数据结构与算法系列笔记
在线阅读 >>
速览手册
·
Report Bug
·
参考资料
数据结构与算法系列笔记。
本书的精排目录导航版请参考 https://ng-tech.icu/Algorithm-Series。
Contributions are what make the open source community such an amazing place to be learn, inspire, and create. Any contributions you make are greatly appreciated.
- Fork the Project
- Create your Feature Branch (
git checkout -b feature/AmazingFeature) - Commit your Changes (
git commit -m 'Add some AmazingFeature') - Push to the Branch (
git push origin feature/AmazingFeature) - Open a Pull Request
-
Awesome-Lists: 📚 Guide to Galaxy, curated, worthy and up-to-date links/reading list for ITCS-Coding/Algorithm/SoftwareArchitecture/AI. 💫 ITCS-编程/算法/软件架构/人工智能等领域的文章/书籍/资料/项目链接精选。
-
Awesome-CS-Books: 📚 Awesome CS Books/Series(.pdf by git lfs) Warehouse for Geeks, ProgrammingLanguage, SoftwareEngineering, Web, AI, ServerSideApplication, Infrastructure, FE etc. 💫 优秀计算机科学与技术领域相关的书籍归档。
笔者所有文章遵循知识共享 署名 - 非商业性使用 - 禁止演绎 4.0 国际许可协议,欢迎转载,尊重版权。您还可以前往 NGTE Books 主页浏览包含知识体系、编程语言、软件工程、模式与架构、Web 与大前端、服务端开发实践与工程架构、分布式基础架构、人工智能与深度学习、产品运营与创业等多类目的书籍列表:

“Bad programmers worry about the code. Good programmers worry about data structures and their relationships.” — Linus Torvalds, creator of Linux
