o19s / quepid Goto Github PK
View Code? Open in Web Editor NEWImprove your Elasticsearch, OpenSearch, Solr, Vectara, Algolia and Custom Search search quality.
Home Page: http://www.quepid.com
License: Apache License 2.0
Improve your Elasticsearch, OpenSearch, Solr, Vectara, Algolia and Custom Search search quality.
Home Page: http://www.quepid.com
License: Apache License 2.0
Is your feature request related to a problem? Please describe.
Comparing snapshots helps highlight jumps and dips in precision (or f(X)@10 depending on what you're measuring). However, the only proxy we have for "losing recall" (which tends to happen when you tune-up search precision), is the Results count from the current query.
Describe the solution you'd like
I would like to see the number of results returned from the snapshot alongside the number of results from the current query.
Describe alternatives you've considered
A more sophisticated recall-measurement solution. But do this hits-diff bit first!
doc_generator.rb is used to create ratings. It is the only aspect of Quepid that use RSolr, and since we arne't solr only, we work with elastic search and maybe others in the future, we need to seperate doc_generator from the search engine. A baby step is to convert to straight up API/JSON queries.
Describe the solution you'd like
Keep doc_generator the same, but use api and json, not rsolr.
Describe alternatives you've considered
A clear and concise description of any alternative solutions or features you've considered.
Additional context
Add any other context or screenshots about the feature request here.
Describe the bug
Quepid consent for cookies pops up regardless of if you have COOKIES_URL set..
To Reproduce
Steps to reproduce the behavior:
Remove COOKIES_URL, open in Private Window.
Expected behavior
Only show popup if you have a COOKIES_URL property.
Describe the bug
Sometimes the Rails image tries to connect to MySQL image before it has fully spun up...
To Reproduce
Steps to reproduce the behavior:
./bin/setup_docker or on docker-compose up with production setup.Expected behavior
Not have this issue!
Screenshots
Running via Spring preloader in process 20
#<Mysql2::Error::ConnectionError: Can't connect to MySQL server on 'mysql' (111 "Connection refused")>
Couldn't create database for {"adapter"=>"mysql2", "encoding"=>"utf8mb4", "collation"=>"utf8mb4_bin", "reconnect"=>false, "pool"=>5, "username"=>"root", "password"=>"password", "host"=>"mysql", "port"=>3306, "database"=>"quepid"}, {:charset=>"utf8mb4", :collation=>"utf8mb4_bin"}
(If you set the charset manually, make sure you have a matching collation)
-- create_table("annotations", {:force=>:cascade})
rake aborted!
Mysql2::Error::ConnectionError: Can't connect to MySQL server on 'mysql' (111 "Connection refused")
/usr/local/bundle/gems/mysql2-0.5.2/lib/mysql2/client.rb:90:in `connect'
/usr/local/bundle/gems/mysql2-0.5.2/lib/mysql2/client.rb:90:in `initialize'
/usr/local/bundle/gems/activerecord-4.2.11/lib/active_record/connection_adapters/mysql2_adapter.rb:18:in `new'
/usr/local/bundle/gems/activerecord-4.2.11/lib/active_record/connection_adapters/mysql2_adapter.rb:18:in `mysql2_connection'
/usr/local/bundle/gems/activerecord-4.2.11/lib/active_record/connection_adapters/abstract/connection_pool.rb:438:in `new_connection'
/usr/local/bundle/gems/activerecord-4.2.11/lib/active_record/connection_adapters/abstract/connection_pool.rb:448:in `checkout_new_connection'
/usr/local/bundle/gems/activerecord-4.2.11/lib/active_record/connection_adapters/abstract/connection_pool.rb:422:in `acquire_connection'
/usr/local/bundle/gems/activerecord-4.2.11/lib/active_record/connection_adapters/abstract/connection_pool.rb:349:in `block in checkout'
/usr/local/bundle/gems/activerecord-4.2.11/lib/active_record/connection_adapters/abstract/connection_pool.rb:348:in `checkout'
/usr/local/bundle/gems/activerecord-4.2.11/lib/active_record/connection_adapters/abstract/connection_pool.rb:263:in `block in connection'
/usr/local/bundle/gems/activerecord-4.2.11/lib/active_record/connection_adapters/abstract/connection_pool.rb:262:in `connection'
/usr/local/bundle/gems/activerecord-4.2.11/lib/active_record/connection_adapters/abstract/connection_pool.rb:571:in `retrieve_connection'
/usr/local/bundle/gems/activerecord-4.2.11/lib/active_record/connection_handling.rb:113:in `retrieve_connection'
/usr/local/bundle/gems/activerecord-4.2.11/lib/active_record/connection_handling.rb:87:in `connection'
/usr/local/bundle/gems/activerecord-4.2.11/lib/active_record/migration.rb:648:in `connection'
/usr/local/bundle/gems/activerecord-4.2.11/lib/active_record/migration.rb:664:in `block in method_missing'
/usr/local/bundle/gems/activerecord-4.2.11/lib/active_record/migration.rb:634:in `block in say_with_time'
/usr/local/bundle/gems/activerecord-4.2.11/lib/active_record/migration.rb:634:in `say_with_time'
/usr/local/bundle/gems/activerecord-4.2.11/lib/active_record/migration.rb:654:in `method_missing'
/srv/app/db/schema.rb:16:in `block in <top (required)>'
/usr/local/bundle/gems/activerecord-4.2.11/lib/active_record/schema.rb:41:in `instance_eval'
/usr/local/bundle/gems/activerecord-4.2.11/lib/active_record/schema.rb:41:in `define'
/usr/local/bundle/gems/activerecord-4.2.11/lib/active_record/schema.rb:61:in `define'
/srv/app/db/schema.rb:14:in `<top (required)>'
/usr/local/bundle/gems/activesupport-4.2.11/lib/active_support/dependencies.rb:268:in `load'
/usr/local/bundle/gems/activesupport-4.2.11/lib/active_support/dependencies.rb:268:in `block in load'
/usr/local/bundle/gems/activesupport-4.2.11/lib/active_support/dependencies.rb:240:in `load_dependency'
/usr/local/bundle/gems/activesupport-4.2.11/lib/active_support/dependencies.rb:268:in `load'
