zzzmj / duola-blog Goto Github PK
View Code? Open in Web Editor NEW哆啦的博客
哆啦的博客


想学会react-redux,得先清楚几个概念
在Redux框架下,一个React组件基本上就是要承担两个任务
和Redux打交道,读取Store的状态,用于初始化组件状态。
同时还要监听Store的状态改变
当需要更新Store状态时,就要派发Action对象
Store状态发生改变时,就需要更新组件状态
根据当前props和state,渲染出用户界面
如果每个React组件都要包办这两个任务,似乎事情稍微多了一些。
所以考虑拆分成两个组件,分别承担一个任务
承担第一个任务的叫做容器组件,负责与Redux打交道(也叫聪明组件)
承担第二个任务的叫做傻瓜组件,负责渲染界面(也叫展示组件)
傻瓜组件是一个纯函数,根据容器组件传进来的props产生结果,因此它也是一个无状态组件
状态全交给容器组件打理
改写Counter
class Counter extends Component {
render() {
const { caption, onClickDecrementButton, onClickIncrementButton, value } = this.props
return (
<div>
<button style={style} onClick={onClickIncrementButton} >+</button>
<button style={style} onClick={onClickDecrementButton} >-</button>
<span>{caption} count: {value}</span>
</div>
)
}
}可以把傻瓜组件写成无状态组件,获取props就不能用this.props,而是通过函数的
参数props获得
const Counter = (props) => {
const { caption, onClickDecrementButton, onClickIncrementButton, value } = props
return (
<div>
<button style={style} onClick={onClickIncrementButton} >+</button>
<button style={style} onClick={onClickDecrementButton} >-</button>
<span>{caption} count: {value}</span>
</div>
)
}容器组件承担了所有的和Store关联的工作,它的Render函数只负责渲染傻瓜组件Counter,传递必要的prop
import store from '../Store.js';
class CounterContainer extends Component {
constructor(props) {
super(props)
this.state = this.getOwnState()
this.onClickIncrementButton = this.onClickIncrementButton.bind(this)
this.onClickDecrementButton = this.onClickDecrementButton.bind(this)
this.onChange = this.onChange.bind(this)
}
shouldComponentUpdate(nextProps, nextState) {
// 避免不必要的渲染
return (nextProps.caption !== this.props.caption) ||
(nextState.value !== this.state.value);
}
componentDidMount() {
// 通过store.subscribe()监听组件变化,只要组件的状态变化,就会调用onChange方法
store.subscribe(this.onChange)
}
componentWillUnmount() {
// 组件删除后,注销监听
store.unsubscribe(this.onChange)
}
getOwnState() {
return {
value: store.getState()[this.props.caption]
}
}
onChange() {
const newState = this.getOwnState()
this.setState(newState)
}
onClickIncrementButton() {
store.dispatch(Actions.increment(this.props.caption))
}
onClickDecrementButton() {
store.dispatch(Actions.decrement(this.props.caption))
}
render() {
return (
<Counter caption={this.props.caption}
onClickDecrementButton={this.onClickDecrementButton}
onClickIncrementButton={this.onClickIncrementButton}
value={this.state.value} />
)
}
}前面我们注意到,我们必须在每个需要监听组件状态的组件中引入store
这样做不仅在组件很多的时候很麻烦,而且在团队开发的时候很不利于复用。
所以在一个应用中,最好只有一个地方直接导入Store,这个地方当然是在最顶层的React组件中。
那使用什么来向下传递我们的Store呢?
用prop显然是不行的,因为prop需要一级一级往下传,假设最底层的组件需要用store,中间的组件都得帮忙传递,这样无疑非常麻烦
React提供了一个叫Context的功能,实现了跨层级的组件数据传递,不需要通过组件树逐层传递prop
首先上级组件宣称自己支持Context,并提供一个函数来返回Context对象
然后这个上级组件的所有子孙组件都可以通过this.context访问到这个共同的环境对象
使用Context需要用到两种组件
现在我们先实现Context的生产者Provider,作为最顶级的父节点
对于Provider,要做两件事
下面是代码示例
import React, { Component } from 'react'
import PropTypes from 'prop-types'
class Provider extends Component {
// 1. 实现getChildContext,返回代表context的对象
getChildContext() {
return {
store: this.props.store
}
}
render() {
// 简单的将子组件渲染出来
return this.props.children
}
}
// 2. 通过childContextTypes静态属性来声明提供给子组件的属性
Provider.childContextTypes = {
store: PropTypes.object
}
export default Provider其中render函数中返回了this.props.children
每个React组件的props中都可以一个特殊属性children,代表的是子组
件
例如下面的代码,this.props.children代表的就是ControlPanel
<Provider>
<ControlPanel />
</Provider>然后我们使用<Provider>来包裹顶层组件中
ReactDOM.render(
<Provider store={store}>
<ControlPanel />
</Provider>,
document.getElementById('root')
)写好了Provider, 我们看子孙组件如何使用context对象
class CounterContainer extends Component {
constructor(props, context) {
// 得带上参数context,
super(props, context)
}
// ...
}
// 子组件需要通过一个静态属性contextTypes声明后,才能访问父组件Context对象的属性
CounterContainer.contextTypes = {
store: PropTypes.object
}在上面两节中,引入了容器组件,傻瓜组件和Context组件来优化Redux
有一个这样的库已经帮我们做好了这些工作,也就是react-redux
react-redux提供了两个最主要的api
connect用法
// 完整写法
const CounterContainer = connect(mapStateToProps, mapDispatchToProps)(Counter)
export default CounterContainer;connect的作用就是根据我们传入的UI组件和业务逻辑,自动生成容器组件
它具体做了什么工作呢?
换句话说这两个工作一个就是傻瓜组件的输入,一个就是傻瓜组件的输出
mapStateToProps是connect函数的第一个参数
看名字就知道意思是建立state和props的映射,也就是把Store上的状态,转化为props传给傻瓜组件
例子
// 第二个是可选参数,这个参数代表着容器组件的props
function mapStateToProps(state, ownProps) {
const { caption } = ownProps
return {
value: state[caption]
}
}mapDispatchToProps是connect函数的第二个参数
建立dispathch和props的映射,将内层傻瓜组件的用户动作转化为派发给容器组件的动作
// 第二个是可选参数,这个参数代表着容器组件的props
function mapDispatchToProps(dispatch, ownProps) {
const {caption} = ownProps
return {
onIncrement: () => {
dispatch(Actions.increment(caption))
},
onDecrement: () => {
dispatch(Actions.decrement(caption))
}
}
}connect函数还是有一些复杂的,脑海中要时刻存在容器组件和傻瓜组件的两个概念
connect函数帮我们做的事情就是创建容器组件,然后连接容器组件和傻瓜组件
记住导出的是connect帮我们创造的容器组件,而并不是我们自己写的傻瓜组件
Provider的用法比较简单,也就是提供包含store的context。
之前也实现过一个完整的Provider,只是没那么严谨
用法没有差别,在APP的顶层包裹,将store传入即可
<Provider store={store}>
<ControlPanel />
</Provider>最后通过react-redux的流程图,再复习一遍流程
在之前做的Todo应用中其实是用性能问题的
const todoList = props => {
const { todos, onToggleTodo, onRemoveTodo } = props
return (
<div>
<ul>
{todos.map(todo => (
<TodoItem
key={todo.id}
text={todo.text}
completed={todo.completed}
onToggleTodo={() => onToggleTodo(todo.id)}
onRemoveTodo={() => onRemoveTodo(todo.id)}
/>
))}
</ul>
</div>
)
}
// ...
export default connect(
mapStateToProps,
mapDispatchToProps
)(todoList)
// TodoItem
const TodoItem = (props) => {
const { text, completed, onToggleTodo, onRemoveTodo } = props
const checked = completed ? 'checked' : ''
return (
<li>
<input type="checkbox" onClick={onToggleTodo} checked={checked} readOnly />
<span>{text}</span>
<button onClick={onRemoveTodo}>删除</button>
</li>
)
}我们发现我们的TodoItem是一个无状态组件
假设我们列表有一千条数据,只有一条数据发生了变化,但是整个TodoList都被重新渲染了一遍
因为TodoItem是一个无状态函
数,所以使用的是React默认的shouldComponentUpdate函数实现,也就是永
远返回true的实现。
所以整个TodoList都被重新渲染了一遍
所以我们可以改写TodoItem
class TodoItem extends Component {
shouldComponentUpdate(nextProps, nextState) {
// completed或者text发生变化时,才重新渲染
return (nextProps.completed !== this.props.completed) ||
(nextProps.text !== this.props.text)
}
render() {
const { text, completed, onToggleTodo, onRemoveTodo } = this.props
const checked = completed ? 'checked' : ''
return (
<li>
<input type="checkbox" onClick={onToggleTodo} checked={checked} readOnly />
<span>{text}</span>
<button onClick={onRemoveTodo}>删除</button>
</li>
)
}
}这里要介绍到React的原理了。
首先在装载阶段,没有太多优化的过程,所有的React的组件都要经历一遍装载
至于卸载阶段,只有一个生命周期函数componentWillUnmount,这个函
数做的事情只是清理componentDidMount添加的事件处理监听等收尾工作,
做的事情比装载过程要少很多,所以也没有什么可优化的空间
关键在更新阶段
在装载阶段的时候,React通过render()函数在内存中产生了一个树形结构,树上每一个节点就代表React组件或者原生DOM元素,这个树形结构就是所谓的虚拟DOM(Virtual DOM)
用户操作触发了页面更新,React重新生成虚拟DOM,然后比较两个虚拟DOM的不同,来修改真实的DOM树
这个找不同的过程就叫做调和,React采用了巧妙的diffing算法进行实现
如果根节点类型不相同,就不用费心考虑了,就直接销毁旧树,重新建树。
原有的树会经历componentWillUnmount的生命周期,取而代之的组件componentWillMount、render和componentDidMount方法依次被调用
举个例子
// 原有的结构
<div>
<Todos />
</div>
// 更新
<span>
<Todos />
</span>我们只是将根节点div改成了span,但是这个算法会废掉div节点以及所有子节点,一切推倒重来
很明显,这是一个巨大的浪费,顶层的元素实际上不做什么实质的功能,但是仅仅因为类
型不同就把本可以重用的Todos组件卸载掉,然后重新再把这个组件装载一
遍。
所以作为开发者一定要尽量避免这种情况
如果两个树形结构的根节点类型相同,React就认为原来的根节点只需
要更新过程,不会将其卸载,也不会引发根节点的重新装载
这里考虑一个情况
// 原状态
<ul>
<TodoItem text="First" completed={false}>
<TodoItem text="Second" completed={false}>
</ul>
// 更新
<ul>
<TodoItem text="Zero" completed={false}>
<TodoItem text="First" completed={false}>
<TodoItem text="Second" completed={false}>
</ul>按道理说只需要渲染 text=Zero 的组件
但React没有那么聪明,它不会仔细判断两个组件是否相同,只是单纯的按位置比较
于是三个组件都被重新渲染了一遍
React就出了一个key的功能,在渲染列表的时候,指定组件的唯一key值(必须稳定不变)
React就会根据key去比较组件,避免重复渲染
Redux 的工作流程图
Redux三个基本原则
单一数据源的意思是应用的数据状态只存储在一个唯一的Store中
保持状态只读,意思就是不要去修改状态,要修改Store的状态,只能通过派发一个action对象完成
思考:驱动用户界面更改的是状态,状态只读,那怎么能引起用户界面的改变呢?
