- 笔记向,不定期更新。
- 没有太多需要理解的东西,需要理解的部分自行学习。
- 自己总结,如果有错的地方欢迎指正。
- 以下所有内容均来自于互联网
- 部分内容为个人整理和提炼,侵删。
- 找到工作了。。。可能维护缓慢了,有兴趣一起维护的可以私聊我
-
索引相关
- 什么是索引
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。 - 什么时候使用索引
能够提升效率的时候使用索引。- 在作为主键的列上,唯一性约束的列(不过大部分数据库会自动加索引);
- 在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度;
- 在经常需要排序的列上创建索引,这样查询可以利用索引的排序,加快排序查询时间;
- 在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
- 什么时候不能使用索引
不能够提升效率的时候不使用索引,例如:该列很少进行查找或排序操作 - 什么时候索引会失效
- 查询的结果太大,性能消耗大于使用索引
- where里面存在!=
- 模糊查询的时候,通配符在第一个
- where查询null值
- 什么是索引
-
数据库连接方法
- DriverManager
Connection conn = DriverManager.getConnection("连接URL","用户名","密码"); PreparedStatement ps = conn.prepareStatement(sql); ps.setInt(index, value); ps.executeUpdate() //或者 Statement stmt=conn.createStatement(); stmt.executeUpdate(sql)...
- 用JDBC连接池,如C3P0
-
事务(Transaction)
- 事务是是一个操作序列,这些操作要么都执行,要么都不执行,它是一个不可分割的工作单位。
- 事务的四个属性
- 原子性 Atomic
就是事务应作为一个工作单元,事务处理完成,所有的工作要么都在数据库中保存下来,要么完全回滚,全部不保留 - 一致性 Consistent
事务完成或者撤销后,都应该处于一致的状态 - 隔离性 Isolated
多个事务同时进行,它们之间应该互不干扰.应该防止一个事务处理其他事务也要修改的数据时,不合理的存取和不完整的读取数据 - 永久性 Durable
事务提交以后,所做的工作就被永久的保存下来
- 原子性 Atomic
-
什么是存储过程?有哪些优缺点?
存储过程是一些预编译的SQL语句。
更加直白的理解:存储过程可以说是一个记录集,它是由一些SQL语句组成的代码块,这些SQL语句代码像一个方法一样实现一些功能(对单表或多表的增删改查),然后再给这个代码块取一个名字,在用到这个功能的时候调用他就行了。- 存储过程是一个预编译的代码块,执行效率比较高
- 一个存储过程替代大量SQL语句 ,可以降低网络通信量,提高通信速率
- 可以一定程度上确保数据安全
-
简单说一说drop、delete与truncate这三种删除的区别
- delete和truncate只删除表的数据不删除表的结构
- 速度,一般来说: drop> truncate >delete
- delete语句是dml,这个操作会放到rollback segement中,事务提交之后才生效;如果有相应的trigger,执行的时候将被触发。truncate,drop是ddl, 操作立即生效,原数据不放到rollback segment中,不能回滚,操作不触发trigger。
使用场景
- 不再需要一张表的时候,用drop
- 想删除部分数据行时候,用delete,并且带上where子句
- 保留表而删除所有数据的时候用truncate
-
超键、候选键、主键、外键分别是什么?
- 超键:在关系中能唯一标识元组的属性集称为关系模式的超键。
- 候选键:没有冗余元素的超键。
- 主键:可以唯一地标识表中的某一条记录的键(和候选键一样,只不过一个表只能有一个主键)
- 外键:在一个表中存在的另一个表的主键称此表的外键。
-
什么是视图?以及视图的使用场景有哪些?
视图是一种虚拟的表,具有和物理表相同的功能。可以对视图进行增,改,查,操作,试图通常是有一个表或者多个表的行或列的子集。对视图的修改不影响基本表。它使得我们获取数据更容易,相比多表查询。- 只暴露部分字段给访问者,所以就建一个虚表,就是视图。
- 查询的数据来源于不同的表,而查询者希望以统一的方式查询,这样也可以建立一个视图,把多个表查询结果联合起来,查询者只需要直接从视图中获取数据,不必考虑数据来源于不同表所带来的差异
-
三大范式
- 第一范式(1NF):数据库表中的字段都是单一属性的,不可再分;
- 第二范式(2NF):数据库表中不存在字段对任一候选关码段的部分函数依赖;
- 第三范式(3NF):数据表中如果不存在字段对任一候选码字段的传递函数依赖。
-
DML、DDL、DCL区别
- DML(Data Manipulation Language,数据操作语言)
如:SELECT、UPDATE、INSERT、DELETE,这4条命令是用来对数据库里的数据进行操作的语言 - DDL(Data Definition Language,数据定义语言)
主要的命令有CREATE、ALTER、DROP等,DDL主要是用在定义或改变表的结构,数据类型,表之间的链接和约束等初始化工作上,他们大多在建立表时使用 - DCL(Data Control Language,数据控制语言)
用来设置或更改数据库用户或角色权限的语句,包括grant,deny,revoke等语句。
-
sql的join
- JOIN: 如果表中有至少一个匹配,则返回行
- LEFT JOIN: 即使右表中没有匹配,也从左表返回所有的行
- RIGHT JOIN: 即使左表中没有匹配,也从右表返回所有的行
- FULL JOIN: 只要其中一个表中存在匹配,就返回行
-
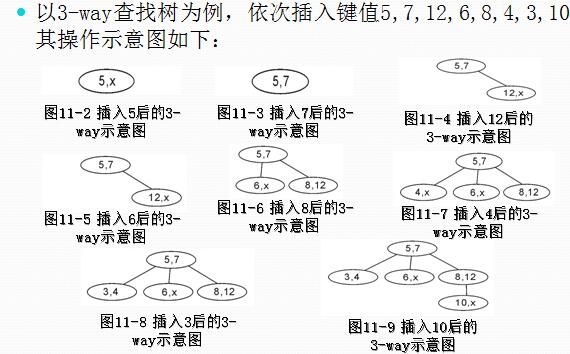
B-tree
- 假设B-tree为m阶
- 树中每个结点至多有m个孩子;
- 除根结点和叶子结点外,其它每个结点至少有有ceil(m / 2)个孩子;
- 若根结点不是叶子结点,则至少有2个孩子(特殊情况:没有孩子的根结点)
- 【不懂】所有叶子结点都出现在同一层,叶子结点不包含任何关键字信息(可以看做是外部结点或查询失败的结点,实际上这些结点不存在,指向这些结点的指针都为null);
- 每个非终端结点中包含有n个关键字信息: (P0,K1,P1,K2,P2,......,Kn,Pn)。其中:
- Ki (i=1...n)为关键字,且关键字按顺序排序K(i-1)< Ki。
- Pi为指向子树根的结点,且指针P(i-1)指向子树中所有结点的关键字均小于Ki,但都大于K(i-1)。
- 关键字的个数n必须满足: ceil(m / 2)-1 <= n <= m-1。
- 插入过程:
-
spring 的优点?
- 降低了组件之间的耦合性;
- 提供了众多服务,如事务管理等
- 容器提供单例模式支持
- 容器提供了AOP技术,利用它很容易实现运行期监控等功能
- spring对于主流的应用框架提供了集成支持,如hibernate等
- spring属于低侵入式设计,代码的污染极低
- 独立于各种应用服务器
- spring的IOC机制降低了业务对象替换的复杂性
- Spring的高度开放性,并不强制应用完全依赖于Spring,开发者可以自由选择spring的部分或全部
-
IOC
- 在Java开发中,IoC意味着将你设计好的类交给系统去控制,而不是在你的类内部控制。
- 举个例子:以前的买东西是你和商家直接交易,而IOC之后,变成了你和淘宝交易,淘宝和商家交易。
- 我觉得就是在一个map里面存上类的具体路径,然后反射实现的
-
AOP
这种在运行时,动态地将代码切入到类的指定方法、指定位置上的编程**就是面向切面的编程。一般都用于日志等地方。
- #{}和${}的区别是什么?
- ${}是Properties文件中的变量占位符,它可以用于标签属性值和sql内部,属于静态文本替换,比如${driver}会被静态替换为com.mysql.jdbc.Driver。#{}是sql的参数占位符,Mybatis会将sql中的#{}替换为?号,在sql执行前会使用PreparedStatement的参数设置方法,按序给sql的?号占位符设置参数值,比如ps.setInt(0, parameterValue),#{item.name}的取值方式为使用反射从参数对象中获取item对象的name属性值,相当于param.getItem().getName()。
- Xml映射文件中,除了常见的select|insert|updae|delete标签之外,还有哪些标签?
- 还有很多其他的标签,、、、、,加上动态sql的9个标签,trim|where|set|foreach|if|choose|when|otherwise|bind等,其中为sql片段标签,通过标签引入sql片段,为不支持自增的主键生成策略标签。
- 最佳实践中,通常一个Xml映射文件,都会写一个Dao接口与之对应,请问,这个Dao接口的工作原理是什么?Dao接口里的方法,参数不同时,方法能重载吗?
