wmenjoy / awesome-knowleges Goto Github PK
View Code? Open in Web Editor NEW汇总有用的知识
汇总有用的知识







































当ssh服务器升级后,使用ssh [email protected]提示
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED! @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
IT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY!
Someone could be eavesdropping on you right now (man-in-the-middle attack)!
It is also possible that a host key has just been changed.
The fingerprint for the ECDSA key sent by the remote host is
SHA256:0QN2og13zzcc3VWaIJtGdUSA9einO8szjgNQj40+S70.
Please contact your system administrator.
Add correct host key in /Users/xxx/.ssh/known_hosts to get rid of this message.
Offending ECDSA key in /Users/xxx/.ssh/known_hosts:2
ECDSA host key for 192.168.xxx.xx has changed and you have requested strict checking.
Host key verification failed.
应该是校验规则失效,删除一下即可, 将本机.ssh/know_hosts的对应ip的记录删除即可
sed -i.bak "/192.168.xxx.xx/d" ~/.ssh/known_hosts && rm ~/.ssh/known_hosts.bak
如果要批量执行,如果要登录一个网段,比如192.168.118.69-192.168.118.80那么可以写成
for i in $(seq 69 80); do sed -i.bak "/192.168.118.$i/d" ~/.ssh/known_hosts && rm ~/.ssh/known_hosts.bak; done
Fluent Bit is an open source and multi-platform Log Processor and Forwarder which allows you to collect data/logs from different sources, unify and send them to multiple destinations. It's fully compatible with Docker and Kubernetes environments.
Fluent Bit is written in C, have a pluggable architecture supporting around 30 extensions. It's fast and lightweight and provide the required security for network operations through TLS.
结构

| 项目 | Fluentd | Fluent Bit |
|---|---|---|
| Scope | Containers / Servers | Containers / Servers |
| Language | C & Ruby | C |
| Memory | ~40MB | ~450KB |
| Performance | High Performance | High Performance |
| Dependencies | Built as a Ruby Gem, it requires a certain number of gems. | Zero dependencies, unless some special plugin requires them. |
| Plugins | More than 650 plugins available | Around 35 plugins available |
| License | Apache License v2.0 | Apache License v2.0 |
支持routing,适合多output的场景。比如有些业务日志,或写入到es中,供查询。或写入到hdfs中,供大数据进行分析。
fliter支持lua。对于那些对c语言hold不住的团队,可以用lua写自己的filter。
output 除了官方已经支持的十几种,还支持用golang写output。

| Interface | Description |
|---|---|
| Input Entry | point of data. Implemented through Input Plugins, this interface allows to gather or receive data. E.g: log file content, data over TCP, built-in metrics, etc. |
| Parser | Parsers allow to convert unstructured data gathered from the Input interface into a structured one. Parsers are optional and depends on Input plugins. |
| Filter | The filtering mechanism allows to alter the data ingested by the Input plugins. Filters are implemented as plugins. |
| Buffer | By default, the data ingested by the Input plugins, resides in memory until is routed and delivered to an Output interface. |
| Routing | Data ingested by an Input interface is tagged, that means that a Tag is assigned and this one is used to determinate where the data should be routed based on a match rule. |
| Output | An output defines a destination for the data. Destinations are handled by output plugins. Note that thanks to the Routing interface, the data can be delivered to multiple destinations. |




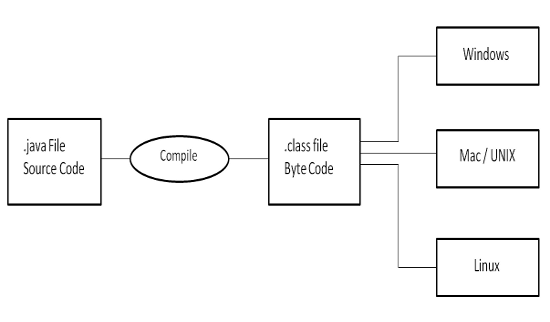
如下图:Java程序的执行过程,都是经过javac变成自class文件,然后在jvm上运行。 而class 文件里面包含的就是字节码,换句话就是,字节码就是Jvm上的操作指令, 是对底层不同操作硬件上指令的进一步抽象

