wild-bit / myblog Goto Github PK
View Code? Open in Web Editor NEW记录Js、Vue源码、计算机网络、性能优化、工作总结、算法等前端相关知识
记录Js、Vue源码、计算机网络、性能优化、工作总结、算法等前端相关知识



JS中的事件循环(浏览器)
当我们调用一个函数时,js会创建对应的执行上下文,这个执行上下文中存在着上层作用域的指向,方法的参数,这个作用域中定义的变量以及这个作用域的this对象。当这一系列方法依次调用的时候,因为js是单线程的,所以同一时间只能执行一个方法,于是其余的方法被排队在一个单独的地方——执行栈(stack)
当脚本被执行时,js就会将其中的同步代码按照执行顺序加入到执行栈中,然后从头开始解析,当解析到是一个方法时,那么js就会在执行栈中创建对应的执行上下文并开始解析其中的同步代码,当执行完成后并返回结果后,js就会弹出该方法的执行上下文并摧毁,然后开始执行之后的同步代码,直至执行栈中的代码执行完成。
那么如果js解析的时异步事件时,它是怎么处理的呢?
我们首先看一段代码
console.log('1');
setTimeout(function() {
console.log('2');
}, 0);
Promise.resolve().then(function() {
console.log('4');
}).then(function() {
console.log('5');
});
console.log('3');
//打印的顺序为
//1 3 4 5 2按照之前的理论,浏览器按照代码的执行顺序执行代码,打印的结果应该为12453,那是因为代码中的setTimout 和 Primise是异步事件,当浏览器遇到异步事件时,浏览器主线程并不会等待其执行完成,而是将异步事件放入一个事件队列中,然后继续执行执行栈中的其他任务,被放入事件队列中的事件并不会马上执行其回调。而是等执行栈中的任务全部执行完毕后,主线程闲置时,主线程会查找事件队列有没有任务,如果有,取出第一个的事件回调并放入执行栈中执行其中的同步代码。
那为什么2在45后面?
不同的任务源会被分配到不同的 Task 队列中,任务源可以分为 微任务(microtask) 和 宏任务(macrotask)。在 ES6 规范中,microtask 称为 jobs,macrotask 称为 task,那么加入事件队列中的异步事件还会被js区分为是jobs还是task,并分别分配到 jobs Queue和task Queue,当主线程的执行栈为空时,先检查jobs Queue中是否有任务,如果有依次取出所有任务的并加入执行栈中执行,然后才会去执行当次事件循环中的task Queue
宏任务中包括了 script ,浏览器会先执行一个宏任务,接下来有异步代码的话就先执行微任务
所以正确的一次 Event loop 顺序是这样的
● 执行同步代码,这属于宏任务
● 执行栈为空,查询是否有微任务需要执行
● 执行所有微任务
● 必要的话渲染 UI
● 然后开始下一轮 Event loop,执行宏任务中的异步代码,循环往复,直到两个 queue 中的任务都取完。
另外如果遇到process.nextTick,在微任务中总是发生在所有异步任务之前
instanceof 运算符用于检测构造函数的 prototype 属性是否出现在某个实例对象的原型链上
使用方式如下:
console.log([] instanceof Array) // true
console.log({} instanceof Object) // true
console.log((()=>{}) instanceof Function) // true思路:
取得比较的当前类的原型和当前实例对象的原型链
按照原型链的查找机制一直向上查找
function _instanceof(example,classFn){
//基本数据类型直接返回false
if(typeof example !== 'object' || example === null) return false;
let proto = Object.getPrototypeOf(example)
while (true) {
if(proto == null) return false;
// 在当前实例对象的原型链上,找到了当前类
if(proto == classFunc.prototype) return true
// 沿着原型链__ptoto__一层一层向上查
proto = Object.getPrototypeof(proto); // 等于proto.__ptoto__
}
}
console.log('test', _instanceof(null, Array)) // false
console.log('test', _instanceof([], Array)) // true
console.log('test', _instanceof('', Array)) // false
console.log('test', _instanceof({}, Object)) // true闭包:闭包是指有权访问另一个函数的作用域中的变量的函数
创建闭包的常见方式就是在一个函数内创建另一个函数,通过另一个函数访问这个函数的局部变量,利用闭包突破作用域链
对于全局变量来说,全局变量的声明周期是永久的,除非主动销毁该变量(xxx = null),但对于函数内部声明的变量来说,当函数退出时,这些变量会随着函数调用的结束而被销毁
现在来看看这段代码:
const func = function(){
let a = 0
return function(){
a++
console.log('a:',a)
}
}
const f = func()
f() // 输出 a:1
f() // 输出 a:2
f() // 输出 a:3
f() // 输出 a:4按之前的理论,局部变量a在退出函数的时候就被销毁了,而代码中的a并没有被销毁,这是因为当执行 const f = func() 的时候,f返回了匿名函数的引用,它可以访问func()函数作用域,而局部变量a在func()的作用域内。既然局部变量还能被外部访问,垃圾回收就不会标记它,自然也就不会被销毁。这里产生了闭包的结构,延续了局部变量的生命周期。
因为js的垃圾回收机制是清理,那些没有被引用到的值,JavaScript 引擎中有一个后台进程称为垃圾回收器,它监视所有对象,并删除那些不可访问的对象。
例如:
function createIncrementor(start) {
return function () {
return start++;
};
}
var inc = createIncrementor(5);
inc() // 5
inc() // 6
inc() // 7通过闭包,start的状态被保留了,闭包(上例的inc)用到了外层变量(start),导致外层函数(createIncrementor)不能从内存释放
只要闭包没有被垃圾回收机制清除,外层函数提供的运行环境也不会被清除,它的内部变量就始终保存着当前值,供闭包读取,所以闭包inc使得函数createIncrementor的内部环境,一直存在
HTTP协议是超文本传输协议(Hyper Text Transfer Protocol) 的缩写,是从Web服务器传输超文本标记语言到本地浏览器传送协议,它是基于传输层协议TCP/IP通信协议来传送数据的。
用于HTTP协议交互的信息叫做HTTP报文
HTTP报文大致分为报文头部和报文主体两部分组成
具体而言:
1. 起始行 + 头部 + 空行 + 实体由于 http 请求报文和响应报文是有一定区别,因此我们分开介绍。
请求报文
GET /home HTTP/1.1
方法 + 路径 + http版本
响应报文
HTTP/1.1 200 OK
http版本 + 状态码 + 原因
请求报文
GET /hello.txt HTTP/1.1 起始行
User-Agent: curl/7.16.3 libcurl/7.16.3 OpenSSL/0.9.7l zlib/1.2.3
Host: www.example.com
Accept-Language: en, mi
头部以键值对的形式出现、字段名:值
响应报文
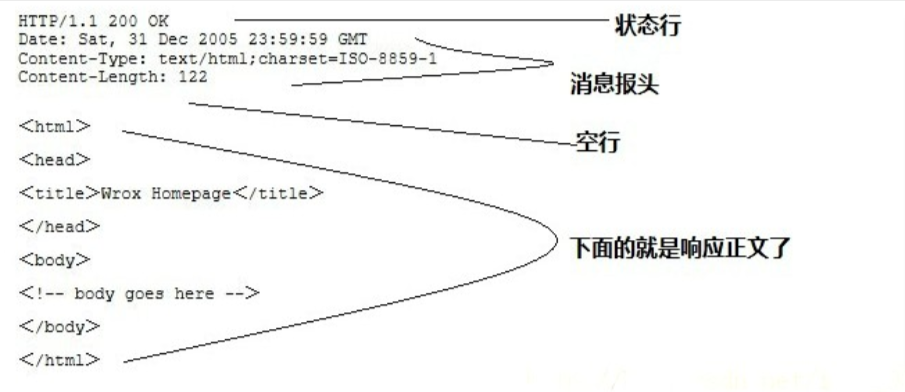
很重要,用来区分开头部和实体。
问: 如果说在头部中间故意加一个空行会怎么样?
那么空行后的内容全部被视为实体。
就是具体的数据了,也就是body部分。请求报文对应请求体, 响应报文对应响应体。
问题:多路复用如何解决HTTP/1.1的队头阻塞?
答:HTTP/2 是一个二进制协议,头信息和数据体都是二进制,并且统称为"帧",Headers帧存放头部字段,Data帧存放请求体数据,分帧之后,服务端看到的就不是一个完整的报文信息,而是一堆乱序的二进制帧,这些二进制帧不存在先后关系,因此也就不会排队等待,也就没有了 HTTP 的队头阻塞问题。
通信双方都可以给对方发送二进制帧,这种二进制帧的双向传输的序列,也叫做流(Stream)。HTTP/2 用流来在一个 TCP 连接上来进行多个数据帧的通信,这就是多路复用的概念。
那最后如何来处理这些乱序的数据帧呢?
所谓的乱序,指的是不同 ID 的 Stream 是乱序的,但同一个 Stream ID 的帧一定是按顺序传输的。二进制帧到达后对方会将 Stream ID 相同的二进制帧组装成完整的请求报文和响应报文。
/**
* @param {number[]} nums
* @param {number} target
* @return {number[]}
*/
var twoSum = function(nums, target) {
let map = new Map()
let res
for(let i = 0;i < nums.length; i++){
let x = target - nums[i]
if(map.has(x)){
res = [map.get(x),i]
}
map.set(nums[i],i)
}
return res
};/**
* @param {number[]} nums
* @param {number} target
* @return {number[]}
*/
var twoSum = function(nums, target) {
let map = new Map()
let res
for(let i = 0;i < nums.length; i++){
let x = target - nums[i]
if(map.has(x)){
res = [map.get(x),i]
}
map.set(nums[i],i)
}
return res
};对比npm、yarn、pnpm,以及它们都解决了哪些痛点?
一个完成的项目或多或少有用到一些依赖,这些依赖是别人为了解决了一些问题而写好的代码(即第三方库),而这些依赖有可能一会用到第三方库来实现功能。那么为什么不自己造轮子呢?因为相对没那么可靠,第三方库是经过多方测试、兼容性和健壮性都比自己写的好。那么当依赖升级的时候,令人头疼的版本管理就出现了,包管理器的出现也解决了这些问题。
它提供方法给你安装依赖(即安装一个包),管理包的存储位置,而且你可以发布自己写的包。
早期的npm包管理器文件结构:

