oracle's People
Contributors


Stargazers


Watchers

oracle's Issues
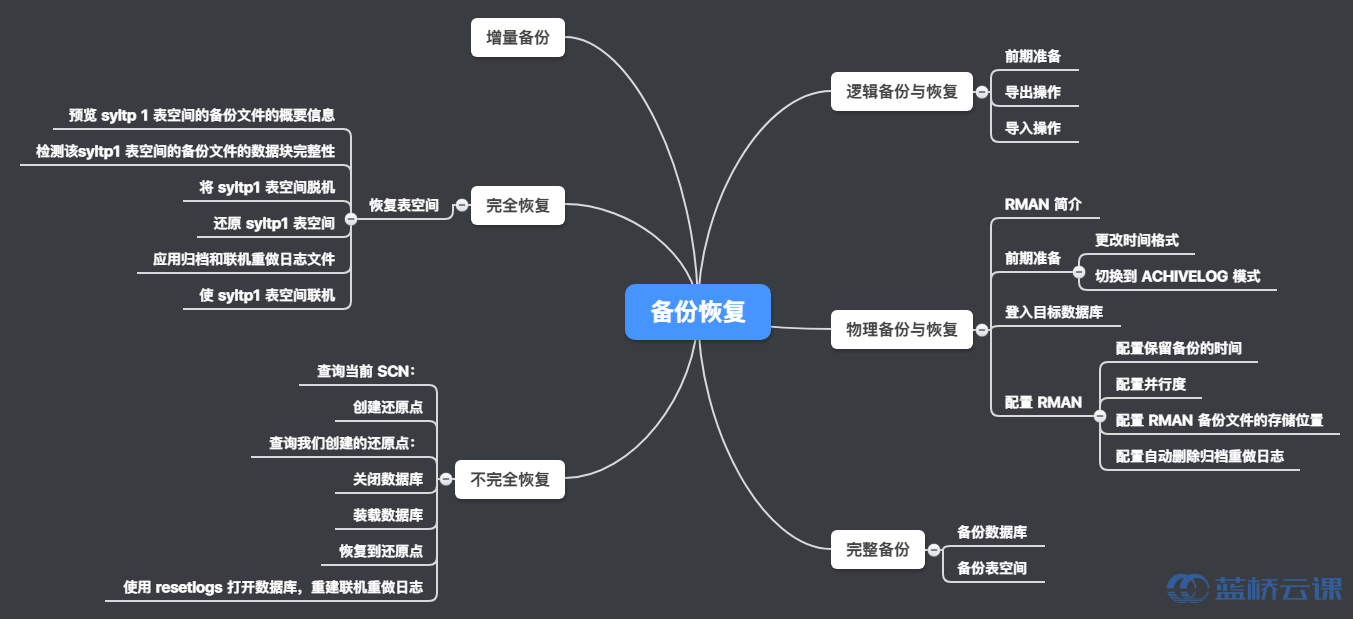
备份恢复
备份恢复
实验介绍
实验内容
本节实验主要讲解了 Oracle 的备份与恢复,包括了逻辑和物理备份与恢复,完整和增量备份,以及完全恢复和不完全恢复。
实验知识点
-
概述
-
逻辑备份与恢复
-
物理备份与恢复
-
完整备份
-
增量备份
-
完全恢复
-
不完全恢复
概述
备份包括逻辑备份和物理备份:
- 逻辑备份是一个导出的操作,它会去查询数据库对象(比如表,用户,存储过程等),然后将创建数据对象和数据的命令写到一个导出转储文件中,要恢复时直接执行导入,就回去读取转储文件中的命令并执行。
- 物理备份是转储的实际文件,比如控制文件,数据文件等等。
逻辑备份与恢复
逻辑备份与恢复使用的是 Data Pump Export 和 Data Pump Import 工具。
这里以导出表 student 和导入表 student 为例。
前期准备
在开始进行导出导入之前,我们需要做如下准备:
- 创建一个目录用来存放日志和转储文件。(也可不创建,直接使用这个目录
$ORACLE_BASE/admin/<database_name>/dpdump) - 在 Oracle 内创建一个指向该目录的指针。
首先修改目录 /u01 的所有者:
$ sudo chown -R oracle.dba /u01然后用 sqlplus 登录进 system 用户:
$ sqlplus system/Syl12345然后创建一个指向该目录的指针:
SQL> create directory dpd as '<oracle_base>/admin/xe/dpdump';上面的
<oracle_base>替换成自己的ORACLE_BASE目录。可以在终端使用命令echo $ORACLE_BASE查看。
创建好后可以用一下命令查询到:
SQL> select * from dba_directories where directory_name='DPD';导出操作
接下来使用 expdp 备份,注意这个命令是在 linux 命令行执行的:
$ expdp system/Syl12345 tables=student directory=dpd dumpfile=exp_student.dmp
system/Syl12345是执行备份的用户名和密码。
tables是指定要备份的表。
directory是指定备份存放的位置。如果不指定参数,则会存放到默认位置DATA_PUMP_DIR,可以使用select * from dba_directories where directory_name='DATA_PUMP_DIR';查询到。
dumpfile是指定备份的文件名。
除了可以指定上述的参数外,还有很多其他的参数,可参见 expdp 命令行输入参数 。
导入操作
将 student 表导入并更名为 studentbak 。
$ impdp system/Syl12345 remap_table=student:studentbak directory=dpd dumpfile=exp_student.dmp
remap_table指定在导入时更改表名。冒号左边的是旧表名,冒号右边的是新表名。如果你想直接覆盖 student 表的话可以使用TABLE_EXISTS_ACTION=REPLACE。dumpfile指定要导入备份的文件名。
除了可以指定上述的参数外,还有很多其他的参数,可参见 impdp 命令行输入参数。
物理备份与恢复
物理备份包含脱机备份和联机备份:
- 脱机备份:在关闭数据库后对数据库文件进行备份
- 联机备份:在数据库启动的情况下对数据库文件进行备份。此时数据库处于归档日志模式(也就是
ACHIVELOG)模式。
我们通常使用 RMAN 工具在归档日志模式下进行备份。
RMAN 简介
RMAN (Recovery Manage)是一个备份工具。它有两种跟踪备份的方法:
- 通过备份数据库的控制文件
- 通过另一个数据库的恢复目录
通常我们将执行备份和还原操作的数据库称为目标数据库。更多有关 RMAN 的介绍可参考 RMAN Backup Concepts 。
在开始备份之前,先执行我们的准备工作。
前期准备
更改时间格式
更改 NLS_DATE_FORMAT 参数。这个步骤主要是为了让 RMAN 显示输出信息中的时间包含小时,分钟和秒,以便于能够获取执行命令更精确的时间信息。因为默认是不包含小时,分钟和秒的,所以需要更改。
$ export NLS_DATE_FORMAT='dd-mon-yyyy hh24:mi:ss'切换到 ACHIVELOG 模式
数据库默认是在非归档日志模式(NOARCHIVELOG)下。我们可以使用下面的方法进行查看。
首先以 sys 用户登入:
$ sqlplus sys/Syl12345 as sysdba然后即可查询当前归档模式:
SQL> select name,log_mode from v$database;
NAME LOG_MODE
------------------ ------------------------
XE NOARCHIVELOG想要切换到归档日志模式下,有以下几个主要步骤:
- 关闭数据库
- 启动数据库到
MOUNT阶段 - 切换为归档日志模式
- 打开数据库
- 查看归档模式
SQL> shutdown immediate;
SQL> startup mount;
SQL> alter database archivelog;
SQL> alter database open;
SQL> archive log list;这样就切换到归档模式了,归档程序进程 ARCn 会启动,归档日志会写入快速恢复区,它所在的目录可以通过如下命令查询到:
SQL> select dest_name,destination from v$ARCHIVE_DEST where dest_name='LOG_ARCHIVE_DEST_1';
SQL> show parameter db_recovery;登入目标数据库
使用如下语句可以登入本地数据库实例:
$ rman target /是以
sysdba权限的用户身份登入的。
更多和连接目标数据库相关内容可参考 Starting RMAN and Connecting to a Database 。
登入进去过后也可以执行 sql 语句,比如查询表空间有哪些:
注意:前面的 RMAN> 不用输入,只是用来代表命令是在 RMAN 命令行输入的。
RMAN> select * from v$tablespace;
TS# NAME INC BIG FLA ENC CON_ID
---------- ------------------------------ --- --- --- --- ----------
1 SYSAUX YES NO YES 0
0 SYSTEM YES NO YES 0
2 UNDOTBS1 YES NO YES 0
4 USERS YES NO YES 0
3 TEMP NO NO YES 0
5 SYLTP1 YES NO YES 0
9 TMP_SP1 NO NO YES 0RMAN 有许多可用命令,参见 About RMAN Commands 。
配置 RMAN
在执行备份前,我们最好配置一下 RMAN 。我们可以通过如下命令查看它的默认配置:
RMAN> show all;
注:它的配置很多,不止下面将会用到的配置,想了解更多配置可参考 RMAN 配置 。
下面将会做这些配置步骤:
- 配置保留备份的时间
- 配置并行度
- 配置 RMAN 备份文件的存储位置
- 配置自动删除归档重做日志
配置保留备份的时间
如下命令配置了 RMAN 不会废弃 3 天内的数据文件和归档重做日志备份:
RMAN> configure retention policy to recovery window of 3 days;
压缩备份