Java Instrument
Dynamic Proxy
Aop: AspectJ
基于注解和字节码的生成工具(Mockit,)
Consul官网描述如下:
Consul is a service mesh solution providing a full featured control plane with service discovery, configuration, and segmentation functionality. Each of these features can be used individually as needed, or they can be used together to build a full service mesh. Consul requires a data plane and supports both a proxy and native integration model. Consul ships with a simple built-in proxy so that everything works out of the box, but also supports 3rd party proxy integrations such as Envoy.
Consul 基本定位服务发现,服务配置,并且提供Service Mesh的控制面板功能,提供如下功能:
1. 服务发现: Consul 客户端可以注册一个服务,比如 api 接口或者 mysql 服务,其他的客户端可以通过 Consul 来发现这些服务的提供方。通过 DNS 或者 HTTP,引用可以很方便地找到它所依赖的服务。
2. 健康检查: Consul 客户端可以提供任意数量的健康检查,无论是特定服务(服务是否返回200状态)还是本地节点(比如内存使用率是否大于90%)。运维人员可以通过这些信息管理集群的健康情况,服务发现组件也可以使用这些信息过滤掉不健康节点。
3. KV 存储: 应用可以使用 Consul 的树状 key/value 存储做很多事情,比如动态配置,开关,协作,leader 选举等等。KV 存储使用的是 HTTP 接口,非常简单易用。
4. 服务通信加密: Consul 可以生成并分发 TLS 证书给服务,从而保证服务之间使用 TLS 通信。我们可以使用 intentions 组件来自定义允许哪些服务访问。使用 intentions 可以实时地操作服务隔离,这比使用复杂的网络拓扑和静态防火墙规则要简单很多。
5. 多数据中心: Consul 支持开箱即用的多数据中心功能。这意味着当工作区域扩展至多个的时候,用户不需要费心去创建额外的抽象层来满足多中心需求。
Consul 设计时就考虑到了对 DevOps 社区和应用开发者友好,这让它非常适合新兴的弹性架构。