这样的文件结构会造就以下几点问题:
扁平化的文件结构

扁平化的文件结构很好处理了依赖的文件路径太长(嵌套太深)的问题,因为所有的依赖都被放在了node_modules目录下
在执行install命令的时候如果发现有些依赖已经被装过了就不会装了,这样也解决了大量包被重复安装的问题
但扁平化又带来了新的问题
依赖结构的不确定性举例
假如B和C都依赖了D,但是依赖的版本不一样,B依赖[email protected],C依赖[email protected],具体的版本是package.json声明顺序决定的,后面声明的会覆盖前面的依赖
缓存是性能优化中非常重要的一环,浏览器的缓存机制对开发是非常重要的知识点:
- 强缓存
- 协商缓存
- 缓存位置
当浏览器发起请求时,首先会先检查强缓存,如果命中则不进行请求,资源直接从磁盘或者缓存中读取
那浏览器如何检查是否命中强缓存呢?
在http/1.0中使用的是Expires字段,而http/1.1中使用的是Cache-Control字段
Expires指的是过期时间,存在请服务器返回响应头中,它的作用就是告诉浏览器在这个过期时间之前不需要再次发起请求,资源可以在缓存中获取。
例如:
Expires: Wed, 22 Nov 2021 08:41:00 GMT表示资源在2021年11月22号8点41分过期,过期了就得向服务端发请求。
但是这种检查方式有个坑点,就是服务端(服务器)和客户端(浏览器)的时间可能会不一致,导致服务端返回的时间会不准确,所以HTTP/1.1使用Cache-Control来检查强缓存
在Http1.1中,采用的是Cache-Control,也是存在请服务器返回响应头中
它和Expires本质的不同就是没有采用具体的时间点,而是采用过期时长来控制缓存,对应的字段是max-age
例如:
Cache-Control:max-age=3600代表这个响应返回后的一小时之内可以使用缓存,超过一小时需要发起请求
Cache-Control不知有max-age一个属性,还有代表其他功能的属性如:
Google Chrome浏览器调式工具中的Disable cache就是使用这个字段的特性强制浏览器发起请求
注意:当两者同时存在时,优先Cache-Control
当强缓存失效,浏览器就会再次发送请求来向服务器获取资源
当浏览器再次发起请求的时候会带上一个标识【缓存tag】发起请求,服务器会根据这个请求判断是否决定使用协商缓存
缓存tag分为两种,Last-Modified 和 ETag
即最后修改时间,在浏览器第一次向服务器发送请求时,服务器会在响应头中加上这个字段。
浏览器接收后,如果强缓存失效,再次发起请求时就会在请求头带上If-Modified-Since,这个字段的值也就是服务器传来的最后修改时间。
服务器拿到请求头中的If-Modified-Since的字段后,其实会和这个服务器中该资源的最后修改时间对比:
ETag是服务器给当前文件的内容生产的一个唯一标识,只要这个文件的内容发生了变动,这个值就会随之发生改变,服务器通过响应头把这个值给浏览器
浏览器接收到ETag的值,会在下次请求时,将这个值作为If-None-Match这个字段的内容,并放到请求头中,然后发给服务器。
服务器接收到If-None-Match后,会跟服务器上该资源的ETag进行比对:
如果两者不一样,说明要更新了。返回新的资源,跟常规的HTTP请求响应的流程一样。
否则返回304,告诉浏览器直接用缓存。
两者对比
1、ETag比Last-Modified更精准,ETag直接精准到文件资源的内容有无发生改变从而判断有无更新,而Last-Modified则是通过时长
2、Last-Modified在性能上比ETag更有优势,因为Last-Modified只是生成一个时间点,而ETag则是根据文件的具体内容生成哈希值
从上面可以知道强缓存和协商缓存阶段,浏览器都是从缓存中获取资源的,那问题来了,这些缓存存放在电脑的哪个位置呢?
浏览器的缓存可以有四个位置存放,优先级从高到低:
Service workers 本质上充当 Web 应用程序、浏览器与网络(可用时)之间的代理服务器。这个 API 旨在创建有效的离线体验,它会拦截网络请求并根据网络是否可用来采取适当的动作、更新来自服务器的的资源。它还提供入口以推送通知和访问后台同步 API。即让 JS 运行在主线程之外,由于它脱离了浏览器的窗体,因此无法直接访问DOM。虽然如此,但它仍然能帮助我们完成很多有用的功能,比如离线缓存、消息推送和网络代理等功能,其中的离线缓存就是 Service Worker Cache。
Memory Cache指的是内存缓存,从效率上讲它是最快的。但是从存活时间来讲又是最短的,当渲染进程结束后,内存缓存也就不存在了。
Disk Cache就是存储在磁盘中的缓存,从存取效率上讲是比内存缓存慢的,但是他的优势在于存储容量和存储时长。稍微有些计算机基础的应该很好理解,就不展开了。
好,现在问题来了,既然两者各有优劣,那浏览器如何决定将资源放进内存还是硬盘呢?主要策略如下:
比较大的JS、CSS文件会直接被丢进磁盘,反之丢进内存
内存使用率比较高的时候,文件优先进入磁盘
TCP是一个面向连接的、可靠的、基于字节流的传输层协议。
而UDP是一个面向无连接的传输层协议。(就这么简单,其它TCP的特性也就没有了)。
具体来分析,和 UDP 相比,TCP 有三大核心特性:
面向连接。所谓的连接,指的是客户端和服务器的连接,在双方互相通信之前,TCP 需要三次握手建立连接,而 UDP 没有相应建立连接的过程。
可靠性。TCP 花了非常多的功夫保证连接的可靠,这个可靠性体现在哪些方面呢?一个是有状态,另一个是可控制。
TCP 会精准记录哪些数据发送了,哪些数据被对方接收了,哪些没有被接收到,而且保证数据包按序到达,不允许半点差错。这是有状态。
当意识到丢包了或者网络环境不佳,TCP 会根据具体情况调整自己的行为,控制自己的发送速度或者重发。这是可控制。
相应的,UDP 就是无状态, 不可控的。
面向字节流。UDP 的数据传输是基于数据报的,这是因为仅仅只是继承了 IP 层的特性,而 TCP 为了维护状态,将一个个 IP 包变成了字节流。
DNS(Domain Name System)服务是一个位于应用层的协议,主要的作用就是提供域名到IP地址之间的解析服务。
域名由三部分组成,以https://www.baidu.com:
https:协议名称
www.baidu.com.才是域名


