![]()
Born out of Microsoft’s SQL Server Big Data Clusters investments, the Apache Spark Connector for SQL Server and Azure SQL is a high-performance connector that enables you to use transactional data in big data analytics and persists results for ad-hoc queries or reporting. The connector allows you to use any SQL database, on-premises or in the cloud, as an input data source or output data sink for Spark jobs.
This library contains the source code for the Apache Spark Connector for SQL Server and Azure SQL.
Apache Spark is a unified analytics engine for large-scale data processing.
There are three version sets of the connector available through Maven, a 2.4.x, a 3.0.x and a 3.1.x compatible version. All versions can be found here and can be imported using the coordinates below:
| Connector | Maven Coordinate | Scala Version |
|---|---|---|
| Spark 2.4.x compatible connector | com.microsoft.azure:spark-mssql-connector:1.0.2 |
2.11 |
| Spark 3.0.x compatible connector | com.microsoft.azure:spark-mssql-connector_2.12:1.1.0 |
2.12 |
| Spark 3.1.x compatible connector | com.microsoft.azure:spark-mssql-connector_2.12:1.2.0 |
2.12 |
| Spark 3.3.x compatible connector | com.microsoft.azure:spark-mssql-connector_2.12:1.3.0 |
2.12 |
| Spark 3.4.x compatible connector | com.microsoft.azure:spark-mssql-connector_2.12:1.4.0 |
2.12 |
The latest Spark 2.4.x compatible connector is on v1.0.2.
The latest Spark 3.0.x compatible connector is on v1.1.0.
The latest Spark 3.1.x compatible connector is on v1.2.0.
For main changes from previous releases and known issues please refer to CHANGELIST
- Support for all Spark bindings (Scala, Python, R)
- Basic authentication and Active Directory (AD) Key Tab support
- Reordered DataFrame write support
- Support for write to SQL Server Single instance and Data Pool in SQL Server Big Data Clusters
- Reliable connector support for Sql Server Single Instance
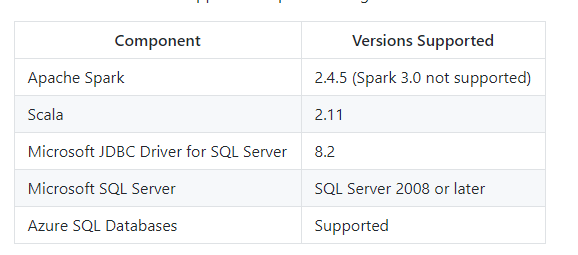
| Component | Versions Supported |
|---|---|
| Apache Spark | 2.4.x, 3.0.x, 3.1.x, 3.3.x |
| Scala | 2.11, 2.12 |
| Microsoft JDBC Driver for SQL Server | 8.4.1 |
| Microsoft SQL Server | SQL Server 2008 or later |
| Azure SQL Databases | Supported |
Note: Azure Synapse (Azure SQL DW) use is not tested with this connector. While it may work, there may be unintended consequences.
The Apache Spark Connector for SQL Server and Azure SQL supports the options defined here: SQL DataSource JDBC
In addition following options are supported
| Option | Default | Description |
|---|---|---|
| reliabilityLevel | "BEST_EFFORT" | "BEST_EFFORT" or "NO_DUPLICATES". "NO_DUPLICATES" implements an reliable insert in executor restart scenarios |
| dataPoolDataSource | none | none implies the value is not set and the connector should write to SQl Server Single Instance. Set this value to data source name to write a Data Pool Table in Big Data Cluster |
| isolationLevel | "READ_COMMITTED" | Specify the isolation level |
| tableLock | "false" | Implements an insert with TABLOCK option to improve write performance |
| schemaCheckEnabled | "true" | Disables strict dataframe and sql table schema check when set to false |
Other Bulk api options can be set as options on the dataframe and will be passed to bulkcopy apis on write
Apache Spark Connector for SQL Server and Azure SQL is up to 15x faster than generic JDBC connector for writing to SQL Server. Note performance characteristics vary on type, volume of data, options used and may show run to run variations. The following performance results are the time taken to overwrite a sql table with 143.9M rows in a spark dataframe. The spark dataframe is constructed by reading store_sales HDFS table generated using spark TPCDS Benchmark. Time to read store_sales to dataframe is excluded. The results are averaged over 3 runs. Note: The following results were achieved using the Apache Spark 2.4.5 compatible connector. These numbers are not a guarantee of performance.
| Connector Type | Options | Description | Time to write |
|---|---|---|---|
| JDBCConnector | Default | Generic JDBC connector with default options | 1385s |
| sql-spark-connector | BEST_EFFORT | Best effort sql-spark-connector with default options | 580s |
| sql-spark-connector | NO_DUPLICATES | Reliable sql-spark-connector | 709s |
| sql-spark-connector | BEST_EFFORT + tabLock=true | Best effort sql-spark-connector with table lock enabled | 72s |
| sql-spark-connector | NO_DUPLICATES + tabLock=true | Reliable sql-spark-connector with table lock enabled | 198s |
Config
- Spark config :
num_executors = 20,executor_memory = '1664m',executor_cores = 2 - Data Gen config :
scale_factor=50,partitioned_tables=true - Data file Store_sales with number of of rows 143,997,590
Environment
- SQL Server Big Data Cluster CU5
- Master + 6 nodes
- Each node gen 5 server, 512GB Ram, 4TB NVM per node, NIC 10GB
This issue arises from using an older version of the mssql driver (which is now included in this connector) in your hadoop environment. If you are coming from using the previous Azure SQL Connector and have manually installed drivers onto that cluster for AAD compatibility, you will need to remove those drivers.
