oneflow-inc / dlperf Goto Github PK
View Code? Open in Web Editor NEWDeepLearning Framework Performance Profiling Toolkit
License: Apache License 2.0
DeepLearning Framework Performance Profiling Toolkit
License: Apache License 2.0































































































































































1.框架安装过程中,可能不一定会自带tensorflow_hub,tensorflow_addons,可以提醒评测人员,如果没有pip安装一下。
2.gin这个包也可能原始的环境中没有,可以提示一下评测人员安装,并且要注意不是直接pip gin,而是得pip gin-config。
3.直接执行混合精度的这个语句:bash run_single_node.sh 64 fp16,似乎会报错:run_single_node.sh:line 9 : [: fp16: integer expression expected. 因此是不是前面的参数还是补齐一下再运行会更好一些?
4.tf2.x我复现了不开xla的性能结果,但是想自验开xla的情况,直接将use_xla设置为了true,但是性能结果与不开一致。然后发现打出来的日志里,无论是开与不开都有以下几句:
XLA service 0x55a2805f39c0 initialized for platform Host (this does not guarantee that XLA will be used). Devices:StreamExecutor device (0): Host, Default Version
XLA service 0x55a28065fd40 initialized for platform CUDA (this does not guarantee that XLA will be used). Devices: StreamExecutor device (0): Tesla V100-SXM2-16GB, Compute Capability 7.0
是不是这意味着 很可能开关上把use_xla设置为了true,但是实际上运行过程中xla仍旧未能使能?
以上是我在运行过程中遇到的一些坑与疑惑,还请有时间check一下,解答一下,谢谢!
我复现单机单卡下Bert Base FP32的性能,遇到脚本一直提示我LoadServer失败:
日志信息:
Log file created at: 2020/12/01 02:57:51
Running on machine: cb48a14bb95c
Log line format: [IWEF]mmdd hh:mm:ss.uuuuuu threadid file:line] msg
I1201 02:57:51.346987 5030 global.h:32] NewGlobal 14cudaDeviceProp
I1201 02:57:51.846197 5030 global.h:32] NewGlobal N7oneflow7EnvDescE
I1201 02:57:51.846268 5030 global.h:32] NewGlobal N7oneflow10CtrlServerE
I1201 02:57:51.849647 5030 ctrl_server.cpp:53] CtrlServer listening on 0.0.0.0:49851
I1201 02:57:51.849778 5030 global.h:32] NewGlobal N7oneflow10CtrlClientE
I1201 02:57:52.290592 5030 ctrl_client.cpp:234] LoadServer 127.0.0.1 Failed at 0 times
I1201 02:58:02.290933 5030 ctrl_client.cpp:234] LoadServer 127.0.0.1 Failed at 1 times
I1201 02:58:12.291249 5030 ctrl_client.cpp:234] LoadServer 127.0.0.1 Failed at 2 times
I1201 02:58:22.291574 5030 ctrl_client.cpp:234] LoadServer 127.0.0.1 Failed at 3 times
I1201 02:58:32.291877 5030 ctrl_client.cpp:234] LoadServer 127.0.0.1 Failed at 4 times
I1201 02:58:42.292199 5030 ctrl_client.cpp:234] LoadServer 127.0.0.1 Failed at 5 times
I1201 02:58:52.292503 5030 ctrl_client.cpp:234] LoadServer 127.0.0.1 Failed at 6 times
I1201 02:59:02.292829 5030 ctrl_client.cpp:234] LoadServer 127.0.0.1 Failed at 7 times
I1201 02:59:12.293128 5030 ctrl_client.cpp:234] LoadServer 127.0.0.1 Failed at 8 times
I1201 02:59:22.293431 5030 ctrl_client.cpp:234] LoadServer 127.0.0.1 Failed at 9 times
oneflow-cu110 0.2.0NUM_NODES=${1:-1}
GPU_NUM_PER_NODE=${2:-1}
BSZ_PER_DEVICE=${3:-32}
BENCH_ROOT=/workspace/Bert-benchmark/OneFlow-Benchmark/LanguageModeling/BERT
DATA_ROOT=./wiki_ofrecord_seq_len_128_example
DATA_PART_NUM=1
if [ -n "$4" ]; then
NODE_IPS=$4
else
NODE_IPS='10.11.0.2','10.11.0.3','10.11.0.4','10.11.0.5'
fi
NODE_IPS=""
rm -rf ./log
mkdir ./log
export PYTHONUNBUFFERED=1
python3 $BENCH_ROOT/run_pretraining.py \
--gpu_num_per_node=$GPU_NUM_PER_NODE \
--num_nodes=$NUM_NODES \
--node_ips=$NODE_IPS \
--learning_rate=1e-4 \
--batch_size_per_device=$BSZ_PER_DEVICE \
--iter_num=140 \
--loss_print_every_n_iter=20 \
--seq_length=128 \
--max_predictions_per_seq=20 \
--num_hidden_layers=12 \
--num_attention_heads=12 \
--max_position_embeddings=512 \
--type_vocab_size=2 \
--vocab_size=30522 \
--attention_probs_dropout_prob=0.1 \
--hidden_dropout_prob=0.1 \
--hidden_size_per_head=64 \
--data_dir=$DATA_ROOT \
--data_part_num=$DATA_PART_NUM \
--log_dir=./log \
--model_save_every_n_iter=10000 \
--save_last_snapshot=False \
--model_save_dir=./snapshots跪求大佬解答~~
使用nvidia提供的pytorch docker运行Bert时,精度为fp32,batch size=32或者以上时会报错out of memory,设置的参数和硬件配置和https://github.com/Oneflow-Inc/DLPerf/tree/master/NVIDIADeepLearningExamples/PyTorch/BERT 相同,请问下这个是什么原因呢?
