flekschas / jupyter-scatter Goto Github PK
View Code? Open in Web Editor NEWInteractive 2D scatter plot widget for Jupyter Lab and Notebook. Scales to millions of points!
Home Page: https://jupyter-scatter.dev
License: Apache License 2.0
Interactive 2D scatter plot widget for Jupyter Lab and Notebook. Scales to millions of points!
Home Page: https://jupyter-scatter.dev
License: Apache License 2.0
When I pip install jscatter on my terminal I get this error
EdIT: found a way out of it [for now]
Currently, selected point are referenced by their index. E.g., scatter.selection([0, 1, 2]) selects the first three points of a dataframe. While this approach works fine, it'd be nice to reference points by some other column of the dataframe as well.
Imagine you want to synchronously explore two embeddings with shared point references but non-matching indices. E.g.:
# DataFrame A
| x | y | id |
| - | - | --- |
| 1 | 0 | 'a' |
| 1 | 1 | 'b' |
| 9 | 9 | 'c' |
# DataFrame B
| x | y | id |
| - | - | --- |
| 2 | 1 | 'c' |
| 5 | 0 | 'b' |
| 0 | 7 | 'a' |To synchronously explore the two datasets we'd have to tell jscatter to reference points by the id column
Add a new property (called point_id) and method (called id()) that can either be a string referencing a column in the data or an array_like list of point IDs.
Assuming we have the two data frames from above, with the new property/method we could synchronously explore the two dataset as follows:
from jscatter import Scatter, compose
config = dict(x='x', y='y', id='id')
jsc_a = Scatter(data=df_a, **config)
jsc_b = Scatter(data=df_b, **config)
compose([jsc_a, jsc_b], sync_selection=True, sync_hover=True)Assuming we select the first point in first scatter plot instance, calling jsc_b.selection() would return 'c' (the ID of the first point in data frame B).
@manzt What do you think of this idea?
I would like to use panels from jupyter-scatter as is for figures in a publication. Is it possible to export to png in high resolution?
(or maybe this is possible and I was just unable to find it)
In the applications I'm interested in the "rotation" tool is not really necessary, and I find it a little confusing in how it treats the axis ticks (they seem to change in some strange, not-data-based way). So it would be preferable to disable that tool from the interactive widget.
From reading the code I think this would be fairly simple, just an additional option that changes how mouse_mode_widget is created?
Thanks for developing this tool, it is very cool!
While investigating #104 I noticed that the x/y domain of the axes are incorrectly bound to x/y data domain instead of the x/y scale domain. This is a problem as it makes the axis show the data domain while the x/y scale function might have re-scaled the data.
For instance, in the following the x data domain is [-10, 10] and the y data domain is [-1, 1]. To render the points on a common range, e.g., [-10, 10], we would pass (-10, 10) to x_scale and y_scale. Internally, the data is normalized to [0, 1] using the scale functions. By default, jscatter uses a linear scale that maps [min, max] linearly to [0, 1] but here we enforce the mapping to be [-10, 10] to [0, 1]. Now the issue is that on the JS kernel, the x/y axis would use the pre-normalized data domain (i.e., [-10, 10] for x and [-1, 1] for y). But this is incorrect. The x/y axis should use the post-normalized data domain, i.e., [-10, 10] for both: x and y.
The code below leads to the following issue:
import jscatter
import numpy as np
import pandas as pd
df = pd.DataFrame({
"x": np.concatenate((np.linspace(start=-10, stop=10, num=50), np.linspace(start=-10, stop=10, num=50))),
"y": np.concatenate((np.linspace(start=-1, stop=1, num=50), np.linspace(start=1, stop=-1, num=50))),
})
min_max = (df[['x', 'y']].min().min(), df[['x', 'y']].max().max())
scatter = jscatter.Scatter(
data=df,
x="x",
y="y",
x_scale=min_max,
y_scale=min_max,
)
scatter.show()
The data is appropriated rendered at the common [-10, 10] range but the y axis reports [-0.1, 0.1]
By manually assigning the correct x/y domain, as follows, we get the correct y axis:
scatter = jscatter.Scatter(
data=df,
x="x",
y="y",
x_scale=common_scale,
y_scale=common_scale,
)
scatter.widget.x_domain = common_scale
scatter.widget.y_domain = common_scale
scatter.show()
It'd be nice to be able to show a legend explaining the color, opacity, or size encoding. We could likely use https://airbnb.io/visx/docs/legend for this.
