xtra-computing / thundergbm Goto Github PK
View Code? Open in Web Editor NEWThunderGBM: Fast GBDTs and Random Forests on GPUs
License: Apache License 2.0
ThunderGBM: Fast GBDTs and Random Forests on GPUs
License: Apache License 2.0
































































































































10 images(250*250)takes me 17s to train a model.
But it takes me 0.6s to predict by my trained model.
Is it normal that I spent so long time to run forward?
thanks!!!
Hi,in your document ,it says that the parameters is identical to XBoost. So Does thunderGBM support early stopping? It seems that 'thundergbm.sparse_train_scikit' doesn't support this parameter.
My system is:
(_env) D:_env\project\series>nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 442.19 Driver Version: 442.19 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+=================|
| 0 GeForce RTX 2070 WDDM | 00000000:01:00.0 Off | N/A |
| N/A 46C P8 7W / N/A | 219MiB / 8192MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|==============================================|
| 0 7852 C+G ...xperience\NVIDIA GeForce Experience.exe N/A |
+-----------------------------------------------------------------------------+
I am on Windows 10
When trying to run the TGBMClassifier I get the following error:
2020-02-22 20:13:15,901 INFO [default] #instances = 20289, #features = 40
2020-02-22 20:13:16,503 INFO [default] convert csr to csc using gpu...
2020-02-22 20:13:16,878 INFO [default] Converting csr to csc using time: 0.363863 s
2020-02-22 20:13:16,878 INFO [default] Fast getting cut points...
2020-02-22 20:13:16,878 FATAL [default] Check failed: [error == cudaSuccess] out of memory
2020-02-22 20:13:16,894 WARNING [default] Aborting application. Reason: Fatal log at [D:_env\project\series\thundergbm\src\thundergbm\syncmem.cpp:107]
Any suggestion how to fix this?
I have some question for save & load model with thundergbm. there are two problem.
1.
the problem is why some hyperparameter value is different from training when i load the model. it seem some hyperparameter value is the same as default setting. for example, i change 'depth','max_num_bin','column_sampling_rate' in training stage. but it has different value when i load the model.
2.
The predict value is all zero, it seem unreasonable.
The follow is my code and os/gpu information, could someone tell me whether i have wrong operation , thanks.
#------------------------------------------------------------------------
from thundergbm import TGBMClassifier
from sklearn import datasets
clf = TGBMClassifier(verbose=0,n_trees=20,depth=8,
... max_num_bin=200,column_sampling_rate=0.8,
... learning_rate=0.8,objective='multi:softmax')
X, y = datasets.load_digits(return_X_y=True)
clf.fit(X, y)
TGBMClassifier(bagging=0, column_sampling_rate=0.8, depth=8, gamma=1.0,
lambda_tgbm=1.0, learning_rate=0.8, max_num_bin=200,
min_child_weight=1.0, n_gpus=1, n_parallel_trees=1, n_trees=20,
num_class=10, objective='multi:softmax', tree_method='auto',
verbose=0)
model_path='/home/admin/Desktop/tgbm.model'
clf.save_model(model_path)
print(clf.predict(X))
[0. 1. 2. ... 8. 9. 8.]
clf2 = TGBMClassifier(objective='multi:softmax')
clf2.load_model(model_path)
print(clf2)
TGBMClassifier(bagging=0, column_sampling_rate=1.0, depth=6, gamma=1.0,
lambda_tgbm=1.0, learning_rate=0.800000011920929,
max_num_bin=255, min_child_weight=1.0, n_gpus=1,
n_parallel_trees=1, n_trees=20, num_class=10,
objective='multi:softmax', tree_method='auto', verbose=1)
y_pred = clf2.predict(X)
print(y_pred)
[0. 0. 0. ... 0. 0. 0.]
#------------------------------------------------------------------------
Ubuntu 16.04
NVIDIA driver : 440.44
CUDA Version: 10.2
GPU - GeForce RTX 2080
RuntimeError Traceback (most recent call last)
in
----> 1 import thundergbm
E:\Anaconda\envs\tf\lib\site-packages\thundergbm_init_.py in
8 """
9 name = "thundergbm"
---> 10 from .thundergbm import *
E:\Anaconda\envs\tf\lib\site-packages\thundergbm\thundergbm.py in
32 thundergbm = CDLL(lib_path)
33 else:
---> 34 raise RuntimeError("Please build the library first!")
35
36 OBJECTIVE_TYPE = ['reg:linear', 'reg:logistic', 'binary:logistic',
RuntimeError: Please build the library first!
import json
import numpy as np
import pandas as pd
import thundergbm
INPUT_DIR = 'https://raw.githubusercontent.com/ArtyomSalnikov/tmp/master/'
X_train = pd.read_csv(INPUT_DIR+'X_train.csv')
y_train = np.ravel(pd.read_json(INPUT_DIR+'y_train.json').values)
thundergbm.TGBMRegressor().fit(X_train, y_train)
I installed thundergbm via pip install thundergbm-cu10-0.2.0-py3-none-win_amd64.whl which is described in quick install of README.rd.
