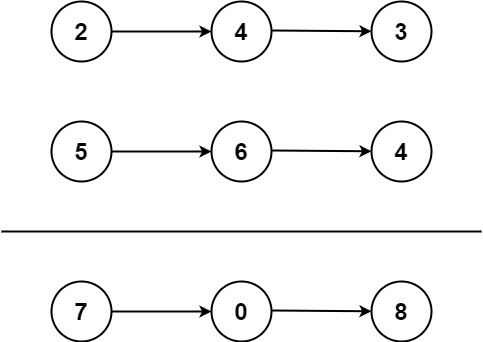
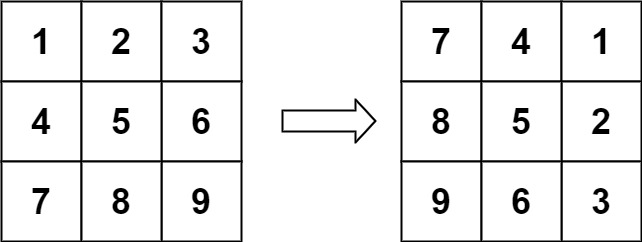
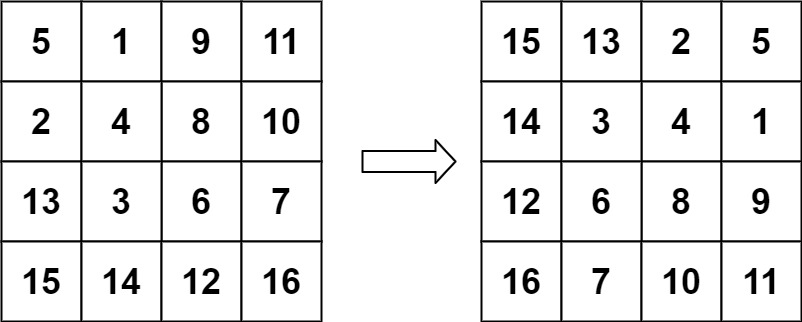
English | 简体中文
Provide all my solutions and explanations in Chinese for all the Leetcode coding problems.
Same as this: LeetCode All in One 题目讲解汇总(持续更新中...)
Click below image to watch YouTube Video

Note: All explanations are written in Github Issues, please do not create any new issue or pull request in this project since the problem index should be consistent with the issue index, thanks!
('$' means the problem is locked on Leetcode, '*' means the problem is related to Database, '#' means the problem is related to Shell, '~' means the concurrency problems.)
| # | Title | Solution | Difficulty |
|---|---|---|---|
| 1352 | Product of the Last K Numbers | 50.20% | Medium |
| 1351 | Count Negative Numbers in a Sorted Matrix | 77.30% | Easy |
| 1350 | Students With Invalid Departments * $ | 89.90% | Easy |
| 1349 | Maximum Students Taking Exam | 49.80% | Hard |
| 1348 | Tweet Counts Per Frequency | 44.00% | Medium |
| 1347 | Minimum Number of Steps to Make Two Strings Anagram | 78.00% | Medium |
| 1346 | Check If N and Its Double Exist | 36.70% | Easy |
| 1345 | Jump Game IV | 46.60% | Hard |
| 1344 | Angle Between Hands of a Clock | 63.40% | Medium |
| 1343 | Number of Sub-arrays of Size K and Average Greater than or Equal to Threshold | 68.10% | Medium |
| 1342 | Number of Steps to Reduce a Number to Zero | 84.90% | Easy |
| 1341 | Movie Rating * | 43.80% | Medium |
| 1340 | Jump Game V | 62.60% | Hard |
| 1339 | Maximum Product of Splitted Binary Tree | 47.70% | Medium |
| 1338 | Reduce Array Size to The Half | 69.20% | Medium |
| 1337 | The K Weakest Rows in a Matrix | 71.40% | Easy |
| 1336 | Number of Transactions per Visit * | 48.10% | Hard |
| 1335 | Minimum Difficulty of a Job Schedule | 58.30% | Hard |
| 1334 | Find the City With the Smallest Number of Neighbors at a Threshold Distance | 57.70% | Medium |
| 1333 | "Filter Restaurants by Vegan-Friendly | Price and Distance" | 60.50% |
| 1332 | Remove Palindromic Subsequences | 76.20% | Easy |
| 1331 | Rank Transform of an Array | 59.80% | Easy |
| 1330 | Reverse Subarray To Maximize Array Value | 41.30% | Hard |
| 1329 | Sort the Matrix Diagonally | 83.00% | Medium |
| 1328 | Break a Palindrome | 52.10% | Medium |
| 1327 | List the Products Ordered in a Period * | 71.90% | Easy |
| 1326 | Minimum Number of Taps to Open to Water a Garden | 51.60% | Hard |
| 1325 | Delete Leaves With a Given Value | 74.40% | Medium |
| 1324 | Print Words Vertically | 62.40% | Medium |
| 1323 | Maximum 69 Number | 82.00% | Easy |
| 1322 | Ads Performance * $ | 60.10% | Easy |
| 1321 | Restaurant Growth * | 53.40% | Medium |
| 1320 | Minimum Distance to Type a Word Using Two Fingers | 59.80% | Hard |
| 1319 | Number of Operations to Make Network Connected | 58.50% | Medium |
| 1318 | Minimum Flips to Make a OR b Equal to c | 66.00% | Medium |
| 1317 | Convert Integer to the Sum of Two No-Zero Integers | 56.00% | Easy |
| 1316 | Distinct Echo Substrings | 49.70% | Hard |
| 1315 | Sum of Nodes with Even-Valued Grandparent | 85.60% | Medium |
| 1314 | Matrix Block Sum | 75.40% | Medium |
| 1313 | Decompress Run-Length Encoded List | 85.90% | Easy |
| 1312 | Minimum Insertion Steps to Make a String Palindrome | 65.70% | Hard |
| 1311 | Get Watched Videos by Your Friends | 45.90% | Medium |
| 1310 | XOR Queries of a Subarray | 72.20% | Medium |
| 1309 | Decrypt String from Alphabet to Integer Mapping | 79.50% | Easy |
| 1308 | Running Total for Different Genders * $ | 88.20% | Medium |
| 1307 | Verbal Arithmetic Puzzle | 34.80% | Hard |
| 1306 | Jump Game III | 63.10% | Medium |
| 1305 | All Elements in Two Binary Search Trees | 79.80% | Medium |
| 1304 | Find N Unique Integers Sum up to Zero | 77.10% | Easy |
| 1303 | Find the Team Size * $ | 90.80% | Easy |
| 1302 | Deepest Leaves Sum | 86.90% | Medium |
| 1301 | Number of Paths with Max Score | 38.70% | Hard |
| 1300 | Sum of Mutated Array Closest to Target | 43.10% | Medium |
| 1299 | Replace Elements with Greatest Element on Right Side | 74.70% | Easy |
| 1298 | Maximum Candies You Can Get from Boxes | 60.90% | Hard |
| 1297 | Maximum Number of Occurrences of a Substring | 52.00% | Medium |
| 1296 | Divide Array in Sets of K Consecutive Numbers | 56.60% | Medium |
| 1295 | Find Numbers with Even Number of Digits | 77.00% | Easy |
| 1294 | Weather Type in Each Country * $ | 68.00% | Easy |
| 1293 | Shortest Path in a Grid with Obstacles Elimination | 45.60% | Hard |
| 1292 | Maximum Side Length of a Square with Sum Less than or Equal to Threshold | 52.10% | Medium |
| 1291 | Sequential Digits | 60.90% | Medium |
| 1290 | Convert Binary Number in a Linked List to Integer | 82.70% | Easy |
| 1289 | Minimum Falling Path Sum II | 61.20% | Hard |
| 1288 | Remove Covered Intervals | 57.40% | Medium |
| 1287 | Element Appearing More Than 25% In Sorted Array | 59.50% | Easy |
| 1286 | Iterator for Combination | 73.20% | Medium |
| 1285 | Find the Start and End Number of Continuous Ranges * $ | 88.30% | Medium |
| 1284 | Minimum Number of Flips to Convert Binary Matrix to Zero Matrix | 72.00% | Hard |
| 1283 | Find the Smallest Divisor Given a Threshold | 53.70% | Medium |
| 1282 | Group the People Given the Group Size They Belong To | 85.20% | Medium |
| 1281 | Subtract the Product and Sum of Digits of an Integer | 86.30% | Easy |
| 1280 | Students and Examinations * $ | 74.60% | Easy |
| 1279 | Traffic Light Controlled Intersection ~ $ | 75.30% | Easy |
| 1278 | Palindrome Partitioning III | 60.90% | Hard |
| 1277 | Count Square Submatrices with All Ones | 74.20% | Medium |
| 1276 | Number of Burgers with No Waste of Ingredients | 50.60% | Medium |
| 1275 | Find Winner on a Tic Tac Toe Game | 54.90% | Easy |
| 1274 | Number of Ships in a Rectangle $ | 68.60% | Hard |
| 1273 | Delete Tree Nodes $ | 61.20% | Medium |
| 1272 | Remove Interval $ | 61.10% | Medium |
| 1271 | Hexspeak $ | 56.30% | Easy |
| 1270 | All People Report to the Given Manager * $ | 88.10% | Medium |
| 1269 | Number of Ways to Stay in the Same Place After Some Steps | 43.40% | Hard |
| 1268 | Search Suggestions System | 65.40% | Medium |
| 1267 | Count Servers that Communicate | 58.30% | Medium |
| 1266 | Minimum Time Visiting All Points | 79.20% | Easy |
| 1265 | Print Immutable Linked List in Reverse $ | 94.30% | Medium |
| 1264 | Page Recommendations * $ | 67.70% | Medium |
| 1263 | Minimum Moves to Move a Box to Their Target Location | 48.30% | Hard |
| 1262 | Greatest Sum Divisible by Three | 50.80% | Medium |
| 1261 | Find Elements in a Contaminated Binary Tree | 75.70% | Medium |
| 1260 | Shift 2D Grid | 62.10% | Easy |
| 1259 | Handshakes That Don't Cross $ | 54.40% | Hard |
| 1258 | Synonymous Sentences $ | 57.40% | Medium |
| 1257 | Smallest Common Region $ | 62.10% | Medium |
| 1256 | Encode Number $ | 69.00% | Medium |
| 1255 | Maximum Score Words Formed by Letters | 71.30% | Hard |
| 1254 | Number of Closed Islands | 62.70% | Medium |
| 1253 | Reconstruct a 2-Row Binary Matrix | 42.70% | Medium |
| 1252 | Cells with Odd Values in a Matrix | 78.50% | Easy |
| 1251 | Average Selling Price * $ | 83.20% | Easy |
| 1250 | Check If It Is a Good Array | 57.50% | Hard |
| 1249 | Minimum Remove to Make Valid Parentheses | 65.00% | Medium |
| 1248 | Count Number of Nice Subarrays | 57.60% | Medium |
| 1247 | Minimum Swaps to Make Strings Equal | 63.60% | Medium |
| 1246 | Palindrome Removal $ | 45.80% | Hard |
| 1245 | Tree Diameter $ | 62.00% | Medium |
| 1244 | Design A Leaderboard $ | 67.30% | Medium |
| 1243 | Array Transformation $ | 50.10% | Easy |
| 1242 | Web Crawler Multithreaded ~ $ | 48.20% | Medium |
| 1241 | Number of Comments per Post * $ | 68.00% | Easy |
| 1240 | Tiling a Rectangle with the Fewest Squares | 52.40% | Hard |
| 1239 | Maximum Length of a Concatenated String with Unique Characters | 50.70% | Medium |
| 1238 | Circular Permutation in Binary Representation | 67.90% | Medium |
| 1237 | Find Positive Integer Solution for a Given Equation | 69.70% | Medium |
| 1236 | Web Crawler $ | 65.40% | Medium |
| 1235 | Maximum Profit in Job Scheduling | 50.50% | Hard |
| 1234 | Replace the Substring for Balanced String | 35.50% | Medium |
| 1233 | Remove Sub-Folders from the Filesystem | 64.50% | Medium |
| 1232 | Check If It Is a Straight Line | 42.30% | Easy |
| 1231 | Divide Chocolate $ | 55.50% | Hard |
| 1230 | Toss Strange Coins $ | 50.80% | Medium |
| 1229 | Meeting Scheduler $ | 54.70% | Medium |
| 1228 | Missing Number In Arithmetic Progression $ | 51.20% | Medium |
| 1227 | Airplane Seat Assignment Probability | 63.00% | Medium |
| 1226 | The Dining Philosophers ~ | 60.20% | Medium |
| 1225 | Report Contiguous Dates * | 63.80% | Hard |
| 1224 | Maximum Equal Frequency | 36.20% | Hard |
| 1223 | Dice Roll Simulation | 47.40% | Hard |
| 1222 | Queens That Can Attack the King | 70.20% | Medium |
| 1221 | Split a String in Balanced Strings | 84.60% | Easy |
| 1220 | Count Vowels Permutation | 56.60% | Hard |
| 1219 | Path with Maximum Gold | 66.10% | Medium |
