spdx / spdx-java-library Goto Github PK
View Code? Open in Web Editor NEWJava library which implements the Java object model for SPDX and provides useful helper functions
License: Apache License 2.0
Java library which implements the Java object model for SPDX and provides useful helper functions
License: Apache License 2.0
According to spec, the field "License information in file" can be omitted.
This clashes with the SpdxFileBuilder where licenseInfosFromFile is required to be non-null.
Currently, ModelObject#clone creates a clone of the instance it is called on inside the passed model store. It does not copy any properties of the original object. The properties of the new object will be:
In the discussion in #106, it turned out that this may be unintended and properties should actually be copied over.
In that case, we should probably fail in case the object already exists in the new store, to avoid accidentally overwriting data (or pass a overwrite flag).
Note: The only usage of clone in the library seems to be inside a test, so changing it won't cause problems in the library. It could be considered a breaking change to public API, however...
There currently isn't a way to delete unused elements.
Add a "delete" method.
Need to track references with some kind of a reference count in the simple storage.
A garbage collection method could be implemented to remove any anonomous unused elements (perhaps just for the simple implementation)
Split off from #108 as there were two issues raised there:
One additional issue I realized: Since we are checking for equivalence, not equality, we need to check equivalence in both directions. Else the listsEquivalent function is not symmetric.
Example: We have list1 = [element11, element12] and list2 = [element21, element22], where element11, element12 and element21 are all equivalent but element22 is completely different. The current algorithm would determine that list1 is equivalent to list2, but list2 is not equivalent to list1.
Here is a short minimal example of a test that passes (using JUnit and AssertJ, should be readable as-is). I skipped the creation of the two SpdxFile instances, as it's not really relevant and I haven't found a good way to create a copy programmatically (clone and copyFrom don't work). The important part is that the two files are identical initially except for using different model stores.
Fwiw, in my case, I had two identical documents in different formats created using SpdxConverter, and deserialized both files.
@Test
public void modelObjectEquivalence() {
SpdxFile file = <...>;
SpdxFile identicalFile = <...>;
file.setCopyrightText(null);
identicalFile.setCopyrightText("Copyright");
assertThat(file.equivalent(identicalFile)).isTrue();
assertThat(identicalFile.equivalent(file)).isFalse();
}
As to what's going on under the hood, the issue lies in this part of the equivalent method: If this has some property that compare does not, it is checked whether the value is an empty collection or noAssertion. If so, it is considered equivalent, else inequivalent.
However:
compare has some property that this does not haveI ran into a super dubious lazy-loading issue (supposedly), related to reading filesAnalyzed from a document deserialized from a json file that did not set this property.
I tried to verify that conversion from tag/value to json using the Python tools does not change any properties. To that end, I wrote a simple test in spdx-testbed:
@Test
public void detectDifferences()
throws IOException, InvalidFileNameException, InvalidSPDXAnalysisException {
var convertedFile = SpdxToolsHelper.deserializeDocument(new File("converted.json"));
var originalFile = SpdxToolsHelper.deserializeDocument(new File("SPDXTagExample-v2.2.spdx"));
var differences = Comparisons.findDifferencesInSerializedJson(convertedFile, originalFile);
assertThat(differences).isEmpty();
}
This test failed, because filesAnalyzed was set to true for the document deserialized from tag/value (named originalFile here), while it was unspecified for the document deserialized from json (named convertedFile).
I first suspected that the json reader does not set the default of true while the tag/value reader does.
This may be one issue, but I ran into something weirder: When setting a breakpoint on the var differences = ... line and evaluating the package in question via
convertedFile.getModelStore().getTypedValue(convertedFile.getDocumentUri(), "SPDXRef-Package")
, the filesAnalyzed value actually came back as true, and the test subsequently passed. This feels like some strange lazy-loading issue, but I can't debug anymore because it stopped behaving like this; I can't reproduce this behavior anymore and the test now consistently fails on my machine.