There are no TGBMClassifier and TGBMRegressor in thundergbm_scikit.py, but only TGBMModel.
I think you'd better to make these two classes in thundergbm_scikit.py or rewrite how-to-use.
为什么y_predict=clf.predict(x,y)后输出y_predict结果是none
I have same problem about out of memory.According to my observation,
it seems related to model complexity(ex: depth or n_trees too large ? ).
is there any method to solve it?
The follow is my code and os/gpu information and error message.
from thundergbm import TGBMClassifier
from sklearn import datasets
import numpy as np
dim=9
row_num=30000
X=np.random.random((row_num,dim))
X = X.astype('float32')
y=np.random.randint(0,7,row_num)
y = y.astype('int32')
clf = TGBMClassifier(depth=18, n_trees=1000,verbose=0,bagging=0)
clf.fit(X, y)
#------------------------------------------------------------------------
Ubuntu 16.04
NVIDIA driver : 440.44
CUDA Version: 10.2
GPU - GeForce RTX 2080
#------------------------------------------------------------------------
Error message
1.
2020-04-09 18:12:35,082 FATAL [default] Check failed: [error == cudaSuccess] out of memory
2020-04-09 18:12:35,082 WARNING [default] Aborting application. Reason: Fatal log at [/home/admin/Desktop/EverComm_ibpem_gpu/thundergbm/src/thundergbm/syncmem.cpp:107]
Aborted (core dumped)
2020-04-09 18:41:17,156 FATAL [default] Check failed: [size() == source.size()] destination and source count doesn't match
2020-04-09 18:41:17,156 WARNING [default] Aborting application. Reason: Fatal log at [/home/admin/Desktop/EverComm_ibpem_gpu/thundergbm/include/thundergbm/syncarray.h:91]
Aborted (core dumped)
CUDA error 4 [C:\Users\Administrator\Desktop\thundergbm\cub\cub/util_allocator.cuh, 657]: driver shutting down
CUDA error 4 [C:\Users\Administrator\Desktop\thundergbm\src\thundergbm\syncmem.cpp, 576]: driver shutting down
CUDA error 4 [C:\Users\Administrator\Desktop\thundergbm\cub\cub/util_allocator.cuh, 657]: driver shutting down
CUDA error 4 [C:\Users\Administrator\Desktop\thundergbm\src\thundergbm\syncmem.cpp, 576]: driver shutting down
CUDA error 4 [C:\Users\Administrator\Desktop\thundergbm\cub\cub/util_allocator.cuh, 657]: driver shutting down
CUDA error 4 [C:\Users\Administrator\Desktop\thundergbm\src\thundergbm\syncmem.cpp, 576]: driver shutting down
CUDA error 4 [C:\Users\Administrator\Desktop\thundergbm\cub\cub/util_allocator.cuh, 657]: driver shutting down
CUDA error 4 [C:\Users\Administrator\Desktop\thundergbm\src\thundergbm\syncmem.cpp, 576]: driver shutting down
CUDA error 4 [C:\Users\Administrator\Desktop\thundergbm\cub\cub/util_allocator.cuh, 657]: driver shutting down
CUDA error 4 [C:\Users\Administrator\Desktop\thundergbm\cub\cub/util_allocator.cuh, 657]: driver shutting down
Process finished with exit code 0
Hi there,
Many thanks for your good library.
I have an issue when import TGBMClassifier:
FileNotFoundError Traceback (most recent call last)
in
1 #from thundergbm import TGBMClassifier
----> 2 from thundergbm import TGBMClassifier
3 #clf = TGBMClassifier()
~\AppData\Roaming\Python\Python39\site-packages\thundergbm_init_.py in
8 """
9 name = "thundergbm"
---> 10 from .thundergbm import *
~\AppData\Roaming\Python\Python39\site-packages\thundergbm\thundergbm.py in
30 # print(lib_path)
31 if path.exists(lib_path):
---> 32 thundergbm = CDLL(lib_path)
33 else:
34 raise RuntimeError("Please build the library first!")
c:\python\lib\ctypes_init_.py in init(self, name, mode, handle, use_errno, use_last_error, winmode)
372
373 if handle is None:
--> 374 self._handle = _dlopen(self._name, mode)
375 else:
376 self._handle = handle
FileNotFoundError: Could not find module 'C:\Users\thang\AppData\Roaming\Python\Python39\site-packages\thundergbm\thundergbm.dll' (or one of its dependencies). Try using the full path with constructor syntax.
I Checked the path above and the module thundergbm.dll already in that folder

Please help me fix this issue.
Thank you very much for your help.