答:当然要改,只是我们不去修改状态值,而是创建一个新的状态对象给Redux,由Redux完成新状态的组装
这里说的纯函数是Reducer
reducer(state, action)
第一个参数state是当前的状态
第二个参数action是接收到的action对象,而reducer函数要做的事情,就是根据state和action的值产生一个新的对象返回,注意reducer必须是纯函数,也就是说函数的返回结果必须完全由参数state和action决定,而且不产生任何副作用,也不能修改参数state和action对象。
例子在src目录下,与上节相同的例子加减组件,用Redux改写。
通过三张图了解Redux中的重要概念
先用因为react-redux帮我们省去了很多代码,不利于理解,所以先从redux开始
给出概念图

Action是一个对象,用来代表所有会引起状态(state)变化的行为
action.js如下所示。
// ActionTypes.js
export const INCREMENT = 'increment'
export const DECREMENT = 'decrement'
// Action.js
import * as ActionTypes from './ActionTypes'
export const increment = (counterCaption) => {
return {
type: ActionTypes.INCREMENT,
counterCaption: counterCaption
}
}
export const decrement = (counterCaption) => {
return {
type: ActionTypes.DECREMENT,
counterCaption: counterCaption
}
}Store是Redux中数据的统一存储,维护着state的所有内容
import { createStore } from 'redux'
import reducer from './Reducer.js'
const initValue = {
'First': 0,
'Second': 10,
'Third': 20
}
const store = createStore(reducer, initValue)
export default storeReducer决定着如何更新state
``(previousState, action) => newState```
该函数接收两个参数,一个旧的状态previousState和一个Action对象
然后返回一个新的状态newState,去重新渲染View
class Counter extends Component {
constructor(props) {
super(props)
this.state = this.getOwnState()
//...
}
getOwnState() {
const { caption } = this.props
return {
value: store.getState()[caption]
}
}
}import store from '../Store'
//...
componentDidMount() {
// 通过store.subscribe()监听组件变化,只要组件的状态变化,就会调用onChange方法
store.subscribe(this.onChange)
}
componentWillUnmount() {
// 组件删除后,注销监听
store.unsubscribe(this.onChange)
}
onChange() {
const newState = this.getOwnState()
this.setState(newState)
}onClickIncrementButton() {
const { caption } = this.props
store.dispatch(Actions.increment(caption))
}
onClickDecrementButton() {
const { caption } = this.props
store.dispatch(Actions.decrement(caption))
}大功告成。 看似复杂了很多,增加了很多约束,其实对开发项目有好处,利于提高软件质量
注意一个地方,我们在每个组件里都需要引入store,这样才能更新变化。
但这样做很麻烦,那有啥好的办法呢? 后面会讲到使用Context组件
ps: 其实Redux的核心功能实现并不难,自己实现了一下核心的功能,导入环境能正常使用
// 发布订阅模式
function createStore(reducer, initState) {
let state = initState
let listeners = []
function subscribe(listener) {
listeners.push(listener)
}
function dispatch(action) {
// 按照 reducer 修改 state
state = reducer(state, action)
for (let i = 0; i < listeners.length; i++) {
const listener = listeners[i]
listener()
}
}
function getState() {
return state
}
return {
subscribe,
dispatch,
getState,
}
}
export default createStore在没有Hooks之前,在React中只有两种组件
因为函数组件是无状态的,所有数据都依赖于props传入,没有生命周期,所以提供的能力非常有限
因此在开发中我们常常会使用class组件,很少用到函数组件
但是在引入hooks之后,可以让无状态的函数组件拥有状态组件才有的能力,极大扩展了函数组件的能力
下面使用class组件来实现一个需求,来借以发现class组件的一些问题
假定一个需求,有一个Tab选项和内容区
根据Tab的切换,会展示不同的内容区
然后我们使用class组件实现一下
import React, { Component } from 'react';
class ContentContainer extends Component {
constructor(props) {
super(props);
this.state = {
loading: true,
msg: ''
};
}
loadMessage() {
this.setState({
loading: true
});
setTimeout(() => {
const message = ['这是第一条信息', '这是第二条信息', '这是第三条信息'];
this.setState({
loading: false,
msg: message[this.props.id]
});
}, 1000);
}
componentDidMount() {
this.loadMessage();
}
// 根据不同的props更新状态
componentDidUpdate(preProps) {
if (preProps.id !== this.props.id) {
this.loadMessage();
}
}
render() {
return <Content loading={this.state.loading} msg={this.state.msg} />;
}
}
const Content = props => {
const { loading, msg } = props;
return <div>{loading ? <p>loading.....</p> : <div>一些信息:{msg}</div>}</div>;
};
class Tab extends Component {
constructor(props) {
super(props);
this.state = {
id: 0
};
}
handleClick = id => {
this.setState({ id });
};
render() {
return (
<div>
<button onClick={() => this.handleClick(0)}>点击0</button>
<button onClick={() => this.handleClick(1)}>点击1</button>
<button onClick={() => this.handleClick(2)}>点击2</button>
<ContentContainer id={this.state.id} />
</div>
);
}
}
export default Tab;我将这个功能抽成了三个组件
第一个问题是:复杂组件变得难以理解
首先把矛点指向ContentContainer组件
这个组件需要根据传入的props.id,去请求不同的数据
因此需要在两个生命周期函数中写重复的请求代码, componentDidMount和componentDidUpdate
在两个不同的生命周期中处理一份相同的逻辑,这显然不太合适,特别是组件复杂了以后,很容易产生bug
第二个问题是:组件之间复用逻辑状态变的困难
React团队其实一直传达一个概念
有状态的组件没有渲染,有渲染的组件没有状态。
也可以叫成UI组件和容器组件
因此在处理Content的时候,我将其拆成了两个组件
为了复用状态,我们只能通过props的形式,做一层嵌套
当组件复杂起来,你会发现由 providers,consumers,高阶组件,render props 等其他抽象层组成的组件会形成嵌套地狱
针对之前遇到的两个问题,我们使用hooks进行改造
import React, { useState, useEffect } from 'react'
const useContent = (id) => {
const [loading, setLoading] = useState(false)
const [msg, setMsg] = useState('')
useEffect(() => {
setLoading(true);
setTimeout(() => {
const message = ['这是第一条信息', '这是第二条信息', '这是第三条信息'];
setLoading(false);
setMsg(message[id])
}, 1000);
}, [id])
return [loading, msg]
}
const Content = ({ id }) => {
const [loading, msg] = useContent(id)
return <div>{loading ? <p>loading.....</p> : <div>一些信息:{msg}</div>}</div>;
}
const TabHooks = () => {
const [id, setId] = useState(0)
return (
<div>
<button onClick={() => setId(0)}>点击0</button>
<button onClick={() => setId(1)}>点击1</button>
<button onClick={() => setId(2)}>点击2</button>
<Content id={id}/>
</div>
)
}
export default TabHooks这里我们分别通过useEffect和自定义hooks解决了class组件中两个问题
这里我们主要讨论自定义hooks
在class组件中,为了复用状态,我们将Content拆成了两个组件,并形成了嵌套
而在hooks中,我们同样是拆成了两个组件
而是更加扁平化,自定义的useContent,负责将组件逻辑抽了出来,只暴露给Content所需的状态
通过hooks改造之后,代码精简了近50%,并且对于class所存在的问题做了很好的解决
真滴很方便,使用React的小伙伴,赶紧用起来吧~~
定义,摘选自维基百科。
散列表(Hash Table)也叫哈希表。
是根据键(Key)而直接访问在内存存储位置的数据结构
它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做散列表。
通过一个简单的例子解释一下。
老师统计班上同学的成绩,想要把每个分数的人数统计一下,也就是说考了100分的有多少人?考了99分的有多少人?