/usr/local/bundle/gems/activerecord-4.2.11/lib/active_record/tasks/database_tasks.rb:221:in `load_schema_for'
/usr/local/bundle/gems/activerecord-4.2.11/lib/active_record/tasks/database_tasks.rb:238:in `block in load_schema_current'
/usr/local/bundle/gems/activerecord-4.2.11/lib/active_record/tasks/database_tasks.rb:278:in `block in each_current_configuration'
/usr/local/bundle/gems/activerecord-4.2.11/lib/active_record/tasks/database_tasks.rb:277:in `each'
/usr/local/bundle/gems/activerecord-4.2.11/lib/active_record/tasks/database_tasks.rb:277:in `each_current_configuration'
/usr/local/bundle/gems/activerecord-4.2.11/lib/active_record/tasks/database_tasks.rb:237:in `load_schema_current'
/usr/local/bundle/gems/activerecord-4.2.11/lib/active_record/railties/databases.rake:237:in `block (3 levels) in <top (required)>'
/usr/local/bundle/gems/activerecord-4.2.11/lib/active_record/railties/databases.rake:241:in `block (3 levels) in <top (required)>'
/usr/local/bundle/gems/activesupport-4.2.11/lib/active_support/dependencies.rb:268:in `load'
/usr/local/bundle/gems/activesupport-4.2.11/lib/active_support/dependencies.rb:268:in `block in load'
/usr/local/bundle/gems/activesupport-4.2.11/lib/active_support/dependencies.rb:240:in `load_dependency'
/usr/local/bundle/gems/activesupport-4.2.11/lib/active_support/dependencies.rb:268:in `load'
-e:1:in `<main>'
Tasks: TOP => db:schema:load
(See full trace by running task with --trace)
Additional context
This is periodically seen, and was reported by a community member "in the wild".
Is your feature request related to a problem? Please describe.
The Query Sandbox section for Elasticsearch generates with the default query
{
"query": {
"match": {
"_all": "#$query##"
}
}
}
Trying to use against Elasticsearch 6 doesn't work without changing the query due to the removal of the _all field.
Describe the solution you'd like
It would be nice if the default generated query worked off something like "multi_match" instead if the desire is to search across multiple fields. Or potentially specify a target ES version to start with a default query that works.
Additional context
Point of confusion when introducing the tool to new team members to play around with. When they generate a new relevancy case and it doesn't work immediately they get confused. The intention is usually to change the query anyway but seeming like it can't query the index at all from the get go causes some headache.
Is your feature request related to a problem? Please describe.
I need to delete some old Custom Scorers. When I delete them, the error message ties them to existing Cases, however I don't know which cases use which scorers, so I have to hunt through all of them!
Describe the solution you'd like
Tell me which case, user, or query the scorer is tied to, so I can investigate furthur.
Show off using thumb: in the wizard..
Describe the solution you'd like
add thumb:poster_path to default setup.
Describe the bug
When your ID of your document contains a ".", for example "mydoc.pdf", then the Quepid API rejects it.
To Reproduce
Steps to reproduce the behavior:
http://www.mysite.com/doc.pdf are properly handled.Expected behavior
I expect a rating to happen if the id is mydoc.pdf or 1234 or http://www.mysite.com/mydoc.pdf
Screenshots
Error in the browser:

Digging in locally in developer mode:

Is your feature request related to a problem? Please describe.
Because Quepid does not support highlighting/snippeting, it is sometime tricky for raters to understand why a result matched with the same clarity they would in-app. "Deep matches", or rankings which seem "out-of-whack" rely on rater understanding of a Splainer explanation to decode. Here's what one of mine looks like:
Relevancy Score: 0.00007684284
0.00007684284 Product of following:
0.03842142 Sum of the following:
0.01921071 script score function, computed with script:"Script{type=inline, lang='painless', idOrCode='params.w * (Math.pow(_score, params.a) / ( Math.pow(params.k, params.a) + Math.pow(_score, params.a) ) )', options={}, params={a=1.5, w=0.02, k=1}}" and parameters:
{a=1.5, w=0.02, k=1}
0.01921071 script score function, computed with script:"Script{type=inline, lang='painless', idOrCode='params.w * (Math.pow(_score, params.a) / ( Math.pow(params.k, params.a) + Math.pow(_score, params.a) ) )', options={}, params={a=1.5, w=0.02, k=1}}" and parameters:
{a=1.5, w=0.02, k=1}
0.002 function score, score mode [sum]
(cough cough)
Describe the solution you'd like
Elasticsearch has a feature called "named queries" which allows search engineers to "name" each clause of boolean queries or filters and have the matching "names" returned with each hit.
This allows the search engineer to give meaningful names to "reasons why a document might match" which are then concisely returned without the spaghetti of an explain plan.
(Here's an example of what comes back with each hit payload)
matched_queries: ["entityFilter", "requiredTermsFilter", "catchallMatch", "editorialNudge"]
Sadly there is no support for this in Solr yet to my knowledge. But the utility should be clear for Elasticsearch users.
Describe alternatives you've considered
Support for highlighting/snippeting in Quepid.
Additional context
Article about using named queries: https://qbox.io/blog/elasticsearch-named-queries
Describe the bug
In both Heroku, and gemfile we reference the container group with sqlite, but we don't use that anymore.
Describe the bug
I want to display a date of type PointDateField but it crashes the whole Quepid result page since the Solr query returns an error for the highlight part, due to highlighter not supporting PointDate field. It is not possible to override hl.fl to exclude the date field.