Consul 支持多中心,就如上图,有两个DataCenter, 通过互联网互联,只有Server 节点才能够跨数据中心通信, Server之间通过哦WAN GOSSIIP协议来沟通哦那个,内部存在Server和Agent节点,之间通过gossiip来维护关系, 数据的读写请求,既可以直接发送到Server,也可以通过Client使用RPC发送到Server。
Consul 系统的每个节点都是一些Agent, Agent 可以使Server或者Client模式
负责转发所有的 RPC 到 server 节点,本身无状态且轻量级,因此可以部署大量的 client 节点
负责的数据存储和数据的复制集,一般 Consul server 由 3-5 个结点组成来达到高可用,server 之间能够进行相互选举。一个 datacenter 推荐至少有一个 Consul server 的集群。
| consul | zookeeper | Eureka | |
|---|---|---|---|
| APi 网关集成 | 1、可以借助于DNS2、可以单独集成API | 1、需要单独集成API | 1、需要单独集成API |
| CAP | CP | CP | AP |
| KV 存储 | 支持 | 支持 | 不支持 |
| spring-cloud集成 | 支持 | 支持 | 支持 |
| 一致性算法 | Raft | Zab | - |
| 分布式任务调度 | 没有现成的框架,需要做开发 | elastic-job | 没有 |
| 可靠性对机器数量的需求 | 5 | 3 | 3 |
| 多数据中心 | 支持 | 不支持 | 不支持 |
| 对外服务 | Http和DNS | 客户端 | HTTP |
| 开发语言 | go | java | java |
参看here
apiVersion: apps/v1
kind: Deployment
metadata:
name: %%work.name%%
labels:
app.kubernetes.io/name: %%work.name%%
app.kubernetes.io/env: %%work.env%%
spec:
replicas: %%work.replicaCount%%
selector:
matchLabels:
app.kubernetes.io/name: %%work.name%%
app.kubernetes.io/env: %%work.env%%
template:
metadata:
labels:
app.kubernetes.io/name: %%work.name%%
app.kubernetes.io/env: %%work.env%%
spec:
containers:
- name: %%work.name%%
image: %%work.image.repository%%:%%work.image.version%%
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
protocol: TCP
livenessProbe:
httpGet:
path: /
port: http
readinessProbe:
httpGet:
path: /
port: http
resources:
limits:
cpu: %%work.limit.cpu%%
memory: %%work.limit.memory%%
requests:
cpu: %%work.limit.cpu%%
memory: %%work.limit.memory%%#!/bin/bash
ARGS=`getopt -o n:c:i:v:e:f:l:c:m --long name:,env:,replicaCount:,image:,version:,file:,:templateFile,cpu:,memory:,limitCPU:,limitMemory:,requestCPU:,requestMemory: -n 'mkdeployment.sh' -- "$@"`
if [ $? != 0 ]; then
echo "参数错误 ./mkservice.sh -n $name"
exit 1
fi
# echo $ARGS
eval set -- "$ARGS"
while true
do
case "$1" in
-n|--name)
name=$2
shift 2
;;
-e|--env)
env=$2
shift 2
;;
-f|--file)
outFile=$2
shift 2
;;
-l|--templateFile)
templateFile=$2
shift 2
;;
-c|--replicaCount)
replicaCount=$2
shift 2
;;
-i|--image)
image=$2
shift 2
;;
-v|--version)
version=$2
shift 2
;;
-c|--cpu)
cpu=$2
shift 2
;;
-m|--memory)
memory=$2
shift 2
;;
--limitCPU)
limitCPU=$2
shift 2
;;
--limitMemory)
limitMemory=$2
shift 2
;;
--requestCPU)
requestCPU=$2
shift 2
;;
--requestMemory)
requestMemory=$2
shift 2
;;
--)
shift
break
;;
*)
echo "error"
exit 1
;;
esac
done
if [ "$#" -gt 0 ]; then
echo "使用了多余的参数,请检查"
for arg in $@
do
echo "processing $arg"
done
exit 1
fi
[ -z "$name" ] && echo "name 不能为空" && exit 1;
[ -z "$image" ] && echo "image 参数不能为空" && exit 1;
env=${env:-test}
replicaCount=${replicaCount:-1}
version=${version:-latest}
[ -z "$cpu" ] && cpu=100m
[ -z "$memory" ] && memory=256Mi
[ -z "$requestCPU" -a ! -z "$cpu" ] && requestCPU=$cpu
[ -z "$requestMemory" -a ! -z "$memory" ] && requestMemory=$memory
[ -z "$limitCPU" ] && limitCPU=$requestCPU
[ -z "$limitMemory" ] && limitMemory=$requestMemory
cDir=$(cd $(dirname .);pwd)
[ -z "$outFile" ] && outputFile=$cDir/deployment.yaml
[ -z "$templateFile" ] && templateFile=$cDir/deployment.tpl
sed "s#%%work.name%%#$name#g; s#%%work.env%%#$env#g;s/%%work.replicaCount%%/$replicaCount/g;s#%%work.image.repository%%#$image#g;s/%%work.image.version%%/$version/g;s/%%work.limit.cpu%%/$limitCpu/g;s/%%work.limit.memory%%/$limitMemory/g;s/%%work.request.cpu%%/$requestCpu/g;s/%%work.request.memory%%/$requestMemory/g;" $templateFile > $outputFile
apiVersion: v1
kind: Service
metadata:
name: %%worker.service.name%%
labels:
app.kubernetes.io/name: %%work.name%%
app.kubernetes.io/env: %%work.env%%
spec:
type: %%worker.service.type%%
ports:
- port: %%worker.service.port%%
targetPort: http
protocol: TCP
name: http
selector:
app.kubernetes.io/name: %%work.name%%
app.kubernetes.io/env: %%work.env%%!/bin/bash
ARGS=`getopt -o n:s:t:p:e:f:l --long name:,env:,serviceName:,serviceType:,port:,file:,:templateFile -n 'mkservice.sh' -- "$@"`
if [ $? != 0 ]; then
echo "参数错误 ./mkservice.sh -n $name"
exit 1
fi
# echo $ARGS
eval set -- "$ARGS"
while true
do
case "$1" in
-n|--name)
name=$2
shift 2
;;
-e|--env)
env=$2
shift 2
;;
-f|--file)
outFile=$2
shift 2
;;
-l|--templateFile)
templateFile=$2
shift 2
;;
-s|--serviceName)
serviceName=$2
shift 2
;;
-t|--serviceType)
serviceType=$2
shift 2
;;
-p|--port)
port=$2
shift 2
;;
--)
shift
break
;;
*)
echo "error"
exit 1
;;
esac
done
if [ "$#" -gt 0 ]; then
echo "使用了多余的参数,请检查"
for arg in $@
do
echo "processing $arg"
done
exit 1
fi
[ -z "$name" ] && echo "name 不能为空" && exit 1;
env=${env:-test}
[ -z "$serviceName" ] && serviceName=$name-service
type=${serviceType:-ClusterIP}
port=${port:-80}
cDir=$(cd $(dirname .);pwd)
echo "$name $serviceName, $port, $env, $serviceType"
[ -z "$outFile" ] && outputFile=$cDir/service.yaml
[ -z "$templateFile" ] && templateFile=$cDir/service.tpl
sed "s#%%work.name%%#$name#g; s#%%work.env%%#$env#g;;s/%%worker.service.type%%/$type/g;s/%%worker.service.port%%/$port/g;s/%%worker.service.name%%/$serviceName/g;" $templateFile > $outputFile
依赖属性, 通过发版平台来定义
appName=
env=test
replicaCount=2
image=
version=
outputDir=
scriptDir=
servicePort=参数传递,通过环境变量
#!/bin/bash
mkdir -p $outputDir
$scriptDir/mkdeployments.sh --name $appName --image $image --version $version --templateFile $scriptDir/deployment.tpl --file $outputDir/deployment.yaml --env $env --replicaCount 2
$scriptDir/mkservice.sh --name $appName --env $env --templateFile $scriptDir/service.tpl --file $outputDir/service.yaml --port=$servicePort
kubectl apply -f $outputDir## no表示关闭 # 打开IPv6
NETWORKING_IPV6=yes
#如果不喜欢自动获取地址,选择"no”
IPV6_AUTOCONF=no
# 网卡初始化IPv6协议栈
IPV6INIT=yes
# 配置IPv6地址
IPV6ADDR=2001:250:4000:2000::53
# 配置IPv6网关
IPV6_DEFAULTGW=2001:250:4000:2000::1
net.ipv4.ip_forward=1
# 0 开启 1 关闭
net.ipv6.conf.all.disable_ipv6=0






