microsoft / sql-spark-connector Goto Github PK
View Code? Open in Web Editor NEWApache Spark Connector for SQL Server and Azure SQL
License: Apache License 2.0
Apache Spark Connector for SQL Server and Azure SQL
License: Apache License 2.0
Require Support to Read/Write from ADLS2 (Azure Data Lake Storage V2) from spark connector with simple connection and not have complex dependencies and jars
i have create table in synapse like this:
create table tb_trans_synapse
(
col1 int,
col2 int,
col3 int,
col4 date
);while my databricks notebook code is this:
df.write \
.format("com.microsoft.sqlserver.jdbc.spark") \
.mode("overwrite") \
.option("truncate","true") \
.option("url", url) \
.option("dbtable", table_name) \
.option("user", username) \
.option("password", password) \
.option("BatchSize","100000") \
.option("autotranslate","true") \
.option("mssqlIsolationLevel", "READ_UNCOMMITTED") \
.save()dateframe's schema is :
root
|-- col1: integer (nullable = true)
|-- col2: integer (nullable = true)
|-- col3: integer (nullable = true)
|-- col4: date (nullable = true)but some exception happened:
SqlNativeBufferBufferBulkCopy.WriteTdsDataToServer, error in OdbcDone: SqlState: 42000, NativeError: 4816, 'Error calling: bcp_done(this->GetHdbc()) | SQL Error Info: SrvrMsgState: 1, SrvrSeverity: 16, Error <1>: ErrorMsg: [Microsoft][ODBC Driver 17 for SQL Server][SQL Server]Invalid column type from bcp client for colid 4. | Error calling: pConn->Done() | state: FFFF, number: 4141, active connections: 36', Connection String: Driver={pdwodbc17e};app=TypeD00-DmsNativeWriter:DB55\mpdwsvc (19024)-ODBC;autotranslate=no;trusted_connection=yes;server=\\.\pipe\DB.55-b2bbd12c7078-0\sql\query;database=Distribution_2
is that an issue writing data to synapse table with date/timestmap type ?
I don't see an option to specify database schema (if you need to use something other than "dbo"). How to write a table to non-default schema?
I have created the Spark Dataframe using the connector. I created another dataframe based on this and aligned with the schema as in the SQL table (due to the issue mentioned here)
Even though the schema of the dataframe and the target SQL table is similar, it throws an error when I try to save the data into a sql data table.
java.sql.SQLException: Spark Dataframe and SQL Server table have differing column data types at column index 6
The readme says this connector is only supported in conjunction with "SQL Server Big Data Clusters".
How is the support insofar as Azure Databricks is concerned? Can I open a ticket with Azure Databricks about this connector?
It seems like this SQL connector would be a central component for solutions that use Databricks to load data into Azure SQL. It would seem that Microsoft engineers should be focusing on this connector to ensure the success of both their Databricks and their Azure SQL customers. Am I wrong? Am I missing something?
There seems to be a wide diversity of products within the Microsoft "big data" platform, and I may be misunderstanding the importance of "Azure Databricks". Perhaps it is prioritized beneath some other competing offerings (eg. Synapse, Big Data Clusters). Is it likely that Databricks will never get the same support that is available for some of the competing products in Azure?
I am not very familiar with the "big data" platform at Microsoft, or the related opensource communities. I still find it really confusing when certain critical components (like this connector) seem to lack the full support and sponsorship of Microsoft. (Another similar one is ".Net for Spark").
Azure Databricks 7.0 was released two months ago, and surely it was under development for many months prior. It seems like Microsoft could have had a SQL connector that was ready for us to use by now. Or perhaps it is the JDBC connector that is the only officially supported mechanism for interacting with Azure SQL? Any clarification would be appreciated.
Hello,
I am trying to save data into Azure SQL DW using Spark (Databricks) and receive that message:
com.microsoft.sqlserver.jdbc.SQLServerException: The server principal "username" is not able to access the database "master" under the current security context. ClientConnectionId:63631086-5712-487d-9481-8b5ee7a24726
This is an issue or I am doing something wrong?
Some places in the code sample execute SQL without checking for potentially dangerous embedded chars, leaving the door open for SQLi attacks (granted, there is restricted negative impact given the user is directly executing the code under their own creds). Ideally the code should check for these chars and escape them out.
ReliableSingleInstanceStrategy does not run phase 2 (union) on executors/workers. It runs this phase on driver. This means it does is not a spark job and does not show up in Spark UI. Is it by design?
Currently the phase 1 shows up as spark job with multiple tasks (1 for each partition) however when it completes the command itself does not complete as phase 2 is still running in driver and as result no update is shown to the user. Ask is to submit union task to executor so it shows up properly in Spark UI.
Because the temp table remains unique to a worker for a table, multiple tasks executing on the same worker will result in deadlock,

Does this connector support ".NET for Apache Spark"? Could you please provide an example to use this connector to read/write data to/from SQL Server stand alone instance (Not Azure/cloud based SQL Server)
I have created the Spark Dataframe using the connector. The schema of the dataframe in terms of nullable columns etc., are different from the source table and this causes the error while try to save the data into a similar sql data table.
java.sql.SQLException: Spark Dataframe and SQL Server table have differing column nullable configurations at column index 0
the legacy spark connector had an option to execute custom SQL codes such as executing stored procedure to a target database, https://github.com/Azure/azure-sqldb-spark#pushdown-query-to-azure-sql-database-or-sql-server .