To Reproduce
Steps to reproduce the behavior:
Expected behavior
Quepid should not attempt to highlight date or numeric fields. Alternatively it should be possible to specify what fields to highlight and not.
Go to www.quepid.com , click Login, end up at https://app.quepid.com/secure/ - the link in
[ ] Agree to terms & conditions? is broken. @epugh tells me this is a problem with the app rather than the website code so re-raising the issue here.
It turns out you can create a Scorer that is labeled as "Communal", which means it isn't a system default scorer OR a team scorer. In production we have exactly 0 of these!
I did dig around, and found out that it is still supported, in the sense that you can pick a communal scorer:
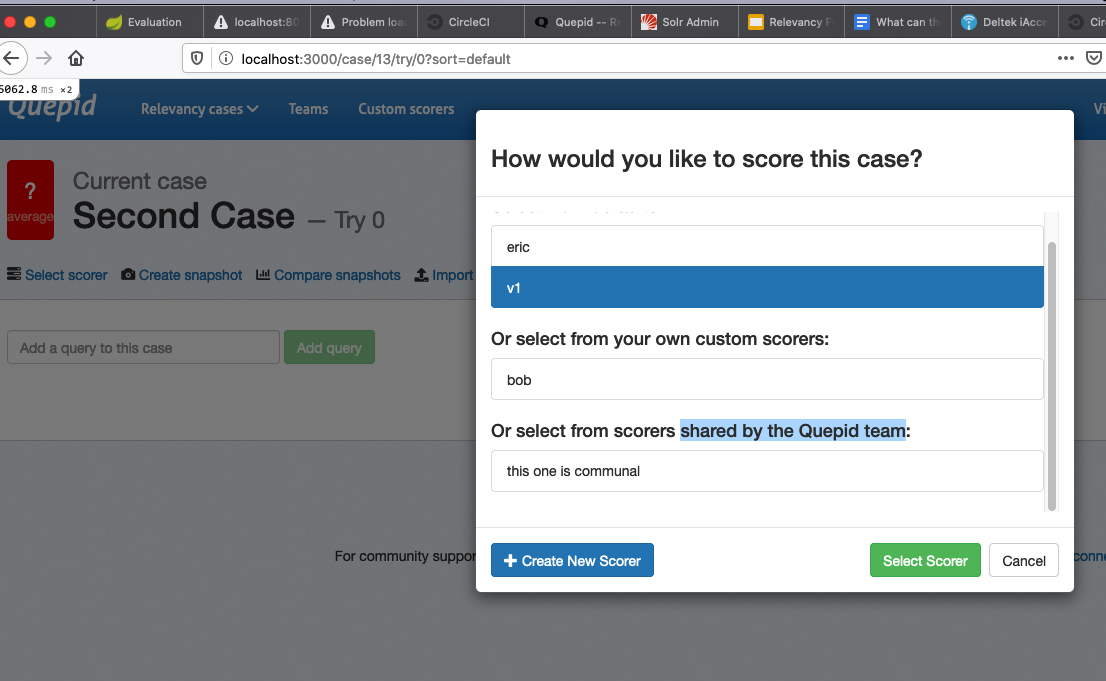
However, it seems like the useful of this feature isn't really there. If you run your own Quepid, you would use the Default Scorer capablity. Or, you use the Team capablity and share it with your team. I think this is from the Dawn of the Quetaceous Era, when we didn't have Teams.
Describe the solution you'd like
I would like to remove this concept from Quepid.
Describe alternatives you've considered
We could document this feature, but again, not quite seeing the use case.
Additional context
We need @softwaredoug and maybe @ychaker or @omnifroodle to weigh in here.
It would be great to be able to play media files from any links returned in the result list, perhaps using a 'media:' option like the 'thumb:' option. This would be useful for those reviewing indexed media files and help them to easily rate them.
Describe the bug
Quepid 6.1.0
Docker Images should not have .env files
REDIS_URL does not override value in .env
To Reproduce
run quepid in production mode with REDIS_URL defined on docker-compose.yml.prod
quepid will still use value in .env
Expected behavior
REDIS_URL would override .env
Additional context
I had to override the start process and remove the .env first before starting foreman...
Is your feature request related to a problem? Please describe.
For deeply-indexed, long-form content search may match on terms which are not evident in short easy-to-scan fields (e.g.: title, summary, metadata).
Those these are often lower-quality matches, they still may wind up on a judgement list. And without the match context, they will be judged poorly.
In search applications with deep indexing, the conventional solution for perceived relevance is snippetting/highlighting.
At present, Quepid will execute a query containing highlighting instructions on Solr/ES without complaint. However the highlighting response is not parsed or presented back to the search listing.
Describe the solution you'd like
Parse [{ field:["snippet1", "snippet2"] }] pairs out of any highlighting payload present in the search response (Solr or Elasticsearch). Display highlights in line with requested fields
Describe alternatives you've considered
The current workaround is to open each document's full _source and visually scan the json to try and figure out what's going on. This is not sustainable for tech users (and impractical for business users).
