite_finished(a_suite_name varchar2, a_flow_id varchar2 default null) return varchar2 is
l_props t_props;
begin
l_props('name') := a_suite_name;
l_props('flowId') := a_flow_id;
return message('testSuiteFinished', l_props);
end;
function test_started(a_test_name varchar2, a_capture_standard_output boolean default null, a_flow_id varchar2 default null) return varchar2 is
l_props t_props;
begin
l_props('name') := a_test_name;
l_props('captureStandardOutput') := case a_capture_standard_output
when true then
'true'
when false then
'false'
else
null
end;
l_props('flowId') := a_flow_id;
return message('testStarted', l_props);
end;
function test_finished(a_test_name varchar2, a_test_duration_milisec number default null, a_flow_id varchar2 default null) return varchar2 is
l_props t_props;
begin
l_props('name') := a_test_name;
l_props('duration') := a_test_duration_milisec;
l_props('flowId') := a_flow_id;
return message('testFinished', l_props);
end;
function test_disabled(a_test_name varchar2, a_flow_id varchar2 default null) return varchar2 is
l_props t_props;
begin
l_props('name') := a_test_name;
l_props('flowId') := a_flow_id;
return message('testIgnored', l_props);
end;
function test_failed(a_test_name varchar2, a_msg in varchar2 default null, a_details varchar2 default null, a_flow_id varchar2 default null, a_actual varchar2 default null, a_expected varchar2 default null) return varchar2 is
l_props t_props;
begin
l_props('name') := a_test_name;
l_props('message') := a_msg;
l_props('details') := a_details;
l_props('flowId') := a_flow_id;
if a_actual is not null and a_expected is not null then
l_props('actual') := a_actual;
l_props('expected') := a_expected;
end if;
return message('testFailed', l_props);
end;
function test_std_err(a_test_name varchar2, a_out in varchar2, a_flow_id in varchar2 default null) return varchar2 is
l_props t_props;
begin
l_props('name') := a_test_name;
l_props('out') := a_out;
l_props('flowId') := a_flow_id;
return message('testStdErr', l_props);
end;
end ut_teamcity_reporter_helper;
/
Code after formatting:
create or replace package body ut_teamcity_reporter_helper is
/*
utPLSQL - Version 3
Copyright 2016 - 2019 utPLSQL Project
Licensed under the Apache License, Version 2.0 (the "License"):
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
*/
subtype t_prop_index is varchar2(2000 char);
type t_props is
table of varchar2(32767) index by t_prop_index;
function escape_value (
a_value in varchar2
) return varchar2 is
begin
return translate(regexp_replace(a_value, q'/(\'|\||\[|\]|/'
|| chr(13)
|| '|'
|| chr(10)
|| ')', '|\1'), chr(13)
|| chr(10), 'rn');
end;
function message (
a_command in varchar2,
a_props t_props default cast ( null as t_props )
) return varchar2 is
l_message varchar2(32767);
l_index t_prop_index;
l_value varchar2(32767);
l_max_len binary_integer := 2000;
begin
l_message := '##teamcity['
|| a_command
|| ' timestamp='''
|| regexp_replace(to_char(systimestamp, 'YYYY-MM-DD"T"HH24:MI:ss.FF3TZHTZM'), '(\.\d{3})\d+(\+)', '\1\2')
|| '''';
l_index := a_props.first;
while l_index is not null loop
if a_props(l_index) is not null then
l_value := escape_value(a_props(l_index));
if length(l_value) > l_max_len then
l_value := substr(l_value, 1, l_max_len - 7)
|| escape_value('[...]');
end if;
l_message := l_message
|| ' '
|| l_index
|| '='''
|| l_value
|| '''';
end if;
l_index := a_props.next(l_index);
end loop;
l_message := l_message || ']';
return l_message;
end message;
function test_suite_started (
a_suite_name varchar2,
a_flow_id varchar2 default null
) return varchar2 is
l_props t_props;
begin
l_props('name') := a_suite_name;
l_props('flowId') := a_flow_id;
return message('testSuiteStarted', l_props);
end;
function test_suite_finished (
a_suite_name varchar2,
a_flow_id varchar2 default null
) return varchar2 is
l_props t_props;
begin
l_props('name') := a_suite_name;
l_props('flowId') := a_flow_id;
return message('testSuiteFinished', l_props);
end;
function test_started (
a_test_name varchar2,
a_capture_standard_output boolean default null,
a_flow_id varchar2 default null
) return varchar2 is
l_props t_props;
begin
l_props('name') := a_test_name;
l_props('captureStandardOutput') :=
case a_capture_standard_output
when true then
'true'
when false then
'false'
else null
end;
l_props('flowId') := a_flow_id;
return message('testStarted', l_props);
end;
function test_finished (
a_test_name varchar2,
a_test_duration_milisec number default null,
a_flow_id varchar2 default null
) return varchar2 is
l_props t_props;
begin
l_props('name') := a_test_name;
l_props('duration') := a_test_duration_milisec;
l_props('flowId') := a_flow_id;
return message('testFinished', l_props);
end;
function test_disabled (
a_test_name varchar2,
a_flow_id varchar2 default null
) return varchar2 is
l_props t_props;
begin
l_props('name') := a_test_name;
l_props('flowId') := a_flow_id;
return message('testIgnored', l_props);
end;
function test_failed (
a_test_name varchar2,
a_msg in varchar2 default null,
a_details varchar2 default null,
a_flow_id varchar2 default null,
a_actual varchar2 default null,
a_expected varchar2 default null
) return varchar2 is
l_props t_props;
begin
l_props('name') := a_test_name;
l_props('message') := a_msg;
l_props('details') := a_details;
l_props('flowId') := a_flow_id;
if a_actual is not null and a_expected is not null then
l_props('actual') := a_actual;
l_props('expected') := a_expected;
end if;
return message('testFailed', l_props);
end;
function test_std_err (
a_test_name varchar2,
a_out in varchar2,
a_flow_id in varchar2 default null
) return varchar2 is
l_props t_props;
begin
l_props('name') := a_test_name;
l_props('out') := a_out;
l_props('flowId') := a_flow_id;
return message('testStdErr', l_props);
end;
end ut_teamcity_reporter_helper;
/Expected behavior would be one of:
To simplify the usage of format.js it should be registered as command. This is less typing and the path to the format.js must not be remembered.
@erikvanroon describes how to register JavaScript functions as commands in this blog post.
Registration as command should be optional. For example with an additional --register parameter. Previously registered command should be automatically unregistered during the registration process to ensure the most recent version is used and avoid duplicate registrations (e.g. when used in login.sql).
How to 'nicely' format the CREATE TABLESPACE statement?