可能刚接触编程的人会这样写
var score = [...] // 存放了所有学生的成绩
for (var i = 0; i <= 100; i++) {
var sum = 0; // 计算考了i分的同学有多少个
for (var j = 0; j < score.length; j++) {
if (i == score[j]) {
sum++
}
}
console.log('考了' + i + '分的同学有' + sum + '人')
}这样显然很慢。假设统计全校的学生的四六级分数呢,每次的查询都是O(n)复杂度
那么我们想想其实可以拿分数来当键值,去访问该分数段的人数。
var total = 1000 // 学生的人数
var res = new Array(total).fill(0)
for (var i = 0; i < score.length; i++) {
res[score[i]]++
}
for (var i = 0; i <= 100; i++) {
console.log('考了' + i + '分的同学有' + res[i]+ '人')
}这就是一个简单的哈希表。
这个散列函数,很简单
Hash(k) = k,简单的将分数这个关键字当成key值(直接定址法)
这个记录的数组就叫做哈希表。
可以发现,我们的哈希表,
正常情况下修改,查找和删除的复杂度都是O(1),是很优秀的数据结构
散列表需要一一对应,也就是说,一个键应该对应一个值
如果一个键对应了多个值,那么就会出现冲突,这种冲突叫哈希冲突
那么解决比较好的方法就是拉链法。
假设score[100]这个位置出现了a, b,那就可以将对应值搞成一个链表
a的next域指向b
其实引入哈希表的概念主要是为了解释摘要算法的一部分
摘要算法是个啥?听起来很吓唬人,其实它就是一个哈希函数。
将长度不固定的消息message作为输入参数,运行特定的Hash函数,生成固定长度的输出,这个输出就是Hash,也称为这个消息的消息摘要(Message Digest)
这个特定的Hash函数,常见的就是MD5,SHA1,还有比较新的SHA256
MD5哈希函数将任意长度的数据摘要(映射)为一个定长的密文
为什么叫摘要而不叫加密呢?因为这个摘要的结果是不可逆的,不能被还原
理论上来说,不管使用什么样的摘要算法,必然存在2个不同的消息,对应同样的摘要。
因为输入是一个无穷集合,而输出是一个有限集合,所以从数学上来说,必然存在多对一的关系
简单说,也就是如果有一个A 对应 B,因为B是固定的,我一定能再找到一个C也对应B
这只是理论上的,安全的Hash算法几乎是无法破解的。
MD5,SHA1已经被破解了,这两个算法都能在较短的时间内找到相同的碰撞,所以被证实为不安全了,现在比较安全的算法是SHA256
数据完整性验证
假设一个软件QQ,开发人员开发完成后
保护用户密码
原理也是一样的。
假设数据库里存储的用户密码都是明文,如果有坏人攻破了数据库,就轻松拿到了用户密码等信息
那我们就可以通过MD5来保护用户密码(此处也可以使用SHA1或者SHA256,原理都是一样的)
数据库中不存储用户的密码,转而存储用户密码经过MD5计算后的MD5值
用户登录的时候,只要将密码进行MD5计算,与数据库中的MD5值比对,相同即可登录
这样一来,即使数据库密码泄露,坏人也只能拿到计算过后的MD5值,并不能反向推导出用户密码
虽然可以只存储用户加密过后的MD5值,由于用户很多,难免有些用户会存储一些简单的密码
这时候坏人如果拿到数据库就可以利用彩虹表(存储一些简单密码的MD5值)暴力破解,看是否与之对应。
所以为了安全考虑,一般在给用户密码加密的时候,还会有一层加盐的操作
加盐就是在给用户密码MD5一次加密之后呢,再把这个摘要值加上我们的盐(一些随机的字符)进行二次加密,这样就保证了安全性,盐可以是一个固定的盐,也可以是随机盐
这样哪怕是MD5加密,用户密码也是非常安全的,破解难度极高,即使黑客知道了盐,破解起来也非常复杂
React Fiber
React框架中,存在着三层结构
Fiber是对React核心算法的重构,这个重构就在Reconciler层
在React 15之前,更新一个组件状态或者组件树,会一连串的做很多事情
比如说,调用组件的生命周期函数,计算比对虚拟DOM,最后更新DOM树,整个过程是同步进行的
如果组件比较复杂,就会导致js长时间运行,会导致样式,布局渲染阻塞,引起卡顿,掉帧的现象
比如说一个文本输入框,可能是一个比较复杂的表单组件,然后每次输入的时候状态更新。
由于比较复杂,更新可能需要100ms,如果用户输入的特别快,就可能的结果是,第一时间用户输入的内容不显示在文本框内,过了一两秒后,一下蹦出了之前输入的全部内容
另外一个例子
明显看到渲染的时候存在卡顿
将同步任务切片,分批完成,这每一个小切片就叫做Fiber
完成一部分任务后,将控制权交给浏览器,让浏览器进行渲染,等浏览器渲染完成,再继承执行之前未完成的任务
这种策略叫做合作式调度,操作系统的三种任务调度策略之一
原来的React是通过递归组件树来进行渲染的,Fiber改成了链表的形式去遍历树渲染
将递归改成循环,可以方便的暂停,继续和丢弃一些执行的任务
Fiber里的工作分为两个阶段
对应着不同的生命周期
第一阶段对应
16.4中废弃了第一阶段多个生命周期函数
第二阶段
因为第一阶段是可以中断的(找嘛,找到一半不找了当然可以)
但是第二阶段是不能被打断的
所以说,尽量不要再第一阶段的生命周期函数里做一些副作用的操作,比如说发送请求,有可能被重新执行
参考文章:
来看看三者的区别
对于call方法来说,它可以指定this和一些参数去调用函数或者方法
apply与call的区别就是
call的参数是一个个传入的call(this, args1, args2...)
apply接收参数数组call(this, [args])
bind方法与call, apply的区别就是,bind会指定好this和参数之后,返回一个新的函数或者方法给你,并不会去执行它
实现的改变this基础是,将方法绑定到添加到指定的this对象上,进行调用,调用完之后再将其删除
也就是这样的
// 原先无关的两个
const t = {
name: 'zmj',
}
const getName = (age) => {
return this.name + '今年' + age + '岁啦'
}
getName.call(t, 18)
// 原理其实就这样
const t = {
name: 'zmj',
getName: (age) => {
return this.name + '今年' + age + '岁啦'
}
}
t.getName(18)那么知道了原理就好办了,
稍微麻烦一点的地方是在参数的处理上,要除去第一个参数,解析其他的参数,将不定个参数传入执行
这里通过了ES6的扩展运算符来简化了这一步操作
Function.prototype.call = function (context) {
context.fn = this
var args = [...arguments].slice(1)
let res = context.fn(...args)
delete context.fn
return res
}如果不能使用ES6,也能通过ES3的eval,魔改参数传入(将参数拼接成字符串),个人不太喜欢这种做法
Function.prototype.call = function (context) {
// 严谨一些,如果传入的context是基本类型,那么将它包装成引用类型
// 如果没传那么就是window
context = context ? Object(context) : window;
context.fn = this;
var args = [];
for(var i = 1, len = arguments.length; i < len; i++) {
args.push('arguments[' + i + ']');
}
var res = eval('context.fn(' + args +')');
delete context.fn
return res;
}apply与call的区别仅仅是参数传递上的区别
es6写法
Function.prototype.apply = function(context, args) {
context.fn = this
let res = context.fn(...args)
delete context.fn
return res
}bind和上述两者的区别是,不执行这个函数,而是绑定好this,返回一个新的函数给你
效果是下面这样的
const t = {
name: 'zmj',
}
const getName = (age) => {
return this.name + '今年' + age + '岁啦'
}
// 第一种使用方法
const foo = getName.bind(t, 18)
foo() // zmj今年18岁啦
// 第二种使用方法
const foo = getName.bind(t)
foo(18) // zmj今年18岁啦上述两者使用方法是有些区别的
所以我们的bind函数现在有几个关键点
实现
Function.prototype.bind = function(context) {
const args = [...arguments].slice(1)
const self = this
return function() {
return self.apply(context, [...args, ...arguments])
}
}const self = this是什么意思?然后还剩下一个关键点
如果bind后的新函数,作为构造函数被new了咋办?
因为bind的优先级比new低,所以this应该指向构造函数
效果是下面这样的
const t = {
name: 'zmj',
price: '$100'
}
function getName(age) {
console.log(this.name + '今年' + age + '岁啦')
}
// 第一种使用方法
const Foo = getName.bind(t, 18)
const f = new Foo(18) // undefined今年18岁啦实现,在apply的时候,做一步判断,判断返回的函数是否被new了
Function.prototype.bind = function(context) {
const args = [...arguments].slice(1)
const self = this
const foo = function() {
// 如果调用的函数的原型foo的原型链上,说明被new了。。
if (this instanceof foo) {
return self.apply(this, [...args, ...arguments])
} else {
return self.apply(context, [...args, ...arguments])
}
}
// 返回的函数原型指向 调用函数的原型
foo.prototype = this.prototype
return foo
}分五步走
解决基本状态,即Promise三个状态pending, fulfilled, rejected的转换
解决then方法
支持异步操作
支持链式调用
all和race
看一段promise代码
const promise = new Promise((resolve, reject) => {
const r = new XMLHttpRequest()
r.open(method, url, false)
r.onreadystatechange = () => {
if (r.readyState == 4 && r.status) {
// 成功后传入值
resolve(r.response)
} else {
// 失败后传入error
reject(err)
}
}
r.send()
})Promise存在三个状态pending、fulfilled、rejected
// 定义三个常量,标记promise运行的状态
const PENDING = 'pending'
const FULFILLED = 'fulfilled'
const REJECTED = 'rejected'
class Promise {
constructor(executor) {
this.status = PENDING
// 储存成功的值
this.value = undefined
// 储存失败的原因
this.reason = undefined
try {
executor(this.resolve, this.reject)
} catch(err) {
this.reject(err)
}
}
resolve = (val) => {
if (this.status !== PENDING) return
this.status = FULFILLED
this.value = val
}
reject = (err) => {
if (this.status !== PENDING) return
this.status = REJECTED
this.reason = err
}
}再来看一段then方法的代码
ajax('get', url).then((res) => {
console.log('成功', res)
}, (err) => {
console.log('失败', err)
})可以看出,then方法接收两个参数
在Promise实现规范中,这两个参数分别是两个回调函数onFulfilled,onRejected
then(onFulfilled, onRejected) {
const { status, value, reason } = this
if (status === FULFILLED) {
onFulfilled(value)
} else if (status === REJECTED) {
onRejected(reason)
}
}至此,就完成了一个Promise,但是只支持同步操作
那么怎么支持异步操作呢?
可以使用发布订阅模式,在调用then的时候,判断当前promise的状态,如果当前promise处于pending的状态
那么我们将onFulfilled和onRejected分别订阅到两个个数组里,当promise完成后(会调用resolve或者reject)
这时候,我们通过一个循环,遍历数组,通知所有的订阅者,异步操作已经完成
resolve = (val) => {
if (this.status !== PENDING) return
this.status = FULFILLED
this.value = val
// 发布
this.fullfilledListner.forEach(listner => listner(val))
}
reject = (err) => {
if (this.status !== PENDING) return
this.status = REJECTED
this.reason = err
// 发布
this.rejectedListner.forEach(listner => listner(err))
}
then = (onFulfilled, onRejected) => {
const { status, value, reason } = this
if (status === PENDING) {
// 订阅
this.fullfilledListner.push(onFulfilled)
this.rejectedListner.push(onRejected)
} else if (status === FULFILLED) {
onFulfilled(value)
} else if (status === REJECTED) {
onRejected(reason)
}
}有一个疑问,既然一个Promise只有一个异步操作,为什么要用数组去存储异步回调,用一个值存不就行了吗?