Describe the bug
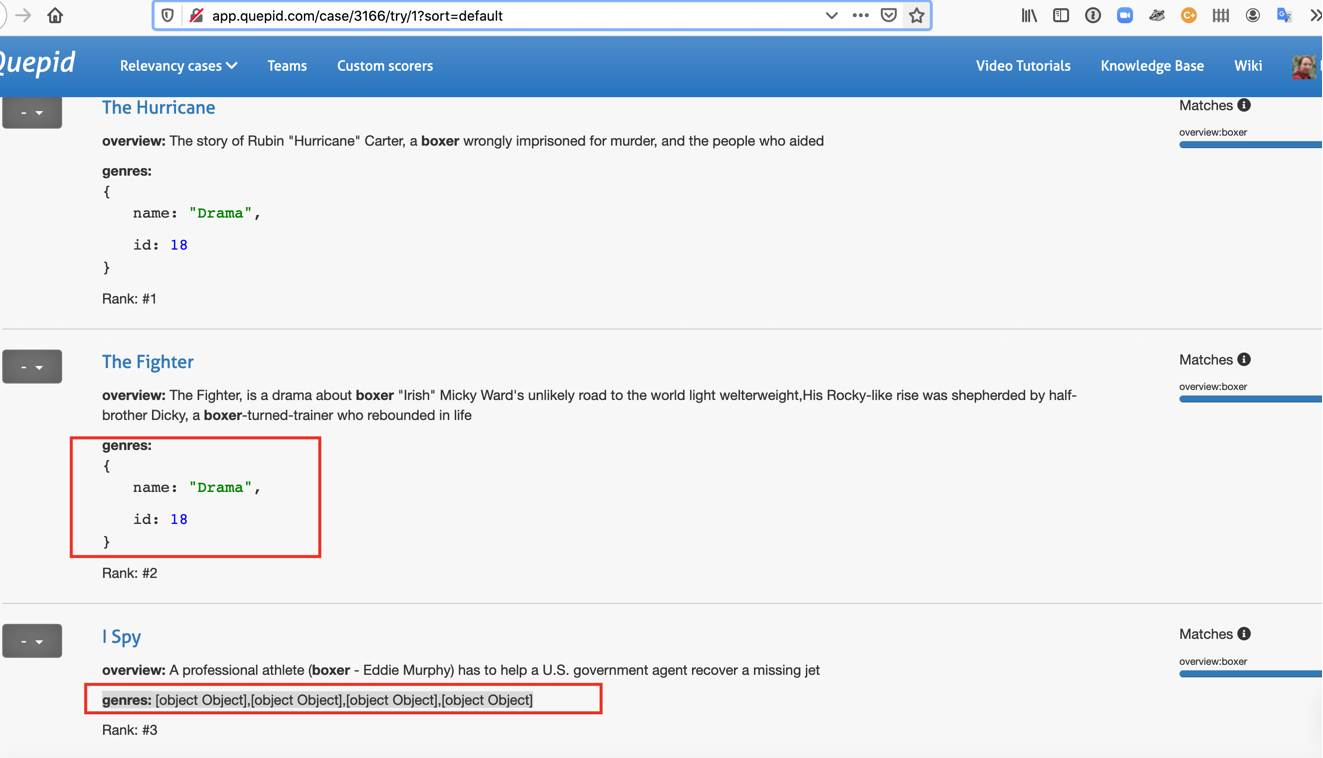
Sometimes we render JSON and other times render as "[object Object],[object Object],[object Object],[object Object]".
To Reproduce
Here is a case demonstrating this problem: http://app.quepid.com/case/3166/try/1?sort=default
Steps to reproduce the behavior:
Expected behavior
The [object object] thing is clearly weird. What can we do about that? JSON nested is maybe okay?
Screenshots
Describe the bug
The very first page in Quepid with a case, if you go to export the case, then we see errors at https://github.com/o19s/quepid/blob/master/app/assets/javascripts/components/export_entire_case/export_entire_case_controller.js#L39
I believe that this method isn't being called: https://github.com/o19s/quepid/blob/master/app/assets/javascripts/components/export_entire_case/export_entire_case_controller.js#L26
To Reproduce
Steps to reproduce the behavior:
However, if you go to the Case Drop down and pick your default case, then you can click the Export Case option.
Expected behavior
Click Export Case, and get an export.
Is your feature request related to a problem? Please describe.
We want to track a certain set of specific documents from the result set, not necessarily the top 10.
Describe the solution you'd like
An easy way to tag subset of docs to compare. Ability to toggle between normal view and this subset view.
We want to concentrate on rating a subset of docuemnts relative to each other and to have the query's score calculated as if the selected documents were the top hits. Thus track how these documents relate to eachother during tuning.
Describe alternatives you've considered
A workaround for us is to manually add a query filter &fq=idfield:(A C F G I) to the case to only consider the selected documents. But it would be easier if this was a feature with tagging of docs.
Additional context
Our use case is not a traditional SERP page, but we use search to select articles that are a good fit for a certain topic, expressed through a query. The long tail of such a search below a certain threshold will have low quality, and we want to inspect a number of hits near this threshold, since our top-10 hits are normally OK.
Describe the bug
Running ./bin/setup_docker nobuild the mysql container may not have fully started before Rails tries to connect. If you re-run the command, it will work, because mysql has had enough time, but obviously that isn't good!
To Reproduce
Steps to reproduce the behavior:
run ./bin/setup_docker nobuild
Expected behavior
Quepid fires up!
We are starting to use the Github provided Wiki for documentation related to Quepid. Someday we may end up migrating all of the https://quepid.com/docs/ content over to the wiki, since that is locked up today in the Quepid marketing site which isn't a public repo.
Describe the solution you'd like
Start out with just adding a Wiki link to the toolbar in Quepid.
Not sure if this has something to do with my environment or somehow the build is not working correctly.
Describe the bug
Looks like the install/build of Node fails when running ./bin/setup_docker
Desktop (please complete the following information):
Expected behavior
Should just complete the docker setup.
To Reproduce
- apt-get install -y lsb-release > /dev/null 2>&1
- '[' 'X lsb-release' '!=' X ']'
- print_status 'Installing packages required for setup: lsb-release...'
- echo
- echo '## Installing packages required for setup: lsb-release...'
- echo
- exec_cmd 'apt-get install -y lsb-release > /dev/null 2>&1'
- exec_cmd_nobail 'apt-get install -y lsb-release > /dev/null 2>&1'
- echo '+ apt-get install -y lsb-release > /dev/null 2>&1'
- bash -c 'apt-get install -y lsb-release > /dev/null 2>&1'
++ lsb_release -d
++ grep 'Ubuntu .*development'
++ echo 1- IS_PRERELEASE=1
- [[ 1 -eq 0 ]]
++ lsb_release -c -s- DISTRO=buster
- check_alt SolydXK solydxk-9 Debian stretch
- '[' Xbuster == Xsolydxk-9 ']'
[... snip ...]
