🚩 [Update] The compatible EFT label files are now available here, which helps to train a much stronger HMR baseline. See issue #58.
This repository contains the code for the following papers:
PyMAF-X: Towards Well-aligned Full-body Model Regression from Monocular Images
Hongwen Zhang, Yating Tian, Yuxiang Zhang, Mengcheng Li, Liang An, Zhenan Sun, Yebin Liu
TPAMI, 2023
[Project Page] [Paper] [Code: smplx branch]
PyMAF: 3D Human Pose and Shape Regression with Pyramidal Mesh Alignment Feedback Loop
Hongwen Zhang*, Yating Tian*, Xinchi Zhou, Wanli Ouyang, Yebin Liu, Limin Wang, Zhenan Sun
* Equal contribution
ICCV, 2021 (Oral Paper)
[Project Page] [Paper] [Code: smpl branch]
Preview of demo results:
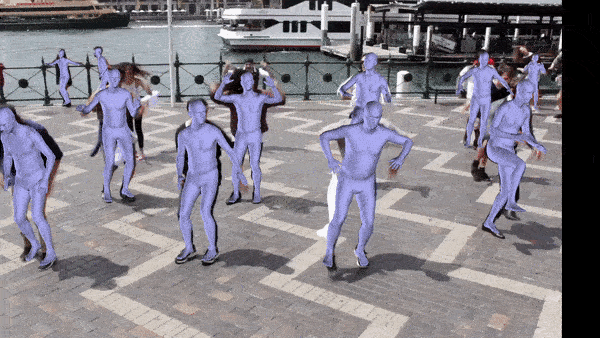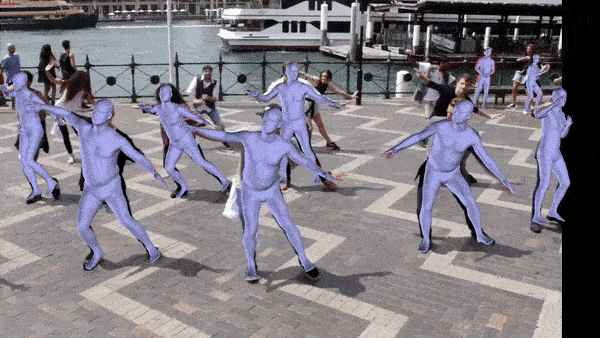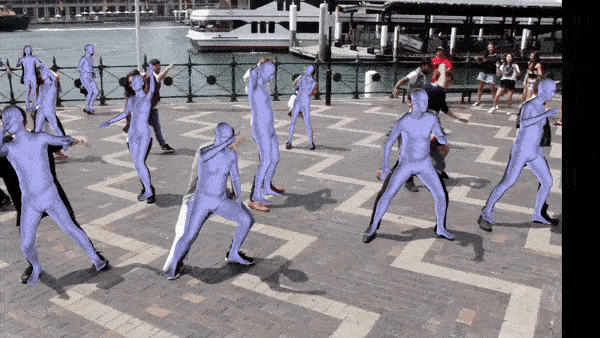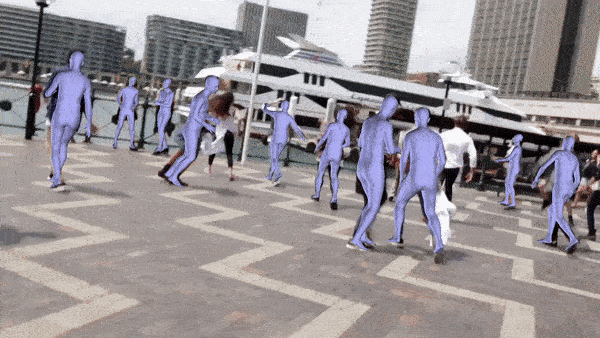
Frame by frame reconstruction. Video clipped from here.

Frame by frame reconstruction. Video from here.
More results: Click Here
- Python 3.8
conda create --no-default-packages -n pymafx python=3.8
conda activate pymafx
- PyTorch tested on version 1.9.0
conda install pytorch==1.9.0 torchvision==0.10.0 cudatoolkit=11.1 -c pytorch -c conda-forge
pip install "git+https://github.com/facebookresearch/pytorch3d.git@stable"
- other packages listed in
requirements.txt
pip install -r requirements.txt
mesh_downsampling.npz & DensePose UV data
- Run the following script to fetch mesh_downsampling.npz & DensePose UV data from other repositories.
bash fetch_data.sh
SMPL model files
- Collect SMPL model files from https://smpl.is.tue.mpg.de and UP. Rename model files and put them into the
./data/smpldirectory.