| 1218 | Longest Arithmetic Subsequence of Given Difference | 48.10% | Medium |
| 1217 | Minimum Cost to Move Chips to The Same Position | 70.70% | Easy |
| 1216 | Valid Palindrome III $ | 50.80% | Hard |
| 1215 | Stepping Numbers $ | 44.60% | Medium |
| 1214 | Two Sum BSTs $ | 67.30% | Medium |
| 1213 | Intersection of Three Sorted Arrays $ | 79.80% | Easy |
| 1212 | Team Scores in Football Tournament * | 57.00% | Medium |
| 1211 | Queries Quality and Percentage * | 70.40% | Easy |
| 1210 | Minimum Moves to Reach Target with Rotations | 47.50% | Hard |
| 1209 | Remove All Adjacent Duplicates in String II | 56.40% | Medium |
| 1208 | Get Equal Substrings Within Budget | 45.30% | Medium |
| 1207 | Unique Number of Occurrences | 72.40% | Easy |
| 1206 | Design Skiplist | 59.60% | Hard |
| 1205 | Monthly Transactions II * | 45.30% | Medium |
| 1204 | Last Person to Fit in the Bus * | 73.00% | Medium |
| 1203 | Sort Items by Groups Respecting Dependencies | 48.80% | Hard |
| 1202 | Smallest String With Swaps | 50.50% | Medium |
| 1201 | Ugly Number III | 27.20% | Medium |
| 1200 | Minimum Absolute Difference | 67.30% | Easy |
| 1199 | Minimum Time to Build Blocks $ | 39.40% | Hard |
| 1198 | Find Smallest Common Element in All Rows $ | 76.30% | Medium |
| 1197 | Minimum Knight Moves $ | 38.60% | Medium |
| 1196 | How Many Apples Can You Put into the Basket $ | 68.30% | Easy |
| 1195 | Fizz Buzz Multithreaded ~ | 71.40% | Medium |
| 1194 | Tournament Winners * | 52.70% | Hard |
| 1193 | Monthly Transactions I * | 68.70% | Medium |
| 1192 | Critical Connections in a Network | 51.80% | Hard |
| 1191 | K-Concatenation Maximum Sum | 24.60% | Medium |
| 1190 | Reverse Substrings Between Each Pair of Parentheses | 65.00% | Medium |
| 1189 | Maximum Number of Balloons | 62.00% | Easy |
| 1188 | Design Bounded Blocking Queue ~ | 73.20% | Medium |
| 1187 | Make Array Strictly Increasing | 43.80% | Hard |
| 1186 | Maximum Subarray Sum with One Deletion | 39.80% | Medium |
| 1185 | Day of the Week | 59.90% | Easy |
| 1184 | Distance Between Bus Stops | 53.90% | Easy |
| 1183 | Maximum Number of Ones $ | 58.70% | Hard |
| 1182 | Shortest Distance to Target Color $ | 54.30% | Medium |
| 1181 | Before and After Puzzle $ | 44.70% | Medium |
| 1180 | Count Substrings with Only One Distinct Letter $ | 78.30% | Easy |
| 1179 | Reformat Department Table * | 82.10% | Easy |
| 1178 | Number of Valid Words for Each Puzzle | 40.80% | Hard |
| 1177 | Can Make Palindrome from Substring | 36.50% | Medium |
| 1176 | Diet Plan Performance $ | 53.50% | Easy |
| 1175 | Prime Arrangements | 51.90% | Medium |
| 1174 | Immediate Food Delivery II * | 63.10% | Medium |
| 1173 | Immediate Food Delivery I * | 83.10% | Easy |
| 1172 | Dinner Plate Stacks | 36.40% | Hard |
| 1171 | Remove Zero Sum Consecutive Nodes from Linked List | 41.90% | Medium |
| 1170 | Compare Strings by Frequency of the Smallest Character | 60.60% | Medium |
| 1169 | Invalid Transactions | 30.40% | Medium |
| 1168 | Optimize Water Distribution in a Village $ | 62.30% | Hard |
| 1167 | Minimum Cost to Connect Sticks $ | 65.70% | Medium |
| 1166 | Design File System $ | 59.00% | Medium |
| 1165 | Single-Row Keyboard $ | 85.50% | Easy |
| 1164 | Product Price at a Given Date * | 69.00% | Medium |
| 1163 | Last Substring in Lexicographical Order | 36.00% | Hard |
| 1162 | As Far from Land as Possible | 46.60% | Medium |
| 1161 | Maximum Level Sum of a Binary Tree | 67.50% | Medium |
| 1160 | Find Words That Can Be Formed by Characters | 67.80% | Easy |
| 1159 | Market Analysis II * | 57.00% | Hard |
| 1158 | Market Analysis I * | 65.00% | Medium |
| 1157 | Online Majority Element In Subarray | 41.60% | Hard |
| 1156 | Swap For Longest Repeated Character Substring | 47.20% | Medium |
| 1155 | Number of Dice Rolls With Target Sum | 47.70% | Medium |
| 1154 | Day of the Year | 50.10% | Easy |
| 1153 | String Transforms Into Another String $ | 35.60% | Hard |
| 1152 | Analyze User Website Visit Pattern $ | 43.20% | Medium |
| 1151 | Minimum Swaps to Group All 1's Together $ | 51.90% | Medium |
| 1150 | Check If a Number Is Majority Element in a Sorted Array $ | 57.10% | Easy |
| 1149 | Article Views II * $ | 48.20% | Medium |
| 1148 | Article Views I * $ | 77.10% | Easy |
| 1147 | Longest Chunked Palindrome Decomposition | 59.80% | Hard |
| 1146 | Snapshot Array | 37.00% | Medium |
| 1145 | Binary Tree Coloring Game | 51.10% | Medium |
| 1144 | Decrease Elements To Make Array Zigzag | 46.50% | Medium |
| 1143 | Longest Common Subsequence | 58.80% | Medium |
| 1142 | User Activity for the Past 30 Days II * $ | 35.50% | Easy |
| 1141 | User Activity for the Past 30 Days I * $ | 54.60% | Easy |
| 1140 | Stone Game II | 64.60% | Medium |
| 1139 | Largest 1-Bordered Square | 48.70% | Medium |
| 1138 | Alphabet Board Path | 51.60% | Medium |
| 1137 | N-th Tribonacci Number | 55.70% | Easy |
| 1136 | Parallel Courses $ | 60.70% | Medium |
| 1135 | Connecting Cities With Minimum Cost $ | 60.00% | Easy |
| 1134 | Armstrong Number $ | 78.50% | Easy |
| 1133 | Largest Unique Number $ | 67.20% | Easy |
| 1132 | Reported Posts II * $ | 34.40% | Medium |
| 1131 | Maximum of Absolute Value Expression | 51.30% | Medium |
| 1130 | Minimum Cost Tree From Leaf Values | 67.40% | Medium |
| 1129 | Shortest Path with Alternating Colors | 40.70% | Medium |
| 1128 | Number of Equivalent Domino Pairs | 45.90% | Easy |
| 1127 | User Purchase Platform * $ | 50.80% | Hard |
| 1126 | Active Businesses * $ | 68.40% | Medium |
| 1125 | Smallest Sufficient Team | 47.20% | Hard |
| 1124 | Longest Well-Performing Interval | 33.50% | Medium |
| 1123 | Lowest Common Ancestor of Deepest Leaves | 68.50% | Medium |
| 1122 | Relative Sort Array | 67.90% | Easy |
| 1121 | Divide Array Into Increasing Sequences $ | 59.00% | Hard |
| 1120 | Maximum Average Subtree $ | 64.50% | Medium |
| 1119 | Remove Vowels from a String $ | 90.50% | Easy |
| 1118 | Number of Days in a Month $ | 57.30% | Easy |
| 1117 | Building H2O ~ | 53.10% | Medium |
| 1116 | Print Zero Even Odd ~ | 58.20% | Medium |
| 1115 | Print FooBar Alternately ~ | 59.00% | Medium |
| 1114 | Print in Order ~ | 67.60% | Easy |
| 1113 | Reported Posts * $ | 66.40% | Medium |
| 1112 | Highest Grade For Each Student * $ | 72.80% | Medium |
| 1111 | Maximum Nesting Depth of Two Valid Parentheses Strings | 72.70% | Medium |
| 1110 | Delete Nodes And Return Forest | 68.00% | Medium |
| 1109 | Corporate Flight Bookings | 54.30% | Medium |
| 1108 | Defanging an IP Address | 88.40% | Easy |
| 1107 | New Users Daily Count * $ | 46.10% | Medium |
| 1106 | Parsing A Boolean Expression | 59.50% | Hard |
| 1105 | Filling Bookcase Shelves | 57.50% | Medium |
| 1104 | Path In Zigzag Labelled Binary Tree | 73.50% | Medium |
| 1103 | Distribute Candies to People | 63.40% | Easy |
| 1102 | Path With Maximum Minimum Value $ | 51.00% | Medium |
| 1101 | The Earliest Moment When Everyone Become Friends $ | 67.80% | Medium |
| 1100 | Find K-Length Substrings With No Repeated Characters $ | 73.10% | Medium |
| 1099 | Two Sum Less Than K $ | 60.80% | Easy |
| 1098 | Unpopular Books * $ | 45.50% | Medium |
| 1097 | Game Play Analysis V * $ | 57.00% | Hard |
| 1096 | Brace Expansion II | 62.90% | Hard |
| 1095 | Find in Mountain Array | 36.10% | Hard |
| 1094 | Car Pooling | 59.70% | Medium |
| 1093 | Statistics from a Large Sample | 48.50% | Medium |
| 1092 | Shortest Common Supersequence | 53.40% | Hard |
| 1091 | Shortest Path in Binary Matrix | 40.30% | Medium |
| 1090 | Largest Values From Labels | 60.10% | Medium |
| 1089 | Duplicate Zeros | 51.60% | Easy |
| 1088 | Confusing Number II | 45.60% | Hard |
| 1087 | Brace Expansion $ | 63.20% | Medium |
| 1086 | High Five $ | 77.50% | Easy |
| 1085 | Sum of Digits in the Minimum Number $ | 75.10% | Easy |
| 1084 | Sales Analysis III * $ | 54.80% | Easy |
| 1083 | Sales Analysis II * $ | 50.80% | Easy |
| 1082 | Sales Analysis I * $ | 73.90% | Easy |
| 1081 | Smallest Subsequence of Distinct Characters | 53.60% | Medium |
| 1080 | Insufficient Nodes in Root to Leaf Paths | 50.10% | Medium |
| 1079 | Letter Tile Possibilities | 75.90% | Medium |
| 1078 | Occurrences After Bigram | 65.00% | Easy |
| 1077 | Project Employees III * $ | 78.00% | Medium |
| 1076 | Project Employees II * $ | 52.80% | Easy |
| 1075 | Project Employees I * $ | 66.20% | Easy |
| 1074 | Number of Submatrices That Sum to Target | 62.00% | Hard |
| 1073 | Adding Two Negabinary Numbers | 34.80% | Medium |
| 1072 | Flip Columns For Maximum Number of Equal Rows | 61.60% | Medium |
| 1071 | Greatest Common Divisor of Strings | 51.50% | Easy |
| 1070 | Product Sales Analysis III * $ | 49.90% | Medium |
| 1069 | Product Sales Analysis II * $ | 83.30% | Easy |
| 1068 | Product Sales Analysis I * $ | 82.10% | Easy |
| 1067 | Digit Count in Range $ | 41.60% | Hard |
| 1066 | Campus Bikes II $ | 54.20% | Medium |
| 1065 | Index Pairs of a String $ | 61.00% | Easy |
| 1064 | Fixed Point $ | 64.90% | Easy |
| 1063 | Number of Valid Subarrays $ | 72.10% | Hard |
| 1062 | Longest Repeating Substring $ | 58.40% | Medium |