- print_status 'Confirming "buster" is supported...'
- echo
- echo '## Confirming "buster" is supported...'
- echo
- '[' -x /usr/bin/curl ']'
- exec_cmd_nobail 'curl -sLf -o /dev/null '''https://deb.nodesource.com/node_8.x/dists/buster/Release'\'''
- echo '+ curl -sLf -o /dev/null '''https://deb.nodesource.com/node_8.x/dists/buster/Release'\'''
- bash -c 'curl -sLf -o /dev/null '''https://deb.nodesource.com/node_8.x/dists/buster/Release'\'''
Confirming "buster" is supported...
- curl -sLf -o /dev/null 'https://deb.nodesource.com/node_8.x/dists/buster/Release'
Your distribution, identified as "buster", is not currently supported, please contact NodeSource at https://github.com/nodesource/distributions/issues if you think this is incorrect or would like your distribution to be considered for support
- RC=60
- [[ 60 != 0 ]]
- print_status 'Your distribution, identified as "buster", is not currently supported, please contact NodeSource at https://github.com/nodesource/distributions/issues if you think this is incorrect or would like your distribution to be considered for support'
- echo
- echo '## Your distribution, identified as "buster", is not currently supported, please contact NodeSource at https://github.com/nodesource/distributions/issues if you think this is incorrect or would like your distribution to be considered for support'
- echo
- exit 1
ERROR: Service 'app' failed to build: The command '/bin/sh -c curl -skL https://deb.nodesource.com/setup_8.x | bash -x -' returned a non-zero code: 1
Saw this over in splainer land.
Is your feature request related to a problem? Please describe.
I most frequently enter judgments on a single query at a time. If multiple wells are open at once it's very easy to lose track of which query is being worked with so I close each query well once I'm done rating.
In order to close a query well, I need to scroll all the way back up to the query header (often 2-3 swipes), stop exactly on the header, and then click the collapse trigger (glyphicon-chevron-up)
Describe the solution you'd like
Currently the collapse trigger lives in the header (up top), but I tend to work my way down the results and then want to collapse the query once I've finished rating all the unrated. A second trigger (glyphicon-chevron-up) at the bottom of results (in the right side of the "Peek at..." div) would remove most of the excess scrolling from this task.
Describe alternatives you've considered (not exclusive)
Alternative 1: If the query header for the query-results in view scrolls up out of the frame, freeze and stack that div under the quepid-header-div allowing the results for the query in focus to scroll underneath it. This way the existing collapse trigger is always in view. (Actually probably a more usable solution... just requires more work)
Alternative 2: Automatically collapse once no "unrated" results remain.
Bonus 3: Keyboard shortcuts (right-arrow open well, left-arrow close well, up/down focus on next result-or-query which is visible above focus (last action).
Additional context
Accelerating judgment entry in Quepid reduces the overall time needed to build judgments. Since the OSC engagement model pushes judgments as a prerequisite, the effort of building judgment lists is likely a major brake on engagement with OSC. Faster human automatons == more work for OSC :-)
I just learned you can add multiple queries at once (https://github.com/o19s/quepid/wiki/Tips-for-working-with-Quepid).
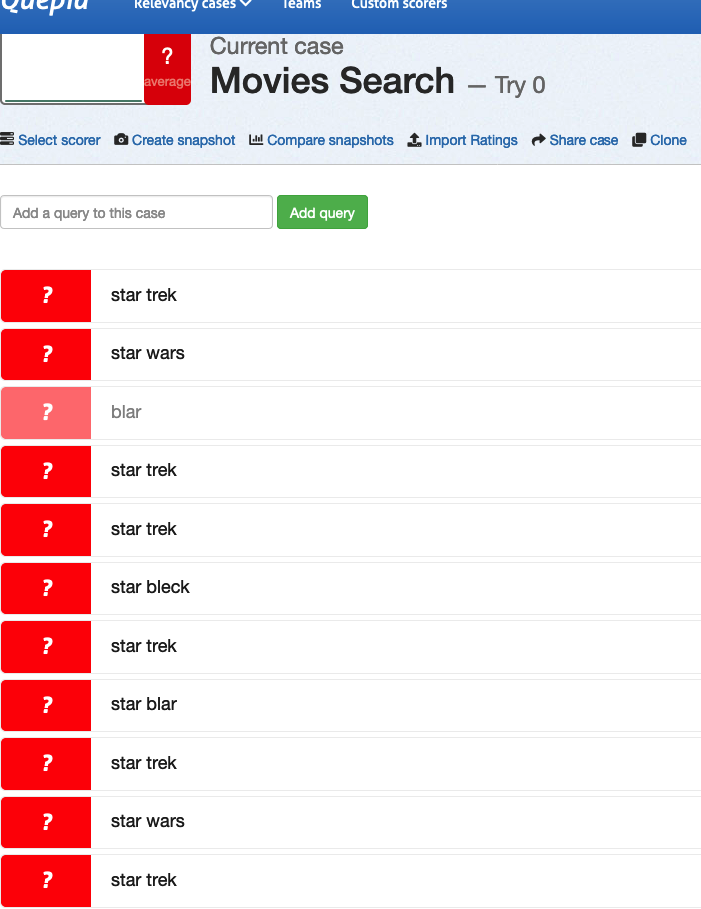
This led me to discover you can also get duplicate queries becasue the bulk querie creator doesn't check to see if a query already exists before inserting it.
So if you add `star trek;star wars' twice, you get dups!
Expected behavior
Don't allow duplicates.
I'd also like, when I add a duplicate, to instead of have the message "Query added", say "Query already exists" in the GUI.
Screenshots
Additional context
There may be a usecase for bulk loaidng without checking, but it seems like a very dangerous "advanced" feature
Hello there,
We have been using (and supporting) quepid for a while, and I'd like to start a discussion about modernizing the Quepid codebase. Quepid is currently running on RoR as backend (old version, and a pretty much a dead technology now) and Angular 1.something (very very old and EOL).