So...
filesAnalyzed should probably be set to true as default, like the spec saysFor completeness sake, this is the json file that I used. It was created by converting the 2.2 tag/value example for spdx-spec to json using the Python tools. I think most of it is irrelevant though, the important part is that it contains a package glibc which does not have a value for filesAnalyzed.
converted.zip
SPDX 2.2 files should validate differently than SPDX 2.3 which relaxes some of the required fields.
When faced with with an SPDXID larger than java's max int, tools-java throws a NumberFormatException:
Example:
"SPDXID": "SPDXRef-6996049013223528",
Throws:
Error converting: Error converting SPDX file: class java.lang.NumberFormatException For input string: "6996049013223528"
License text containing Full Width Comma's U+FF0C will fail a comparison with text containing a comma U+002C.
Based on a Unicode reference for comma's, the following Unicode characters should all be considered equivalent:
U+002CU+FF0CU+FE10U+FE50This is not really a bug, but I'm noting it here in the issues in case a recent change in behavior trips up any users of the library.
Prior to PR #144 the order of any lists or collections involving any SPDX elements was preserved (e.g. a list of external references, list of checksums). With the introduction of hash maps to improve performance, the order is no longer preserved.
Note that the spec does not guarantee any order and the RDF serializations have never preserved the order - this change will only be noticed in the Tag/Value, Spreadsheet, YAML, JSON, and XML serialization formats.
When using
var licenseRef1 = LicenseInfoFactory.parseSPDXLicenseString("LicenseRef-1");
I get (as expected) LicenseRef-1 in my output SPDX document when using licenseRef1.
On the other hand, when using
var extractedLicenseInfo1 = new ExtractedLicenseInfo(modelStore, documentUri, "LicenseRef-1", copyManager, true);
var licenseRef1 = LicenseInfoFactory.parseSPDXLicenseString("LicenseRef-1");
I get the expected lines
<hasExtractedLicensingInfos>
<licenseId>LicenseRef-1</licenseId>
</hasExtractedLicensingInfos>
but get LicenseRef-gnrtd0 everywhere else in the output document when using licenseRef1.
If this is actually intended behaviour, I would like to know how to reference the extractedLicenseInfo correctly such that the license shows as LicenseRef-1 again.
Same issue as #53, just ran into another edge case: https://regex101.com/r/LQrrUU/1
[email protected]:myorg/myrepo.git -- works!
[email protected]:myorg/my-repo.git -- doesn't work, hyphen in my-repo
[email protected]:my-org/myrepo.git -- doesn't work, hyphen in my-org
Is this the substitute? https://github.com/spdx/spdx-spec/blob/development/v2.2.1/model/SPDX-UML-Class-Diagram.jpg
You might want to actually link to a specific revision so it won't break again, which would be https://github.com/spdx/spdx-spec/blob/2a7aff7afa089a774916bd5c64fc2cb83637ea07/model/SPDX-UML-Class-Diagram.jpg
Yet another technical issue incoming...
It is possible to create an instance of ModelObject using an id that is already in use. In that case, data in the model store will be untouched during instance creation, but will be changed when using the corresponding methods on the instance.
As an example, let's assume that id is not present in the model store before the following lines:
Annotation annotation = new Annotation(modelStore, namespace, id, copyManager, true);
annotation.setAnnotator("Person:annotator");
SpdxFile file = new SpdxFile(modelStore, namespace, id, copyManager, true);
file.setCopyrightText("copyrightText");
What happens is that the first line creates the corresponding StoredTypedItem in the model store, and the second line sets the annotator property. The third line creates a SpdxFile instance, but due to this part of the ModelObject constructor, nothing is changed in the model store. But the fourth line adds the copyrightText property, and we end up with a stored item having an inconsistent set of properties (some from Annotation, some from SpdxFile).