Horovod建议在GPU集群里安装nv_peer_memory驱动,以使用GPUDirect的能力,不知道在测试的时候有没有安装?
在各深度学习框架的评测报告中,没有resnet50在ImageNet上的准确率,没有BERT在GLUE leaderboard上的分数。在实际应用中,重要的不只是效率还有预测效果。没有报告这些重要模型在重要benchmark上的准确率等指标,别人很难确定使用oneflow框架能不能复现出经典模型的效果。
Hi, I find that maybe your distributed bash scripts specify a wrong value for node_rank.
This code may be wrong for launching the pytorch distributed training program. The node_rank would be different for each node. But I find that your multinodes bash script does not change it.
CMD="python3 -m torch.distributed.launch --nproc_per_node=$num_gpus --nnodes $num_nodes --node_rank=0 --master_addr=$master_node --master_port=$master_port $CMD"本报告比较了多个深度学习框架在多个经典的深度学习模型训练任务上分布式训练的吞吐率、加速比、硬件使用率(如:GPU、CPU、内存、硬盘、网络等)。测试均采用相同的数据集、相同的硬件环境和算法,仅比较各个框架之间的速度差异。
结果表明(期望结果):
分布式性能:在20台以上虚机或服务器组合时,线性加速比达到80%以上,与业界已有框架相比有突出的优势;
资源利用率:大规模分布式训练计算时,在各大典型任务上训练的硬件资源平均利用率不低于80%。
本次评测基于基于之江天枢平台,以下简要介绍平台使用流程:
1)平台地址:zjlab.dubhe.club
测试账号(详询俞再亮)
2)选择资源总量(可扩容)
当前可支持 1机1卡 -> 4机32卡
单节点详细配置(单节点上限 8 卡)
Tesla V100S-PCIE-32GB x 8
Intel(R) Xeon(R) Gold 6248R CPU @ 3.00GHz
Memory 754G
Ubuntu 18.04.5 LTS (GNU/Linux 4.4.0-142-generic x86_64)
CUDA Version: 11.1, Driver Version: 460.73.01
nvidia-smi topo -m
本次评测包含了4个框架:
TensorFlow 1.x & 2.x
其中 TensorFlow 1.x、PyTorch、MXNet采用的是NVIDIA深度优化后的版本,性能测试在NGC 20.03 镜像中复现。其余框架的性能测试在相同的物理环境中复现。
各个框架对应的模型训练脚本,从该框架的官方模型库中选取,或者从NVIDIA- DeepLearningExamples 仓库中选取。
本次评测基于以上评测框架,选择了两个经典主流的深度学习模型:
2) BERT-Base
其中ResNet-50是计算机视觉(Computer Version)领域最主流的深度学习模型,而BERT是自然语言处理(Natural Language Processing)领域的进行预训练的主流模型。
同时为了验证OneFlow框架的易用性以及可拓展性,基于OneFlow单独测试了在人脸识别、大规模预训练、点击率预估任务中的经典的深度学习模型:
3)GPT2
为保证能更好地测试框架本身的性能好坏,做到公平公正,本次测评所有的测试均在相同的物理集群中测试,使用相同的软件环境等。
测试环境共有1000张V100 GPU显卡。具体的硬件和软件配置描述如下(根据实验设备实际情况填写,包括型号、大小、速度、版本等):
显卡参数
通信设备
CPU参数
内存大小
系统版本
CUDA版本
nvidia-smi topo -m
针对每个框架的每个模型,我们都测试了其分布式环境下的吞吐率,包含了不同的batch size、是否经过XLA优化加速、是否使用自动混合精度训练。下面简要介绍一下相关概念:
在本测试报告中,batch size表示深度学习训练过程中每个设备(GPU/卡)上的样例个数。简称bsz(batch size per GPU)。特别地,使用global batch size(global bsz)表示表示深度学习训练过程中所有设备(GPUs)上的样例个数。
由于各个深度学习框架的显存管理策略不同,内存优化程度也不一样,所以对于相同的深度学习模型,各个框架在同样显存大小的GPU上所能支持的最大batch size是不同的。通常来说,batch size越大,则性能评测结果越好。
XLA (Accelerated Linear Algebra)是一种深度学习编译器,可以在不改变源码的情况下进行线性代数加速。针对支持XLA的深度学习框架我们也会测试其开启或关闭状态下的性能表现。
AMP(Automatic Mixed Precision) 自动混合精度,在GPU上可以加速训练过程,与Float32精度相比,AMP在某些GPU上可以做到3倍左右的速度提升。我们对支持AMP的深度学习框架会测试其开启或关闭AMP的性能表现。
根据2.5小节介绍的评测配置,针对每个框架每个模型的一个测试(each test case),我们都会遍历如下可能的参数:
1) 机器数(1,2,4,8,16,32,64,125),GPU数(1,8,16,32,64,128,256,512,1000)
2) 每个设备上的batch size
3) 是否开启XLA
4) 是否开启AMP
注:
125和1000分别为此次测评的最大机器数和最多GPU数。
针对每个框架的每次性能测试,我们至少测试了 1机1卡、1机8卡、2机16卡、4机32卡直到64机512卡这些情况。用于评价各个框架在分布式训练情况下的横向扩展能力。