Would you consider rebuilding the project, piece by piece, using modern technologies? We can help. We propose using React for the frontend, and Typescript/NodeJS or Go for the backend.
Would love to hear your thoughts.
Describe the bug
The new auto-URL feature introduced here #27 will wrap any string containing the substring "http" anywhere in the string.
To Reproduce
Expected behavior
Only strings beginning with http should be hyperlinked.
Describe the bug
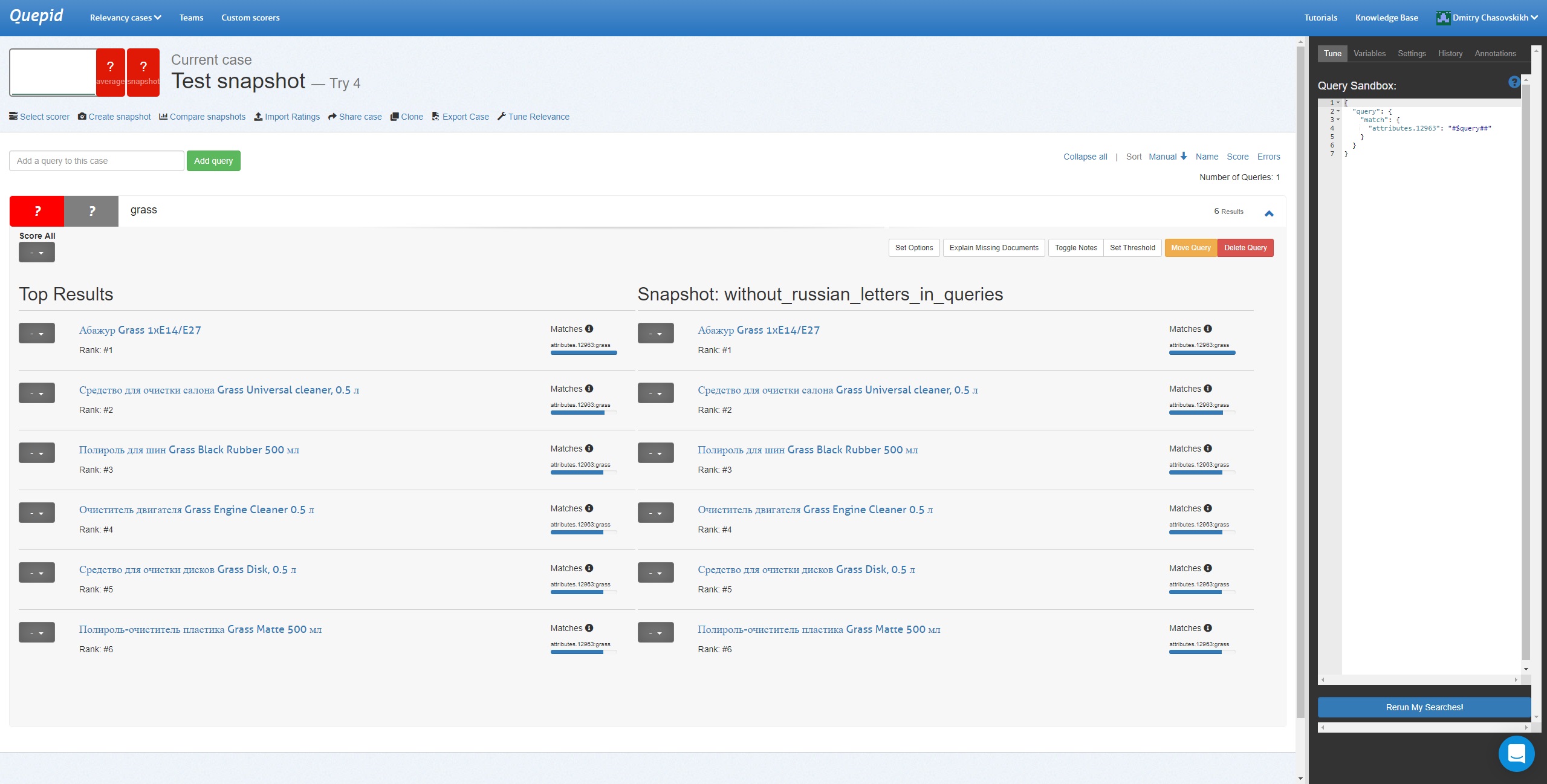
"Comparing of snapshots doesn't work, if one of the queries in Relevancy cases contains russian letters "
To Reproduce
Steps to reproduce the behavior:
Expected behavior
If all queries doesn't contain russian letters, everything works as well, we can look at old and new search results.
Screenshots

Desktop (please complete the following information):
Is your feature request related to a problem? Please describe.
I would like to be able to modify files like the Dockerfile or docker-compose.yml without breaking the caching on step 13 of the dockerfile (copying everything into the container).
Describe the solution you'd like
Either a .dockerignore file should be added that (at a minimum) excludes Dockerfiles and docker-compose.yml files, or the code that belongs inside the container should be moved to a subfolder, and only that code should be copied into it.
Additional context
I am trying to get the project building and running behind a pile of proxies. This involves changing some environment variables and adding some steps to the Dockerfile. Every time I make a change, I have to wait for RUN bundle install to run because all changes invalidate the cache on the COPY . /srv/app step.
Describe the bug
nDCG@10 scorer is returning a score of 100, regardless of how I score the documents the query is returning.
To Reproduce
Steps to reproduce the behavior:
nDCG@10Expected behavior
Marking all results as "Poor" should cause the overall score for the query to be lowered.
Screenshots
If applicable, add screenshots to help explain your problem.

Additional context
Add any other context about the problem here.