Let's take an example which I consider quite well-formatted (well, at least this is my personal preference):
CREATE TABLESPACE my_table_space
DATAFILE 'my_tablespace_file.dbf' SIZE 50M
AUTOEXTEND ON NEXT 10M
MAXSIZE UNLIMITED
EXTENT MANAGEMENT LOCAL AUTOALLOCATE;But the formatter uglyfies it into this:
CREATE TABLESPACE my_table_space DATAFILE
'my_tablespace_file.dbf' SIZE 50M
AUTOEXTEND ON NEXT 10M MAXSIZE UNLIMITED
EXTENT MANAGEMENT LOCAL AUTOALLOCATE;All tests in this project are written in Xtend. Mostly the Text block feature is used in Xtend. Therefore a migration to Java 15 should be simple.
Consider this ugly piece of code:
SET ECHO OFF
BEGIN
println('Creating general_tools package');
END;
/
----------------------------------------------------------------------------
-- begin package specification
----------------------------------------------------------------------------
CREATE OR REPLACE PACKAGE general_tools AS
FUNCTION exist_table (
usrname VARCHAR2,
tabname VARCHAR2
) RETURN BOOLEAN;
FUNCTION exist_column (
usrname VARCHAR2,
tabname VARCHAR2,
colname VARCHAR2
) RETURN BOOLEAN;
END;
/After formatting (settings are indent=4 and double break after statements, everything else default):
SET ECHO OFF
BEGIN
println('Creating general_tools package');
END;
/
----------------------------------------------------------------------------
-- begin package specification
----------------------------------------------------------------------------
CREATE OR REPLACE PACKAGE general_tools AS
FUNCTION exist_table (
usrname VARCHAR2,
tabname VARCHAR2
) RETURN BOOLEAN;
FUNCTION exist_column (
usrname VARCHAR2,
tabname VARCHAR2,
colname VARCHAR2
) RETURN BOOLEAN;
END;
/Everything looks great but let's say I don't like that empty line after the 1st line, empty line after the package declaration (after AS) and another empty line just before the last END;
So I decide to remove them like this:
SET ECHO OFF
BEGIN
println('Creating general_tools package');
END;
/
----------------------------------------------------------------------------
-- begin package specification
----------------------------------------------------------------------------
CREATE OR REPLACE PACKAGE general_tools AS
FUNCTION exist_table (
usrname VARCHAR2,
tabname VARCHAR2
) RETURN BOOLEAN;
FUNCTION exist_column (
usrname VARCHAR2,
tabname VARCHAR2,
colname VARCHAR2
) RETURN BOOLEAN;
END;
/Now I change the break settings to "Preserve original" and hit CTRL+F7 and see how the FUNCTIONs are misaligned
SET ECHO OFF
BEGIN
println('Creating general_tools package');
END;
/
----------------------------------------------------------------------------
-- begin package specification
----------------------------------------------------------------------------
CREATE OR REPLACE PACKAGE general_tools AS
FUNCTION exist_table (
usrname VARCHAR2,
tabname VARCHAR2
) RETURN BOOLEAN;
FUNCTION exist_column (
usrname VARCHAR2,
tabname VARCHAR2,
colname VARCHAR2
) RETURN BOOLEAN;
END;
/Line breaks were preserved, allright but that misalignment is a problem. Is that easy to fix?
SQL Developer 20.2.0 is out. The current do not produce the same results as in 19.4.0.
Example:
BEGIN
-- a comment
NULL;
END;
/will result in produce this after formatting it the first time:
BEGIN
-- a comment
NULL;
END;
/and this after formatting it the second time:
BEGIN
-- a comment
NULL;
END;
/Every time an additional (unwanted) indentation is added before NULL;. This works fine with SQL Developer 19.4.0.
Unformatted source:
CREATE TABLE configuration (
id NUMBER NOT NULL,
namespace VARCHAR2(64 CHAR) NOT NULL,
key VARCHAR2(128 CHAR) NOT NULL,
owner VARCHAR2(256 CHAR),
scope VARCHAR2(256 CHAR),
CONSTRAINT c$pk PRIMARY KEY (id),
CONSTRAINT c$un_1 UNIQUE (id, namespace, key, owner, scope),
CONSTRAINT c$un_2 UNIQUE (namespace, key, owner, scope)
);What I get after formatting:
CREATE TABLE configuration (
id NUMBER NOT NULL,
namespace VARCHAR2(64 CHAR) NOT NULL,-- where is this double space between name and type coming from? is it configurable? maybe I always want 4 spaces between, or maybe I want one tab there (i.e. 1-4 spaces)
key VARCHAR2(128 CHAR) NOT NULL,
owner VARCHAR2(256 CHAR),
scope VARCHAR2(256 CHAR),
CONSTRAINT c$pk PRIMARY KEY ( id ), --keep because <= 4 args and no spaces inside parentheses
CONSTRAINT c$un_1 UNIQUE ( id, --split because >4 args but just like inside some proc/function call. i.e. all args on their own line,
namespace, --not keeping first on the constraint line and not having last combined with parenthesis
key,
owner,
scope ),
CONSTRAINT c$un_2 UNIQUE ( namespace,
key,
owner,
scope ) --keep because <= 4 args and no spaces inside parentheses
);So basically I want to achieve this:
CREATE TABLE configuration (
id NUMBER NOT NULL,
namespace VARCHAR2(64 CHAR) NOT NULL,
key VARCHAR2(128 CHAR) NOT NULL,
owner VARCHAR2(256 CHAR),
scope VARCHAR2(256 CHAR),
CONSTRAINT c$pk PRIMARY KEY (id),
CONSTRAINT c$un_1 UNIQUE (
id,
namespace,
key,
owner,
scope
),
CONSTRAINT c$un_2 UNIQUE (namespace, key, owner, scope)
);
);Any advice?
add two features:
format the buffer
E.g. by provided "-" for the rootPath. Similar to built-in FORMAT BUFFER.
format a single file
E.g. by provided the path the a file (instead of a directory). Similar to built-in FORMAT FILE.
The ext option is not applicable in both cases. It can be passed, but is ignored.
When i try to add the code for indentExistsSubqueries i get the following error:

Please note that i use SQL developer Version 19.1.0.094
I answered a question on my blog to format XMLTABLE.
With default setting the formatting result looks like this:
SELECT stg.payload_type,
xt_hdr.*
FROM stg,
XMLTABLE ( '/XML/Header' PASSING xmltype.createxml(stg.xml_payload) COLUMNS source VARCHAR2(50) PATH 'Source', action_type
VARCHAR2(50) PATH 'Action_Type', message_type VARCHAR2(40) PATH 'Message_Type', company_id NUMBER PATH 'Company_ID' )
hdr; Expected result should look like this:
SELECT stg.payload_type,
xt_hdr.*
FROM stg,
XMLTABLE (
'/XML/Header'
PASSING xmltype.createxml(stg.xml_payload)
COLUMNS source VARCHAR2(50) PATH 'Source',
action_type VARCHAR2(50) PATH 'Action_Type',
message_type VARCHAR2(40) PATH 'Message_Type',
company_id NUMBER PATH 'Company_ID'
) hdr;It's different to the solution I've provided to the question. I consider this more consistent to the existing formatting styles such as function and procedure parameters.
The initial Arbori program in this repository is based on the one provided by SQL Developer 19.4. Since then some fixes have been applied in the default Arbori program.