数据结构与算法的**适用于任何语言,开发者也应当能够使用他们日常工作的语言来快速实现常见的数据结构或者算法。本系列文章包含了 Java, JavaScript, Go, Rust, Python 等不同的语言实现,请参考关联仓库 algorithm-snippets 浏览。
首先,我们在数据结构与算法知识脑图中了解本系列包含的关键知识脉络:
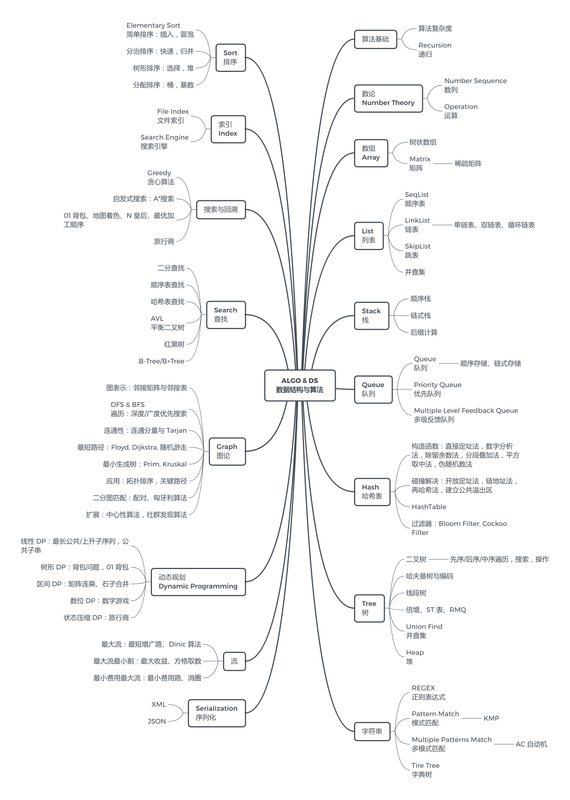
当我们谈起算法这个词时,必然会想到数据结构中相关的经典算法与数据挖掘、机器学习、深度学习等数据科学与人工智能中讨论的算法。算法(Algorithm),在数学(算学)和计算机科学之中,为任何良定义的具体计算步骤的一个序列,常用于计算、数据处理和自动推理。精确而言,算法是一个表示为有限长列表的有效方法,也即解决问题的一系列步骤。数据结构中的经典算法是对确定的数据 使用如数组,链表,队列,图等一系列存储结构进行存储,通过优化时间复杂度以及空间复杂度提高效率来对数据进行处理,得出问题答案的过程。而机器学习中的算法是一类从数据中运用数学工具自动分析获得规律,并利用规律对未知数据进行预测的算法,注重数据来源以及数据规律。
-
从目的做比较:经典算法是对确定的数据进行显而易见的操作,并注重效率(时间复杂度和空间复杂度)。例如排序。数据挖掘算法则是建立一个模式,学会对未知的数据进行预测或者分类。
-
从应用数学的深度以及广度做比较:经典算法主要涉及初等数学、简单概率论、简单离散数学等。数据挖掘主要涉及高等数学、概率论、线性代数、数理统计、微积分、运筹学、信息论、最优化方法等。
-
从评价标准做比较:经典算法主要考虑执行效率、时间复杂度、空间复杂度等维度。数据挖掘则主要考虑准确率、泛化能力、经验风险、结构风险等方面,例如正确率,召回率等。
-
从解决问题的种类做比较:经典算法主要是为了解决传统 CS 领域问题,譬如对数据进行组织并进行 CURD 操作。数据挖掘则面向预测,分类等未知问题,研究数据内在的规律。
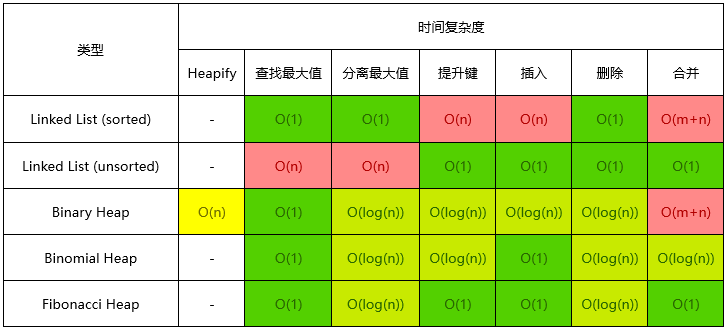
在数据结构与算法的学习中,我们最常见的就是用大 O 符号来描述算法的复杂度。

以下是一些最常用的大 O 标记法列表以及它们与不同大小输入数据的性能比较。
| 大 O 标记法 | 计算 10 个元素 | 计算 100 个元素 | 计算 1000 个元素 |
|---|---|---|---|
| O(1) | 1 | 1 | 1 |
| O(log N) | 3 | 6 | 9 |
| O(N) | 10 | 100 | 1000 |
| O(N log N) | 30 | 600 | 9000 |
| O(N^2) | 100 | 10000 | 1000000 |