The only fairly quick fix I can think of is to change the semantics of the create boolean flag that is passed:
true, fail if an object with the given id already existsfalse, fail if no object with the given id existsOf course, this could break a bunch of existing code, depending on how it is used.
Remark: As @armintaenzertng pointed out to me, this is also the reason that some weird examples described in #112 (review) are possible, where objects of different classes are erroneously considered equal.
The hasFile property was deprecated in SPDX 2.0 to be replaced with a CONTAINED relationship between the SpdxPackage and the SpdxFile.
WARNING: Fixing this issue may introduce an incompatibility of the hasFile property is used.
The following Spdx Store implementations should be reviewed and possibly modified to remove the use of the hasFile property:
Here it sais, that it is a required property:
https://spdx.org/rdf/terms/#d4e3064
And here you can see that it is missing:
https://github.com/spdx/license-list-data/blob/master/rdfturtle/AFL-2.0.turtle
(It seems to be missing in all the formats, not just turtle)
The id string can be found there as the entity identifier, which is good enough for humans, but not machines.
While reading code, I noticed this part of the list comparison that seems weird to me. Here is my understanding of what's going on in general:
list1list2 that is equivalentHere is my issue with the IndividualUriValue case. Setup:
item instanceOf IndividualUriValuelist2 contains new SimpleUriValue((IndividualUriValue)item). Let's call this newly created instance simpleUri.list2 contains any element satisfying simpleUri.equals(element)element is an instance of any class except SimpleUriValue that implements IndividualUriValue (e.g. ExternalSpdxElement or ReferenceType), it will automatically be falseIn case this is too abstract, I can try to come up with some minimal test cases, but may require some time.
Would love to hear your opinion @goneall to determine whether these are indeed bugs, or I am misunderstanding things.
edit: Fixed the github links (now they link to specific commit instead of master to avoid getting out of sync when master changes)
The following additional issue was split off into #114
One additional issue I realized: Since we are checking for equivalence, not equality, we need to check equivalence in both directions. Else the
listsEquivalentfunction is not symmetric.
Example: We havelist1 = [element11, element12]andlist2 = [element21, element22], whereelement11,element12andelement21are all equivalent butelement22is completely different. The current algorithm would determine thatlist1is equivalent tolist2, butlist2is not equivalent tolist1.
maven deploy - this will deploy to the bintray SPDX toolsWhen comparing 2 SPDX documents with a LicenseRef containing no text, the comparison of those LicenseRef's is false, but no explanation is given.
We probably do not want them to match since we don't have the text to compare, but we could list them in the Extracted Licenses tab as EMPTY.
While writing test cases for a tool, I ran into a confusing scenario. I might be misunderstanding something, so I'll describe the situation as detailed as possible.
SpdxFile file = document.createSpdxFile("SPDXRef-somefile", "./foo.txt", concludedLicense, List.of(), "Copyright 2022 some guy", sha1Checksum).build();
document.getDocumentDescribes().add(file);
add call adds a relationship to the document and increases the reference count on the filedocument.getDocumentDescribes().remove(file);
IModelStore modelStore = document.getModelStore();
modelStore.delete(documentUri, "SPDXRef-somefile");
My impression is that RelatedElementCollection#add increases the reference count on the file (while creating a relationship, when the file is set as the related element), but RelatedElementCollection#remove does not decrease the reference count. As far as I can tell, when the remove method is called with the file as parameter, the reference count is decreased on the relationship, but not on the file itself.
So - is there some logic missing, or is this usage not intended? Or am I simply missing some step in the process?
When trying to convert a tag-value document to YAML I get
java -jar tools-java-1.0.4-jar-with-dependencies.jar Convert doc.spdx doc.yaml
11:00:11.804 [main] ERROR org.spdx.storage.listedlicense.SpdxListedLicenseModelStore - I/O error opening Json TOC URL
Can this by due to the system proxy not being support? If so, would it maybe make sense to add proxy support e.g. via https://github.com/MarkusBernhardt/proxy-vole?