1、工作成果管理和维护. ( 文档的丢失等等,文档版本化)
2、提升文档的效率(集中式的锁,分支式-> 分布式的)
集中式单分支 CSV/VSS -> SVN ->分布式的GIT
1、master开发
2、分支开发
3、fork + 修改 + 分支 + merge request
4、分布式的master开发(微服务)
| 版本工具差异 | svn | git |
|---|---|---|
| 系统特点 | 1.集中式版本控制系统(文档管理很方便)2.企业内部并行集中开发3.windows系统上开发推荐使用4.克隆一个拥有将近一万个提交(commit),五个分支,每个分支有大约1500个文件,用时将近一个小时 | 1.分布式系统(代码管理很方便)2.开源项目开发3.mac,Linux系统上开发推荐使用4.克隆一个拥有将近一万个提交(commit),五个分支,每个分支有大约1500个文件,用时1分钟 |
| 灵活性 | 1.搭载svn的服务器出现故障,无法与之交互2.所有的svn操作都需要**仓库交互(例:拉分支,看日志等) | 1.可以单机操作,git服务器故障也可以在本地git仓库工作2.除了push和pull(或fetch)操作,其他都可以在本地操作3.根据自己开发任务任意在本地创建分支4.日志都是在本地查看,效率较高 |
| 安全性 | 较差,定期备份,并且是整个svn都得备份 | 较高,每个开发者的本地就是一套完整版本库,记录着版本库的所有信息(gitlab集成了备份功能) |
| 分支方面 | 1.拉分支更像是copy一个路径2.可针对任何子目录进行branch3.拉分支的时间较慢,因为拉分支相当于copy4.创建完分支后,影响全部成员,每个人都会拥有这个分支5.多分支并行开发较重(工作较多而且繁琐) | 1.我可以在Git的任意一个提交点(commit point)开启分支!(git checkout -b newbranch HashId)2.拉分支时间较快,因为拉分支只是创建文件的指针和HEAD3.自己本地创建的分支不会影响其他人4.比较适合多分支并行开发5.git checkout hash值(切回之前的版本,无需版本回退)6.强大的cherry-pick |
| 版本控制 | 1.保存前后变化的差异数据,作为版本控制2.版本号进行控制,每次操作都会产生一个高版本号(svn的全局版本号,这是svn一个较大的特点,git是hash值) | 1.git只关心文件数据的整体发生变化,更像是把文件做快照,文件没有改变时,分支只想这个文件的指针不会改变,文件发生改变,指针指向新版本2. 40 位长的哈希值作为版本号,没有先后之分3.git rebase操作可以更好的保持提交记录的整洁 |
| 工作流程 | 1.每次更改文件之前都得update操作,有的时候修改过程中这个文件有更新,commit不会成功2.有冲突,会打断提交动作(冲突解决是一个提交速度的竞赛:手快者,先提交,平安无事;手慢者,后提交,可能遇到麻烦的冲突解决。) | 1.开始工作前进行fetch操作,完成开发工作后push操作,有冲突解决冲突2.git的提交过程不会被打断,有冲突会标记冲突文件3.gitflow流程(经典) |
| 内容管理 | svn对中文支持好,操作简单,适用于大众 | 对程序的源代码管理方便,代码库占用的空间少,易于分支化管理 |
| 学习成本 | 使用起来更方便,svn对中文支持好,操作简单,适用于大众 | 更在乎效率而不是易用性,成本较高(有很多独有的命令,rebase,远程仓库交互的命令,等等) |
| 权限管理 | svn的权限管理相当严格,可以按组、个人针对某个子目录的权限控制(每个目录下都会有个.svn的隐藏文件) | git没有严格的权限管理控制,只有账号角色划分(在项目的home文件下有且只有一个.git目录) |
| 管理平台 | 有吧(这个“吧”字,肯定有,但本人没有接触过) | gitlab(建议使用,集成的功能较多,API开发),gerrit,github等 |
比如 kubernate 使用python启动
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#author:wq date:2016-4-28
#import os
#os.system("systemctl start etcd")
#os.system("systemctl start docker")
#os.system("systemctl start kube-apiserver")
#os.system("systemctl start kube-controller-manager")
#os.system("systemctl start kube-scheduler")
#os.system("systemctl start kubelet")
#os.system("systemctl start kube-proxy")
import subprocess
subprocess.call('systemctl start etcd',shell=True)
subprocess.call('systemctl start docker',shell=True)
subprocess.call('systemctl start kube-apiserver',shell=True)
subprocess.call('systemctl start kube-controller-manager',shell=True)
subprocess.call('systemctl start kube-scheduler',shell=True)
subprocess.call('systemctl start kubelet',shell=True)
subprocess.call('systemctl start kube-proxy',shell=True)强大的DNS Lookup 工具,用来做DNS查询以及调试DNS问题。man的介绍如下
NAME
dig - DNS lookup utility,
SYNOPSIS
dig [@server] [-b address] [-c class] [-f filename] [-k filename] [-m] [-p port#] [-q name] [-t type] [-v] [-x addr] [-y [hmac:]name:key] [[-4] | [-6]]
[name] [type] [class] [queryopt...]
dig [-h]
dig [global-queryopt...] [query...]
DESCRIPTION
dig is a flexible tool for interrogating DNS name servers. It performs DNS lookups and displays the answers that are returned from the name server(s)