Hi, I am getting the following error when calling make -j
[ 3%] Building CXX object src/thundergbm/CMakeFiles/thundergbm.dir/objective/ranking_obj.cpp.o
/tmp/thundergbm/src/thundergbm/objective/ranking_obj.cpp: In member function ‘virtual void LambdaRank::get_gradient(const SyncArray<float>&, const SyncArray<float>&, SyncArray<GHPair>&)’:
/tmp/thundergbm/src/thundergbm/objective/ranking_obj.cpp:50:14: error: ‘mt19937’ is not a member of ‘std’
std::mt19937 gen(std::rand());
^~~~~~~
/tmp/thundergbm/src/thundergbm/objective/ranking_obj.cpp:50:14: note: suggested alternative:
In file included from /usr/include/c++/7/tr1/random:47:0,
from /usr/include/c++/7/parallel/random_number.h:36,
from /usr/include/c++/7/parallel/partition.h:38,
from /usr/include/c++/7/parallel/quicksort.h:36,
from /usr/include/c++/7/parallel/sort.h:48,
from /usr/include/c++/7/parallel/algo.h:45,
from /usr/include/c++/7/parallel/algorithm:37,
from /tmp/thundergbm/src/thundergbm/objective/ranking_obj.cpp:6:
/usr/include/c++/7/tr1/random.h:701:7: note: ‘std::tr1::mt19937’
> mt19937;
^~~~~~~
/tmp/thundergbm/src/thundergbm/objective/ranking_obj.cpp:61:33: error: ‘gen’ was not declared in this scope
int m = dis(gen);
^~~
/tmp/thundergbm/src/thundergbm/objective/ranking_obj.cpp:61:33: note: suggested alternative: ‘len’
int m = dis(gen);
^~~
len
src/thundergbm/CMakeFiles/thundergbm.dir/build.make:11442: recipe for target 'src/thundergbm/CMakeFiles/thundergbm.dir/objective/ranking_obj.cpp.o' failed
make[2]: *** [src/thundergbm/CMakeFiles/thundergbm.dir/objective/ranking_obj.cpp.o] Error 1
CMakeFiles/Makefile2:131: recipe for target 'src/thundergbm/CMakeFiles/thundergbm.dir/all' failed
make[1]: *** [src/thundergbm/CMakeFiles/thundergbm.dir/all] Error 2
Makefile:83: recipe for target 'all' failed
make: *** [all] Error 2
I am watching GPU memory in task manager, and notice that thundergbm is not releasing GPU memory in between runs. Only killing the console and restarting forces a release of the GPU memory.
Are there any commands, in line with xgboost's .del call that let me accomplish this?
Thanks.
I need to build ThunderGBM statically.
How I can do this?
Hi, when I run the test, I got following problem:
(base) root@96ceaf0f06eb:~/thundergbm/build# ./bin/thundergbm-train ../dataset/machine.conf
2021-05-27 03:59:03,078 INFO dataset.cpp:162 : loading LIBSVM dataset from file ## ../dataset/test_dataset.txt ##
2021-05-27 03:59:03,084 INFO dataset.cpp:292 : #instances = 1605, #features = 119
2021-05-27 03:59:03,084 INFO dataset.cpp:301 : Load dataset using time: 0.00575318 s
2021-05-27 03:59:03,119 INFO sparse_columns.cu:22 : convert csr to csc using gpu...
2021-05-27 03:59:03,329 FATAL device_lambda.cuh:54 : Check failed: [error == cudaSuccess] no kernel image is available for execution on the device
I use :
Ubuntu 18.04
NVIDIA-SMI 460.73.01
Driver Version: 460.73.01
CUDA Version: 11.2
GPU: GeForce GTX 950
Can anyone help me ? Thanks !
Hi!
I ran the following command and got an error:
reg = tgb.TGBMRegressor(num_round=500)
reg.fit(X_train, y_train)
Exception ignored in: <bound method TGBMModel.__del__ of TGBMRegressor(bagging=None, column_sampling_rate=None, depth=None, gamma=None,
lambda_tgbm=None, learning_rate=None, max_num_bin=None,
min_child_weight=None, n_gpus=None, n_parallel_trees=None,
n_trees=None, num_class=None, objective=None, tree_method=None,
verbose=None)>
Traceback (most recent call last):
File "/usr/local/lib/python3.6/dist-packages/thundergbm/thundergbm.py", line 74, in __del__
if self.model is not None:
AttributeError: 'TGBMRegressor' object has no attribute 'model'
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
[<ipython-input-44-549c7ba30e91>](https://localhost:8080/#) in <module>() ----> 1 reg = tgb.TGBMRegressor(num_round=500) 2 reg.fit(X_train, y_train)
TypeError: __init__() got an unexpected keyword argument 'num_round'
I checked thundergbm.py and changed the parameter from 'num_round' to 'n_trees' and ran it and it worked fine.
I suggest documentation updates.
Thank you
and/or train tree by tree with callbacks whether to stop training?
that'd be nice.
Doesn't have to be a python callback. c++ is fine if you don't want to lose in speed performance.
My environment is:
Windows 10
Visual Studio 2017 Community
CMake3.14.0-rc3
CUDA10.1.105
Using test_dataset.txt in the library is successful,but Using my own .txt is failed.
my thundergbm-predict:

When building thundergbm-predict :

Hello,
I'm running TGBM on a Windows 10 machine with Cuda 10.