Spec: https://spdx.github.io/spdx-spec/3-package-information/#37-package-download-location
Code:
Here is a link to a bunch of test cases that should work according to the spec, but do not: https://regex101.com/r/mb4tWm/1
For reference in case that link dies, here's a summary of ones that do and do not work:
git://git.myproject.org/MyProject.git@master ✅
git://git.myproject.org/MyOrg/MyProject.git@master ✅
[email protected]:MyProject ✅
[email protected]:MyOrg/MyProject ❌
[email protected]:MyProject.git ❌
[email protected]:MyOrg/MyProject.git ❌
[email protected]:MyProject@main ❌
[email protected]:MyProject@6338c7a2525e055a05bae1580e4dd189c2feff7b ❌
The file below was generated by SCANOSS (in JSON then I converted to tag:value with online tool).
It contains the line:
PackageLicenseDeclared: (GPL-2.0-only AND LicenseRef-scancode-unknown-license-reference AND BSD-2-Clause AND BSD-3-Clause AND LGPL-3.0-only AND MIT)
but LicenseRef-scancode-unknown-license-reference is not defined in the file.
So I consider the file invalid. The validator should at least issue a warning. What do you think?
This is a rather serious regression caused by PR #144
In the final JSON generated, there are three different name-value pairs named as "name". This doesn't seem to comply with the SPDX standard, and it lacks precision.
As reported in spdx/license-list-XML#1319, the comment syntax of groff, and therefore that of the man-pages, isn't supported.
The implementation is here:
groff comments basically start with .\". If I have some time, I'll try and fix it, but in the meantime I'll report it :)
Transactions are not supported in most storage classes, but we can implement the locking.
The function InMemSpdxStore.delete(String, String) takes significant CPU for large documents.
This is due to checking if the element ID is in use. It basically cycles through all other values stored in all other elements checking.
One possible design approach is to maintain a reference count for each of the element ID's. Care would need to be taken that these reference counts are maintained in a threadsafe manner.
This issue is one of the causes for spdx/spdx-online-tools#289
One way to speed up the verification algorithm is to cache the results of each element being verified. It will take up more memory, but save having to re-parse and traverse the graph for elements if they are referenced more than once (e.g. within a relationship).
Since the license matching is tokanized and the var tags assume the regular expression is a token, it likely will not match a string in the middle of an expression.
It will also match when the template has an incorrect space (see LicenseListXML issue spdx/license-list-XML#1146).
ISerializableModelStore modelStore = new MultiFormatStore(new InMemSpdxStore(), MultiFormatStore.Format.XML);
String documentUri = "some_namespace";
ModelCopyManager copyManager = new ModelCopyManager();
SpdxDocument document = SpdxModelFactory.createSpdxDocument(modelStore, documentUri, copyManager);
document.setSpecVersion(Version.TWO_POINT_THREE_VERSION);
document.setName("SPDX-tool-test");
Checksum sha1Checksum = Checksum.create(modelStore, documentUri, ChecksumAlgorithm.SHA1, "d6a770ba38583ed4bb4525bd96e50461655d2758");
AnyLicenseInfo concludedLicense = LicenseInfoFactory.parseSPDXLicenseString("LGPL-3.0-only");
SpdxFile file = document.createSpdxFile("SPDXRef-somefile", "./foo.txt", concludedLicense,
List.of(), "Copyright 2022 some guy", sha1Checksum)
.build();
document.getDocumentDescribes().add(file);
assertThat(modelStore.getValue(documentUri, "SPDXRef-DOCUMENT", "documentNamespace")).isEmpty();
modelStore.serialize(documentUri, new FileOutputStream("output.xml"));
SpdxDocument newDocument = SpdxToolsHelper.deserializeDocument(new File("output.xml"));
assertThat(newDocument.getModelStore().getValue(newDocument.getDocumentUri(), "SPDXRef-DOCUMENT", "documentNamespace").get()).isEqualTo("some_namespace");
The code above creates a minimal SpdxDocument, serializes it and then deserializes it again.