Promise的核心是支持链式调用,这一块也是比较复杂的,主要要实现以下功能
第一点和第二点都比较好理解
看第三点和第四点
let p = new Promise((resolve,reject)=>{
resolve(1);
});
p.then(res => {
console.log(res) // 输出1
return 2; //返回一个普通值
}).then(res => {
console.log(res); //输出2,这里由于没有return,于是返回一个用Undefined包装的Promise对象
});再看一下第六点
let p = new Promise((resolve, reject) => {
resolve(1);
});
p.then(res => 2) // 这里包装了一个 2 的Promise对象
.then()
.then()
.then(res => {
console.log(res); //2
});从这个例子可以看出,中间虽然经过了两个then方法,但是由于then里面没有回调函数,所以将这个Promise一直传递到了最下面
实现的主要思路有一点:
我们要根据上一个Promise的返回值来确定返回的新的Promise应该是怎么样的
根据上一节的六点来实现我们这个函数
首先我们必须整理好思路,搭好一个架子
then方法无论如何都返回一个Promise对象
Promise.prototype.then = function (onFulfilled, onRejected) {
// 注意这是当前Promise的状态
const { status } = this
// 这是我们要返回的新Promise
var newPromise = new Promise((resolve, reject) => {
// 代码略...
}
return newPromise;
};中间省略的代码是比较核心的部分,是用来描述我们当前Promise返回值和新的Promise对象之间的关系
let x = onFulfilled(value)resolvePromise(newPromise, x, resolve, reject) this.fullfilledListner.push(() => {
// 这是上一个Promise的结果
let x = onFulfilled(this.value)
resolvePromise(newPromise, x, resolve, reject)
})实现后,我们的代码是这样的 (这里为了阅读清晰,去除了一些错误判断的代码,后面再加上)
then = (onFulfilled, onRejected) => {
const { status, value, reason } = this
const newPromise = new MyPromise((resolve, reject) => {
if (status === PENDING) {
this.fullfilledListner.push(() => {
let x = onFulfilled(this.value)
resolvePromise(newPromise, x, resolve, reject)
})
this.rejectedListner.push(() => {
let x = onRejected(this.value)
resolvePromise(newPromise, x, resolve, reject)
})
} else if (status === FULFILLED) {
let x = onFulfilled(value)
resolvePromise(newPromise, x, resolve, reject)
} else if (status === REJECTED) {
let x = onRejected(reason)
resolvePromise(newPromise, x, resolve, reject)
}
})
return newPromise
}resolvePromise函数是我们实现的关键部分,看我们这个函数的基本框架是下面这样的
/**
* 解析then返回值与新Promise对象
* @param {Object} newPromise 新的Promise对象
* @param {*} x then返回值
* @param {Function} resolve 新Promise对象的resolve
* @param {Function} reject 新Promise对象的reject
*/
const resolvePromise = (newPromise, x, resolve, reject) => {
// ...
}下面一步步开始解决一个函数
1. 解决循环引用
什么是循环引用,当then的返回值与新生成的Promise对象为同一个(引用地址相同),则会抛出TypeError错误
let promise2 = p.then(data => {
return promise2;
});解决它很简单,一行
// 解决循环引用
if (newPromise === x) {
reject(new TypeError('Chaining cycle detected for promise'))
}2. 根据then返回值确定新的Promise对象
// then方法返回值如果是Promise对象
if (x !== null && (typeof x === 'object' || typeof x === 'function')) {
try {
let then = x.then
// 如果返回值x中包含then方法,说明返回值x肯定是个Promise对象
if (typeof then === 'function') {
// 调用 then()
then.call(x, (res) => resolve(res), (err) => reject(err))
} else {
resolve(x)
}
} catch(err) {
reject(err)
}
} else {
// 对应六条规则中的第二条规则,普通属性直接包装成Promise返回成功即可
resolve(x)
}至此,链式调用差不多就完成了,但还得考虑一个比较特殊的情况
then中返回的Promise对象的resolve传入的还是Promise
如果按照我们写的Promise的话,就会出现问题
p.then(data => {
return new MyPromise((resolve,reject)=>{
// resolve传入的还是Promise
resolve(new MyPromise((resolve,reject)=>{
resolve(2)
}))
})
}).then(data => {
// 于是
// data 不是我们想要的2
// 而是 new MyPromise((resolve, reject) => { // ... })
})所以我们需要改写一下
// then方法返回值如果是Promise对象
if (x !== null && (typeof x === 'object' || typeof x === 'function')) {
try {
let then = x.then
// 如果返回值x中包含then方法,说明返回值x肯定是个Promise对象
if (typeof then === 'function') {
// 调用 then()
then.call(
x,
(res) => resolvePromise(newPromise, res, resolve, reject),
(err) => reject(err)
)
} else {
resolve(x)
}
} catch(err) {
reject(err)
}
} else {
// 对应六条规则中的第二条规则,普通属性直接包装成Promise返回成功即可
resolve(x)
}至此就已经完成了我们的resolvePromise函数
3. 将then方法改写为异步方法
规范中规定then方法是异步方式,我们通过
setTimeout(()=> , 0)来包装,使之成为异步方法
给出完整代码(包括错误处理和Promise.resolve, Promise.reject, Promise.all, Promise.race )
Promise.resolve = function(val) {
return new Promise((resolve, reject) => {
resolve(val)
})
}
Promise.reject = function(val) {
return new Promise((resolve, reject) => {
reject(val)
})
}
// race方法
Promise.race = function (promises) {
return new Promise((resolve, reject) => {
for (let i = 0; i < promises.length; i++) {
promises[i].then(resolve, reject)
};
})
}
//all方法(获取所有的promise,都执行then,把结果放到数组,一起返回)
Promise.all = function (promises) {
let arr = [];
let i = 0;
function processData(index, data) {
arr[index] = data;
i++;
if (i == promises.length) {
resolve(arr);
};
};
return new Promise((resolve, reject) => {
for (let i = 0; i < promises.length; i++) {
promises[i].then(data => {
processData(i, data);
}, reject);
};
});
}对于每个执行上下文,都有三个重要属性
执行上下文的生命周期可以分为两个阶段
在js中,不可避免的要声明变量和函数,这里JS解析器就通过变量对象解决了。
变量对象创建分三个过程
ps. 函数声明优先
注意在执行上下文中变量对象创建过程中属性是不能被访问的
当变量对象创建完毕后
当执行上下文进行代码执行阶段,此时变量对象就转变为了活动对象,里面的属性就可以访问了,变量也会随之赋值
问:变量对象和活动对象的区别?
答:它们其实是同一个对象,只是处于执行上下文不同的生命周期,变量对象是在执行上下文创建过程中建立的,当执行上下文进入了代码执行阶段,变量对象就会变为活动对象Generator 函数是 ES6 提供的一种异步编程解决方案,语法行为与传统函数完全不同。
那么我们一步步的从迭代器到生成器,来看看generator的优点和缺点
首先简单了解一下迭代器的概念
迭代器(iterator)
迭代器,下面是一个简单的迭代器,迭代一个数组
var iterator = function(arr) {
var index = 1
return {
next: function() {
if (index < arr.length) {
return {
value: arr[index++],
done: false,
}
} else {
return {
done: true,
}
}
}
}
}
var it = iterator([1, 2, 3, 4])
it.next() // 1
it.next() // 2可以看到这个迭代器的作用,我们给数组[1,2, 3, 4]创建了一个迭代器,然后每次调用迭代器的next方法,就可以指向数组的下一个元素。
但是这种方法显然比较麻烦
那我们就可以通过了解更高级的做法,生成器generator
生成器(generator)
先简单了解一下generator的语法,通过阮老师的文章Generator 函数的语法
我们需要知道几个关键的地方是:
generator函数调用后,函数不会执行,而是返回一个迭代器对象,替我们维护函数内部状态next方法后,函数开始执行,直到遇到yield表达式(或者return语句)的时候停止yield后面的表达式值,作为next方法返回值中的value属性值于是我们可以知道generator,可以很好的解决迭代器的两个问题,它会自动的维护创建的状态,请看下面的简单例子
var generator = function* (arr) {
for(let i = 0; i < arr.length; i++) {
yield arr[i]
}
}
var it = generator([1, 2, 3, 4, 5])
it.next() // {value: 1, done: false}
it.next() // {value: 2, done: false}
it.next() // {value: 3, done: false}
// ...显而易见,generator做到了与迭代器一样的事情,神奇的是
generator配合yield做到了'暂停代码'的功能,让代码像进度条样,一点一点执行
(对运行机制感兴趣可以使用Babel将generator代码转换为ES5形式,它其实是模拟了一个状态机)
利用这个特性,我们可以以同步的方式来执行异步代码
我们造一个需求,使用node中的readFile方法依次读取三份文件1.txt, 2.txt, 3.txt的内容(要求使用generator)
这个地方还有一个小知识点,
fs.readFile函数没有返回值,文件的内容在回调函数中传出,那我们怎么将值传递给yield呢?
答案是写在next参数里,当yield表达式本身没有返回值。next方法可以带一个参数,该参数就会被当作上一个yield表达式的返回值。
所以我们可以这样实现
var fs = require('fs')
var dealCallback = (err, data) => {
console.log('data', data.toString())
gen.next(data)
}
var read = function* (arr) {
yield fs.readFile('1.txt', dealCallback)
yield fs.readFile('2.txt', dealCallback)
yield fs.readFile('3.txt', dealCallback)
}
var gen = read()
gen.next()
// 依次打印
// 1.txt
// 2.txt
// 3.txt但是这样做的缺点很明显
很麻烦,其实我们想要的就是运行read函数,然后按照顺序执行我们的代码而言
有什么方法可以让它变的更简单些呢?