It will be also be nice if the home page or sample folder has more example of how to use the functions in https://github.com/microsoft/sql-spark-connector/blob/master/src/main/scala/com/microsoft/sqlserver/jdbc/spark/utils/BulkCopyUtils.scala
The old connector (https://github.com/Azure/azure-sqldb-spark) was released on Maven for easy consumption, where as this needs to be build from scratch ourselves, which is one more piece to maintain, version etc. without any gains. Are there any plans of releasing it on e.g. Maven as the previous connector was?
Trying to use sql spark connector to connect to Azure SQL (single instance) from data bricks runtime (6.6) using Active Directory Password auth. I have uploaded adal library into the cluster.
import adal
dbname = "G_Test"
servername = "jdbc:sqlserver://" + "samplesql.database.windows.net:1433"
database_name = dbname
url = servername + ";" + "database_name=" + dbname + ";"
table_name = "dbo.cap"
aduser="[email protected]"
adpwd="mypwd"
dfCountry = spark.read
.format("com.microsoft.sqlserver.jdbc.spark")
.option("url", url)
.option("dbtable", table_name)
.option("authentication", "ActiveDirectoryPassword")
.option("hostNameInCertificate", "*.database.windows.net")
.option("user", aduser)
.option("password", adpwd)
.option("encrypt", "true").load()
Getting Authentication Exception:
in
17 .option("user", aduser)
18 .option("password", adpwd)
---> 19 .option("encrypt", "true").load()
20
21
/databricks/spark/python/pyspark/sql/readwriter.py in load(self, path, format, schema, **options)
170 return self._df(self._jreader.load(self._spark._sc._jvm.PythonUtils.toSeq(path)))
171 else:
--> 172 return self._df(self._jreader.load())
173
174 @SInCE(1.4)
/databricks/spark/python/lib/py4j-0.10.7-src.zip/py4j/java_gateway.py in call(self, *args)
1255 answer = self.gateway_client.send_command(command)
1256 return_value = get_return_value(
-> 1257 answer, self.gateway_client, self.target_id, self.name)
1258
1259 for temp_arg in temp_args:
/databricks/spark/python/pyspark/sql/utils.py in deco(*a, **kw)
61 def deco(*a, **kw):
62 try:
---> 63 return f(*a, **kw)
64 except py4j.protocol.Py4JJavaError as e:
65 s = e.java_exception.toString()
/databricks/spark/python/lib/py4j-0.10.7-src.zip/py4j/protocol.py in get_return_value(answer, gateway_client, target_id, name)
326 raise Py4JJavaError(
327 "An error occurred while calling {0}{1}{2}.\n".
--> 328 format(target_id, ".", name), value)
329 else:
330 raise Py4JError(
Py4JJavaError: An error occurred while calling o510.load.
: java.lang.NoClassDefFoundError: com/microsoft/aad/adal4j/AuthenticationException
at com.microsoft.sqlserver.jdbc.SQLServerConnection.getFedAuthToken(SQLServerConnection.java:3609)
at com.microsoft.sqlserver.jdbc.SQLServerConnection.onFedAuthInfo(SQLServerConnection.java:3580)
at com.microsoft.sqlserver.jdbc.SQLServerConnection.processFedAuthInfo(SQLServerConnection.java:3548)
at com.microsoft.sqlserver.jdbc.TDSTokenHandler.onFedAuthInfo(tdsparser.java:261)
at com.microsoft.sqlserver.jdbc.TDSParser.parse(tdsparser.java:103)
at com.microsoft.sqlserver.jdbc.SQLServerConnection.sendLogon(SQLServerConnection.java:4290)
at com.microsoft.sqlserver.jdbc.SQLServerConnection.logon(SQLServerConnection.java:3157)
at com.microsoft.sqlserver.jdbc.SQLServerConnection.access$100(SQLServerConnection.java:82)
at com.microsoft.sqlserver.jdbc.SQLServerConnection$LogonCommand.doExecute(SQLServerConnection.java:3121)
at com.microsoft.sqlserver.jdbc.TDSCommand.execute(IOBuffer.java:7151)
at com.microsoft.sqlserver.jdbc.SQLServerConnection.executeCommand(SQLServerConnection.java:2478)
at com.microsoft.sqlserver.jdbc.SQLServerConnection.connectHelper(SQLServerConnection.java:2026)
at com.microsoft.sqlserver.jdbc.SQLServerConnection.login(SQLServerConnection.java:1687)
at com.microsoft.sqlserver.jdbc.SQLServerConnection.connectInternal(SQLServerConnection.java:1528)
at com.microsoft.sqlserver.jdbc.SQLServerConnection.connect(SQLServerConnection.java:866)
at com.microsoft.sqlserver.jdbc.SQLServerDriver.connect(SQLServerDriver.java:569)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$createConnectionFactory$1.apply(JdbcUtils.scala:64)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$createConnectionFactory$1.apply(JdbcUtils.scala:55)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCRDD$.resolveTable(JDBCRDD.scala:56)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCRelation$.getSchema(JDBCRelation.scala:210)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcRelationProvider.createRelation(JdbcRelationProvider.scala:35)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:350)
at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:311)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:297)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:203)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:380)
at py4j.Gateway.invoke(Gateway.java:295)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:251)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.ClassNotFoundException: com.microsoft.aad.adal4j.AuthenticationException
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:352)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
... 36 more
Dataset<Row> driverNodesDataset =
spark.read()
.format("com.microsoft.sqlserver.jdbc.spark")
.option("url", url).option("dbtable", table_name)
.option("user", username)
.option("password", password)
.load();
I am getting an error Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/spark/sql/execution/datasources/jdbc/JdbcOptionsInWrite while executing the above code.
