PISE (Protocol Inference with Symbolic Execution) is a tool that leverages symbolic execution and automata learning to uncover the state machine of a protocol implemented in a given executable. It is available in two modules:
- The server (this repo): for performing the symbolic execution. Implemented in Python.
- The client: responsible for automata learning. Implemented in Java.
- angr - symbolic execution engine
- PISEClient - the module that performs the actual learning ("Learner")
- Python - 3.8+
In order to start working with PISE, first clone this repo:
git clone https://github.com/ron4548/InferenceServer.git
cd InferenceServerWe recommend working with virtual environments, as angr recommends doing so:
python -m venv ./venvThen simply run source ./venv/bin/activate(linux) or venv\Scripts\activate.bat (Windows) to enter the virtual environment.
Now install all the required python packages:
pip install -r requirements.txtAnd you are done.
- Make sure you have installed PISEClient.
- Start a PISE server instance for the Gh0st RAT example:
python -m examples.ghost.gh0st_rat_inference. Wait for the server to load the binary and set hooks. - Start a PISE learner instance by running
mvn exec:java -Dexec.mainClass="com.pise.client.PiseLearner". PISE will now run. - While PISE is running, you will be able to see a snapshot of the currently learned state machine in
PISEClient/out/snapshot.dot.pngand the currently known message types inPISEClient/out/snapshot_alphabet.txt. - When the learning is done, the learned state machine will be available in
PISEClient/out/final_graph.dot.pngand the final set of message types inPISEClient/out/final_alphabet.txt.
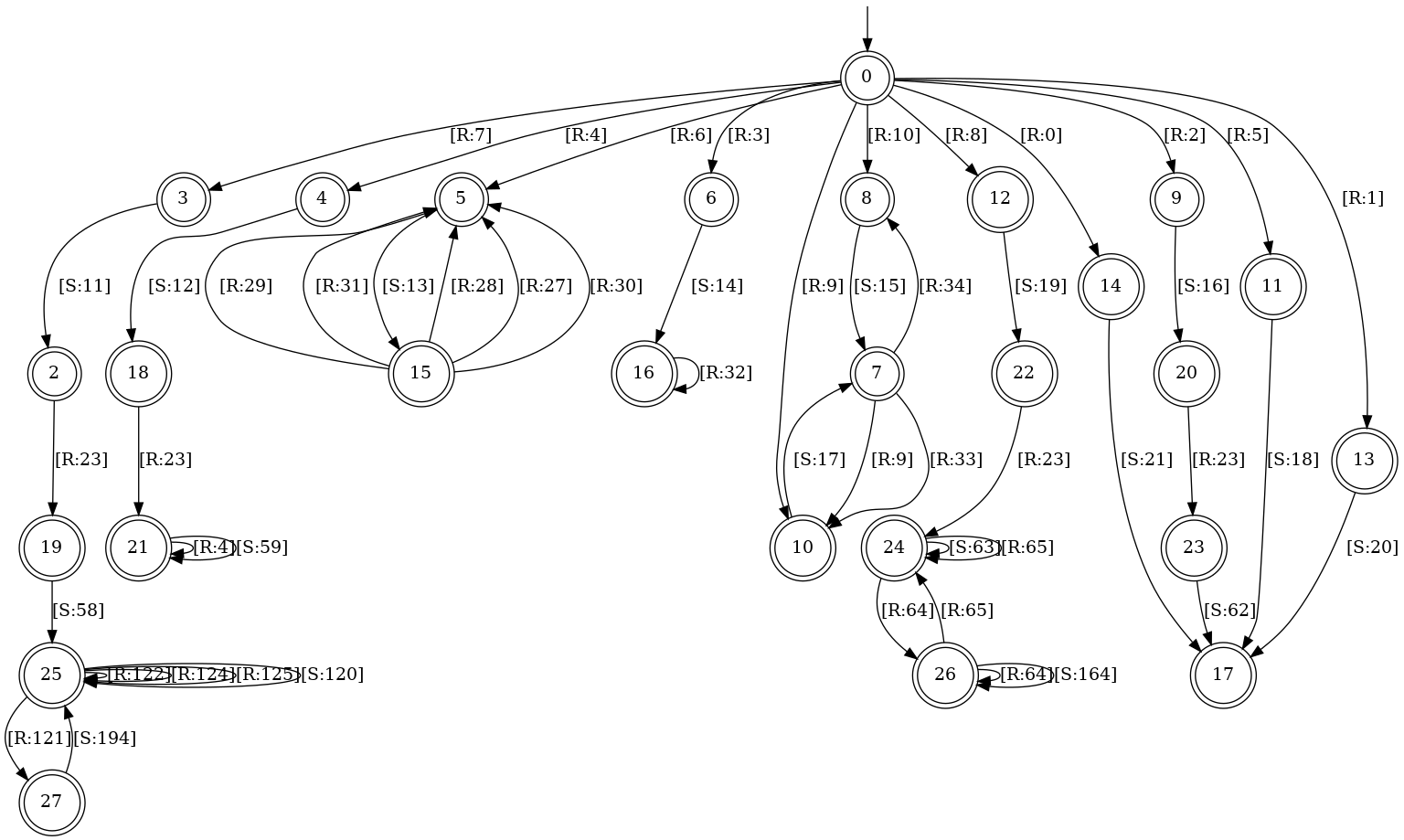
We demonstrate the application of the tool on a toy client we provide (examples/toy_example/toy_example). Alternatively, You can compile this example by executing cd examples/toy_example && make && cd ../... We recommend that you use the binary we provide to avoid issues with the extraction of the message buffer and length. The code that starts a server for the toy example already exists in examples/toy_example/toy_client_inference.py.