that were queried. Most DNS administrators use dig to troubleshoot DNS problems because of its flexibility, ease of use and clarity of output. Other
lookup tools tend to have less functionality than dig.
Although dig is normally used with command-line arguments, it also has a batch mode of operation for reading lookup requests from a file. A brief
summary of its command-line arguments and options is printed when the -h option is given. Unlike earlier versions, the BIND 9 implementation of dig
allows multiple lookups to be issued from the command line.
Unless it is told to query a specific name server, dig will try each of the servers listed in /etc/resolv.conf. If no usable server addresses are
found, dig will send the query to the local host.
When no command line arguments or options are given, dig will perform an NS query for "." (the root).
It is possible to set per-user defaults for dig via ${HOME}/.digrc. This file is read and any options in it are applied before the command line
arguments.
The IN and CH class names overlap with the IN and CH top level domain names. Either use the -t and -c options to specify the type and class, use the -q
the specify the domain name, or use "IN." and "CH." when looking up these top level domains.
nslookup
yum install bind-utils
[root@fs03-192-168-xxx-xx ~]# dig baidu.com
; <<>> DiG 9.11.4-P2-RedHat-9.11.4-9.P2.el7 <<>> @127.0.0.1 -p 53 baidu.com
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 594
;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;baidu.com. IN A
;; ANSWER SECTION:
baidu.com. 61 IN A 220.181.38.148
baidu.com. 61 IN A 39.156.69.79
;; Query time: 17 msec
;; SERVER: 127.0.0.1#53(127.0.0.1)
;; WHEN: 四 1月 16 14:33:37 CST 2020
;; MSG SIZE rcvd: 59大部分的时候dig最下面显示了查询所用的时间及DNS服务器,时间,数据大小。DNS超时时间为30秒,查询时间对于排查DNS问题很有用。
[root@fs03-192-168-xxx-xx ~]# dig @127.0.0.1 -p 53 baidu.com +short
220.181.38.148
39.156.69.79
[root@fs03-192-168-xxx-xx ~]# dig mx baidu.com +short
10 mx.maillb.baidu.com.
15 mx.n.shifen.com.
20 mx1.baidu.com.
20 jpmx.baidu.com.
20 mx50.baidu.com.
[root@fs03-192-168-126-xxx ~]# dig ns baidu.com +short
dns.baidu.com.
ns4.baidu.com.
ns2.baidu.com.
ns7.baidu.com.
ns3.baidu.com.
[root@fs03-192-168-xxx-xx ~]# dig soa baidu.com +short
dns.baidu.com. sa.baidu.com. 2012142011 300 300 2592000 7200
[root@fs03-192-168-xxx-xx ~]# dig @127.0.0.1 -p 53 baidu.com +short
39.156.69.79
220.181.38.148
DNS的解析是递规解析,那么用dig可以加+trace参数,会显示完整的,无缓存,递规的查询,显示的是完整的trace记录。
[root@fs03-192-168-xxx-xx ~]# dig @127.0.0.1 -p 53 baidu.com +trace
; <<>> DiG 9.11.4-P2-RedHat-9.11.4-9.P2.el7 <<>> @127.0.0.1 -p 53 baidu.com +trace
; (1 server found)
;; global options: +cmd
. 446818 IN NS m.root-servers.net.
. 446818 IN NS i.root-servers.net.
. 446818 IN NS h.root-servers.net.
. 446818 IN NS f.root-servers.net.
. 446818 IN NS a.root-servers.net.
. 446818 IN NS g.root-servers.net.
. 446818 IN NS c.root-servers.net.
. 446818 IN NS e.root-servers.net.
. 446818 IN NS k.root-servers.net.
. 446818 IN NS d.root-servers.net.
. 446818 IN NS j.root-servers.net.
. 446818 IN NS b.root-servers.net.
. 446818 IN NS l.root-servers.net.
$ dig -x 8.8.8.8 +short