Compare Version 19.4 with 20.3 and include the changes in the current version.
Fix test cases if necessary.
In SQLcl 20.3.0 the BreaksX2.Keep seems to work without unwanted side effects. This is the better default than BreaksX2.X1 (no empty line) or BreaksX2.X2 (always empty line).
Update trivadis_advanced_format.xml, format.js and related test cases.
The following query is formatted with default settings as follows:
SELECT *
FROM dba_tables
WHERE table_name IN (
SELECT queue_table
FROM dba_queue_tables
)
AND ( owner,
table_name ) NOT IN (
SELECT owner,
name
FROM dba_snapshots
)
AND temporary = 'N'
ORDER BY blocks DESC;I'd expect something like this:
SELECT *
FROM dba_tables
WHERE table_name IN (
SELECT queue_table
FROM dba_queue_tables
)
AND ( owner, table_name ) NOT IN (
SELECT owner,
name
FROM dba_snapshots
)
AND temporary = 'N'
ORDER BY blocks DESC;These are two issues:
NOT IN (bug)( owner, table_name ) (enhancement, could be based on the number of args as well)After formatting, first and last line are indented with 3 spaces. Should be 0. (Why not 4 when I have indent set to 4 spaces in the formatter settings?)
SET ECHO OFF;
CREATE OR REPLACE PACKAGE BODY emp_mgmt AS
FUNCTION hire (
last_name IN VARCHAR2,
job_id IN VARCHAR2,
manager_id IN NUMBER,
salary IN NUMBER,
department_id IN NUMBER
) RETURN NUMBER IS
new_empno NUMBER(16, 0);
BEGIN
--some code
return(new_empno);
END;
END emp_mgmt;
/
SET ECHO ONThanks @rogertroller for reporting this via another channel.
Here's an adapted version of the issue, reproducible in any environment using Oracle Database 12.2 or newer.
The following code
CREATE TABLE t (
c CLOB CHECK ( c IS JSON )
);
--
INSERT INTO t VALUES ( '{accountNumber:123, accountName:"Name", accountType:"A"}' );
--
COLUMN accountNumber FORMAT A15
COLUMN accountName FORMAT A15
COLUMN accountType FORMAT A10
--
SELECT j.c.accountNumber,
j.c.accountName,
j.c.accountType
FROM t j
WHERE j.c.accountType = 'A';
--
DROP TABLE t PURGE;produces this output in SQL Developer:
Table T created.
1 row inserted.
ACCOUNTNUMBER ACCOUNTNAME ACCOUNTTYP
--------------- --------------- ----------
123 Name A
Table T dropped.
When formatting the code in SQL Developer using the settings provided in this repository the code is changed to:
CREATE TABLE t (
c CLOB CHECK ( c IS JSON )
);
--
INSERT INTO t VALUES ( '{accountNumber:123, accountName:"Name", accountType:"A"}' );
--
COLUMN accountnumber FORMAT a15
COLUMN accountname FORMAT a15
COLUMN accounttype FORMAT a10
--
SELECT j.c.accountnumber,
j.c.accountname,
j.c.accounttype
FROM t j
WHERE j.c.accounttype = 'A';
--
DROP TABLE t PURGE;Look at the identifiers. They are all lowercase now. This breaks the code. The result is now:
Table T dropped.
Table T created.
1 row inserted.
no rows selected
Table T dropped.
Hence the case of identifiers should not be changed.
I use "comma before" setting.
I use parenthesis in where for AND and OR.
I have got after formatting this:
SELECT *
FROM dba_tables
WHERE ( owner = 'SYSTEM'
AND ( table_name = 'REDO_DB'
OR table_name = 'REDO_LOG' ) )
OR ( owner = 'SYS'
AND ( table_name = 'ALERT_QT'
OR table_name = 'ALL_UNIFIED_AUDIT_ACTIONS' ) );There are all conditions optically on the same level, it could be confusing.
I think it would be useful if formatting looks like
SELECT *
FROM dba_tables
WHERE ( owner = 'SYSTEM'
AND ( table_name = 'REDO_DB'
OR table_name = 'REDO_LOG' ) )
OR ( owner = 'SYS'
AND ( table_name = 'ALERT_QT'
OR table_name = 'ALL_UNIFIED_AUDIT_ACTIONS' ) );This happens when certain number of characters between IS and BEGIN is exceeded
FUNCTION get_id1 (
p_1 NUMBER,
p_2 NUMBER,
p_3 NUMBER
) RETURN NUMBER IS
local_1 NUMBER;
local_2 NUMBER;
local_3 NUMBER;
local_4 NUMBER;
local_5 NUMBER;
BEGIN
RETURN 9999;
END get_id1;
FUNCTION get_id2 (
p_1 my_table.id%TYPE,
p_2 my_table.id%TYPE,
p_3 my_table.id%TYPE
) RETURN my_table.id%TYPE IS
local_1 my_table.id%TYPE;
local_2 my_table.id%TYPE;
local_3 my_table.id%TYPE;
local_4 my_table.id%TYPE;
local_5 my_table.id%TYPE;
BEGIN
-- some code
RETURN 9999;
END get_id2;The table name is not on the same line as update/insert statement but below


When formatting a below block I get the following:
declare
l_array my_array_tab;
begin
select t.a,
t.b,
t.c,
n.stuff bulk collect
into l_array
from some_table s outer apply ( s.nested_tab ) n;
end;
/
I would expect to get:
declare
l_array my_array_tab;
begin
select t.a,
t.b,
t.c,
n.stuff
bulk collect
into l_array
from some_table s
outer apply ( s.nested_tab ) n;
end;
/
or:
declare
l_array my_array_tab;
begin
select t.a,
t.b,
t.c,
n.stuff
bulk collect
into l_array
from some_table s
outer apply ( s.nested_tab ) n;
end;
/
or:
declare
l_array my_array_tab;
begin
select t.a,
t.b,
t.c,
n.stuff
bulk collect into l_array
from some_table s
outer apply ( s.nested_tab ) n;
end;
/
How to achieve this formatting? I.e. same as parameters of a procedure/function
CREATE OR REPLACE PACKAGE BODY tools AS
-----------------------------------------
-- Private functions and procedures START
-----------------------------------------
TYPE arr IS
VARRAY(20) OF VARCHAR2(20) NOT NULL;
orderable_key_prefixes arr := arr(
'aaaaaaaaaaaa',
'bbbbbbbbbbbb',
'cccccccccccc',
'dddddddddddd',
'eeeeeeeeeeee',
'ffffffffffff',
'gggggggggggg',
'hhhhhhhhhhhh',
'iiiiiiiiiiii',
'jjjjjjjjjjjj',
'kkkkkkkkkkkk',
'llllllllllll',
'mmmmmmmmmmmm'
);
END;
/When I format I get this:
CREATE OR REPLACE PACKAGE BODY tools AS
-----------------------------------------
-- Private functions and procedures START
-----------------------------------------
TYPE arr IS
VARRAY(20) OF VARCHAR2(20) NOT NULL;
orderable_key_prefixes arr := arr('aaaaaaaaaaaa', 'bbbbbbbbbbbb', 'cccccccccccc', 'dddddddddddd', 'eeeeeeeeeeee', 'ffffffffffff', 'gggggggggggg', 'hhhhhhhhhhhh', 'iiiiiiiiiiii', 'jjjjjjjjjjjj', 'kkkkkkkkkkkk',
'llllllllllll', 'mmmmmmmmmmmm');
END;
/With #72 the default settings for extraLinesAfterSignificantStatements changed to BreaksX2.Keep.