API-wise I'm imagining this too look as follows
jscatter.Scatter(legend=True, legend_position='top-right')
# or
scatter.legend(True, position='top-right')We could support the following positions:
Since in some cases, the number of categories could be quite high (e.g., for cell embeddings with lots of cell types). There should be an option to show the legend in a separate widget.
Hi,
Tried to work with the library using the sample example in the tutorial.
I'm getting the following error:

I'm using anywidged=='0.9.3'
the problem seems to happen in jupyter notebook and not in jupyter lab
Thanks
My JupyterLab version is 3.1.12
I cannot seem to get the example code to work on my system. I get the error as follows -

import jscatter
import numpy as np
# Just some random float and int values
data = np.random.rand(500, 4)
tf = pd.DataFrame(data, columns=['mass', 'speed', 'pval', 'group'])
# We'll convert the `group` column to strings to ensure it's recognized as
# categorical data. This will come in handy in the advanced example.
tf['group'] = tf['group'].map(lambda c: chr(65 + round(c)), na_action=None)
jscatter.plot(data=tf, x='mass', y='speed')Error displaying widget: model not found
When exporting a notebook to HTML via the following snippet, the resulting HTML file properly renders the scatter plot instance and data but the view, selection, and hover linking do not work as they currently require a Python kernel. However, this is not necessary. By using jslink() we can ensure that the linking works with and without a Python kernel. Therefore, we should switch jslink() over observe().
jupyter nbconvert --execute --to html notebooks/get-started.ipynbI want to hand this over to non-technical users, and stitch it together with a few python workflows.
What's my best option for this? Should I try to productionise the jupyter notebook as a web app?
Could I embed it in anything else?
This is work in progress but I want to document it somewhere:
After discussions with @nvictus I am thinking to change the Python API of plot() to be more intuitive and support dataframes out of the box. The API is inspired by https://seaborn.pydata.org/generated/seaborn.scatterplot.html
jscatter.plot(
x = str or ndarray,
y = str or ndarray,
# Optional:
data = dataframe, # a dataframe
color = str or ndarray, # a single color
color_by = str or ndarray, # color encoding
color_norm = tuple or matplotlib.colors.Normalize, # normalization strategy for color_by
color_order = list, # in case of categorical color encoding this specifies the color order
color_map = list or ndarray, # a list of colors to map color_by to
size = int or float, # a single point size
size_by = str or ndarray, # size encoding
size_norm = tuple or matplotlib.colors.Normalize, # normalization strategy for size_by
size_order = list, # in case of categorical size encoding this specifies the size order
size_map = list or ndarray, # a list of size to map size_by to
connect_by = str or ndarray, # a categorical
connect_order = str or ndarray, # order in which the points are to be connected
opacity = float or str, # a static opacity value that overrides the color's alpha value or 'auto'
)Would love to be able to download the HTML & Javascript the same way you can with bokeh. This way I can use the visualizations on my website!
I use VSCode when developing and running jupyter notebooks. However, I'm not able to get jupyter-scatter plots to display here. They do work when running a jupyter notebook in the browser. I have not tested jupyterlab functionality.
Here's a small reproducible test case:
from IPython.display import display
import jscatter
import numpy as np
x = np.random.randn(100)
y = np.random.randn(100)
fig = jscatter.Scatter(x, y)
fig.show()
This will return an empty cell. When printing the fig variable, it seems to have been created properly, but does not display. print(fig.show()) produces:
HBox(children=(VBox(children=(Button(button_style='primary', icon='arrows', layout=Layout(width='36px'), style=ButtonStyle(), tooltip='Activate pan & zoom'), Button(icon='....
To verify that ipywidgets still work, I made and displayed the following simple widget. This worked as expected.
import ipywidgets
out = ipywidgets.Dropdown(options=['1', '2', '3'], value='2', description='Number')
display(out)
When I try the tool, I keep hitting this error.