dig 命令默认的输出信息比较丰富,大概可以分为 5 个部分。
第一部分显示 dig 命令的版本和输入的参数。
第二部分显示服务返回的一些技术详情,比较重要的是 status。如果 status 的值为 NOERROR 则说明本次查询成功结束。
第三部分中的 "QUESTION SECTION" 显示我们要查询的域名。
第四部分的 "ANSWER SECTION" 是查询到的结果。
第五部分则是本次查询的一些统计信息,比如用了多长时间,查询了哪个 DNS 服务器,在什么时间进行的查询等等。
默认情况下 dig 命令查询 A 记录,上图中显示的 A 即说明查询的记录类型为 A 记录。
| 类型 | 目的 |
|---|---|
| A | 地址记录,用来指定域名的 IPv4 地址,如果需要将域名指向一个 IP 地址,就需要添加 A 记录。 |
| AAAA | 用来指定主机名(或域名)对应的 IPv6 地址记录。 |
| CNAME | 如果需要将域名指向另一个域名,再由另一个域名提供 ip 地址,就需要添加 CNAME 记录。 |
| MX | 如果需要设置邮箱,让邮箱能够收到邮件,需要添加 MX 记录。 |
| NS | 域名服务器记录,如果需要把子域名交给其他 DNS 服务器解析,就需要添加 NS 记录。 |
| SOA | SOA 这种记录是所有区域性文件中的强制性记录。它必须是一个文件中的第一个记录。 |
| TXT | 可以写任何东西,长度限制为 255。绝大多数的 TXT记录是用来做 SPF 记录(反垃圾邮件)。 |
如果没有top, netstat, awk, sed, ps, lsof等 命令如何查看进程的状态?
在个人电脑上,运行单节点Kubenates集群的一个工具。
grep -E --color 'vmx\|svm' /proc/cpuinfosysctl -a \| grep -E --color 'machdep.cpu.features\|VMX'
如果能在输出看到VMX,那么你的电脑是支持虚拟化的
Minikube利用本地虚拟机环境部署Kubernetes,其基本架构如下图所示。