This leads to strange (but technically correct) result for code that does not contain line breaks in usual places. For example when formatting this code (see also package_body.pkb):
create or replace package body the_api.math as function to_int_table(in_integers
in varchar2,in_pattern in varchar2 default '[0-9]+')return sys.ora_mining_number_nt deterministic accessible
by(package the_api.math,package the_api.test_math)is l_result sys
.ora_mining_number_nt:=sys.ora_mining_number_nt();l_pos integer:= 1;l_int integer;
begin<<integer_tokens>>loop l_int:=to_number(regexp_substr(in_integers,in_pattern,1,l_pos));
exit integer_tokens when l_int is null;l_result.extend;l_result(l_pos):= l_int;l_pos:=l_pos+1;
end loop integer_tokens;return l_result;end to_int_table;end math;
/The result like this (with BreaksX2.Keep):
CREATE OR REPLACE PACKAGE BODY the_api.math AS FUNCTION to_int_table (
in_integers IN VARCHAR2,
in_pattern IN VARCHAR2 DEFAULT '[0-9]+'
) RETURN sys.ora_mining_number_nt
DETERMINISTIC
ACCESSIBLE BY ( PACKAGE the_api.math, PACKAGE the_api.test_math )
IS
l_result sys.ora_mining_number_nt := sys.ora_mining_number_nt();
l_pos INTEGER := 1;
l_int INTEGER;
BEGIN
<<integer_tokens>>
LOOP
l_int := to_number(regexp_substr(in_integers, in_pattern, 1, l_pos));
EXIT integer_tokens WHEN l_int IS NULL;
l_result.extend;
l_result(l_pos) := l_int;
l_pos := l_pos + 1;
END LOOP integer_tokens;RETURN l_result;
END to_int_table;END math;
/The next image visualises the difference to BreaksX2.X1:

We already limit the maximum number of empty lines after a significant statement to one line. Therefore it would make sense to ensure that a new line exists after every significant statement.
In this case the formatting result for BreaksX2.X1 and BreaksX2.Keep is expected to be the same.
Hi,
INTO clause is formatted as follows:
SELECT namespace,
key,
scope
INTO
l_namespace,
l_key,
l_scope
FROM configuration
WHERE id = p_id;Shouldn't it be the same as SELECT clause, i.e. 1st variable on the same line as INTO and following variables aligned accordingly to 1st?
JavaScript with following usage:
usage: script format.js <rootPath> [options]
mandatory arguments:
<rootPath> path to directory containing files to format (content will be replaced!)
options:
ext=<ext> comma separated list of file extensions to process, e.g. ext=sql,pks,pkb
arbori=<file> path to the file containing the Arbori program for custom format settings
I see some issues with formatting in some cases.
Example below.
declare
function transform_cancel_rec (
p_input_obj some_obj_type
) return return_rec is
l_return_rec return_rec;
l_some_rec some_rec_type;
l_some_tab some_tab_type;
l_some_long_named_variable_rec some_record_type;
l_some_long_named_variable_tab some_table_type;
begin
l_return_rec.some_primary_id := p_input_obj.primary_id;
for i in 1..p_input_obj.items.count loop
l_some_long_named_variable_tab := some_table_type();
for j in 1..p_input_obj.items(i).some_nested_element_array.count loop
l_some_long_named_variable_rec.some_primary_item_id := p_input_obj.items(i).some_nested_element_array(j).some_primary_item_id;
l_some_long_named_variable_rec.some_other_key_element := get_some_other_key_element(p_input_obj.items(i).some_nested_element_array(
j).some_sun_element_id);
l_some_long_named_variable_tab.extend();
l_some_long_named_variable_tab(j) := l_some_long_named_variable_rec;
end loop;
l_some_rec.items := l_some_long_named_variable_tab;
l_some_tab.extend();
l_some_tab(i) := l_some_rec;
end loop;
l_return_rec.items := l_some_tab;
return l_return_rec;
end;
begin
null;
end;
/
Would rather see it like this:
declare
function transform_cancel_rec (
p_input_obj some_obj_type
) return return_rec is
l_return_rec return_rec;
l_some_rec some_rec_type;
l_some_tab some_tab_type;
l_some_long_named_variable_rec some_record_type;
l_some_long_named_variable_tab some_table_type;
begin
l_return_rec.some_primary_id := p_input_obj.primary_id;
for i in 1..p_input_obj.items.count loop
l_some_long_named_variable_tab := some_table_type();
for j in 1..p_input_obj.items(i).some_nested_element_array.count loop
l_some_long_named_variable_rec.some_primary_item_id :=
p_input_obj.items(i).some_nested_element_array(j).some_primary_item_id;
l_some_long_named_variable_rec.some_other_key_element :=
get_some_other_key_element(
p_input_obj.items(i).some_nested_element_array(j).some_sun_element_id
);
l_some_long_named_variable_tab.extend();
l_some_long_named_variable_tab(j) :=
l_some_long_named_variable_rec;
end loop;
l_some_rec.items := l_some_long_named_variable_tab;
l_some_tab.extend();
l_some_tab(i) := l_some_rec;
end loop;
l_return_rec.items := l_some_tab;
return l_return_rec;
end;
begin
null;
end;
/
The Arbori program trivadis_custom_format.arbori is found then it is loaded, if no arbori parameter is passed, otherwise the "default" Arbori program is used.
A similar logic should be applied for Advanced format. If trivadis_advanced_format.xml is found then it is loaded. Otherwise the default, hard-coded settings (as currently defined in the format.js) should be applied. Add also a new parameter to pass the path to the XML file. Support the dummy "default" value as well.
Unformatted:
CREATE INDEX c$idx_1 ON configuration (key);
CREATE INDEX c$idx_2 ON configuration (owner);
CREATE INDEX c$idx_3 ON configuration (scope);
CREATE INDEX c$idx_4 ON configuration (key, namespace, owner);
CREATE INDEX c$idx_5 ON configuration (key, namespace, owner, scope);
CREATE INDEX c$idx_6 ON configuration (id, key, namespace, owner, scope);Expected:
CREATE INDEX c$idx_1 ON configuration (key);
CREATE INDEX c$idx_2 ON configuration (owner);
CREATE INDEX c$idx_3 ON configuration (scope);
CREATE INDEX c$idx_4 ON configuration (key, namespace, owner);
CREATE INDEX c$idx_5 ON configuration (key, namespace, owner, scope);
CREATE INDEX c$idx_6 ON configuration (
id,
key,
namespace,
owner,
scope
);Reality:
CREATE INDEX c$idx_1 ON
configuration (
key
);
CREATE INDEX c$idx_2 ON
configuration (
owner
);
CREATE INDEX c$idx_3 ON
configuration (
scope
);
CREATE INDEX c$idx_4 ON
configuration (
key,
namespace,
owner
);
CREATE INDEX c$idx_5 ON
configuration (
key,
namespace,
owner,
scope
);
CREATE INDEX c$idx_6 ON
configuration (
id,
key,
namespace,
owner,
scope
);I'd be OK with having
CREATE INDEX c$idx_5 ONon one line and the rest on other, but again based on number of cols , keep the cols on 1 line with the table if there are no more than 4, i.e.