My Spark Cluster Version is 2.3.0. Does this work with Spark 2.3?
Thanks.
Are you planning to support SQL Graph Database tables?
We are looking to use SQL bulk copy with Databricks runtime 7.3, which supports Spark 3.0 and above. Can you please let us know what the plan is to make the Spark SQL connector compatible with at least Spark 3.0?
The previous, unrelated version of this solution supported DDL and DML operations. We need the ability to execute Update, Delete, and Stored Procedures from within a Spark notebook.

com.microsoft.sqlserver.jdbc.SQLServerException: Login failed for user 'AZURE_DBRICKS_USER'. ClientConnectionId:99b4b16e-d74b-44e3-aed5-b408589e16ea
I have no idea what is wrong with this, using sql spark connector it works pretty fine
Note: connection info removed from the picture on purpose
BULK INSERT allow to specify if data already has a specific order so that Azure SQL / SQL Server can avoid sorting it again if inserting data into a clustered index.
https://docs.microsoft.com/en-us/sql/t-sql/statements/bulk-insert-transact-sql?view=sql-server-ver15
The changelist URL / file is missing
About This Release
This is a V1 release of the Apache Spark Connector for SQL Server and Azure SQL. It is a high-performance connector that enables you transfer data from Spark to SQLServer.
For main changes from previous releases and known issues please refer to CHANGELIST
https://github.com/microsoft/sql-spark-connector/blob/master/docs/CHANGELIST.md
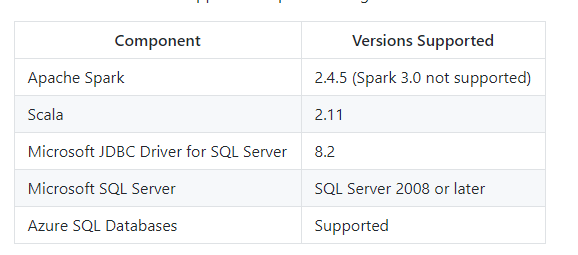
I am trying to read a table from an Azure SQL Server instance using AAD. I run the following code snippet on a Databricks cluster running Apache Spark 2.4.5, Scala 2.11 with the sql-spark-connector JAR installed as well as the adal PyPi package:
import adal
aadPassword = dbutils.secrets.get(scope = "szk1", key = "szkpw2")
server_name = "jdbc:sqlserver://mydatabsename.database.windows.net"
database_name = "dbname"
url = server_name + ";" + "databaseName=" + database_name + ";"
jdbc_df = spark.read \
.format("com.microsoft.sqlserver.jdbc.spark") \
.option("url", url) \
.option("databaseName", "azprdDbReportingAnalytics") \
.option("dbtable", "UK_PredVsActual") \
.option("authentication", "ActiveDirectoryPassword") \
.option("user", "[email protected]") \
.option("password", aadPassword) \
.option("encrypt", "true") \
.option("ServerCertificate", "false") \
.option("driver", "com.microsoft.sqlserver.jdbc.SQLServerDriver") \
.load()
This is the error I receive:
com.microsoft.sqlserver.jdbc.SQLServerException: The driver could not establish a secure connection to SQL Server by using Secure Sockets Layer (SSL) encryption. Error: "java.security.cert.CertificateException: Failed to validate the server name in a certificate during Secure Sockets Layer (SSL) initialization.". ClientConnectionId:6f8c1a95-4f62-435b-a4b6-93ce93e3bbbd
Expanded:
Py4JJavaError Traceback (most recent call last)
<command-3456430591294638> in <module>
20 .option("password", aadPassword) \
21 .option("encrypt", "true") \
---> 22 .option("driver", "com.microsoft.sqlserver.jdbc.SQLServerDriver") \
23 .load()
/databricks/spark/python/pyspark/sql/readwriter.py in load(self, path, format, schema, **options)
170 return self._df(self._jreader.load(self._spark._sc._jvm.PythonUtils.toSeq(path)))
171 else:
--> 172 return self._df(self._jreader.load())
173
174 @since(1.4)
/databricks/spark/python/lib/py4j-0.10.7-src.zip/py4j/java_gateway.py in __call__(self, *args)
1255 answer = self.gateway_client.send_command(command)
1256 return_value = get_return_value(
-> 1257 answer, self.gateway_client, self.target_id, self.name)
1258
1259 for temp_arg in temp_args:
/databricks/spark/python/pyspark/sql/utils.py in deco(*a, **kw)
61 def deco(*a, **kw):
62 try:
---> 63 return f(*a, **kw)
64 except py4j.protocol.Py4JJavaError as e:
65 s = e.java_exception.toString()
/databricks/spark/python/lib/py4j-0.10.7-src.zip/py4j/protocol.py in get_return_value(answer, gateway_client, target_id, name)
326 raise Py4JJavaError(
327 "An error occurred while calling {0}{1}{2}.\n".
--> 328 format(target_id, ".", name), value)
329 else:
330 raise Py4JError(
Py4JJavaError: An error occurred while calling o537.load.