| 1061 | Lexicographically Smallest Equivalent String $ | 66.90% | Medium |
| 1060 | Missing Element in Sorted Array $ | 54.80% | Medium |
| 1059 | All Paths from Source Lead to Destination $ | 43.00% | Medium |
| 1058 | Minimize Rounding Error to Meet Target $ | 43.70% | Medium |
| 1057 | Campus Bikes $ | 57.80% | Medium |
| 1056 | Confusing Number $ | 47.00% | Easy |
| 1055 | Shortest Way to Form String $ | 57.20% | Medium |
| 1054 | Distant Barcodes | 44.20% | Medium |
| 1053 | Previous Permutation With One Swap | 51.20% | Medium |
| 1052 | Grumpy Bookstore Owner | 55.90% | Medium |
| 1051 | Height Checker | 72.10% | Easy |
| 1050 | Actors and Directors Who Cooperated At Least Three Times * $ | 72.40% | Easy |
| 1049 | Last Stone Weight II | 45.40% | Medium |
| 1048 | Longest String Chain | 55.50% | Medium |
| 1047 | Remove All Adjacent Duplicates In String | 70.90% | Easy |
| 1046 | Last Stone Weight | 62.40% | Easy |
| 1045 | Customers Who Bought All Products * $ | 68.40% | Medium |
| 1044 | Longest Duplicate Substring | 31.40% | Hard |
| 1043 | Partition Array for Maximum Sum | 67.10% | Medium |
| 1042 | Flower Planting With No Adjacent | 48.80% | Medium |
| 1041 | Robot Bounded In Circle | 55.00% | Medium |
| 1040 | Moving Stones Until Consecutive II | 54.10% | Medium |
| 1039 | Minimum Score Triangulation of Polygon | 50.10% | Medium |
| 1038 | Binary Search Tree to Greater Sum Tree | 82.30% | Medium |
| 1037 | Valid Boomerang | 37.80% | Easy |
| 1036 | Escape a Large Maze | 34.50% | Hard |
| 1035 | Uncrossed Lines | 56.10% | Medium |
| 1034 | Coloring A Border | 45.70% | Medium |
| 1033 | Moving Stones Until Consecutive | 43.20% | Easy |
| 1032 | Stream of Characters | 48.60% | Hard |
| 1031 | Maximum Sum of Two Non-Overlapping Subarrays | 58.90% | Medium |
| 1030 | Matrix Cells in Distance Order | 66.90% | Easy |
| 1029 | Two City Scheduling | 57.90% | Medium |
| 1028 | Recover a Tree From Preorder Traversal | 70.90% | Hard |
| 1027 | Longest Arithmetic Subsequence | 49.80% | Medium |
| 1026 | Maximum Difference Between Node and Ancestor | 69.40% | Medium |
| 1025 | Divisor Game | 66.20% | Easy |
| 1024 | Video Stitching | 49.00% | Medium |
| 1023 | Camelcase Matching | 57.40% | Medium |
| 1022 | Sum of Root To Leaf Binary Numbers | 71.50% | Easy |
| 1021 | Remove Outermost Parentheses | 79.00% | Easy |
| 1020 | Number of Enclaves | 58.90% | Medium |
| 1019 | Next Greater Node In Linked List | 58.20% | Medium |
| 1018 | Binary Prefix Divisible By 5 | 47.80% | Easy |
| 1017 | Convert to Base -2 | 59.60% | Medium |
| 1016 | Binary String With Substrings Representing 1 To N | 58.90% | Medium |
| 1015 | Smallest Integer Divisible by K | 41.80% | Medium |
| 1014 | Best Sightseeing Pair | 52.90% | Medium |
| 1013 | Partition Array Into Three Parts With Equal Sum | 49.10% | Easy |
| 1012 | Numbers With Repeated Digits | 37.80% | Hard |
| 1011 | Capacity To Ship Packages Within D Days | 59.70% | Medium |
| 1010 | Pairs of Songs With Total Durations Divisible by 60 | 50.10% | Medium |
| 1009 | Complement of Base 10 Integer | 61.50% | Easy |
| 1008 | Construct Binary Search Tree from Preorder Traversal | 78.80% | Medium |
| 1007 | Minimum Domino Rotations For Equal Row | 50.90% | Medium |
| 1006 | Clumsy Factorial | 53.70% | Medium |
| 1005 | Maximize Sum Of Array After K Negations | 52.40% | Easy |
| 1004 | Max Consecutive Ones III | 60.50% | Medium |
| 1003 | Check If Word Is Valid After Substitutions | 56.10% | Medium |
| 1002 | Find Common Characters | 68.10% | Easy |
| 1001 | Grid Illumination | 36.60% | Hard |
| 1000 | Minimum Cost to Merge Stones | 40.40% | Hard |
| 999 | Available Captures for Rook | 66.80% | Easy |
| 998 | Maximum Binary Tree II | 63.70% | Medium |
| 997 | Find the Town Judge | 49.80% | Easy |
| 996 | Number of Squareful Arrays | 48.00% | Hard |
| 995 | Minimum Number of K Consecutive Bit Flips | 49.60% | Hard |
| 994 | Rotting Oranges | 49.60% | Medium |
| 993 | Cousins in Binary Tree | 52.20% | Easy |
| 992 | Subarrays with K Different Integers | 50.40% | Hard |
| 991 | Broken Calculator | 46.40% | Medium |
| 990 | Satisfiability of Equality Equations | 46.50% | Medium |
| 989 | Add to Array-Form of Integer | 44.70% | Easy |
| 988 | Smallest String Starting From Leaf | 46.60% | Medium |
| 987 | Vertical Order Traversal of a Binary Tree | 37.60% | Medium |
| 986 | Interval List Intersections | 68.10% | Medium |
| 985 | Sum of Even Numbers After Queries | 60.70% | Easy |
| 984 | String Without AAA or BBB | 38.50% | Medium |
| 983 | Minimum Cost For Tickets | 62.60% | Medium |
| 982 | Triples with Bitwise AND Equal To Zero | 56.10% | Hard |
| 981 | Time Based Key-Value Store | 54.00% | Medium |
| 980 | Unique Paths III | 77.10% | Hard |
| 979 | Distribute Coins in Binary Tree | 69.30% | Medium |
| 978 | Longest Turbulent Subarray | 46.60% | Medium |
| 977 | Squares of a Sorted Array | 72.40% | Easy |
| 976 | Largest Perimeter Triangle | 58.50% | Easy |
| 975 | Odd Even Jump | 41.70% | Hard |
| 974 | Subarray Sums Divisible by K | 50.30% | Medium |
| 973 | K Closest Points to Origin | 64.40% | Medium |
| 972 | Equal Rational Numbers | 41.80% | Hard |
| 971 | Flip Binary Tree To Match Preorder Traversal | 46.10% | Medium |
| 970 | Powerful Integers | 39.90% | Easy |
| 969 | Pancake Sorting | 68.40% | Medium |
| 968 | Binary Tree Cameras | 38.40% | Hard |
| 967 | Numbers With Same Consecutive Differences | 44.30% | Medium |
| 966 | Vowel Spellchecker | 47.70% | Medium |
| 965 | Univalued Binary Tree | 67.60% | Easy |
| 964 | Least Operators to Express Number | 44.70% | Hard |
| 963 | Minimum Area Rectangle II | 51.60% | Medium |
| 962 | Maximum Width Ramp | 46.00% | Medium |
| 961 | N-Repeated Element in Size 2N Array | 74.20% | Easy |
| 960 | Delete Columns to Make Sorted III | 54.00% | Hard |
| 959 | Regions Cut By Slashes | 66.70% | Medium |
| 958 | Check Completeness of a Binary Tree | 52.30% | Medium |
| 957 | Prison Cells After N Days | 40.30% | Medium |
| 956 | Tallest Billboard | 39.70% | Hard |
| 955 | Delete Columns to Make Sorted II | 33.40% | Medium |
| 954 | Array of Doubled Pairs | 35.30% | Medium |
| 953 | Verifying an Alien Dictionary | 52.90% | Easy |
| 952 | Largest Component Size by Common Factor | 36.00% | Hard |
| 951 | Flip Equivalent Binary Trees | 65.50% | Medium |
| 950 | Reveal Cards In Increasing Order | 75.00% | Medium |
| 949 | Largest Time for Given Digits | 36.30% | Medium |
| 948 | Bag of Tokens | 46.20% | Medium |
| 947 | Most Stones Removed with Same Row or Column | 55.30% | Medium |
| 946 | Validate Stack Sequences | 63.10% | Medium |
| 945 | Minimum Increment to Make Array Unique | 46.50% | Medium |
| 944 | Delete Columns to Make Sorted | 70.90% | Easy |
| 943 | Find the Shortest Superstring | 43.20% | Hard |
| 942 | DI String Match | 73.20% | Easy |
| 941 | Valid Mountain Array | 32.20% | Easy |
| 940 | Distinct Subsequences II | 41.50% | Hard |
| 939 | Minimum Area Rectangle | 52.00% | Medium |
| 938 | Range Sum of BST | 79.90% | Easy |
| 937 | Reorder Data in Log Files | 53.70% | Easy |
| 936 | Stamping The Sequence | 38.10% | Hard |
| 935 | Knight Dialer | 43.80% | Medium |
| 934 | Shortest Bridge | 46.50% | Medium |
| 933 | Number of Recent Calls | 70.90% | Easy |
| 932 | Beautiful Array | 57.10% | Medium |
| 931 | Minimum Falling Path Sum | 61.30% | Medium |
| 930 | Binary Subarrays With Sum | 41.40% | Medium |
| 929 | Unique Email Addresses | 67.60% | Easy |
| 928 | Minimize Malware Spread II | 40.10% | Hard |
| 927 | Three Equal Parts | 32.80% | Hard |
| 926 | Flip String to Monotone Increasing | 51.60% | Medium |
| 925 | Long Pressed Name | 45.00% | Easy |
| 924 | Minimize Malware Spread | 41.70% | Hard |
| 923 | 3Sum With Multiplicity | 35.30% | Medium |
| 922 | Sort Array By Parity II | 68.30% | Easy |
| 921 | Minimum Add to Make Parentheses Valid | 72.30% | Medium |
| 920 | Number of Music Playlists | 45.70% | Hard |
| 919 | Complete Binary Tree Inserter | 55.70% | Medium |
| 918 | Maximum Sum Circular Subarray | 33.20% | Medium |
| 917 | Reverse Only Letters | 56.30% | Easy |
| 916 | Word Subsets | 45.90% | Medium |
| 915 | Partition Array into Disjoint Intervals | 43.90% | Medium |
| 914 | X of a Kind in a Deck of Cards | 34.00% | Easy |
| 913 | Cat and Mouse | 29.90% | Hard |
| 912 | Sort an Array | 62.90% | Medium |
| 911 | Online Election | 48.30% | Medium |
| 910 | Smallest Range II | 24.90% | Medium |
| 909 | Snakes and Ladders | 36.10% | Easy |
| 908 | Smallest Range I | 65.00% | Easy |
| 907 | Sum of Subarray Minimums | 29.40% | Medium |
| 906 | Super Palindromes | 30.80% | Hard |
| 905 | Sort Array By Parity | 72.60% | Easy |
| 904 | Fruit Into Baskets | 41.70% | Medium |
| 903 | Valid Permutations for DI Sequence | 45.10% | Hard |
| 902 | Numbers At Most N Given Digit Set | 28.80% | Hard |
| 901 | Online Stock Span | 49.90% | Medium |
| 900 | RLE Iterator | 50.50% | Medium |
| 899 | Orderly Queue | 47.70% | Hard |
| 898 | Bitwise ORs of Subarrays | 34.70% | Medium |
| 897 | Increasing Order Search Tree | 65.20% | Easy |