CREATE INDEX c$idx_5 ON
configuration (key, namespace, owner, scope);But best for me (again personal preference) would be to keep the whole index definition on one line (including table and cols) if num_cols <= 4 (as in the 'Expected:' snippet)
Hi,
why are 2 line breaks added after some statements and not after others? They all seem equal to me.
but after that no breaks after either of those. As to what I would like to achieve is having no double breaks there. I am still using the X2 setting because I want empty lines between proc/func declarations/definitions.
I would happily switch to X1 breaks if somehow those empty lines between individual procs/funcs were preserved (can you point me to the relevant arbori part?) or even preserve original (but we know that doesn't really work well as some unwanted indentation and whatnot is added to some lines after each performed formatting)
BEGIN
FOR c_ord IN (
SELECT *
FROM configuration_ordering
WHERE REGEXP_LIKE ( ordering,
fmt('(^%s$|^%s,.+$|^.+,%s,.+$|^.+,%s$)', p_id, p_id, p_id, p_id) )
ORDER BY scope
) LOOP
BEGIN
println(' Removing id from ordering for %s, scope=%s, owner=%s... ', c_ord.key_prefix, son(c_ord.scope), son(c_ord.owner));
l_new_ordering := REGEXP_REPLACE(c_ord.ordering, fmt('^%s$', l_id), NULL);
l_new_ordering := REGEXP_REPLACE(l_new_ordering, fmt('^%s,(.+)$', l_id), '\1');
l_new_ordering := REGEXP_REPLACE(l_new_ordering, fmt('^(.+),%s,(.+)$', l_id), '\1,\2');
l_new_ordering := REGEXP_REPLACE(l_new_ordering, fmt('^(.+),%s$', l_id), '\1');
println(' OLD:%s', son(c_ord.ordering));
println(' NEW:%s', son(l_new_ordering));
-- UPDATE configuration_ordering
-- SET ordering = l_new_ordering
-- WHERE id = c_ordering.id;
dbms_output.put_line('OK');
EXCEPTION
WHEN OTHERS THEN
dbms_output.put_line('FAILED');
RAISE;
END;
END LOOP;
END delete_from_ordering;My settings:

Currently the SQL Developer settings
can only be tested manually, using a similar workflow as this:
This is cumbersome and error-prone.
Instead the formatting results should be tested with unit tests using a unit testing framework such as JUnit. The tests should be executed without starting SQL Developer or SQLcl, and the configuration files should be maintained only once.
First of, thank you Philip for tremendous work and effort you took to understand the formatter and implement custom formatting settings.
I've downloaded latest version of settings and tried to apply formatter on some of utPLSQL sources.
I think utPLSQL can be a good battlefield for formatter as we use quite a lot of PL/SQL and SQL language features.
The only setting I have changed was to keep keywords as lowercase.
When formatting type spec, the methods are not aligned properly.
Some examples below:
create or replace type ut_realtime_reporter force under ut_output_reporter_base (
/*
utPLSQL - Version 3
Copyright 2016 - 2019 utPLSQL Project
Licensed under the Apache License, Version 2.0 (the "License"):
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
*/
/**
* Cached XML header to be used for every XML document
*/
xml_header varchar2(4000),
/**
* Total number of all tests in the run (incl. disabled tests).
*/
total_number_of_tests integer,
/**
* Currently executed test number.
*/
current_test_number integer,
/**
* Current indentation in logical tabs.
*/
current_indent integer,
/**
* Buffers lines to be printed.
*/
print_buffer ut_varchar2_rows,
/**
* The realtime reporter.
* Provides test results in a XML format, for clients such as SQL Developer interested in showing progressing details.
*/ constructor function ut_realtime_reporter (
self in out nocopy ut_realtime_reporter
) return self as result,
/**
* Provides meta data of complete run in advance.
*/ overriding member procedure before_calling_run (
self in out nocopy ut_realtime_reporter,
a_run in ut_run
),
/**
* Provides meta data of a completed run.
*/ overriding member procedure after_calling_run (
self in out nocopy ut_realtime_reporter,
a_run in ut_run
),
/**
* Indicates the start of a test suite execution.
*/ overriding member procedure before_calling_suite (
self in out nocopy ut_realtime_reporter,
a_suite in ut_logical_suite
),
/**
* Provides meta data of completed test suite.
*/ overriding member procedure after_calling_suite (
self in out nocopy ut_realtime_reporter,
a_suite in ut_logical_suite
),
/**
* Indicates the start of a test.
*/ overriding member procedure before_calling_test (
self in out nocopy ut_realtime_reporter,
a_test in ut_test
),
/**
* Provides meta data of a completed test.
*/ overriding member procedure after_calling_test (
self in out nocopy ut_realtime_reporter,
a_test in ut_test
),
/**
* Provides the description of this reporter.
*/ overriding member function get_description return varchar2,
/**
* Prints the start tag of a XML node with an optional attribute.
*/ member procedure print_start_node (
self in out nocopy ut_realtime_reporter,
a_node_name in varchar2,
a_attr_name in varchar2 default null,
a_attr_value in varchar2 default null
),
/**
* Prints the end tag of a XML node.
*/ member procedure print_end_node (
self in out nocopy ut_realtime_reporter,
a_name in varchar2
),
/**
* Prints a child node with content. Special characters are encoded.
*/ member procedure print_node (
self in out nocopy ut_realtime_reporter,
a_name in varchar2,
a_content in clob
),
/**
* Prints a child node with content. Content is passed 1:1 using CDATA.
*/ member procedure print_cdata_node (
self in out nocopy ut_realtime_reporter,
a_name in varchar2,
a_content in clob
),
/**
* Prints a line of the resulting XML document using the current indentation.
* a_indent_summand_before is added before printing a line.
* a_indent_summand_after is added after printing a line.
* All output is produced through this function.
*/ member procedure print_xml_fragment (
self in out nocopy ut_realtime_reporter,
a_fragment in clob,
a_indent_summand_before in integer default 0,
a_indent_summand_after in integer default 0
),
/**
* Flushes the local print buffer to the output buffer.
*/ member procedure flush_print_buffer (
self in out nocopy ut_realtime_reporter,
a_item_type in varchar2
)
) not final
/In above, the member procedure is not placed on new line.