Describe the bug
Less of a bug and just cleanup to the schema. Scorers and DefaultScorers overlap each other enough that they can be merged to cleanup some code. Consolidate the scorers into one scorers table with a default flag and any other fields that may need be necessary and remove the default_scorers table.
Additional context
This will require changing the schema then updating the rails and angular bit to make use of one table versus two different ones.
Describe the bug
I created a new case, and then got the stalled "Updating Queries" message. Looking in the debugger I see
i.markUnscored is not a function
Unfortunantly on app.quepid.com we use compiled javascript, so I can really see which file this error is coming from.
To Reproduce
Steps to reproduce the behavior:
I am using Firefox
Screenshots
see the stalled "updating queries"

Additional context
Is there any way to identify this error, even if we don't know how to fix it, and message the user "Please reload the webapp".
I think this problem only occurs coming out of the setup wizard...
Describe the bug
I cannot clone a Case with only one try. If I clone with full try history it succeeds.
To Reproduce
Steps to reproduce the behavior:
Expected behavior
Should be able to clone one try only (and ideally the dropdown should show the newest try on top)
Additional context
I have started Quepid about one week ago from docker-compose
Describe the bug
The names of any custom variables are copied with "clone", but the values are not.
To Reproduce
Steps to reproduce the behavior:
Expected behavior
Variable values would be cloned with the case.
Screenshots
If applicable, add screenshots to help explain your problem.
Additional context
Add any other context about the problem here.
Describe the bug
Notes on a query are lost when you collapse then expand the query. But after a full page refresh they come back again.
To Reproduce
Steps to reproduce the behavior:
From #56 (comment) it was requested to support custom templates in the search result listing.
Describe the solution you'd like
Add templates to cases that default to the current template in Quepid. Allow for users to customize the display based on the available data.
Additional context
Because the app is angular based the templates will need to be angular. We can document the available data and allow users to render/style however they want. This can help support users that would prefer seeing search results they are familiar with if they can match the style of their own SERP.
Describe the bug
With ES 6 and 7, but not in ES 5, the explain Other function doesn't work.
To Reproduce
Steps to reproduce the behavior:
Expected behavior
you should get explains!
Is your feature request related to a problem? Please describe.
As of Solr 8.4.1 we need to tweak solr to have connectivity. There is now a wiki page for this.
Describe the solution you'd like
When I can't connect to solr in quepid it encoursages me to check the instance to see if it's running, and mentions adblockers. Lets link to wiki page.
Is your feature request related to a problem? Please describe.
Coming out of #77 and #78, the explainOther is a powerful tool but you may not know what other docs you have rated unless you know the query to use. There is no "Show me all rated docs" feature.
Describe the solution you'd like
In the Explain Missing Documents, it would be nice to click a toggle and see all the missing documents that are rated. That way you know if a doc was rated or not, or if there are ratings that need to be cleared out.
If you have defined query varialbe, like ##titleBoost##, and don't use it in the template, then the Your Knobs screen has an odd UI.
To Reproduce
Steps to reproduce the behavior:
Your Knobs.Expected behavior
Show me all knobs defined. Tell me which are in use or not.
Screenshots
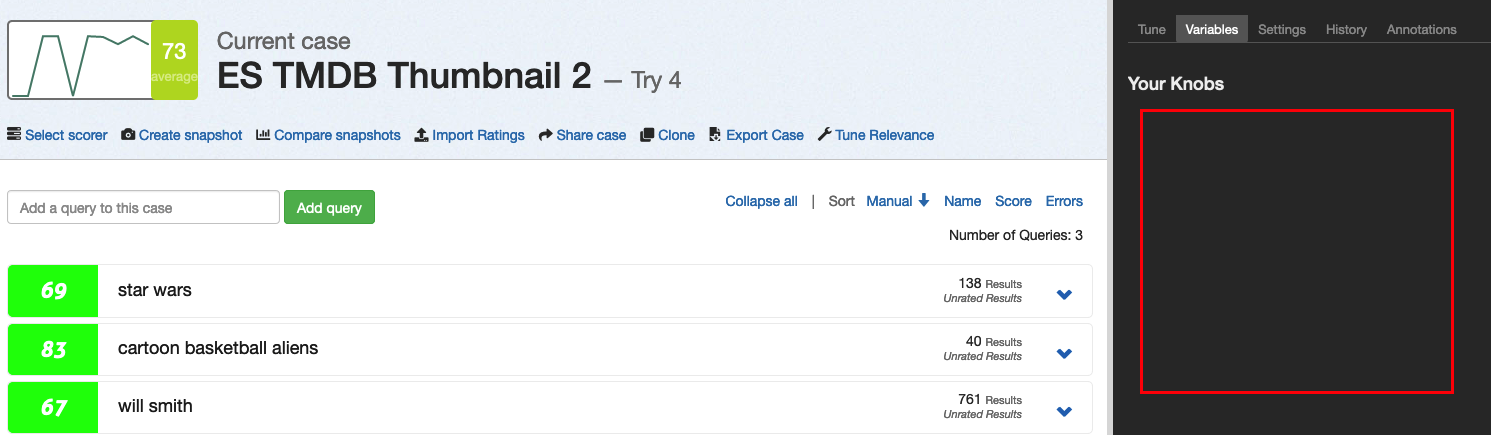
Additional context
Someday we should add a DELETE function on the knobs and dials!
Is your feature request related to a problem? Please describe.
Sometimes what is returned in Quepid isn't enough to evaluate the document. You need more context, which sometimes is best provided in the original website, or, in our case, stored in a remote PDF document.
Describe the solution you'd like
We want to be able to provide HTML link to pop open a document in a new browser. url:DOCUMENT_URL_FIELD would render a html link to the URL in the DOCUMENT_URL_FIELD.
Describe alternatives you've considered
Really want to have custom renderes for search results, where formatting of a a href link could be done, but that seems too much to tackle technically.
Thought about varilable interprolation in the url:, so you could do url:http://example.com/docs/{{doc.document_id}}.html, but again that is tougher...