RMAN> configure device type disk backup type to compressed backupset;
compressed代表压缩备份集,可节省空间。
在企业版中还可以通过命令configure device type disk parallelism n backup type to compressed backupset;设置以 n 个通道并行执行。(n 代表一个数字)。
配置 RMAN 备份文件的存储位置
RMAN> configure channel device type disk format '/u01/rman_%U';
%U是动态字符串。这样每次 RMAN 存储的备份文件的文件名不重复。
配置自动删除归档重做日志
下面的命令配置当归档重做日志在磁盘中至少备份两次时,归档重做日志可自动被删除。
RMAN> configure archivelog deletion policy to backed up 2 times to disk;
完成了上述的准备和配置操作后,就可以开始进入到我们备份操作的实验中了。
完整备份
下面以备份数据库和表空间为例。
备份数据库
直接执行下面的命令就可以备份数据库了:
RMAN> backup database;
备份完成过后,在我们开始设置的备份文件的存储位置可以看到我们有我们的备份文件。
备份表空间
这里就以备份我们之前在安全性管理的实验中创建的 syltp1 表空间为例。
RMAN> backup tablespace syltp1;
备份完成后,在我们配置的位置就可以看到该备份文件。
增量备份
我们上面的备份操作都是将整个数据库或者整个表空间备份下来。增量备份就是先创建一个初始备份文件,这个创建操作被称为 0 级备份,以后的备份操作( 1 级备份)只是在初始备份文件的基础上备份了改变了的数据块。这样的话节省了很多时间和空间,因为 1 级备份的备份文件只是包含了改变了的数据块。
下面以增量备份 syltp1 表空间为例。
首先要进行我们的 0 级备份操作:
RMAN> backup incremental level 0 tablespace syltp1;
这个时候就创建了初始备份文件。以后备份的时候可以使用 1 级备份,如下所示:
RMAN> backup incremental level 1 tablespace syltp1;
完全恢复
注意完全恢复并不是对应的完整备份。它只是指这个恢复是完全的,没有丢失数据。它在数据库打开状态即可进行,根据我们上面备份操作产生的备份文件进行还原和恢复。
恢复表空间
假设表空间 syltp1 现在已经损坏了,那么我们就需要使用之前的 syltp1 表空间的备份来恢复该表空间。接下来的恢复操作有一下几个主要步骤:
- 预览该表空间的备份文件的概要信息
- 检测该表空间的备份文件的数据块完整性
- 将该表空间脱机
- 还原该表空间
- 应用归档和联机重做日志文件
- 使该表空间联机
预览 syltp 1 表空间的备份文件的概要信息
RMAN> restore tablespace syltp1 preview summary;
检测该syltp1 表空间的备份文件的数据块完整性
RMAN> restore tablespace syltp1 validate;
将 syltp1 表空间脱机
RMAN> alter tablespace syltp1 offline immediate;
脱机后该表空间就不可访问了。
还原 syltp1 表空间
RMAN> restore tablespace syltp1;
应用归档和联机重做日志文件
RMAN> recover tablespace syltp1;
使 syltp1 表空间联机
RMAN> alter tablespace syltp1 online;
至此,恢复 syltp1 表空间的操作就完成了。
不完全恢复
同样,不完全恢复并不是对应的增量备份。有时候,我们在一段时间内执行了很多错误的修改,比如说误删了很多东西,这个时候就可以用不完全备份将数据库恢复到过去的某个时刻的状态。它要在数据库装载模式下进行。并且要重建联机重做日志文件。