每一级的域名服务器只保留下一级域名服务器的IP地址。比如根域名服务器只保留了顶级域名服务器的IP地址
当服务器返回渲染文件(HTML/CSS/JS),浏览器是读不懂这些文件的(臣妾做不到啊!!!)
必须经过一系列的转化过程:
- 构建DOM树
- 样式计算
- 布局
- 构建、绘制图层
- 栅格化(raster)
- 合成
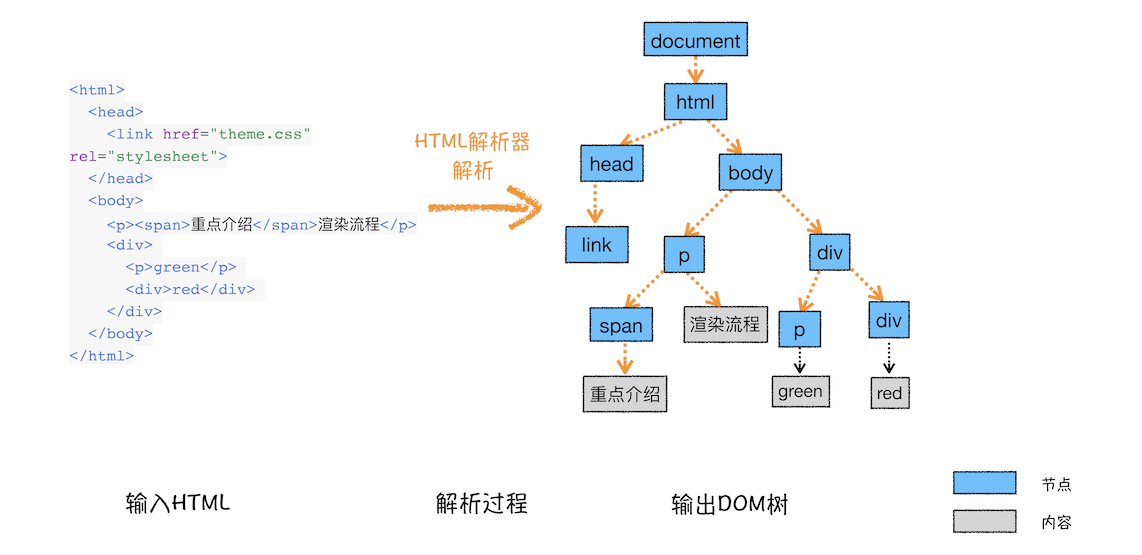
构建DOM树的目的就是将HTML文件的内容构建成浏览器能够理解的树结构
生成DOM树之后,就要将CSS文件、内联样式、style标记里的样式转化为浏览器可以理解的结构——styleSheets(可以在Chrome控制台中查看其结构,只需要在控制台中输入document.styleSheets)
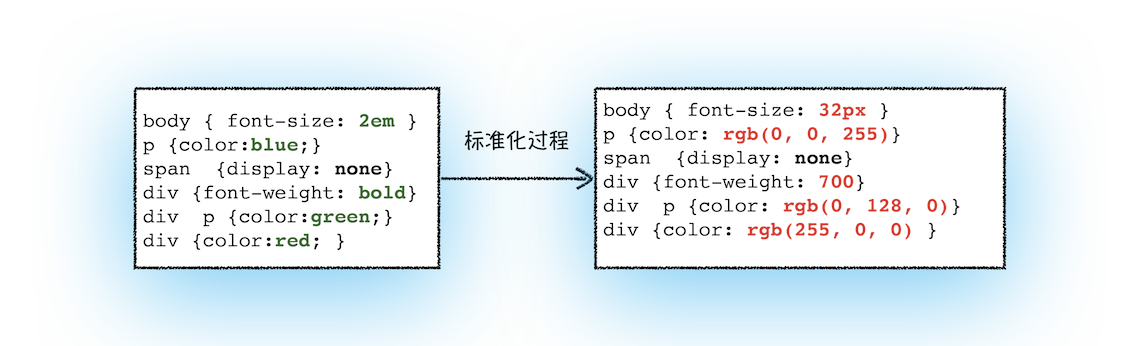
除了转化为styleSheets结构还需要转换样式表中的属性值,使其标准化
标准化的意思就是像一些rem,em需要根据对应的字体大小进行等值转换,比如一些颜色值,将会转换成RGB的格式
然后将标准化的styleSheet结合到DOM树上,也就是计算DOM树中每个节点的样式属性了。
这里涉及到CSS的继承规则和层叠规则
继承简单的理解就是子节点继承父节点的样式
可以想象一下这样一张样式表是如何应用到DOM节点上的。
body { font-size: 20px }
p {color:blue;}
span {display: none}
div {font-weight: bold;color:red}
div p {color:green;}合到上面的DOM树上计算出来的每个节点的具体样式为:
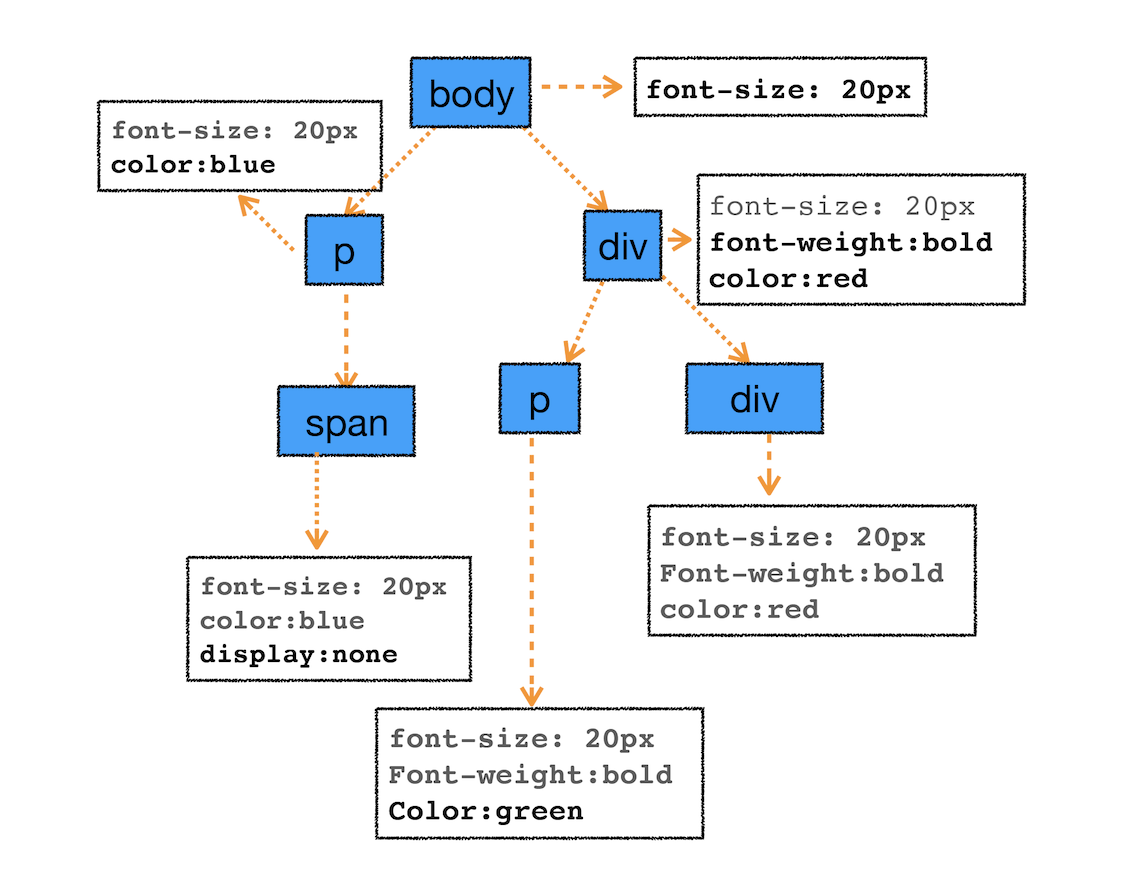
样式计算过程中,会根据DOM节点的继承关系来合理计算节点样式
虽然经过了构建DOM树和样式计算已经有了DOM树和样式,但还无法得知DOM元素的几何位置信息,那么计算DOM树中可见元素的位置信息这个阶段叫做布局阶段。
布局阶段需要经过构建布局树和布局计算两个程序
由于DOM树中有不可见的元素,比如html、meta标签以及一些样式为display:none的元素。
所以生成布局树就是需要将这些不可见的元素忽略掉并将可见的DOM树节点加入到布局树中。
当浏览器解析完html片段后,会触发layout tree的构建,遍历所有DOM节点,每个非不可见的元素会被加入到布局树中,并建立父子兄弟关系。
布局计算是一个递归的过程,因为一个节点的大小通常需要先计算它的子女节点的位置,大小等信息。每当发生重排时也就是每当元素几何位置属性发生更改时,那么浏览器就会重新布局、绘制以及之后的一系列操作。
元素的几何位置属性:宽度、margin、盒模型的数据结构、位置、浮动
布局计算就是计算元素的几何位置属性值,如果元素有子节点则会递归这个一个过程,通过上面的层层计算,就可以拿到位置坐标和具体大小保存到布局树中。
这个阶段是根据LayoutTree生成对应的图层树(layerTree)两者之间的关系如图所示:
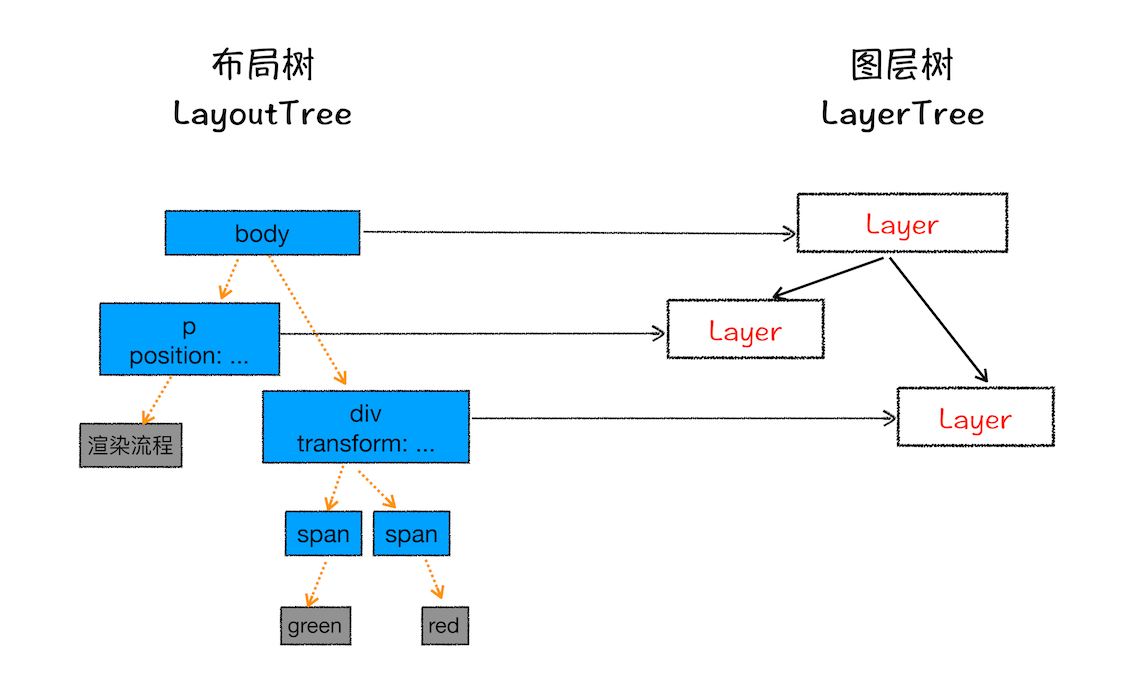
可看到并不是每个DOM节点都需要构建图层,只有满足构建图层的条件才会有对应的图层。
那需要满足什么样的条件,浏览器的渲染引擎才会为该节点创建图层呢?
1、拥有层叠上下文属性的元素会被提升为单独的一层
层叠上下文就是HTML中三维的概念,可以理解为浏览器创建图层的标识。如果一个元素含
有层叠上下文,我们可以理解为这个元素在 z 轴上就离用户越近。
z 轴:表示的是用户与显示器之间这条看不见的垂直线。
层叠上下文的特性:
层叠上下文的属性有:
2、需要剪裁(clip)的地方也会被创建为图层
这里的剪裁是当前元素内容溢出元素的所定的宽*高,并且设置了overflow:auto属性,这时候就产生了剪裁,渲染引擎会把裁剪文字内容的一部分用于显示在div区域,下图是示例:

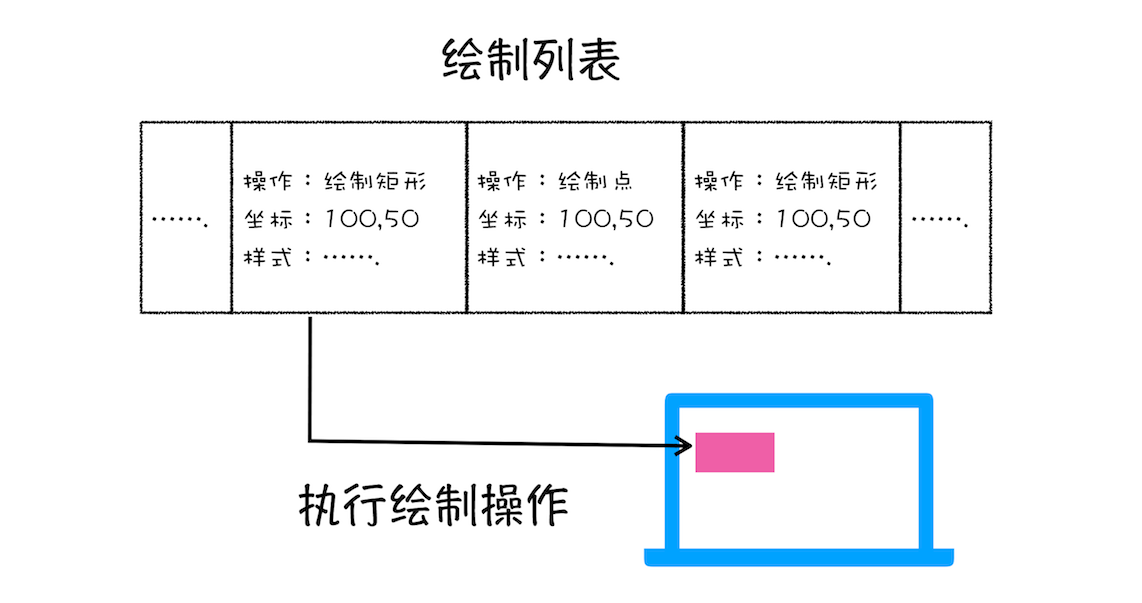
产生绘制指令,组成待绘制列表】
渲染引擎绘制图层会把一个图层的绘制分成若干个小的绘制指令,然后再把这些指令按照顺序组成一个待绘制列表
栅格化(raster)操作
绘制列表只是用来记录绘制顺序和绘制指令的列表,而实际上绘制操作是由渲染引擎中的合成线程来完成的。
通常一个页面可能很大,但是用户只能看到其中的一部分,我们把用户可以看到的这个部分叫做视口(viewport)。
在有些情况下,有的图层可以很大,比如有的页面你使用滚动条要滚动好久才能滚动到底部,但是通过视口,用户只能看到页面的很小一部分,所以在这种情况下,要绘制出所有图层内容的话,就会产生太大的开销,而且也没有必要。
基于这个原因,合成线程会将图层划分为图块(tile)然后合成线程会按照视口附近的图块来优先生成位图,实际生成位图的操作是由栅格化来执行的。
栅格化:将图块转换为位图。而图块是栅格化执行的最小单位
渲染进程维护了一个维护了一个栅格化的线程池,所有的图块栅格化都是在线程池内执行的
由于栅格化过程都会使用GPU来加速生成,使用GPU生成位图的过程叫快速栅格化,或者GPU栅格化,所以最终生成的位图保存在GPU进程内存中,如图所示:
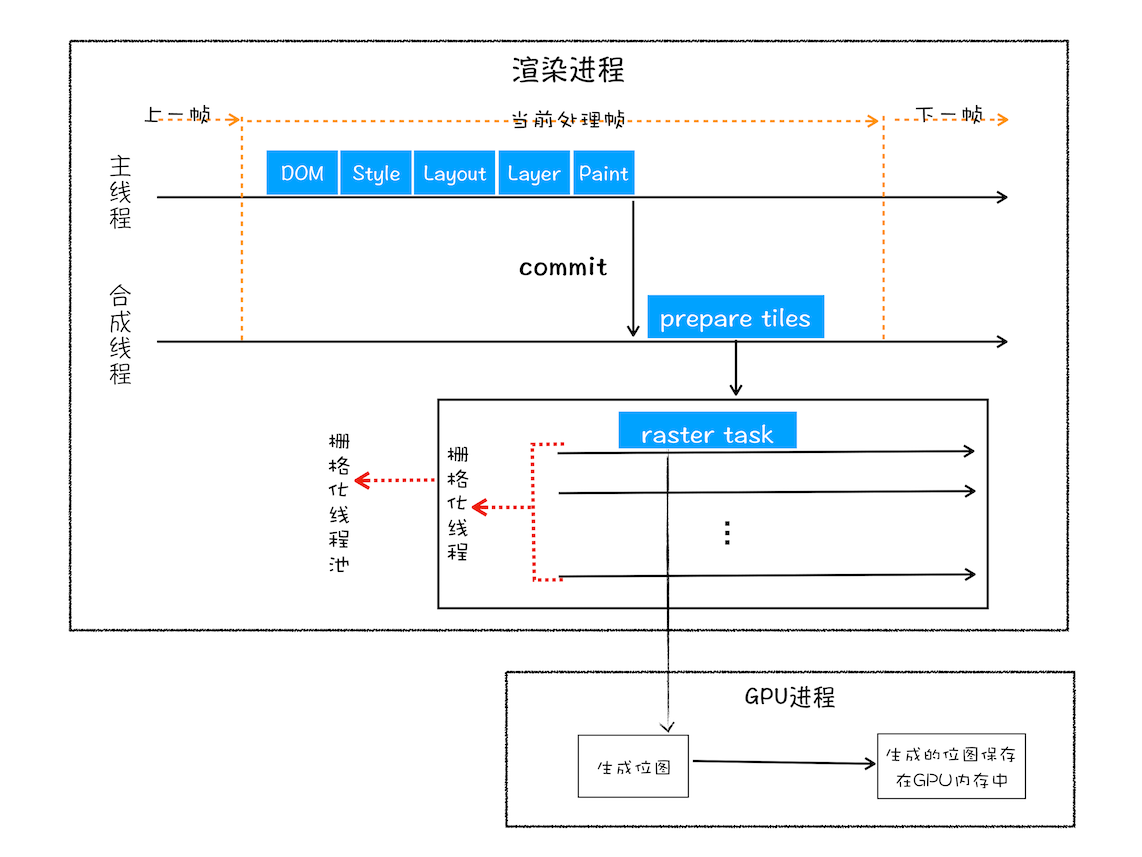
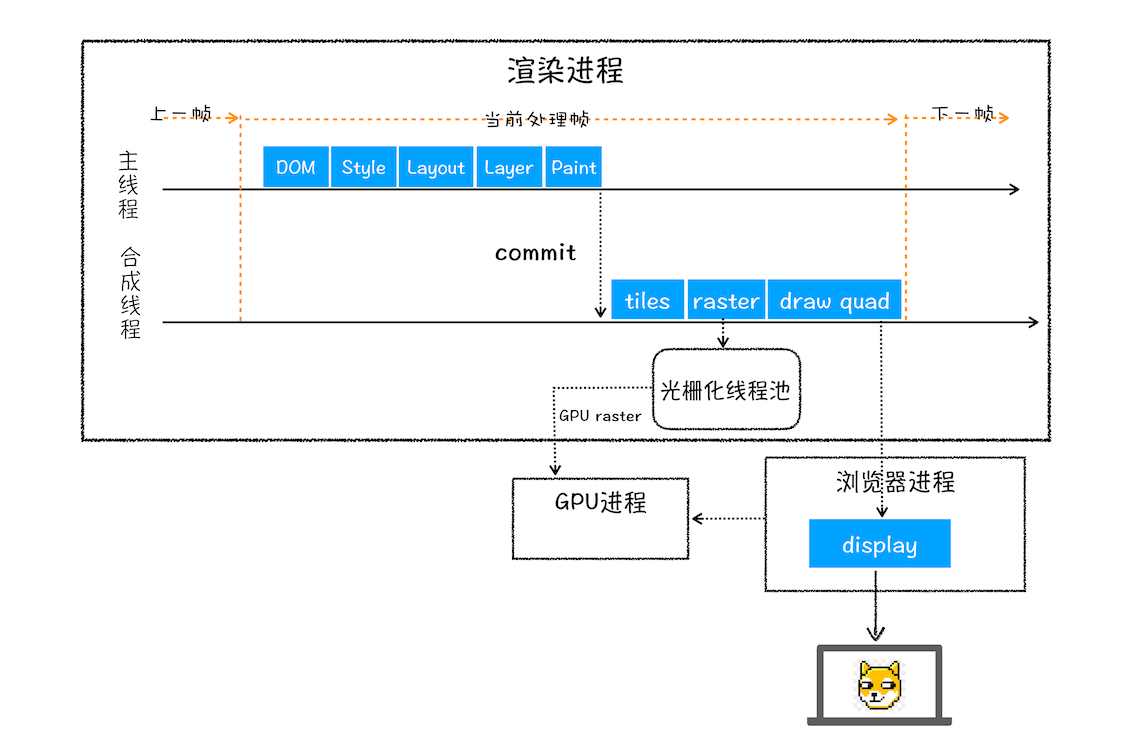
完整的渲染流程:
JsBridge作为 Hybrid 应用的一个利器,H5页面其实运行在Navtive的webView中,webView是移动端提供的JavaScript的环境,他是一种嵌入式浏览器原生应用可以用它来展示网络内容。可与页面JavaScript交互,实现混合开发。所以jsBridge自然也运行在webView中的JS Content中,这与原生有运行环境的隔离,所以需要有一种机制实现Native端和Web端的双向通信,这就是JsBridg。
以JavaScript引擎或Webview容器作为媒介,通过协定协议进行通信,实现Native端和Web端双向通信的一种机制。
JSBridge 是一种 JS 实现的 Bridge,连接着桥两端的 Native 和 H5。它在 APP 内方便地让 Native 调用 JS,JS 调用 Native ,是双向通信的通道。JSBridge 主要提供了 JS 调用 Native 代码的能力,实现原生功能如查看本地相册、打开摄像头、指纹支付等。
jsBridge就像它的名字的意义一样,是作为Native端(Ios端, Android端等)与非 Native 之间(这里指H5页面)的桥梁,它的核心作用是构建两端之间相互通信的通道。
在H5中JavaScript调用Native的方式有两种:
注入 API 方式的主要原理是,通过 WebView 提供的接口,向 JavaScript 的 Context(window)中注入对象或者方法,让 JavaScript 调用时,直接执行相应的 Native 代码逻辑,达到 JavaScript 调用 Native 的目的,使用该方式时,JS 需要等到 Native 执行完对应的逻辑后才能进行回调里面的操作。
Android 的 Webview 提供了 addJavascriptInterface 方法,支持 Android 4.2 及以上系统:
gpcWebView.addJavascriptInterface(new JavaScriptInterface(), 'nativeApiBridge');
public class JavaScriptInterface {
Context mContext;
JavaScriptInterface(Context c) {
mContext = c;
}
public void share(String webMessage){
// Native 逻辑
}
}上面代码的作用就是webView中绑定一个全局的对象(桥对象),然后将nativeApiBridge对象中的方法映射到Javascript中的nativeApiBridge的方法。
前端调用方式:
window.nativeBridge.postMessage(message);先简单的了解一下什么是URL Scheme?URL Scheme是一种类似url的链接,是为了方便app直接互相调用设计的,形式和普通的url近似 ,主要区别是schemel和host一般是自定义的:
如普通的url:

而url scheme类似这样:
kcnative://go/url?query拦截 URL SCHEME 的主要流程是:Web 端通过某种方式(例如 iframe.src)发送 URL Scheme 请求,之后 Native 通过( shouldOverrideUrlLoading() 方法)拦截到请求并根据 URL SCHEME(包括所带的参数)进行相关操作。
那么调用 Native 功能时 Callback 怎么实现的?
对于 JSBridge 的 Callbac,可以用JSONP的机制实现:
当发送 JSONP 请求时,url 参数里会有 callback 参数,其值是 当前页面唯一 的,而同时以此参 数值为 key 将回调函数存到 window 上,随后,服务器返回 script 中,也会以此参数值作为句柄,调>用相应的回调函数。
1.在H5中注入一个callback方法,放在window对象或者与Native端相绑定的对象中
/**
*
* @param callbackId
* @param obj
* 客户端通知webviw的callback
*/
const onCallback = function (callbackId: number, obj: any) {
if (ApiBridge.callbackCache[callbackId]) {
console.log('onCallback调用',callbackId);
console.log(ApiBridge.callbackCache[callbackId]);
ApiBridge.callbackCache[callbackId](obj)
}
}
//预先把callback存到一个callbackCache数组或者对象中,通过自增的方式确定callbackId2.然后把callback对应的id通过Url Schema传到Native端
const callNative = function (clz: string, method: string, args: any, callback?: any) {
let msgJson = {
clz,
method,
args,
}
if (args != undefined) msgJson.args = args
if (callback) {
const callbackId = getCallbackId()
ApiBridge.callbackCache[callbackId] = callback
if (msgJson.args) {
msgJson.args.callbackId = callbackId.toString()
} else {
msgJson.args = {
callbackId: callbackId.toString(),
}
}
}
if (browser.versions.ios) {
if (ApiBridge.bridgeIframe == undefined) {
bridgeCreate()
}
ApiBridge.msgQueue.push(msgJson)
if (!ApiBridge.processingMsg) ApiBridge.bridgeIframe!.src = 'native://go'
window.initJSBridge = true
} else if (browser.versions.android) {
var ua = window.navigator.userAgent.toLowerCase()
window.initJSBridge = true
// android
// prompt传参给Native
return prompt(JSON.stringify(msgJson))
}
}Native通过shouldOverrideUrlLoading(),拦截到WebView的请求,并通过与前端约定好的Url Schema判断是否是JSBridge调用。
3.Native解析出前端带上的callback,并使用下面方式调用callback
webView.loadUrl(String.format("javascript:callback_1(%s)", isChecked)); // 可以带上相应的参数通过上面几步就可以实现JavaScript到Native的通信
核心代码的实现
(function (window) {
let global = window
let kerkee:jsBridgeClient = {
getNativeData,
setNativeData,
doAction,
}
global.jsBridgeClient = kerkee
onBridgeInitComplete(function (aConfigs: any) {
// do something
})
})(window)getNativeData(method:string,params:{},callback) 从客户端获取数据
setNativeData(method:string,params:{key:value})H5告诉客户端一些数据 ,客户端执行相应操作
doAction(method:string,params:{},calllback:any)H5调用客户端组件或方法使用示例:
jsBridge.getNativeData('getUserInfo', (data: any) => {
console.log(data)
})
jsBridge.setNativeData('setWebBackColor', { back_color: 'red' })
jsBridge.doAction('buyGoods', { goods_info: state.goodsInfo, buy_num: 1 })
jsBridge.doAction('showShareDialog', {
is_share: 1,
share_type: 1,
share_url: '分享链接',
thumb: '项目链接'
content: '分享内容',
share_title: '分享标题!',
})总结:

核心Web指标:
Largest Contentful Paint (LCP) :最大内容绘制 (LCP) 指标会根据页面首次开始加载的时间点来报告可视区域内可见的最大图像或文本块完成渲染的相对时间。
如上图所示:为了提供良好的用户体验,页面应该将最大内容绘制控制在2.5 秒或以内,。为了确保您能够在大部分用户的访问期间达成建议目标值,一个良好的测量阈值为页面加载的第 75 个百分位数。
使用performanceObserver来监听largest-contentful-paint条目
new PerformanceObserver((entryList) => {
for (const entry of entryList.getEntries()) {
console.log('LCP candidate:', entry.startTime, entry);
}
}).observe({type: 'largest-contentful-paint', buffered: true});每条记录在案的largest-contentful-paint条目代表当前的 LCP 候选对象。通常情况下,最近条目发射的startTime值就是 LCP 值。
或者使用web-vitals库获取测量的LCP值
import {getLCP} from 'web-vitals';
// 当 LCP 可用时立即进行测量和记录。
getLCP(({value:lcp}) => {
// 上报
});可以上报用户真实的网络环境、系统语言并已柱状图的形式来观察页面的性能
如:

这样可视化的图更直观的页面的性能是否是在一个良好的水平
参考链接:webDev
定义:保证一个类仅有一个实例,并提供一个访问它的全局访问点
要实现单例模式比较简单,只要用一个变量来标志类是否被创建过,如果是,则在下次获取类的实例的时候,直接返回类上一次创建的实例对象。代码如下:
ES5版:
const createSingleInstance = (function (){
let instance = null
const createSingleInstance = function(name){
if(instance) return instance
this.name = name
instance = this
return instance
}
createSingleInstance.prototype.getName = function(){
return this.name
}
return createSingleInstance
})()
// text
const a = new createSingleInstance("a")
const b = new createSingleInstance("b")
console.log(a === b) // 输出true
a.getName() // 输出a
b.getName() // 输出a现在已经完成了透明单例类的编写,透明指可以通过传统new XXX的方式来获取对象。
但这样阅读起来不太舒服,我们来用ES6版本在实现一遍。
ES6:
class createSingleInstance {
constructor(name){
if(createSingleInstance.instance){
return createSingleInstance.instance
}
this.name = name
createSingleInstance.instance = this
}
getName(){
return this.name
}
}
const a = new createSingleInstance("a")
const b = new createSingleInstance("b")
console.log(a === b) // 输出true先看看call的MDN
Function.prototype.call()
call() 方法使用一个指定的 this 值和单独给出的一个或多个参数来调用一个函数。
使用:
function Product(name, price) {
this.name = name;
this.price = price;
}
function Food(name, price) {
Product.call(this, name, price);
this.category = 'food';
}
console.log(new Food('cheese', 5).name);思路
/**
* @prams context 上下文 也就是this要指向的函数
* @paams args 传入的参数
* @return 使用调用者提供的 this 值和参数调用该函数的返回值。若该方法没有返回值,则返回 undefined
*/
Function.prototype._call = function(context = window, ...args){
if(typeof this !== 'function'){
throw new Error('Type Error: this is not a function')
}
// 在context上加一个唯一值不影响context上的属性
let key = Symbol('key')
context[key] = this //将调用者提供的this指向传入的context的属性
let result = context[key](...args)
// 清除定义的this 不删除会导致context属性越来越多
delete context[key];
return result
}测试:
function Product(name, price) {
this.name = name;
this.price = price;
}
function Food(name, price) {
Product._call(this, name, price);
this.category = 'food';
}
const text = new Food('麻辣烫',15)
console.log(text); // Food {name: '麻辣烫', price: 15, category: 'food'}先上代码
/**
* @param {string} s
* @return {string}
*/
const longestPalindrome = function (s) {
let res = ""
let len = s.length
if (len < 2) return s
let maxLen = 1
let begin = 0
// 创建二维数组
let dp = Array.from(new Array(len), () => new Array(len).fill(false))
// 先将对角线的值初始化填为true
for (let i = 0; i < len; i++) {
dp[i][i] = true
}
// 状态 dp[i][j] 表示子串s[i...j]是否是回文子串
// 先计算左下方的值
for (let j = 1; j < len; j++) {
for (let i = 0; i < j; i++) {
if (s[i] !== s[j]) {
dp[i][j] = false
} else if (j - i < 3) {
// 头尾去掉没有字符和剩下一个字符的时候 一定是回文子串
dp[i][j] = true
} else {
// 如果都不是,则需要看左下角的状态
dp[i][j] = dp[i + 1][j - 1]
}
if (dp[i][j] && j - i + 1 > maxLen) {
maxLen = j - i + 1
begin = i
}
}
}
return s.substring(begin, begin + maxLen)
}
console.log(longestPalindrome("babad"))页面:userLeaderBoardList(首页榜单)【chikii】
优化前:81.78KB(Gzipped)
优化目标:73.602KB (Gzipped)
从webpack-bundle-analyzer 可视化打包报告来看,体积比较大的有:vue-i18n、web-sdk、main.js,所以优化的重点也从这三个文件入手
正所谓羊毛出在羊身上,首先删除项目中多余的模块、代码等(main.js项目入口文件)
去除后:减少了30个多余的modules
体积:81.78KB(Gzipped)→ 76.49 KB(Gzipped)
在Vue项目中,引入到工程中的所有js,编译时都会被打包进vendor.js
如果不做cdn配置通常来讲会将Vue,Vuex,axios,VueRouter等都打包进vendor.js里面,导致vendor.js文件过大
而浏览器在加载该文件之后才能开始显示首屏、所以一些不经常改变的包会让webpack不打包到vendor文件,而是在运行时(runtime)再去从外部获取这些扩展依赖
目前项目基建中已经对Vue,Vuex,axios,VueRouter 等第三方模块进行cdn配置。
基于这个思路vue- i18n包也可以以cdn的方式从外部获取
通过html-webpack-plugin 和 webpack-cdn-plugin 在打包后的index.html文件插入script标签,并告诉webpack哪些模块不需要打包
打包后的文件:
配置完重新打包后可以看到vue- i18n这个包没有被打包进来,而是以外链的方式存在
体积变化:76.49 KB(Gzipped)-> 68.11 KB(Gzipped)
同理web-sdk也可以从外部获取这些扩展依赖
体积变化:68.11 KB(Gzipped)-> 53.06 KB(Gzipped)
注意点:web-sdk包定义导出变量为library,所以挂载在window的变量也定为library供webpack使用
总体积变化:81.78KB(Gzipped)→ 53.06 KB(Gzipped) 减少了35%左右的体积,远远超出预定的优化目标
页面性能指标:
优化前:
优化后:
页面平均加载时长: 3.15s -> 2.52s
最大内容平均渲染时长: 3.15s -> 1.79s
首次内容平均渲染时长: 2.86s -> 1.59s
首次平均有效渲染时长: 2.89s -> 1.79s
在JavaScript中定义变量可以使用三个关键字:
- var
- let
- const
var VAR = '我是var'
let LET = '我是let'
const CONST = '我是const'以上代码都以各自的大写名称定义了变量,并赋予了值。既然这样可能就会有人困惑了?我该用哪种来定义变量?那我们就来分析一下:
这三种定义变量的方式都有什么区别呢?
1、var声明提升
console.log(VAR)
var VAR = '我是VAR'使用var时,上面的代码不会报错,正常来讲我在定义变量之前去使用变量应该会报错,但var不会。这是因为使用var这个关键字来声明的变量会自动提升到函数作用域的顶部,因为这个缘故ECMAScript会把这段代码看成等价于以下代码:
var VAR; // 这个时候它的值为undefined
console.log(VAR)
var VAR = '我是VAR'这就是“提升”,也就是把所有变量声明都拉到函数作用域的顶部。
2、let声明
let 跟 var 的作用差不多,但有着非常重要的区别。最明显的区别是,let 声明的范围是块作用域,
而 var 声明的范围是函数作用域。
let定义的变量会有暂时性死区,就是 let 声明的变量不会在作用域中被提升。
// name 会被提升
console.log(name); // undefined
var name = 'Matt';
// age 不会被提升
console.log(age); // ReferenceError:age 没有定义
let age = 26;在解析代码时,JavaScript 引擎也会注意出现在块后面的 let 声明,只不过在此之前不能以任何方式来引用未声明的变量。在 let 声明之前的执行瞬间被称为“暂时性死区”(temporal dead zone),在此阶段引用任何后面才声明的变量都会抛出 ReferenceError。
注意:这并不是常说的 let 不会提升,let 提升了,在第一阶段内存也已经为他开辟好了空间(暂时性死区),因为这个声明的特性导致了并不能在声明前使用
3、const声明
const 的行为与 let 基本相同,唯一一个重要的区别是用它声明变量时必须同时初始化变量,且
尝试修改 const 声明的变量会导致运行时错误。
JavaScript通过自动内存管理实现内存分配和闲置资源回收。
基本思路:确认哪个变量不会再使用,然后释放它占用的内存。
周期性:每个一段时间就会执行垃圾回收
那么如何确定哪个变量不会再被使用呢?主要通过两种策略:
总结:先所有都加上标记,再把环境中引用到的变量去除标记,剩下有标记的就是要删除的
顾名思义就是对每个值记录被引用的次数,当声明变量并给它赋一个引用值时,这个值的引用数为 1。如果保存对该值引用的变量被其他值给覆盖了,那么引用数减 1。垃圾回收程序下次运行的时候就会释放引用数为 0 的值的内存
发布订阅核心基于一个中心来建立整个体系。其中发布者和订阅者不直接进行通信,而是发布者将要发布的消息交由中心管理,订阅者也是根据自己的情况,按需订阅中心中的消息。
举个现实的案例,当英雄联盟的游戏玩家想要看比赛了,那么玩家可以订阅英雄联盟官方比赛,当比赛开始直播了,那么斗鱼、虎牙、bilibili、掌上英雄联盟等一下平台就会通知对应的订阅观众。
所以各大游戏直播平台充当调度中心、各大游戏官方号则充当发布者的角色,而玩家们则充当订阅者的角色
// 定义调度中心
class EventEmitter {
constructor(){
// 事件对象,存放订阅的比赛
this._event = {}
}
// 实现订阅 type为消息类别
on(type,callBack){
// 如果没有订阅过此类消息,给该消息创建一个消息的缓存列表
if(!this._event[type]){
this._event[type] = []
}
// 将订阅的消息添加进消息缓存列表
this._event[type].push(callBack)
}
// 实现发布
emit(type,...args){
if(this._event[type]){
this._event[type].forEach(callback => {
callback.apply(this,args)
})
}
}
// 取消订阅
off(type,callback){
if(!this._event[type]) return
this._event[type] = this._event[type].filter(fn => fn !== callback)
}
}
// 示例
const event = new EventEmitter()
const fn = function (time){
console.log(time,'比赛时间')
}
// 玩家订阅
event.on('LOL',fn)
// 官方号发布的信息
event.emit('LOL','2022-11-27') // 2022-11-27 比赛时间
// 有时候玩家不想看了,于是想取消订阅的比赛,所以还需要添加一个取消订阅的功能
event.off('LOL',fn)总结:
发布订阅模式优点:一方面实现了发布者与订阅者之间的解耦,中间者可在两者操作之间进行更细粒度的控制
new操作符做了这些事:
代码实现:
function myNew(fn, ...args) {
// 基于原型链 创建一个新对象
let newObj = Object.create(fn.prototype);
// 添加属性到新对象上 并获取obj函数的结果
let res = fn.apply(newObj, args); // 改变this指向
// 如果执行结果有返回值并且是一个对象, 返回执行的结果, 否则, 返回新创建的对象
return typeof res === 'object' ? res: newObj;
}用法:
// 用法
function Person(name, age) {
this.name = name;
this.age = age;
}
Person.prototype.say = function() {
console.log(this.age);
};
let p1 = myNew(Person, "poety", 18);
console.log(p1.name);
console.log(p1);
p1.say();先看一道面试题:
让下面的表达式成立:
const [a,b] = {a:1,b:2}
// Uncaught TypeError: {(intermediate value)(intermediate value)} is not iterable正常来讲浏览器会报 "{}" 是不可迭代的错误,需求就是让其变成可迭代的
在ES6中对象(Object)之所以没有默认部署 Iterator 接口,是因为对象的哪个属性先遍历,哪个属性后遍历是不确定的,需要开发者手动指定。
那么一个对象如果要具备可被for...of循环调用的 Iterator 接口,就必须在Symbol.iterator的属性上部署遍历器生成方法(原型链上的对象具有该方法也可)
所以为了让表达式成立,代码可以这样写:
Object.prototype[Symbol.iterator] = function () {
return {
next:function () {
return {
value:1,
done:true
}
}
}
}
const [a,b] = {a:1,b:2}这样就不会报错了
可迭代对象是Iterator接口的实现
Iterator 的作用有三个:一是为各种数据结构,提供一个统一的、简便的访问接口;二是使得数据结构的成员能够按某种次序排列;三是 ES6 创造了一种新的遍历命令for...of循环,Iterator 接口主要供for...of使用
解构是ES6提供的语法糖,其实内在是针对可迭代对象的Iterator接口,通过遍历器按顺序获取对应的值进行赋值
基本**:通过原型继承多个引用类型的属性和方法
代码示例:
function Animal(){
this.name = 'father'
}
Animal.prototype.getName = function(){return this.name}
function Cat(){}
Cat.prototype = new Animal()
const cat1 = new Cat()
cat1.name = 'dudu'
console.log(cat1.getName()) // dudu缺点:引用类型的属性被所有实例共享、子类型在实例化时不能给父类型的构造函数传参
基本**:在子类的构造函数中调用父类的构造函数,通过call()、bind()方法访问父类的构造函数属性
代码示例:
function Animal(name,type){
this.name = name
this.animalType = type
console.log(name,type)
}
function Cat(name,animalType,type){
// 继承Animal
Animal.call(this,name,animalType)
this.type = '田园猫'
}
const cat = new Cat('dudu','猫科动物','田园猫')
console.log(cat.animalType,cat.name,cat.type)优势:
缺点:父类构造函数的方法无法复用,因为方法都是写在构造函数中,每创建实例都会重新创建一遍方法,子类也不能访问父类原型上定义的方法
基本**:把原型链继承和借用构造函数继承结合一起
function Animal(name,type){
this.name = name
this.animalType = type
}
Animal.prototype.getName = function(){
// console.log(this.name);
return this.name
}
function Cat(name,animalType,type){
// 继承Animal
Animal.call(this,name,animalType)
this.type = type
}
Cat.prototype = new Animal()
const cat = new Cat('dudu','猫科动物','田园猫')
console.log(cat.animalType,cat.name,cat.type,cat.getName())优势:既能实现父类构造函数的方法复用,又能够保证每个实例有自己的属性
基本**:通过Object.create()创建新对象以及新对象定义的额外属性
let person = {
name: "Nicholas",
friends: ["Shelby", "Court", "Van"]
};
let anotherPerson = object(person);
anotherPerson.name = "Greg";
anotherPerson.friends.push("Rob");
let yetAnotherPerson = object(person);
yetAnotherPerson.name = "Linda";
yetAnotherPerson.friends.push("Barbie");
console.log(person.friends); // "Shelby,Court,Van,Rob,Barbie"优点:适合不需要创建构造函数的方式,但需要对象间共享信息。
缺点:属性中包含的引用值始终会在相关对象间共享,跟使用原型模式是一样的
基本**:实现一个创建对象的工厂函数,并返回对象
const objFactory = function(obj){
function fn(){}
fn.prototype = obj
return new fn()
}
function createAnother(original){
let clone = objFactory(original); // 通过调用函数创建一个新对象
clone.sayHi = function() { // 以某种方式增强这个对象
console.log("hi");
};
return clone; // 返回这个对象
}
let person = {
name: "Nicholas",
friends: ["Shelby", "Court", "Van"]
};
let anotherPerson = createAnother(person);
anotherPerson.sayHi(); // "hi"缺点:使用寄生式继承来为对象添加函数,会由于不能做到函数复用造成效率降低,这一点与构造函数模式类似
基本**:使用借用构造函数继承方法的来继承父类属性,使用原型链继承的方法来继承父类的方法。
不通过调用父类构造函数给子类原型赋值,而是取得父类原型的一个副本
function objFactory(obj) {
function fn() {}
fn.prototype = obj
return new fn()
}
function inheritPrototype(child,person){
const person1 = objFactory(person.prototype)
person1.constructor = person
child.prototype = person1
}
function person(name){
this.name = name
}
person.prototype.sayName = function(){
console.log(this.name);
}
function child(name){
person.call(this,name)
this.age = 18
}
inheritPrototype(child,person)
const child1 = new child('lzh')
console.log(child1.sayName());总结:通过创建一个父类构造函数的副本复制给子类的原型,在通过借用构造函数继承的方式来继承父类属性
优点:复制了超类原型的副本,而不必调用超类构造函数;既能够实现函数复用,又能避免引用类型实例被子类共享,同时创建子类只需要调用一次超类构造函数,最佳解
TCP 的三次握手,也是需要确认双方的两样能力: 发送的能力和接收的能力。
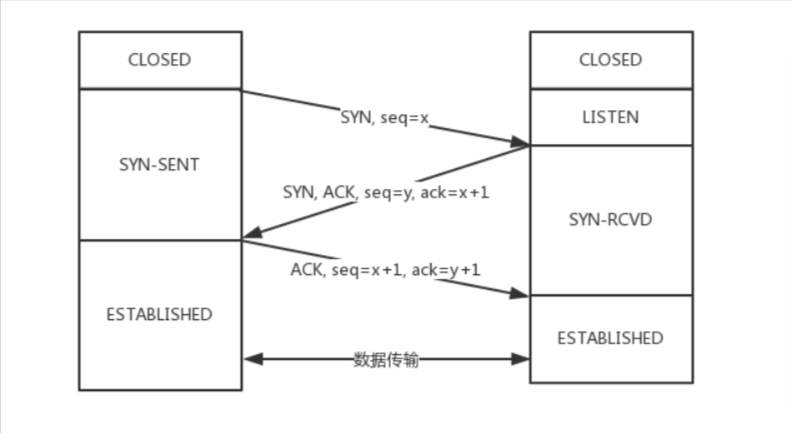
从图中可以看出,SYN 是需要消耗一个序列号的,下次发送对应的 ACK 序列号要加1,为什么呢?
因为凡是需要对端确认的,一定消耗TCP报文的序列号。
SYN 需要对端的确认, 而 ACK 并不需要,因此 SYN 消耗一个序列号而 ACK 不需要
问题:为什么是三次,两次行不行,四次呢?
根本原因: 无法确认客户端的接收能力。
如果是两次,客户端发送了SYN包想要建立连接,但是因为网络问题,这个包滞留在了当前的网络中迟迟没有到达,TCP 以为这是丢了包,于是重传,两次握手建立好了连接。
但是连接关闭后,如果这个滞留在网路中的包到达了服务端呢?这时候由于是两次握手,服务端只要接收到然后发送相应的数据包,就默认建立连接,但是现在客户端已经断开了。这就带来了连接资源的浪费。
在指定时间内只执行一次回调函数,如果在指定的时间内又触发了该事件,则回调函数的执行时间会基于此刻重新开始计算
function debounce(fn,delay = 100){
let timer;
return function(){
const context = this
const args = arguments
if(timer){
clearTimerout(timer)
timer = null
}
timer = setTimeout(() => {
fn.apply(context,args)
},delay)
}
}防抖动和节流本质是不一样的。防抖动是将多次执行变为最后一次执行,节流是将多次执行变成每隔一段时间执行。
函数节流:规定一个单位时间,在这个单位时间内,只能有一次触发事件的回调函数执行,如果在同一个单位时间内某事件被触发多次,只有一次能生效。
简单版本:
function createDeteTemp(){
return Date.now()
}
/**
* @param fn
* @param delay
*/
function throttle(fn,delay){
let preTime = createDeteTemp()
const context = this
const args = arguments
return function(){
const nowTime = createDeteTemp()
if(nowTime - preTime >= delay){
preTime = nowTime
fn.apply(context,args)
}
}
}
// test
const throttleRun = throttle(() => {
console.log(123);
}, 2000);
// 不停的移动鼠标,控制台每隔2s就会打印123
window.addEventListener('mousemove', throttleRun);navigator.connection
背景:需要获取用户的网络状态来统计不同网络下页面的性能情况
const networkType = navigator.connection.effectiveType
// 类型:
// '2g'
// '3g'
// '4g'
// 'slow-2'Chorome可以获得该属性,但是在Safari中effectiveType无法获得(导致了线上出现短暂的页面白屏),兼容性差,后续方案使用Native端提供的方法获取
总结:使用全局属性没有查看兼容性问题导致白屏,后续查明后无影响在使用
Event接口
背景:实现红包雨的动画需求时,由于整个动画实质是添加DOM,并在动画完成或者用户点击时删除对应的DOM元素在删除元素的逻辑中使用事件委托addEventListener
HTML结构:
<!-- 在外层 整个动画的下降区域 -->
<div class="down-area">
<!-- 父 控制红包雨下降 -->
<div class='red-down'>
<!-- 子 控制红包旋转 -->
<img src="xxx.png" class="red-envelop-rotate" />
</div>
</div>JS逻辑:
const handerPacketClick = () => {
rainAreaRef.value.addEventListener('click', e => {
const targetClassName = e.target.className
if (targetClassName === 'red-envelop-rotate') {
// Safari 的点击事件中不存在 event.path 可以通过event.composedPath()
const el = event.path || (event.composedPath && event.composedPath());
const id = el.id
if (!hitedPacketIdList.value.includes(id)) {
hitedPacketIdList.value.push(id)
rainAreaRef.value.removeChild(el)
}
}
})
}Safari 的点击事件中不存在 event.path 可以通过event.composedPath()获取事件路径
日期字符串转为时间戳
创建 Date 对象时没有使用new Date('2023-01-30')这样的写法,iOS 不支持以中划线分隔的日期格式,正确写法是new Date('2023/01/30')。
/**
* 力扣 647 回文子串
* 题目描述:
* 给你一个字符串 s ,请你统计并返回这个字符串中 回文子串 的数目。
* 回文字符串 是正着读和倒过来读一样的字符串。
* 子字符串 是字符串中的由连续字符组成的一个序列
* 具有不同开始位置或结束位置的子串,即使是由相同的字符组成,也会被视作不同的子串。
*
* @param {string} s
* @return {number}
*/
const countSubstrings = function (s) {
let len = s.length
let res = 0 // 结果
let dp = Array.from(new Array(len), () => new Array(len).fill(false))
for (let i = 0; i < len; i++) {
dp[i][i] = true
res += 1
}
for (let j = 1; j < len; j++) {
for (let i = 0; i < j; i++) {
if (s[i] !== s[j]) {
dp[i][j] = false
} else if (j - i < 3) {
dp[i][j] = true
} else {
dp[i][j] = dp[i + 1][j - 1]
}
if (dp[i][j]) {
res += 1
}
}
}
return res
}
console.log(countSubstrings("aaa")) // 6
console.log(countSubstrings("aaaaa")) // 15老样子实现之前先看看bind做了啥
Function.prototype.bind()
bind() 方法创建一个新的函数,在 bind() 被调用时,这个新函数的 this 被指为 bind() 的第一个参数,而其余参数将作为新函数的参数,供调用时使用
- bind返回一个新的函数
- 调用函数的方式有两种,一种是普通调用,一种是构造函数调用
对于普通函数,绑定this指向
对于构造函数,要保证原函数的原型对象上的属性不能丢失
代码实现:
Function.prototype._bind = function(context = window,...args){
// 先保存this指向,这里表示调用_bind的函数
let self = this
/**
* @params innerArgs 表示实际调用时传入的参数 fn.bind(obj, 1)(2)
*/
let fBound = function (...innerArgs) {
// 需要判断是否是普通函数调用还是构造函数调用
//this instanceof fBound为true表示构造函数的情况。如new func.bind(obj)
// 当作为构造函数时,this 指向实例,此时 this instanceof fBound 结果为 true,可以让实例获得来自绑定函数的值
// 当作为普通函数时,this 指向 window,此时结果为 false,将绑定函数的 this 指向 context
return self.apply(
this instanceof fBound
? this
: context
,args.concat(innerArgs)
)
}
// 如果是构造函数需要通过原型式继承 Object.cteate()的方式保证原函数原型对象上属性不丢失
fBound.prototype = Object.create(this.prototype)
return fBound
}// 测试用例
function Person(name, age) {
console.log('Person name:', name);
console.log('Person age:', age);
console.log('Person this:', this); // 构造函数this指向实例对象
}
// 构造函数原型的方法
Person.prototype.say = function() {
console.log('person say');
}
// 普通函数
function normalFun(name, age) {
console.log('普通函数 name:', name);
console.log('普通函数 age:', age);
console.log('普通函数 this:', this); // 普通函数this指向绑定bind的第一个参数 也就是例子中的obj
}
var obj = {
name: 'poetries',
age: 18
}
// 先测试作为构造函数调用
var bindFun = Person.myBind(obj, 'poetry1') // undefined
var a = new bindFun(10) // Person name: poetry1、Person age: 10、Person this: fBound {}
a.say() // person say
// 再测试作为普通函数调用
var bindNormalFun = normalFun.myBind(obj, 'poetry2') // undefined
bindNormalFun(12) // 普通函数name: poetry2 普通函数 age: 12 普通函数 this: {name: 'poetries', age: 18}什么是原型
在javaScript中,每当定义一个数据类型(如函数,对象)的时候,都会随之创建一个prototype属性,这个属性指向函数的原型对象
当一个函数通过new这个关键字调用时,这个函数就是一个构造函数,返回一个全新实例对象,这个实例对象有个__prto__属性指向这个构造函数的原型对象
总结:原型就是对象或者函数定义的时候所自带prototype属性,而它指向这个函数或者对象的原型对象
代码示例:
const person = function(){}
const p1 = new person()
console.log(person.prototype === p1.__proto__) // true如图所示:
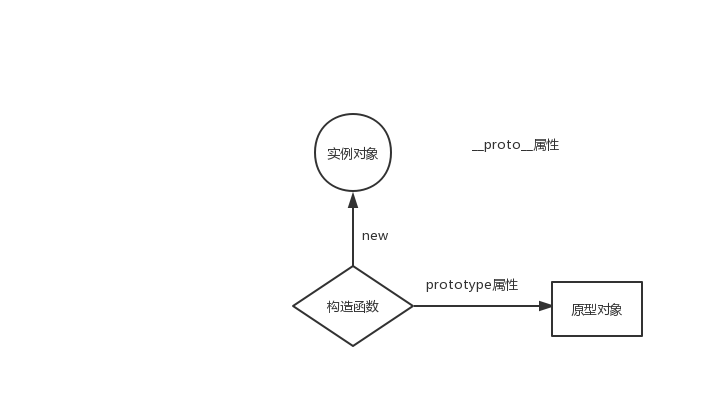
原型
如何理解原型链?
JavaScript对象通过prototype指向父类对象,直到指向Object对象为止,这样就形成了一个原型指向的链条, 即原型链。

