A C++ library for parallel graph processing
![]()
libgrape-lite is a C++ library from Alibaba for parallel graph processing. It differs from prior systems in its ability to parallelize sequential graph algorithms as a whole by following the PIE programming model from GRAPE. Sequential algorithms can be easily "plugged into" libgrape-lite with only minor changes and get parallelized to handle large graphs efficiently. In addition to the ease of programming, libgrape-lite is designed to be highly efficient and flexible, to cope the scale, variety and complexity from real-life graph applications.
libgrape-lite is developed and tested on CentOS 7. It should also work on other unix-like distributions. Building libgrape-lite requires the following softwares installed as dependencies.
- CMake (>=2.8)
- A modern C++ compiler compliant with C++-11 standard. (g++ >= 4.8.1 or clang++ >= 3.3)
- MPICH (>= 2.1.4) or OpenMPI (>= 3.0.0)
- glog (>= 0.3.4)
Here are the dependencies for optional features:
- jemalloc (>= 5.0.0) for better memory allocation;
- Doxygen (>= 1.8) for generating documentation;
- Linux HUGE_PAGES support, for better performance.
- CUDA (>= 10.0) for GPU-based graph processing.
- NCCL (>= 2.7) for multi-GPU communication.
Extra dependencies are required by examples:
- gflags (>= 2.2.0);
- Apache Kafka (>= 2.3.0);
- librdkafka(>= 0.11.3);
Once the required dependencies have been installed, go to the root directory of libgrape-lite and do a out-of-source build using CMake.
mkdir build && cd build
cmake ..
make -jThe building targets include a shared/static library, and two sets of examples: analytical_apps and a gnn_sampler.
Alternatively, you can build a particular target with command:
make libgrape-lite # or
make analytical_apps # or
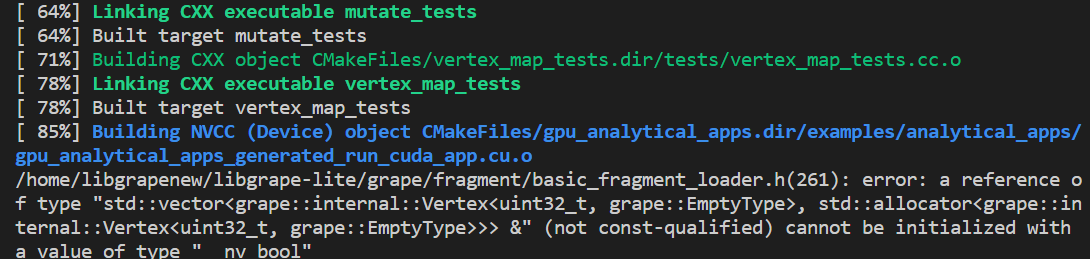
make gnn_samplerlibgrape-lite supports deploying graph algorithms to GPUs. When CUDA is detected on the machine and NCCL >= 2.7, GPU support will be enabled automatically.
The input of libgrape-lite is formatted following the LDBC Graph Analytics benchmark, with two files for each graph, a .v file for vertices with 1 or 2 columns, which are a vertex_id and optionally followed by the data assigned to the vertex; and a .e file for edges with 2 or 3 columns, representing source, destination and optionally the data on the edge, correspondingly. See sample files p2p-31.v and p2p-31.e under the dataset directory.
libgrape-lite provides six algorithms from the LDBC benchmark as examples. The deterministic algorithms are, single-source shortest path(SSSP), connected component(WCC), PageRank, local clustering coefficient(LCC), community detection of label propagation(CDLP), and breadth first search(BFS).