请看下一篇: javascript异步编程第二步:co库
执行上下文可以理解为当前代码的执行环境,它会形成一个作用域。
每个执行上下文都包含三个东西
存在生命周期
javascript中的运行环境大概为三种
在js中,会有很多执行上下文,js会用执行栈来处理这些上下文
第一个肯定是将全局执行上下文push到栈里
然后每调用一次函数,就将函数的执行上下文push到栈里
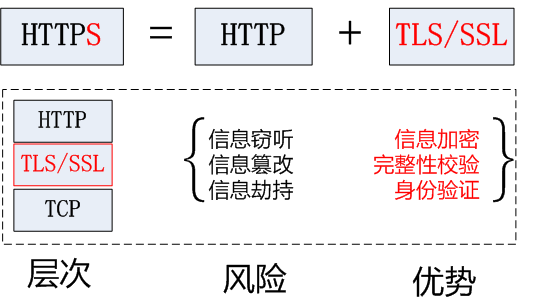
SSL(Secure Sockets Layer)直译过来是安全套接层。
TLS是
他是HTTPS协议中的一个东西
在网络层和传输层中加入了一个SSL层,称为加密传输协议(非对称加密)
其实HTTPS = HTTP + SSL/TLS
TLS是SSL的升级版,最新版,不过大家都叫SSL叫惯了
参考文章:大致介绍一下SSL
SSL和TLS的区别
浅谈HTTPS协议和SSL、TLS之间的区别与关系
那么是怎么加密的呢?
加密类型有两种
对称加密是客户端和服务端双方共有一个公钥,如果公钥泄露了,那么传输内容就会泄露
非对称加密有两把密钥,一把是公钥,一把是私钥。
客户端先向服务器端索要公钥,然后用公钥加密信息,服务器收到密文后,用自己的私钥解密。
但是还是存在一些问题
在公钥传输的过程中,有可能被第三方篡改,传给你一个假的公钥,你就解析不了数据了
所以有了SSL证书
公钥保存在SSL证书里(这个证书是CA机构颁发的)
公钥加密信息太慢,怎么减少时间
解决方法:每一次对话(session),客户端和服务器端都生成一个"对话密钥"(session key),用它来加密信息。
由于"对话密钥"是对称加密,所以运算速度非常快,而服务器公钥只用于加密"对话密钥"本身,这样就减少了加密运算的消耗时间。
图解流程
参考文章:
为了解决第一步中的两个问题
其实也就是我们得想办法让generator函数能够自动执行
于是乎,TJ大神出了一个CO库,来解决这两个问题
早期的CO库基于Thunk化实现,现在的CO库是基于Promise的
Thunk化是什么呢? 例如一个readFile函数
// 普通的readFile
readFile('file.txt', (err, data) => {
console.log(data.toString())
})
// thunk化后的readFile
var readFile = function(filename) => {
return function(callback) {
fs.readFile(filename, callback)
}
}
var thunk = readFile('file.txt')
thunk((err,data) => {
console.log(data.toString())
})其实thunk化有点类似柯里化的概念,将多个入参,转变成一个入参的新函数,并且这个新函数只接收回调函数作为参数
我们可以将thunk化封装一下做一个thunkify,将函数自动包装为一个thunk化的函数
// 这个thunkify并不能用于生产环境,特殊情况没有考虑
var thunkify = function(fn) {
return function() {
var args = [].slice.call(arguments)
return function(callback) {
args.push(callback)
fn.apply(this, args)
}
}
}
var readFile = thunkify(fs.readFile)
readFile('file.txt')((err,data) => {
console.log(data.toString())
})然后使用这种方式我们来改写之前异步的代码
var readFile = thunkify(fs.readFile)
var read = function* (arr) {
var file1 = yield readFile('1.txt')
console.log('file1', file1.toString())
var file2 = yield readFile('2.txt')
console.log('file2', file2.toString())
var file3 = yield readFile('3.txt')
console.log('file3', file3.toString())
}
var gen = read()
var t = gen.next()
t.value((err, data) => {
t = gen.next(data)
t.value((err, data) => {
t = gen.next(data)
t.value((err, data) => {
t = gen.next(data)
})
})
})
// 这里注意next的调用
// 因为next方法的参数表示上一个yield表达式的返回值,第一次next的参数无效,用以启动生成器由于我们将readFile thunk化了,所以每次yield后,返回的都是readFile处理完之后的回调函数
这个时候,我们可以发现gen.next()这个过程虽然嵌套了很多回调,但其实都是相同的代码,可以自动化掉
编写一个run函数来自动化这个过程
var run = function(fn) {
var gen = fn()
function next(err, data) {
var res = gen.next(data)
if (res.done) {
return
}
res.value(next)
}
next()
}所以我们的代码由异步代码转变成了'同步代码'
var read = function* (arr) {
var file1 = yield readFile('1.txt')
console.log('file1', file1.toString())
var file2 = yield readFile('2.txt')
console.log('file2', file2.toString())
var file3 = yield readFile('3.txt')
console.log('file3', file3.toString())
}
run(read)Thunk 函数并不是 Generator 函数自动执行的唯一方案。因为自动执行的关键是,必须有一种机制,自动控制 Generator 函数的流程,接收和交还程序的执行权。回调函数可以做到这一点,Promise 对象也可以做到这一点。
其实Generator 函数就是一个异步操作的容器。它的自动执行需要一种机制,当异步操作有了结果,能够自动交回执行权。
之前使用Thunk化的方法实现了这个自动执行的机制
现在基于Promise来实现
将readFile函数改造成Promise形式,手动来执行
var readFile = function(filename) {
return new Promise((resolve, reject) => {
fs.readFile(filename, (err, data) => {
if (err) {
reject(err)
}
resolve(data)
})
})
}
var read = function* () {
var file1 = yield readFile('1.txt')
console.log('file1', file1.toString())
var file2 = yield readFile('2.txt')
console.log('file2', file2.toString())
var file3 = yield readFile('3.txt')
console.log('file3', file3.toString())
}
var gen = read()
gen.next().value.then(data => {
gen.next(data).value.then(data => {
gen.next(data).value.then(data => {
gen.next(data)
})
})
})自动化掉手动执行的过程
var run = function(fn) {
var gen = fn()
function next(data) {
var res = gen.next(data)
if (res.done) return
res.value.then(data =>{
next(data)
})
}
next()
}
run(read)回顾todoList项目中的FooterContainer(这是一个todoList的过滤器容器)
import { connect } from 'react-redux'
import * as actions from '../actions'
import Footer from '../components/Footer'
const mapStateToProps = state => {
return {
filter: state.filter
}
}
const mapDispatchToProps = dispatch => {
return {
setVisibleTodos: (filter) => dispatch(actions.setFilter(filter))
}
}
export default connect(mapStateToProps, mapDispatchToProps)(Footer)在mapStateToProps函数中,我们发现FooterContainer作为视图层的一个容器组件,直接引用了Redux层的数据,这是一种强耦合的关系。
我们可以通过selector来对这两者进行解耦
改写后
// FooterContainer
import { connect } from 'react-redux'
import * as actions from '../actions'
import Footer from '../components/Footer'
import { getFilter } from '../seletors'
const mapStateToProps = state => {
return {
filter: getFilter(state)
}
}
const mapDispatchToProps = dispatch => {
return {
setVisibleTodos: (filter) => dispatch(actions.setFilter(filter))
}
}
export default connect(mapStateToProps, mapDispatchToProps)(Footer)
// selectors
export const getFilter = (state) => state.filter这样我们就通过selector,实现了两者的解耦
我们来看todoList中的getVisibleTodos方法
export const getVisibleTodos = (state) => {
const {todos, filter} = state
switch (filter) {
case 'all':
return todos
case 'completed':
return todos.filter(todo => todo.completed)
case 'active':
return todos.filter(todo => !todo.completed)
default:
return new Error('Unknown filter:' + filter)
}
}我们发现,我们的这个selector函数,需要经过一些计算。
每当state发生改变的时候,即使是一个无关的state,getVisibleTodos函数都会被重新执行一遍
我们发现只要我们的state的todos和filter字段没有发生改变,我们就不需要再重复进行计算
可以选择引用上次计算好的结果,就没必要再重复计算了,reselect就帮我们做了这件事情,帮我们缓存好结果,避免重新的计算
使用方法:
import { createSelector } from 'reselect'
export const getFilter = (state) => state.filter
const getTodos = (state) => state.todos
export const getVisibleTodos = createSelector(
[ getFilter, getTodos ],
(filter, todos) => {
switch (filter) {
case 'all':
return todos
case 'completed':
return todos.filter(todo => todo.completed)
case 'active':
return todos.filter(todo => !todo.completed)
default:
return new Error('Unknown filter:' + filter)
}
}
)首先我们要明白,cookie是用来做什么的?
Cookie 是客户端保存用户信息的一种方式。(除此之外还有localStorage,sessionStorage)
由于HTTP协议是无连接,无状态的。
它就像给服务器写信一样,每个请求都是一封单独的信,服务端想要识别这每封信,
也就需要信上写上自己的地址。 因此引进了Cookie概念,客户端带上自己的Cookie去请求服务器
Cookie可以记录客户端一些信息,在每次发送HTTP请求的时候带上Cookie字段告诉服务器
服务器可以通过客户端的Cookie来识别用户,比如说就可以让用户直接登录,之类的
Cookie的工作流程
Set-Cookie: ...存在的安全隐患
既然Cookie是客户端保存的,那么就存在安全隐患
我们可以伪造HTTP请求,伪造Cookie字段,发送给服务器
....
Cookie: user=zmj服务器误以为我们是用户zmj,返回了用户的相关信息
那么应该怎么解决这个安全隐患呢?就引入了Session的概念
首先,我们思考,可以在Cookie工作流程的第三步中做手脚
想到一个方案,在服务器响应客户端,设置Cookie的时候,我们加密这个用户,让这个客户端就看不懂了
Set-Cookie: user=213d21shxfk97dmcxuids那谁服务端怎么看懂它呢?
服务端把这个加密过后的东西叫做session_id,存在数据结构中,与User做一个映射
# 生成一个随机id
session_id = random_str()
# 与用户做映射
session[session_id] = username
# 设置Cookie
headers['Set-Cookie'] = 'user=' +session_id 下次客户端发请求就会携带上这个一段乱码样的字符串
request
...
Cookie: user=213d21shxfk97dmcxuids那么我服务端就可以通过session[cookie]获取到这段乱码对应的是哪个用户
session持久化就是重启服务器后仍然可以使用
一般有两种实现方式
通过Session就能正确保证用户的安全了吗?
