This repository contains the source code and dataset for the paper: A Novel Cascade Binary Tagging Framework for Relational Triple Extraction. Zhepei Wei, Jianlin Su, Yue Wang, Yuan Tian and Yi Chang. ACL 2020. [pdf]
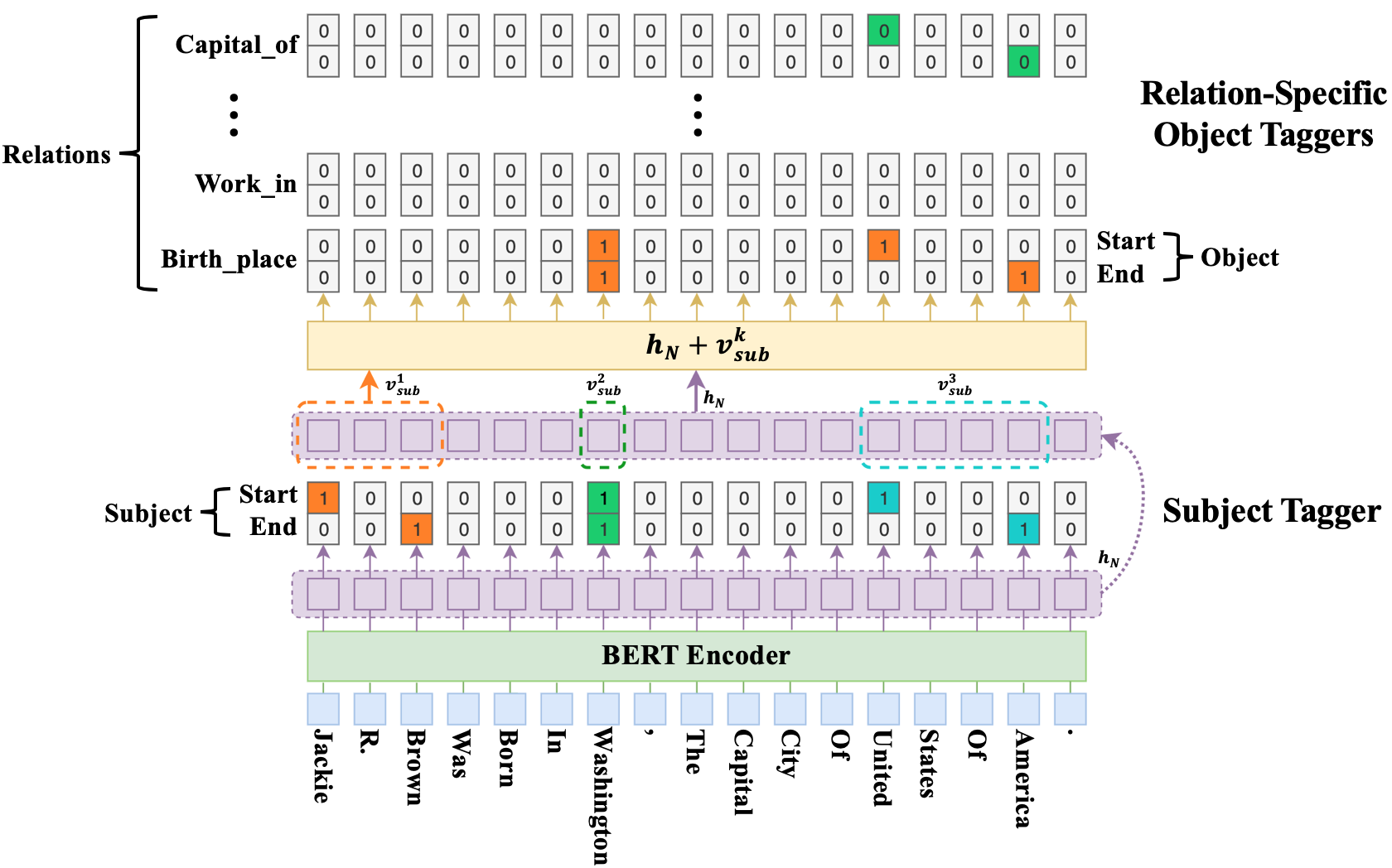
At the core of the proposed CasRel framework is the fresh perspective that instead of treating relations as discrete labels on entity pairs, we actually model the relations as functions that map subjects to objects. More precisely, instead of learning relation classifiers f(s,o) -> r, we learn relation-specific taggers f_{r}(s) -> o, each of which recognizes the possible object(s) of a given subject under a specific relation. Under this framework, relational triple extraction is a two-step process: first we identify all possible subjects in a sentence; then for each subject, we apply relation-specific taggers to simultaneously identify all possible relations and the corresponding objects.
This repo was tested on Python 3.7 and Keras 2.2.4. The main requirements are:
- tqdm
- codecs
- keras-bert = 0.80.0
- tensorflow-gpu = 1.13.1
-
Get pre-trained BERT model for Keras
Download Google's pre-trained BERT model (
BERT-Base, Cased). Then decompress it underpretrained_bert_models/. More pre-trained models are available here. -
Build dataset in the form of triples
Take the NYT dataset for example:
a) Switch to the corresponding directory and download the dataset
cd CasRel/data/NYT/raw_NYTb) Follow the instructions at the same directory, and just run
python generate.py
c) Finally, build dataset in the form of triples
cd CasRel/data/NYT python build_data.pyThis will convert the raw numerical dataset into a proper format for our model and generate
train.json,test.jsonandval.json(if not provided in the raw dataset, it will randomly sample 5% or 10% data from thetrain.jsonortest.jsonto createval.jsonas in line with previous works). Then split the test dataset by type and num for in-depth analysis on different scenarios of overlapping triples. -
Specify the experimental settings
By default, we use the following settings in run.py:
{ "bert_model": "cased_L-12_H-768_A-12", "max_len": 100, "learning_rate": 1e-5, "batch_size": 6, "epoch_num": 100, } -
Train and select the model
Specify the running mode and dataset at the command line
python run.py ---train=True --dataset=NYT
The model weights that lead to the best performance on validation set will be stored in
saved_weights/DATASET/. -
Evaluate on the test set
Specify the test dataset at the command line
python run.py --dataset=NYT
The extracted result will be saved in
results/DATASET/with the following format:{ "text": "Tim Brooke-Taylor was the star of Bananaman , an STV series first aired on 10/03/1983 and created by Steve Bright .", "triple_list_gold": [ { "subject": "Bananaman", "relation": "starring", "object": "Tim Brooke-Taylor" }, { "subject": "Bananaman", "relation": "creator", "object": "Steve Bright" } ], "triple_list_pred": [ { "subject": "Bananaman", "relation": "starring", "object": "Tim Brooke-Taylor" }, { "subject": "Bananaman", "relation": "creator", "object": "Steve Bright" } ], "new": [], "lack": [] }
@inproceedings{wei2020CasRel,
title={A Novel Cascade Binary Tagging Framework for Relational Triple Extraction},
author={Wei, Zhepei and Su, Jianlin and Wang, Yue and Tian, Yuan and Chang, Yi},
booktitle={Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics},
pages={1476--1488},
year={2020}
}