In my use case I create a lot of different GBDTs, which go out of scope after some time.
The problem is, that the gpu memory stays allocated.
My expectation were, that when pythons garbage collector deletes the instance, the memory gets freed. However, even when I explicitly delete the instance, the memory stays allocated.
I think to resolve this Issue in "scikit_tgbm.cpp" the model_free function must be extended to free the allocated memory. Currently, I don't know how to do this. But maybe if I find time I will take a deeper look in memory management with Cuda.
I found a very very ugly workaround by changing some code in the "thundergbm.py".
I extended the del function of TGBMModel to reload the whole dll. This isn't a good solution but okayish as a workaround if really required by somebody.
Lookin for a way to run this in Google Colab environment, thanks.
The most time consuming task is training. Prediction runs faster.
But there is some obstacles with CUDA requirements on some systems (e.g. can't run it in Colab, because it requires CUDA 9.0). It would be useful to be able to export ThunderGBM models to non-CUDA environements in light CPU-oriented form (e.g. add thundergbm-cpu to pip).
I trained the test_dataset.txt under thundergbm/dataset with thundergbm, but the execution time was 1-2 seconds slower than xgboost. I don't know if it's because I didn't use the GPU?(Windows 10, NVIDIA GETFORCE GTX 1050,CUDA 10.1)
There is one situation need to predict one sample at one time. I find some problem when i predict with one sample, but there is no error when sample number greater than two .
could someone tell me is it a bug ? or i have wrong operation .thanks
the follow is my code and error message and os information.
#------------------------------------------------------------------------
import numpy as np
import pandas as pd
import time
from thundergbm import TGBMClassifier
#------------------------------------------------------------------------------
clf=TGBMClassifier(verbose=1)
x1=np.random.random((40,2))
y1=np.random.randint(0,2,40)
clf.fit(x1,y1)
clf.predict(x1[3,:])
#------------------------------------------------------------------------------
2020-04-21 20:00:12,855 INFO [default] #instances = 1, #features = 2
2020-04-21 20:00:12,858 INFO [default] use shared memory to predict
2020-04-21 20:00:12,858 FATAL [default] Check failed: [size_ > 0]
2020-04-21 20:00:12,858 WARNING [default] Aborting application. Reason: Fatal log at [/home/admin/Desktop/EverComm_ibpem_gpu/thundergbm/include/thundergbm/syncarray.h:71]
Aborted (core dumped)
#------------------------------------------------------------------------
Ubuntu 16.04
NVIDIA driver : 440.44
CUDA Version: 10.2
GPU - GeForce RTX 2080
There is only "n_device" in TGBMClassifier . But it will shutdown with n_device >1.
And I cann‘t get predict when objective='multi:softprob'.
Also, when my Train DATA amount is larger but will not exceedGPU memory。 ThunderGBM still shutdown and failed with [error == cudaSuccess] out of memory.
Hello,
in my current use case it would be cool if I can use multi threading/multi processing, cause I have a lot of calculations and my GPU could handle it.
However, I get strange results by using threading. Here is a small script to reproduce
from thundergbm import TGBMRegressor
from sklearn.datasets import load_boston
from sklearn.metrics import mean_squared_error
from multiprocessing.pool import ThreadPool as Pool
import functools
import numpy as np
def main():
print("Without parallel threads: " + str(calc(2, 1)))
print("With parallel threads: " + str(calc(2, 2)))
def calc(num_repeats, pool_size):
x, y = load_boston(return_X_y=True)
x = np.repeat(x, 1000, axis=0)
y = np.repeat(y, 1000)
x = np.asarray([x]*num_repeats)
y = np.asarray([y]*num_repeats)
pool = Pool(pool_size)
func = functools.partial(fit_gbdt, x=x, y=y)
results = pool.map(func, range(num_repeats))
return results
def fit_gbdt(idx, x, y):
clf = TGBMRegressor(verbose=0)
clf.fit(x[idx], y[idx])
y_pred = clf.predict(x[idx])
rmse = (mean_squared_error(y[idx], y_pred)**(1/2))
return rmse
if __name__ == '__main__':
main()Sometimes I get the error:
2019-10-14 10:48:22,422 FATAL [default] Check failed: [error == cudaSuccess] an illegal memory access was encountered
2019-10-14 10:48:22,426 WARNING [default] Aborting application. Reason: Fatal log at [/thundergbm/include\thundergbm/util/device_lambda.cuh:49]
2019-10-14 10:48:22,434 FATAL [default] Check failed: [error == cudaSuccess] an illegal memory access was encountered
and sometimes bad results:
Without parallel threads: [0.011103539879039557, 0.011174528160149052]
With parallel threads: [0.04638805412265755, 4.690559078455652]
Multi processing does work, but only if I'm not returning a TGBM instance.
Returning the instance would be the best solution but dosn't work at all cause TGBM is not picklable.
I'm using Windows 10 with CUDA 10.
From my experience it's sometimes hard to do multithreading with CUDA (=> tensorflow) but multiprocessing should be okay if the object is pickelable.