下面的实验将学习如何进行不完全恢复,不完全恢复主要有以下几个步骤:
- 创建还原点
- 关闭数据库
- 装载数据库
- 恢复到还原点
- 打开数据库
查询当前 SCN:
RMAN> select current_scn from v$database;
注:SCN:系统变更编号。 SCN的值是对数据库进行更改的逻辑时间点。它有点像一个版本号的概念。
创建一个测试表。
RMAN> create table syl_res (id number);
我们下面来基于 SCN 创建一个还原点。
创建还原点
RMAN> create restore point syl_res_scn;
查询我们创建的还原点:
RMAN> select name,scn from v$restore_point;
此操作查询出还原点的名称和 SCN。
还原点有一定的保存时间,由初始参数 CONTROL_FILE_RECORD_KEEP_TIME 控制的。可以使用如下命令查看其值:
RMAN> select name,value from v$parameter where name='control_file_record_keep_time';
创建好还原点后,我们删除表 syl_res :
RMAN> drop table syl_res;
RMAN> select * from tab where tname='syl_res';
后来我们发现这个表是误删,想要回到之前的还原点,就可以执行如下操作:
关闭数据库
RMAN> shutdown immediate;
装载数据库
RMAN> startup mount;
恢复到还原点
RMAN> restore database until restore point syl_res_scn;
RMAN> recover database until restore point syl_res_scn;
使用 resetlogs 打开数据库,重建联机重做日志
RMAN> alter database open resetlogs;
再查询表 syl_res 会发现这个表已经被恢复了:
RMAN> select * from tab where tname='SYL_RES';
更多有关 RMAN 备份还原的内容可参考 Getting Started withRMAN 。
总结
适配 12.1.0.2 标准版
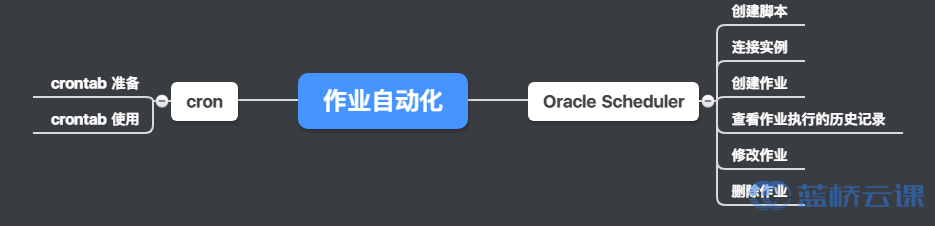
作业自动化
实验介绍
实验内容
在使用数据库的过程中,通常会有一些重复的事情,比如备份操作,检查错误,启动数据库等等。如果每次都手动操作,不仅有可能忘记而且很麻烦,如果创建一个作业,让系统自动处理会很方便。本节实验主要介绍两个用来实现作业自动化的程序:
Oracle Scheduler:这个是 Oracle 提供的。cron:这个是 Linux 系统本身就有的。
实验知识点
- 使用 Oracle Scheduler 实现作业自动化
- 使用 crontab 实现作业自动化
Oracle Scheduler
这里以定期备份表空间 system 为例。
创建脚本
创建一个 bash 脚本,执行作业的时候会执行这个脚本,以实现备份。
$ vi /home/oracle/backup_system.sh输入如下内容:
#!/bin/bash
rman target / <<EOF
backup tablespace system;
EOF
exit 0连接实例
$ sqlplus system/Syl12345创建作业
创建作业需要用到 DBMS_SCHEDULER 软件包的 CREATE_JOB 过程,它需要的参数可以使用 desc DBMS_SCHEDULER 查看到,参数详情可以参阅 DBMS_SCHEDULER 。
下面就创建一个作业,实现在每周的星期五备份表空间 system。
注:下面命令在 SQL 命令行输入
BEGIN
DBMS_SCHEDULER.CREATE_JOB(