用户使用Minikube CLI管理虚拟机上的Kubernetes环境,比如:启动,停止,删除,获取状态等。一旦Minikube虚拟机启动,用户就可以使用熟悉的Kubectl CLI在Kubernetes集群上执行操作。
#架构

| 包名 | 说明 | 其他 |
|---|---|---|
| biz | 业务 | |
| web | dashboard页面 | |
| deployer | node启动代码 |
| 包名 | 说明 | 其他 |
|---|---|---|
| canal | ||
| common | ||
| deployer | node启动代码 | |
| etl | 数据转换工具 | |
| extend | 扩展 |
URI = scheme:[//authority]path[?query][#fragment]
authority = [userinfo@]host[:port]

第一部分,scheme,可以翻译成协议名,表示资源应该使用哪种协议来访问。最常见的就是http和https了,其它的如:ftp、file等。
在 scheme 之后,必须是三个特定的字符“://”,它把 scheme 和后面的部分分离开。这个是今天的主角,如果单单是用作区分,完全可以只使用“:”这1个字母,而不是“://”这3个字母。
在“://”之后,是被称为“authority”的部分,表示资源所在的主机名,通常的形式是“host:port”,即主机名加端口号。以前authority还会包含身份信息userinfo,即“user:passwd@”的形式,不过现在已经不流行了,可以忽略。在后面的内容代表什么含义,相信大家都已经很清楚了。
1、可以给主机、服务、等一个标识,通过标识,可以建立各个实体之间的关系
2、通过标签系统,建立起各种资源之间的关系,便于管理
import java.util.concurrent.TimeUnit;
import java.util.function.Consumer;
public class VolatileDemo {
static int i = 5;
volatile static int x;
static int k ;
public static void worker1(Consumer<Integer> consumer) {
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + "\t start......");
while (i == 5) {
//无线等待
consumer.accept(i);
}
System.out.println(Thread.currentThread().getName() + "\t end.....");
}, "A").start();
//暂停几秒钟线程
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
new Thread(() -> {
i = i + 2;
System.out.println(Thread.currentThread().getName() + "\t update i value");
}, "B").start();
}
}写main方法分别执行以下语句,程序会退出吗?为什么?
worker1( i -> { System.out.println("hello" + i);});
worker1( i -> { x ++; });
worker1( i -> { int a = new Integer(1);});
worker1( i -> { k ++; });
worker1( i -> { System.out.println("hello" + i);});

2. worker1( i -> { x ++; });

worker1( i -> { int a += new Integer(1);});

worker1( i -> { k ++; });

程序死循环不胡突出
以上很明显是个程序可见性的问题,一个很重要的原因,就是程序什么时候会去内存中取数据?
jvm 没有明确说明都有哪些情况程序会去内存取数据,只是明确规定,锁,synchronzie关键字, 函数构造函数,volatile 等,程序一定回去内存去读数据。
那么是不是说就一定没有办法确定所有去内存读数据的场景了吗?
不是的, 根据jvm的内存模型,jvm的内存有主内存和工作区内存组成。 这完全就是一个缓存模型
根据缓存模型,工作区一定是对主内存的一个缓冲,映射。类似于cpu的cache,所以,当需要工作的数据不再工作区,或者工作区空间不够的时候,一定会去内存中读取数据。那么什么时候工作区空间会不够呢,申请大对象,或者申请太多空间的时候, 当需要的容量超过工作区容量的时候,工作区只能根据一定的策略把部分数据暂存到内存。
此外,值得注意的是为了效率,每次读数据一定不是只读当前操作的数据,而是读一块数据。所以即使对于jvm规定的必须去读内存的场景,也是有可能影响到当前线程的其他变量
综上所述,程序从内存中读数据分为3种
然后我们在回来看,程序
正如Docker官网所言:
Docker is an open platform for developing, shipping, and running applications. Docker enables you to separate your applications from your infrastructure so you can deliver software quickly. With Docker, you can manage your infrastructure in the same ways you manage your applications. By taking advantage of Docker’s methodologies for shipping, testing, and deploying code quickly, you can significantly reduce the delay between writing code and running it in production.
Docker 简单来讲是一个基于容器的生态开源平台,它不仅仅是容器,而且集成了软件的生命周期的管理, 利用Docker平台集成的应用程序的开发,发布,运行管理的功能和容器的优势,你可以很好的将软件和基础设施隔离,实现软件的快速交付。同时容易是轻量级的,具有很强的隔离性和安全性,这样可以提供给你一种成本更低的软件开发方案。
Docker 技术的核心便是Docker Engine, 他是一个CS架构的应用程序,主要有三个组件

Docker 本身灵活,高效可移植,松耦合,可扩展,安全;
lexible: Even the most complex applications can be containerized.
Lightweight: Containers leverage and share the host kernel, making them much more efficient in terms of system resources than virtual machines.
Portable: You can build locally, deploy to the cloud, and run anywhere.
Loosely coupled: Containers are highly self sufficient and encapsulated, allowing you to replace or upgrade one without disrupting others.
Scalable: You can increase and automatically distribute container replicas across a datacenter.
Secure: Containers apply aggressive constraints and isolations to processes without any configuration required on the part of the user.
Docker 的基于容器的平台支持高度可移植的工作负载。 Docker 容器可以在开发人员的本地笔记本电脑上运行,也可以在数据中心的物理或虚拟机、云提供商或混合环境中运行。
Docker使用容器来标准化应用程序和服务的环境,能够极大简化软件的开发周期,避免配置异常的问题,对CI/CD非常有用:
Docker 的可移植性和轻量级特性使得动态管理work Loads变得非常容易,可以根据业务需求以接近实时的方式扩展或拆卸应用程序和服务。
Docker是轻量级和快速的。 它为基于虚拟机监控程序的虚拟机提供了一个可行的、经济有效的替代方案,因此您可以使用更多的计算能力来实现业务目标。 Docker 非常适合高密度环境和中小型部署,在这些环境中您需要用更少的资源完成更多的工作。
容器在 Linux 上本地运行,并与其他容器共享主机的内核。 它运行一个离散的进程,占用的内存不比其他任何可执行文件多,因此它是轻量级的。
相比之下,虚拟机(VM)要完全运行一个操作系统,通过管理程序虚拟访问主机资源。 一般来说,除了您的应用程序逻辑所消耗的内容之外,vm 还会产生大量的开销。