- Dao接口,就是人们常说的Mapper接口,接口的全限名,就是映射文件中的namespace的值,接口的方法名,就是映射文件中MappedStatement的id值,接口方法内的参数,就是传递给sql的参数。Mapper接口是没有实现类的,当调用接口方法时,接口全限名+方法名拼接字符串作为key值,可唯一定位一个MappedStatement,举例:com.mybatis3.mappers.StudentDao.findStudentById,可以唯一找到namespace为com.mybatis3.mappers.StudentDao下面id = findStudentById的MappedStatement。在Mybatis中,每一个、、、标签,都会被解析为一个MappedStatement对象。 Dao接口里的方法,是不能重载的,因为是全限名+方法名的保存和寻找策略。 Dao接口的工作原理是JDK动态代理,Mybatis运行时会使用JDK动态代理为Dao接口生成代理proxy对象,代理对象proxy会拦截接口方法,转而执行MappedStatement所代表的sql,然后将sql执行结果返回。 Mybatis是如何进行分页的?分页插件的原理是什么? 答:Mybatis使用RowBounds对象进行分页,它是针对ResultSet结果集执行的内存分页,而非物理分页,可以在sql内直接书写带有物理分页的参数来完成物理分页功能,也可以使用分页插件来完成物理分页。 分页插件的基本原理是使用Mybatis提供的插件接口,实现自定义插件,在插件的拦截方法内拦截待执行的sql,然后重写sql,根据dialect方言,添加对应的物理分页语句和物理分页参数。 举例:select * from student,拦截sql后重写为:select t.* from (select * from student)t limit 0,10 简述Mybatis的插件运行原理,以及如何编写一个插件。 答:Mybatis仅可以编写针对ParameterHandler、ResultSetHandler、StatementHandler、Executor这4种接口的插件,Mybatis使用JDK的动态代理,为需要拦截的接口生成代理对象以实现接口方法拦截功能,每当执行这4种接口对象的方法时,就会进入拦截方法,具体就是InvocationHandler的invoke()方法,当然,只会拦截那些你指定需要拦截的方法。 实现Mybatis的Interceptor接口并复写intercept()方法,然后在给插件编写注解,指定要拦截哪一个接口的哪些方法即可,记住,别忘了在配置文件中配置你编写的插件。 Mybatis动态sql是做什么的?都有哪些动态sql?能简述一下动态sql的执行原理不? 答:Mybatis动态sql可以让我们在Xml映射文件内,以标签的形式编写动态sql,完成逻辑判断和动态拼接sql的功能,Mybatis提供了9种动态sql标签trim|where|set|foreach|if|choose|when|otherwise|bind。 其执行原理为,使用OGNL从sql参数对象中计算表达式的值,根据表达式的值动态拼接sql,以此来完成动态sql的功能。 Mybatis是如何将sql执行结果封装为目标对象并返回的?都有哪些映射形式? 答:第一种是使用标签,逐一定义列名和对象属性名之间的映射关系。第二种是使用sql列的别名功能,将列别名书写为对象属性名,比如T_NAME AS NAME,对象属性名一般是name,小写,但是列名不区分大小写,Mybatis会忽略列名大小写,智能找到与之对应对象属性名,你甚至可以写成T_NAME AS NaMe,Mybatis一样可以正常工作。 有了列名与属性名的映射关系后,Mybatis通过反射创建对象,同时使用反射给对象的属性逐一赋值并返回,那些找不到映射关系的属性,是无法完成赋值的。 Mybatis能执行一对一、一对多的关联查询吗?都有哪些实现方式,以及它们之间的区别。 答:能,Mybatis不仅可以执行一对一、一对多的关联查询,还可以执行多对一,多对多的关联查询,多对一查询,其实就是一对一查询,只需要把selectOne()修改为selectList()即可;多对多查询,其实就是一对多查询,只需要把selectOne()修改为selectList()即可。 关联对象查询,有两种实现方式,一种是单独发送一个sql去查询关联对象,赋给主对象,然后返回主对象。另一种是使用嵌套查询,嵌套查询的含义为使用join查询,一部分列是A对象的属性值,另外一部分列是关联对象B的属性值,好处是只发一个sql查询,就可以把主对象和其关联对象查出来。 那么问题来了,join查询出来100条记录,如何确定主对象是5个,而不是100个?其去重复的原理是标签内的子标签,指定了唯一确定一条记录的id列,Mybatis根据列值来完成100条记录的去重复功能,可以有多个,代表了联合主键的语意。 同样主对象的关联对象,也是根据这个原理去重复的,尽管一般情况下,只有主对象会有重复记录,关联对象一般不会重复。 举例:下面join查询出来6条记录,一、二列是Teacher对象列,第三列为Student对象列,Mybatis去重复处理后,结果为1个老师6个学生,而不是6个老师6个学生。 t_id t_name s_id | 1 | teacher | 38 | | 1 | teacher | 39 | | 1 | teacher | 40 | | 1 | teacher | 41 | | 1 | teacher | 42 | | 1 | teacher | 43 | Mybatis是否支持延迟加载?如果支持,它的实现原理是什么? 答:Mybatis仅支持association关联对象和collection关联集合对象的延迟加载,association指的就是一对一,collection指的就是一对多查询。在Mybatis配置文件中,可以配置是否启用延迟加载lazyLoadingEnabled=true|false。 它的原理是,使用CGLIB创建目标对象的代理对象,当调用目标方法时,进入拦截器方法,比如调用a.getB().getName(),拦截器invoke()方法发现a.getB()是null值,那么就会单独发送事先保存好的查询关联B对象的sql,把B查询上来,然后调用a.setB(b),于是a的对象b属性就有值了,接着完成a.getB().getName()方法的调用。这就是延迟加载的基本原理。 当然了,不光是Mybatis,几乎所有的包括Hibernate,支持延迟加载的原理都是一样的。 Mybatis的Xml映射文件中,不同的Xml映射文件,id是否可以重复? 答:不同的Xml映射文件,如果配置了namespace,那么id可以重复;如果没有配置namespace,那么id不能重复;毕竟namespace不是必须的,只是最佳实践而已。 原因就是namespace+id是作为Map<String, MappedStatement>的key使用的,如果没有namespace,就剩下id,那么,id重复会导致数据互相覆盖。有了namespace,自然id就可以重复,namespace不同,namespace+id自然也就不同。 Mybatis中如何执行批处理? 答:使用BatchExecutor完成批处理。 Mybatis都有哪些Executor执行器?它们之间的区别是什么? 答:Mybatis有三种基本的Executor执行器,SimpleExecutor、ReuseExecutor、BatchExecutor。 SimpleExecutor:每执行一次update或select,就开启一个Statement对象,用完立刻关闭Statement对象。 ReuseExecutor:执行update或select,以sql作为key查找Statement对象,存在就使用,不存在就创建,用完后,不关闭Statement对象,而是放置于Map<String, Statement>内,供下一次使用。简言之,就是重复使用Statement对象。 BatchExecutor:执行update(没有select,JDBC批处理不支持select),将所有sql都添加到批处理中(addBatch()),等待统一执行(executeBatch()),它缓存了多个Statement对象,每个Statement对象都是addBatch()完毕后,等待逐一执行executeBatch()批处理。与JDBC批处理相同。 作用范围:Executor的这些特点,都严格限制在SqlSession生命周期范围内。 Mybatis中如何指定使用哪一种Executor执行器? 答:在Mybatis配置文件中,可以指定默认的ExecutorType执行器类型,也可以手动给DefaultSqlSessionFactory的创建SqlSession的方法传递ExecutorType类型参数。 Mybatis是否可以映射Enum枚举类? 答:Mybatis可以映射枚举类,不单可以映射枚举类,Mybatis可以映射任何对象到表的一列上。映射方式为自定义一个TypeHandler,实现TypeHandler的setParameter()和getResult()接口方法。TypeHandler有两个作用,一是完成从javaType至jdbcType的转换,二是完成jdbcType至javaType的转换,体现为setParameter()和getResult()两个方法,分别代表设置sql问号占位符参数和获取列查询结果。 Mybatis映射文件中,如果A标签通过include引用了B标签的内容,请问,B标签能否定义在A标签的后面,还是说必须定义在A标签的前面? 答:虽然Mybatis解析Xml映射文件是按照顺序解析的,但是,被引用的B标签依然可以定义在任何地方,Mybatis都可以正确识别。 原理是,Mybatis解析A标签,发现A标签引用了B标签,但是B标签尚未解析到,尚不存在,此时,Mybatis会将A标签标记为未解析状态,然后继续解析余下的标签,包含B标签,待所有标签解析完毕,Mybatis会重新解析那些被标记为未解析的标签,此时再解析A标签时,B标签已经存在,A标签也就可以正常解析完成了。 简述Mybatis的Xml映射文件和Mybatis内部数据结构之间的映射关系? 答:Mybatis将所有Xml配置信息都封装到All-In-One重量级对象Configuration内部。在Xml映射文件中,标签会被解析为ParameterMap对象,其每个子元素会被解析为ParameterMapping对象。标签会被解析为ResultMap对象,其每个子元素会被解析为ResultMapping对象。每一个、、、标签均会被解析为MappedStatement对象,标签内的sql会被解析为BoundSql对象。
- 为什么说Mybatis是半自动ORM映射工具?它与全自动的区别在哪里?
- 答:Hibernate属于全自动ORM映射工具,使用Hibernate查询关联对象或者关联集合对象时,可以根据对象关系模型直接获取,所以它是全自动的。而Mybatis在查询关联对象或关联集合对象时,需要手动编写sql来完成,所以,称之为半自动ORM映射工具。
- 优化Hibernate的7大措施【不懂。。】
- 尽量使用many-to-one,避免使用单项one-to-many
- 灵活使用单向one-to-many
- 不用一对一,使用多对一代替一对一
- 配置对象缓存,不使用集合缓存
- 一对多使用Bag 多对一使用Set
- 继承使用显示多态 HQL:from object polymorphism="exlicit" 避免查处所有对象
- 消除大表,使用二级缓存
-
http
- http和https区别
HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全。
HTTPS和HTTP的区别主要如下:- https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
- http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
- http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
- http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
- 说一下什么是Http协议?