| O(2^N) | 1024 | 1.26e+29 | 1.07e+301 |
| O(N!) | 3628800 | 9.3e+157 | 4.02e+2567 |
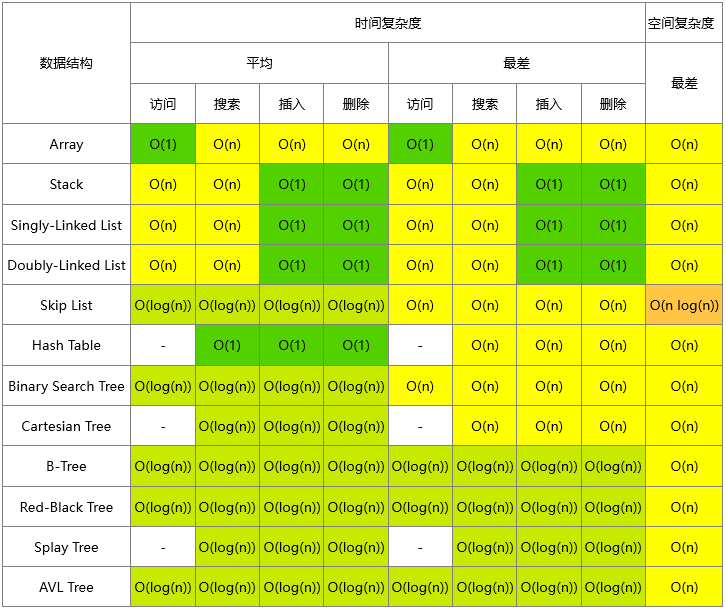
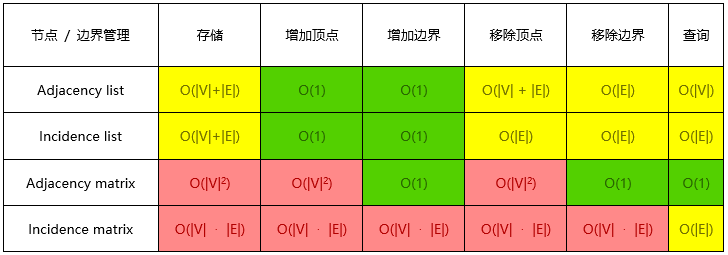
| 数据结构 | 连接 | 查找 | 插入 | 删除 | 备注 |
|---|---|---|---|---|---|
| 数组 | 1 | n | n | n | |
| 栈 | n | n | 1 | 1 | |
| 队列 | n | n | 1 | 1 | |
| 链表 | n | n | 1 | 1 | |
| 哈希表 | - | n | n | n | 在完全哈希函数情况下,复杂度是 O(1) |
| 二分查找树 | n | n | n | n | 在平衡树情况下,复杂度是 O(log(n)) |
| B 树 | log(n) | log(n) | log(n) | log(n) | |
| 红黑树 | log(n) | log(n) | log(n) | log(n) | |
| AVL 树 | log(n) | log(n) | log(n) | log(n) | |
| 布隆过滤器 | - | 1 | 1 | - | 存在一定概率的判断错误(误判成存在) |
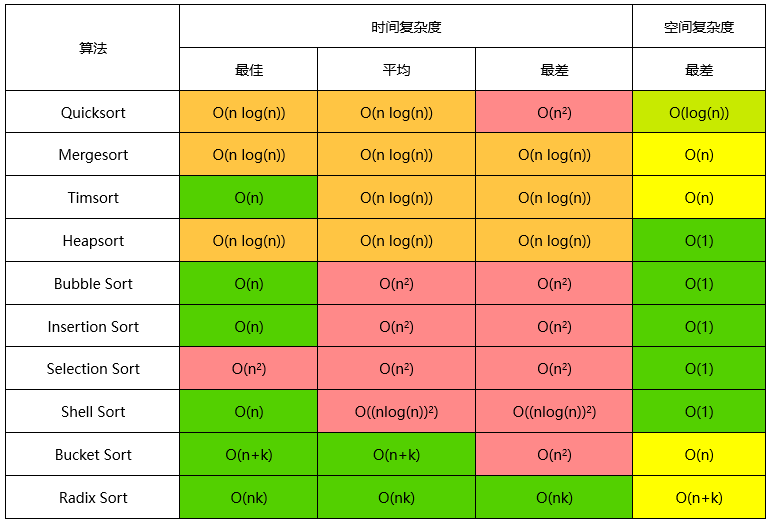
| 名称 | 最优 | 平均 | 最坏 | 内存 | 稳定 | 备注 |
|---|---|---|---|---|---|---|
| 冒泡排序 | n | n^2 | n^2 | 1 | Yes | |
| 插入排序 | n | n^2 | n^2 | 1 | Yes | |
| 选择排序 | n^2 | n^2 | n^2 | 1 | No | |
| 堆排序 | n log(n) | n log(n) | n log(n) | 1 | No | |
| 归并排序 | n log(n) | n log(n) | n log(n) | n | Yes | |
| 快速排序 | n log(n) | n log(n) | n^2 | log(n) | No | 在 in-place 版本下,内存复杂度通常是 O(log(n)) |
| 希尔排序 | n log(n) | 取决于差距序列 | n (log(n))^2 | 1 | No | |
| 计数排序 | n + r | n + r | n + r | n + r | Yes | r - 数组里最大的数 |
| 基数排序 | n * k | n * k | n * k | n + k | Yes | k - 最长 key 的升序 |