| 896 | Monotonic Array | 55.40% | Easy |
| 895 | Maximum Frequency Stack | 56.70% | Hard |
| 894 | All Possible Full Binary Trees | 71.30% | Medium |
| 893 | Groups of Special-Equivalent Strings | 63.00% | Easy |
| 892 | Surface Area of 3D Shapes | 56.10% | Easy |
| 891 | Sum of Subsequence Widths | 29.20% | Hard |
| 890 | Find and Replace Pattern | 71.30% | Medium |
| 889 | Construct Binary Tree from Preorder and Postorder Traversal | 60.70% | Medium |
| 888 | Fair Candy Swap | 56.90% | Easy |
| 887 | Super Egg Drop | 24.90% | Hard |
| 886 | Possible Bipartition | 40.90% | Medium |
| 885 | Spiral Matrix III | 64.80% | Medium |
| 884 | Uncommon Words from Two Sentences | 60.90% | Easy |
| 883 | Projection Area of 3D Shapes | 65.90% | Easy |
| 882 | Reachable Nodes In Subdivided Graph | 38.20% | Hard |
| 881 | Boats to Save People | 44.10% | Medium |
| 880 | Decoded String at Index | 23.00% | Medium |
| 879 | Profitable Schemes | 36.20% | Hard |
| 878 | Nth Magical Number | 25.40% | Hard |
| 877 | Stone Game | 61.10% | Medium |
| 876 | Middle of the Linked List | 63.80% | Easy |
| 875 | Koko Eating Bananas | 45.90% | Medium |
| 874 | Walking Robot Simulation | 31.70% | Easy |
| 873 | Length of Longest Fibonacci Subsequence | 46.00% | Medium |
| 872 | Leaf-Similar Trees | 63.10% | Easy |
| 871 | Minimum Number of Refueling Stops | 28.70% | Hard |
| 870 | Advantage Shuffle | 42.20% | Medium |
| 869 | Reordered Power of 2 | 50.60% | Medium |
| 868 | Binary Gap | 59.30% | Easy |
| 867 | Transpose Matrix | 63.90% | Easy |
| 866 | Prime Palindrome | 20.00% | Medium |
| 865 | Smallest Subtree with all the Deepest Nodes | 55.40% | Medium |
| 864 | Shortest Path to Get All Keys | 35.70% | Hard |
| 863 | All Nodes Distance K in Binary Tree | 46.80% | Medium |
| 862 | Shortest Subarray with Sum at Least K | 22.00% | Hard |
| 861 | Score After Flipping Matrix | 69.30% | Medium |
| 860 | Lemonade Change | 50.20% | Easy |
| 859 | Buddy Strings | 27.60% | Easy |
| 858 | Mirror Reflection | 52.00% | Medium |
| 857 | Minimum Cost to Hire K Workers | 47.30% | Hard |
| 856 | Score of Parentheses | 55.90% | Medium |
| 855 | Exam Room | 38.10% | Medium |
| 854 | K-Similar Strings | 33.20% | Hard |
| 853 | Car Fleet | 39.30% | Medium |
| 852 | Peak Index in a Mountain Array | 68.50% | Easy |
| 851 | Loud and Rich | 47.40% | Medium |
| 850 | Rectangle Area II | 44.00% | Hard |
| 849 | Maximize Distance to Closest Person | 40.40% | Easy |
| 848 | Shifting Letters | 39.90% | Medium |
| 847 | Shortest Path Visiting All Nodes | 45.90% | Hard |
| 846 | Hand of Straights | 48.60% | Medium |
| 845 | Longest Mountain in Array | 34.00% | Medium |
| 844 | Backspace String Compare | 45.50% | Easy |
| 843 | Guess the Word | 42.60% | Hard |
| 842 | Split Array into Fibonacci Sequence | 34.60% | Medium |
| 841 | Keys and Rooms | 59.70% | Medium |
| 840 | Magic Squares In Grid | 35.10% | Easy |
| 839 | Similar String Groups | 33.50% | Hard |
| 838 | Push Dominoes | 42.80% | Medium |
| 837 | New 21 Game | 29.50% | Medium |
| 836 | Rectangle Overlap | 45.50% | Easy |
| 835 | Image Overlap | 50.30% | Medium |
| 834 | Sum of Distances in Tree | 38.10% | Hard |
| 833 | Find And Replace in String | 44.50% | Medium |
| 832 | Flipping an Image | 71.30% | Easy |
| 831 | Masking Personal Information | 41.50% | Medium |
| 830 | Positions of Large Groups | 47.40% | Easy |
| 829 | Consecutive Numbers Sum | 32.10% | Hard |
| 828 | Unique Letter String | 38.10% | Hard |
| 827 | Making A Large Island | 42.10% | Hard |
| 826 | Most Profit Assigning Work | 34.70% | Medium |
| 825 | Friends Of Appropriate Ages | 35.00% | Medium |
| 824 | Goat Latin | 56.70% | Easy |
| 823 | Binary Trees With Factors | 31.50% | Medium |
| 822 | Card Flipping Game | 39.70% | Medium |
| 821 | Shortest Distance to a Character | 62.60% | Easy |
| 820 | Short Encoding of Words | 46.00% | Medium |
| 819 | Most Common Word | 41.50% | Easy |
| 818 | Race Car | 34.00% | Hard |
| 817 | Linked List Components | 51.90% | Medium |
| 816 | Ambiguous Coordinates | 42.40% | Medium |
| 815 | Bus Routes | 36.10% | Hard |
| 814 | Binary Tree Pruning | 68.30% | Medium |
| 813 | Largest Sum of Averages | 42.40% | Medium |
| 812 | Largest Triangle Area | 53.80% | Easy |
| 811 | Subdomain Visit Count | 61.50% | Easy |
| 810 | Chalkboard XOR Game | 41.90% | Hard |
| 809 | Expressive Words | 39.50% | Medium |
| 808 | Soup Servings | 33.60% | Medium |
| 807 | Max Increase to Keep City Skyline | 79.60% | Medium |
| 806 | Number of Lines To Write String | 62.10% | Easy |
| 805 | Split Array With Same Average | 21.00% | Hard |
| 804 | Unique Morse Code Words | 71.30% | Easy |
| 803 | Bricks Falling When Hit | 22.90% | Hard |
| 802 | Find Eventual Safe States | 39.20% | Medium |
| 801 | Minimum Swaps To Make Sequences Increasing | 31.00% | Medium |
| 800 | Similar RGB Color $ | 54.50% | Easy |
| 799 | Champagne Tower | 29.90% | Medium |
| 798 | Smallest Rotation with Highest Score | 34.30% | Hard |
| 797 | All Paths From Source to Target | 67.40% | Medium |
| 796 | Rotate String | 49.60% | Easy |
| 795 | Number of Subarrays with Bounded Maximum | 41.60% | Medium |
| 794 | Valid Tic-Tac-Toe State | 27.80% | Medium |
| 793 | Preimage Size of Factorial Zeroes Function | 40.80% | Hard |
| 792 | Number of Matching Subsequences | 37.30% | Medium |
| 791 | Custom Sort String | 59.40% | Medium |
| 790 | Domino and Tromino Tiling | 32.80% | Medium |
| 789 | Escape The Ghosts | 51.00% | Medium |
| 788 | Rotated Digits | 51.00% | Easy |
| 787 | Cheapest Flights Within K Stops | 29.90% | Medium |
| 786 | K-th Smallest Prime Fraction | 32.50% | Hard |
| 785 | Is Graph Bipartite | 38.50% | Medium |
| 784 | Letter Case Permutation | 53.00% | Easy |
| 783 | Minimum Distance Between BST Nodes | 47.80% | Easy |
| 782 | Transform to Chessboard | 37.50% | Hard |
| 781 | Rabbits in Forest | 49.80% | Medium |
| 780 | Reaching Points | 23.90% | Hard |
| 779 | K-th Symbol in Grammar | 37.30% | Medium |
| 778 | Swim in Rising Water | 44.60% | Hard |
| 777 | Swap Adjacent in LR String | 28.90% | Medium |
| 776 | Split BST $ | 49.90% | Medium |
| 775 | Global and Local Inversions | 33.60% | Medium |
| 774 | Minimize Max Distance to Gas Station $ | 32.80% | Hard |
| 773 | Sliding Puzzle | 46.50% | Hard |
| 772 | Basic Calculator III $ | 40.10% | Hard |
| 771 | Jewels and Stones | 81.90% | Easy |
| 770 | Basic Calculator IV | 42.10% | Hard |
| 769 | Max Chunks To Make Sorted | 48.00% | Medium |
| 768 | Max Chunks To Make Sorted II | 43.20% | Hard |
| 767 | Reorganize String | 36.50% | Medium |
| 766 | Toeplitz Matrix | 57.90% | Easy |
| 765 | Couples Holding Hands | 48.50% | Hard |
| 764 | Largest Plus Sign | 39.20% | Medium |
| 763 | Partition Labels | 64.10% | Medium |
| 762 | Prime Number of Set Bits in Binary Representation | 55.00% | Easy |
| 761 | Special Binary String | 41.00% | Hard |
| 760 | Find Anagram Mappings $ | 75.60% | Easy |
| 759 | Employee Free Time $ | 51.90% | Hard |
| 758 | Bold Words in String $ | 37.90% | Easy |
| 757 | Set Intersection Size At Least Two | 34.60% | Hard |
| 756 | Pyramid Transition Matrix | 45.50% | Medium |
| 755 | Pour Water $ | 34.00% | Medium |
| 754 | Reach a Number | 26.10% | Medium |
| 753 | Cracking the Safe | 39.70% | Hard |
| 752 | Open the Lock | 38.20% | Medium |
| 751 | IP to CIDR $ | 54.80% | Easy |
| 750 | Number Of Corner Rectangles $ | 51.00% | Medium |
| 749 | Contain Virus | 39.60% | Hard |
| 748 | Shortest Completing Word | 53.50% | Medium |
| 747 | Largest Number At Least Twice of Others | 42.60% | Easy |
| 746 | Min Cost Climbing Stairs | 43.60% | Easy |
| 745 | Prefix and Suffix Search | 24.50% | Hard |
| 744 | Find Smallest Letter Greater Than Target | 45.30% | Easy |
| 743 | Network Delay Time | 34.30% | Medium |
| 742 | Closest Leaf in a Binary Tree $ | 33.20% | Medium |
| 741 | Cherry Pickup | 22.50% | Hard |
| 740 | Delete and Earn | 42.60% | Medium |
| 739 | Daily Temperatures | 53.50% | Medium |
| 738 | Monotone Increasing Digits | 41.80% | Medium |
| 737 | Sentence Similarity II $ | 41.20% | Medium |
| 736 | Parse Lisp Expression | 42.00% | Hard |
| 735 | Asteroid Collision | 37.60% | Medium |
| 734 | Sentence Similarity $ | 38.60% | Easy |
| 733 | Flood Fill | 49.30% | Easy |
| 732 | My Calendar III | 51.30% | Hard |
| 731 | My Calendar II | 35.00% | Medium |
| 730 | Count Different Palindromic Subsequences | 32.40% | Hard |
| 729 | My Calendar I | 40.10% | Medium |
| 728 | Self Dividing Numbers | 68.50% | Easy |
| 727 | Minimum Window Subsequence | 30.10% | Hard |
| 726 | Number of Atoms | 45.00% | Hard |
| 725 | Split Linked List in Parts | 50.00% | Medium |
| 724 | Find Pivot Index | 41.00% | Easy |
| 723 | Candy Crush $ | 56.10% | Medium |
| 722 | Remove Comments | 26.30% | Medium |
| 721 | Accounts Merge | 29.60% | Medium |
| 720 | Longest Word in Dictionary | 40.60% | Easy |
| 719 | Find K-th Smallest Pair Distance | 26.10% | Hard |
| 718 | Maximum Length of Repeated Subarray | 39.90% | Medium |
| 717 | 1-bit and 2-bit Characters | 50.90% | Easy |
| 716 | Max Stack $ | 35.50% | Hard |
| 715 | Range Module | 31.00% | Hard |