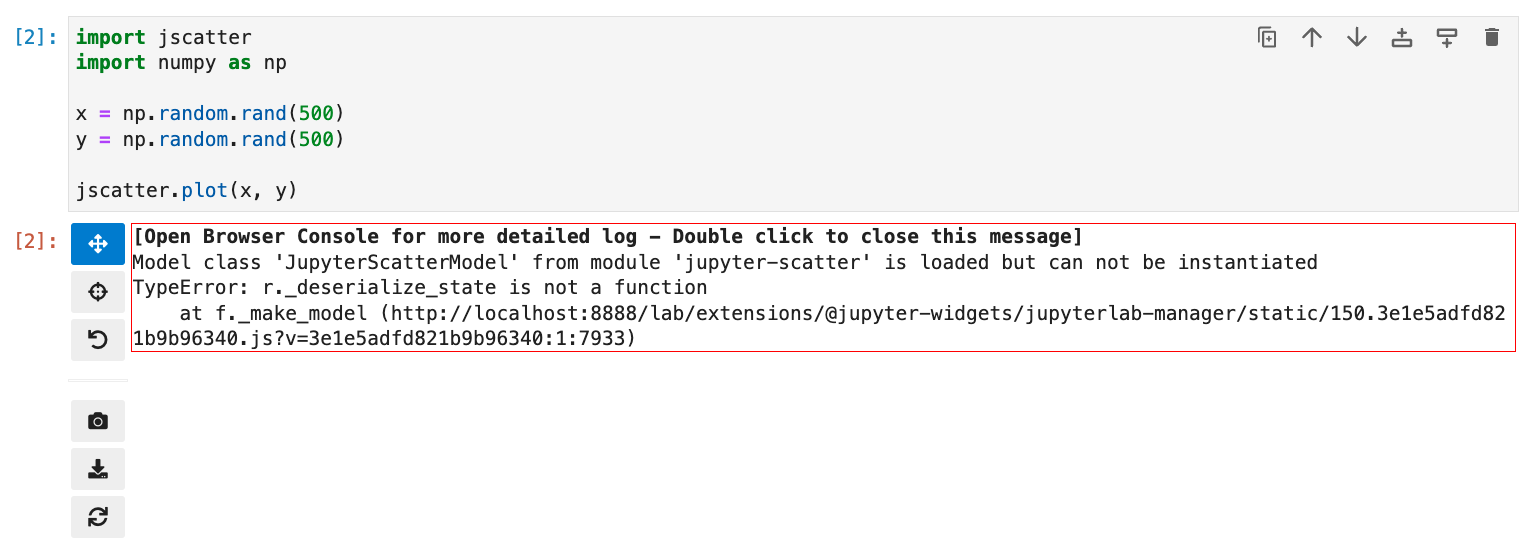
[Open Browser Console for more detailed log - Double click to close this message]
Model class 'JupyterScatterModel' from module 'jupyter-scatter' is loaded but can not be instantiated
TypeError: r._deserialize_state is not a function
at f._make_model (http://localhost:8888/lab/extensions/@jupyter-widgets/jupyterlab-manager/static/150.3e1e5adfd821b9b96340.js?v=3e1e5adfd821b9b96340:1:7933)
Any idea what might cause it? Here are my versions:
jupyter-scatter==0.7.1
jupyterlab==3.4.8
I'm running Python 3.9.9, should that be relevant.
After upgrading to jupyter-scatter==0.10.0 JupyterLab prints the following error:
Error displaying widget: model not found
Rolling back to jupyter-scatter==0.9.0 fixes the issue.
I'm using JupyterLab 3.4.8, jupyterlab_widgets 1.1.1, ipywidgets 7.7.2
https://github.com/flekschas/jupyter-scatter/blob/main/jscatter/jscatter.py#L148 link leads to nowhere
The ability to overlay text layers for labelling / annotation would be very useful. Some examples include in ThisNotThat (see the plot at the bottom of this page) or Atlas from Nomic eg this example. Looking through the regl-scatterplot examples it looks like this is relatively tractable. Some questions remain as to the exact API that would work well.
Javascript is not a language I know well, but I would be willing to try and get a version working and try to make a PR if you feel like this would be a useful addition. I'm also happy to discuss options on what the API/options exposed on the python end should be.
You have an idea how to enhance Jupyter Scatter? That's awesome!
Before you file your idea, please:
You are encouraged to prototype multiple alternative APIs or implementation approaches for your proposed feature. Doing so often leads to a better solution.
Hi!
Thanks a lot for this great widget!