针对此次测评,我们会重复几次(5-7次),并选取这几次测试的中位数作为实际的测试结果。测试结果选取规则尽可能的屏蔽掉随机因素的干扰,使得测试结果接近真实值。
我们选取吞吐率(throughput)、加速比(speedup)、硬件使用率(如:GPU、CPU、内存、硬盘、网络)等作为评测指标。
吞吐率表示了深度学习框架的处理速度,吞吐率越高,则训练一个深度学习模型所需的时间越短,深度学习框架的性能就越高。加速比表示了深度学习框架多机多卡的扩展性,加速比越高,则额外增加一个硬件设备所带来的收益就越高,深度学习框架的多机扩展性就越好。硬件使用率表示了深度学习框架的资源利用效率,数值越大,深度学习框架的性能就越高。
吞吐率表示训练过程中深度学习框架每秒处理的样例个数。对于图片分类任务而言,表示每秒处理多少张图片(images/sec);对于自然语言处理任务而言,表示每秒处理多少个句子(sentences/sec)。
为了得到连续且稳定的吞吐率,我们会过滤掉训练一开始的几个step。在实际测试中,一般我们过滤了前20个step,并选取后续100个step的均值计算吞吐率。(有些框架在有些训练模型上的log是按照100的倍数输出的,这时我们会过滤掉前100个step,选取后面几百个step计算均值。)
通过加速比,可测试出深度学习框架在分布式训练环境下的横向扩展能力。加速比是针对该框架在某一分布式配置下(如n台机器,共m个设备)的吞吐率与该框架在相同配置下(相同的bsz per GPU,相同的参数)单机单卡的吞吐率的比值。理想情况下,加速比为m(m>1),但每个框架都只能尽可能接近m,而无法达到和超过m。
通过硬件使用率,特别是GPU、CPU、内存、硬盘、网络的使用率。在实际测试中,我们取阶段性step(每阶段的选择参考2.7.1)硬件使用率的平均值。该数值越高,说明深度学习框架的效率越高,资源调度越优化。
参与本次评测的框架、版本、模型库、以及额外特性如表3-1(该表格中的各个版本需要再确认)所示:
表 3-1 参与ResNet50-v1.5 性能评测的各个框架介绍
| Framework | Version | Docker From | DNN Model Sources | Features |
|---|---|---|---|---|
| OneFlow | 0.*.0 | - | OneFlow-Benchmark | - |
| NGC MXNet | 1.6.0 | nvcr.io/nvidia/mxnet:20.03-py3 | DeepLearningExamples/MxNet | DALI+Horovod |
| NGC TensorFlow 1.x | 1.15.2 | nvcr.io/nvidia/tensorflow:20.03-tf1-py3 | DeepLearningExamples/TensorFLow | DALI+Horovod+XLA |
| NGC PyTorch | 1.5.0a0+8f84ded | nvcr.io/nvidia/pytorch:20.03-py3 | DeepLearningExamples/PyTorch | DALI+APEX |
| MXNet | 1.6.0 | - | gluon-cv | Horovod |
| TensorFlow 2.x | 2.3.0 | - | TensorFlow-models | - |
| PyTorch | 1.6.0 | - | pytorch/examples | - |
| PaddlePaddle | 1.8.3.post107 | - | PaddleCV | DALI |
【注】的内容需要根据具体实验情况进行修改
GPT2实验中不同并行模式的参数根据具体实验情况修改
耗时(latency)需要在每个实验中增加吗?(目前在Wise & Deep、GPT2有)
在两个服务器上,起了两个容器,然后在里面装好了openmpi之类的通信工具。
简单用horovodrun 命令测试了一下,似乎应该是通的?
horovodrun -np 8 -H localhost:8 -p 10000 echo "233"
2021-01-30 03:50:03.454606: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
[1,0]<stdout>:233
[1,1]<stdout>:233
[1,2]<stdout>:233
[1,3]<stdout>:233
[1,4]<stdout>:233
[1,5]<stdout>:233
[1,6]<stdout>:233
[1,7]<stdout>:233
horovodrun -np 8 -H node2:8 -p 10000 echo "233"
2021-01-30 03:51:07.190350: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
[1,0]<stdout>:233
[1,1]<stdout>:233
[1,2]<stdout>:233
[1,3]<stdout>:233
[1,4]<stdout>:233
[1,5]<stdout>:233
[1,6]<stdout>:233
[1,7]<stdout>:233
horovodrun -np 8 -H node1:8,node2:8 -p 10000 --start-timeout 100 echo "233"
2021-01-30 03:53:35.059288: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
[1,0]<stdout>:233
[1,1]<stdout>:233
[1,2]<stdout>:233
[1,3]<stdout>:233
[1,4]<stdout>:233
[1,5]<stdout>:233
[1,6]<stdout>:233
[1,7]<stdout>:233
接着验了一下horovd run 16卡的,好像也没问题?