Maybe it is possible to make tgbm pickelable or find the bug which causes multi threading to crash.
Many thanks!
I tried to use joblib and pickle to save a trained model in python, but i got a 'TypeError: can't pickle module objects' error. Hence, I wonder how can i save and load thundergbm model in python. Thanks for your help!
H,
How should be configured parameters (cpp API) for classification task for 10 classes - objective=".."
Maybe some information about possible values for objective parameter will be informative together with examples for
JK
python2.7.15
boost-install.generate-cmake-config- D:\boost\boost_1_70_0\lib\cmake\boost_coroutine-1.70.0\boost_coroutine-config.cmake
boost-install.generate-cmake-config-version- D:\boost\boost_1_70_0\lib\cmake\boost_coroutine-1.70.0\boost_coroutine-config-version.cmake
boost-install.generate-cmake-variant- D:\boost\boost_1_70_0\lib\cmake\boost_coroutine-1.70.0\libboost_coroutine-variant-vc140-mt-gd-x32-1_70-shared.cmake
boost-install.generate-cmake-config- D:\boost\boost_1_70_0\lib\cmake\boost_thread-1.70.0\boost_thread-config.cmake
boost-install.generate-cmake-config-version- D:\boost\boost_1_70_0\lib\cmake\boost_thread-1.70.0\boost_thread-config-version.cmake
boost-install.generate-cmake-variant- D:\boost\boost_1_70_0\lib\cmake\boost_thread-1.70.0\libboost_thread-variant-vc140-mt-gd-x32-1_70-shared.cmake
boost-install.generate-cmake-config- D:\boost\boost_1_70_0\lib\cmake\boost_date_time-1.70.0\boost_date_time-config.cmake
boost-install.generate-cmake-config-version- D:\boost\boost_1_70_0\lib\cmake\boost_date_time-1.70.0\boost_date_time-config-version.cmake
boost-install.generate-cmake-variant- D:\boost\boost_1_70_0\lib\cmake\boost_date_time-1.70.0\libboost_date_time-variant-vc140-mt-gd-x32-1_70-shared.cmake
boost-install.generate-cmake-config- D:\boost\boost_1_70_0\lib\cmake\boost_exception-1.70.0\boost_exception-config.cmake
boost-install.generate-cmake-config-version- D:\boost\boost_1_70_0\lib\cmake\boost_exception-1.70.0\boost_exception-config-version.cmake
...failed updating 2949 targets...
...skipped 16 targets...
...updated 12449 targets...
I use the windows 10 system.I installed the latest version of cmake. When I download the WHL file, pip install will show the following prompt:
(tf) PS C:\Users\WD\desktop> pip install --user thundergbm-0.3.16-py3-none-any.whl
WARNING: Requirement 'thundergbm-0.3.16-py3-none-any.whl' looks like a filename, but the file does not exist
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Processing c:\users\wd\desktop\thundergbm-0.3.16-py3-none-any.whl
ERROR: Could not install packages due to an EnvironmentError: [Errno 2] No such file or directory: 'C:\Users\WD\desktop\thundergbm-0.3.16-py3-none-any.whl'
src/thundergbm/CMakeFiles/thundergbm.dir/build.make:147: recipe for target 'src/thundergbm/CMakeFiles/thundergbm.dir/thundergbm_generated_tree.cu.o' failed
...
I have download the latest version of ThunderGBM, but it still can't make it.
can you tell me how to fix it? Thank you very much!
I am trying to run thundergbm under Ubuntu 18.04, cuda 10.2 driver 440.64.00. I was getting the following error:
~/venv/tf2/lib/python3.6/site-packages/thundergbm/thundergbm.py in fit(self, X, y, groups) 96 fit = self._sparse_fit 97 ---> 98 fit(X, y, groups=groups) 99 return self 100 ~/venv/tf2/lib/python3.6/site-packages/thundergbm/thundergbm.py in _sparse_fit(self, X, y, groups) 128 n_class, self.tree_method.encode('utf-8'), byref(self.model), tree_per_iter_ptr, 129 group_label, --> 130 in_groups, num_groups) 131 self.num_class = n_class[0] 132 self.tree_per_iter = tree_per_iter_ptr[0] ArgumentError: argument 6: <class 'TypeError'>: Don't know how to convert parameter 6
The following modification allows the code to run:
depth = c_int(int(self.depth)); n_trees = c_int(int(self.n_trees)) thundergbm.sparse_train_scikit(X.shape[0], data, indptr, indices, label, depth, n_trees,
I previously had to do a very similar fix for thundersvm, see https://github.com/Xtra-Computing/thundersvm/issues/210.
It might be helpful to treat the integers consistently.
The sklearn support for muliple output, i.e. the shape of y can be (B,L) rather than (B,)
For example,
from sklearn.ensemble import RandomForestRegressor
x_train = np.random.randn(100,100)
y_train = np.random.randn(100,50)
rfr = RandomForestRegressor(n_estimators=20,n_jobs=1)
rfr.fit(x_train, y_train)
But here, for thundergbm, if we use multiple y, we get
rfr = TGBMRegressor(256)
rfr.fit(x_train, y_train)
--> 797 raise ValueError("bad input shape {0}".format(shape))
798
799
ValueError: bad input shape (2000, 200)
I notice the source code using sklearn.utils.check_X_y and turn on the option 'multi_output=True'
The there goes wrong for your fit function at set(y) part.