对器客户端和服务器端之间数据传输的格式规范,格式简称为“超文本传输协议”。 - 什么是Http协议无状态协议?怎么解决Http协议无状态协议?(曾经去某创业公司问到)
- 无状态协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息
- 无状态协议解决办法: 通过1、Cookie 2、通过Session会话保存。
- 说一下Http协议中302状态
http协议中,返回状态码302表示重定向。这种情况下,服务器返回的头部信息中会包含一个 Location 字段,内容是重定向到的url - Http协议有什么组成?
- 请求报文 包含三部分:
- 请求行:包含请求方法、URI、HTTP版本信息
- 请求首部字段
- 请求内容实体
- 响应报文 包含三部分:
- 状态行:包含HTTP版本、状态码、状态码的原因短语
- 响应首部字段
- 响应内容实体
- 请求报文 包含三部分:
- Http协议中有那些请求方式?
- GET: 用于请求访问已经被URI(统一资源标识符)识别的资源,可以通过URL传参给服务器
- POST:用于传输信息给服务器,主要功能与GET方法类似,但一般推荐使用POST方式。
- PUT: 传输文件,报文主体中包含文件内容,保存到对应URI位置。
- HEAD: 获得报文首部,与GET方法类似,只是不返回报文主体,一般用于验证URI是否有效。
- DELETE:删除文件,与PUT方法相反,删除对应URI位置的文件。
- OPTIONS:查询相应URI支持的HTTP方法。
- Http协议中Http1.0与1.1区别?
- 在http1.0中,当建立连接后,客户端发送一个请求,服务器端返回一个信息后就关闭连接,当浏览器下次请求的时候又要建立连接,显然这种不断建立连接的方式,会造成很多问题。
- 在http1.1中,引入了持续连接的概念,通过这种连接,浏览器可以建立一个连接之后,发送请求并得到返回信息,然后继续发送请求再次等到返回信息,也就是说客户端可以连续发送多个请求,而不用等待每一个响应的到来。
- get与post请求区别?
- get重点在从服务器上获取资源,post重点在向服务器发送数据;
- get传输数据是通过URL请求,post传输数据通过Http的post机制,将字段与对应值封存在请求实体中发送给服务器,这个过程对用户是不可见的;
- Get传输的数据量小,因为受URL长度限制,但效率较高;Post可以传输大量数据,所以上传文件时只能用Post方式;
- get是不安全的,因为URL是可见的,可能会泄露信息;post较get安全性较高;
- 常见Http协议状态?
- 1** 信息,服务器收到请求,需要请求者继续执行操作
- 200 - 请求成功
- 301 - 资源(网页等)被永久转移到其它URL
- 404 - 请求的资源(网页等)不存在
- 500 - 内部服务器错误
- Http优化
- 利用负载均衡优化和加速HTTP应用
- 利用HTTP Cache来优化网站
- http缓存机制
【待补充】 - DNS解析的方法
【待补充】 - 跨域方法
【待补充】 - xss, csrf
【待补充】
- http和https区别
-
osi七层
-
TCP
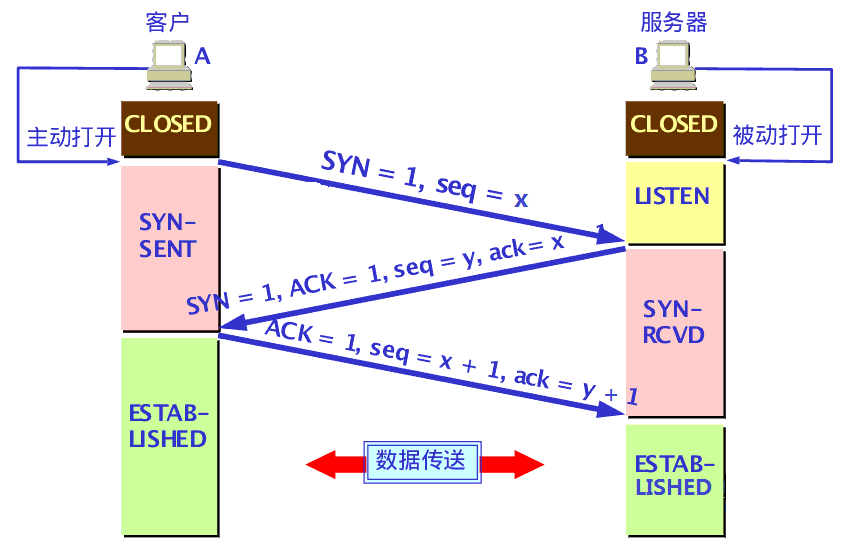
三次握手
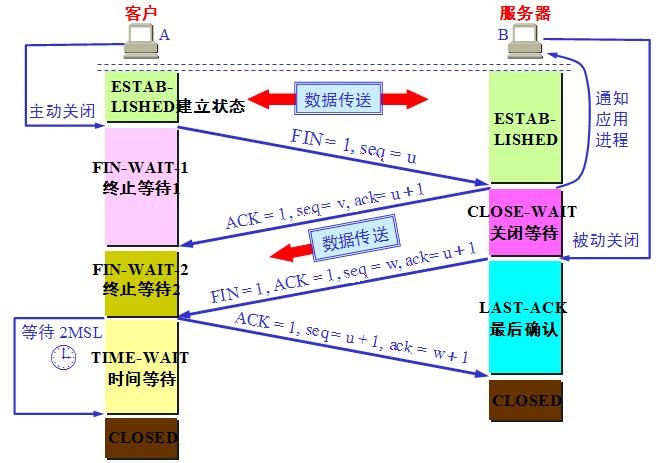
四次断开
因为之前存在没有传送完的数据,所以要等待。
小故事
三次握手:- A:喂,你听得到吗?
- B:我听得到呀,你听得到我吗?
- A:我能听到你,balabala……
四次挥手: - A:喂,我不说了。
- B:我知道了。等下,上一句还没说完。balabala…..
- B:好了,说完了,我也不说了。
- A:我知道了。
- A等待2MSL,保证B收到了消息,否则重说一次”我知道了”(如果没收到将进行重传)
-
TCP与UDP之间的区别
- 基于连接vs无连接
TCP是面向连接的协议,而UDP是无连接的协议。 - 可靠性不同
- TCP提供交付保证,这意味着一个使用TCP协议发送的消息是保证交付给客户端的。
- UDP是不可靠的,它不提供任何交付的保证。一个数据报包在运输途中可能会丢失。
- 有序性
- TCP保证了消息的有序性,该消息将以从服务器端发出的同样的顺序发送到客户端,
- UDP不提供任何有序性或序列性的保证,数据包将以任何可能的顺序到达。
- 数据边界
TCP不保存数据的边界,而UDP保证。 在传输控制协议,数据以字节流的形式发送, 并没有明显的标志表明传输信号消息(段)的边界。 在UDP中,数据包单独发送的,只有当他们到达时,才会再次集成。包有明确的界限来哪些包已经收到,这意味着在消息发送后,在接收器接口将会有一个读操作,来生成一个完整的消息。虽然TCP也将在收集所有字节之后生成一个完整的消息,但是这些信息在传给传输给接受端之前将储存在TCP缓冲区,以确保更好的使用网络带宽 - 速度
因为TCP必须创建连接,以保证消息的可靠交付和有序性,他需要做比UDP多的多。 - 重量级vs轻量级
由于上述的开销,TCP被认为是重量级的协议,而与之相比,UDP协议则是一个轻量级的协议。因为UDP传输的信息中不承担任何间接创造连接,保证交货或秩序的的信息。这也反映在用于承载元数据的头的大小。 - 头大小
TCP具有比UDP更大的头。 - 流量控制
- TCP有流量控制。在任何用户数据可以被发送之前,TCP需要三数据包来设置一个套接字连接。TCP处理的可靠性和拥塞控制。
- UDP不能进行流量控制。
- 基于连接vs无连接
-
https://www.nowcoder.com/test/question/done?tid=9501873&qid=46337#summary
-
Java GC如何判断对象是否为垃圾
根搜索算法,根:- 虚拟机栈中引用的对象(本地变量表)
- 方法区中静态属性引用的对象
- 方法区中常量引用的对象
- 本地方法栈中引用的对象(Native对象)
-
JVM的垃圾收集器主要有哪些,各自的特点是什么?
-
为什么要设置工作内存和主内存
缓存加速,相当于是内存和硬盘的关系。 -
当发现虚拟机频繁GC时应该怎么办?
【待补充】 -
请描述java的内存分区
【待补充】 -
请描述java的对象生命周期,以及对象的访问?