horovodrun -np 16 -H node1:8,node2:8 -p 10000 --start-timeout 100 echo "233"
2021-01-30 06:26:32.968745: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
[1,8]<stdout>:233
[1,9]<stdout>:233
[1,10]<stdout>:233
[1,11]<stdout>:233
[1,12]<stdout>:233
[1,13]<stdout>:233
[1,14]<stdout>:233
[1,15]<stdout>:233
[1,0]<stdout>:233
[1,1]<stdout>:233
[1,2]<stdout>:233
[1,3]<stdout>:233
[1,4]<stdout>:233
[1,5]<stdout>:233
[1,6]<stdout>:233
[1,7]<stdout>:233
然后配好了相关路径,执行
bash run_two_node.sh 64 fp16 true
当然,multi xxx.sh里,我加了一个--start-timeout 300, 否则好像会显示超时报错。
这样之后可以正常跑,但是性能明显不对:
[1,0]<stdout>:Skipping time record for 0 due to checkpoint-saving/warmup overhead
[1,0]<stdout>:DLL 2021-01-30 03:37:35.188454 - Iteration: 1 throughput_train : 487.252 seq/s mlm_loss : 10.4442 nsp_loss : 0.6882 total_loss : 11.1323 avg_loss_step : 11.1323 learning_rate : 0.0 loss_scaler : 67108864
[1,0]<stdout>:Skipping time record for 0 due to checkpoint-saving/warmup overhead
[1,0]<stdout>:DLL 2021-01-30 03:37:37.309305 - Iteration: 1 throughput_train : 482.925 seq/s mlm_loss : 10.4311 nsp_loss : 0.7286 total_loss : 11.1597 avg_loss_step : 11.1597 learning_rate : 0.0 loss_scaler : 33554432
[1,0]<stdout>:Skipping time record for 0 due to checkpoint-saving/warmup overhead
[1,0]<stdout>:DLL 2021-01-30 03:37:39.419278 - Iteration: 1 throughput_train : 485.466 seq/s mlm_loss : 10.4503 nsp_loss : 0.7116 total_loss : 11.1619 avg_loss_step : 11.1619 learning_rate : 0.0 loss_scaler : 16777216
[1,0]<stdout>:Skipping time record for 0 due to checkpoint-saving/warmup overhead
[1,0]<stdout>:DLL 2021-01-30 03:37:41.516706 - Iteration: 1 throughput_train : 488.409 seq/s mlm_loss : 10.4479 nsp_loss : 0.7024 total_loss : 11.1503 avg_loss_step : 11.1503 learning_rate : 0.0 loss_scaler : 8388608
[1,0]<stdout>:Skipping time record for 0 due to checkpoint-saving/warmup overhead
[1,0]<stdout>:DLL 2021-01-30 03:37:43.757067 - Iteration: 1 throughput_train : 457.224 seq/s mlm_loss : 10.4415 nsp_loss : 0.7040 total_loss : 11.1455 avg_loss_step : 11.1455 learning_rate : 0.0 loss_scaler : 4194304
[1,0]<stdout>:Skipping time record for 0 due to checkpoint-saving/warmup overhead
[1,0]<stdout>:DLL 2021-01-30 03:37:45.888906 - Iteration: 1 throughput_train : 480.491 seq/s mlm_loss : 10.4445 nsp_loss : 0.7108 total_loss : 11.1553 avg_loss_step : 11.1553 learning_rate : 0.0 loss_scaler : 2097152
[1,0]<stdout>:Skipping time record for 0 due to checkpoint-saving/warmup overhead
[1,0]<stdout>:DLL 2021-01-30 03:37:47.978569 - Iteration: 1 throughput_train : 490.213 seq/s mlm_loss : 10.4558 nsp_loss : 0.7030 total_loss : 11.1589 avg_loss_step : 11.1589 learning_rate : 0.0 loss_scaler : 1048576
[1,0]<stdout>:Skipping time record for 0 due to checkpoint-saving/warmup overhead
[1,0]<stdout>:DLL 2021-01-30 03:37:50.481595 - Iteration: 1 throughput_train : 409.234 seq/s mlm_loss : 10.4543 nsp_loss : 0.7094 total_loss : 11.1637 avg_loss_step : 11.1637 learning_rate : 0.0 loss_scaler : 524288
[1,0]<stdout>:Skipping time record for 0 due to checkpoint-saving/warmup overhead
[1,0]<stdout>:DLL 2021-01-30 03:37:53.738915 - Iteration: 1 throughput_train : 314.426 seq/s mlm_loss : 10.4676 nsp_loss : 0.7103 total_loss : 11.1779 avg_loss_step : 11.1779 learning_rate : 0.0 loss_scaler : 262144
[1,0]<stdout>:Skipping time record for 0 due to checkpoint-saving/warmup overhead
[1,0]<stdout>:DLL 2021-01-30 03:37:57.473934 - Iteration: 1 throughput_train : 274.211 seq/s mlm_loss : 10.4273 nsp_loss : 0.7190 total_loss : 11.1463 avg_loss_step : 11.1463 learning_rate : 0.0 loss_scaler : 131072
[1,0]<stdout>:Skipping time record for 0 due to checkpoint-saving/warmup overhead
[1,0]<stdout>:DLL 2021-01-30 03:38:01.415495 - Iteration: 1 throughput_train : 259.842 seq/s mlm_loss : 10.4480 nsp_loss : 0.7205 total_loss : 11.1685 avg_loss_step : 11.1685 learning_rate : 0.0 loss_scaler : 65536
[1,0]<stdout>:Skipping time record for 0 due to checkpoint-saving/warmup overhead
[1,0]<stdout>:DLL 2021-01-30 03:38:03.598933 - Iteration: 1 throughput_train : 469.080 seq/s mlm_loss : 10.4538 nsp_loss : 0.7007 total_loss : 11.1545 avg_loss_step : 11.1545 learning_rate : 0.0 loss_scaler : 32768
--------------------------------------------------------------------------
An MPI communication peer process has unexpectedly disconnected. This
usually indicates a failure in the peer process (e.g., a crash or
otherwise exiting without calling MPI_FINALIZE first).