| 714 | Best Time to Buy and Sell Stock with Transaction Fee | 41.60% | Medium |
| 713 | Subarray Product Less Than K | 32.90% | Medium |
| 712 | Minimum ASCII Delete Sum for Two Strings | 50.90% | Medium |
| 711 | Number of Distinct Islands II $ | 39.40% | Hard |
| 710 | Random Pick with Blacklist | 29.80% | Hard |
| 709 | To Lower Case | 74.50% | Easy |
| 708 | Insert into a Cyclic Sorted List $ | 25.50% | Medium |
| 707 | Design Linked List | 19.10% | Easy |
| 706 | Design HashMap | 49.10% | Easy |
| 705 | Design HashSet | 43.60% | Easy |
| 704 | Binary Search | 40.10% | Easy |
| 703 | Kth Largest Element in a Stream | 39.60% | Easy |
| 702 | Search in a Sorted Array of Unknown Size | 43.00% | Medium |
| 701 | Insert into a Binary Search Tree | 67.90% | Medium |
| 700 | Search in a Binary Search Tree | 62.70% | Easy |
| 699 | Falling Squares | 36.80% | Hard |
| 698 | Partition to K Equal Sum Subsets | 35.60% | Medium |
| 697 | Degree of an Array | 47.90% | Easy |
| 696 | Count Binary Substrings | 51.90% | Easy |
| 695 | Max Area of Island | 53.30% | Easy |
| 694 | Number of Distinct Islands $ | 43.90% | Medium |
| 693 | Binary Number with Alternating Bits | 54.20% | Easy |
| 692 | Top K Frequent Words | 41.70% | Medium |
| 691 | Stickers to Spell Word | 32.30% | Hard |
| 690 | Employee Importance | 53.60% | Easy |
| 689 | Maximum Sum of 3 Non-Overlapping Subarrays | 41.70% | Hard |
| 688 | Knight Probability in Chessboard | 38.90% | Medium |
| 687 | Longest Univalue Path | 32.90% | Easy |
| 686 | Repeated String Match | 31.70% | Easy |
| 685 | Redundant Connection II | 28.40% | Hard |
| 684 | Redundant Connection | 37.40% | Medium |
| 683 | K Empty Slots | 37.00% | Hard |
| 682 | Baseball Game | 58.60% | Easy |
| 681 | Next Closest Time $ | 43.00% | Medium |
| 680 | Valid Palindrome II | 31.10% | Easy |
| 679 | 24 Game | 38.30% | Hard |
| 678 | Valid Parenthesis String | 28.30% | Medium |
| 677 | Map Sum Pairs | 53.80% | Medium |
| 676 | Implement Magic Dictionary | 50.70% | Medium |
| 675 | Cut Off Trees for Golf Event | 27.20% | Hard |
| 674 | Longest Continuous Increasing Subsequence | 43.20% | Easy |
| 673 | Number of Longest Increasing Subsequence | 30.80% | Medium |
| 672 | Bulb Switcher II | 47.60% | Medium |
| 671 | Second Minimum Node In a Binary Tree | 42.30% | Easy |
| 670 | Maximum Swap | 38.40% | Medium |
| 669 | Trim a Binary Search Tree | 58.70% | Easy |
| 668 | Kth Smallest Number in Multiplication Table | 36.30% | Hard |
| 667 | Beautiful Arrangement II | 51.50% | Medium |
| 666 | Path Sum IV $ | 48.90% | Medium |
| 665 | Non-decreasing Array | 21.20% | Easy |
| 664 | Strange Printer | 31.10% | Hard |
| 663 | Equal Tree Partition $ | 36.70% | Medium |
| 662 | Maximum Width of Binary Tree | 37.00% | Medium |
| 661 | Image Smoother | 46.60% | Easy |
| 660 | Remove 9 $ | 46.10% | Hard |
| 659 | Split Array into Consecutive Subsequences | 39.40% | Medium |
| 658 | Find K Closest Elements | 36.30% | Medium |
| 657 | Judge Route Circle | 69.30% | Easy |
| 656 | Coin Path $ | 24.60% | Hard |
| 655 | Print Binary Tree | 50.80% | Medium |
| 654 | Maximum Binary Tree | 70.80% | Medium |
| 653 | Two Sum IV - Input is a BST | 50.60% | Easy |
| 652 | Find Duplicate Subtrees | 33.20% | Medium |
| 651 | 4 Keys Keyboard $ | 46.70% | Medium |
| 650 | 2 Keys Keyboard | 42.70% | Medium |
| 649 | Dota2 Senate | 35.60% | Medium |
| 648 | Replace Words | 48.40% | Medium |
| 647 | Palindromic Substrings | 55.70% | Medium |
| 646 | Maximum Length of Pair Chain | 47.40% | Medium |
| 645 | Set Mismatch | 40.40% | Easy |
| 644 | Maximum Average Subarray II $ | 20.30% | Hard |
| 643 | Maximum Average Subarray I | 38.40% | Easy |
| 642 | Design Search Autocomplete System $ | 29.40% | Hard |
| 641 | Design Circular Deque | 48.00% | Medium |
| 640 | Solve the Equation | 39.00% | Medium |
| 639 | Decode Ways II | 22.80% | Hard |
| 638 | Shopping Offers | 41.50% | Medium |
| 637 | Average of Levels in Binary Tree | 55.60% | Easy |
| 636 | Exclusive Time of Functions | 40.30% | Medium |
| 635 | Design Log Storage System $ | 47.70% | Medium |
| 634 | Find the Derangement of An Array $ | 32.70% | Medium |
| 633 | Sum of Square Numbers | 31.60% | Easy |
| 632 | Smallest Range | 42.80% | Hard |
| 631 | Design Excel Sum Formula $ | 25.60% | Hard |
| 630 | Course Schedule III | 20.50% | Medium |
| 629 | K Inverse Pairs Array | 23.90% | Hard |
| 628 | Maximum Product of Three Numbers | 45.40% | Easy |
| 627 | Swap Salary | 67.40% | Easy |
| 626 | Exchange Seats | 49.60% | Medium |
| 625 | Minimum Factorization | 29.50% | Medium |
| 624 | Maximum Distance in Arrays $ | 32.70% | Easy |
| 623 | Add One Row to Tree | 48.70% | Medium |
| 622 | Design Circular Queue | 36.60% | Medium |
| 621 | Task Scheduler | 41.40% | Medium |
| 620 | Not Boring Movies | 59.80% | Easy |
| 619 | Biggest Single Number $ | 36.60% | Easy |
| 618 | Students Report By Geography $ | 40.40% | Hard |
| 617 | Merge Two Binary Trees | 69.60% | Easy |
| 616 | Add Bold Tag in String $ | 37.30% | Medium |
| 615 | Average Salary: Departments VS Company $ | 33.00% | Hard |
| 614 | Second Degree Follower $ | 22.70% | Medium |
| 613 | Shortest Distance in a Line $ | 70.60% | Easy |
| 612 | Shortest Distance in a Plane $ | 51.00% | Medium |
| 611 | Valid Triangle Number | 38.90% | Medium |
| 610 | Triangle Judgement $ | 59.10% | Easy |
| 609 | Find Duplicate File in System | 52.50% | Medium |
| 608 | Tree Node $ | 54.60% | Medium |
| 607 | Sales Person $ | 51.10% | Easy |
| 606 | Construct String from Binary Tree | 51.80% | Easy |
| 605 | Can Place Flowers | 30.00% | Easy |
| 604 | Design Compressed String Iterator $ | 31.60% | Easy |
| 603 | Consecutive Available Seats $ | 54.50% | Easy |
| 602 | Friend Requests II: Who Has the Most Friends $ | 42.50% | Medium |
| 601 | Human Traffic of Stadium | 33.80% | Hard |
| 600 | Non-negative Integers without Consecutive Ones | 27.40% | Hard |
| 599 | Minimum Index Sum of Two Lists | 48.00% | Easy |
| 598 | Range Addition II | 48.30% | Easy |
| 597 | Friend Requests I: Overall Acceptance Rate $ | 38.40% | Easy |
| 596 | Classes More Than 5 Students | 33.40% | Easy |
| 595 | Big Countries | 72.00% | Easy |
| 594 | Longest Harmonious Subsequence | 40.00% | Easy |
| 593 | Valid Square | 39.20% | Medium |
| 592 | Fraction Addition and Subtraction | 47.00% | Medium |
| 591 | Tag Validator | 26.40% | Hard |
| 590 | N-ary Tree Postorder Traversal | 63.00% | Easy |
| 589 | N-ary Tree Preorder Traversal | 63.10% | Easy |
| 588 | Design In-Memory File System $ | 32.40% | Hard |
| 587 | Erect the Fence | 29.90% | Hard |
| 586 | Customer Placing the Largest Number of Orders $ | 62.50% | Easy |
| 585 | Investments in 2016 $ | 44.60% | Medium |
| 584 | Find Customer Referee $ | 63.60% | Easy |
| 583 | Delete Operation for Two Strings | 44.00% | Medium |
| 582 | Kill Process $ | 47.70% | Medium |
| 581 | Shortest Unsorted Continuous Subarray | 30.10% | Easy |
| 580 | Count Student Number in Departments $ | 40.00% | Medium |
| 579 | Find Cumulative Salary of an Employee $ | 30.90% | Hard |
| 578 | Get Highest Answer Rate Question $ | 33.10% | Medium |
| 577 | Employee Bonus $ | 53.80% | Easy |
| 576 | Out of Boundary Paths | 33.10% | Medium |
| 575 | Distribute Candies | 59.50% | Easy |
| 574 | Winning Candidate $ | 34.50% | Medium |
| 573 | Squirrel Simulation $ | 51.00% | Medium |
| 572 | Subtree of Another Tree | 41.00% | Easy |
| 571 | Find Median Given Frequency of Numbers $ | 44.90% | Hard |
| 570 | Managers with at Least 5 Direct Reports $ | 59.00% | Medium |
| 569 | Median Employee Salary $ | 41.60% | Hard |
| 568 | Maximum Vacation Days $ | 39.90% | Hard |
| 567 | Permutation in String | 36.30% | Medium |
| 566 | Reshape the Matrix | 59.80% | Easy |
| 565 | Array Nesting | 50.00% | Medium |
| 564 | Find the Closest Palindrome | 16.60% | Hard |
| 563 | Binary Tree Tilt | 47.00% | Easy |
| 562 | Longest Line of Consecutive One in Matrix $ | 38.80% | Medium |
| 561 | Array Partition I | 69.80% | Easy |
| 560 | Subarray Sum Equals K | 41.80% | Medium |
| 559 | Maximum Depth of N-ary Tree | 62.10% | Easy |
| 558 | Quad Tree Intersection | 36.40% | Easy |
| 557 | Reverse Words in a String III | 61.20% | Easy |
| 556 | Next Greater Element III | 27.70% | Medium |
| 555 | Split Concatenated Strings $ | 30.00% | Medium |
| 554 | Brick Wall | 42.70% | Medium |
| 553 | Optimal Division | 55.20% | Medium |
| 552 | Student Attendance Record II | 28.50% | Hard |
| 551 | Student Attendance Record I | 43.90% | Easy |
| 549 | Binary Tree Longest Consecutive Sequence II $ | 38.10% | Medium |
| 548 | Split Array with Equal Sum $ | 30.80% | Medium |
| 547 | Friend Circles | 49.00% | Medium |
| 546 | Remove Boxes | 29.60% | Hard |
| 545 | Boundary of Binary Tree $ | 29.10% | Medium |
| 544 | Output Contest Matches $ | 73.20% | Medium |
| 543 | Diameter of Binary Tree | 42.70% | Easy |
| 542 | 01 Matrix | 32.50% | Medium |
| 541 | Reverse String II | 44.40% | Easy |
| 540 | Single Element in a Sorted Array | 55.90% | Medium |
| 539 | Minimum Time Difference | 44.70% | Medium |