Take note of the two assertion statements:
Before serialization, there is no value named documentNamespace saved in the modelStore.
After deserialization, the value has been set to that of the documentUri.
Thus, one of the procedures -- either generating a document from scratch or deserializing an existing one -- seems to be buggy. This also raises the question of why the documentNamespace property is desirable in the first place, as it seems to simply mirror the documentUri.
This issue is probably related to spdx/spdx-java-tagvalue-store#26
I was recently evaluating org.spdx.utility.compare.LicenseCompareHelper, and noticed that it doesn't detect any licenses or exceptions in a text that contains multiple licenses and/or exceptions. Specifically, I was testing with the license text from the JavaMail project which is CDDL-1.1 OR GPL-2.0 WITH Classpath-exception-2.0, and which I would expect to find a match for all three SPDX identifiers in that expression (albeit I wasn't expecting it to construct a license expression, though that would be very nice too!).
More specifically, I expected the following code to print false three times, but instead it prints true three times:
String text = /* Code to read https://raw.githubusercontent.com/javaee/javamail/master/LICENSE.txt */
System.out.println(LicenseCompareHelper.isTextStandardLicense(text, LicenseInfoFactory.getListedLicenseById("CDDL-1.1")).isDifferenceFound());
System.out.println(LicenseCompareHelper.isTextStandardLicense(text, LicenseInfoFactory.getListedLicenseById("GPL-2.0")).isDifferenceFound()); // Perhaps this should be GPL-2.0-only?
System.out.println(LicenseCompareHelper.isTextStandardException(text, LicenseInfoFactory.getListedExceptionById("Classpath-exception-2.0")).isDifferenceFound());(apologies for any syntax errors in this code - this is hand translated from the actual Clojure code I wrote)
Is matching of multi-license texts something that's in scope for the project, and if so might this be a potential new feature?
Hello,
My team is working on enhancing the functionalities of SW360 (https://github.com/eclipse/sw360) - a software component catalog application. We plan to replace the old library used in SW360 with this library. But we are facing some problems so I come here to see if I can get some help.
We are using writeToFile method (https://github.com/spdx/Spdx-Java-Library/blob/master/src/main/java/org/spdx/library/Read.java#L124) and readFile method (https://github.com/spdx/Spdx-Java-Library/blob/master/src/main/java/org/spdx/library/Write.java#L97) to implement the Import/Export functions of SW360. However, these methods need one parameter modelStore, but as we understand, this interface was not implemented yet.
Ref:
Could you tell me if our understanding is correct or not?
Another question is, we found this message in the README.md:
The default storage interface is an in-memory Map which should be sufficient for light weight usage of the library.
Does it mean we cannot use this library to read or write the large size file?
Thank you in advance!
Hi, I am wondering where to put the Vulnerabilities or CVE info for SBOM packages. In the official document, such reference should be put in external reference, but only two types are provided. None of them are suitable for CVE. However, the example here in this issue provide a totally different solution, which has a huge gap between the example we previously referred to. These examples make me confused. Which one is the real SPDX format? What is the true official format for vulnerability (CVE) information?
It would help first time users to create some examples for common library usage.
Some ideas for different examples:
As of v2.3, copyrightText is not mandatory anymore for packages, files and snippets. Instead, it is stated in the specification:
If the Copyright Text field is not present for a package, it implies an equivalent meaning to NOASSERTION
ModelObject#createPackage, ModelObject#createSpdxFile and ModelObject#createSpdxSnippet all still require a String copyrightText. When set to null, the .verify() method will log an error saying
"Missing required copyright text for packagename in packagename"
Disclaimer: I don't have a good understanding of the "external" entities ExternalExtractedLicenseInfo and ExternalSpdxElement, but was rather following the code.