Although this local MPI process will likely now behave unpredictably
(it may even hang or crash), the root cause of this problem is the
failure of the peer -- that is what you need to investigate. For
example, there may be a core file that you can examine. More
generally: such peer hangups are frequently caused by application bugs
or other external events.
Local host: node1
Local PID: 197398
Peer host: node2
--------------------------------------------------------------------------
--------------------------------------------------------------------------
Primary job terminated normally, but 1 process returned
a non-zero exit code. Per user-direction, the job has been aborted.
--------------------------------------------------------------------------
--------------------------------------------------------------------------
mpirun noticed that process rank 9 with PID 217958 on node node2 exited on signal 9 (Killed).
--------------------------------------------------------------------------
link ok
Writting log to ../logs//ngc/tensorflow/bert/bz64/2n8g/bert_b64_fp16_2.log
最后每轮还会打出这些信息,这是出了什么问题么?感觉应该是连接上了,且有结果,是不是就说明没有出现通信卡死的情况?
然后我进一步换了一下跑的参数 改成了跑32bacth的混合精度: bash run_two_node.sh 32 fp16 true,
这次直接出现了报错:
[1,7]<stderr>: [[node HorovodBroadcast_bert_encoder_layer_9_output_dense_bias_0 (defined at /usr/local/lib/python3.6/dist-packages/tensorflow_core/python/framework/ops.py:1748) ]]
[1,7]<stderr>:
[1,7]<stderr>:Original stack trace for 'HorovodBroadcast_bert_encoder_layer_9_output_dense_bias_0':
[1,7]<stderr>: File "/workspace/bert/run_pretraining.py", line 713, in <module>
[1,7]<stderr>: tf.compat.v1.app.run()
[1,7]<stderr>: File "/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/platform/app.py", line 40, in run
[1,7]<stderr>: _run(main=main, argv=argv, flags_parser=_parse_flags_tolerate_undef)
[1,7]<stderr>: File "/usr/local/lib/python3.6/dist-packages/absl/app.py", line 303, in run
[1,7]<stderr>: _run_main(main, args)
[1,7]<stderr>: File "/usr/local/lib/python3.6/dist-packages/absl/app.py", line 251, in _run_main
[1,7]<stderr>: sys.exit(main(argv))
[1,7]<stderr>: File "/workspace/bert/run_pretraining.py", line 633, in main
[1,7]<stderr>: estimator.train(input_fn=train_input_fn, hooks=training_hooks, max_steps=FLAGS.num_train_steps)
[1,7]<stderr>: File "/usr/local/lib/python3.6/dist-packages/tensorflow_estimator/python/estimator/estimator.py", line 370, in train
[1,7]<stderr>: loss = self._train_model(input_fn, hooks, saving_listeners)
[1,7]<stderr>: File "/usr/local/lib/python3.6/dist-packages/tensorflow_estimator/python/estimator/estimator.py", line 1161, in _train_model
[1,7]<stderr>: return self._train_model_default(input_fn, hooks, saving_listeners)
[1,7]<stderr>: File "/usr/local/lib/python3.6/dist-packages/tensorflow_estimator/python/estimator/estimator.py", line 1195, in _train_model_default
[1,7]<stderr>: saving_listeners)
[1,7]<stderr>: File "/usr/local/lib/python3.6/dist-packages/tensorflow_estimator/python/estimator/estimator.py", line 1490, in _train_with_estimator_spec
[1,7]<stderr>: log_step_count_steps=log_step_count_steps) as mon_sess:
[1,7]<stderr>: File "/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/training/monitored_session.py", line 584, in MonitoredTrainingSession
[1,7]<stderr>: stop_grace_period_secs=stop_grace_period_secs)
[1,7]<stderr>: File "/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/training/monitored_session.py", line 1014, in __init__
[1,7]<stderr>: stop_grace_period_secs=stop_grace_period_secs)
[1,7]<stderr>: File "/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/training/monitored_session.py", line 713, in __init__
[1,7]<stderr>: h.begin()
[1,7]<stderr>: File "/usr/local/lib/python3.6/dist-packages/horovod/tensorflow/__init__.py", line 240, in begin
[1,7]<stderr>: self.bcast_op = broadcast_global_variables(self.root_rank)
[1,7]<stderr>: File "/usr/local/lib/python3.6/dist-packages/horovod/tensorflow/__init__.py", line 191, in broadcast_global_variables
[1,7]<stderr>: return broadcast_variables(_global_variables(), root_rank)
[1,7]<stderr>: File "/usr/local/lib/python3.6/dist-packages/horovod/tensorflow/functions.py", line 56, in broadcast_variables
[1,7]<stderr>: return broadcast_group(variables, root_rank)
[1,7]<stderr>: File "/usr/local/lib/python3.6/dist-packages/horovod/tensorflow/functions.py", line 42, in broadcast_group
[1,7]<stderr>: for var in variables])
[1,7]<stderr>: File "/usr/local/lib/python3.6/dist-packages/horovod/tensorflow/functions.py", line 42, in <listcomp>
[1,7]<stderr>: for var in variables])
[1,7]<stderr>: File "/usr/local/lib/python3.6/dist-packages/horovod/tensorflow/mpi_ops.py", line 198, in broadcast
[1,7]<stderr>: ignore_name_scope=ignore_name_scope)
[1,7]<stderr>: File "<string>", line 320, in horovod_broadcast
[1,7]<stderr>: File "/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/framework/op_def_library.py", line 794, in _apply_op_helper
[1,7]<stderr>: op_def=op_def)
[1,7]<stderr>: File "/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/util/deprecation.py", line 513, in new_func
[1,7]<stderr>: return func(*args, **kwargs)
[1,7]<stderr>: File "/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/framework/ops.py", line 3357, in create_op
[1,7]<stderr>: attrs, op_def, compute_device)
[1,7]<stderr>: File "/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/framework/ops.py",[1,7]<stderr>: line 3426, in _create_op_internal
[1,7]<stderr>: op_def=op_def)
[1,7]<stderr>: File "/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/framework/ops.py", line 1748, in __init__
[1,7]<stderr>: self._traceback = tf_stack.extract_stack()
[1,6]<stderr>:Traceback (most recent call last):
[1,6]<stderr>: File "/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/client/session.py", line 1365, in _do_call
[1,6]<stderr>: return fn(*args)
[1,6]<stderr>: File "/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/client/session.py", line 1350, in _run_fn
[1,6]<stderr>: target_list, run_metadata)
[1,6]<stderr>: File "/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/client/session.py", line 1443, in _call_tf_sessionrun
[1,6]<stderr>: run_metadata)
很奇怪 是啥姿势不对么?
