Problem
I was able to successfully transfer the model you proposed to the USD/RUB currency pair, which is traded on the Moscow Exchange, and classify the further behavior of the quotes within next 10 minutes. However, I was constantly failing to create a profitable trading strategy based on your model using the smoothed target you suggested:
-m_-(t)}{m_-(t)}})
It seemed strange to me, since the following two factors support the assumption that at least some kind of strategy can still be built:
- High ROC-AUC score (80%) on a well balanced binary classification.
- Beautiful and meaningful coloring of the price plot. Indeed, where there was an upward trend, the target turned out to be much greater than zero (green zones), and where there was a downward trend, it turned out to be much less (red zones):
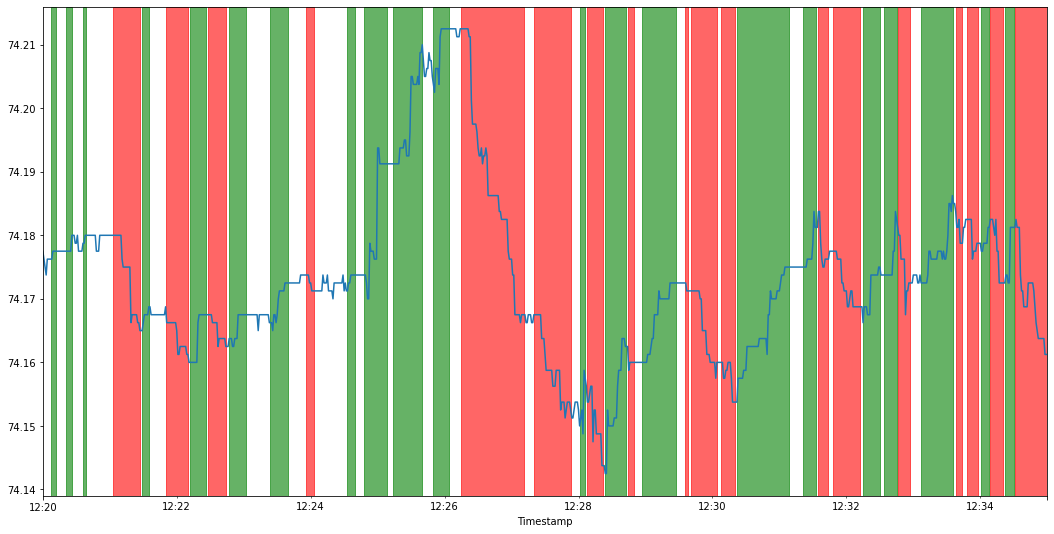
Then I realized that the target you proposed contains a rather obvious information leak, which can be described by the following formula:
-m_-(t)>\alpha\}=1)
Moreover:
-m_-(t)\,|\,p(t)-m_-(t)=\alpha\}=\alpha)
And this is what makes your target useless from the trading perspective, since at time t you cannot make deals at price m-minus(t).
To prove this I trained sklearn LogisticRegression using only one feature, which is the difference between the current price and m-minus term in the proposed target. ROC-AUC of such a simple model increased to 81%.
Then I refitted your model on the "noisy" alternative target, which is meaningful from the trading perspective (unlike the previous one):
-p(t)}{p(t)}})
ROC-AUC dropped to a value slightly greater than 50%, and this was not enough to beat even the bid-ask spread.
Conclusion
My experiment shows that the success you reached using the above target is not due to any "smoothing" as you say and the lack of noise, but only due to the bad target design. You simply made your target conditionally dependent on the trivially extracted feature information. Moreover, it is absolutely useless from the trading perspective, since at time t we cannot make deals at price m-minus(t), but only at something near to p(t).
























































































