I wanted to as whether it's currently possible to use different symbols in the scatter plot based on the values of a column of the dataframe or not. A bit like the symbol option in plotly (https://plotly.com/python-api-reference/generated/plotly.express.scatter.html).
I couldn't find anything in the documentation, hence I'm wondering whether there's some workaround or the feature simply does not exist at the moment.
Thanks!
I would like to ensure that the x and y axis are scaled such that data is shown with equal aspect ratio (similar to matplotlib: ax.set_aspect('equal'). I thought of using the width() and height() function to figure out the dimensions of the scatter widget and use that for scaling. However, width() return auto, and I am not sure I am on the right track.
Follow up to #96. We could reuse the categorical colormap in the tooltip to color the stacked barchart.
Do the categorical bars use any color encoding? Maybe for a second PR, but I wonder for the case where you are coloring by a category we could (re)use the cmap here.
Originally posted by @manzt in #96 (comment)
It appears that jupyter-scatter is not working with jupyter-widgets v2 and/or v3. This is probably due to not bumping the version of @jupyter-widgets/base to accept v5 and v6. These jupyter versions are a complete mess...
This looks really excellent.
I want to be able to label an image dataset from a 2d UMAP of its embeddings, but keep struggling to find frameworks that reliably support this. Something like
plot.selected_ids
Is that possible with this framework?
Note how the size map is reversed in the two examples below. The scatter plot reflects this change. However, the size legend is identical in both cases!
import jscatter
import numpy as np
import pandas as pd
data = np.random.rand(500, 4)
df = pd.DataFrame(data, columns=['mass', 'speed', 'pval', 'group'])
df['group'] = df['group'].map(lambda c: chr(65 + round(c)), na_action=None)
sc = jscatter.Scatter(data=df, x='mass', y='speed', legend=True)
sc.size(by='pval', norm=[0, 1], map=[2, 4, 6, 8, 10], order='reverse')
sc.show()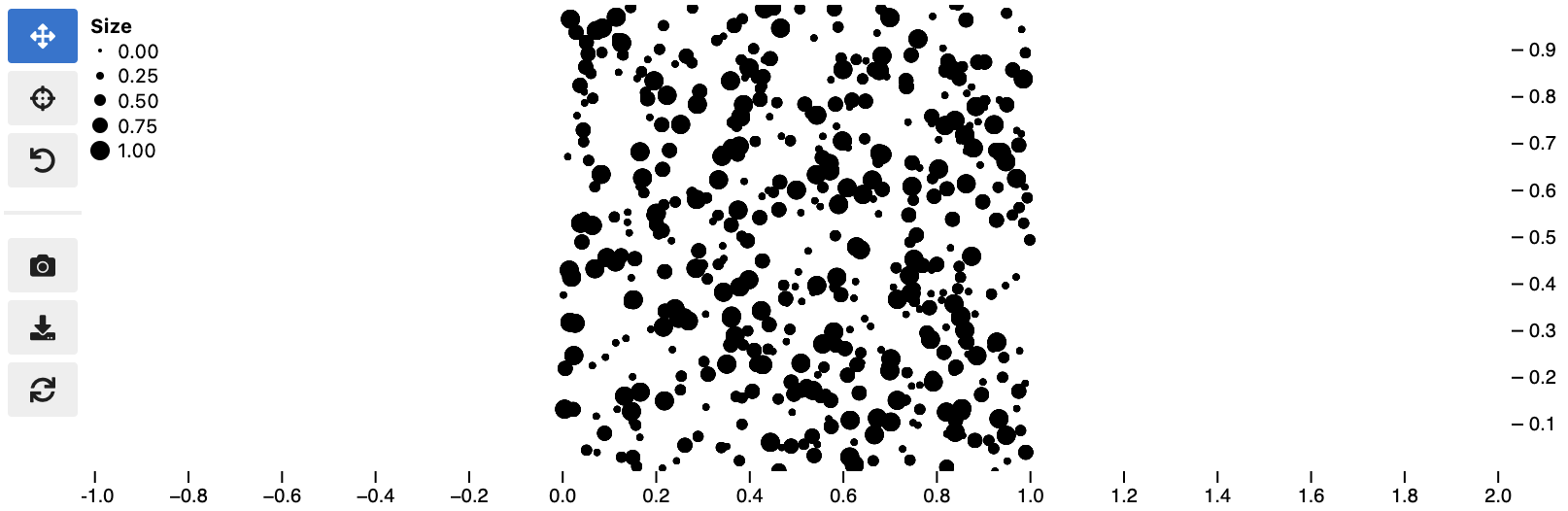
sc2 = jscatter.Scatter(data=df, x='mass', y='speed', legend=True)
sc2.size(by='pval', norm=[0, 1], map=[2, 4, 6, 8, 10])
sc2.show()
Let's say I have this data frame:
data = pd.DataFrame({
"x": [1, 2, 3],
"y": [8, 3, 0],
"color": [0, 0, 1],
})
dataAccording to the documentation (and this indirect clue), the opacity_by property should be settable like this:
ppp = Scatter(
data=data,
x="x",
y="y",
color_by="color",
color_map=glasbey_light,
size=10,
opacity_by=[1, 1, 0],
opacity_map=(.25, 1, 2)
)However, this raises a TypeError with the following traceback:
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[28], line 1
----> 1 ppp = Scatter(
2 data=data,
3 x="x",
4 y="y",
5 color_by="color",
6 color_map=glasbey_light,
7 size=10,
8 opacity_by=[1, 1, 0],
9 opacity_map=(.25, 1, 2)
10 )
11 ppp.show()