【待补充】 -
JVM调优
【待补充】
-
乐观锁,悲观锁
- 乐观锁假设认为数据一般情况下不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果发现冲突了,则让返回用户错误的信息,让用户决定如何去做。
- 悲观锁指的是对数据被外界(包括本系统当前的其他事务,以及来自外部系统的事务处理)修改持保守态度, 因此,在整个数据处理过程中,将数据处于锁定状态。悲观锁的实现,往往依靠数据库提供的锁机制
-
volatile关键字的作用
- 保证变量的可见性
- 保证指令集不被重排
-
Callable与Future
- CallableAndFutureTask,利用Thread启动单线程
void testCallableAndFutureTask() throws InterruptedException, ExecutionException { FutureTask<Integer> future = new FutureTask<>(new Callable<Integer>() { //后面用lambda了 @Override public Integer call() throws Exception { return new Random().nextInt(100); } }); new Thread(future).start(); Thread.sleep(5000);// 可能做一些事情 System.out.println(future.get()); }
- CallableAndFuture,利用线程池,启动单线程
void testCallableAndFuture() throws InterruptedException, ExecutionException { ExecutorService threadPool = Executors.newSingleThreadExecutor(); Future<Integer> future = threadPool.submit(() -> new Random().nextInt(100)); Thread.sleep(5000);// 可能做一些事情 System.out.println(future.get()); }
- CallableAndFuture,利用线程池,启动多线程
void multipleReturnValues() throws InterruptedException, ExecutionException { ExecutorService threadPool = Executors.newCachedThreadPool(); CompletionService<Integer> cs = new ExecutorCompletionService<>(threadPool); for (int i = 1; i < 5; i++) { final int taskID = i; cs.submit(() -> taskID); } // 可能做一些事情 for (int i = 1; i < 5; i++) { System.out.println(cs.take().get()); } }
- 和Runnable接口中的run()方法不同, Callable接口中的call()方法是有返回值的
-
CountDownLatch
- 先看用法
public static void main(String[] args) throws InterruptedException { CountDownLatch latch = new CountDownLatch(2);//两个工人的协作 Worker worker1 = new Worker("张三", latch); Worker worker2 = new Worker("李四", latch); worker1.start(); worker2.start(); latch.await(); System.out.println("all work done."); } static class Worker extends Thread { String workerName; CountDownLatch latch; Worker(String workerName, CountDownLatch latch) { this.workerName = workerName; this.latch = latch; } public void run() { try { System.out.println("Worker " + workerName + " do work begin."); Thread.sleep(1000); System.out.println("Worker " + workerName + " do work complete"); } catch (InterruptedException e) { e.printStackTrace(); } finally { latch.countDown();//工人完成工作,计数器减一 } } }
- 主线程必须在启动其他线程后立即调用CountDownLatch.await()方法。这样主线程的操作就会在这个方法上阻塞,直到其他线程完成各自的任务。
- CountDownLatch只有await()和countDown()方法,分别表示等待和减一
-
CyclicBarrier
- CyclicBarrier简单的理解就是内存屏障
- CyclicBarrier初始化时规定一个数目,然后计算调用了CyclicBarrier.await()进入等待的线程数。当线程数达到了这个数目时,所有进入等待状态的线程被唤醒并继续。
- CyclicBarrier初始时还可带一个Runnable的参数, 此Runnable任务在CyclicBarrier的数目达到后,所有其它线程被唤醒前被执行。
- 具体见代码
class TestCyclicBarrier { private static final int THREAD_NUM = 5; public static void main(String[] args) { //当所有线程到达barrier时执行,这里的lambda是Runnable(可选参数) CyclicBarrier cb = new CyclicBarrier(THREAD_NUM, () -> System.out.println("Inside Barrier")); for (int i = 0; i < THREAD_NUM; i++) { new Thread(() -> { System.out.println("Worker's waiting"); //线程在这里等待,直到所有线程都到达barrier。 try { cb.await(); } catch (InterruptedException | BrokenBarrierException e) { e.printStackTrace(); } System.out.println("ID:" + Thread.currentThread().getId() + " Working"); }).start(); } } } /* 执行结果 Worker's waiting Worker's waiting Worker's waiting Worker's waiting Worker's waiting Inside Barrier ID:15 Working ID:14 Working ID:12 Working ID:16 Working ID:13 Working*/
-
阻塞队列BlockingQueue
- 就是一个带阻塞功能的队列
- 放入数据:
- offer(anObject):如果BlockingQueue可以容纳, 则返回true,否则返回false.
- offer(E o, long timeout, TimeUnit unit): 可以设定等待的时间,如果在指定的时间内,还不能往队列中,则返回失败。
- put(anObject): 如果BlockQueue没有空间,则调用此方法的线程被阻塞,直到BlockingQueue里面有空间再继续.
- 获取数据:
- poll(): 若不能立即取出返回null;
- poll(long timeout, TimeUnit unit): 如果在指定时间内,队列一旦有数据可取,则立即返回队列中的数据,否则返回null
- take():若BlockingQueue为空, 则进入等待状态直到BlockingQueue有新的数据被加入;
- drainTo(Collection<? super E> c, int maxElements):一次性从BlockingQueue获取所有可用的数据对象(还可以指定获取数据的个数,第二个参数可选),通过该方法,可以提升获取数据效率;不需要多次分批加锁或释放锁。
-
锁(lock)和监视器(monitor)有什么区别?
- 锁是为了实现监视器排他性的一种手段
-
怎么检测一个线程是否持有对象监视器
- Thread类提供了一个holdsLock(Object obj)方法
- 当且仅当对象obj的监视器被某当前线程持有的时候才会返回true,注意这是一个static方法.
-
Executor框架 【待学习】
- 内容有点多,有空整理
-
Java编程写一个会导致死锁的程序
class DeadLock { private static final String obj1 = "obj1"; private static final String obj2 = "obj2"; public static void main(String[] args) { ExecutorService es = Executors.newFixedThreadPool(2); es.submit(() -> { System.out.println("Lock1 running"); while (true) { synchronized (DeadLock.obj1) { System.out.println("Lock1 lock obj1"); Thread.sleep(3000);//获取obj1后先等一会儿,让Lock2有足够的时间锁住obj2 synchronized (DeadLock.obj2) { System.out.println("Lock1 lock obj2"); }}}}); es.submit(() -> { System.out.println("Lock1 running"); while (true) { synchronized (DeadLock.obj2) { System.out.println("Lock2 lock obj2"); Thread.sleep(3000); synchronized (DeadLock.obj1) { System.out.println("Lock2 lock obj1"); }}}}); } }
-
怎么唤醒一个阻塞的线程
- 如果线程是因为调用了wait()、sleep()或者join()方法而导致的阻塞,可以中断线程,并且通过抛出InterruptedException来唤醒它;
- 如果线程遇到了IO阻塞,无能为力,因为IO是操作系统实现的,Java代码并没有办法直接接触到操作系统。
-
什么是多线程的上下文切换
- CPU控制权由一个已经正在运行的线程切换到另外一个就绪并等待获取CPU执行权的线程的过程。
-
什么是自旋
- 让等待锁的线程不要被阻塞,而是在synchronized的边界做忙循环,这就是自旋。
-
什么是CAS
- CAS,全称为Compare and Set,即比较-设置。
- 假设有三个操作数:内存值V、旧的预期值A、要修改的值B,
- 当且仅当预期值A和内存值V相同时,才会将内存值修改为B并返回true,
- 否则什么都不做并返回false。当然CAS一定要volatile变量配合,这样才能保证每次拿到的变量是主内存中最新的那个值
-
什么是AQS【待学习】
- http://www.cnblogs.com/waterystone/p/4920797.html
- 内容较多,以后再学
- 简单说一下AQS,AQS全称为AbstractQueuedSynchronizer,翻译过来应该是抽象队列同步器。
- 如果说java.util.concurrent的基础是CAS的话,那么AQS就是整个Java并发包的核心了,ReentrantLock、CountDownLatch、Semaphore等等都用到了它。
- AQS实际上以双向队列的形式连接所有的Entry,比方说ReentrantLock,所有等待的线程都被放在一个Entry中并连成双向队列,前面一个线程使用ReentrantLock好了,则双向队列实际上的第一个Entry开始运行。
- AQS定义了对双向队列所有的操作,而只开放了tryLock和tryRelease方法给开发者使用,开发者可以根据自己的实现重写tryLock和tryRelease方法,以实现自己的并发功能。
-
Semaphore有什么作用
class SemaphoreTest { public static void main(String[] args) { ExecutorService exec = Executors.newCachedThreadPool(); // 只能5个线程同时访问 final Semaphore semp = new Semaphore(5); for (int index = 0; index < 20; index++) { final int NO = index; exec.execute(() -> { try { // 获取许可 semp.acquire(); System.out.println("Accessing: " + NO); Thread.sleep((long) (Math.random() * 10000)); semp.release(); } catch (InterruptedException ignored) { } }); } exec.shutdown(); } }
- Java中的Semaphore是一种新的同步类,它是一个计数信号。
- 从概念上讲,信号量维护了一个许可集合。如有必要,在许可可用前会阻塞每一个 acquire(),然后再获取该许可。每个 release()添加一个许可,从而可能释放一个正在阻塞的获取者。
- 但是,不使用实际的许可对象,Semaphore只对可用许可的号码进行计数,并采取相应的行动。
- 信号量常常用于多线程的代码中,比如数据库连接池。
-
线程池的使用场景
- 高并发、任务执行时间短的业务:线程池线程数可以设置为CPU核数+1,减少线程上下文的切换
- 并发不高、任务执行时间长的业务要区分开看:
- 假如是业务时间长集中在IO操作上,也就是IO密集型的任务,因为IO操作并不占用CPU,所以不要让所有的CPU闲下来,可以加大线程池中的线程数目,让CPU处理更多的业务
- 假如是业务时间长集中在计算操作上,也就是计算密集型任务,这个就没办法了,和(1)一样吧,线程池中的线程数设置得少一些,减少线程上下文的切换
- 并发高、业务执行时间长:解决这种类型任务的关键不在于线程池而在于整体架构的设计,看看这些业务里面某些数据是否能做缓存是第一步,增加服务器是第二步,至于线程池的设置,设置参考(2)。最后,业务执行时间长的问题,也可能需要分析一下,看看能不能使用中间件对任务进行拆分和解耦。
-
Java中什么是竞态条件?
- 计算的正确性取决于多个线程的交替执行时序时,就会发生竞态条件。
-
Java中如何停止一个线程?
- 使用退出标志,使线程正常退出,也就是当run方法完成后线程终止。
- 使用stop方法强行终止,但是不推荐这个方法,因为stop和suspend及resume一样都是过期作废的方法。
- 使用interrupt方法中断线程。
-
一个线程运行时发生异常会怎样?
