


Check out our website.
Have a question? Join our community on Slack or Linen!
For the complete documentation, go here.
Get the LangStream VS Code extension here.
Warning CLI requires Java 11+ to be already installed on your machine.
There are multiple ways to install the CLI.
-
MacOS:
- Homebrew
brew install LangStream/langstream/langstream- Binary with curl
curl -Ls "https://raw.githubusercontent.com/LangStream/langstream/main/bin/get-cli.sh" | bash -
Unix:
- Binary with curl
curl -Ls "https://raw.githubusercontent.com/LangStream/langstream/main/bin/get-cli.sh" | bash
Verify the binary is available:
langstream -V
Refer to the CLI documentation to learn more.
Run the sample Chat Completions application on-the-fly:
export OPEN_AI_ACCESS_KEY=your-key-here
langstream docker run test \
-app https://github.com/LangStream/langstream/blob/main/examples/applications/openai-completions \
-s https://github.com/LangStream/langstream/blob/main/examples/secrets/secrets.yamlIn a different terminal window:
langstream gateway chat test -cg consume-output -pg produce-input -p sessionId=$(uuidgen)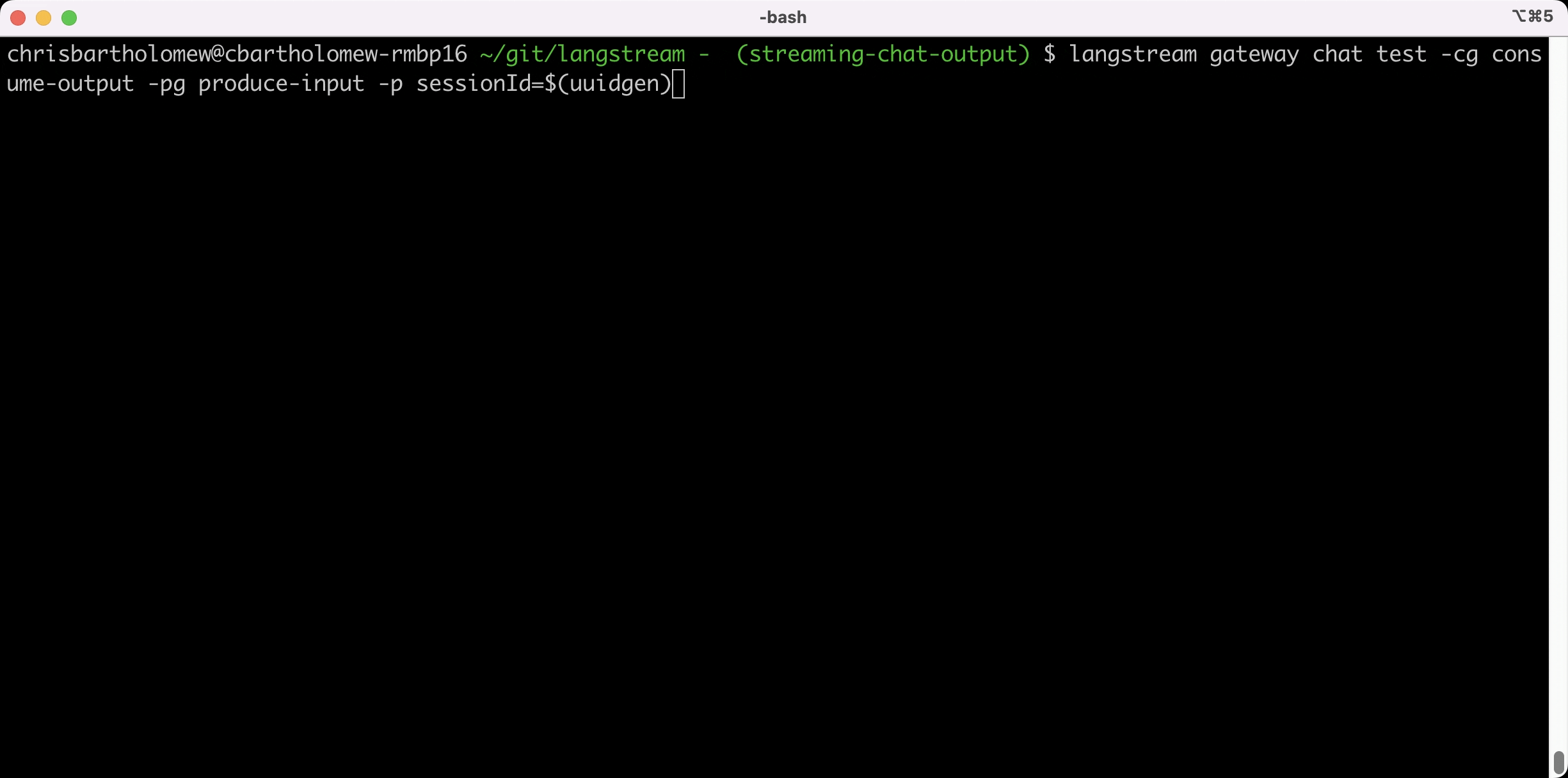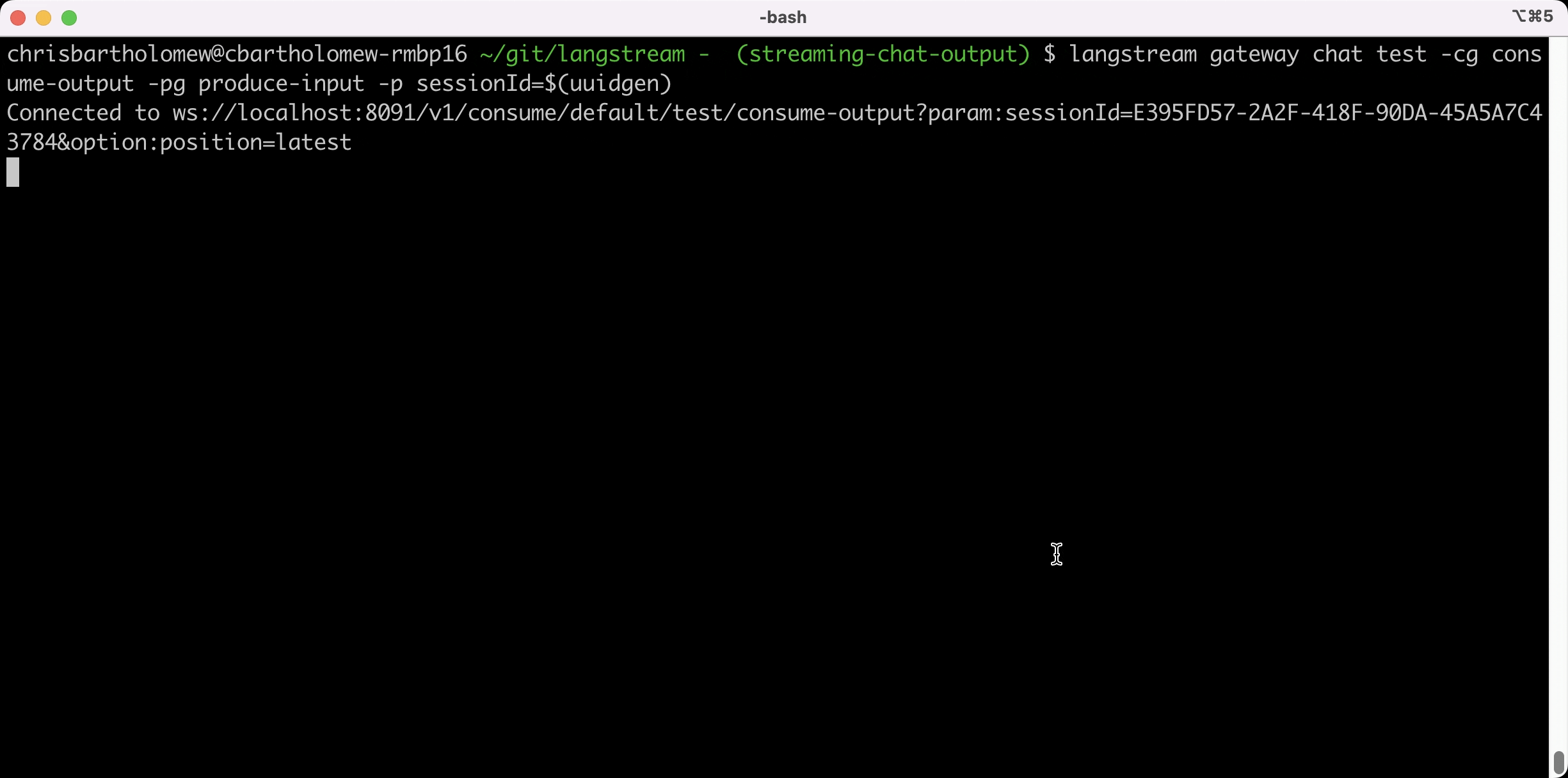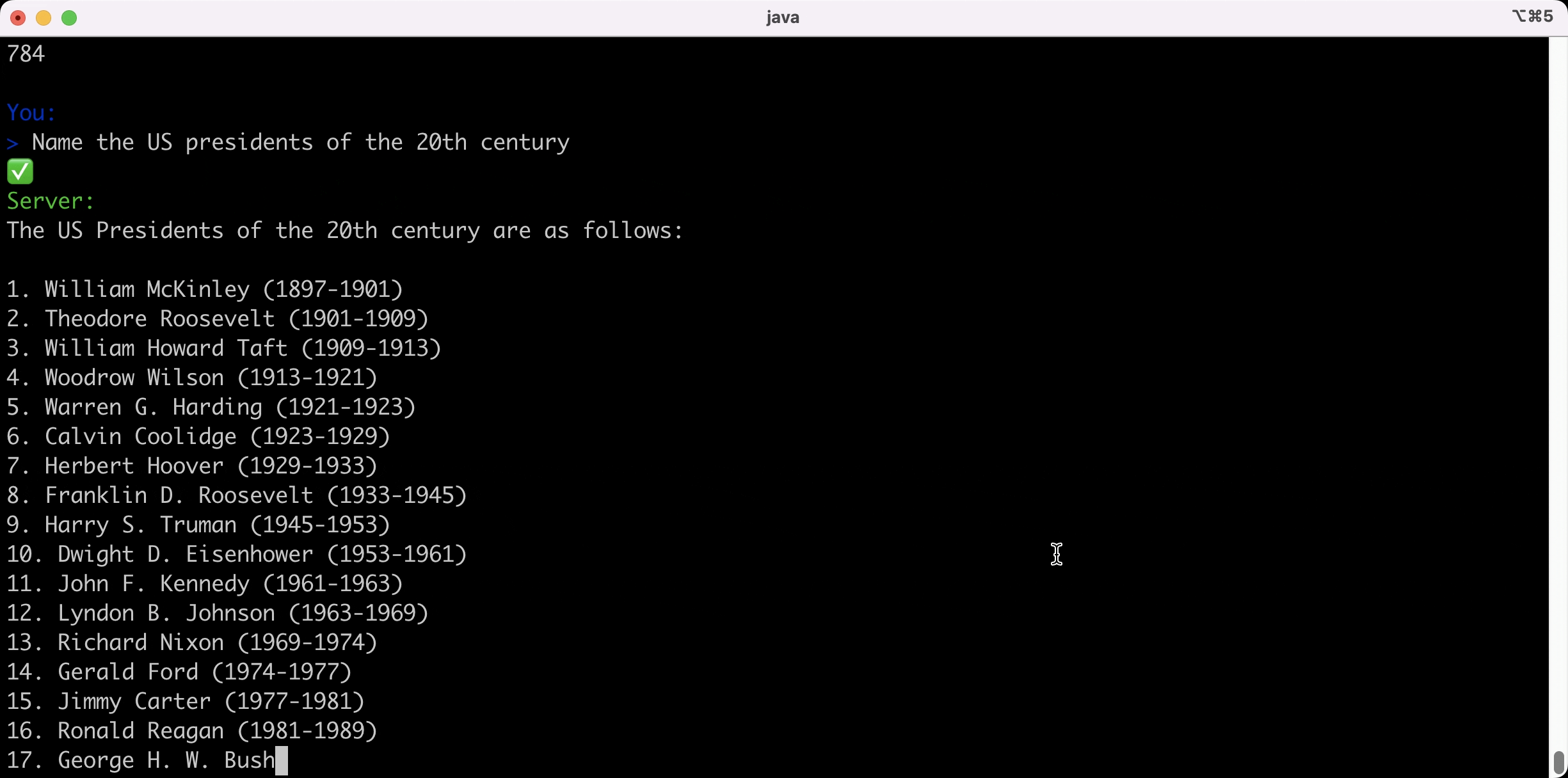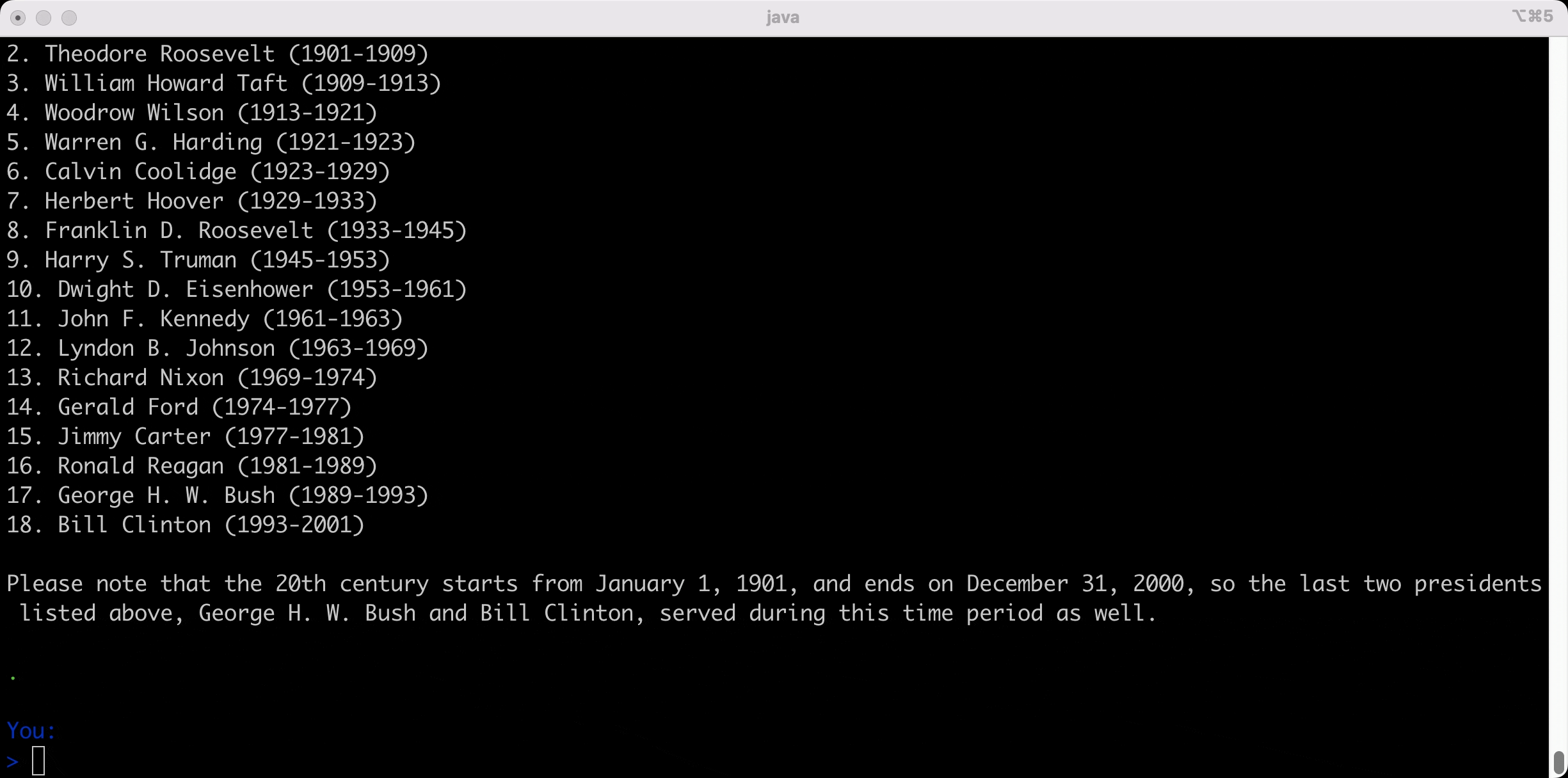
See more sample applications in the examples folder.
To create your own application, refer to the developer documentation.
LangStream is production-ready, and it's highly suggested deploying it on a Kubernetes cluster. The following Kubernetes distributions are supported:
- Amazon EKS
- Azure AKS
- Google GKE
- Minikube
To run a LangStream cluster, you need to the following external components:
