![]()
![]()

A picture of the car along with it's POV
This project builds on top of the NVIDIA Jetracer project to instrument it with Weights&Biases, making it easier to train, evaluate and refine models.
It features a full pipeline to effortlessly collect_data, label it, train/optimize models and finally drive the car while monitoring how the model is doing.
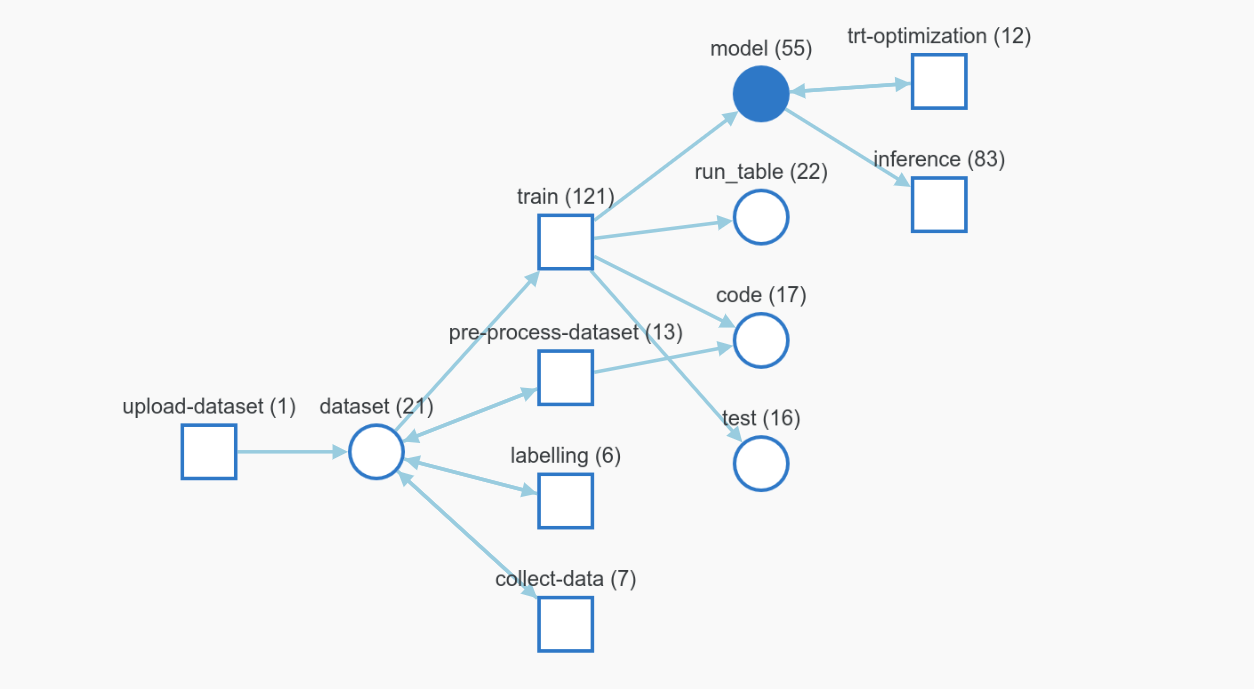
Weights&Biases Artifacts' graph showing the whole pipeline.
The repo is meant to be used by running (and modifying!) scripts under src/wandb_jetracer/scripts. These allow to train a model to detect the center of the racetrack which we can then feed to a control policy to drive the car.
collect_data.pywill take pictures using the car's camera and upload them to Weights&Biases. It should be ran while manually driving the car around.label.pyis a labelling utiliy. It will download the images from the previous step to a computer to annotate them with the relevant labels. The labels will then be added to the dataset stored on Weights&Biases servers.wandb_jetracer_training.ipynbis used to download the same dataset, train a model and upload it's weights to WandB.trt_optimis meant to be ran on the car. It will convert the latest trained model to TensorRT for inference.drive.pywill take the optimized model and use it to drive the car. It will also log sensor data (IMU, Camera), system metrics (jetson stats, inference time) as well as the control signal to WandB. This helps with monitoring the model's perfomances in production.
Check out NVIDIA Jetracer.
These scripts are ran on three different types of machine: the actual embedded jetson nano computer on the car, a machine used for labelling and a colab instance used for training.
They all relie on different dependencies:
- Training dependencies are installed in the Colab notebook so you don't need to worry about those.
- Labelling dependencies can be installed in a conda env using
conda create -f labelling_env.yml - Dependencies for the car are slightly trickier to get right, you'll find instructions here. Feel free to open issues if you run into troubles!
Even though default throttle values are set in the scripts under /src/scripts I would recommend testing those while the car is on a stand and it's wheels are not touching the ground. Depending on how your ESC was calibrated a throttle value of 0.0002 might mean going full reverse and your car might fly off into a wall.
After installing the labelling dependencies run pytest
Feel free to open GitHub issues if you have any questions!