| 538 | Convert BST to Greater Tree | 52.70% | Medium |
| 537 | Complex Number Multiplication | 65.90% | Medium |
| 536 | Construct Binary Tree from String $ | 36.30% | Medium |
| 535 | Encode and Decode TinyURL | 76.10% | Medium |
| 534 | Game Play Analysis III | 67.10% | Medium |
| 533 | Lonely Pixel II $ | 38.90% | Medium |
| 532 | K-diff Pairs in an Array | 27.20% | Easy |
| 531 | Lonely Pixel I $ | 50.20% | Medium |
| 530 | Minimum Absolute Difference in BST | 48.00% | Easy |
| 529 | Minesweeper | 52.00% | Medium |
| 528 | Random Pick with Weight | 41.80% | Medium |
| 527 | Word Abbreviation $ | 33.90% | Hard |
| 526 | Beautiful Arrangement | 53.50% | Medium |
| 525 | Contiguous Array | 34.40% | Medium |
| 524 | Longest Word in Dictionary through Deleting | 40.20% | Medium |
| 523 | Continuous Subarray Sum | 21.30% | Medium |
| 522 | Longest Uncommon Subsequence II | 28.10% | Medium |
| 521 | Longest Uncommon Subsequence I | 50.70% | Easy |
| 520 | Detect Capital | 54.20% | Easy |
| 519 | Random Flip Matrix | 32.20% | Medium |
| 518 | Coin Change 2 | 33.20% | Medium |
| 517 | Super Washing Machines | 34.60% | Hard |
| 516 | Longest Palindromic Subsequence | 42.00% | Medium |
| 515 | Find Largest Value in Each Tree Row | 52.70% | Medium |
| 514 | Freedom Trail | 27.20% | Hard |
| 513 | Find Bottom Left Tree Value | 55.60% | Medium |
| 510 | Inorder Successor in BST II $ | 56.20% | Medium |
| 509 | Fibonacci Number | 66.40% | Easy |
| 508 | Most Frequent Subtree Sum | 52.00% | Medium |
| 507 | Perfect Number | 32.70% | Easy |
| 506 | Relative Ranks | 48.50% | Easy |
| 505 | The Maze II | 34.80% | Medium |
| 504 | Base 7 | 46.40% | Easy |
| 503 | Next Greater Element II | 46.20% | Medium |
| 502 | IPO | 32.40% | Hard |
| 501 | Find Mode in Binary Search Tree | 39.40% | Easy |
| 500 | Keyboard Row | 60.20% | Easy |
| 499 | The Maze III | 32.00% | Hard |
| 498 | Diagonal Traverse | 46.20% | Medium |
| 497 | Random Point in Non-overlapping Rectangles | 33.20% | Medium |
| 496 | Next Greater Element I | 58.80% | Easy |
| 495 | Teemo Attacking | 51.90% | Medium |
| 494 | Target Sum | 44.40% | Medium |
| 493 | Reverse Pairs | 17.10% | Hard |
| 492 | Construct the Rectangle | 49.70% | Easy |
| 491 | Increasing Subsequences | 39.30% | Medium |
| 490 | The Maze | 42.80% | Medium |
| 489 | Robot Room Cleaner | 57.10% | Hard |
| 488 | Zuma Game | 38.00% | Hard |
| 487 | Max Consecutive Ones II $ | 42.70% | Medium |
| 486 | Predict the Winner | 43.60% | Medium |
| 485 | Max Consecutive Ones | 55.30% | Easy |
| 484 | Find Permutation $ | 50.50% | Medium |
| 483 | Smallest Good Base | 30.60% | Hard |
| 482 | License Key Formatting | 41.20% | Medium |
| 481 | Magical String | 46.20% | Medium |
| 480 | Sliding Window Median | 31.00% | Hard |
| 479 | Largest Palindrome Product | 23.90% | Easy |
| 478 | Generate Random Point in a Circle | 33.80% | Medium |
| 477 | Total Hamming Distance | 44.10% | Medium |
| 476 | Number Complement | 61.20% | Easy |
| 475 | Heaters | 30.20% | Easy |
| 474 | Ones and Zeroes | 34.90% | Medium |
| 473 | Matchsticks to Square | 31.80% | Medium |
| 472 | Concatenated Words | 29.20% | Hard |
| 471 | Encode String with Shortest Length $ | 43.50% | Hard |
| 470 | Implement Rand10() Using Rand7() | 43.00% | Medium |
| 469 | Convex Polygon $ | 27.20% | Medium |
| 468 | Validate IP Address | 22.10% | Medium |
| 467 | Unique Substrings in Wraparound String | 29.90% | Medium |
| 466 | Count The Repetitions | 24.20% | Hard |
| 465 | Optimal Account Balancing $ | 29.20% | Hard |
| 464 | Can I Win | 22.20% | Medium |
| 463 | Island Perimeter | 56.70% | Easy |
| 462 | Minimum Moves to Equal Array Elements II | 50.90% | Medium |
| 461 | Hamming Distance | 73.20% | Easy |
| 460 | LFU Cache | 18.30% | Hard |
| 459 | Repeated Substring Pattern | 39.70% | Easy |
| 458 | Poor Pigs | 40.70% | Easy |
| 457 | Circular Array Loop | 20.60% | Medium |
| 456 | 132 Pattern | 28.00% | Medium |
| 455 | Assign Cookies | 48.10% | Easy |
| 454 | 4Sum II | 42.80% | Medium |
| 453 | Minimum Moves to Equal Array Elements | 46.30% | Easy |
| 452 | Minimum Number of Arrows to Burst Balloons | 42.10% | Medium |
| 451 | Sort Characters By Frequency | 50.90% | Medium |
| 450 | Delete Node in a BST | 34.50% | Medium |
| 449 | Serialize and Deserialize BST | 41.20% | Medium |
| 448 | Find All Numbers Disappeared in an Array | 58.30% | Easy |
| 447 | Number of Boomerangs | 42.20% | Easy |
| 446 | Arithmetic Slices II - Subsequence | 22.30% | Hard |
| 445 | Add Two Numbers II | 45.40% | Medium |
| 444 | Sequence Reconstruction $ | 20.50% | Medium |
| 443 | String Compression | 35.80% | Easy |
| 442 | Find All Duplicates in an Array | 46.40% | Medium |
| 441 | Arranging Coins | 36.20% | Easy |
| 440 | K-th Smallest in Lexicographical Order | 21.50% | Hard |
| 439 | Ternary Expression Parser $ | 49.40% | Medium |
| 438 | Find All Anagrams in a String | 33.50% | Easy |
| 437 | Path Sum III | 38.60% | Easy |
| 436 | Find Right Interval | 42.30% | Medium |
| 435 | Non-overlapping Intervals | 39.80% | Medium |
| 434 | Number of Segments in a String | 38.40% | Easy |
| 433 | Minimum Genetic Mutation | 33.50% | Medium |
| 432 | All O`one Data Structure | 28.30% | Hard |
| 431 | Encode N-ary Tree to Binary Tree $ | 53.70% | Hard |
| 430 | Flatten a Multilevel Doubly Linked List | 36.20% | Medium |
| 429 | N-ary Tree Level Order Traversal | 55.80% | Easy |
| 428 | Serialize and Deserialize N-ary Tree $ | 48.10% | Hard |
| 427 | Construct Quad Tree | 49.20% | Easy |
| 426 | Convert Binary Search Tree to Sorted Doubly Linked List | 43.30% | Medium |
| 425 | Word Squares $ | 40.10% | Hard |
| 424 | Longest Repeating Character Replacement | 38.10% | Medium |
| 423 | Reconstruct Original Digits from English | 40.80% | Medium |
| 422 | Valid Word Square $ | 36.40% | Easy |
| 421 | Maximum XOR of Two Numbers in an Array | 36.40% | Medium |
| 420 | Strong Password Checker | 22.10% | Hard |
| 419 | Battleships in a Board | 59.30% | Medium |
| 418 | Sentence Screen Fitting $ | 25.10% | Medium |
| 417 | Pacific Atlantic Water Flow | 31.10% | Medium |
| 416 | Partition Equal Subset Sum | 36.80% | Medium |
| 415 | Add Strings | 41.50% | Easy |
| 414 | Third Maximum Number | 26.50% | Easy |
| 413 | Arithmetic Slices | 53.50% | Medium |
| 412 | Fizz Buzz | 57.50% | Easy |
| 411 | Minimum Unique Word Abbreviation $ | 25.60% | Hard |
| 410 | Split Array Largest Sum | 25.00% | Hard |
| 409 | Longest Palindrome | 44.90% | Easy |
| 408 | Valid Word Abbreviation $ | 26.20% | Easy |
| 407 | Trapping Rain Water II | 33.10% | Hard |
| 406 | Queue Reconstruction by Height | 54.10% | Medium |
| 405 | Convert a Number to Hexadecimal | 41.80% | Easy |
| 404 | Sum of Left Leaves | 46.20% | Easy |
| 403 | Frog Jump | 31.70% | Hard |
| 402 | Remove K Digits | 25.90% | Medium |
| 401 | Binary Watch | 43.00% | Easy |
| 400 | Nth Digit | 30.70% | Easy |
| 399 | Evaluate Division | 34.60% | Medium |
| 398 | Random Pick Index | 30.40% | Medium |
| 397 | Integer Replacement | 25.90% | Easy |
| 396 | Rotate Function | 28.40% | Easy |
| 395 | Longest Substring with At Least K Repeating Characters | 32.50% | Medium |
| 394 | Decode String | 38.60% | Medium |
| 393 | UTF-8 Validation | 33.00% | Medium |
| 392 | Is Subsequence | 44.10% | Medium |
| 391 | Perfect Rectangle | 13.30% | Hard |
| 390 | Elimination Game | 12.50% | Medium |
| 389 | Find the Difference | 49.90% | Easy |
| 388 | Longest Absolute File Path | 28.30% | Medium |
| 387 | First Unique Character in a String | 43.10% | Easy |
| 386 | Lexicographical Numbers | 31.00% | Medium |
| 385 | Mini Parser | 26.90% | Medium |
| 384 | Shuffle an Array | 45.50% | Medium |
| 383 | Ransom Note | 44.60% | Easy |
| 382 | Linked List Random Node | 48.60% | Medium |
| 381 | Insert Delete GetRandom O(1) - Duplicates allowed | 30.90% | Hard |
| 380 | Insert Delete GetRandom O(1) | 33.80% | Medium |
| 379 | Design Phone Directory $ | 25.80% | Medium |
| 378 | Kth Smallest Element in a Sorted Matrix | 40.20% | Medium |
| 377 | Combination Sum IV | 37.50% | Medium |
| 376 | Wiggle Subsequence | 35.80% | Medium |
| 375 | Guess Number Higher or Lower II | 28.30% | Medium |
| 374 | Guess Number Higher or Lower | 31.70% | Easy |
| 373 | Find K Pairs with Smallest Sums | 25.50% | Medium |
| 372 | Super Pow | 30.10% | Medium |
| 371 | Sum of Two Integers | 54.00% | Easy |
| 370 | Range Addition $ | 49.90% | Medium |
| 369 | Plus One Linked List $ | 50.10% | Medium |
| 368 | Largest Divisible Subset | 32.00% | Medium |
| 367 | Valid Perfect Square | 36.60% | Medium |
| 366 | Find Leaves of Binary Tree $ | 53.60% | Medium |
| 365 | Water and Jug Problem | 20.10% | Medium |
| 364 | Nested List Weight Sum II $ | 47.20% | Medium |
| 363 | Max Sum of Rectangle No Larger Than K | 27.00% | Hard |
| 362 | Design Hit Counter $ | 48.30% | Medium |
| 361 | Bomb Enemy $ | 32.60% | Medium |
| 360 | Sort Transformed Array $ | 40.80% | Medium |
| 359 | Logger Rate Limiter $ | 56.00% | Easy |
| 358 | Rearrange String k Distance Apart $ | 26.90% | Hard |
| 357 | Count Numbers with Unique Digits | 42.50% | Medium |