It is even more visible here:
create or replace type ut_xunit_reporter under ut_junit_reporter (
/*
utPLSQL - Version 3
Copyright 2016 - 2019 utPLSQL Project
Licensed under the Apache License, Version 2.0 (the "License"):
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
*/
/**
* The XUnit reporter.
* Provides outcomes in a format conforming with JUnit4 as defined in:
* https://gist.github.com/kuzuha/232902acab1344d6b578
*/
constructor function ut_xunit_reporter (
self in out nocopy ut_xunit_reporter
) return self as result, overriding member function get_description return varchar2
) not final
/When formatting type body the behavior is also odd with some keywords:
create or replace type body ut_xunit_reporter is
/*
utPLSQL - Version 3
Copyright 2016 - 2019 utPLSQL Project
Licensed under the Apache License, Version 2.0 (the "License"):
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
*/
constructor function ut_xunit_reporter (
self in out nocopy ut_xunit_reporter
) return self as result is
begin
self.init($$plsql_unit);
return;
end;
overriding
member function get_description return varchar2 as
begin
return 'Depracated reporter. Please use Junit.
Provides outcomes in a format conforming with JUnit 4 and above as defined in: https://gist.github.com/kuzuha/232902acab1344d6b578';
end;
end;
/All was done running SQLDeveloper 19.4 (JDK 8 included) and Windows 10 Pro x64.
Manually formatted Statement:
CREATE OR REPLACE FUNCTION get_dep_cols (
in_parse_tree IN XMLTYPE,
in_column_pos IN INTEGER
) RETURN XMLTYPE IS
l_result XMLTYPE;
BEGIN
SELECT XMLQUERY(
q'{
declare function local:analyze-col($col as element()) as element()* {
let $tableAlias := $col/ancestor::QUERY[1]/FROM/FROM_ITEM//TABLE_ALIAS[local-name(..) != 'COLUMN_REF'
and text() = $col/TABLE_ALIAS/text()]
let $tableAliasTable := if ($tableAlias) then (
$tableAlias/preceding::TABLE[1]
) else (
)
let $queryAlias := $col/ancestor::QUERY[1]/FROM/FROM_ITEM//QUERY_ALIAS[local-name(..) != 'COLUMN_REF'
and text() = $col/TABLE_ALIAS/text()]
let $column := $col/COLUMN
let $ret := if ($queryAlias) then (
for $rcol in $col/ancestor::QUERY/WITH/WITH_ITEM[QUERY_ALIAS/text() = $queryAlias/text()]
//SELECT_LIST_ITEM//COLUMN_REF[ancestor::SELECT_LIST_ITEM/COLUMN_ALIAS/text() = $column/text()
or COLUMN/text() = $column/text()]
let $rret := if ($rcol) then (
local:analyze-col($rcol)
) else (
)
return $rret
) else (
let $tables := if ($tableAliasTable) then (
$tableAliasTable
) else (
for $tab in $col/ancestor::QUERY[1]/FROM/FROM_ITEM//*[self::TABLE or self::QUERY_ALIAS]
return $tab
)
for $tab in $tables
return
typeswitch($tab)
case element(QUERY_ALIAS)
return
let $rcol := $col/ancestor::QUERY/WITH/WITH_ITEM[QUERY_ALIAS/text() = $tab/text()]
//SELECT_LIST_ITEM//COLUMN_REF[ancestor::SELECT_LIST_ITEM/COLUMN_ALIAS/text() = $column/text()
or COLUMN/text() = $column/text()]
let $rret := if ($rcol) then (
for $c in $rcol
return local:analyze-col($c)
) else (
)
return $rret
default
return
<column>
<schemaName>
{$tab/../SCHEMA/text()}
</schemaName>
<tableName>
{$tab/text()}
</tableName>
<columnName>
{$column/text()}
</columnName>
</column>
)
return $ret
};
for $col in //SELECT/SELECT_LIST/SELECT_LIST_ITEM[not(ancestor::SELECT_LIST_ITEM)][$columnPos]//COLUMN_REF
let $res := local:analyze-col($col)
return $res
}'
PASSING in_parse_tree, in_column_pos AS "columnPos"
RETURNING CONTENT
)
INTO l_result
FROM dual;
RETURN l_result;
END;
/Formatted statement with default settings:
CREATE OR REPLACE FUNCTION get_dep_cols (
in_parse_tree IN XMLTYPE,
in_column_pos IN INTEGER
) RETURN XMLTYPE IS
l_result XMLTYPE;
BEGIN
SELECT
XMLQUERY(q'{
declare function local:analyze-col($col as element()) as element()* {
let $tableAlias := $col/ancestor::QUERY[1]/FROM/FROM_ITEM//TABLE_ALIAS[local-name(..) != 'COLUMN_REF'
and text() = $col/TABLE_ALIAS/text()]
let $tableAliasTable := if ($tableAlias) then (
$tableAlias/preceding::TABLE[1]
) else (
)
let $queryAlias := $col/ancestor::QUERY[1]/FROM/FROM_ITEM//QUERY_ALIAS[local-name(..) != 'COLUMN_REF'
and text() = $col/TABLE_ALIAS/text()]
let $column := $col/COLUMN
let $ret := if ($queryAlias) then (
for $rcol in $col/ancestor::QUERY/WITH/WITH_ITEM[QUERY_ALIAS/text() = $queryAlias/text()]
//SELECT_LIST_ITEM//COLUMN_REF[ancestor::SELECT_LIST_ITEM/COLUMN_ALIAS/text() = $column/text()
or COLUMN/text() = $column/text()]
let $rret := if ($rcol) then (
local:analyze-col($rcol)
) else (
)
return $rret
) else (
let $tables := if ($tableAliasTable) then (
$tableAliasTable
) else (
for $tab in $col/ancestor::QUERY[1]/FROM/FROM_ITEM//*[self::TABLE or self::QUERY_ALIAS]
return $tab
)
for $tab in $tables
return
typeswitch($tab)
case element(QUERY_ALIAS)
return
let $rcol := $col/ancestor::QUERY/WITH/WITH_ITEM[QUERY_ALIAS/text() = $tab/text()]
//SELECT_LIST_ITEM//COLUMN_REF[ancestor::SELECT_LIST_ITEM/COLUMN_ALIAS/text() = $column/text()
or COLUMN/text() = $column/text()]
let $rret := if ($rcol) then (
for $c in $rcol
return local:analyze-col($c)
) else (
)
return $rret
default
return
<column>
<schemaName>
{$tab/../SCHEMA/text()}
</schemaName>
<tableName>
{$tab/text()}
</tableName>
<columnName>
{$column/text()}
</columnName>
</column>
)
return $ret
};
for $col in //SELECT/SELECT_LIST/SELECT_LIST_ITEM[not(ancestor::SELECT_LIST_ITEM)][$columnPos]//COLUMN_REF
let $res := local:analyze-col($col)
return $res
}'
PASSING in_parse_tree,
in_column_pos
AS
"columnPos"
RETURNING
CONTENT)
INTO l_result
FROM
dual;
RETURN l_result;
END;
/The following code after PASSING in_parse_tree, is aligned on column 4198!
in_column_pos
AS
"columnPos"
RETURNING
CONTENT)The issue happens also with default 20.2 settings (XML and Arbori).