首先,各个框架存在不同版本;其次,项目代码也在不断维护和更新,我们需要复现一个项目,首先需要熟读项目的readme,然后精确地匹配到对应的commit,保证代码版本和框架版本相匹配,才能将由于代码/框架版本不匹配导致各种问题的概率降至最低。
多机情况下常见的问题:
无论是在物理机还是nvidia-ngc容器中,要运行horovod/mpi,都需要提前在节点之间配置ssh免密登录,保证用于通信的端口可以互相连通。
如:
# export PORT=10001
horovodrun -np ${gpu_num} \
-H ${node_ip} -p ${PORT} \
--start-timeout 600 \
python3 train.py ${CMD} 2>&1 | tee ${log_file}
# 或者:
mpirun --allow-run-as-root -oversubscribe -np ${gpu_num} -H ${node_ip} \
-bind-to none -map-by slot \
-x LD_LIBRARY_PATH -x PATH \
-mca pml ob1 -mca btl ^openib \
-mca plm_rsh_args "-p ${PORT} -q -o StrictHostKeyChecking=no" \
-mca btl_tcp_if_include ib0 \
python3 train.py ${CMD} 2>&1 | tee ${log_file}需要保证节点间ssh可以通过端口10001互相连通
如果是在docker容器中进行多机训练,需要保证docker容器间可以通过指定端口互相ssh免密登录。(如:在10.11.0.2节点的docker容器内可以通过ssh [email protected] -p 10001可以直接登录10.11.0.3节点的docker容器)
而在docker容器里,有两种实现方式:
**
docker的host模式
host模式,需要通过docker run时添加参数 --net=host 指定,该模式下表示容器和物理机共用端口(没有隔离),需要修改容器内ssh服务的通信端口号(vim /etc/ssh/sshd_config),用于docker容器多机通讯,具体方式见:README—SSH配置
docker的bridge模式
即docker的默认模式。该模式下,容器内部和物理机的端口是隔离的,可以通过docker run时增加参数如:-v 9000:9000进行端口映射,表明物理机9000端口映射到容器内9000端口,docker容器多机时即可指定9000端口进行通信。
两种方式都可以,只要保证docker容器间能通过指定端口互相ssh免密登录即可。
通信库没有正确安装
通常是没有正确地安装多机依赖的通信库(openmpi、nccl)所导致。譬如paddle、tensorflow2.x等框架依赖nccl,则需要在每个机器节点上安装版本一致的nccl,多机训练时,可以通过export NCCL_DEBUG=INFO来查看nccl的日志输出。
openmpi安装
官网:https://www.open-mpi.org/software/ompi/v4.0/
wget https://download.open-mpi.org/release/open-mpi/v4.0/openmpi-4.0.0.tar.gz
gunzip -c openmpi-4.0.0.tar.gz | tar xf -
cd openmpi-4.0.0
sudo ./configure --prefix=/usr/local/openmpi --with-cuda=/usr/local/cuda-10.2 --enable-orterun-prefix-by-default
sudo make && make installmake时,若报错numa相关的.so找不到:
sudo apt-get install libnuma-dev添加到环境变量
vim ~/.bashrc
export PATH=$PATH:/usr/local/openmpi/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/openmpi/lib
source ~/.bashrchorovod安装
官网:https://github.com/horovod/horovod
HOROVOD_GPU_OPERATIONS=NCCL python -m pip install --no-cache-dir horovod存在虚拟网卡,nccl需指定网卡类型
有时,nccl已经正常安装,且节点间可以正常ssh免密登录,且都能互相ping通,不过还是遭遇多机训练长时间卡住的问题,可能是虚拟网卡的问题,当存在虚拟网卡时,如果不指定nccl变量,则多机通信时可能会走虚拟网卡,而导致多机不通的问题。
如下图:
NCCL WARN Connect to fe80::a480:7fff:fecf:1ed9%13<45166> failed : Network is unreachable表明多机下遭遇了网络不能连通的问题。具体地,是经过网卡:fe80::a480:7fff:fecf...通信时不能连通。
我们排查时,通过在发送端ping一个较大的数据包(如ping -s 10240 10.11.0.4),接收端通过bwm-ng命令查看每个网卡的流量波动情况(找出ping相应ip时,各个网卡的流量情况),发现可以正常连通,且流量走的是enp类型的网卡。
通过ifconfig查看当前节点中的所有网卡类型:
可以发现有很多enp开头的网卡,也有很多veth开头的虚拟网卡,而nccl日志输出中的:fe80::a480:7fff:fecf:1ed9是veth虚拟网卡。
通过查看nccl官网文档发现,我们可以通过指定nccl变量来设定nccl通信使用的网卡类型:
export NCCL_SOCKET_IFNAME=enp官方实现:https://github.com/tensorflow/models/tree/r2.3.0/official/vision/image_classification