| 356 | Line Reflection $ | 28.70% | Medium |
| 355 | Design Twitter | 22.20% | Medium |
| 354 | Russian Doll Envelopes | 27.10% | Hard |
| 353 | Design Snake Game $ | 19.80% | Medium |
| 352 | Data Stream as Disjoint Intervals | 34.40% | Hard |
| 351 | Android Unlock Patterns $ | 32.00% | Medium |
| 350 | Intersection of Two Arrays II | 41.50% | Easy |
| 349 | Intersection of Two Arrays | 47.80% | Easy |
| 348 | Design Tic-Tac-Toe $ | 45.60% | Medium |
| 347 | Top K Frequent Elements | 44.50% | Medium |
| 346 | Moving Average from Data Stream $ | 69.20% | Easy |
| 345 | Reverse Vowels of a String | 35.30% | Easy |
| 344 | Reverse String | 58.90% | Easy |
| 343 | Integer Break | 43.60% | Medium |
| 342 | Power of Four | 34.10% | Easy |
| 341 | Flatten Nested List Iterator $ | 18.70% | Medium |
| 340 | Longest Substring with At Most K Distinct Characters $ | 36.30% | Hard |
| 339 | Nested List Weight Sum $ | 54.60% | Easy |
| 338 | Counting Bits | 55.40% | Medium |
| 337 | House Robber III | 37.00% | Medium |
| 336 | Palindrome Pairs | 18.70% | Hard |
| 335 | Self Crossing | 18.00% | Medium |
| 334 | Increasing Triplet Subsequence | 33.20% | Medium |
| 333 | Largest BST Subtree $ | 26.50% | Medium |
| 332 | Reconstruct Itinerary | 23.40% | Medium |
| 331 | Verify Preorder Serialization of a Binary Tree | 31.50% | Medium |
| 330 | Patching Array | 28.80% | Medium |
| 329 | Longest Increasing Path in a Matrix | 29.50% | Medium |
| 328 | Odd Even Linked List | 37.80% | Easy |
| 327 | Count of Range Sum | 24.30% | Hard |
| 326 | Power of Three | 35.30% | Easy |
| 325 | Maximum Size Subarray Sum Equals k $ | 39.60% | Easy |
| 324 | Wiggle Sort II | 20.10% | Medium |
| 323 | Number of Connected Components in an Undirected Graph $ | 43.30% | Medium |
| 322 | Coin Change | 24.90% | Medium |
| 321 | Create Maximum Number | 19.10% | Hard |
| 320 | Generalized Abbreviation $ | 40.40% | Medium |
| 319 | Bulb Switcher | 39.20% | Medium |
| 318 | Maximum Product of Word Lengths | 38.70% | Medium |
| 317 | Shortest Distance from All Buildings $ | 29.10% | Hard |
| 316 | Remove Duplicate Letters | 23.00% | Medium |
| 315 | Count of Smaller Numbers After Self | 28.20% | Hard |
| 314 | Binary Tree Vertical Order Traversal $ | 30.10% | Medium |
| 313 | Super Ugly Number | 31.20% | Medium |
| 312 | Burst Balloons | 24.50% | Medium |
| 311 | Sparse Matrix Multiplication $ | 40.00% | Medium |
| 310 | Minimum Height Trees | 20.20% | Medium |
| 309 | Best Time to Buy and Sell Stock with Cooldown | 32.60% | Medium |
| 308 | Range Sum Query 2D - Mutable $ | 20.30% | Hard |
| 307 | Range Sum Query - Mutable | 14.50% | Medium |
| 306 | Additive Number | 23.30% | Medium |
| 305 | Number of Islands II $ | 26.70% | Hard |
| 304 | Range Sum Query 2D - Immutable | 21.50% | Medium |
| 303 | Range Sum Query - Immutable | 25.70% | Easy |
| 302 | Smallest Rectangle Enclosing Black Pixels $ | 36.70% | Hard |
| 301 | Remove Invalid Parentheses | 27.00% | Hard |
| 300 | Longest Increasing Subsequence | 31.50% | Medium |
| 299 | Bulls and Cows | 23.80% | Easy |
| 298 | Binary Tree Longest Consecutive Sequence $ | 32.20% | Medium |
| 297 | Serialize and Deserialize Binary Tree | 23.80% | Medium |
| 296 | Best Meeting Point $ | 41.40% | Hard |
| 295 | Find Median from Data Stream | 18.60% | Hard |
| 294 | Flip Game II $ | 38.10% | Medium |
| 293 | Flip Game $ | 47.60% | Easy |
| 292 | Nim Game | 49.50% | Easy |
| 291 | Word Pattern II $ | 31.50% | Hard |
| 290 | Word Pattern | 26.50% | Easy |
| 289 | Game of Life | 32.60% | Medium |
| 288 | Unique Word Abbreviation $ | 16.80% | Easy |
| 287 | Find the Duplicate Number | 32.80% | Hard |
| 286 | Walls and Gates $ | 29.90% | Medium |
| 285 | Inorder Successor in BST $ | 32.50% | Medium |
| 284 | Peeking Iterator | 31.00% | Medium |
| 283 | Move Zeroes | 41.40% | Easy |
| 282 | Expression Add Operators | 18.90% | Hard |
| 281 | Zigzag Iterator $ | 37.20% | Medium |
| 280 | Wiggle Sort $ | 43.30% | Medium |
| 279 | Perfect Squares | 28.80% | Medium |
| 278 | First Bad Version | 19.80% | Easy |
| 277 | Find the Celebrity $ | 31.70% | Medium |
| 276 | Paint Fence $ | 25.00% | Easy |
| 275 | H-Index II | 31.40% | Medium |
| 274 | H-Index | 25.30% | Medium |
| 273 | Integer to English Words | 15.50% | Medium |
| 272 | Closest Binary Search Tree Value II $ | 26.90% | Hard |
| 271 | Encode and Decode Strings $ | 25.40% | Medium |
| 270 | Closest Binary Search Tree Value $ | 29.40% | Easy |
| 269 | Alien Dictionary $ | 16.50% | Hard |
| 268 | Missing Number | 34.70% | Medium |
| 267 | Palindrome Permutation II $ | 22.50% | Medium |
| 266 | Palindrome Permutation $ | 45.80% | Easy |
| 265 | Paint House II $ | 30.00% | Hard |
| 264 | Ugly Number II | 21.60% | Medium |
| 263 | Ugly Number | 32.60% | Easy |
| 262 | Trips and Users * | 16.10% | Hard |
| 261 | Graph Valid Tree $ | 25.40% | Medium |
| 260 | Single Number III | 37.60% | Medium |
| 259 | 3Sum Smaller $ | 34.20% | Medium |
| 258 | Add Digits | 46.50% | Easy |
| 257 | Binary Tree Paths | 21.90% | Easy |
| 256 | Paint House $ | 38.40% | Medium |
| 255 | Verify Preorder Sequence in Binary Search Tree $ | 32.30% | Medium |
| 254 | Factor Combinations $ | 29.00% | Medium |
| 253 | Meeting Rooms II $ | 28.80% | Medium |
| 252 | Meeting Rooms $ | 35.40% | Easy |
| 251 | Flatten 2D Vector $ | 28.30% | Medium |
| 250 | Count Univalue Subtrees $ | 32.70% | Medium |
| 249 | Group Shifted Strings $ | 25.20% | Easy |
| 248 | Strobogrammatic Number III $ | 21.80% | Hard |
| 247 | Strobogrammatic Number II $ | 26.70% | Medium |
| 246 | Strobogrammatic Number $ | 31.60% | Easy |
| 245 | Shortest Word Distance III $ | 43.20% | Medium |
| 244 | Shortest Word Distance II $ | 33.70% | Medium |
| 243 | Shortest Word Distance $ | 41.80% | Easy |
| 242 | Valid Anagram | 39.30% | Easy |
| 241 | Different Ways to Add Parentheses | 27.10% | Medium |
| 240 | Search a 2D Matrix II | 31.40% | Medium |
| 239 | Sliding Window Maximum | 24.30% | Hard |
| 238 | Product of Array Except Self | 42.40% | Medium |
| 237 | Delete Node in a Linked List | 50.90% | Easy |
| 236 | Lowest Common Ancestor of a Binary Tree | 28.30% | Medium |
| 235 | Lowest Common Ancestor of a Binary Search Tree | 38.90% | Medium |
| 234 | Palindrome Linked List | 23.80% | Easy |
| 233 | Number of Digit One | 16.10% | Medium |
| 232 | Implement Queue using Stacks | 37.40% | Easy |
| 231 | Power of Two | 31.30% | Easy |
| 230 | Kth Smallest Element in a BST | 30.50% | Medium |
| 229 | Majority Element II | 30.50% | Medium |
| 228 | Summary Ranges | 21.10% | Easy |
| 227 | Basic Calculator II | 18.00% | Medium |
| 226 | Invert Binary Tree | 35.40% | Easy |
| 225 | Implement Stack using Queues | 29.60% | Medium |
| 224 | Basic Calculator | 15.80% | Medium |
| 223 | Rectangle Area | 25.60% | Easy |
| 222 | Count Complete Tree Nodes | 19.40% | Medium |
| 221 | Maximal Square | 20.30% | Medium |
| 220 | Contains Duplicate III | 15.30% | Medium |
| 219 | Contains Duplicate II | 25.60% | Easy |
| 218 | The Skyline Problem | 16.20% | Hard |
| 217 | Contains Duplicate | 35.90% | Easy |
| 216 | Combination Sum III | 27.70% | Medium |
| 215 | Kth Largest Element in an Array | 27.30% | Medium |
| 214 | Shortest Palindrome | 16.80% | Hard |
| 213 | House Robber II | 26.30% | Medium |
| 212 | Word Search II | 15.00% | Hard |
| 211 | Add and Search Word - Data structure design | 20.70% | Medium |
| 210 | Course Schedule II | 19.30% | Medium |
| 209 | Minimum Size Subarray Sum | 22.90% | Medium |
| 208 | Implement Trie (Prefix Tree) | 24.80% | Medium |
| 207 | Course Schedule | 21.70% | Medium |
| 206 | Reverse Linked List | 31.50% | Easy |
| 205 | Isomorphic Strings | 24.20% | Easy |
| 204 | Count Primes | 19.00% | Easy |
| 203 | Remove Linked List Elements | 25.80% | Easy |
| 202 | Happy Number | 31.40% | Easy |
| 201 | Bitwise AND of Numbers Range | 23.30% | Medium |
| 200 | Number of Islands | 21.90% | Medium |
| 199 | Binary Tree Right Side View | 27.10% | Medium |
| 198 | House Robber | 28.80% | Easy |
| 197 | Rising Temperature * | 25.90% | Easy |
| 196 | Delete Duplicate Emails * | 19.00% | Easy |
| 195 | Tenth Line # | 32.20% | Easy |
| 194 | Transpose File # | 21.40% | Medium |
| 193 | Valid Phone Numbers # | 24.40% | Easy |
| 192 | Word Frequency # | 26.10% | Medium |
| 191 | Number of 1 Bits | 37.30% | Easy |
| 190 | Reverse Bits | 28.40% | Easy |
| 189 | Rotate Array | 17.80% | Easy |
| 188 | Best Time to Buy and Sell Stock IV | 17.30% | Hard |
| 187 | Repeated DNA Sequences | 19.50% | Medium |
| 186 | Reverse Words in a String II $ | 31.10% | Medium |
| 185 | Department Top Three Salaries * | 15.20% | Hard |
| 184 | Department Highest Salary * | 19.00% | Medium |
| 183 | Customers Who Never Order * | 33.70% | Easy |
| 182 | Duplicate Emails * | 38.10% | Easy |
| 181 | Employees Earning More Than Their Managers * | 41.00% | Easy |
| 180 | Consecutive Numbers * | 26.60% | Medium |
| 179 | Largest Number | 15.70% | Medium |
| 178 | Rank Scores * | 24.60% | Medium |
| 177 | Nth Highest Salary * | 16.30% | Medium |
