




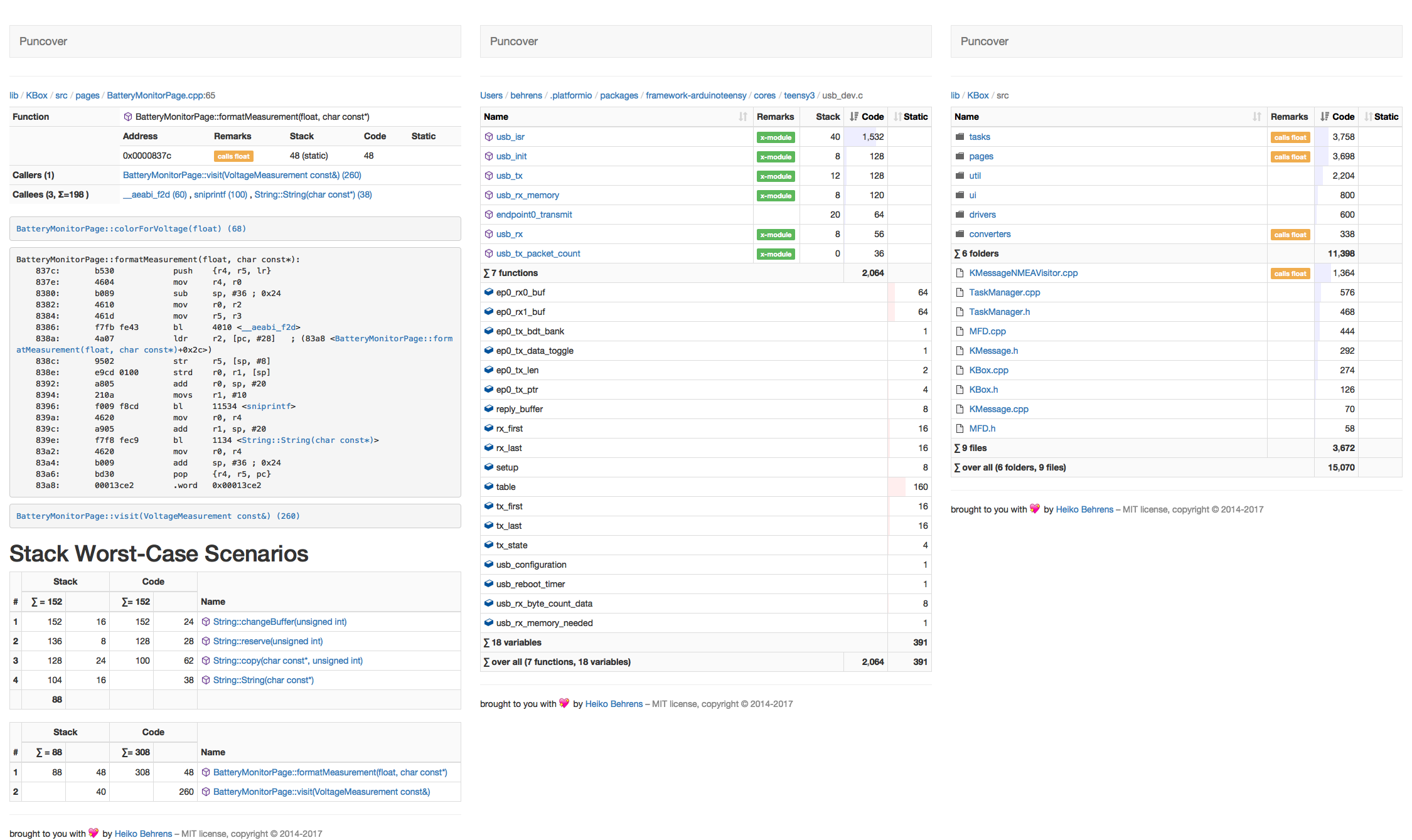
Analyzes C/C++ binaries for code size, static variables and stack usages. It creates a report with disassembler and call-stack analysis per directory, file, or function.
Install with pip:
pip install puncoverRun it by passing the binary to analyze:
puncover --elf_file project.elf
...
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)Open the link in your browser to view the analysis.
To run the tests locally, you need to install the development dependencies:
-
install pyenv: https://github.com/pyenv/pyenv
curl https://pyenv.run | bash -
install all the python environments, using this bashism (this can take a few minutes):
for _py in $(<.python-version ); do pyenv install ${_py}; done
-
install the development dependencies:
pip install -r requirements-dev.txt
Then you can run the tests with:
toxor, to target only the current python on $PATH:
tox -e pySee release.sh for a script that automates the above steps. This example will
work with the PyPi tokens (now required):
PUNCOVER_VERSION=0.3.5 TWINE_PASSWORD="<pypi token>" TWINE_USERNAME=__token__ ./release.shOnly for reference, the release script should take care of all of this.
Click to expand
-
Update the version in
puncover/__version__.py. -
Commit the version update:
git add . && git commit -m "Bump version to x.y.z"
-
Create an annotated tag:
git tag -a {-m=,}x.y.z -
Push the commit and tag:
git push && git push --tags -
Either wait for the GitHub Action to complete and download the release artifact for uploading: https://github.com/HBehrens/puncover/actions OR Build the package locally:
python setup.py sdist bdist_wheel -
Upload the package to PyPI:
twine upload dist/* -
Create GitHub releases:
gh release create --generate-notes x.y.z- attach the artifacts to the release too:
gh release upload x.y.z dist/*
Contributions are welcome! Please open an issue or pull request on GitHub.





























































































