: com.microsoft.sqlserver.jdbc.SQLServerException: The driver could not establish a secure connection to SQL Server by using Secure Sockets Layer (SSL) encryption. Error: "java.security.cert.CertificateException: Failed to validate the server name in a certificate during Secure Sockets Layer (SSL) initialization.". ClientConnectionId:6f8c1a95-4f62-435b-a4b6-93ce93e3bbbd
at com.microsoft.sqlserver.jdbc.SQLServerConnection.terminate(SQLServerConnection.java:2435)
at com.microsoft.sqlserver.jdbc.TDSChannel.enableSSL(IOBuffer.java:1816)
at com.microsoft.sqlserver.jdbc.SQLServerConnection.connectHelper(SQLServerConnection.java:2022)
at com.microsoft.sqlserver.jdbc.SQLServerConnection.login(SQLServerConnection.java:1687)
at com.microsoft.sqlserver.jdbc.SQLServerConnection.connectInternal(SQLServerConnection.java:1528)
at com.microsoft.sqlserver.jdbc.SQLServerConnection.connect(SQLServerConnection.java:866)
at com.microsoft.sqlserver.jdbc.SQLServerDriver.connect(SQLServerDriver.java:569)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$createConnectionFactory$1.apply(JdbcUtils.scala:64)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$createConnectionFactory$1.apply(JdbcUtils.scala:55)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCRDD$.resolveTable(JDBCRDD.scala:56)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCRelation$.getSchema(JDBCRelation.scala:210)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcRelationProvider.createRelation(JdbcRelationProvider.scala:35)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:351)
at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:311)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:297)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:203)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:380)
at py4j.Gateway.invoke(Gateway.java:295)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:251)
at java.lang.Thread.run(Thread.java:748)
Caused by: javax.net.ssl.SSLHandshakeException: java.security.cert.CertificateException: Failed to validate the server name in a certificate during Secure Sockets Layer (SSL) initialization.
at sun.security.ssl.Alerts.getSSLException(Alerts.java:198)
at sun.security.ssl.SSLSocketImpl.fatal(SSLSocketImpl.java:1967)
at sun.security.ssl.Handshaker.fatalSE(Handshaker.java:331)
at sun.security.ssl.Handshaker.fatalSE(Handshaker.java:325)
at sun.security.ssl.ClientHandshaker.serverCertificate(ClientHandshaker.java:1688)
at sun.security.ssl.ClientHandshaker.processMessage(ClientHandshaker.java:226)
at sun.security.ssl.Handshaker.processLoop(Handshaker.java:1082)
at sun.security.ssl.Handshaker.process_record(Handshaker.java:1010)
at sun.security.ssl.SSLSocketImpl.readRecord(SSLSocketImpl.java:1079)
at sun.security.ssl.SSLSocketImpl.performInitialHandshake(SSLSocketImpl.java:1388)
at sun.security.ssl.SSLSocketImpl.startHandshake(SSLSocketImpl.java:1416)
at sun.security.ssl.SSLSocketImpl.startHandshake(SSLSocketImpl.java:1400)
at com.microsoft.sqlserver.jdbc.TDSChannel.enableSSL(IOBuffer.java:1753)
... 25 more
Caused by: java.security.cert.CertificateException: Failed to validate the server name in a certificate during Secure Sockets Layer (SSL) initialization.
at com.microsoft.sqlserver.jdbc.TDSChannel$HostNameOverrideX509TrustManager.validateServerNameInCertificate(IOBuffer.java:1543)
at com.microsoft.sqlserver.jdbc.TDSChannel$HostNameOverrideX509TrustManager.checkServerTrusted(IOBuffer.java:1456)
at sun.security.ssl.AbstractTrustManagerWrapper.checkServerTrusted(SSLContextImpl.java:1099)
at sun.security.ssl.ClientHandshaker.serverCertificate(ClientHandshaker.java:1670)
... 33 more
I was using a separate cluster before where I had set up the manual dependencies for the legacy version of this connector. This cluster is a new cluster with only the JAR for the connector and the adal PyPi package installed. Any help with why this is happening would be really appreciated.
Finding that this occurs when writing to Azure SQL db.
Spark column is FloatType and jdbc converts to Real.