job_name => 'BACKUP_SYSTEM',
job_type => 'EXECUTABLE',
job_action => '/home/oracle/backup_system.sh',
repeat_interval => 'FREQ=WEEKLY;BYDAY=FRI;BYHOUR=4',
start_date => to_date('04-03-2018','dd-mm-yyyy'),
job_class => '"DEFAULT_JOB_CLASS"',
auto_drop => FALSE,
comments => 'backup system tablespace',
enabled => TRUE
);
END;
/
=>右边的值会传入左边的参数。
参数解释:
| 参数 | 说明 |
|---|---|
| job_name | 作业名。 |
| job_type | 作业类型。这里是调用的 bash 脚本,所以为 EXECUTABLE 。它还有其他值,可以调用 sql 脚本,plsql 语句块等等。 |
| job_action | 作业执行的动作。这里是执行 backup_system.sh 这个 bash 脚本。 |
| repeat_interval | 这里指在每周五早上 4 点执行备份操作。 |
| start_date | 开始日期。 |
| job_class | 作业类。这里使用的是默认的作业类。 |
| auto_drop | 这里设为 FALSE ,表示不会在作业完成后自动删除。 |
| comments | 这个作业的描述。 |
| enabled | 指示作业是否应在创建后立即启用。这里是立即启用。 |
创建好了作业,我们可以通过如下命令查询到作业:
SQL> select job_name,repeat_interval from dba_scheduler_jobs where job_name='BACKUP_SYSTEM';有关创建作业更多内容可参考 CREATE_JOB 。
查看作业执行的历史记录
作业执行时,会生成一条执行作业的历史记录,我们可以通过如下命令查询:
SQL> select job_name,log_date,operation,status from dba_scheduler_job_log where job_name='BACKUP_SYSTEM';这里如果查询没有结果,说明作业还没有执行过。
日志纪录的默认保留天数是 30 天。这个时间是可以修改,例如把时间修改为 29 天:
SQL> exec dbms_scheduler.set_scheduler_attribute('log_history',29);修改作业
可以调用 DBMS_SCHEDULER 包的一些过程实现修改作业,启动,暂停,停止作业等操作。
例:把作业的执行时间更改为每天一次。
exec DBMS_SCHEDULER.set_attribute(-
name => 'BACKUP_SYSTEM',-
attribute => 'repeat_interval',-
value => 'FREQ=DAILY' -
);
还有一些其他过程:
run_job:启动作业enable:启动暂停的作业disable:暂停作业copy_job:复制作业
注:你在使用上面几个过程的时候可能会报权限的错误,那是由于实验环境的原因,默认是采用 shiyanlou 用户去执行了,自己的环境操作时不会遇此问题。
不止列举的这些,还有很多其他可调用的过程,可参阅 DBMS_SCHEDULER 。
删除作业
例如删除我们新建的 BACKUP_SYSTEM 这个作业。
exec DBMS_SCHEDULER.drop_job(job_name='BACKUP_SYSTEM');
crontab
crontab 命令常见于 Unix 和类 Unix 的操作系统之中(Linux 就属于类 Unix 操作系统),用于设置周期性被执行的指令。它通过守护进程 cron 使得任务能够按照固定的时间间隔在后台自动运行。cron 利用的是一个被称为 “cron 表”(cron table)的文件,这个文件中存储了需要执行的脚本或命令的调度列表以及执行时间。