How do we use multiple output y
I have downloaded the covtype dataset mentioned in the original paper, but I can't reproduce the result in the original paper which stated that thundergbm is 10x times faster than lightgbm whereas in my case, it is, on the contraty, slightly slower than lightgbm and not as fast as mentioned in the paper.
My gpu is nvidia gtx 1060 and my cpu is intel core i7-7700 CPU @ 3.60GHz
The following is my experiment result, I have transfered the data to libsvm format to use especially for thundergbm, but for the other two I simply used dataframe
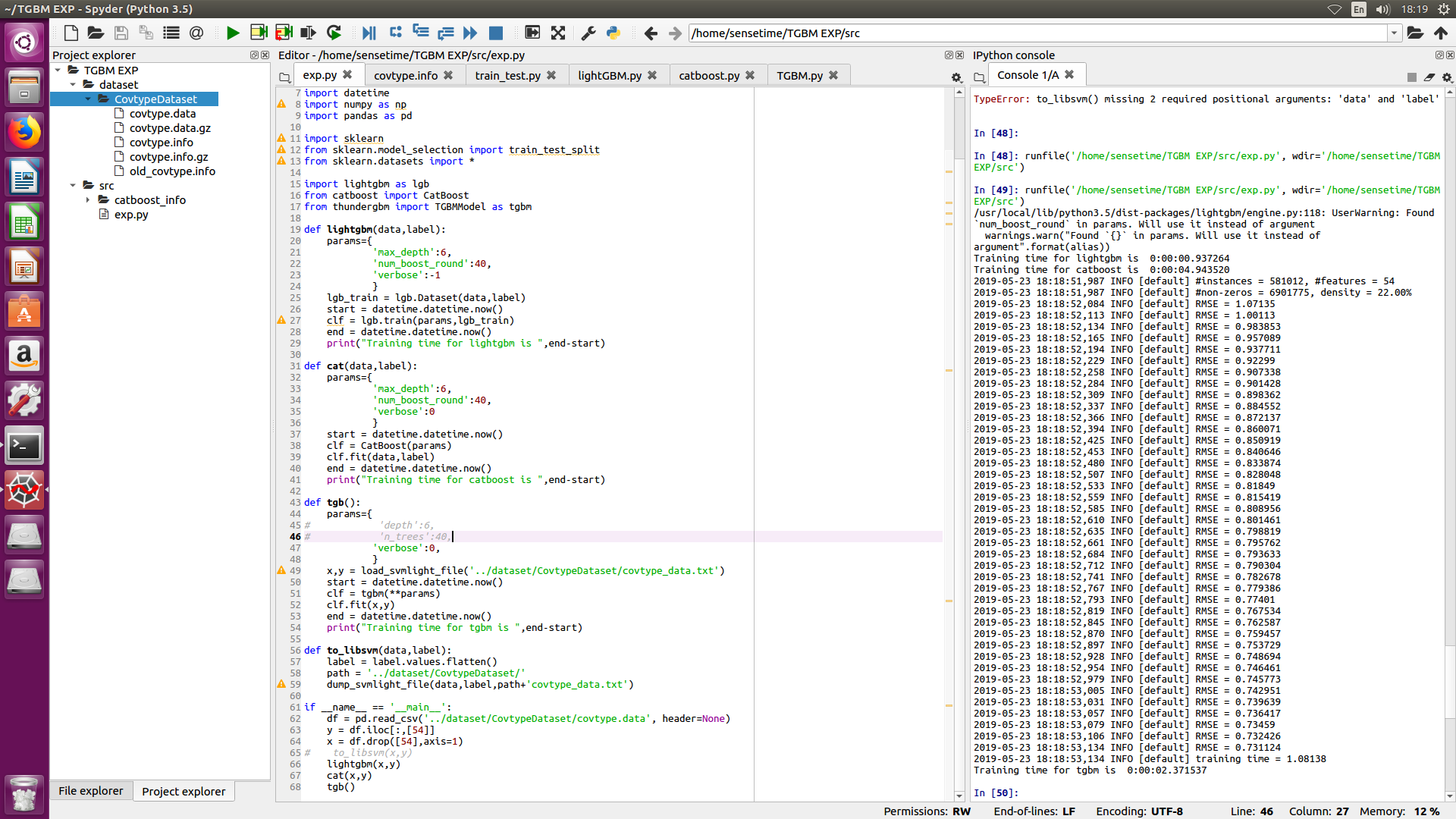
Hi,
I am trying to build thundergbm on ubuntu18.04 with CUDA 11.0 using the instructions here.