DLPERF实现:https://github.com/Oneflow-Inc/DLPerf/tree/master/TensorFlow/resnet50v1.5
官方official目录下提供的requirements.txt里并未指定tensorflow-datasets的版本,直接通过pip install -r requirements.txt安装,训练时会报错找不到imagenet数据集信息,可通过指定版本解决:
在requirements.txt中指定tensorflow-datasets==3.0.0即可。
开始训练前,需要将项目路径加入到PYTHONPATH,或者通过vim ~/.bashrc在用户变量中指定。
export PYTHONPATH=$PYTHONPATH:/home/leinao/tensorflow/models-2.3.0tf2.3依赖cuda-10.1下的库文件,如果在cuda10.2的环境下运行,会报错:
2020-08-10 22:24:27.641197: W tensorflow/stream_executor/platform/default/dso_loader.cc:59]
Could not load dynamic library 'libcudart.so.10.1'; dlerror: libcudart.so.10.1:
cannot open shared object file: No such file or directory;类似报错信息还有:libcupti.so.10.1等.so文件
解决方式:
sudo ln -s /usr/local/cuda-10.2/targets/x86_64-linux/lib/libcudart.so.10.2 /usr/lib/x86_64-linux-gnu/libcudart.so.10.1参考github issue:
tensorflow/tensorflow#38194 (comment)
单机训练策略采取默认的MirroredStrategy策略,多机策略采取:MultiWorkerMirroredStrategy。tf2.x可用的策略详见官方文档:https://tensorflow.google.cn/guide/distributed_training
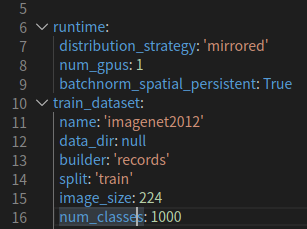
在DLPerf中,我们通过run_single_node.sh脚本运行单机测试,脚本调用single_node_train.sh执行单机训练脚本,其中通过--config_file参数设置训练所需要的yaml配置文件(gpu.yaml或gpu_fp16.yaml)。单机训练时,需要将yaml配置文件中runtime下的distribution_strategy设置为'mirrored',以使用MirroredStrategy策略:
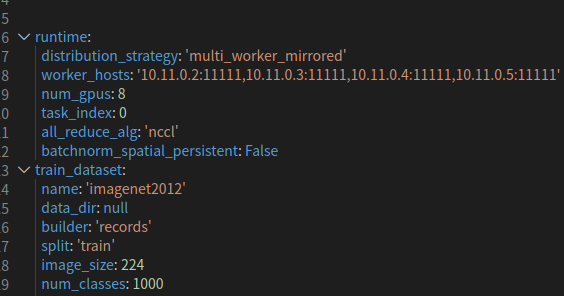
多机器训练时,multi_node_train.sh脚本中通过--config_file参数设置训练所需的yaml配置文件(multi_node_gpu.yaml或multi_node_gpu_fp16.yaml)。多机训练时,需要将yaml配置文件中runtime下的distribution_strategy设置为'multi_worker_mirrored'以使用MultiWorkerMirroredStrategy策略,同时需要增加all_reduce_alg:'nccl'以指定all_reduce过程使用nccl,否则会报错。
基本参数设置同tf2.x-resnet,不过无需.yaml配置文件,统一使用run_pretraining.py进行训练。
不过测试过程中我们发现,官方提供的python脚本运行多机时会报错,即使在修改代码后也只能支持
--all_reduce_alg='ring'模式的多机训练(cpu多机),而不能支持'nccl'模式的多gpu训练,故多机的测试暂不开展。
详见:https://github.com/Oneflow-Inc/DLPerf/tree/master/TensorFlow/bert#%E5%A4%9A%E6%9C%BA
paddle在利用imagenet训练分类网络时,需要对imagenet数据集做一定的处理,将图像和标签文件写入train_list.txt、val_list.txt文件中,具体格式和制作方式参考:官方文档—数据准备
单机单卡时,可以直接通过python train.py...训练,单机多卡时,最好使用多进程训练的模式:
python -m paddle.distributed.launch train.py...否则训练速度和加速比都会比较差。
在单机采用多进程训练时,可以自行调节--reader_thread参数,以达到最优速度,且thread并非越大越好,超过一定数值后thread越大,线程数越多,会导致速度变慢。经测试,单机1卡时thread=8速度较优;4卡时thread=12;8卡时thread=8能达到较优的速度。
多机训练时,必须采用多进程训练的模式,多机通讯走nccl。同样,可以自行测试,以选取最优化的--reader_thread参数,在DLPerf的多机测试时,默认使用--reader_thread=8。
参考:官方文档—模型训练
数据集制作过程见:DLPerf文档;单机、多机训练说明可参考:官方文档 其他按照正常流程走即可,没有需要特别注意的地方。
当需要在NGC容器间进行多机测试时,容器间需要配置ssh免密登录,具体参考DLPerf的README—SSH 免密。
如果服务器之间支持IB(InfiniBand)网络,则可以安装IB驱动,使得多机情况下各个节点间的通信速率明显提升,从而加速框架在多机环境下的训练,提升加速比。
具体安装方式可参考:IB驱动安装(可选)
容器内提供的代码可能和官方代码不完全同步,需要作一些修改才能正确运行,详见README—额外准备。
在用mxnet进行resnet50测试时,需要加上一系列mxnet默认的环境变量,否则速度可能不够理想,这些变量已经在脚本runner.sh(Line:70~Line:81)中包含,可自行修改以设定最优化的值。