- 简单的说,如果异常没有被捕获该线程将会停止执行。
- Thread.UncaughtExceptionHandler是用于处理未捕获异常造成线程突然中断情况的一个内嵌接口。当一个未捕获异常将造成线程中断的时候JVM会使用Thread.getUncaughtExceptionHandler()来查询线程的UncaughtExceptionHandler并将线程和异常作为参数传递给handler的uncaughtException()方法进行处理。
-
Java中interrupted 和 isInterrupted方法的区别?
- interrupted() 和 isInterrupted()的主要区别是前者会将中断状态清除而后者不会。
- Java多线程的中断机制是用内部标识来实现的,调用Thread.interrupt()来中断一个线程就会设置中断标识为true。
- 当中断线程调用静态方法Thread.interrupted()来检查中断状态时,中断状态会被清零。
- 而非静态方法isInterrupted()用来查询其它线程的中断状态且不会改变中断状态标识。
- 简单的说就是任何抛出InterruptedException异常的方法都会将中断状态清零。无论如何,一个线程的中断状态有有可能被其它线程调用中断来改变。
-
为什么你应该在循环中检查等待条件?
-
Java中的同步集合与并发集合有什么区别?
-
如何写代码来解决生产者消费者问题?
-
如何避免死锁?
- 死锁是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。这是一个严重的问题,因为死锁会让你的程序挂起无法完成任务,死锁的发生必须满足以下四个条件:
- 互斥条件:一个资源每次只能被一个进程使用。
- 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
- 不剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺。
- 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
- 避免死锁最简单的方法就是阻止循环等待条件,将系统中所有的资源设置标志位、排序,规定所有的进程申请资源必须以一定的顺序(升序或降序)做操作来避免死锁。
- 死锁是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。这是一个严重的问题,因为死锁会让你的程序挂起无法完成任务,死锁的发生必须满足以下四个条件:
-
有三个线程T1,T2,T3,怎么确保它们按顺序执行?
-
Thread类中的yield方法有什么作用?
- Yield方法可以暂停当前正在执行的线程对象,让其它有相同优先级的线程执行。它是一个静态方法而且只保证当前线程放弃CPU占用而不能保证使其它线程一定能占用CPU,执行yield()的线程有可能在进入到暂停状态后马上又被执行。
-
写出3条你遵循的多线程最佳实践
- 给你的线程起个有意义的名字。
这样可以方便找bug或追踪。OrderProcessor, QuoteProcessor or TradeProcessor 这种名字比 Thread-1. Thread-2 and Thread-3 好多了,给线程起一个和它要完成的任务相关的名字,所有的主要框架甚至JDK都遵循这个最佳实践。 - 避免锁定和缩小同步的范围
锁花费的代价高昂且上下文切换更耗费时间空间,试试最低限度的使用同步和锁,缩小临界区。因此相对于同步方法我更喜欢同步块,它给我拥有对锁的绝对控制权。 - 多用同步类少用wait 和 notify
首先,CountDownLatch, Semaphore, CyclicBarrier 和 Exchanger 这些同步类简化了编码操作,而用wait和notify很难实现对复杂控制流的控制。其次,这些类是由最好的企业编写和维护在后续的JDK中它们还会不断优化和完善,使用这些更高等级的同步工具你的程序可以不费吹灰之力获得优化。 - 多用并发集合少用同步集合
这是另外一个容易遵循且受益巨大的最佳实践,并发集合比同步集合的可扩展性更好,所以在并发编程时使用并发集合效果更好。如果下一次你需要用到map,你应该首先想到用ConcurrentHashMap。我的文章Java并发集合有更详细的说明。
- 给你的线程起个有意义的名字。
-
Java中的fork join框架是什么?
- fork join框架是JDK7中出现的一款高效的工具,Java开发人员可以通过它充分利用现代服务器上的多处理器。它是专门为了那些可以递归划分成许多子模块设计的,目的是将所有可用的处理能力用来提升程序的性能。fork join框架一个巨大的优势是它使用了工作窃取算法,可以完成更多任务的工作线程可以从其它线程中窃取任务来执行。
-
Java线程池中submit() 和 execute()方法有什么区别?
- 两个方法都可以向线程池提交任务,
- execute()方法的返回类型是void,它定义在Executor接口中,
- 而submit()方法可以返回持有计算结果的Future对象,它定义在ExecutorService接口中,它扩展了Executor接口,
- 其它线程池类像ThreadPoolExecutor和ScheduledThreadPoolExecutor都有这些方法。
-
优化反射性能
- 利用缓存
- 对Field、Method、Constructor进行setAccessible(true);
-
什么时候用接口、什么时候用抽象类
- 表达is-a关系的时候用抽象类
- 表达like-a关系的时候用接口
-
List的实现类
- LinkedList
- ArrayList 默认自动扩容1.5倍
-
Map的实现类
- HashMap
先hash,hash冲突的用链表连起来(jdk1.8 当链表长度超过8时,链表变成红黑树) - TreeMap
红黑树 - LinkedHashMap
默认按照插入排序,
accessOrder为true时,记录访问顺序,最近访问的放在最后 - hashTable 与 concurrentHashMap 区别
- HashTable每次同步执行的时候都要锁住整个结构
- ConcurrentHashMap锁的方式是稍微细粒度的,ConcurrentHashMap里面的操作只锁当前数据所在的桶
- HashMap
-
Servlet的生命周期,是否是线程安全的?
- Servlet 生命周期可被定义为从创建直到毁灭的整个过程。以下是 Servlet 遵循的过程:
- Servlet 通过调用 init () 方法进行初始化。
- Servlet 调用 service() 方法来处理客户端的请求。
service() 方法检查 HTTP 请求类型(GET、POST、PUT、DELETE 等),并在适当的时候调用 doGet、doPost、doPut,doDelete 等方法。 - Servlet 通过调用 destroy() 方法终止(结束)。
- 最后,Servlet 是由 JVM 的垃圾回收器进行垃圾回收的。
- 不是线程安全的,因为Servlet只会被实例化一次。如果Servlet中含有可变的域
- Servlet 生命周期可被定义为从创建直到毁灭的整个过程。以下是 Servlet 遵循的过程:
-
Java表达式转型规则由低到高转换
- 所有的byte,short,char型的值将被提升为int型;
- 如果有一个操作数是long型,计算结果是long型;
- 如果有一个操作数是float型,计算结果是float型;
- 如果有一个操作数是double型,计算结果是double型;
- 被final修饰的变量不会自动改变类型,当2个final修饰相操作时,结果会根据左边变量的类型而转化。
-
进程和线程的区别
每个进程拥有自己的一套变量,而线程之间则共享数据的。 -
进程的通信方式 【待理解】
- 管道:管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
- 信号量:信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
- 消息队列:消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
- 共享内存:共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号两,配合使用,来实现进程间的同步和通信。
- 套接字:套解口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同及其间的进程通信。
-
缓冲区溢出
- 缓冲区溢出是指当计算机向缓冲区填充数据时超出了缓冲区本身的容量,溢出的数据覆盖在合法数据上。
- 危害有以下两点:
- 程序崩溃,导致拒绝额服务
- 跳转并且执行一段恶意代码
- 造成缓冲区溢出的主要原因是程序中没有仔细检查用户输入。
-
死锁
在两个或者多个并发进程中,如果每个进程持有某种资源而又等待其它进程释放它或它们现在保持着的资源,在未改变这种状态之前都不能向前推进,称这一组进程产生了死锁。通俗的讲就是两个或多个进程无限期的阻塞、相互等待的一种状态。
死锁产生的四个条件(有一个条件不成立,则不会产生死锁)- 互斥条件:一个资源一次只能被一个进程使用
- 请求与保持条件:一个进程因请求资源而阻塞时,对已获得资源保持不放
- 不剥夺条件:进程获得的资源,在未完全使用完之前,不能强行剥夺
- 循环等待条件:若干进程之间形成一种头尾相接的环形等待资源关系
处理策略:鸵鸟策略、预防策略、避免策略、检测与恢复策略
-
进程有哪几种状态?
- 就绪状态:进程已获得除处理机以外的所需资源,等待分配处理机资源
- 运行状态:占用处理机资源运行,处于此状态的进程数小于等于CPU数
- 阻塞状态: 进程等待某种条件,在条件满足之前无法执行
-
分页和分段有什么区别?