While building the binary, I get a string of warnings about C++14 (from CUB and THRUST), but the build proceeds until it hits this error:
thundergbm/src/thundergbm/sparse_columns.cu(52): error: identifier "cusparseScsr2csc" is undefined 1 error detected in the compilation of "thundergbm/src/thundergbm/sparse_columns.cu". CMake Error at thundergbm_generated_sparse_columns.cu.o.Release.cmake:279 (message): Error generating file thundergbm/build/src/thundergbm/CMakeFiles/thundergbm.dir//./thundergbm_generated_sparse_columns.cu.o src/thundergbm/CMakeFiles/thundergbm.dir/build.make:9146: recipe for target 'src/thundergbm/CMakeFiles/thundergbm.dir/thundergbm_generated_sparse_columns.cu.o' failed make[2]: *** [src/thundergbm/CMakeFiles/thundergbm.dir/thundergbm_generated_sparse_columns.cu.o] Error 1 CMakeFiles/Makefile2:126: recipe for target 'src/thundergbm/CMakeFiles/thundergbm.dir/all' failed make[1]: *** [src/thundergbm/CMakeFiles/thundergbm.dir/all] Error 2 Makefile:83: recipe for target 'all' failed make: *** [all] Error 2
The line that is seemingly causing the problem (sparse_columns.cu(52)) is
usparseScsr2csc(handle, dataset.n_instances(), n_column, nnz, val.device_data(), row_ptr.device_data(), col_idx.device_data(), csc_val.device_data(), csc_row_idx.device_data(), csc_col_ptr.device_data(), CUSPARSE_ACTION_NUMERIC, CUSPARSE_INDEX_BASE_ZERO);
Any suggestions on how to get around this?
Thanks.
Thanks for writing thundergbm! Please consider providing a R interface.
My environment is:
Windows 10
Visual Studio 2017 Community
CMake3.14.0-rc3
CUDA10.1.105
Using test_dataset.txt in the library is successful,but Using my own .txt is failed.
### my config file is:
max_depth=6
num_round=40
n_gpus=1
verbosity=0
profiling=0
data=D:\thundergbm\dataset\2.txt
max_bin=255
colsample=1
bagging=1
num_parallel_tree=1
eta=1.0
objective=multi:softmax
num_class=8
min_child_weight=1
lambda=1
gamma=1
model_out=tgbm.model
model_in=D:\thundergbm\build\tgbm.model
tree_method=auto
Errors output:
CUDA error 2 [D:\thundergbm\src\thundergbm\syncmem.cpp, 238]: out of memory
waiting for your advice,thank you~!
I am getting this error after executing make -j:
/thundergbm/src/thundergbm/hist_cut.cu(142): error: a reference of type "SyncArray<float> &" (not const-qualified) cannot be initialized with a value of type "SyncArray<float_type>"
I am using the code of the support_cuda11 branch (as my CUDA version is 11).
Hi,
I am implementing ThunderGBM in an AutoML framework with the goal to optimise for speed.
It would be great if we had the option to run .fit() and .predict() methods with no printing to stdout.
I tried searching in the Python files but it became apparent that it is not there.
I did see the a reply in another issue that this is currently not possible.
If you tell me where/how to do this, I could give it a try.
Thanks
I get the following error at the end of my training for TGBMRegressor with default parameters, this doesn't allow the python process to release the GPU memory and it stays there.
2019-06-27 16:15:43,952 INFO [default] #instances = 1280, #features = 729
2019-06-27 16:15:44,031 INFO [default] copy csr matrix to GPU
2019-06-27 16:15:44,220 INFO [default] converting csr matrix to csc matrix
2019-06-27 16:15:44,483 INFO [default] Getting cut points...
2019-06-27 16:15:44,485 INFO [default] ################>>>: 1
2019-06-27 16:15:44,491 INFO [default] ----------------->>> Last LOOP: 0.0072718
2019-06-27 16:15:44,494 INFO [default] TOTAL CP:152949
2019-06-27 16:15:45,617 INFO [default] RMSE = 3.72949
2019-06-27 16:15:45,645 INFO [default] RMSE = 3.3029
2019-06-27 16:15:45,672 INFO [default] RMSE = 2.93213
2019-06-27 16:15:45,673 INFO [default] training time = 1.17665
2019-06-27 16:15:45,711 INFO [default] #instances = 549, #features = 729
CUDA error 29 [D:\thundergbm\src\thundergbm\syncmem.cpp, 576]: driver shutting down
CUDA error 29 [D:\thundergbm\cub\cub/util_allocator.cuh, 657]: driver shutting down
I was able to build thundergbm, but now how do I install it?
I get this error, causing python to crash, when I invoke the save_model method after a model run. Trees are about 10+ deep, and 200 trees to save. Any ideas?

the dataset was download from https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/regression.html#E2006-log1p
when running with the log1p.E2006.train dataset, an error occurred.