不是的,虽然我作为一个坏人看不懂Cookie是啥
但我可以如果截取到了你的HTTP请求,我知道你给服务器发送的Cookie是这个字段,那我照样可以伪造成你去做坏事
那这个怎么解决呢?就要通过HTTPS了,通过HTTPS我们加密HTTP请求。
HTTPS协议,简单来说,客户端有一个公钥,服务端有一个私钥。
有人说async是是异步编程的终极解决方案,确实很优雅~
但实质上async函数其实就是generator的语法糖
使用async来改写例子
var readFile = function(filename) {
return new Promise((resolve, reject) => {
fs.readFile(filename, (err, data) => {
if (err) {
reject(err)
}
resolve(data)
})
})
}
var read = async function () {
var file1 = await readFile('1.txt')
console.log('file1', file1.toString())
var file2 = await readFile('2.txt')
console.log('file2', file2.toString())
var file3 = await readFile('3.txt')
console.log('file3', file3.toString())
}
read()其实和generator很相像
优点主要体现在以下几点
react-router等前端路由的原理大致相同,可以实现无刷新的条件下切换显示不同的页面。路由的本质就是页面的URL发生改变时,页面的显示结果可以根据URL的变化而变化,但是页面不会刷新。
基本实现方式有两种
改变url的hash值是不会刷新页面的
使用方法:
// 使用前页面http://localhost:3000
window.location.hash='/discover'
// 使用后页面http://localhost:3000/#/3000url中多了一个#号的hash值,然后我们可以通过监听url中的hash值变化,来显示不同的页面,从而实现前端路由
优点是兼容性比较好,仅 hash 符号之前的内容会被包含在请求中,如 http://www.abc.com,因此对于后端来说,即使没有做到对路由的全覆盖,也不会返回 404 错误。
缺点是不太美观
history是HTML5提供的一个对象
提供了两个方法history.pushState和history.replaceState
这两者的区别,前者是push进去当前地址状态,后者是修改当前地址状态,也不会引起浏览器的刷新
它像一个栈,可以让我们将浏览器地址历史记录push到栈中
// 初始值:http://localhost:3000
// http://localhost:3000/test
window.history.pushState(null, null, "test");
// http://localhost:3000/test/book
window.history.pushState(null, null, "test/book");
// http://localhost:3000/test/book#/hello
window.history.pushState(null, null, "#/hello");
// http://localhost:3000/test/book?name=
window.history.pushState(null, null, "?name=");
// http://localhost:3000/test/book#/hello
window.history.back()
// http://localhost:3000/test/book?name=
window.history.forward()然后我们push进去的状态,可以通过前进,后退来控制
优点是比较美观,不带#
缺点是需要后端配合,不然刷新就会发送http请求,导致404错误
react-router中有三种组件
对于每个react-router项目来说, 核心就是路由器组件.
react-router-dom提供了两个路由器
两者的区别
// <BrowserRouter>
http://example.com/about
// <HashRouter>
http://example.com/#/about如果你想兼容老式浏览器,你应该使用。
一般来说使用第一个.
有两种
Route是react-router中最重要的组件, 负责路由的匹配, 一般和Link结合使用
Route的用法.
// 如果路径是/about, 则显示组件About
<Route path="/about" component={About}></Route>有一点需要注意, 如果有两个路由匹配组件
<Route path="/about" component={About}></Route>
<Route path="/about/resume" component={Resume}></Route>如路径是/about, 则两个组件均会被渲染.
如果要完全匹配, 需要加上exact关键字
<Route exact path="/about" component={About}></Route>Link的用法
Link类似于HTML中的a标签, 使用它可以跳转到指定的URL
// 点击即可跳到about界面
<Link to="/about">about</Link>
<Route exact path="/about" component={About}></Route>Switch有点类似我们js中的switch语法, 它与Route组合使用
<Switch>
<Route exact path="/" component={Main}></Route>
<Route path="/about" component={About}></Route>
<Route path="/topics" component={Topics}></Route>
</Switch>Switch只渲染一个与之匹配的地址, 找到一个与之匹配的地址后, 就会结束.
当路由路径和当前路径成功匹配,会生成一个对象,我们叫它match.
match对象包含了很多url和path的信息.
第三个属性需要例子来理解=.=
举个栗子
<Route path="/Home/:name" component={HomePage} />
const HomePage = ({ match }) => (
<div>
<h1> parameter => {match.params.name}
</div>
);在这个例子中match.params.name 就是 从Route中传来的:name属性
Route组件特别重要,因此来详细了解一下Route组件
Route组件有三个可以来定义渲染内容的props
<Route path='/page' component={Page} />
const extraProps = { color: 'red' }
<Route path='/page' render={(props) => (
<Page {...props} data={extraProps}/>
)}/>
<Route path='/page' children={(props) => (
props.match
? <Page {...props}/>
: <EmptyPage {...props}/>
)}/>component参数与render参数的组件是用很大的区别的。使用component参数的组件会使用React.createElement来创建元素,使用render参数的组件则会调用render函数。如果我们定义一个内联函数并将其传给component参数,这将会比使用render参数慢很多。
很多前端er认为深拷贝很难,其实我觉得主要是网上很多文章代码虽然实现了深拷贝,但代码冗余度很高,确实是不利于阅读。
首先我给出下面这个对象
var obj = {
name: "muyiy",
book: {
title: "You Don't Know JS",
price: "45",
b: {
name: '小b',
age: 18,
next: {
name: '小二'
}
}
},
a1: undefined,
a2: null,
a3: 123
}深拷贝与浅拷贝的区别就在于层级,浅拷贝只会复制一层的属性,深拷贝会完整的复制整个对象
我们不考虑任何特殊情况,实现一个简单的深拷贝(其实就是DFS遍历)
function cloneDeep(obj) {
var res = {}
for(var key in obj) {
if (obj.hasOwnProperty(key)) {
var value = obj[key]
if (typeof(value) == 'object') {
res[key] = cloneDeep(value)
} else {
res[key] = value
}
}
}
return res
}这个函数是有问题的,遍历我们给出的obj对象时,a2: null复制失败了,因为我们判断对象的函数很粗糙
引出第一个问题:
复制一些特殊对象(像Function,Date,Regexp...等)时要单独处理,比较复杂
所以我们只对普通的对象进行处理
// 更精确的判断object函数
function isObject (obj) {
return Object.prototype.toString.call(obj) == '[object Object]'
}然后我们看看还存在了什么问题?
然后看看其他比较常见的问题
当递归的层级过深的时候,会出现栈溢出的危险,一般我们考虑使用循环来代替递归来解决栈溢出的问题
先不管怎么去用循环重构我们的深拷贝函数
思考一下,深拷贝函数设计的流程是怎么样的?
只有两个步骤
ok,那按照步骤来,我们试着用循环去遍历对象,其实这就是BFS,广度优先搜索
其实与二叉树的层序遍历异曲同工,只是我们的对象不只两个节点,而是多个节点
下面的代码均采用ES6新语法
// BFS遍历对象
const cloneDeep = (obj) => {
// q是一个队列结构,实现BFS的基础
const q = [obj]
while (q.length > 0) {
const t = q.shift()
Object.keys(t).map(key => {
const value = t[key]
// console.log(`${key}: ${value}`)
if (isObject(value)) {
q.push(value)
}
})
}
return res
}ok,遍历对象完成了,那怎么在遍历对象的时候,将拷贝对象的属性呢?