When setting truncate to True, it throws error:
Connector write failed An error occurred while calling o885.save. : java.sql.SQLException: Spark Dataframe and SQL Server table have differing column data types at column index 4 at com.microsoft.sqlserver.jdbc.spark.BulkCopyUtils$.com$microsoft$sqlserver$jdbc$spark$BulkCopyUtils$$assertCondition(BulkCopyUtils.scala:526) at com.microsoft.sqlserver.jdbc.spark.BulkCopyUtils$$anonfun$matchSchemas$1.apply$mcVI$sp(BulkCopyUtils.scala:276) at scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:160) at com.microsoft.sqlserver.jdbc.spark.BulkCopyUtils$.matchSchemas(BulkCopyUtils.scala:249) at com.microsoft.sqlserver.jdbc.spark.BulkCopyUtils$.getColMetaData(BulkCopyUtils.scala:207) at com.microsoft.sqlserver.jdbc.spark.Connector.write(Connector.scala:53) at com.microsoft.sqlserver.jdbc.spark.DefaultSource.createRelation(DefaultSource.scala:51) at org.apache.spark.sql.execution.datasources.SaveIntoDataSourceCommand.run(SaveIntoDataSourceCommand.scala:45) at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:72) at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:70) at org.apache.spark.sql.execution.command.ExecutedCommandExec.doExecute(commands.scala:88) at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:146) at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:134) at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$5.apply(SparkPlan.scala:187) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151) at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:183) at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:134) at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:116) at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:116) at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:711) at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:711) at org.apache.spark.sql.execution.SQLExecution$$anonfun$withCustomExecutionEnv$1.apply(SQLExecution.scala:111) at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:240) at org.apache.spark.sql.execution.SQLExecution$.withCustomExecutionEnv(SQLExecution.scala:97) at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:170) at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:711) at org.apache.spark.sql.DataFrameWriter.saveToV1Source(DataFrameWriter.scala:307) at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:293) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244) at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:380) at py4j.Gateway.invoke(Gateway.java:295) at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132) at py4j.commands.CallCommand.execute(CallCommand.java:79) at py4j.GatewayConnection.run(GatewayConnection.java:251) at java.lang.Thread.run(Thread.java:748)
Is there support for any DML available e.g. UPDATE, DELETE, MERGE on the datasets as I could not find them on the example.
If no, what are the suggested options.
Does it support bulk copy when reading? If not, why? Is it because of any limitation in azure sql sdk?
Any idea how to fix this?
: java.lang.ClassNotFoundException: Failed to find data source: com.microsoft.sqlserver.jdbc.spark. Please find packages at http://spark.apache.org/third-party-projects.html
conf = SparkConf() \
.setAppName(appName) \
.setMaster(master) \
.set("spark.driver.extraClassPath","C:/Users/XXXX//mssql-jdbc-8.3.1.jre14-preview.jar")\
.set("spark.sql.execution.arrow.enabled", True)
server_name = "jdbc:sqlserver://mydbsample.database.windows.net"
database_name = "dbsample"
url = server_name + ";" + "database_name=" + database_name + ";"
table_name = "[SalesLT].[Product]"
username = "akshay"
password = "Password_1" # Please specify password here
try:
jdbcDF = spark.read \
.format("com.microsoft.sqlserver.jdbc.spark") \
.option("url", url) \
.option("dbtable", table_name) \
.option("user", username) \
.option("password", password).load()
except ValueError as error :
print("Connector read failed", error)
I tried to test the Spark connector using the above in Databricks (installed by creating a jar file using sbt and uploading to cluster).
Received the following error at line .option("password", password).load()
java.lang.NoClassDefFoundError: org/apache/spark/internal/Logging$class
detailed_error.txt
Could you please help?
Hello,
I get error connecting to Azure SQL Server database when using spark connector using DataBricks notebook. DataBricks cluster has the spark connector loaded. Any help appreciated.
Trying to extract data from parquet files in DataBricks and load into Azure SQL servere database.
Following the example mentioned in https://docs.microsoft.com/en-us/sql/connect/spark/connector?view=sql-server-ver15
I have used 2 different options to create SQL Server database
Azure Dedicated SQL Pool (formerly SQL DW)
Synapse workspace dedicated SQL pool
To extract data I use
df = spark.read.parquet("abfss://[email protected]/Extract/*.parquet")
I have com.microsoft.azure:spark-mssql-connector:1.0.1 installed on databricks cluster and use the below code to load data into SQL Server database on Azure.
ERROR java.lang.RuntimeException: com.microsoft.sqlserver.jdbc.SQLServerDriver does not allow create table as select.
server_name = "jdbc:sqlserver://esqlserver.database.windows.net,1433"
database_name = "dedpool"
url = server_name + ";" + "databaseName=" + database_name + ";"
table_name = "dbo.spark_test1"
username = "ETL"
password = xxxx
try:
df.write \
.format("com.microsoft.sqlserver.jdbc.SQLServerDriver") \
.mode("append") \ .option("url", url) \
.option("dbtable", table_name) \
.option("user", username) \
.option("password", password) \
.save()
except ValueError as error : print("Connector write failed", error)
Thanks,
When you create with NO_DUPLICATES staging tables are created and dropped
Given App Names may have special characters, need to use QUOTENAME when generating create/drop table syntax else there is a possibility of failure if the app name has some special character. This for example always fails on databricks
This is true for both the drop AND the create of staging tables.
https://docs.microsoft.com/en-us/sql/t-sql/functions/quotename-transact-sql?view=sql-server-ver15
TSQL Example:
drop table ##app-20200723122746-0000_627
Msg 102, Level 15, State 1, Line 20
Incorrect syntax near '-'.
Log4j logs:
/07/23 14:34:59 ERROR ReliableSingleInstanceStrategy: cleanupStagingTables: Exception while dropping table ##app-20200723122746-0000_407 :Incorrect syntax near '-'.
20/07/23 14:34:59 ERROR ReliableSingleInstanceStrategy: cleanupStagingTables: Exception while dropping table ##app-20200723122746-0000_408 :Incorrect syntax near '-'.