File ~/cloud-label-propagation/.conda-env/lib/python3.11/site-packages/jscatter/jscatter.py:284, in Scatter.__init__(self, x, y, data, **kwargs)
271 self.selection(
272 kwargs.get('selection', UNDEF),
273 )
274 self.color(
275 kwargs.get('color', UNDEF),
276 kwargs.get('color_selected', UNDEF),
(...)
282 kwargs.get('color_labeling', UNDEF),
283 )
--> 284 self.opacity(
285 kwargs.get('opacity', UNDEF),
286 kwargs.get('opacity_unselected', UNDEF),
287 kwargs.get('opacity_by', UNDEF),
288 kwargs.get('opacity_map', UNDEF),
289 kwargs.get('opacity_norm', UNDEF),
290 kwargs.get('opacity_order', UNDEF),
291 kwargs.get('opacity_labeling', UNDEF),
292 )
293 self.size(
294 kwargs.get('size', UNDEF),
295 kwargs.get('size_by', UNDEF),
(...)
299 kwargs.get('size_labeling', UNDEF),
300 )
301 self.connect(
302 kwargs.get('connect_by', UNDEF),
303 kwargs.get('connect_order', UNDEF)
304 )
File ~/cloud-label-propagation/.conda-env/lib/python3.11/site-packages/jscatter/jscatter.py:1220, in Scatter.opacity(self, default, unselected, by, map, norm, order, labeling, **kwargs)
1217 self._encodings.delete('opacity')
1219 else:
-> 1220 self._encodings.set('opacity', by)
1222 component = self._encodings.data[by].component
1223 try:
File ~/cloud-label-propagation/.conda-env/lib/python3.11/site-packages/jscatter/encodings.py:124, in Encodings.set(self, channel, dimension)
121 if self.is_unique(channel):
122 self.delete(channel)
--> 124 if dimension not in self.data:
125 assert not self.components.full, f'Only {self.max} data encodings are supported'
126 # The first value specifies the component
127 # The second value
TypeError: unhashable type: 'list'
(Fortunately, setting opacity_by as a field of the data frame works as expected.)
Is the documentation wrong, and all data associated to the scatter points expected to be sourced out of the data frame? Or is this a bug?
I can think of three ways to activate axes labels:
Using the column names of the dataframe (this would only if the user passing in the dataframe via data)
scatter.axes(True, labels=True)Using custom labels
scatter.axes(True, labels=['x', 'y'])
scatter.axes(True, labels=dict(x='x', y='y'))The ability to visualize large amounts of embeddings in 2D was missing from the Python ecosystem for awhile. Thank you so much for making this - it will really improve a lot of downstream functionality related to NLP/CV visualizations.
When I pip install jscatter and then cd into the directory and jupyter lab, and then run the code
``import jscatter
import numpy as np
x = np.random.rand(500)
y = np.random.rand(500)
jscatter.plot(x, y)
I get the error "JupyterScatter' object has no attribute 'hovered_point' #115"
same issue on https://colab.research.google.com/drive/195z6h6LsYpC25IIB3fSZIVUbqVlhtnQo?usp=sharing#scrollTo=fhBnK0fHzIe6
Hi, thanks so much for developing this wonderful package! It's been extremely helpful, and I'd like to report some bug that I encountered.