关键点在于我们怎么去复制边,这个边就是我们两个节点,原节点和克隆节点的映射关系
我们通过Map来映射我们的节点关系
在es6中有一个新的数据结构叫Map,多数静态语言中都会有,因为js中的object实质上就是一个类Map的结构,但是它的键值只能存字符串,所以它不能很好的描述两个节点的映射关系
const cloneDeep = (obj) => {
// res是我们的clone节点
const res = {}
const q = [obj]
const map = new Map()
// 建立对象节点与克隆节点的映射关系
map.set(obj, res)
while (q.length > 0) {
const t = q.shift()
Object.keys(t).map(key => {
const value = t[key]
if (isObject(value)) {
// 建立这个属性对象与克隆节点的映射关系
map.set(value, {})
q.push(value)
}
// 找到对应的克隆节点
const clone = map.get(t)
clone[key] = value
})
}
return res
}这个深拷贝就解决了我们的递归爆栈问题,它其实并不难,相对于遍历树这步的代码而言,我们只增加了三行代码就解决了拷贝这一问题
引用丢失问题,obj.a和obj.c都引用到了c对象
就像下面这样
var obj = {
a: {
name: c
}
b: c
}那是不是会丢失引用呢?当然不会,引用本就不可能丢失,只是大多数人写的深拷贝函数有问题,需要额外的来增加代码解决引用丢失问题。
闭环是个啥子情况呢?是指对象的引用链中,有一个属性引用到了之前的对象,于是引用链成了一个环形结构,也就是闭环
var a = {
b: {}
}
a.b.c = a
这种情况也很好解决,我们在更新映射关系的时候,我们加个判断,如果原节点在map中能找到,就不用创建新的克隆对象
最终版代码
const cloneDeep = (obj) => {
// res是我们的clone节点
const res = {}
const q = [obj]
const map = new Map()
// 建立对象节点与克隆节点的映射关系
map.set(obj, res)
while (q.length > 0) {
const t = q.shift()
Object.keys(t).map(key => {
const value = t[key]
if (isObject(value)) {
// 如果对象已经存在在表中,说明存在循环引用
if (map.has(value)) {
map.set(t, value)
} else {
// 建立这个属性对象与克隆节点的映射关系
map.set(value, {})
q.push(value)
}
}
// 找到对应的克隆节点
const clone = map.get(t)
clone[key] = value
})
}
return res
}其实深拷贝下来,比较重要的就两个点
怎么遍历对象,怎么建立原节点和克隆节点之间的联系
目录
React通过props自上到下传递数据,如果层级较深就会很麻烦
于是有了Context,它就像React中的全局变量,无需传递Props,组件树中就能进行数据传递
像react-redux中,传递store,就是利用了这个属性
使用Context用到了生产者消费者模式
需要两个组件
<Provider> 生产者 (通常是父节点)<Consumer> 消费者 (通常是子节点)例子
import React from 'react';
import Main from './Context/Main';
// 通过该createContext静态方法创建一个Context对象
// 这个对象包含了Provider和Context
// 传值是默认值,也可以不传
const ThemeContext = React.createContext({
background: 'red',
color: 'black'
})
class App extends React.Component() {
return (
<ThemeContext.Provider value="dark">
<Main/>
</ThemeContext.Provider>
);
}
class Main extends React.Component {
render() {
return (
<ToolBar />
)
}
}
class ToolBar extends React.Component {
render() {
return (
<ThemeContext.Consumer>
{
(theme) => {
console.log('theme', theme)
}
}
</ThemeContext.Consumer>
)
}
}
export default App;可以看见theme对象属性 跨了几个层级,传递到了ToolBar
看以看见 Provider 接收一个 value 属性,传递给Consumer组件使用
Context组件就像作用域链一样,Consumer使用 value 值的使用,会一层一层往上找,找到最近的Provider提供的value值
contextType其实就是语法糖,它约束了组件只能使用单一的context
在上面消费者写的形式不太优雅,通过contextType改写
class ToolBar extends React.Component {
// 套路,后面的ThemeContext是你定义的context
static contextType = ThemeContext
render() {
// 通过this.context可以拿到这个Provider提供的value值
const theme = this.context
return (
<h1>
{theme.background}
</h1>
)
}
}相关文章:
聊一聊我对 React Context 的理解以及应用
lazy可以动态引入组件,让组件在被需要的时候动态引入
const Counter = React.lazy(() => import('./Counter'))需要配合Suspense使用,因为组件在引入的时候需要加载,在模块还没加载出来的时候
可以通过Suspense来渲染加载状态, fallback中包裹这个加载状态
import React, {Suspense} from 'react';
<Suspense fallback={<div>Loading...</div>}>
<Counter />
</Suspense>异常捕获边界(Error boundaries)
错误边界是一种 React 组件,这种组件可以捕获并打印发生在其子组件树任何位置的 JavaScript 错误,并且,它会渲染出备用 UI
如果由于网络原因,模块加载失败,组件树崩溃,那么错误组件就会渲染出备用UI
class ErrorBoundary extends React.Component {
state = {
hasError: false
};
static getDerivedStateFromError(error) {
// 更新 state 使下一次渲染能够显示降级后的 UI
return { hasError: true };
}
componentDidCatch(error, errorInfo) {
// 你同样可以将错误日志上报给服务器
logErrorToMyService(error, errorInfo);
}
render() {
if (this.state.hasError) {
// 你可以自定义降级后的 UI 并渲染
return <h1>Something went wrong.</h1>;
}
return this.props.children;
}
}pureComponent就是帮忙实现了shouldComponentUpdate中浅层对象的对比
如果传入的props在浅层对比上没有变化,那么组件就不会被重新渲染,提高了性能。
memo是高阶组件,它和pureComponent的效果一样,它是针对于函数组件的
使用方法,用memo将函数组件包裹即可
const MyComponent = React.memo(function MyComponent(props) {
});使用class的方式使得组件很难复用,一般只有两种方式
这两者方式,特别是第二种,比较麻烦,而且不好理解
复杂组件变得难以理解
组件越来越复杂的时候,会被逻辑和副作用充斥。
import React, { useState } from 'react';
function Example() {
// 声明一个叫 “count” 的 state 变量。
const [count, setCount] = useState(0);
return (
<div>
<p>You clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>
Click me
</button>
</div>
);
}关键是userState这个函数
首先这个函数只接收一个参数, 就是初始state, useState(initState)
然后这个函数返回一对值,
然后就能通过这个函数,完美实现了原来的this.state, this.setState模式
什么时候我会用 Hook?
如果你在编写函数组件并意识到需要向其添加一些 state,以前的做法是必须将其它转化为 class。
现在你可以在现有的函数组件中使用 Hook。
在 React 组件中执行过数据获取、订阅或者手动修改过 DOM。
我们统一把这些操作称为副作用
有两种常见的副作用
在以往的class方式中,我们会在
componentDidMount、componentDidUpdate 和 componentWillUnmount中处理这些东西
现在使用 useEffect来代替它们。
function Counter() {
const [count, setCount] = React.useState(0)
React.useEffect(() => {
console.log(count)
})
return (
<div>
Count: {count}
<button onClick={() => setCount(prevCount => prevCount + 1)}>+</button>
<button onClick={() => setCount(prevCount => prevCount - 1)}>-</button>
</div>
);
}useEffect做了什么? 会在第一次渲染之后和每次更新后调用
为什么要在组件内部调用useEffect?将它放入组件内部可以直接使用state变量,这是利于到了闭包的特性
疑问1. 为什么componentDidMount 或 componentDidUpdate 会阻塞浏览器更新屏幕
与 componentDidMount 或 componentDidUpdate 不同,使用 useEffect 调度的 effect 不会阻塞浏览器更新屏幕,这让你的应用看起来响应更快。大多数情况下,effect 不需要同步地执行。在个别情况下(例如测量布局),有单独的 useLayoutEffect Hook 供你使用,其 API 与 useEffect 相同。
在class的方式中
// 在组件挂载后订阅
componentDidMount() {
ChatAPI.subscribeToFriendStatus(
this.props.friend.id,
this.handleStatusChange
);
}
// 在组件销毁后取消订购
componentWillUnmount() {
ChatAPI.unsubscribeFromFriendStatus(
this.props.friend.id,
this.handleStatusChange
);
}在hooks中,你可能认为要单独再使用一个函数来执行组件销毁后的操作
但设计仍然是在useEffect之中,如果你的 effect 返回一个函数,React 将会在执行清除操作时调用它:
useEffect(() => {
function handleStatusChange(status) {
setIsOnline(status.isOnline);
}
ChatAPI.subscribeToFriendStatus(props.friend.id, handleStatusChange);
// Specify how to clean up after this effect:
return function cleanup() {
ChatAPI.unsubscribeFromFriendStatus(props.friend.id, handleStatusChange);
};
});在上面的例子中,我们发现useEffect在每次状态更新 组件重新渲染后都会调用
可以通过useEffect第二个可选参数实现
useEffect(() => {
console.log(count)
}, [count]); // 仅在 count 更改时更新它会对更新之前的count和更新之后的count 做比对,如果发生了改变才去执行effect,否则就会跳过这个effect
注意,如果使用这种方式优化,确保数组中包含了这个useEffect中使用到的所有会随时间变化的变量
那如果我不想每次都重新渲染,比如说加载组件数据的网络请求
可能在原先的class组件上,我只想调用一次就够了,而不是每次状态更新都去重新发送请求
可以给第二个参数传一个空数组
// 只会执行一次了
useEffect(() => {
// ...ajax请求
}, [])其实原理是一样的,由于传了空数组,下一次更新的空数组等于第一次更新的空数组,所以就会跳过下一次更新
使用起来比class的方式方便很多
// 创建一个
const CounterContext = createContext(0)
function Counter() {
return (
<CounterContext.Provider value={count}>
<Bar></Bar>
</CounterContext.Provider>
)
}
// 而且使用多个context也是可以的
function Bar() {
const count = useContext(CounterContext)
return (
<h1>{count}</h1>
)
}相关文章
官方文档
CSRF的全称是(Cross-site requst forgery)
翻译为中文是:跨站请求伪造
举个例子。
一天,小明输入了账号密码登录了自己的邮箱(登录后 qq邮箱保存了用户的cookie)
然后,小明在浏览自己的邮件的时候,发现一封可疑邮件
title: 免费领取999块红包
content:点击 test 立即获取
抱着看一看的想法,小明点击了这个链接
这时候,小明进入了test页面后(cookie也会传过来)
那么坏人拥有了小明的cookie,于是乎可以坏人就可以伪造小明的请求,让服务器误认为是小明在操作
<!--test.html页面代码-->
<body>
<h1> 哈哈,逗你玩的 </h1>
<form action="https://xxxx.com/post" id="form" method="post" style="visibility:hidden" target="hiddenIframe">
<input type="text" name="giftId" value="ab231">
</form>
<script>
document.getElementById('form').submit();
</script>
</body>然后坏人就可以通过这个方式,冒充用户执行某项操作
一个典型的CSRF攻击有以下步骤
从例子能看出,CSRF攻击一般是跨域的,攻击者网站向正规网站发送攻击请求
它有两个很重要的特点
一般防护手段有两种
既然CSRF攻击大多都来自第三方网站
那么我们在一些用户敏感操作的时候,判断请求来源是不是外域的,如果是外域请求就禁止
比如在银行页面转账操作时
我们限定死,只能从A按钮跳到B页面进行转账,对于其他的来源,全部禁止
假设攻击者拿到了用户信息cookie,他填写好各种信息,像B页面发起转账请求,
这时候,用户者的请求来源就是他自己所在的网站,所以攻击就失败了
那怎么确定请求来源呢?
HTTP请求里有一个字段referer,记录请求的来源,通过这个字段判断就可以
但是这个字段是由浏览器来保证的,有可能用户会删除,而且黑客可能伪造请求的时候去掉这个字段。
所以一般处理方式是对没有请求来源的请求全部禁止掉
这个Token防御措施,很多文章讲的都不清楚=。=!,或者说就直接乱讲一通,强力谴责!
CSRF之所以成功,是因为服务端把伪造的请求误认为是正常请求
现在我们使用Token技术,大概是以下步骤
但是有两个很重要的问题
对于第一个问题,有两个步骤
<input type="hidden" name="_csrf_token" value="xxxx">,或者说在ajax请求头中携带上这个字段又放到cookie里?那岂不是攻击者又可以通过cookie攻击了?
别急,看第二个问题
对于第二个问题
我们要注意CSRF的本质,CSRF是伪造用户的状态,去模拟用户发送请求,它只能使用cookie,但是它是拿不到cookie里面的信息的
因此我们的Token只有同源页面可以读取,并放在表单中
CSRF虽然使用了cookie,但是它拿不到这个Token值,伪造的请求中也就带不上Token值,所以就被防止掉了。
参考文章:
前端安全系列之二:如何防止CSRF攻击?
关于Token抵御CSRF攻击的疑问
CSRF防御,token保存在服务器session中,客户端是如何获取token?