如上图所示,Docker使用CS体系结构,Client通过和Docker的Daemon来完成Docker容器的构建、发布、运行工作,Client和Daemon可以在同一台主机,也可以在不同主机上(通过网络进行交互)
Docker Daemon(dockerd)监听 通过 Docker API 过来的请求,并管理 Docker 对象,如图像、容器、网络和卷。 守护进程还可以与其他守护进程通信,用来管理 Docker 服务。
Docker Client(Docker命令)是许多 Docker 用户与 Docker 交互的主要方式。 当使用诸如 docker run 之类的命令时,客户机将这些命令发送给 dockerd,然后又dockerd执行这些命令。 Docker 命令使用 Docker API和dockerd进行通信。 Docker 客户机可以与多个守护进程通信。
Docker Registries 用来存储Docker Image, Docker Hub是一个公共Docker Regstires, 类似于公用的maven仓库,是Docker默认配置的。 你也可以注册自己的私有Regsitries
当您使用 docker pull 或 docker 运行命令时,所需的映像将从您配置的Regsitries中提取出来。 当您使用 docker push 命令时,您的映像将被推送到您配置的Regsitries中。
这里所说的Docker对象指的是镜像(images), 容器(containers), 网络(networks), 卷(volume), 插件,和其他对象
镜像是一个创建Docker Container的只读指令模板,通常,一个镜像基于另一个镜像(dockerfile中农的FROM),并在基础上增加一些定制,比如在centos镜像的基础上,增加nginx服务器,以及运行nginx所需的配置
可以使用其他人在Docker Registries创建好的镜像,也可以创建自己的镜像,创建镜像,需要一个dockerfile.Dockerfile用间接的语法来描述创建和运行镜像所需要的步骤。Dockerfile 中的每条指令都在图像中创建一个图层。 当您更改 dockerfile 并重新生成图像时,只会重新生成已更改的图层。 与其他虚拟化技术相比,这是使映像如此轻量化、小巧和快速的部分原因。
容器是镜像的可运行实例。可以使用Docker Rest API或者Docker CLI 来创建,启动,停止,移动,删除容器,也可以将容器连接成一个或多个网络,可以给镜像添加存储卷,生成可以基于当前的状态创建一个新的镜像
默认情况下,容器与其他容器及其主机相对隔离较好。 可以控制容器的网络、存储或其他基础子系统与其他容器或主机的隔离程度。
容器是由其镜像以及创建或启动时提供给它的任何配置选项定义的。 当移除容器时,对其状态的任何未存储在持久性存储中的更改都将消失。
严格的将,这个Service 是对Docker 容器所运行服务的一个更上层抽象,借助于负载均衡,不同容器的管理机制,来提供一个整体的引用程序,比如K8s的服务概念,Docker Swarm的服务概念
Docker 是用go编写,利用lInux提供的Namespace, Control group 和Union File System来实现功能
Docker 使用Namespace技术提供称为容器的隔离工作区。 运行容器时,Docker 为该容器创建一组Namespace
这些Namespace提供了一个隔离层。 容器的每个方面都运行在一个单独的Namespace中,它的访问受到该Namespace的限制。
linux提供了7种Namespace,Docker目前使用了一下5种(User name space没有使用)
Linux 上的 Docker Engine 还依赖于另一种称为cgroups的技术。 Cgroup 将应用程序限制为一组特定的资源。 Control Groups允许 Docker 引擎向容器共享可用的硬件资源,并可选地实施限制和约束。 例如,可以将可用内存限制为特定容器。
nion 文件系统,或 UnionFS,是通过创建层来操作的文件系统,这使得它们非常轻量级和快速。 Docker Engine 使用 UnionFS 为容器提供构建块。 Docker Engine 可以使用多个 UnionFS 变体,包括 AUFS、 btrfs、 vfs 和 DeviceMapper。
Docker Engine 将Namespace、Controle group和 UnionFS 组合成一个称为Container format
的包装器,默认的容器格式是 libcontainer。 在未来,Docker 可能会通过集成技术来支持其他容器格式,如 BSD Jails 或者 Solaris Zones.

A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.