I often find the tick label value is different from what I get from the selection. Moreover, the tick label value is not properly adjusted as I zoom in and out.
For example, the following point which should be close to (0, 0) would move further from the origin when I zoomed out.


I'm using the following code to generate above plot.
# scatterplot
scatter = jscatter.Scatter(data=plot_df, x='A', y='B', color_by="group",
width=500, height=500, opacity=0.5)
# output area to display dataframe
out = widgets.Output()
# handler for when "selection" changes from scatterplot
def on_change(change):
out.clear_output()
with out:
indicies = change["new"]
subset = plot_df.iloc[indicies]
display(subset)
# add change handler to scatterplot widget.
# `on_change` runs every time the `scatterplot.widget.selection` changes
scatter.size(by='rate', norm=(-0.2, 1))
scatter.color(map = {"NegCtrl":"grey", "PosCtrl_inc":"red",
"PosCtrl_dec":"blue", "Variant":"green"})
scatter.widget.observe(on_change, names='selection')
scatter.axes(True, True, labels=True)
scatter.legend(True, position='top-left')
display(scatter.show(), out)
As pointed out by @manzt, it'd be nice to allow filtering out points. Currently, this requires re-initializing the scatter plot instance. However, re-initialization will reset the current camera position etc. which is annoying.
I am proposing a new method for dynamic filtering:
scatter = Scatter(data=df, x='x', y='y')
scatter.filter([1,2,3]) # only show points 1, 2, and 3@manzt What do yo think of this?
I tried the initial example:
import jscatter
x = np.random.rand(500)
y = np.random.rand(500)
jscatter.plot(x, y)This is what it looks like

After clicking on box:

The text reads:
[Open Browser Console for more detailed log - Double click to close this message]
Failed to load model class 'JupyterScatterModel' from module 'jupyter-scatter'
Error: No version of module jupyter-scatter is registered
at f.loadClass (http://fry:8888/lab/extensions/@jupyter-widgets/jupyterlab-manager/static/134.402424ef4079078b2e0e.js?v=402424ef4079078b2e0e:1:74855)
at f.loadModelClass (http://fry:8888/lab/extensions/@jupyter-widgets/jupyterlab-manager/static/150.1a6d6a3a0542a41bec5a.js?v=1a6d6a3a0542a41bec5a:1:10729)
at f._make_model (http://fry:8888/lab/extensions/@jupyter-widgets/jupyterlab-manager/static/150.1a6d6a3a0542a41bec5a.js?v=1a6d6a3a0542a41bec5a:1:7517)
at f.new_model (http://fry:8888/lab/extensions/@jupyter-widgets/jupyterlab-manager/static/150.1a6d6a3a0542a41bec5a.js?v=1a6d6a3a0542a41bec5a:1:5137)
at f.handle_comm_open (http://fry:8888/lab/extensions/@jupyter-widgets/jupyterlab-manager/static/150.1a6d6a3a0542a41bec5a.js?v=1a6d6a3a0542a41bec5a:1:3894)
at _handleCommOpen (http://fry:8888/lab/extensions/@jupyter-widgets/jupyterlab-manager/static/134.402424ef4079078b2e0e.js?v=402424ef4079078b2e0e:1:73392)
at y._handleCommOpen (http://fry:8888/static/lab/jlab_core.f68a597bc4700114bad4.js?v=f68a597bc4700114bad4:1:1233317)
at async y._handleMessage (http://fry:8888/static/lab/jlab_core.f68a597bc4700114bad4.js?v=f68a597bc4700114bad4:1:1235307)
Here are my package versions:
name : jupyter-scatter
version : 0.12.4
description : A scatter plot extension for Jupyter Notebook and Lab
dependencies
- ipython *
- ipywidgets >=7.6,<9
- jupyter-packaging *
- jupyterlab-widgets >=1.0,<4
- matplotlib *
- numpy *
- pandas *
- traittypes >=0.2.1
- typing-extensions *
name : jupyter
version : 1.0.0
description : Jupyter metapackage. Install all the Jupyter components in one go.
dependencies
- ipykernel *
- ipywidgets *
- jupyter-console *
- nbconvert *
- notebook *
- qtconsole *
name : jupyterlab
version : 4.0.2
description : JupyterLab computational environment
dependencies
- async-lru >=1.0.0
- importlib-metadata >=4.8.3
- ipykernel *
- jinja2 >=3.0.3
- jupyter-core *
- jupyter-lsp >=2.0.0
- jupyter-server >=2.4.0,<3
- jupyterlab-server >=2.19.0,<3
- notebook-shim >=0.2
- packaging *
- tomli *
- tornado >=6.2.0
- traitlets *
jupyter server --version #2.6.0
As a suggestion: think about integrating into streamlit.