-
First we need to identify the addresses (or names) of the functions that send/receive messages within the executable. They can be as low-level as libc's
sendandreceive, or possibly a more abstract function likesend_messageorreceive_message. The key part here is to identify where are the message buffer and its length are stored within the program state, as well as what is the return value that indicates a successful send/receive of a message. We suggest doing so with a disassembler tool, like IDA. In our toy example we simply hook libc'ssendandreceivefunctions. -
Create a class to describe every function identified in (1). This class should implement the interface
SendReceiveCallSitethat contains 3 methods:# This interface describes a callsite that sends/receive messages in the binary, and therefore should be hooked class SendReceiveCallSite: # This function should set the hook within the symbolic execution engine # In our case it gets the angr project with the executable loaded # Return value is ignored def set_hook(self, angr_project): raise NotImplementedError() # This function should extract the buffer pointer and the buffer length from the program state # It is given the call_context as angr's SimProcedure instance, which contains under call_context.state the program state # Should return: (buffer, length) tuple def extract_arguments(self, call_context): raise NotImplementedError() # This function should return the suitable return value to simulate a successful send or receive from the callsite # It is given the buffer, the length and the call_context (which contains the state) # Should return: the return value that will be passed to the caller def get_return_value(self, buffer, length, call_context): raise NotImplementedError()
In our toy example, we simply hook
sendandreceive, which use the standard x86-64 calling convention. The functions should return the length of the provided buffer, to simulate a successful send or receive of the desired length.from pise import hooks # Hook libc's send function # The first argument is the buffer, the second argument is its length. # The return value should be simply the length of the buffer class ToySendHook(hooks.SendReceiveCallSite): def get_return_value(self, buff, length, call_context): # Something messed up with angr return value handling, so we simply set rax with the desired return value call_context.state.regs.rax = length def set_hook(self, p): p.hook_symbol('send', hooks.SendHook(self)) def extract_arguments(self, call_context): length = call_context.state.regs.edx buffer = call_context.state.regs.rsi return buffer, length # Hook libc's receive function # The first argument is the buffer, the second argument is its length. # The return value should be simply the length of the buffer class ToyRecvHook(hooks.SendReceiveCallSite): def get_return_value(self, buff, length, call_context): # Something messed up with angr return value handling, so we simply set rax with the desired return value call_context.state.regs.rax = length def set_hook(self, p): p.hook_symbol('recv', hooks.RecvHook(self)) def extract_arguments(self, call_context): length = call_context.state.regs.edx buffer = call_context.state.regs.rsi return buffer, length
-
Finally, we should setup a query runner and a server to use that query runner. In our example it looks like:
query_runner = sym_execution.QueryRunner('toy_example', [ToySendHook(), ToyRecvHook()]) server.Server(query_runner).listen()
where
toy_exampleis the binary to work with, and[ToySendHook(), ToyRecvHook()]is a list of call sites that should be hooked. The server simply gets a query runner for which it passes the queries, and listens for a learner to connect.The server will start up, and listen on port 8080, ready to process queries from the learner module.
The server for our toy example can be simply started with python -m examples.toy_example.toy_client_inference. Once your server is running, you are ready to start the learner.
The PISE paper is available here.
Our Black Hat USA 2022 briefing is available here.