I tried to use a ExternalExtractedLicenseInfo in a document, adding it to the list of extractedLicenseInfos, and to serialize that doc to json. Then doc.verify() passes, but when trying to serialize to json, the error Extracted License Infos not of type ExtractedLicensingInfo. That feels wrong to me, since ExternalExtractedLicenseInfo extends ExtractedLicenseInfo.
A halfway complete test case: Here, doc is some minimal document. The error is thrown on the last line, when trying to serialize the document.
var externalDocumentRef = doc.createExternalDocumentRef("DocumentRef-1", "externalDocUri", sha1Checksum);
var externalLicenseInfo = new ExternalExtractedLicenseInfo(doc.getModelStore(), doc.getDocumentUri(), "DocumentRef-1:LicenseRef-XXX", doc.getCopyManager(), true);
doc.setExternalDocumentRefs(List.of(externalDocumentRef));
doc.setExtractedLicenseInfos(List.of(externalLicenseInfo));
assertThat(doc.verify()).isEmpty();
var serializer = new JacksonSerializer(new ObjectMapper(),
MultiFormatStore.Format.JSON_PRETTY, MultiFormatStore.Verbose.COMPACT,
doc.getModelStore());
var jsonNode = serializer.docToJsonNode(doc.getDocumentUri());
e.g. SPDX Listed License
According to spec, an extractedLicenseInfo has the property LicenseCrossReference which I assumed to be implemented by the class CrossRef.
extractedLicenseInfo has no setter for a CrossRef object, though, only for a string collection seeAlso. Which for current purposes is totally fine as the intent to provide a URL is still taken care of. I just wondered if seeAlso should actually be a (collection of) CrossRefs
Bintray is retiring their service on May 1. Prior to retirement, we need to start publishing an alternative package storage provider.
Suggest both Maven Central and Github Packages.
This can be automated using Github actions. See https://docs.github.com/en/actions/guides/publishing-java-packages-with-maven#publishing-packages-to-the-maven-central-repository-and-github-packages
As per the License Matching Guidelines section 6, comment characters should be ignored when matching licenses.
Currently, comment characters are not ignored in the license matching algorithm.
Both the SpdxFileBuilder and the SpdxPackageBuilder have methods setAttributionText and addAttributionText. According to the specification, snippets support attributions, too, so it would be convenient to have them accessible in the builder.
Per SPDX spec issue spdx/spdx-spec#282
Hi,
Currently, we are working on building an SPDX document from scratch. We referred to the example here. Everything goes fine until we need to refer to a package that has already been created. We do this because we construct the graph structure from top to bottom. From the example below, we want to refer to the dependencies A again (for adding relationships) when we find A is a dependency of C. This is common when a dependency is referred to multiple times.
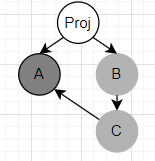
But seems that we cannot do that directly. There is no function designed for retrieving the SpdxItems by SpdxId directly. Method getItem() is protected and we cannot access that. We only found a method called getAllItems(), but that is obviously too heavy for retrieving only one package item. Is there any similar functions that can do this?
Comparing licenses which contain thin spaces (e.g. Technology — Portable) fails.
This can be resolved by normalizing all thin spaces to regular spaces.
See discussion in the License List XML PR #1175 for reference.
current implementation of storage uses immutable lists for collections which is now a performance problem when implementing the collections interface in the library.
Currently, when serializing an SPDX document all properties for listed licenses are copied into the serialized file. Although this can be convenient when you want to access the properties without having to refer to the listed license RDF files accessible through RDFa on the spdx.org/licenses or through other RDF formats in the spdx-license-data repo, it also expands the size of the file significantly.
Adding an option either during creation of the store or to the deserialization method provide flexibility to the producers of the RDF file.
Adding an option to the CopyManager copy functions to not copy the details of any listed license or exception will allow utilities such as the SPDX Converter to optionally ignore these details.
for NPE prevention
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
{kind=link}
{kind=link}