当需要在NGC容器间进行多机测试时,容器间需要配置ssh免密登录,具体参考DLPerf的README—SSH配置(可选)。
如果服务器之间支持IB(InfiniBand)网络,则可以安装IB驱动,使得多机情况下各个节点间的通信速率明显提升,从而加速框架在多机环境下的训练,提升加速比。
具体安装方式可参考:IB驱动安装(可选)
当需要在NGC容器间进行多机测试时,容器间需要配置ssh免密登录,具体参考DLPerf的README—SSH配置(可选)。
如果服务器之间支持IB(InfiniBand)网络,则可以安装IB驱动,使得多机情况下各个节点间的通信速率明显提升,从而加速框架在多机环境下的训练,提升加速比。
具体安装方式可参考:IB驱动安装(可选)
**
在bert的测试中发现,安装IB驱动后,2机、4机情况下的加速比提升明显
horovod是支持pytorch,tensorflow,mxnet多机分布式训练的库,其底层机器间通讯依赖nccl或mpi,所以安装前通常需要先安装好nccl、openmpi,且至少安装了一种深度学习框架,譬如mxnet:
python3 -m pip install gluonnlp==0.10.0 mxnet-cu102mkl==1.6.0.post0 -i https://mirror.baidu.com/pypi/simple安装完mxnet以及gluonnlp后,可进行horovod的安装。horovod安装时,需为NCCL指定相关变量,否则运行时可能不会走nccl通讯导致速度很慢。在DLPerf中如何安装horovod,可直接参考README-环境安装 。
更多关于horovod多机速度慢的问题,可参考issue:#48
具体参考:README—额外准备部分
nvidia-smi topo -m
可以看出,此台机器包含8块GPU(GPU0~7),mlx5_0是Mellanox ConnectX-4 PCIe网卡设备(10/25/40/50千兆以太网适配器,另外该公司是IBA芯片的主要厂商)。图的上半部分表示GPU间的连接方式,如gpu1和gpu0通过NV1互联,gpu4和gpu1通过SYS互联;图的下半部分为连接方式的具体说明,如NV表示通过nvlink互联,PIX通过至多一个PCIe网桥互联。
在图的下半部分,理论上GPU间的连接速度从上到下依次加快,最底层的NV表示通过nvlink互联,速度最快;最上层SYS表示通过pcie以及穿过NUMA节点间的SMP互联(即走了PCie又走了QPI总线),速度最慢。
关于NUMA,SMP等服务器结构的简单介绍可参考:服务器体系(SMP, NUMA, MPP)与共享存储器架构(UMA和NUMA)
在下面这个链接里看到有提到tensorflow的bert不支持nccl
https://github.com/Oneflow-Inc/DLPerf/blob/master/reports/dlperf_benchmark_test_report_v1_cn.md

但这个链接里又给出了测评结果https://github.com/Oneflow-Inc/DLPerf/tree/master/TensorFlow/bert#%E5%A4%9A%E6%9C%BA
且在https://github.com/Oneflow-Inc/DLPerf/blob/master/TensorFlow/bert/scripts/single_node_train.sh#L64 里看到@YongtaoShi 提交的增加了nccl的配置。
请问你们后来是咋运行成功的?我现在也遇到指定nccl就不能正常运行了。
感谢~
horovod是支持pytorch,tensorflow,mxnet多机分布式训练的库,其底层机器间通讯依赖nccl或mpi,所以安装前通常需要先安装好nccl、openmpi,且至少安装了一种深度学习框架,譬如mxnet:
python3 -m pip install gluonnlp==0.10.0 mxnet-cu102mkl==1.6.0.post0 -i https://mirror.baidu.com/pypi/simple安装好依赖后,可以进行horovod的安装,horovod安装时,需为NCCL指定相关变量,否则运行时可能不会走nccl通讯导致速度很慢。详细安装过程:https://github.com/horovod/horovod/blob/master/docs/gpus.rst
HOROVOD_WITH_MXNET=1 HOROVOD_GPU_OPERATIONS=NCCL HOROVOD_GPU_ALLREDUCE=NCCL HOROVOD_GPU_BROADCAST=NCCL如果不指定变量直接安装,则用horovodrun时也能运行,不过速度会很慢,因为其底层并未走nccl,直接走的是mpi通信
horovodrun -np ${gpu_num} -H ${node_ip} -p ${PORT} \
--start-timeout 600 --log-level INFO \
python3 ${WORKSPACE}/run_pretraining.py ${CMD} 2>&1 | tee ${log_file}mpirun -oversubscribe -np ${gpu_num} -H ${node_ip} \
-bind-to none -map-by numa \
-x NCCL_DEBUG=INFO -x LD_LIBRARY_PATH -x PATH \
-mca pml ob1 -mca btl ^openib \
-mca plm_rsh_args "-p 22 -q -o StrictHostKeyChecking=no" \
-mca btl_tcp_if_include ib0 \
python3 ${WORKSPACE}/run_pretraining.py ${CMD} 2>&1 | tee ${log_file}A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.