I previously used notebooks for scrnaseq and a bit for flow cytometry, but that's too problematic to share with bio folks.
Streamlit provides a better ground for 'shareable interactive visualization'. I currently use a streamlit component based on plotly (it is very scalable too, and provides just selections), but linked plots are much more responsive than my current solution.
Hi, any plans to xpose setLassoLongPressTime to python? I think the current timeout of 750 ms is way too long and would want it to be much shorter.
Also it seems like the animation has changed? Now it's a circle arc increasing in angle, before it was a circle increasing in size. Any reason why it was changed?
Thanks!
I found the linked plots does not supply the .selection() method. How can I get the selected points?
given result=jscatter.link(list_of_scatters, );result, I tried result.children[0].selection() but failed
I couldn't get the scatter_instace.selection() to work with the fresh install of jupyter-scatter (tried different browsers) ...
It looks like the issue is on the javascript side :

Could you help me debug it ?
here is an output of pip freeze just in case:
aiofiles==22.1.0
aiosqlite==0.18.0
anyio==3.6.2
argon2-cffi==21.3.0
argon2-cffi-bindings==21.2.0
arrow==1.2.3
asttokens==2.2.1
attrs==22.2.0
Babel==2.12.1
backcall==0.2.0
beautifulsoup4==4.12.2
bleach==6.0.0
certifi==2022.12.7
cffi==1.15.1
charset-normalizer==3.1.0
comm==0.1.3
contourpy @ file:///home/conda/feedstock_root/build_artifacts/contourpy_1673633659350/work
cycler @ file:///home/conda/feedstock_root/build_artifacts/cycler_1635519461629/work
debugpy==1.6.7
decorator==5.1.1
defusedxml==0.7.1
deprecation==2.1.0
executing==1.2.0
fastjsonschema==2.16.3
fonttools @ file:///home/conda/feedstock_root/build_artifacts/fonttools_1680021155848/work
fqdn==1.5.1
idna==3.4
importlib-metadata==6.3.0
importlib-resources @ file:///home/conda/feedstock_root/build_artifacts/importlib_resources_1676919000169/work
ipykernel==6.22.0
ipython==8.12.0
ipython-genutils==0.2.0
ipywidgets==8.0.6
isoduration==20.11.0
jedi==0.18.2
Jinja2==3.1.2
json5==0.9.11
jsonpointer==2.3
jsonschema==4.17.3
jupyter-events==0.6.3
jupyter-scatter==0.11.0
jupyter-ydoc==0.2.4
jupyter_client==8.1.0
jupyter_core==5.3.0
jupyter_packaging==0.12.3
jupyter_server==2.5.0
jupyter_server_fileid==0.9.0
jupyter_server_terminals==0.4.4
jupyter_server_ydoc==0.8.0
jupyterlab==3.6.3
jupyterlab-pygments==0.2.2
jupyterlab-widgets==3.0.7
jupyterlab_server==2.22.0
kiwisolver @ file:///home/conda/feedstock_root/build_artifacts/kiwisolver_1666805784128/work
MarkupSafe==2.1.2
matplotlib @ file:///home/conda/feedstock_root/build_artifacts/matplotlib-suite_1678135567769/work
matplotlib-inline==0.1.6
mistune==2.0.5
munkres==1.1.4
nbclassic==0.5.5
nbclient==0.7.3
nbconvert==7.3.1
nbformat==5.8.0
nest-asyncio==1.5.6
notebook==6.5.4
notebook_shim==0.2.2
numpy @ file:///home/conda/feedstock_root/build_artifacts/numpy_1675642561072/work
packaging @ file:///home/conda/feedstock_root/build_artifacts/packaging_1673482170163/work
pandas==2.0.0
pandocfilters==1.5.0
parso==0.8.3
pexpect==4.8.0
pickleshare==0.7.5
Pillow @ file:///home/conda/feedstock_root/build_artifacts/pillow_1675487166627/work
platformdirs==3.2.0
prometheus-client==0.16.0
prompt-toolkit==3.0.38
psutil==5.9.4
ptyprocess==0.7.0
pure-eval==0.2.2
pyarrow==10.0.1
pycparser==2.21
Pygments==2.15.0
pyparsing @ file:///home/conda/feedstock_root/build_artifacts/pyparsing_1652235407899/work
PyQt5==5.12.3
PyQt5_sip==4.19.18