Steps to fix the issue:
- If you are using a generic Hadoop environment, check and remove the mssql jar:
rm $HADOOP_HOME/share/hadoop/yarn/lib/mssql-jdbc-6.2.1.jre7.jar. If you are using Databricks, add a global or cluster init script to remove old versions of the mssql driver from the/databricks/jarsfolder, or add this line to an existing script:rm /databricks/jars/*mssql* - Add the
adal4jandmssqlpackages, I used Maven, but anyway should work. DO NOT install the SQL spark connector this way. - Add the driver class to your connection configuration:
connectionProperties = {
"Driver": "com.microsoft.sqlserver.jdbc.SQLServerDriver"
}
For more information and explanation, visit the closed issue.
The Apache Spark Connector for SQL Server and Azure SQL is based on the Spark DataSourceV1 API and SQL Server Bulk API and uses the same interface as the built-in JDBC Spark-SQL connector. This allows you to easily integrate the connector and migrate your existing Spark jobs by simply updating the format parameter with com.microsoft.sqlserver.jdbc.spark.
To include the connector in your projects download this repository and build the jar using SBT.
Receiving java.lang.NoClassDefFoundError when trying to use the new connector with Azure Databricks?
If you are migrating from the previous Azure SQL Connector for Spark and have manually installed drivers onto that cluster for AAD compatibility, you will most likely need to remove those custom drivers, restore the previous drivers that ship by default with Databricks, uninstall the previous connector, and restart your cluster. You may be better off spinning up a new cluster.
With this new connector, you should be able to simply install onto a cluster (new or existing cluster that hasn't had its drivers modified) or a cluster which previously used modified drivers for the older Azure SQL Connector for Spark provided the modified drivers were removed and the previous default drivers restored.
See Issue #26 for more details.
The previous Azure SQL Connector for Spark provided the ability to execute custom SQL code like DML or DDL statements through the connector. This functionality is out-of-scope of this connector since it is based on the DataSource APIs. This functionality is readily provided by libraries like pyodbc or you can use the standard java sql interfaces as well.
You can read the closed issue and view community provided alternatives in Issue #21.
overwrite mode will first DROP the table if it already exists in the database by default. Please use this option with due care to avoid unexpected data loss!
overwrite if you do not use the option truncate, on recreation of the table indexes will be lost. For example a columnstore table would now be a heap. If you want to maintain existing indexing please also specify option truncate with value true. i.e .option("truncate",true)
server_name = "jdbc:sqlserver://{SERVER_ADDR}"
database_name = "database_name"
url = server_name + ";" + "databaseName=" + database_name + ";"
table_name = "table_name"
username = "username"
password = "password123!#" # Please specify password here
try:
df.write \
.format("com.microsoft.sqlserver.jdbc.spark") \
.mode("overwrite") \
.option("url", url) \
.option("dbtable", table_name) \
.option("user", username) \
.option("password", password) \
.save()
except ValueError as error :
print("Connector write failed", error)try:
df.write \
.format("com.microsoft.sqlserver.jdbc.spark") \
.mode("append") \
.option("url", url) \
.option("dbtable", table_name) \
.option("user", username) \
.option("password", password) \
.save()
except ValueError as error :
print("Connector write failed", error)This connector by default uses READ_COMMITTED isolation level when performing the bulk insert into the database. If you wish to override this to another isolation level, please use the mssqlIsolationLevel option as shown below.
.option("mssqlIsolationLevel", "READ_UNCOMMITTED") \jdbcDF = spark.read \
.format("com.microsoft.sqlserver.jdbc.spark") \
.option("url", url) \
.option("dbtable", table_name) \
.option("user", username) \
.option("password", password).load()context = adal.AuthenticationContext(authority)
token = context.acquire_token_with_client_credentials(resource_app_id_url, service_principal_id, service_principal_secret)
access_token = token["accessToken"]
jdbc_db = spark.read \
.format("com.microsoft.sqlserver.jdbc.spark") \
.option("url", url) \
.option("dbtable", table_name) \
.option("accessToken", access_token) \
.option("encrypt", "true") \
.option("hostNameInCertificate", "*.database.windows.net") \
.load()jdbc_df = spark.read \
.format("com.microsoft.sqlserver.jdbc.spark") \
.option("url", url) \
.option("dbtable", table_name) \
.option("authentication", "ActiveDirectoryPassword") \
.option("user", user_name) \
.option("password", password) \
.option("encrypt", "true") \
.option("hostNameInCertificate", "*.database.windows.net") \
.load()A required dependency must be installed in order to authenticate using Active Directory.
For Scala, the com.microsoft.aad.adal4j artifact will need to be installed.
For Python, the adal library will need to be installed. This is available
via pip.
Please check the sample notebooks for examples.
The Apache Spark Connector for Azure SQL and SQL Server is an open source project. This connector does not come with any Microsoft support. For issues with or questions about the connector, please create an Issue in this project repository. The connector community is active and monitoring submissions.
Visit the Connector project in the Projects tab to see needed / planned items. Feel free to make an issue and start contributing!
This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact [email protected] with any additional questions or comments.






![microsoft-github-operations[bot] avatar](https://avatars.githubusercontent.com/in/41902?v=4 "microsoft-github-operations[bot]")