The expected output would be something like this:
CREATE OR REPLACE FUNCTION get_dep_cols (
in_parse_tree IN XMLTYPE,
in_column_pos IN INTEGER
) RETURN XMLTYPE IS
l_result XMLTYPE;
BEGIN
SELECT XMLQUERY(q'{
declare function local:analyze-col($col as element()) as element()* {
let $tableAlias := $col/ancestor::QUERY[1]/FROM/FROM_ITEM//TABLE_ALIAS[local-name(..) != 'COLUMN_REF'
and text() = $col/TABLE_ALIAS/text()]
let $tableAliasTable := if ($tableAlias) then (
$tableAlias/preceding::TABLE[1]
) else (
)
let $queryAlias := $col/ancestor::QUERY[1]/FROM/FROM_ITEM//QUERY_ALIAS[local-name(..) != 'COLUMN_REF'
and text() = $col/TABLE_ALIAS/text()]
let $column := $col/COLUMN
let $ret := if ($queryAlias) then (
for $rcol in $col/ancestor::QUERY/WITH/WITH_ITEM[QUERY_ALIAS/text() = $queryAlias/text()]
//SELECT_LIST_ITEM//COLUMN_REF[ancestor::SELECT_LIST_ITEM/COLUMN_ALIAS/text() = $column/text()
or COLUMN/text() = $column/text()]
let $rret := if ($rcol) then (
local:analyze-col($rcol)
) else (
)
return $rret
) else (
let $tables := if ($tableAliasTable) then (
$tableAliasTable
) else (
for $tab in $col/ancestor::QUERY[1]/FROM/FROM_ITEM//*[self::TABLE or self::QUERY_ALIAS]
return $tab
)
for $tab in $tables
return
typeswitch($tab)
case element(QUERY_ALIAS)
return
let $rcol := $col/ancestor::QUERY/WITH/WITH_ITEM[QUERY_ALIAS/text() = $tab/text()]
//SELECT_LIST_ITEM//COLUMN_REF[ancestor::SELECT_LIST_ITEM/COLUMN_ALIAS/text() = $column/text()
or COLUMN/text() = $column/text()]
let $rret := if ($rcol) then (
for $c in $rcol
return local:analyze-col($c)
) else (
)
return $rret
default
return
<column>
<schemaName>
{$tab/../SCHEMA/text()}
</schemaName>
<tableName>
{$tab/text()}
</tableName>
<columnName>
{$column/text()}
</columnName>
</column>
)
return $ret
};
for $col in //SELECT/SELECT_LIST/SELECT_LIST_ITEM[not(ancestor::SELECT_LIST_ITEM)][$columnPos]//COLUMN_REF
let $res := local:analyze-col($col)
return $res
}'
PASSING in_parse_tree, in_column_pos AS "columnPos"
RETURNING CONTENT
)
INTO l_result
FROM dual;
RETURN l_result;
END;
/For testing purposes it might be simpler to work with this input (using a reduced string_literal).
CREATE OR REPLACE FUNCTION get_dep_cols (
in_parse_tree IN XMLTYPE,
in_column_pos IN INTEGER
) RETURN XMLTYPE IS
l_result XMLTYPE;
BEGIN
SELECT XMLQUERY(q'{
...
}'
PASSING in_parse_tree, in_column_pos AS "columnPos"
RETURNING CONTENT
)
INTO l_result
FROM dual;
RETURN l_result;
END;
/The formatting result is
CREATE OR REPLACE FUNCTION get_dep_cols (
in_parse_tree IN XMLTYPE,
in_column_pos IN INTEGER
) RETURN XMLTYPE IS
l_result XMLTYPE;
BEGIN
SELECT XMLQUERY(q'{
...
}' PASSING in_parse_tree,
in_column_pos AS "columnPos" RETURNING CONTENT)
INTO l_result
FROM dual;
RETURN l_result;
END;
/This issue was described by @wienerri in PR #61.
The following code is formatted correctly with default settings:
UPDATE my_table
SET n01 = 1,
n02 = 2,
n03 = 3,
n04 = my_function(1, 2, 3)
WHERE n01 = 1
AND n02 = 2
AND n03 = my_function(1, 2, 3);With "Line breaks on comma" set to "After" the result looks like this:
UPDATE my_table
SET n01 = 1, n02 = 2
, n03 = 3
, n04 = my_function(1, 2, 3)
WHERE n01 = 1
AND n02 = 2
AND n03 = my_function(1, 2, 3);Expected is the following:
UPDATE my_table
SET n01 = 1
, n02 = 2
, n03 = 3
, n04 = my_function(1, 2, 3)
WHERE n01 = 1
AND n02 = 2
AND n03 = my_function(1, 2, 3);The JavaScript function maxOneEmptyLine eliminates leading spaces on each line. It excludes lines starting with a comment token, since they are not part of the parse-tree.
It looks like conditional compilation tokens are also in need of a special treatment.
This is a manually formatted coded block, it's also the expected formatter result:
CREATE OR REPLACE PROCEDURE p IS
BEGIN
-- comment 1
$IF DBMS_DB_VERSION.VER_LE_12_2 $THEN
-- comment 2
dbms_output.put_line('older');
$ELSE
-- comment 3
dbms_output.put_line('newer');
$END
END;
/After calling the formatter with default settings it looks like this:
CREATE OR REPLACE PROCEDURE p IS
BEGIN
-- comment 1
$IF DBMS_DB_VERSION.VER_LE_12_2 $THEN
-- comment 2
dbms_output.put_line('older');
$ELSE
-- comment 3
dbms_output.put_line('newer');
$END
END;
/Hi,
I use "on comma before" setting
Example:
MERGE INTO tcp_pol_agent_commission_no c
USING (
SELECT DISTINCT a2.name_id_no -- name_id_no number 22 N Agent identifier
,a2.commission_no -- commission_no number 22 N Commission number
,a2.TIMESTAMP -- timestamp date 7 Y Date and time for last insert/update of the record
,
a2.userid -- userid varchar2 8 Y Identification of the user who last inserted/updated the record
,a2.record_version -- record_version number 22 Y Updated whenever a record is inserted/updated to ensure locking
,a2.superordinate_no -- superordinate_no number 22 Y
,
a2.legal_form -- legal_form varchar2 2000 Y
,a2.start_date -- start_date date 7 Y
,a2.end_date -- end_date date 7 Y
,
a2.location_id_no -- location_id_no number 22 Y
,a2.sellerpid -- sellerpid number 22 Y
,a2.ag_channel -- ag_channel number 22 Y Kanál obchodníka - viz XLA_REFERENCE(AGENT_CHANNEL).