PyQtChart==5.12
PyQtWebEngine==5.12.1
pyrsistent==0.19.3
python-dateutil @ file:///home/conda/feedstock_root/build_artifacts/python-dateutil_1626286286081/work
python-json-logger==2.0.7
pytz @ file:///home/conda/feedstock_root/build_artifacts/pytz_1680088766131/work
PyYAML==6.0
pyzmq==25.0.2
requests==2.28.2
rfc3339-validator==0.1.4
rfc3986-validator==0.1.1
Send2Trash==1.8.0
six @ file:///home/conda/feedstock_root/build_artifacts/six_1620240208055/work
sniffio==1.3.0
soupsieve==2.4
stack-data==0.6.2
terminado==0.17.1
tinycss2==1.2.1
tomli==2.0.1
tomlkit==0.11.7
tornado @ file:///home/conda/feedstock_root/build_artifacts/tornado_1666788587690/work
traitlets==5.9.0
traittypes==0.2.1
typing_extensions==4.5.0
tzdata @ file:///home/conda/feedstock_root/build_artifacts/python-tzdata_1680081134351/work
unicodedata2 @ file:///home/conda/feedstock_root/build_artifacts/unicodedata2_1667239485250/work
uri-template==1.2.0
urllib3==1.26.15
wcwidth==0.2.6
webcolors==1.13
webencodings==0.5.1
websocket-client==1.5.1
widgetsnbextension==4.0.7
y-py==0.5.9
ypy-websocket==0.8.2
zipp @ file:///home/conda/feedstock_root/build_artifacts/zipp_1677313463193/work
After #11, we use traittypes.Array to annotate JupyterScatter.points and JupyterScatter.selection.
However, traittypes.Array is valid for any numpy array and the shape/dtype for points and selection are more strict. We should add custom validators for these attributes, which will raise an exception if an array of the wrong shape/dtype is assigned on the python side.
This isn't urgent, since jscatter.Scatter for the most part ensures the data are correct, but this would probably help with tracking down weird bugs of where dtypes aren't what are expected.
When I use the widget in colab, I get this warning
/usr/local/lib/python3.10/dist-packages/anywidget/_util.py:201: UserWarning: anywidget: Live-reloading feature is disabled. To enable, please install the 'watchfiles' package.
start_thread=_should_start_thread(maybe_path),
Code
import jscatter
import numpy as np
x = np.random.rand(500)
y = np.random.rand(500)
jscatter.plot(x, y)
For continuous encodings, the legend's value labels order the minimum to maximum value labels from top to bottom, which is opposite of what one would except (top = high and bottom = low)
See this minimally modified example from get-started:

See how the axis of the right scatter plot does not update as I zoom the left scatter plot and vice versa:
As I was investigating #104 I noticed that the options argument, which allows setting any regl-scatterplot option, isn't used during the creation of a Scatter instance.
For instance, the following does not work
scatter = jscatter.Scatter(data=df, x="x", y="y", options={"aspectRatio": 2})
scatter.widget.other_options = {"aspectRatio": 2}
scatter.show()Instead one has to update the options after initializing the Scatter instance as follows:
scatter = jscatter.Scatter(data=df, x="x", y="y")
scatter.widget.other_options = {"aspectRatio": 2} # this circumvents the issue
scatter.show()Investigating #107, I noticed that upon resizing the cell, the x axis wouldn't properly update.
As you can see in the video, the left most point, which is located at x equals -10 appears to be located at -20 after the resize. (Also noticed how zooming even just a tiny bit at the end properly re-renders the x axis. This indicates that the resize-related axis updater isn't updating the axis scale correctly.)
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.