- 页是信息的物理单位,分页是为实现离散分配方式,以消减内存的外零头,提高内存的利用率;或者说,分页仅仅是由于系统管理的需要,而不是用户的需要。
- 段是信息的逻辑单位,它含有一组其意义相对完整的信息。分段的目的是为了能更好的满足用户的需要。
- 页的大小固定且由系统确定,把逻辑地址划分为页号和页内地址两部分,是由机器硬件实现的,因而一个系统只能有一种大小的页面。段的长度却不固定,决定于用户所编写的程序,通常由编辑程序在对源程序进行编辑时,根据信息的性质来划分。
- 分页的作业地址空间是一维的,即单一的线性空间,程序员只须利用一个记忆符,即可表示一地址。分段的作业地址空间是二维的,程序员在标识一个地址时,既需给出段名,又需给出段内地址。
-
操作系统中进程调度策略
- 先来先服务
- 优先级
- 短作业优先
- 时间片轮转
- 最高响应比优先算法(HRN):FCFS可能造成短作业用户不满,SPF可能使得长作业用户不满,于是提出HRN,选择响应比最高的作业运行。响应比=1+作业等待时间/作业处理时间。
-
进程同步机制 【待补充】
-
中断和轮询的特点
- 对I/O设备的程序轮询的方式,是早期的计算机系统对I/O设备的一种管理方式。它定时对各种设备轮流询问一遍有无处理要求。轮流询问之后,有要求的,则加以处理。在处理I/O设备的要求之后,处理机返回继续工作。
- 程序中断是指CPU在正常运行程序的过程中,由于预先安排或发生了各种随机的内部或外部事件,使CPU中断正在运行的程序,而转到为响应的服务程序去处理。
- 轮询——效率低,等待时间很长,CPU利用率不高。
- 中断——容易遗漏一些问题,CPU利用率高。
-
临界区
每个进程中访问临界资源的那段程序称为临界区,每次只准许一个进程进入临界区,进入后不允许其他进程进入。- 如果有若干进程要求进入空闲的临界区,一次仅允许一个进程进入;
- 任何时候,处于临界区内的进程不可多于一个。如已有进程进入自己的临界区,则其它所有试图进入临界区的进程必须等待;
- 进入临界区的进程要在有限时间内退出,以便其它进程能及时进入自己的临界区;
- 如果进程不能进入自己的临界区,则应让出CPU,避免进程出现“忙等”现象。
-
数据传输率(C)=记录位密度(D) x 线速度( V )
-
https://www.nowcoder.com/test/question/done?tid=9502589&qid=44781#summary
-
常用命令
- cd 切换路径
- ls 列出文件
- -l :列出长数据串,包含文件的属性与权限数据等
- -a :列出全部的文件,连同隐藏文件(开头为.的文件)一起列出来(常用)
- -R :连同子目录的内容一起列出(递归列出),等于该目录下的所有文件都会显示出来
- grep【待补充】
- find【待补充】
- cp 复制
- -a :将文件的特性一起复制
- -p :连同文件的属性一起复制,而非使用默认方式,与-a相似,常用于备份
- -i :若目标文件已经存在时,在覆盖时会先询问操作的进行
- -r :递归持续复制,用于目录的复制行为
- -u :目标文件与源文件有差异时才会复制
- mv 移动
- -f :force强制的意思,如果目标文件已经存在,不会询问而直接覆盖
- -i :若目标文件已经存在,就会询问是否覆盖
- -u :若目标文件已经存在,且比目标文件新,才会更新
- rm 删除
- -f :就是force的意思,忽略不存在的文件,不会出现警告消息
- -i :互动模式,在删除前会询问用户是否操作
- -r :递归删除,最常用于目录删除,它是一个非常危险的参数
- ps 查看进程
- ps aux # 查看系统所有的进程数据
- ps ax # 查看不与terminal有关的所有进程
- ps -lA # 查看系统所有的进程数据
- ps axjf # 查看连同一部分进程树状态
- kill 关闭
- kill pid
- file 判断接在file命令后的文件的基本数据
- tar 打包
- 压缩:tar -zcv -f filename.tar.gz 要被处理的文件或目录名称
- 查询:tar -ztv -f filename.tar.gz
- 解压:tar -zxv -f filename.tar.gz -C 欲解压缩的目录
- cat 查看文本文件的内容
- time 用于测算一个命令(即程序)的执行时间
- 在命令的前面加入一个time即可
- pwd 显示当前目录
-
Linux文件属性 【待补充】
-
Linux中stdout和stderr输出缓冲
- 结论:stdout使用了行缓冲区,stderr没使用缓冲区
- 仔细的说,stdout只有在换行的时候才输出
-
https://www.nowcoder.com/test/question/done?tid=9501873&qid=46328#summary
-
用户态 内核态
-
find grep
-
文件权限5-7位
-
详解参考 Java之美[从菜鸟到高手演变]之设计模式 ,我只是对这篇文章进行了提炼,错误的简单更正,能让自己回忆起来。
-
工厂方法模式
- 普通工厂模式,用字符串产生实例
- 多个工厂方法模式,直接调用相应的建造实例的方法
- 静态工厂方法模式,多个工厂方法模式里的方法置为静态的,不需要创建工厂实例,直接调用即可
-
抽象工厂模式
- 为了解决程序扩展问题
- 每个类对应一个工厂,然后这些工厂实现一个接口,使用时对相相应的工厂进行实例化,然后通过接口获取实例。
Provider provider = new SendMailFactory(); //Privider为所有工厂实现的接口 Sender sender = provider.produce(); //produce方法获取该工厂想要产生的实例 sender.Send();
-
单例模式(Singleton)
- 实现一,静态加载
class Singleton { private static Singleton instance = new Singleton(); private Singleton (){} public static Singleton getInstance() { return instance; } }
- 实现二,双重锁定
class Singleton { private static Singleton instance = null; private Singleton() {} public static Singleton getInstance() { if (instance == null) { synchronized (Singleton.class) { if (instance == null) { instance = new Singleton(); } } } return instance; } }
-
建造者模式(Builder)
- Builder:给出一个接口,以规范产品对象的各个组成成分的建造。规定要实现复杂对象的哪些部分的创建。(人的身体有哪些部分)
- ConcreteBuilder:实现Builder接口,具体化复杂对象的各部分的创建。 在建造过程完成后,提供产品的实例。(某个人具体每部分的样子)
- Director:调用具体建造者来创建复杂对象的各个部分,在指导者中不涉及具体产品的信息,只负责保证对象各部分完整创建或按某种顺序创建。(按照样子来创建一个人)
- Product:要创建的复杂对象。(从Builder中接收这个人)
-
原型模式(Prototype)
- 用原型实例指定创建对象的种类,并通过拷贝这些原型创建新的对象
- 原型类需要具备两个条件
- 实现Cloneable接口
- 重写Object类中的clone方法,如果是浅拷贝的话,直接super.clone()
- 优点
- 创建对象比直接new一个对象在性能上要好的多,因为Object类的clone方法是一个本地方法,它直接操作内存中的二进制流,特别是复制大对象时,性能的差别非常明显。
- 简化对象的创建,使得创建对象就像我们在编辑文档时的复制粘贴一样简单。
-
适配器模式(Adapter)
- 适配器模式将一个类的接口转换成客户期望的另一个接口,让原本不兼容的接口可以合作无间。
- 适配器对象实现原有接口
- 适配器对象组合一个实现新接口的对象
- 对适配器原有接口方法的调用被委托给新接口的实例的特定方法
public class Adapter implements OldInterface{ //实现旧接口 private NewInterface newInterface;//组合新接口 //在创建适配器对象时,必须传入一个新接口的实现类 public Adapter(NewInterface newInterface) { this.newInterface = newInterface; } //将对旧接口的调用适配到新接口 @Override public void oldFunction() { newInterface.newFunction(); } }
-
装饰器模式(Decorator)
- 简而言之,就是用一个装饰器,将需要装饰的类进行装饰,类似于AOP代理
- Component:组件对象的接口,可以给这些对象动态的添加职责;
- ConcreteComponent:具体的组件对象,实现了组件接口。该对象通常就是被装饰器装饰的原始对象,可以给这个对象添加职责;
- Decorator:所有装饰器的父类,需要定义一个与组件接口一致的接口(主要是为了实现装饰器功能的复用,即具体的装饰器A可以装饰另外一个具体的装饰器B,因为装饰器类也是一个Component),并持有一个Component对象,该对象其实就是被装饰的对象。如果不继承组件接口类,则只能为某个组件添加单一的功能,即装饰器对象不能在装饰其他的装饰器对象。
- ConcreteDecorator:具体的装饰器类,实现具体要向被装饰对象添加的功能。用来装饰具体的组件对象或者另外一个具体的装饰器对象。
Component c1 = new ConcreteComponent(); //首先创建需要被装饰的原始对象(即要被装饰的对象) Decorator decoratorA = new ConcreteDecoratorA(c1); //给对象透明的增加功能A并调用 decoratorA.operation(); Decorator decoratorB = new ConcreteDecoratorB(c1); //给对象透明的增加功能B并调用 decoratorB.operation(); Decorator decoratorBandA = new ConcreteDecoratorB(decoratorA);//装饰器也可以装饰具体的装饰对象,此时相当于给对象在增加A的功能基础上在添加功能B decoratorBandA.operation();
-
代理模式
- 抽象角色:声明真实对象和代理对象的共同接口。
- 代理角色:代理对象角色内部含有对真实对象的引用,从而可以操作真实对象,同时代理对象提供与真实对象相同的接口以便在任何时刻都能代替真实对象。同时,代理对象可以在执行真实对象操作时,附加其他的操作,相当于对真实对象进行封装(也就是Decorator?)。
- 真实角色:代理角色所代表的真实对象,是我们最终要引用的对象
-
外观模式
- 外观模式是为了解决类与类之间的依赖关系的,外观模式就是将他们的关系放在一个Facade[fə'sɑːd]类中,降低了类类之间的耦合度,该模式中没有涉及到接口。
//Facade public class Computer { //...cpu, memory, disk之间没有关系,如果没有Computer他们将互相严重依赖 public void startup(){ System.out.println("start the computer!"); cpu.startup(); memory.startup(); disk.startup(); System.out.println("start computer finished!"); } }
-
桥接模式
- 桥接的用意是:将抽象化与实现化解耦,使得二者可以独立变化
- 常见的JDBC桥DriverManager就是桥接模式。
- 设计一个桥,传入需要连接的对象,然后用桥来调用方法(那和实现一个拥有该方法的接口有什么区别呢?为了解决历史遗留问题?)