To run a specific analytical application, users may use command like this:
# run single-source shortest path with 4 workers in local.
mpirun -n 4 ./run_app --vfile ../dataset/p2p-31.v --efile ../dataset/p2p-31.e --application sssp --sssp_source 6 --out_prefix ./output_sssp --directed
# or run connected component with 4 workers on a cluster.
# HOSTFILE provides a list of hosts where MPI processes are launched.
mpirun -n 4 -hostfile HOSTFILE ./run_app --application=wcc --vfile ../dataset/p2p-31.v --efile ../dataset/p2p-31.e --out_prefix ./output_wcc
# or run breadth-first search with 8 workers in a multi-GPU server.
mpirun -n 8 ./run_cuda_app --application=bfs --lb=cm --bfs_source 6 --vfile ../dataset/p2p-31.v --efile ../dataset/p2p-31.e --out_prefix ./output_wcc
# see more flags info.
./run_app --helpThe analytical applications support the LDBC Analytical Benchmark suite with the provided ldbc_driver. Please refer to ldbc_driver for more details. The benchmark results for libgrape-lite and other state-of-the-art systems could be found here.
In addition to offline graph analytics, libgrape-lite could also be utilized to handle more complex graph tasks. A sampler for GNN training/inference on dynamic graphs (taking graph changes and queries, and producing results via Kafka) is included as an example. Please refer to examples/gnn_sampler for more details.
libgrape-lite also supports graph analytics on multi-GPU servers. Unlike CPUs, GPUs have more-but-weaker cores, making load balancing the key to high-performance sparse graph processing on GPUs. libgrape-lite provides multiple load balancing strategies on GPUs (wm, cm, cta, and strict). libgrape-lite adopts NCCL to handle communication between multiple GPUs. With GPU acceleration, libgrape-lite can obtain similar performance for a 4-node CPU cluster with a single GPU. The detailed benchmark results of libgrape-lite on GPUs could also be found here.
Documentation is generated using Doxygen. Users can build doxygen documentation in the build directory using:
cd build
make doc
# open docs/index.htmlThe latest version of online documentation can be found at https://alibaba.github.io/libgrape-lite
libgrape-lite is distributed under Apache License 2.0. Please note that third-party libraries may not have the same license as libgrape-lite.
- flat_hash_map, an efficient hashmap implementation;
- granula, a tool for gathering performance information for LDBC Benchmark;
- xoroshiro, a pseudo-random number generator;
- threadpool, a concise C++11 Thread Pool implementation.
-
Wenfei Fan, Jingbo Xu, Wenyuan Yu, Jingren Zhou, Xiaojian Luo, Ping Lu, Qiang Yin, Yang Cao, and Ruiqi Xu. Parallelizing Sequential Graph Computations. ACM Transactions on Database Systems (TODS) 43(4): 18:1-18:39.
-
Wenfei Fan, Jingbo Xu, Yinghui Wu, Wenyuan Yu, Jiaxin Jiang. GRAPE: Parallelizing Sequential Graph Computations. The 43rd International Conference on Very Large Data Bases (VLDB), demo, 2017 (the Best Demo Award).
-
Wenfei Fan, Jingbo Xu, Yinghui Wu, Wenyuan Yu, Jiaxin Jiang, Zeyu Zheng, Bohan Zhang, Yang Cao, and Chao Tian. Parallelizing Sequential Graph Computations, ACM SIG Conference on Management of Data (SIGMOD), 2017 (the Best Paper Award).
Please cite the following paper in your publications if GRAPE or this repo helps your research.
@inproceedings{10.1145/3035918.3035942,
author = {Fan, Wenfei and Xu, Jingbo and Wu, Yinghui and Yu, Wenyuan and Jiang, Jiaxin and Zheng, Zeyu and Zhang, Bohan and Cao, Yang and Tian, Chao},
title = {Parallelizing Sequential Graph Computations},
year = {2017},
isbn = {9781450341974},
publisher = {Association for Computing Machinery},
url = {https://doi.org/10.1145/3035918.3035942},
doi = {10.1145/3035918.3035942},
booktitle = {Proceedings of the 2017 ACM International Conference on Management of Data},
pages = {495–510},
numpages = {16},
location = {Chicago, Illinois, USA},
series = {SIGMOD '17}
}- Read contribution guide.
- Join in the Slack channel
- Please report bugs by submitting a GitHub issue.
- Submit contributions using pull requests.
Thank you in advance for your contributions!