描述Buffer之前,先需要了解js的一些比较底层的原生知识
ArrayBuffer 对象来表示通用的,固定长度的原始二进制数据缓冲区。
简单说,ArrayBuffer就是一块内存,不方便直接用它,就像C语言 malloc申请一块内存,也会把它转换为实际上所需要的数组/指针来使用
它只是一堆01串,并不知道字节有多长,该用多少位去存
new ArrayBuffer(length): length代表申请ArrayBuffer的大小,单位为字节
我们可以通过Int8类型的数组,告诉ArrayBuffer,你需要将01串分割成以8位为一组的序列
就像这样
var buffer = new ArrayBuffer(1024)
var arr = new Int8Array(buffer) // 使用buffer创建一个8位的数组,
// 一个字节=8位,所以数组长度是1024在js中,你找不到名为TypedArray的构造函数,其实它只是一个名称,是下面几个类型的统称
简单说,它的作用就是告诉ArrayBuffer应该以怎样的形式来分离存放二进制字节
有了前面的基础后,我们来看看node中的Buffer类
Buffer实例其实也是Uint8Array的实例,但是与TypedBuffer有一些微小的不同
例如:TypedBuffer.slice方法会创建一个新的数组拷贝
而Buffer.slice会在原先的数组上做修改
在Node 6.0之前,Buffer实例是由Buffer构造函数创建的
var buffer = new Buffer(10)但是这种方式存在两个问题
具体的安全隐患例子:
第一个参数如果是100,new Buffer("100")会为字符串"100"分配三个字节的内存本来我的程序中是默认接收字符串来分配内存的,但是攻击者如果恶意的传入很大的数字9999999999999
就会导致
new Buffer(999999999999)申请了一个超大内存,导致内存耗尽,服务器奔溃
所以新的Buffer提供了四个方法来申请内存
Buffer.from()是根据已有的数据创建Buffer实例,不接收数字为参数
Buffer.from(obj) // obj支持array, arrayBuffer, buffer, Buffer.alloc()是申请内存,
Buffer.alloc(size) // 分配size大小的内存,并填充为0这两者和alloc的区别就是
alloc会将字节填充为0,
这两个不会做填充,分配的内存没有初始化,可能是旧内存,所以不安全,也就更快了
常见的就是对Buffer进行转换,转换为字符串转换为JSON,一般通过toXXX就可以实现了
Buffer的行为更类似于静态语言里的数组,而不像传统的js数组
如slice方法不会创建新数组,而是在原数组上做修改
长度一但确定就不会再发生改变
...
具体增删,读写,清空合并可以查API
更重要的是在流中,使用到了Buffer进行传输
Redux自身提供了很强大的数据流管理功能,当Redux不满足我们要求的时候,开发者可以通过扩展增强Redux的功能
一般有两种方式扩展Redux
Redux中间件原理图解
在派发一些特殊action的时候,中间件可以拦截,中间件先将这个action进行处理后,再交给下一个中间件,依次最后交付给原生的dispatch处理
中间件的特定
来看一个最简单的中间件例子
function doNothingMiddleware({dispatch, getState}) {
return function(next) {
return function(action) {
return next(action)
}
}
}看起来很复杂吧,其实不然,现在分析一下这个中间件
接收一个对象为参数,对象参数有两个函数dispatch,getState
这代表Redux上两个同名函数
doNothingMiddleware返回的函数接收一个next类型的参数
redux-thunk源码非常的简单,只有十行不到
function createThunkMiddleware(extraArgument) {
return ({ dispatch, getState }) => next => action => {
if (typeof action === 'function') {
return action(dispatch, getState, extraArgument);
}
return next(action);
};
}
const thunk = createThunkMiddleware();
thunk.withExtraArgument = createThunkMiddleware;
export default thunk;代码很容易看懂,redux-thunk执行时,发现action是函数,于是执行这个action,否则就直接交给下一个中间件处理
写一个Logger中间件
// logger.js
const logger = ({dispatch, getState}) => next => action => {
console.group(action.type)
console.log('dispathching:', action)
const result = next(action)
console.log('next state:', getState())
console.groupEnd()
return result
}
export default logger
// store.js
const store = createStore(rootReducer, applyMiddleware(logger))再看一遍图,理解中间件的在Redux数据流动中的位置
中间件可以用来增强Redux Store的dispatch方法,但是也仅限于dispatch方法
Store Enhancer可以对Redux Store进行更深度的定制,比中间件更强大(事实上中间件applyMiddleware也是作为一个store enhancer)
怎么用呢?
createStore(reducer, [preloadedstate], [enhancer])
createStore的第三个参数就是我们要传入的Enhancer
看一个什么都不做的Enhancer的例子
const doNothingEnhancer = (createStore) => (reducerpreloadedState, enhancer) => {
const store = createStore(reducer, preloadedState, enhancer)
return store
}最里层的函数可以拿到createStore函数,然后最里层的函数接收三个参数,通过这三个参数,创造出一个store对象,然后定制store对象,最后返回store对象就可以了
自己写一个logEnhancer
const logger = createStore => (...args) => {
const store = createStore(...args)
const dispatch = (action) => {
console.group(action.type)
console.log('dispathching:', action)
const result = store.dispatch(action)
console.log('next state:', getState())
console.groupEnd()
return result
}
return {...store, dispatch}
}
export default loggerenhancer一般都是这样的套路
这个例子中,增强了dispatch方法的功能
使用compose可以组合多个Store Enhancer
import { createStore, applyMiddleware, compose } from 'redux'
import rootReducer from './reducers'
import logger from './middleare/logger';
import logEnhancer from './enhancers/logger'
const store = createStore(rootReducer, compose(applyMiddleware(logger), logEnhancer))
export default store这一章是介绍构建高质量组件的原则和方法
React组件的数据只分为两种:prop和state
无论prop或者state发生改变,都可能引发组件的重新渲染
使用这两者的原则是:
对外使用prop,对内使用state
在React中, prop是从外部传递给组件的数据。
每个React组件都是独立存在的模块,组件之外都是外部世界,外部世界就是通过prop跟组件进行对话的
class ControlPanel extends Component {
render() {
return (
<div>
<Counter caption="First" initValue={0} />
<Counter caption="Second" initValue={10} /> <Counter caption="Third" initValue={20} />
</div>
);
}
}
class Counter extends Component {
constructor(props) {
// 如果要用this,必须调用super()
super(props)
this.state = {
count: props.initValue || 0
}
this.onClickIncrementButton = this.onClickIncrementButton.bind(this)
this.onClickDecrementButton = this.onClickDecrementButton.bind(this)
}
onClickIncrementButton() {
var count = this.state.count + 1
this.setState({
count
})
}
onClickDecrementButton() {
var count = this.state.count - 1
this.setState({
count
})
}
render() {
const { caption } = this.props
return (
<div>
<button style={style} onClick={this.onClickIncrementButton} >+</button>
<button style={style} onClick={this.onClickDecrementButton} >-</button>
<span>{ caption } count: {this.state.count}</span>
</div>
)
}
}ControlPanel组件给Counter组件传递了两个prop属性caption和initValue
propTypes
因为prop是组件的对外接口,以防传进来的东西混杂,应该制定良好的接口规范
通过propTypes即可实现约束我们的prop
Counter.propTypes = {
caption: PropTypes.string.isRequired, // caption必须是字符串并且必须要填
initValue: PropTypes.number // initValue必须是数字,可不填
}state代表组件的内部状态,是对内的。
React不能修改传入的prop,记录自身数据变化就需要用到state
上面的例子也说明了
要更新state必须使用setState方法,不能直接修改
React的生命周期分为三个阶段
如图所示
讲解
constructor()也就是ES6中的构造函数。
注意:并不是每个组件都需要定义构造函数,无状态组件就不需要定义构造函数
一个React组件需要定义构造函数的原因一般有几点:
尽量不要去动它
render函数无疑是React组件中最重要的函数,一个React组件可以忽略
其他所有函数都不实现,但是一定要实现render函数,因为所有React组件的
父类React.Component类对除render之外的生命周期函数都有默认实现.
render()函数并不会做实际上的渲染动作,它只是返回JSX描述的结构,最终由React完成渲染。
需要注意,render函数应该是一个纯函数,完全根据this.state和this.props
来决定返回的结果,而且不要产生任何副作用
componentDidMount在render函数之后被调用
组件渲染完成后调用。
shouldComponentUpdate(nextProps, nextState)
render和shouldComponentUpdate函数,也是React生命周期函数中唯二两
个要求有返回结果的函数
render函数的返回结果将用于构造DOM对象,而
shouldComponent-Update函数返回一个布尔值,告诉React库这个组件在这次
更新过程中是否要继续。
值得一提的是,通过this.setState函数引发更新过程,并不是立刻更新组件的state值,在执行到到函数shouldComponentUpdate的时候,this.state依然是this.setState函数执行之前的值,所以我们要做的实际上就是在nextProps、nextState、this.props和this.state中互相比对。
在JavaScript中,我们可以将作用域定义为一套规则,这套规则用来管理引擎如何在当前作用域以及嵌套的子作用域中根据标识符(变量名和函数名)名称进行变量查找
作用域链其实是个很简单的东西,当前执行上下文如果找不到这个变量对象,就会往上层找,这样多个执行上下文的变量对象构成的链表就叫做作用域链
举个例子
var a = 20;
function test() {
var b = a + 10;
function innerTest() {
var c = 10;
return b + c;
}
return innerTest();
}
test();innerTest的执行上下文可表示为
innerTestEC = {
VO: {...}, // 变量对象
scopeChain: [VO(innerTest), VO(test), VO(global)], // 作用域链
}闭包是个特殊的对象。
它由两部分组成。
当B执行的时候,如果访问了A中变量对象的值,那么闭包就会产生。
在大多数理解中,包括许多著名的书籍,文章里都以函数B的名字代指这里生成的闭包。而在chrome中,则以执行上下文A的函数名代指闭包。
因此我们只需要知道,一个闭包对象,由A、B共同组成
闭包例子
var a = 30
function foo() {
var a = 20
return function() {
return a
}
}
console.log(foo()())举个更实际的例子,写一个迭代器
const createIterator = (items) => {
var i = 0
return {
next: () => {
const done = (i >= items.length)
return {
value: items[i++],
done
}
}
}
}A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.