- Apache Kafka or Apache Pulsar cluster
- S3 API-compatible storage or Azure Blob Storage (Amazon S3, Google Cloud Storage, Azure Blob Storage, MinIO)
To install LangStream, you can use the langstream Helm chart:
helm repo add langstream https://langstream.ai/charts
helm repo update
Then create the values file. At this point you already need the storage service to be up and running.
In case you're using S3, you can use the following values:
codeStorage:
type: s3
configuration:
access-key: <aws-access-key>
secret-key: <aws-secret-key>For Azure:
codeStorage:
type: azure
configuration:
endpoint: https://<storage-account>.blob.core.windows.net
container: langstream
storage-account-name: <storage-account>
storage-account-key: <storage-account-key>Now install LangStream with it:
helm install -n langstream --create-namespace langstream langstream/langstream --values values.yaml
kubectl wait -n langstream deployment/langstream-control-plane --for condition=available --timeout=300s
To create a local LangStream cluster, it's recommended to use minikube.
mini-langstream comes in help for installing and managing your local cluster.
To install mini-langstream:
- MacOS:
brew install LangStream/langstream/mini-langstream- Unix:
curl -Ls "https://raw.githubusercontent.com/LangStream/langstream/main/mini-langstream/get-mini-langstream.sh" | bashThen startup the cluster:
mini-langstream startDeploy an application:
export OPEN_AI_ACCESS_KEY=<your-openai-api-key>
mini-langstream cli apps deploy my-app -app https://github.com/LangStream/langstream/tree/main/examples/applications/openai-completions -s https://github.com/LangStream/langstream/blob/main/examples/secrets/secrets.yamlTo stop the cluster:
mini-langstream deleteRefer to the mini-langstream documentation to learn more.
Requirements for building the project:
- Docker
- Java 17
- Git
- Python 3.11+ and PIP
If you want to test local code changes, you can use mini-langstream.
mini-langstream dev startThis command will build the images in the minikube context and install all the LangStream services with the snapshot image.
Once the cluster is running, if you want to build abd load a new version of a specific service you can run:
mini-langstream dev build <service>or for all the services
mini-langstream dev build


![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")














































































