20/07/23 14:34:59 ERROR ScalaDriverLocal: User Code Stack Trace:
com.microsoft.sqlserver.jdbc.SQLServerException: Incorrect syntax near '-'.
at com.microsoft.sqlserver.jdbc.SQLServerException.makeFromDatabaseError(SQLServerException.java:258)
at com.microsoft.sqlserver.jdbc.SQLServerStatement.getNextResult(SQLServerStatement.java:1535)
at com.microsoft.sqlserver.jdbc.SQLServerStatement.doExecuteStatement(SQLServerStatement.java:845)
at com.microsoft.sqlserver.jdbc.SQLServerStatement$StmtExecCmd.doExecute(SQLServerStatement.java:752)
at com.microsoft.sqlserver.jdbc.TDSCommand.execute(IOBuffer.java:7151)
at com.microsoft.sqlserver.jdbc.SQLServerConnection.executeCommand(SQLServerConnection.java:2478)
at com.microsoft.sqlserver.jdbc.SQLServerStatement.executeCommand(SQLServerStatement.java:219)
at com.microsoft.sqlserver.jdbc.SQLServerStatement.executeStatement(SQLServerStatement.java:199)
at com.microsoft.sqlserver.jdbc.SQLServerStatement.executeUpdate(SQLServerStatement.java:680)
at com.microsoft.sqlserver.jdbc.spark.BulkCopyUtils$.executeUpdate(BulkCopyUtils.scala:371)
at com.microsoft.sqlserver.jdbc.spark.ReliableSingleInstanceStrategy$.com$microsoft$sqlserver$jdbc$spark$ReliableSingleInstanceStrategy$$createStagingTable(ReliableSingleInstanceStrategy.scala:223)
at com.microsoft.sqlserver.jdbc.spark.ReliableSingleInstanceStrategy$$anonfun$createStagingTables$2.apply(ReliableSingleInstanceStrategy.scala:237)
at com.microsoft.sqlserver.jdbc.spark.ReliableSingleInstanceStrategy$$anonfun$createStagingTables$2.apply(ReliableSingleInstanceStrategy.scala:236)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at scala.collection.Iterator$class.foreach(Iterator.scala:891)
In matchSchemas, it seems auto-increment columns are not accounted for. This is causing my write (using SaveMode.Overwrite and truncate = true) to fail.
I downloaded the jar file and added it to my project and updated the code accordingly.
dataFrame
.write
.format("com.microsoft.sqlserver.jdbc.spark")
.mode("append")
.option("url", url)
.option("dbtable", destinationTable)
.option("user", username)
.option("password", password)
.option("reliabilityLevel", "BEST_EFFORT")
.option("tableLock", "true")
.save()While running the code, I get an issue below :
java.lang.NoClassDefFoundError: org/apache/spark/sql/execution/datasources/jdbc/JdbcOptionsInWrite
at java.lang.ClassLoader.defineClass1(Native Method)
at java.lang.ClassLoader.defineClass(ClassLoader.java:763)
at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142)
at java.net.URLClassLoader.defineClass(URLClassLoader.java:468)
at java.net.URLClassLoader.access$100(URLClassLoader.java:74)
at java.net.URLClassLoader$1.run(URLClassLoader.java:369)
at java.net.URLClassLoader$1.run(URLClassLoader.java:363)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:362)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at java.lang.Class.getDeclaredConstructors0(Native Method)
at java.lang.Class.privateGetDeclaredConstructors(Class.java:2671)
at java.lang.Class.getConstructor0(Class.java:3075)
at java.lang.Class.newInstance(Class.java:412)
at org.apache.spark.sql.execution.datasources.DataSource.planForWriting(DataSource.scala:544)
at org.apache.spark.sql.DataFrameWriter.saveToV1Source(DataFrameWriter.scala:278)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:267)
at td2.spark.common.SQLUtilities.writeToSqlTable(SQLUtilities.scala:78)
at td2.spark.da.TD2DBConnector$.loadToDestination(TD2DBConnector.scala:382)
at td2.spark.da.TD2DBConnector$.insertDASessionPAAS(TD2DBConnector.scala:171)
at td2.spark.da.MainWorkflow$.main(MainWorkflow.scala:68)
at td2.spark.da.MainWorkflow.main(MainWorkflow.scala)
Caused by: java.lang.ClassNotFoundException: org.apache.spark.sql.execution.datasources.jdbc.JdbcOptionsInWrite
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 24 more
server_name = "jdbc:sqlserver://{SERVER_ADDR}"
database_name = "database_name"
url = servername + ";" + "database_name=" + dbname + ";"
servername variable should be server_name
dbname should be database_name
When trying to read / write data from SQL tables, the schema doesn't automatically handle nullable type columns. It would be good to handle these automatically in the connector.