,
a2.companyid$$ -- companyid$$ number 22 Y
,a2.agency -- agency varchar2 3 N
,a2.com_group -- com_group varchar2 2 N
,
a2.level_code -- level_code number 22 Y
,a2.distribution -- distribution varchar2 2 Y
FROM tcp_pol_agent_commission_no@rwie_mig_vias
a2
,tcp_mig_vias_m11_adrpol r
WHERE r.role_cislo = 7
AND to_number(r.role_id) = a2.commission_no
)
d ON ( c.commission_no = d.commission_no )
WHEN MATCHED THEN UPDATE
SET start_date = d.start_date
,end_date = d.end_date
WHEN NOT MATCHED THEN
INSERT (
name_id_no
,commission_no
,TIMESTAMP
,userid
,record_version
,superordinate_no
,legal_form
,start_date
,end_date
,location_id_no
,sellerpid
,ag_channel
,companyid$$
,agency
,com_group
,level_code
,distribution )
VALUES
( 629021949 -- d.name_id_no -- name_id_no number 22 N Agent identifier
,d.commission_no -- commission_no number 22 N Commission number
,d.TIMESTAMP -- timestamp date 7 Y Date and time for last insert/update of the record
,d.userid -- userid varchar2 8 Y Identification of the user who last inserted/updated the record
,d.record_version -- record_version number 22 Y Updated whenever a record is inserted/updated to ensure locking
,d.superordinate_no -- superordinate_no number 22 Y
,d.legal_form -- legal_form varchar2 2000 Y
,d.start_date -- start_date date 7 Y
,
d.end_date -- end_date date 7 Y
,d.location_id_no -- location_id_no number 22 Y
,d.sellerpid -- sellerpid number 22 Y
,d.ag_channel -- ag_channel number 22 Y Kanál obchodníka - viz XLA_REFERENCE(AGENT_CHANNEL).
,d.companyid$$ -- companyid$$ number 22 Y
,d.agency -- agency varchar2 3 N
,d.com_group -- com_group varchar2 2 N
,d.level_code -- level_code number 22 Y
,d.
distribution -- distribution varchar2 2 Y
/* */ );
With the default settings the code is formatted as follows:
BEGIN
OPEN c1 FOR SELECT *
FROM same_tab;
END;
/instead the code should be formatted like this:
BEGIN
OPEN c1 FOR
SELECT *
FROM same_tab;
END;
/
We discussed in #19 that the number of arguments is not always a good indicator to split an argument/expression list. That's the formatting result based on the current logic (split list with 5 or more arguments):
PROCEDURE test_dedup_t_obj IS
l_input t_obj_type;
l_actual t_obj_type;
l_expected t_obj_type;
BEGIN
l_input := t_obj_type(obj_type('MY_OWNER', 'VIEW', 'MY_VIEW'), obj_type('MY_OWNER', 'PACKAGE', 'MY_PACKAGE'), obj_type(
'MY_OWNER', 'VIEW', 'MY_VIEW'));
l_expected := t_obj_type(obj_type('MY_OWNER', 'PACKAGE', 'MY_PACKAGE'), obj_type(
'MY_OWNER', 'VIEW', 'MY_VIEW'));
l_actual := type_util.dedup(l_input);
ut.expect(l_actual.count).to_equal(2);
ut.expect(anydata.convertCollection(l_actual)).to_equal(anydata.convertCollection(l_expected)).unordered;
END test_dedup_t_obj;These nested list make the line long. Each list as max of 2 or three arguments only. Hence, no splitting.
I'd like to have a result like this:
PROCEDURE test_dedup_t_obj IS
l_input t_obj_type;
l_actual t_obj_type;
l_expected t_obj_type;
BEGIN
l_input := t_obj_type(
obj_type('MY_OWNER', 'VIEW', 'MY_VIEW'),
obj_type('MY_OWNER', 'PACKAGE', 'MY_PACKAGE'),
obj_type('MY_OWNER', 'VIEW', 'MY_VIEW')
);
l_expected := t_obj_type(
obj_type('MY_OWNER', 'PACKAGE', 'MY_PACKAGE'),
obj_type('MY_OWNER', 'VIEW', 'MY_VIEW')
);
l_actual := type_util.dedup(l_input);
ut.expect(l_actual.count).to_equal(2);
ut.expect(anydata.convertCollection(l_actual)).to_equal(anydata.convertCollection(l_expected)).unordered;
END test_dedup_t_obj;When splitting the outer list then there is no need to split the inner lists anymore. Everything is within the defined maximum line width of 120 chars.
As discussed in #19 calculating the line length exactly is very challenging. However, estimating the line size should be much easier. The result is expected to be better, but certainly not perfect. A defensive approach is preferred to avoid the default line splitting logic, which always leads to an unwanted result. Splitting argument lists which would fit within the line boundaries is the lesser evil.
When using tvdformat with settings for SQLDev 20.2 in SQLcl 20.3 error messages are printed on the console saying that certain symbols are not found.
Here's an example:
SQLcl: Release 20.3 Production on Sat Oct 31 14:28:28 2020
Copyright (c) 1982, 2020, Oracle. All rights reserved.
Connected to:
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
Version 19.9.0.0.0
SQL> select * from dept;
DEPTNO DNAME LOC
---------- -------------- -------------
10 ACCOUNTING NEW YORK
20 RESEARCH DALLAS
30 SALES CHICAGO
40 OPERATIONS BOSTON
SQL> tvdformat *
Formatting SQLcl buffer... Symbol 'create_view#[104,120)' not found
Symbol 'create_view#[107,114)' not found
Symbol 'create_view#[104,120)' not found
done.
1 SELECT *
2* FROM dept;
Thanks Philip for providing direction.
i am currently using your xml and arbori files.
i am using sqlcl 19.1 there i am seeing indentation of procedure args increased,
so tried to below snippet of code you provided. but i am running into parsing error at " -> { ".
tried fews changes but couldnt get around parsing error. arbori format is new to me.
thanks in advance.
removeWhitspaceInDecodeFunction: [node) "(x,y,z)" & [node-1) identifier & (?node-1 = 'DECODE') & [node^) function -> { var parentNode = tuple.get("node"); var descendants = parentNode.descendants(); for (i = 1, len = descendants.length; i < len; i++) { var node = descendants.get(i); var pos = node.from; var nodeIndent = struct.getNewline(pos); if (nodeIndent != null) { struct.putNewline(pos, null); } } };
@wienerri provided a solution approach in #61 which uses a noformatarbori tag to disable a sql_query_or_dml_stmt. This was the trigger to open this enhancement request.
The IntelliJ IDEA and Eclipse IDE use @formatter:off and @formatter:on tags in comments to turn the formatter off and on in a source file. Both products allow to configure other values for the off/on tags. IntelliJ even allows to use regular expressions to identify the on/off tags.
Currently it is not possible to add custom formatter properties in SQLDev. Therefore I suggest to use the default tag names as used in IntelliJ and Eclipse.
Arbori is suited to support the off/on tags approach in an efficient way. However, the current maxOneEmptyLine implementation nukes certain whitespaces to workaround some SQLDev issues. Hence an implementation has to deal with that. This means add an exception in maxOneEmptyLine for nodes not to be formatted or wait for a future SQLDev version where maxOneEmptyLine just does its job and nothing more.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.