Fetch preprocessed data from SPIN.
Fetch final_fits data from SPIN. [important note: using EFT fits for training is much better. Compatible npz files are available here]
Download the pre-trained model and put it into the
./data/pretrained_modeldirectory.
After collecting the above necessary files, the directory structure of ./data is expected as follows.
./data
├── dataset_extras
│ └── .npz files
├── J_regressor_extra.npy
├── J_regressor_h36m.npy
├── mesh_downsampling.npz
├── pretrained_model
│ └── PyMAF_model_checkpoint.pt
├── smpl
│ ├── SMPL_FEMALE.pkl
│ ├── SMPL_MALE.pkl
│ └── SMPL_NEUTRAL.pkl
├── smpl_mean_params.npz
├── final_fits
│ └── .npy files
└── UV_data
├── UV_Processed.mat
└── UV_symmetry_transforms.mat
You can first give it a try on Google Colab using the notebook we have prepared, which is no need to prepare the environment yourself:
Run the demo code.
python3 demo.py --checkpoint=data/pretrained_model/PyMAF_model_checkpoint.pt --img_file examples/COCO_val2014_000000019667.jpg
# video with single person
python3 demo.py --checkpoint=data/pretrained_model/PyMAF_model_checkpoint.pt --vid_file examples/dancer.mp4
# video with multiple persons
python3 demo.py --checkpoint=data/pretrained_model/PyMAF_model_checkpoint.pt --vid_file examples/flashmob.mp4
-
Download the preprocessed data coco_2014_val.npz. Put it into the
./data/dataset_extrasdirectory. -
Run the COCO evaluation code.
python3 eval_coco.py --checkpoint=data/pretrained_model/PyMAF_model_checkpoint.pt
Run the evaluation code. Using --dataset to specify the evaluation dataset.
# Example usage:
# 3DPW
python3 eval.py --checkpoint=data/pretrained_model/PyMAF_model_checkpoint.pt --dataset=3dpw --log_freq=20
🚀 [Important update]: Using EFT fits is recommended, as it can significantly improve the baseline. Compatible data is available here. See issue #58 for more training details using the EFT labels.
Below messages are the training details of the conference version of PyMAF.
To perform training, we need to collect preprocessed files of training datasets at first.
The preprocessed labels have the same format as SPIN and can be retrieved from here. Please refer to SPIN for more details about data preprocessing.
PyMAF is trained on Human3.6M at the first stage and then trained on the mixture of both 2D and 3D datasets at the second stage. Example usage:
# training on COCO
CUDA_VISIBLE_DEVICES=0 python3 train.py --regressor pymaf_net --single_dataset --misc TRAIN.BATCH_SIZE 64
# training on mixed datasets
CUDA_VISIBLE_DEVICES=0 python3 train.py --regressor pymaf_net --pretrained_checkpoint path/to/checkpoint_file.pt --misc TRAIN.BATCH_SIZE 64
Running the above commands will use Human3.6M or mixed datasets for training, respectively. We can monitor the training process by setting up a TensorBoard at the directory ./logs.
If this work is helpful in your research, please cite the following paper.
@inproceedings{pymaf2021,
title={PyMAF: 3D Human Pose and Shape Regression with Pyramidal Mesh Alignment Feedback Loop},
author={Zhang, Hongwen and Tian, Yating and Zhou, Xinchi and Ouyang, Wanli and Liu, Yebin and Wang, Limin and Sun, Zhenan},
booktitle={Proceedings of the IEEE International Conference on Computer Vision},
year={2021}
}
@article{pymafx2023,
title={PyMAF-X: Towards Well-aligned Full-body Model Regression from Monocular Images},
author={Zhang, Hongwen and Tian, Yating and Zhang, Yuxiang and Li, Mengcheng and An, Liang and Sun, Zhenan and Liu, Yebin},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
year={2023}
}
The code is developed upon the following projects. Many thanks to their contributions.





















































































