Sample error when there is a mismatch:
java.sql.SQLException: Spark Dataframe and SQL Server table have differing column nullable configurations at column index 5
Py4JJavaError Traceback (most recent call last) in 17 .option("password", sqlmipwd) \ 18 .option("applicationintent", "ReadWrite") \ ---> 19 .mode("append") \ 20 .save() 21 except ValueError as error : /databricks/spark/python/pyspark/sql/readwriter.py in save(self, path, format, mode, partitionBy, **options) 735 self.format(format) 736 if path is None: --> 737 self._jwrite.save() 738 else: 739 self._jwrite.save(path) /databricks/spark/python/lib/py4j-0.10.7-src.zip/py4j/java_gateway.py in call(self, *args) 1255 answer = self.gateway_client.send_command(command) 1256 return_value = get_return_value( -> 1257 answer, self.gateway_client, self.target_id, self.name) 1258 1259 for temp_arg in temp_args: /databricks/spark/python/pyspark/sql/utils.py in deco(*a, **kw) 61 def deco(*a, **kw): 62 try: ---> 63 return f(*a, **kw) 64 except py4j.protocol.Py4JJavaError as e: 65 s = e.java_exception.toString() /databricks/spark/python/lib/py4j-0.10.7-src.zip/py4j/protocol.py in get_return_value(answer, gateway_client, target_id, name) 326 raise Py4JJavaError( 327 "An error occurred while calling {0}{1}{2}.\n". --> 328 format(target_id, ".", name), value) 329 else: 330 raise Py4JError( Py4JJavaError: An error occurred while calling o9488.save. : java.sql.SQLException: Spark Dataframe and SQL Server table have differing column nullable configurations at column index 5 at com.microsoft.sqlserver.jdbc.spark.BulkCopyUtils$.com$microsoft$sqlserver$jdbc$spark$BulkCopyUtils$$assertCondition(BulkCopyUtils.scala:526) at com.microsoft.sqlserver.jdbc.spark.BulkCopyUtils$$anonfun$matchSchemas$1.apply$mcVI$sp(BulkCopyUtils.scala:279) at scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:160) at com.microsoft.sqlserver.jdbc.spark.BulkCopyUtils$.matchSchemas(BulkCopyUtils.scala:249) at com.microsoft.sqlserver.jdbc.spark.BulkCopyUtils$.getColMetaData(BulkCopyUtils.scala:207) at com.microsoft.sqlserver.jdbc.spark.Connector.write(Connector.scala:66) at com.microsoft.sqlserver.jdbc.spark.DefaultSource.createRelation(DefaultSource.scala:51) at org.apache.spark.sql.execution.datasources.SaveIntoDataSourceCommand.run(SaveIntoDataSourceCommand.scala:45) at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70) at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68) at org.apache.spark.sql.execution.command.ExecutedCommandExec.doExecute(commands.scala:86) at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:150) at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:138) at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$5.apply(SparkPlan.scala:191) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151) at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:187) at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:138) at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:117) at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:115) at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:710) at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:710) at org.apache.spark.sql.execution.SQLExecution$$anonfun$withCustomExecutionEnv$1$$anonfun$apply$1.apply(SQLExecution.scala:112) at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:217) at org.apache.spark.sql.execution.SQLExecution$$anonfun$withCustomExecutionEnv$1.apply(SQLExecution.scala:98) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:835) at org.apache.spark.sql.execution.SQLExecution$.withCustomExecutionEnv(SQLExecution.scala:74) at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:169) at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:710) at org.apache.spark.sql.DataFrameWriter.saveToV1Source(DataFrameWriter.scala:306) at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:292) at sun.reflect.GeneratedMethodAccessor435.invoke(Unknown Source) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244) at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:380) at py4j.Gateway.invoke(Gateway.java:295) at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132) at py4j.commands.CallCommand.execute(CallCommand.java:79) at py4j.GatewayConnection.run(GatewayConnection.java:251) at java.lang.Thread.run(Thread.java:748)
When connecting to AzureSQL Serverless which are configured to go to sleep/pause mode [Mostly in Dev/Stage], Spark should not fail, rather it should wait for 5-7 sec and retry 3 times before throwing exception
Hi All,
Config - Databricks 6.6 (Spark 2.45)
Target - Azure SQL DB Premium P4
This connector , code
FLOC_VW.write \ .format("com.microsoft.sqlserver.jdbc.spark") \ .mode("overwrite") \ .option("url", url) \ .option("dbtable", tableName) \ .option("user", Username) \ .option("password", Password) \ .option("BEST_EFFORT","true") \ .option("tabLock","true") \ .save()
Minutes taken - 53 on Average
Same configuration but - spark connector - Performance 4x faster <10 mins of average
Any suggestions where it could be going wrong?
Are there plan to support Spark 3.0 with this connector ?
I have a table like this:
Create table Test
(
Id int,
Year nvarchar(4),
Month nvarch(2),
Date As (Year + '-' + Month)
)
Because Date is a computed column, my dataframe doesn't have this column, I get exception 'Spark Dataframe and SQL Server table have different numbers of columns'.
I'm trying to ingest data with a spark job from kafta into big data cluster's data pool, by running the spark job in an external spark cluster (external to the big data cluster). This is my configuration into the .py:
datapool_table = 'SYSLOG_TEST_TABLE' datasource_name = 'SqlDataPool' url = 'jdbc:sqlserver://192.168.14.150:31433;database=sales;' logs_df.write.format('com.microsoft.sqlserver.jdbc.spark').mode('append').option('url', url).option('dbtable', datapool_table).option('user', user).option('password', password).option('dataPoolDataSource',datasource_name).save()
I'm getting this error:
Caused by: com.microsoft.sqlserver.jdbc.SQLServerException: The TCP/IP connection to the host data-0-1.data-0-svc, port 1433 has failed. Error: "data-0-1.data-0-svc. Verify the connection properties. Make sure that an instance of SQL Server is running on the host and accepting TCP/IP connections at the port. Make sure that TCP connections to the port are not blocked by a firewall.".
Is it possible to load into a data pool from an external spark cluster? Is there any configuration in the big data cluster that must be set up?
Thank you
Since this is supposed to be the Successor of https://github.com/Azure/azure-sqldb-spark, the old connector had the option to use sqlContext.sqlDBQuery(config) to execute arbitrary SQL code. There should be a possibility to migrate from the old to the new connector - and to have this option you need to support aribitaray SQL.