2019-06-13 00:20:56,908 INFO sparse_columns.cu:47 : converting csr matrix to csc matrix finished terminate called after throwing an instance of 'thrust::system::detail::bad_alloc' what(): std::bad_alloc: temporary_buffer::allocate: get_temporary_buffer failed Aborted (core dumped)
However, running with the log1p.E2006.test dataset has no problem.
when debugging, I found the error occurred with build_approximate() function in tree_build.cu,
`vector TreeBuilder::build_approximate(const MSyncArray &gradients) {
vector trees(param.num_class);
TIMED_FUNC(timerObj);
DO_ON_MULTI_DEVICES(param.n_device, [&](int device_id){
this->shards[device_id].column_sampling(param.column_sampling_rate);
});
for (int k = 0; k < param.num_class; ++k) {
Tree &tree = trees[k];
DO_ON_MULTI_DEVICES(param.n_device, [&](int device_id){
this->ins2node_id[device_id].resize(n_instances);
this->gradients[device_id].set_device_data(const_cast<GHPair *>(gradients[device_id].device_data() + k * n_instances));
this->trees[device_id].init2(this->gradients[device_id], param);
});
for (int level = 0; level < param.depth; ++level) {
DO_ON_MULTI_DEVICES(param.n_device, [&](int device_id){
find_split(level, device_id);
});`
when k = 0 and level = 4. The find_split() function cannot be finished.
And when tracing into the find_split(), the funcall in line 229-236 of file exact_tree_builder.cu cause the crash. However, I cannot find out why.
I input the commend ./bin/thundergbm-train ../dataset/machine.conf, but get the result:
-bash: ./bin/thundergbm-train: 没有那个文件或目录
just as the title says.
from thundergbm import TGBMClassifier
Traceback (most recent call last):
File "", line 1, in
File "/home/dell/anaconda3/lib/python3.7/site-packages/thundergbm/init.py", line 10, in
from .thundergbm import *
File "/home/dell/anaconda3/lib/python3.7/site-packages/thundergbm/thundergbm.py", line 32, in
thundergbm = CDLL(lib_path)
File "/home/dell/anaconda3/lib/python3.7/ctypes/init.py", line 364, in init
self._handle = _dlopen(self._name, mode)
OSError: libcusparse.so.10.0: cannot open shared object file: No such file or directory
Hi - I get the following message when trying to run the tests.
(base) josh@josh-HP:~/thundergbm/build$ ./bin/thundergbm-train ../dataset/machine.conf
2019-02-15 14:15:27,469 INFO dataset.cpp:11 : loading LIBSVM dataset from file "../dataset/test_dataset.txt"
2019-02-15 14:15:27,477 INFO dataset.cpp:113 : #instances = 1605, #features = 119
2019-02-15 14:15:27,579 INFO sparse_columns.cu:22 : #non-zeros = 22249, density = 11.65%
2019-02-15 14:15:27,637 FATAL device_lambda.cuh:38 : Check failed: [error == cudaSuccess] no kernel image is available for execution on the device
2019-02-15 14:15:27,637 WARNING device_lambda.cuh:38 : Aborting application. Reason: Fatal log at [/home/josh/thundergbm/include/thundergbm/util/device_lambda.cuh:38]
Aborted (core dumped)
What other information will help with solving this issue please? :)
I installed thudergbm with wheel file thundergbm-0.3.4-py3-win64.whl. And there is an problem in thundergbm.dll. It finds cusparse64_10.dll, but there is only cusparse64_100.dll in CUDA 10.0. So it cause WinError 126. When I search cusparse64_10.dll on Google, it exists in 10.1 only. If you using CUDA 10.1, then I recommend to build file again or to fix README.
Hi, sorry for bothering you all again.
I have installed thundergbm via pip on windows 8.1 before and it succeed. This time I install it on linux(CentOS 7.6) but some problems occur.
When I install via pip, it succeed. But when I import it, the error is:
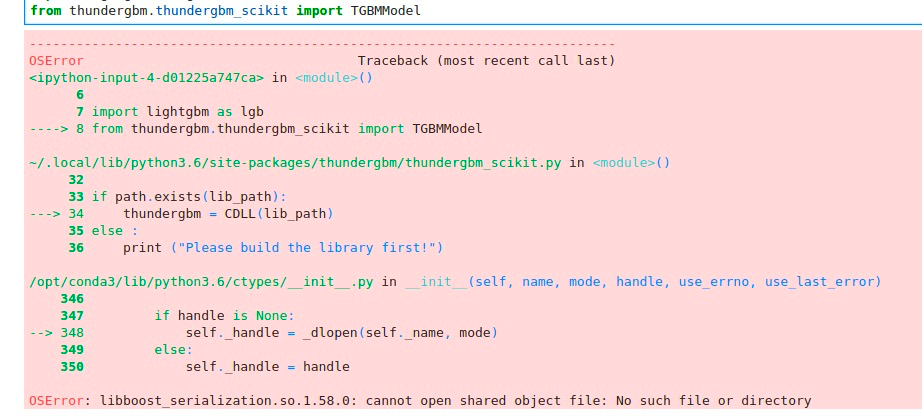
So I try to build it via CMake. However, there are still errors saying:

It's strange because it requires higher CMake version but on the Readme.md it says:
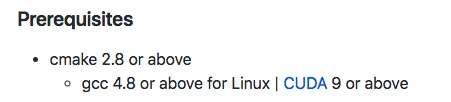
My environment:
Wating for your advice. Thanks~
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.