-
组合模式(部分-整体模式)
- 将对象组合成树形结构以表示“部分整体”的层次结构。组合模式使得用户对单个对象和使用具有一致性。
- 如果你想要创建层次结构,并可以在其中以相同的方式对待所有元素,那么组合模式就是最理想的选择
-
享元模式
- 实现对象的共享,即共享池,当系统中对象多的时候可以减少内存的开销,通常与工厂模式一起使用。
- 例如jdbc连接池
-
策略模式(strategy)
- 把一个类中经常改变或者将来可能改变的部分提取出来,作为一个接口,然后在类中包含这个对象的实例,这样类的实例在运行时就可以随意调用实现了这个接口的类的行为。
- 比如定义一系列的算法,把每一个算法封装起来, 并且使它们可相互替换,使得算法可独立于使用它的客户而变化。
-
模板方法模式
- 父类中,有一个主方法,再定义1...n个方法,可以是抽象的,也可以是实际的方法
- 定义一个类,继承该父类,重写方法,通过调用类,实现对子类的调用
- 一般不需要变的方法可以为定义为final
-
观察者模式
- 当一个对象变化时,其它依赖该对象的对象都会收到通知,并且随着变化
- 用一个类来保存依赖关系,并通知依赖者被依赖者的变化情况
-
迭代子模式
- 顺序访问聚集中的对象
-
责任链模式
- 有多个对象,每个对象持有对下一个对象的引用,这样就会形成一条链,请求在这条链上传递,直到某一对象决定处理该请求。
- 发出者并不清楚到底最终那个对象会处理该请求
- 责任链模式可以实现,在隐瞒客户端的情况下,对系统进行动态的调整。
-
命令模式
- 抽象命令(Command):定义命令的接口,声明执行的方法。
- 具体命令(ConcreteCommand):具体命令,实现要执行的方法,它通常是“虚”的实现;通常会有接收者,并调用接收者的功能来完成命令要执行的操作。
- 接收者(Receiver):真正执行命令的对象。任何类都可能成为一个接收者,只要能实现命令要求实现的相应功能。
- 调用者(Invoker):要求命令对象执行请求,通常会持有命令对象,可以持有很多的命令对象。这个是客户端真正触发命令并要求命令执行相应操作的地方,也就是说相当于使用命令对象的入口。
- 客户端(Client):命令由客户端来创建,并设置命令的接收者。
-
备忘录模式
- 目的是保存一个对象的某个状态,以便在适当的时候恢复对象
- 假设有原始类A,A中有各种属性,A可以决定需要备份的属性
- 备忘录类B是用来存储A的一些内部状态
- 类C就是一个用来存储备忘录的,且只能存储,不能修改等操作。
-
状态模式
- 通过改变状态来改变行为
-
访问者模式【似懂非懂】
- 封装某些作用于某种数据结构中各元素的操作,它可以在不改变数据结构的前提下定义作用于这些元素的新的操作。
class A { void method1() { System.out.println("我是A"); } void method2(B b) { b.showA(this); } } class B { void showA(A a) { a.method1(); } public static void main(String[] args) { A a = new A(); a.method1(); a.method2(new B()); } }
-
中介者模式
- 定义一个中介对象来封装系列对象之间的交互。
- 中介者使各个对象不需要显示地相互引用,从而使其耦合性松散,而且可以独立地改变他们之间的交互。
-
解释器模式
- 就是写个解释器,比如正则表达式解释器,四则运算解释器。
- 单例模式相较于静态类的优点
- 静态类对接口不友好,Java8 才出现静态方法。
- 单例可以被延迟初始化,静态类一般在第一次加载是初始化。之所以延迟加载,是因为有些类比较庞大,所以延迟加载有助于提升性能。不过用静态实现的单例模式没有这个优点。
- 单例类可以被继承,他的方法可以被override。但是静态类内部方法都是static,无法被override。
- 单例类比较灵活,毕竟从实现上只是一个普通的Java类,只要满足单例的基本需求,你可以在里面随心所欲的实现一些其它功能,但是静态类不行。
只总结一些我接触的少,或者常见但是忘记了的算法
-
Reservoir Sampling
【待补充】 -
排序
- 简单修改了一下DualPivotQuicksort的源码
- 源码很强
- 含有:
- 插入排序
- 普通快排
- 双轴快排
- Tim sort
- 还有各种特判优化
- 值得一默
-
哈夫曼树
-
老鼠喝可乐
- 问题:有15瓶可乐,其中有一瓶是坏的,问需要多少只老鼠同时喝才能知道哪一瓶可乐是坏的
- 答案:不懂。。我感觉是二进制问题,我猜的是4
-
2、5、7改变开关
-
两个人约6~7点见面,如果等超过15min就回家,问能见面的概率
-
堆排序
-
给你一个整型数组,把它补充成回文数组,要求所有的数字和最小
- 如: [1,2,3,1,2] -> [1,2,1,3,1,2,1] -> 11
-
Hash
-
有一个苹果,两个人轮流抛硬币,抛到正面的可以吃苹果。问先抛的人吃到苹果的概率
-
a1,a2,a3,a4入栈,一共有多少种出栈顺序
-
kmp
public class KMP { public static int[] getNext(char[] s) { int next[] = new int[s.length + 1]; for (int i = 1, j = 0; i < s.length; i++) { while (j > 0 && s[i] != s[j]) j = next[j]; if (s[i] == s[j]) j++; next[i + 1] = j; } return next; } public static void search(char[] s, char[] t) { int[] next = getNext(t); System.out.println(Arrays.toString(next)); for (int i = 0, j = 0; i < s.length; i++) { while (j > 0 && s[i] != t[j]) j = next[j]; if (s[i] == t[j]) j++; if (j == t.length) { System.out.println("find at position " + (i - j + 1)); j = next[j]; }}}}
Python相关内容,点击这里
-
为什么选择我们公司
- 首先非常喜欢XX,举例。。,我也非常喜欢XX的企业文化。(提前了解)
- 而且我所投的岗位和自己的能力非常的契合,我相信我的个人能力在你们公司可以得到充分的发挥,并为XX做更多的贡献。
-
对平台的要求和期待
- 首先,期待与领导、同事能够和睦相处,作为新人,希望能够尽快融入他们这个圈子里。
- 其次,希望通过自己的学到的知识能够尽快适应这份工作,不给工作单位拖后腿。对于单位领导、同事的批评要虚心接受,多多请教那些经验丰富的人,“三人行,必有我师焉”。
- 最后,希望通过自己的不懈努力,自己的工作能够得到领导和同事的认可。
-
你的职业规划是什么样的?
- 如果我能进入贵公司,在这样一个大的平台,能够向周围优秀的同事们学习,学习XX(公司名)的文化,通过追赶他们,让自己成为一个更加职业化、专业化的职业人,我觉得这是难得的一次机会。
- 所以我会在接下来的三年里,让自己从他们身上学到更多,扎根XX(公司名),在业务上做出更多的成绩,让自己在专业领域更有影响力。
- [如果HR追问,那职位上你就没有什么预期吗?你可以回答:]
- 谁还能没有职位的预期呢?但是我觉得职位和薪酬都是你到那个水平,组织自然会考虑到的。所以在职的管理人员必然有他的过人之处,我觉得在我获得组织的认可之后,一切都是水到渠成的。
- 在职之前,我觉得更应该考虑的是如何扎根在这,成长起来,承担起自己的职责,让自己更有影响力。
-
缺点:对自己的要求过高,实际能力低于预期能力。
-
薪资
-
对加班的看法
-
就是问我有什么爱好…最崇拜谁…
-
你有什么业余爱好?
- 最好不要说自己没有业余爱好。
- 不要说自己有那些庸俗的、令人感觉不好的爱好。
- 最好不要说自己仅限于读书、听音乐、上网,否则可能令面试官怀疑应聘者性格孤僻。
- 最好能有一些户外的业余爱好来“点缀”你的形象。
-
你最崇拜谁?
- 不宜说自己谁都不崇拜。
- 不宜说崇拜自己。
- 不宜说崇拜一个虚幻的、或是不知名的人。
- 不宜说崇拜一个明显具有负面形象的人。
- 所崇拜的人人最好与自己所应聘的工作能“搭”上关系。
- 最好说出自己所崇拜的人的哪些品质、哪些**感染着自己、鼓舞着自己。
-
未来几年内你的目标是什么?
-
你对我们公司有了解吗?
-
你为什么要来滴滴?如何看待滴滴
-
然后如何择业,考虑未来的发展方向
-
喜欢什么样的工作氛围?
-
你为什么想离开目前的职务?
- 老板不愿授权,工作处处受限,绑手绑脚、很难做事。
- 公司营运状况不佳,大家人心惶惶。
-
你对我们公司了解有多少?
- 贵公司有意改变策略,加强与国外大厂的OEM合作,自有品牌的部分则透过海外经销商。
-
你找工作时,最重要的考虑因素为何?
- 工作的性质是否能让我发挥所长,并不断成长。
- 解答:以C居多,因为公司要找工作表现好、能够真正有贡献的人,而非纯粹慕名、求利而来的人。
-
为什么我们应该录取你?
- 解答:这题理想的回答是C。你如何让对方看到你的好?单凭口才,是很难令对方信服的,因此,从履历表内容或之前的回答内容中,如果能以客观数字、具体的工作成果,来辅助说明,是最理想的回答。
-
请谈谈你个人的最大特色。
- 我的坚持度很高,事情没有做到一个令人满意的结果,绝不罢手。
-
谈谈你的家庭情况
- 简单地罗列家庭人口。
- 宜强调温馨和睦的家庭氛围。
- 宜强调父母对自己教育的重视。
- 宜强调各位家庭成员的良好状况。
- 宜强调家庭成员对自己工作的支持。
- 宜强调自己对家庭的责任感。
-
你的座右铭是什么?
