This repo provides a TensorFlow-based implementation of the wonderful paper "PWC-Net: CNNs for Optical Flow Using Pyramid, Warping, and Cost Volume," by Deqing Sun et al. (CVPR 2018).
There are already a few attempts at implementing PWC-Net using TensorFlow out there. However, they either use outdated architectures of the paper's CNN networks, only provide TF inference (no TF training), only work on Linux platforms, and do not support multi-GPU training.
This implementation provides both TF-based training and inference. It is portable: because it doesn't use any dynamically loaded CUDA-based TensorFlow user ops, it works on Linux and Windows. It also supports multi-GPU training (the notebooks and results shown here were collected on a GTX 1080 Ti paired with a Titan X). The code also allows for mixed-precision training.
Finally, as shown in the "Links to pre-trained models" section, we achieve better results than the ones reported in the official paper on the challenging MPI-Sintel 'final' dataset.
- Background
- Environment Setup
- Links to pre-trained models
- PWC-Net
- Datasets
- References
- Acknowledgments
The purpose of optical flow estimation is to generate a dense 2D real-valued (u,v vector) map of the motion occurring from one video frame to the next. This information can be very useful when trying to solve computer vision problems such as object tracking, action recognition, video object segmentation, etc.
Figure [2017a] (a) below shows training pairs (black and white frames 0 and 1) from the Middlebury Optical Flow dataset as well as the their color-coded optical flow ground truth. Figure (b) indicates the color coding used for easy visualization of the (u,v) flow fields. Usually, vector orientation is represented by color hue while vector length is encoded by color saturation:

The most common measures used to evaluate the quality of optical flow estimation are angular error (AE) and endpoint error (EPE). The angular error between two optical flow vectors (u0, v0) and (u1, v1) is defined as arccos((u0, v0) . (u1, v1)). The endpoint error measures the distance between the endpoints of two optical flow vectors (u0, v0) and (u1, v1) and is defined as sqrt((u0 - u1)2 + (v0 - v1)2).
The code in this repo was developed and tested using Anaconda3 v.5.2.0. To reproduce our conda environment, please refer to the following files:
On Ubuntu:
On Windows:
Pre-trained models can be found here. They come in two flavors: "small" (sm, with 4,705,064 learned parameters) models don't use dense connections or residual connections, "large" (lg, with 14,079,050 learned parameters) models do. They are all built with a 6-level pyramid, upsampling level 2 by 4 in each dimension to generate the final prediction, and construct an 81-channel cost volume at each level from a search range (maximum displacement) of 4.
Please note that we trained these models using slightly different dataset and learning rate schedules. The official multistep schedule discussed in [2018a] is as follows: Slong 1.2M iters training, batch size 8 + Sfine 500k iters finetuning, batch size 4). Ours is Slong only, 1.2M iters, batch size 8, on a mix of FlyingChairs and FlyingThings3DHalfRes. FlyingThings3DHalfRes is our own version of FlyingThings3D where every input image pair and groundtruth flow has been downsampled by two in each dimension. We also use a different set of augmentation techniques.
| Model name | Notebooks | FlyingChairs (384x512) AEPE | Sintel clean (436x1024) AEPE | Sintel final (436x1024) AEPE |
|---|---|---|---|---|
pwcnet-lg-6-2-multisteps-chairsthingsmix |
train | 1.44 (notebook) | 2.60 (notebook) | 3.70 (notebook) |
pwcnet-sm-6-2-multisteps-chairsthingsmix |
train | 1.71 (notebook) | 2.96 (notebook) | 3.83 (notebook) |
As a reference, here are the official, reported results:

We also measured the following MPI-Sintel (436 x 1024) inference times on a few GPUs:
| Model name | Titan X | GTX 1080 | GTX 1080 Ti |
|---|---|---|---|
pwcnet-lg-6-2-cyclic-chairsthingsmix |
90ms | 81ms | 68ms |
pwcnet-sm-6-2-cyclic-chairsthingsmix |
68.5ms | 64.4ms | 53.8ms |
A few clarifications about the numbers above...
First, please note that this implementation is, by design, portable, i.e., it doesn't use any user-defined CUDA kernels whereas the official NVidia implementation does. Ours will work on any OS and any hardware configuration (even one without a GPU) that can run TensorFlow.
Second, the timing numbers we report are the inference times of the models trained on FlyingChairs and FlyingThings3DHalfRes. These are models that you can train longer if you want to, or finetune using an additional dataset, should you want to do so. In other words, these graphs haven't been frozen yet.
In a typical production environment, you would freeze the model after final training/finetuning and optimize the graph to whatever platform(s) you need to distribute them on using TensorFlow XLA or TensorRT. In that important context, the inference numbers we report on unoptimized graphs are rather meaningless.
Per [2018a], PWC Net improves on FlowNet2 [2016a] by adding domain knowledge into the design of the network. The basic idea behind optical flow estimation it that a pixel will retain most of its brightness over time despite a positional change from one frame to the next ("brightness" constancy). We can grab a small patch around a pixel in video frame 1 and find another small patch in video frame 2 that will maximize some function (e.g., normalized cross correlation) of the two patches. Sliding that patch over the entire frame 1, looking for a peak, generates what's called a cost volume (the C in PWC). This techniques is fairly robust (invariant to color change) but is expensive to compute. In some cases, you may need a fairly large patch to reduce the number of false positives in frame1, raising the complexity even more.
To alleviate the cost of generating the cost volume, the first optimization is to use pyramidal processing (the P in PWC). Using a lower resolution image lets you perform the search sliding a smaller patch from frame 1 over a smaller version of frame 2, yielding a smaller motion vector, then use that information as a hint to perform a more targeted search at the next level of resolution in the pyramid. That multiscale motion estimation can be performed in the image domain or in the feature domain (i.e., using the downscaled feature maps generated by a convnet). In practice, PWC warps (the W in PWC) frame 1 using an upsampled version of the motion flow estimated at a lower resolution because this will lead to searching for a smaller motion increment in the next higher resolution level of the pyramid (hence, allowing for a smaller search range). Here's a screenshot of a talk given by Deqing Sun that illustrates this process using a 2-level pyramid:

Note that none of the three optimizations used here (P/W/C) are unique to PWC-Net. These are techniques that were also used in SpyNet [2016b] and FlowNet2 [2016a]. However, here, they are used on the CNN features, rather than on an image pyramid:

The authors also acknowledge the fact that careful data augmentation (e.g., adding horizontal flipping) was necessary to reach best performance. To improve robustness, the authors also recommend training on multiple datasets (Sintel+KITTI+HD1K, for example) with careful class imbalance rebalancing.
Since this algorithm only works on two continuous frames at a time, it has the same limitations as methods that only use image pairs (instead of n frames with n>2). Namely, if an object moves out of frame, the predicted flow will likely have a large EPE. As the authors remark, techniques that use a larger number of frames can accommodate for this limitation by propagating motion information over time. The model also sometimes fails for small, fast moving objects.
Here's a picture of the network architecture described in [2018a]:

The recommended way to test this implementation is to use the following Jupyter notebooks:
-
Optical flow datasets (prep and inspect): In this notebook, we:- Load the optical flow datasets and (automatically) create the additional data necessary to train our models (one-time operation on first-time load).
- Show sample images/flows from each dataset. Note that you must have downloaded and unpacked the master data files already. See [Datasets] for download links to each dataset.
-
PWC-Net-large model training (with multisteps learning rate schedule): In this notebook, we:- Use a PWC-Net-large model (with dense and residual connections), 6 level pyramid, upsample level 2 by 4 as the final flow prediction
- Train the model on a mix of the
FlyingChairsandFlyingThings3DHalfResdataset using the Slong schedule described in [2016a] - In
PWC-Net-small model training (with multisteps learning rate schedule), we train the small version of the model (no dense or residual connections) - In
PWC-Net-large model training (with cyclical learning rate schedule), we train the large version of the model using the Cyclicshort schedule - In
PWC-Net-small model training (with cyclical learning rate schedule), we train the small version of the model (no dense or residual connections) using the Cyclicshort schedule
-
PWC-Net-large model evaluation (on FlyingChairs validation split): In this notebook, we:- Evaluate the PWC-Net-large model trained on a mix of the
FlyingChairsandFlyingThings3DHalfResdatasets using the Slong schedule - Run the evaluation on the validation split of the
FlyingChairsdataset, yielding an average EPE of 1.44 - Perform basic error analysis
- Evaluate the PWC-Net-large model trained on a mix of the
-
PWC-Net-large model evaluation (on MPI-Sintel 'clean'): In this notebook, we:- Evaluate the PWC-Net-large model trained on a mix of the
FlyingChairsandFlyingThings3DHalfResdatasets using the Slong schedule - Run the evaluation on the 'clean' version of the MPI-Sintel dataset, yielding an average EPE of 2.60
- Perform basic error analysis
- Evaluate the PWC-Net-large model trained on a mix of the
-
PWC-Net-large model evaluation (on MPI-Sintel 'final'): In this notebook, we:- Evaluate the PWC-Net-large model trained on a mix of the
FlyingChairsandFlyingThings3DHalfResdatasets using the Slong schedule - Run the evaluation on the 'final' version of the MPI-Sintel dataset, yielding an average EPE of 3.70
- Perform basic error analysis
- Evaluate the PWC-Net-large model trained on a mix of the
Differently from the original paper, we do not train on FlyingChairs and FlyingThings3D sequentially (i.e, pre-train on FlyingChairs then finetune on FlyingThings3D). This is because the average flow magnitude on the MPI-Sintel dataset is only 13.5, while the average flow magnitudes on FlyingChairs and FlyingThings3D are 11.1 and 38, respectively. In our experiments, finetuning on FlyingThings3D would only yield worse results on MPI-Sintel.
We got more stable results by using a half-resolution version of the FlyingThings3D dataset with an average flow magnitude of 19, much closer to FlyingChairs and MPI-Sintel in that respect. We then trained on a mix of the FlyingChairs and FlyingThings3DHalfRes datasets. This mix, of course, could be extended with additional datasets.
Here are the training curves for the Slong training notebooks listed above:



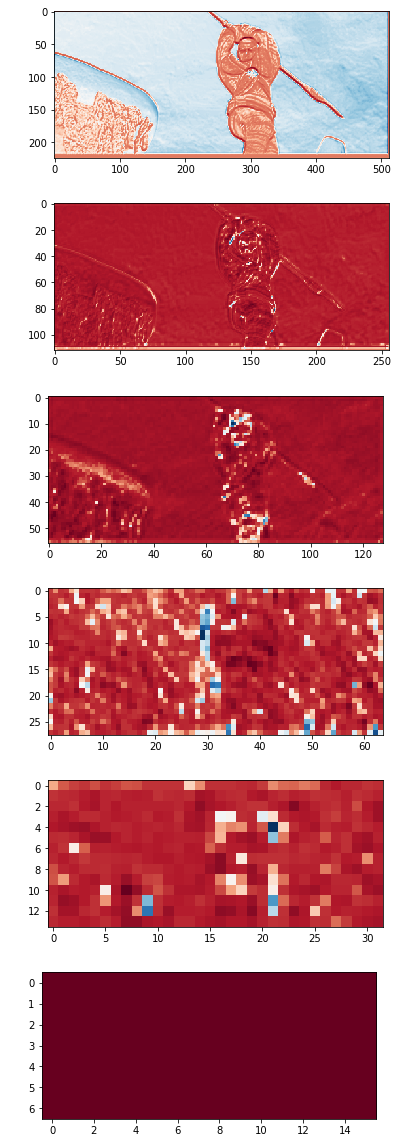
Note that, if you click on the IMAGE tab in Tensorboard while running the training notebooks above, you will be able to visualize the progress of the training on a few validation samples (including the predicted flows at each pyramid level), as demonstrated here:


If you don't want to use the long training schedule, but still would like to play with this code, try our very short cyclic learning rate schedule (100k iters, batch size 8). The results are nowhere near as good, but they allow for quick experimentation:
| Model name | Notebooks | FlyingChairs (384x512) AEPE | Sintel clean (436x1024) AEPE | Sintel final (436x1024) AEPE |
|---|---|---|---|---|
pwcnet-lg-6-2-cyclic-chairsthingsmix |
train | 2.67 (notebook) | 3.99 (notebook) | 5.08 (notebook) |
pwcnet-sm-6-2-cyclic-chairsthingsmix |
train | 2.79 (notebook) | 4.34 (notebook) | 5.3 (notebook) |
Below are the training curves for the Cyclicshort training notebooks:



You can speed up training even further by using mixed-precision training. But, again, don't expect the same level of accuracy:
| Model name | Notebooks | FlyingChairs (384x512) AEPE | Sintel clean (436x1024) AEPE | Sintel final (436x1024) AEPE |
|---|---|---|---|---|
pwcnet-sm-6-2-cyclic-chairsthingsmix-fp16 |
train | 2.47 (notebook) | 3.77 (notebook) | 4.90 (notebook) |
As shown in the evaluation notebooks, and as expected, it becomes harder for the PWC-Net models to deliver accurate flow predictions if the average flow magnitude from one frame to the next is high:

It is especially hard for this -- and any other 2-frame based motion estimator! -- model to generate accurate predictions when picture elements simply disappear out-of-frame or suddenly fly-in:

Still, when the average motion is moderate, both the small and large models generate remarkable results:

There are two ways you can call the code provided here to generate flow predictions for your own dataset:
- Pass a list of image pairs to a
ModelPWCNetobject using itspredict_from_img_pairs()method - Pass an
OpticalFlowDatasetobject to aModelPWCNetobject and call itspredict()method
If you want to use a pre-trained PWC-Net model on your own set of images, you can pass a list of image pairs to a ModelPWCNet object using its predict_from_img_pairs() method, as demonstrated here:
from __future__ import absolute_import, division, print_function
from copy import deepcopy
from skimage.io import imread
from model_pwcnet import ModelPWCNet, _DEFAULT_PWCNET_TEST_OPTIONS
from visualize import display_img_pairs_w_flows
# Build a list of image pairs to process
img_pairs = []
for pair in range(1, 4):
image_path1 = f'./samples/mpisintel_test_clean_ambush_1_frame_00{pair:02d}.png'
image_path2 = f'./samples/mpisintel_test_clean_ambush_1_frame_00{pair+1:02d}.png'
image1, image2 = imread(image_path1), imread(image_path2)
img_pairs.append((image1, image2))
# TODO: Set device to use for inference
# Here, we're using a GPU (use '/device:CPU:0' to run inference on the CPU)
gpu_devices = ['/device:GPU:0']
controller = '/device:GPU:0'
# TODO: Set the path to the trained model (make sure you've downloaded it first from http://bit.ly/tfoptflow)
ckpt_path = './models/pwcnet-lg-6-2-multisteps-chairsthingsmix/pwcnet.ckpt-595000'
# Configure the model for inference, starting with the default options
nn_opts = deepcopy(_DEFAULT_PWCNET_TEST_OPTIONS)
nn_opts['verbose'] = True
nn_opts['ckpt_path'] = ckpt_path
nn_opts['batch_size'] = 1
nn_opts['gpu_devices'] = gpu_devices
nn_opts['controller'] = controller
# We're running the PWC-Net-large model in quarter-resolution mode
# That is, with a 6 level pyramid, and upsampling of level 2 by 4 in each dimension as the final flow prediction
nn_opts['use_dense_cx'] = True
nn_opts['use_res_cx'] = True
nn_opts['pyr_lvls'] = 6
nn_opts['flow_pred_lvl'] = 2
# The size of the images in this dataset are not multiples of 64, while the model generates flows padded to multiples
# of 64. Hence, we need to crop the predicted flows to their original size
nn_opts['adapt_info'] = (1, 436, 1024, 2)
# Instantiate the model in inference mode and display the model configuration
nn = ModelPWCNet(mode='test', options=nn_opts)
nn.print_config()
# Generate the predictions and display them
pred_labels = nn.predict_from_img_pairs(img_pairs, batch_size=1, verbose=False)
display_img_pairs_w_flows(img_pairs, pred_labels)The code above can be found in the pwcnet_predict_from_img_pairs.ipynb notebook and the pwcnet_predict_from_img_pairs.py script.
If you want to train a PWC-Net model from scratch, or finetune a pre-trained PWC-Net model using your own dataset, you will need to implement a dataset handler that derives from the OpticalFlowDataset base class in dataset_base.py.
We provide several dataset handlers for well known datasets, such as MPI-Sintel (dataset_mpisintel.py), FlyingChairs (dataset_flyingchairs.py), FlyingThings3D (dataset_flyingthings3d.py), and KITTI (dataset_kitti.py). Anyone of them is a good starting point to figure out how to implement your own.
Please note that that this is not complicated work; the derived class does little beyond telling the base class which list of files are to be used for training, validation, and testing, leaving the heavy lifting to the base class.
Once you have a data handler, you can pass it to a ModelPWCNet object and call its predict() method to generate flow predictions for its test split, as shown in the pwcnet_predict.ipynb notebook and the pwcnet_predict.py script.
Datasets most commonly used for optical flow estimation include:
- FlyingThings3D [image pairs + flows + all_unused_files.txt]
- FlyingChairs [images pairs + flows + FlyingChairs_train_val split]
- MPI Sintel [zip]
- KITTI Flow 2012 [zip] and/or KITTI Flow 2015 [zip]
Additional optical flow datasets (not used here):
Per [2018a], KITTI and Sintel are currently the most challenging and widely-used benchmarks for optical flow. The KITTI benchmark is targeted at autonomous driving applications and its semi-dense ground truth is collected using LIDAR. The 2012 set only consists of static scenes. The 2015 set is extended to dynamic scenes via human annotations and more challenging to existing methods because of the large motion, severe illumination changes, and occlusions.
The Sintel benchmark is created using the open source graphics movie "Sintel" with two passes, clean and final. The final pass contains strong atmospheric effects, motion blur, and camera noise, which cause severe problems to existing methods.
- [2018a] Sun et al. 2018. PWC-Net: CNNs for Optical Flow Using Pyramid, Warping, and Cost Volume. [arXiv] [web] [PyTorch (Official)] [PyTorch] [PyTorch] [Caffe (Official)] [TensorFlow] [TensorFlow] [Video] [Video]
- [2017a] Baghaie et al. 2017. Dense Descriptors for Optical Flow Estimation: A Comparative Study. [web]
- [2016a] Ilg et al. 2016. FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks. [arXiv] [PyTorch (Official)] [TensorFlow]
- [2016b] Ranjan et al. 2016. SpyNet: Optical Flow Estimation using a Spatial Pyramid Network. [arXiv] [Torch (Official)] [PyTorch]
- [2015a] Fischer et al. 2015. FlowNet: Learning Optical Flow with Convolutional Networks. [arXiv] [Tensorflow (FlowNet-S)]
Other TensorFlow implementations we are indebted to:
- https://github.com/daigo0927/PWC-Net_tf by daigo0927
- https://github.com/djl11/PWC_Net_TensorFlow by djl11
- https://github.com/tensorpack/tensorpack/tree/master/examples/OpticalFlow by PatWie
@InProceedings{Sun2018PWC-Net,
author = {Deqing Sun and Xiaodong Yang and Ming-Yu Liu and Jan Kautz},
title = {{PWC-Net}: {CNNs} for Optical Flow Using Pyramid, Warping, and Cost Volume},
booktitle = CVPR,
year = {2018},
}
@InProceedings\{DFIB15,
author = "A. Dosovitskiy and P. Fischer and E. Ilg and P. H{\"a}usser and C. Hazirbas and V. Golkov and P. v.d. Smagt and D. Cremers and T. Brox",
title = "FlowNet: Learning Optical Flow with Convolutional Networks",
booktitle = "IEEE International Conference on Computer Vision (ICCV)",
month = "Dec",
year = "2015",
url = "http://lmb.informatik.uni-freiburg.de//Publications/2015/DFIB15"
}
If you have any questions about this work, please feel free to contact us here:




































































































































{kind=link}