Additional context
Nope.
Describe the bug
The ES TMDB data dump has poster path size of 135, but that was removed by TMDB, so we need to use a width of 185.
To Reproduce
Steps to reproduce the behavior:
1: Create TMDB test case.
2. Add thumb:poster_path
3. confirm that poster image shows up and isn't a broken image.
When you are on a specfic team page (http://app.quepid.com/teams/88) you see all the Cases. You have some options to manipulate them, for example, rename them, however that method fails.
To Reproduce
Steps to reproduce the behavior:
Look in the Browser console and you will see:
TypeError: "ctrl.thisCase.rename is not a function"
Expected behavior
You should be able to rename the case.
Additional context
What appears to be happening is that when you load a team, we just hit the API, grab the team, and via a ?load_cases method, we get the case data as well. This means that we don't go through the normal creation of a Case object via the caseSvc, so our thisCase object doesn't have the rename method added to it.
I think we need to rethink this. Should we have the load_case parameter? Or maybe we should add some method to caseSvc that gets them all by team_id? Or, should we return a list of case ids, and then go out and get them.
This was discovered during work on #61
Describe the bug
A Case shared via a Team with me. The Case on the Team page doesn't have a Try no, and when I click through the url has a NaN.
To Reproduce
Steps to reproduce the behavior:
Expected behavior
Should just be try 0 I think!
Screenshots

leads to

**Additional context
Describe the bug
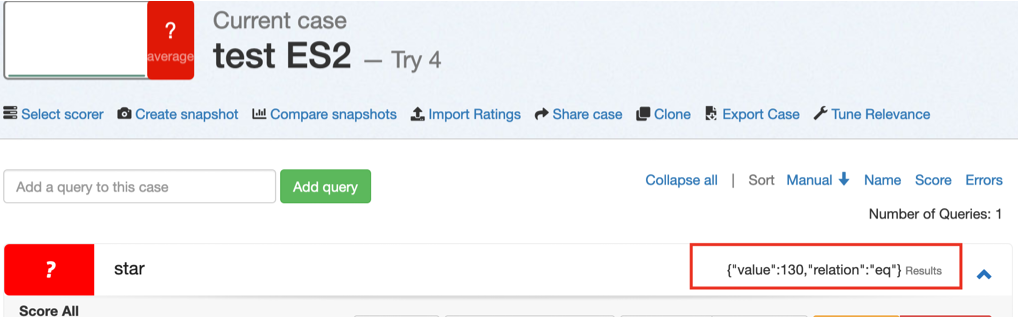
Elasticsearch 7 returns total hits in different JSON format than ES 5 and 6, which leads to odd rendering in the GUI.
To Reproduce
Steps to reproduce the behavior:
{"value":130,"relation":"eq"} Results text.130 Results textExpected behavior
Just show me the number!
Screenshots
Describe the bug
We have created a NDCG@10 scorer that is the default scorer in app.quepid.com. However, we haven't migrated that scorer to either the Docker version of Quepid OR the dev version. This means if you run Quepid in either of those modes, then you must copy the NDCG@10 scorer from app.quepid.com to your setup.
To Reproduce
Steps to reproduce the behavior:
Expected behavior
We expect a set of different scorers to be available regardless of if you are running Quepid as a developer, or on prem via Docker image, or on app.quepid.com. These should include P@, DCG@, CG@, MRR@ to start with.
Additional context
Right now we only have the old V1 scorer available to dev and docker, and our better newer scorers only in app.quepid.com. There isn't a well defined "seed" apprach.
Maybe we should think about having our scorers that we ship in a db/scorers, and that an initializer checks and updates them in the database if the scorer.js is newer that what is in the database?
Is your feature request related to a problem? Please describe.
When doing development you want some sample users to validate various use cases. The method you run is:
bin/rake db:seed:test
This makes you think it ahs something to do with setting up the testing environment for Quepid, probably populating quepid_test database! But it doesn't, it populates your quepid_development database. So lets change this to something more generic. Because you could deploy a production evnerionment, with quepid_production database, and get some sampel users via bin/rake db:seed:sample RAILS_ENV=production for example!
Describe the solution you'd like
rename method and ocs.
The ndcg@10 appears to only look at the first 10 search results, which I think is the NDCG Local implementation. We notice that for a query that has only a single result, because of how NDCG works, no matter the rating, it scores 100. This makes sense.
However, when we use the Explain Other to find other documents that are relevant and score them, because they don't show up in the search results, the score for the 1 doc result remains 100. We think we should look at the explain other rated documents as well if we don't either have 10 results, or we should use all the explain other results (and make it easy to find them in the UI).
The README.md has lots of developer docs, left over from when Quepid was a closed source project.
Rework it to point to the Wiki page, maybe duplicating the page contents on https://github.com/o19s/quepid/wiki ???
Is your feature request related to a problem? Please describe.
This is an improvement which will help measuring query scores from different angles.
For all intents and purposes, #50 is in fact a private case of the approach suggested here.
Describe the solution you'd like
Right now a single query score is computed and displayed. A single scorer is selected and used to compute those scores, which is then aggregated to become the Case Score.
Describe alternatives you've considered
We would like to be able to optionally show multiple scores - e.g. CG, NDCG@10, ERR, P@1, P@10 etc. Visually it's definitely possible to show at least 3 scores per query, and this can provide great benefit while tuning relevance - during the initial discovery and research phases, but also for on-going efforts and regression testing.
All the infrastructure for this is already built-in into quepid. Our suggestion is to allow picking more than one scorer to be used for a case. Each scorer will compute it's own score per query, and all computed scorers will be displayed with a clear indication of the scorer name used to produced that score.
A case score can then be decided to be the mean of all query-scores for selected scorers (one or more).
Comparing snapshots should also take all scorers into account (which is in-fact the goal of this change)
Please let me know your thoughts and if all the above makes sense I can go ahead and implement this change.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.