当使用者使用 crontab 后,该项工作会被记录到/var/spool/cron/ 里。不同用户执行的任务记录在不同用户的文件中。
通过 crontab 命令,我们可以在固定的间隔时间或指定时间执行指定的系统指令或脚本。时间间隔的单位可以是分钟、小时、日、月、周的任意组合。
这里我们看一看 crontab 的格式
# Example of job definition:
# .---------------- minute (0 - 59)
# | .------------- hour (0 - 23)
# | | .---------- day of month (1 - 31)
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
# | | | | |
# * * * * * command to be executed
其中特殊字符的意义:
| 特殊字符 | 意义 |
|---|---|
| * | 任何时刻 |
| , | 分隔时段,例如0 7,9 * * * command代表7:00和9:00 |
| - | 时间范围,例如30 7-9 * * * command 代表7点到9点之间每小时的30分 |
| /n | 每隔n单位间隔,例如*/10 * * * * 每10分钟 |
crontab 准备
crontab 在本实验环境中需要做一些特殊的准备,首先我们会启动 rsyslog,以便我们可以通过日志中的信息来了解我们的任务是否真正的被执行了(在本实验环境中需要手动启动,而在自己本地中 Ubuntu 会默认自行启动不需要手动启动)
sudo service rsyslog start在本实验环境中 crontab 也是不被默认启动的,同时不能在后台由 upstart 来管理,所以需要我们手动启动它(同样在本实验环境中需要手动启动,自己的本地 Ubuntu 的环境中也不需要手动启动)
sudo cron -f &crontab 使用
使用 crontab 的基本语法如下:
crontab [-u username] [-l|-e|-r]其常用的参数有:
| 选项 | 意思 |
|---|---|
-u |
只有root才能进行这个任务,帮其他使用者创建/移除crontab工作调度 |
-e |
编辑crontab工作内容 |
-l |
列出crontab工作内容 |
-r |
移除所有的crontab工作内容 |
我们这里还是以定期备份表空间为例。首先执行如下命令以添加一个任务计划:
$ crontab -e第一次启动会出现这样一个画面,这是让我们选择编辑的工具,选择第一个基本的 vim 就可以了
选择后我们会进入一个添加计划的界面,按 i 键便可编辑文档,在文档的最后一行加上这样一行命令,实现每周日 9 点执行备份操作。
00 09 * * 0 /home/oracle/BACKUP_SYSTEM.sh输入完成后按 esc 再输入 :wq 保存并退出。
添加成功后我们会得到 installing new crontab 的一个提示 。
为了确保我们任务添加的正确与否,我们会查看添加的任务详情:
$ crontab -l
虽然我们添加了任务,但是如果 cron 的守护进程并没有启动,当然也就不会帮我们执行,我们可以通过以下 2 种方式来确定我们的 cron 是否成功的在后台启动,若是没有则需要启动一次。
$ ps aux | grep cron
#或者使用下面
$ pgrep cron另外,可以通过如下命令查看执行任务命令之后在日志中的信息反馈:
$ sudo tail -f /var/log/syslog当我们并不需要某个任务的时候我们可以通过 -e 参数去配置文件中删除相关命令,若是我们需要清除所有的计划任务,我们可以使用这么一个命令去删除任务:
$ crontab -r总结
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.