This will also help many other scenarios in migration and speed up in loads - more generic loading scenarios at least. It could cover issues #68 and #46. I posted this idea there already once, but thought it would be worth its own topic.
I think you have this option in your code already because you need to run truncate table or create table, its just not exposed externally - or am I missing something?
I myself have been coding it manually on the old connector with this functionality to bulk load in STAGING tables and was running sqlContext.sqlDBQuery(config) before and after for table creation / partition switching / table removal.
I could envision something like azure data factory has on the COPY Activity - an aribitaray "PRE-COPY-SCRIPT" (https://docs.microsoft.com/en-us/azure/data-factory/tutorial-bulk-copy-portal#create-pipelines) if you do not want to expose something like sqlContext.sqlDBQuery(config).
Adding a PRE/POST COPYSCRIPT would allow for a streamlined "dataframe" interface. And for example using the PRE-COPY-SCRIPT on and empty dataframe could allow arbitrary SQL to be run.
Options like "overwrite" or "truncate: true" would then just be special simple cases of an aribitary pre-copy script.
Whatever options you intend to provided, you cannot cover every usecase, so better give the uses to option to do what they want if they know what the do.
Curious to hear other options.
When loading a partitioned table a very common pattern is to load a staging table and then perform a switch-in into the target partitioned table. That would allow the ability to perform bulk loading into tables that are still used, as loading will be done on the staging table and switch-in will be done only at the end of all load (+indexing if needed) operations, increasing concurrency a lot.
When column contains timestamp with non 0 microseconds the .save() fails with generic "com.microsoft.sqlserver.jdbc.SQLServerException: The connection is closed." exception.
Truncation of microsecond to 0 works around the problem. The output table created by the .save() has column of "datetime" data type. Hence i presume it might be related to handling of "rounding" microseconds to satisfy precision requirements of "datetime" datatype.
env:
how to reproduce:
batchTimestamp = datetime.now()
#
# uncomment to truncate milliseconds, only truncation to 0 works
#batchTimestamp = batchTimestamp.replace(microsecond = 0)
print(batchTimestamp.isoformat(sep=' '))
df = spark \
.createDataFrame([("a", 1), ("b", 2), ("c", 3)], ["Col1", "Col2"]) \
.withColumn('ts', lit(batchTimestamp))
df.show()
df \
.write \
.format("com.microsoft.sqlserver.jdbc.spark") \
.mode("overwrite") \
.option("url", sql_url) \
.option("dbtable", 'test_table') \
.option("user", sql_username) \
.option("password", sql_password) \
.save()Today JDBC defaults when you use savemode overwrite is to truncate - http://spark.apache.org/docs/latest/sql-data-sources-jdbc.html --> “It defaults to false"
This has a few problems but the main one is that we don't maintain schema.
a. A table with columnstore now becomes a heap/rowstore
b. Any other secondary indexes are lost
We should make the default when you have savemode overwrite to Truncate and not drop/recreate.
Scala samples or usage pattern are welcomed.
Could you please confirm if Azure SQL Synapse is officially supported? The doc mentions below
Note: Azure Synapse (Azure SQL DW) use is not tested with this connector. While it may work, there may be unintended consequences.
I get below error when writing to SQL Synapse
Caused by: java.lang.ClassNotFoundException: com.microsoft.sqlserver.jdbc.ISQLServerBulkData
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at com.databricks.backend.daemon.driver.ClassLoaders$LibraryClassLoader.loadClass(ClassLoaders.scala:151)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
... 33 more
When an Emoji is present in one of the dataframe fields (e.g 🐝🌿) the Write operation fails with com.microsoft.sqlserver.jdbc.SQLServerException: The connection is closed.
Full stack:
org.apache.spark.SparkException: Job aborted due to stage failure: Task 1 in stage 18.0 failed 4 times, most recent failure: Lost task 1.3 in stage 18.0 (TID 1814, 10.5.1.5, executor 1): com.microsoft.sqlserver.jdbc.SQLServerException: The connection is closed.
at com.microsoft.sqlserver.jdbc.SQLServerException.makeFromDriverError(SQLServerException.java:227)
at com.microsoft.sqlserver.jdbc.SQLServerConnection.checkClosed(SQLServerConnection.java:796)
at com.microsoft.sqlserver.jdbc.SQLServerConnection.rollback(SQLServerConnection.java:2698)
at com.microsoft.sqlserver.jdbc.spark.BulkCopyUtils$.savePartition(BulkCopyUtils.scala:53)
at com.microsoft.sqlserver.jdbc.spark.SingleInstanceWriteStrategies$$anonfun$write$2.apply(BestEffortSingleInstanceStrategy.scala:30)
at com.microsoft.sqlserver.jdbc.spark.SingleInstanceWriteStrategies$$anonfun$write$2.apply(BestEffortSingleInstanceStrategy.scala:29)
at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$28.apply(RDD.scala:987)
at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$28.apply(RDD.scala:987)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2321)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2321)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.doRunTask(Task.scala:140)
at org.apache.spark.scheduler.Task.run(Task.scala:113)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$17.apply(Executor.scala:606)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1541)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:612)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
When the emoji is removed the operation is successful, the database is definitely capable of supporting emoji as they can be inserted by other means, just not with this connector.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.