- 不宜说那些引起不好联想的座右铭。
- 不宜说那些太抽象的座右铭。
- 不宜说太长的座右铭。
- 座右铭最好能反映出自己某种优秀品质。
- 参考答案——“只为成功找方法,不为失败找借口”
-
谈谈你的缺点
- 不宜说自己没缺点。
- 不宜把那些明显的优点说成缺点。
- 不宜说出严重影响所应聘工作的缺点。
- 不宜说出令人不放心、不舒服的缺点。
- 可以说出一些对于所应聘工作“无关紧要”的缺点,甚至是一些表面上看是缺点,从工作的角度看却是优点的缺点。
-
谈一谈你的一次失败经历
- 不宜说自己没有失败的经历。
- 不宜把那些明显的成功说成是失败。
- 不宜说出严重影响所应聘工作的失败经历。
- 所谈经历的结果应是失败的。
- 宜说明失败之前自己曾信心白倍、尽心尽力。
- 说明仅仅是由于外在客观原因导致失败。
- 失败后自己很快振作起来,以更加饱满的热情面对以后的工作。
-
你为什么选择我们公司?
- 建议从行业、企业和岗位这三个角度来回答。
- 参考答案——“我十分看好贵公司所在的行业,我认为贵公司十分重视人才,而且这项工作很适合我,相信自己一定能做好。”
-
如果我录用你,你将怎样开展工作?”
- 如果应聘者对于应聘的职位缺乏足够的了解,最好不要直接说出自己开展工作的具体办法。
- 可以尝试采用迂回战术来回答,如“首先听取领导的指示和要求,然后就有关情况进行了解和熟悉,接下来制定一份近期的工作计划并报领导批准,最后根据计划开展工作。”
-
与上级意见不一致时,你将怎么办?
- 一般可以这样回答“我会给上级以必要的解释和提醒,在这种情况下,我会服从上级的意见。”
- 如果面试你的是总经理,而你所应聘的职位另有一位经理,且这位经理当时不在场,可以这样回答:“对于非原则性问题,我会服从上级的意见,对于涉及公司利益的重大问题,我希望能向更高层领导反映。”“应届毕业生缺乏经验,如何能胜任工作?”
-
我们为什么要录用你?
- 应聘者最好站在招聘单位的角度来回答。
- 招聘单位一般会录用这样的应聘者:基本符合条件、对这份共组感兴趣、有足够的信心。
- 如“我符合贵公司的招聘条件,凭我目前掌握的技能、高度的责任感和良好的饿适应能力及学习能力,完全能胜任这份工作。我十分希望能为贵公司服务,如果贵公司给我这个机会,我一定能成为贵公司的栋梁!”
-
你能为我们做什么?
- 基本原则上“投其所好”。
- 回答这个问题前应聘者最好能“先发制人”,了解招聘单位期待这个职位所能发挥的作用。
- 应聘者可以根据自己的了解,结合自己在专业领域的优势来回答这个问题。
-
你是应届毕业生,缺乏经验,如何能胜任这项工作?”
- 如果招聘单位对应届毕业生的应聘者提出这个问题,说明招聘单位并不真正在乎“经验”,关键看应聘者怎样回答。
- 对这个问题的回答最好要体现出应聘者的诚恳、机智、果敢及敬业。
- 如“作为应届毕业生,在工作经验方面的确会有所欠缺,因此在读书期间我一直利用各种机会在这个行业里做兼职。我也发现,实际工作远比书本知识丰富、复杂。但我有较强的责任心、适应能力和学习能力,而且比较勤奋,所以在兼职中均能圆满完成各项工作,从中获取的经验也令我受益非浅。请贵公司放心,学校所学及兼职的工作经验使我一定能胜任这个职位。”
-
你希望与什么样的上级共事?
- 通过应聘者对上级的“希望”可以判断出应聘者对自我要求的意识,这既上一个陷阱,又上一次机会。
- 最好回避对上级具体的希望,多谈对自己的要求。
- 如“做为刚步入社会新人,我应该多要求自己尽快熟悉环境、适应环境,而不应该对环境提出什么要求,只要能发挥我的专长就可以了。”
-
您在前一家公司的离职原因是什么?”
- 最重要的是:应聘者要使找招聘单位相信,应聘者在过往的单位的“离职原因”在此家招聘单位里不存在。
- 避免把“离职原因”说得太详细、太具体。
- 不能掺杂主观的负面感受,如“太幸苦”、“人际关系复杂”、“管理太混乱”、“公司不重视人才”、“公司排斥我们某某的员工”等。
- 但也不能躲闪、回避,如“想换换环境”、“个人原因”等。
- 不能涉及自己负面的人格特征,如不诚实、懒惰、缺乏责任感、不随和等。
- 尽量使解释的理由为应聘者个人形象添彩。
- 如“我离职是因为这家公司倒闭。我在公司工作了三年多,有较深的感情。从去年始,由于市场形势突变,公司的局面急转直下。到眼下这一步我觉得很遗憾,但还要面对,重新寻找能发挥我能力的舞台。”同一个面试问题并非只有一个答案,而同一个答案并不是在任何面试场合都有效,关键在于应聘者掌握了规律后,对面试的具体情况进行把握,有意识地揣摩面试官提出问题的心理背景,然后投其所好。
- 自我介绍:姓名、工作地、教育背景、工作经历,简明扼要,不要超过一分半钟;
- 个人了解:有什么优点?主要缺点?职业规划?抗压能力?执行能力?
- 您为何要离开目前服务的这家公司?
- (答案可能是待遇或成长空间或人际氛围或其它,待回答完毕后继续发问)
- 您跟您的主管或直接上司有没有针对以上问题沟通过?
- (如果没有,问其原因;如果有,问其过程和结果)
- 除了简历上的工作经历,您还会去关注哪些领域
- (若有,继续发问)您觉得这跟您目前从事的职业有哪些利弊关系?
- (若无,继续发问)您不觉得您的知识结构有些狭窄或兴趣比较贫乏,说说未来改善的计划?
- 您在选择工作中更看重的是什么?
- (可能是成长空间、培训机会、发挥平台、薪酬等答案)
- (若薪酬不是排在第一,问)——您可不可以说说您在薪酬方面的心里预期?
- (薪酬可以综合考虑,有让步空间,可问)
- 那您刚才的意思也可以理解为:薪酬方面可以适当降低于您的心里预期,对吗?
- (若薪酬显得不肯让步,可问)有人说挣未来比挣钱更为重要,您怎么理解?
- (若薪酬排在第一,可问)有人说挣未来比挣钱更为重要,您怎么理解?
- 假设,某一天,在工作办公室走廊,您和一位同事正在抱怨上级陈某平时做事缺乏公平性,恰巧被陈某听到,您会怎么办?
- 您怎么看待加班问题?
- 怎么样处理工作和生活的关系?怎么处理在工作中遇到困难?请举例说明
- 在您的现实生活中,您最不喜欢和什么样的人共事?为什么?举例说明。
- 在您认识的人中,有没有人不喜欢您?为什么不喜欢您?请举例说明。
- 当老板/上司/同事/客户误会你,你会怎么办?
- 当你发现其他部门的工作疏漏已经影响到您的工作绩效时,您怎么办?
- 您希望在什么样的领导下工作?
- 我们工作与生活历程并不是一帆风顺的,谈谈您的工作或生活中出现的挫折或低潮期,您如何克服?
- 假如您的上司是一个非常严厉、领导手腕强硬,时常给您巨大压力的人,您觉得这种领导方式对您有何利、弊?
- 您的领导给您布置了一项您以前从未触及过的任务,您打算如何去完成它?(如果有类似的经历说说完成的经历。)
- 谈谈您以往职业生涯中最有压力的一、两件事,并说说是如何克服的。
- 谈谈您以往职业生涯中令您有成就感的一、两件事,并说说它给您的启示。
- 您觉得自己的个性适合井然有序的工作环境还是灵活自如的工作环境。
- 请您举一个例子,说明在完成一项重要任务时,您是怎样和他人进行有效合作的。
- 请描述当你意识到工作进程中出现问题了,你是如何处理的?
- 请说出一个工作进程中的确切目标,你怎样确保达到此既定目标。
- 请您举一个例子,说明在完成一项重要任务时,您是怎样和他人进行有效合作的。
- 当你要牺牲自己的某些方面与他人共事时,你会怎么办?
- 有时团队成员不能有效共事,当遇到这种问题时你是怎么处理的?你又是如何改善这类情况的?
- 我们有时不得不与自己不喜欢的人在一个团队工作,如果遇到这样的情况你会怎么办?
- 您对委任的任务完成不了时如何处理?
- 请描述一下您以往所就职公司中您认为最适合您自己的企业文化的特色
- 描述一下您对上司所布置任务的完成**与过程。
- 当您所在的集体处于竞争劣势时,您有什么想法和行动?
- 往往跨组织的任务中,由于涉及过多成员最后易形成责任者缺位现象,您如果身处其境会是什么心态?
- 您每一次离职时有没有过失落感?您跟过去就职过的公司的一、两个上司或同事还有联系吗?并说说他们目前的处境。
- 您的下属未按期完成您所布置给他的任务,如果您的上司责怪下来,您认为这是谁的责任,为什么?
- 在您以往的工作中是如何去约束部属的,是如何去调动他们积极性的?
- 举个例子来说明一下您曾经做过的一个成功计划及实施过程。工作中您发现自己的实施结果与事先计划出现较大的偏差,你将如何去行动?
- 说说您对下属布置的任务在时间方面是如何要求的?
- 说说您在完成上司布置的任务时,在时间方面是如何要求自己的8.
- 您以往在领导岗位中,一个月内分别有哪些主要的工作任务?
- 当您发现您的部属目前士气较低沉,您一般从哪些方面去调动?
- 说说您在以往领导岗位中出现管理失控的事例及事后的原因分析。您的部属在一个专业的问题上跟您发生争议,您如何对待这种事件?