| 176 | Second Highest Salary * | 25.00% | Easy |
| 175 | Combine Two Tables * | 34.40% | Easy |
| 174 | Dungeon Game | 17.70% | Hard |
| 173 | Binary Search Tree Iterator | 29.30% | Medium |
| 172 | Factorial Trailing Zeroes | 28.40% | Easy |
| 171 | Excel Sheet Column Number | 36.50% | Easy |
| 170 | Two Sum III - Data structure design $ | 24.70% | Easy |
| 169 | Majority Element | 35.00% | Easy |
| 168 | Excel Sheet Column Title | 18.10% | Easy |
| 167 | Two Sum II - Input array is sorted $ | 43.30% | Medium |
| 166 | Fraction to Recurring Decimal | 12.70% | Medium |
| 165 | Compare Version Numbers | 15.20% | Easy |
| 164 | Maximum Gap | 24.40% | Hard |
| 163 | Missing Ranges $ | 24.10% | Medium |
| 162 | Find Peak Element | 31.50% | Medium |
| 161 | One Edit Distance $ | 24.00% | Medium |
| 160 | Intersection of Two Linked Lists | 28.70% | Easy |
| 159 | Longest Substring with At Most Two Distinct Characters $ | 30.20% | Hard |
| 158 | Read N Characters Given Read4 II - Call multiple times $ | 22.30% | Hard |
| 157 | Read N Characters Given Read4 $ | 29.80% | Easy |
| 156 | Binary Tree Upside Down $ | 34.30% | Medium |
| 155 | Min Stack | 18.50% | Easy |
| 154 | Find Minimum in Rotated Sorted Array II | 31.90% | Hard |
| 153 | Find Minimum in Rotated Sorted Array | 33.30% | Medium |
| 152 | Maximum Product Subarray | 19.40% | Medium |
| 151 | Reverse Words in a String | 15.10% | Medium |
| 150 | Evaluate Reverse Polish Notation | 21.10% | Medium |
| 149 | Max Points on a Line | 12.60% | Hard |
| 148 | Sort List | 22.00% | Medium |
| 147 | Insertion Sort List | 26.40% | Medium |
| 146 | LRU Cache | 15.00% | Hard |
| 145 | Binary Tree Postorder Traversal | 32.40% | Hard |
| 144 | Binary Tree Preorder Traversal | 36.30% | Medium |
| 143 | Reorder List | 21.00% | Medium |
| 142 | Linked List Cycle II | 31.40% | Medium |
| 141 | Linked List Cycle | 36.30% | Medium |
| 140 | Word Break II | 17.70% | Hard |
| 139 | Word Break | 23.00% | Medium |
| 138 | Copy List with Random Pointer | 25.10% | Hard |
| 137 | Single Number II | 35.00% | Medium |
| 136 | Single Number | 45.10% | Medium |
| 135 | Candy | 20.50% | Hard |
| 134 | Gas Station | 25.70% | Medium |
| 133 | Clone Graph | 24.00% | Medium |
| 132 | Palindrome Partitioning II | 19.70% | Hard |
| 131 | Palindrome Partitioning | 26.70% | Medium |
| 130 | Surrounded Regions | 14.60% | Medium |
| 129 | Sum Root to Leaf Numbers | 30.30% | Medium |
| 128 | Longest Consecutive Sequence | 29.40% | Hard |
| 127 | Word Ladder | 19.30% | Medium |
| 126 | Word Ladder II | 12.90% | Hard |
| 125 | Valid Palindrome | 22.00% | Easy |
| 124 | Binary Tree Maximum Path Sum | 21.50% | Hard |
| 123 | Best Time to Buy and Sell Stock III | 23.90% | Hard |
| 122 | Best Time to Buy and Sell Stock II | 38.30% | Medium |
| 121 | Best Time to Buy and Sell Stock | 32.60% | Medium |
| 120 | Triangle | 27.40% | Medium |
| 119 | Pascal's Triangle II | 29.40% | Easy |
| 118 | Pascal's Triangle | 30.10% | Easy |
| 117 | Populating Next Right Pointers in Each Node II | 32.00% | Hard |
| 116 | Populating Next Right Pointers in Each Node | 36.20% | Medium |
| 115 | Distinct Subsequences | 26.30% | Hard |
| 114 | Flatten Binary Tree to Linked List | 28.80% | Medium |
| 113 | Path Sum II | 26.60% | Medium |
| 112 | Path Sum | 29.80% | Easy |
| 111 | Minimum Depth of Binary Tree | 29.10% | Easy |
| 110 | Balanced Binary Tree | 32.00% | Easy |
| 109 | Convert Sorted List to Binary Search Tree | 27.90% | Medium |
| 108 | Convert Sorted Array to Binary Search Tree | 34.00% | Medium |
| 107 | Binary Tree Level Order Traversal II | 31.10% | Easy |
| 106 | Construct Binary Tree from Inorder and Postorder Traversal | 26.80% | Medium |
| 105 | Construct Binary Tree from Preorder and Inorder Traversal | 26.40% | Medium |
| 104 | Maximum Depth of Binary Tree | 45.10% | Easy |
| 103 | Binary Tree Zigzag Level Order Traversal | 26.40% | Medium |
| 102 | Binary Tree Level Order Traversal | 29.30% | Easy |
| 101 | Symmetric Tree | 31.60% | Easy |
| 100 | Same Tree | 41.80% | Easy |
| 99 | Recover Binary Search Tree | 24.30% | Hard |
| 98 | Validate Binary Search Tree | 20.60% | Medium |
| 97 | Interleaving String | 20.80% | Hard |
| 96 | Unique Binary Search Trees | 36.00% | Medium |
| 95 | Unique Binary Search Trees II | 28.00% | Medium |
| 94 | Binary Tree Inorder Traversal | 36.20% | Medium |
| 93 | Restore IP Addresses | 21.00% | Medium |
| 92 | Reverse Linked List II | 26.10% | Medium |
| 91 | Decode Ways | 16.40% | Medium |
| 90 | Subsets II | 27.70% | Medium |
| 89 | Gray Code | 32.80% | Medium |
| 88 | Merge Sorted Array | 29.70% | Easy |
| 87 | Scramble String | 24.20% | Hard |
| 86 | Partition List | 27.50% | Medium |
| 85 | Maximal Rectangle | 22.00% | Hard |
| 84 | Largest Rectangle in Histogram | 22.60% | Hard |
| 83 | Remove Duplicates from Sorted List | 34.50% | Easy |
| 82 | Remove Duplicates from Sorted List II | 25.00% | Medium |
| 81 | Search in Rotated Sorted Array II | 31.40% | Medium |
| 80 | Remove Duplicates from Sorted Array II | 30.50% | Medium |
| 79 | Word Search | 20.30% | Medium |
| 78 | Subsets | 28.20% | Medium |
| 77 | Combinations | 30.90% | Medium |
| 76 | Minimum Window Substring | 18.90% | Hard |
| 75 | Sort Colors | 32.60% | Medium |
| 74 | Search a 2D Matrix | 31.60% | Medium |
| 73 | Set Matrix Zeroes | 31.40% | Medium |
| 72 | Edit Distance | 26.20% | Hard |
| 71 | Simplify Path | 20.00% | Medium |
| 70 | Climbing Stairs | 34.40% | Easy |
| 69 | Sqrt(x) | 23.10% | Medium |
| 68 | Text Justification | 14.60% | Hard |
| 67 | Add Binary | 24.70% | Easy |
| 66 | Plus One | 30.40% | Easy |
| 65 | Valid Number | 11.40% | Hard |
| 64 | Minimum Path Sum | 32.20% | Medium |
| 63 | Unique Paths II | 28.00% | Medium |
| 62 | Unique Paths | 32.80% | Medium |
| 61 | Rotate List | 21.70% | Medium |
| 60 | Permutation Sequence | 22.80% | Medium |
| 59 | Spiral Matrix II | 31.80% | Medium |
| 58 | Length of Last Word | 28.00% | Easy |
| 57 | Insert Interval | 21.40% | Hard |
| 56 | Merge Intervals | 22.40% | Hard |
| 55 | Jump Game | 27.00% | Medium |
| 54 | Spiral Matrix | 20.80% | Medium |
| 53 | Maximum Subarray | 34.50% | Medium |
| 52 | N-Queens II | 35.80% | Hard |
| 51 | N-Queens | 26.50% | Hard |
| 50 | Pow(x, n) | 26.70% | |
| 49 | Anagrams | 24.30% | Medium |
| 48 | Rotate Image | 31.90% | Medium |
| 47 | Permutations II | 25.80% | Hard |
| 46 | Permutations | 31.90% | Medium |
| 45 | Jump Game II | 24.20% | Hard |
| 44 | Wildcard Matching | 15.00% | Hard |
| 43 | Multiply Strings | 21.00% | Medium |
| 42 | Trapping Rain Water | 30.00% | Hard |
| 41 | First Missing Positive | 22.90% | Hard |
| 40 | Combination Sum II | 25.20% | Medium |
| 39 | Combination Sum | 27.90% | Medium |
| 38 | Count and Say | 25.20% | Easy |
| 37 | Sudoku Solver | 21.80% | Hard |
| 36 | Valid Sudoku | 27.20% | Easy |
| 35 | Search Insert Position | 35.40% | Medium |
| 34 | Search for a Range | 27.50% | Medium |
| 33 | Search in Rotated Sorted Array | 28.80% | Hard |
| 32 | Longest Valid Parentheses | 20.90% | Hard |
| 31 | Next Permutation | 25.00% | Medium |
| 30 | Substring with Concatenation of All Words | 19.40% | Hard |
| 29 | Divide Two Integers | 15.00% | Medium |
| 28 | Implement strStr() | 22.20% | Easy |
| 27 | Remove Element | 32.10% | Easy |
| 26 | Remove Duplicates from Sorted Array | 31.30% | Easy |
| 25 | Reverse Nodes in k-Group | 25.50% | Hard |
| 24 | Swap Nodes in Pairs | 32.50% | Medium |
| 23 | Merge k Sorted Lists | 21.10% | Hard |
| 22 | Generate Parentheses | 32.60% | Medium |
| 21 | Merge Two Sorted Lists | 32.70% | Easy |
| 20 | Valid Parentheses | 26.50% | Easy |
| 19 | Remove Nth Node From End of List | 27.10% | Easy |
| 18 | 4Sum | 21.70% | Medium |
| 17 | Letter Combinations of a Phone Number | 25.80% | Medium |
| 16 | 3Sum Closest | 26.90% | Medium |
| 15 | 3Sum | 16.90% | Medium |
| 14 | Longest Common Prefix | 25.50% | Easy |
| 13 | Roman to Integer | 34.00% | Easy |
| 12 | Integer to Roman | 33.80% | Medium |
| 11 | Container With Most Water | 32.00% | Medium |
| 10 | Regular Expression Matching | 20.70% | Hard |
| 9 | Palindrome Number | 28.30% | Easy |
| 8 | String to Integer (atoi) | 13.00% | Easy |
| 7 | Reverse Integer | 25.10% | Easy |
| 6 | ZigZag Conversion | 21.80% | Easy |
| 5 | Longest Palindromic Substring | 20.70% | Medium |
| 4 | Median of Two Sorted Arrays | 17.40% | Hard |
| 3 | Longest Substring Without Repeating Characters | 20.60% | Medium |
| 2 | Add Two Numbers | 21.10% | Medium |
| 1 | Two Sum | 17.70% | Medium |
Welcome to follow my subscription account on Wechat, I will update the newest updated problem solution and explanation. And also welcome to add me as your wechat friend.

This app displays all practical coding problems from leetcode.com, and provids the solutions.

Not available anymore.
If you like this project and want to sponsor the author, you can reward the author using Wechat by scanning the following QR code.

Or you can also sponsor me by scanning the following Venmo QR code.

Special thanks to @notfresh to help extract the blog content in markdown format from my cnblogs.