对象的 hasOwnProperty() 来检查对象自身中是否含有该属性
使用 in 检查对象中是否含有某个属性时,如果对象中没有但是原型链中有,也会返回 true
先看图解四次挥手过程

答:这样做的目的是确保服务端收到自己的 ACK 报文。如果服务端在规定时间内没有收到客户端发来的 ACK 报文的话,服务端会重新发送 FIN 报文给客户端,客户端再次收到 FIN 报文之后,就知道之前的 ACK 报文丢失了,然后再次发送 ACK 报文给服务端)。服务端收到 ACK 报文之后,就关闭连接了,处于 CLOSED 状态。
答:由于TCP通信的双端都具有发送的能力和接收的能力。所以需要确认双方的发送的能力和接收的能力都关闭连接。
任何一方都可以在数据传送结束后发出连接释放的通知,待对方确认后进入半关闭状态。当另一方也没有数据再发送的时候,则发出连接释放通知,对方确认后就完全关闭了TCP连接。
两次握手就可以释放一端到另一端的 TCP 连接,完全释放连接一共需要四次握手。
如果是三次挥手会有什么问题?
等于说服务端将ACK和FIN的发送合并为一次挥手,这个时候长时间的延迟可能会导致客户端误以为FIN没有到达客户端,从而让客户端不断的重发FIN。
我们知道HTTP协议是使用明文传输的。所以在HTTP协议中有可能会出现信息窃听或者身份伪装等安全问题,而使用HTTPS通信机制可以有效防止这些问题。
HTTP协议的传输主要由以下缺点:
- 通信使用明文(不加密),内容可能会被窃听
- 不验证通信方身份,可能遭遇伪装
- 无法证明报文的完整性,所以有可能被篡改
这些问题在其他未加密的协议中也都会体现。
为什么说使用明文的方式传输是个缺点呢?这是因为,按TCP/IP的工作机制进行通信时,传输的数据都会经过应用层、传输层、网络层、链路层,TCP/IP的工作机制进如下图:

由图中可知,每一层都会给数据加上该层独特的标识,然后经过路由器、运营商、目标服务器,在这些环境中主需要收集互联网上流动的数据包就可以窃听请求中的数据了,常见的抓包工具Wireshark,它可以获得HTTP协议的请求和相应的内容,并对其进行解析。
Wireshark抓包示例图:

- SSL
- 对内容进行加密
通过SSL(Secure Socket Layer 安全套接层)或 TLS(Transport Layer Security 安全传输协议)的组合使用,加密HTTP的通信内容。
这种方式是建立一条安全的通信线路使HTTP可以在这条线路上进行通信,这种与SSL组合使用的加密方式称为HTTPS
内容的加密:顾名思义就是对数据内容本身进行加密,即把HTTP报文里所含内容进行加密处理,这种方式要求客户端和服务器都需要具有加密和解密的机制
HTTP协议中的请求和响应不会对通信方进行身份验证,就是存在服务器是否是客户端发起请求URL中的真正指定的主机,返回的响应是否真的返回到实际发起请求的客户端的问题。
所以SSL使用了一种被称为证书的手段来确定通信方。
证书由值得信赖的第三方机构颁发,用以证明服务器和客户端是实际存在的。只要能够确定(服务器和客户端)通信方的持有的证书即可确定双方身份。
完整性就是信息的准确度,无法证明报文的完成性就是无法确定信息的是否准确。
接受到的内容可能有误
由于HTTP协议无法证明通信报文的准确性,因此,在请求或响应后到对方接受之前的这段时间,请求或响应的内容有可能会被篡改,并且无法知悉。

比如,从某个web网站下载内容,客户端接收到的内容是无法确定是否与服务器存放的内容是一致的。文件内容有可能在传输过程中被第三方篡改,而客户端是无法得知内容是否被篡改的。这种行为被成为中间人攻击(Man-in-the-Middle-attack,MITM)。

对称加密(共享密钥)
非对称加密 (公开密钥)
对成加密: 加密和解密都用同一个密钥,这样带来的好处就是加解密效率很快,但是并不安全。
非对称加密: 一把公开密钥(public key),一把私有密钥(private key)。顾名思义公开密钥可以随意发布给他人,私有密钥不能让其他人知道。效率慢
使用非对称加密方式,发送密文的一方使用对方发布的公开密钥进行加密,对方收到加密的信息后,在使用自己的私钥进行加密。
混合加密: HTTPS采用对称加密和非对称加密两者合并并用的混合加密机制。


在客户端第一次给服务端发送HTTPS请求的时候,服务端会将它自己的证书随着其它的信息(例如server_random、 server_params、需要使用的加密套件等东西)一起返给客户端。
所以数字证书认证就能够保证HTTP通信方的身份和报文的完整性。
先看看apply的MDN
Function.prototype.apply()
apply() 方法调用一个具有给定 this 值的函数,以及以一个数组(或一个类数组对象)的形式提供的参数
使用:
function Product(name, price) {
this.name = name;
this.price = price;
}
function Food(name, price) {
Product.apply(this, name, price);
this.category = 'food';
}
console.log(new Food('cheese', 5).name);实现思路跟call一样,只不过传参不同,不了解的请看上篇:实现call方法
/**
* @prams context 上下文 也就是this要指向的函数
* @parms args 传入的参数 Array
* @return 返回结果
*/
Function.prototype._apply = function(context = window, args){
if(typeof this !== 'function'){
throw new Error('Type Error: this is not a function')
}
const isArray = args instanceof Array
if(!isArray){
throw new Error('Type Error: args is not a Array')
}
// 在context上加一个唯一值不影响context上的属性
let key = Symbol('key')
context[key] = this //将调用者提供的this指向传入的context的属性
let result = context[key](args)
// 清除定义的this 不删除会导致context属性越来越多
delete context[key];
return result
}测试:
function Product(name, price) {
this.name = name;
this.price = price;
}
function Food(name, price) {
Product._apply(this, name, price);
this.category = 'food';
}
const text = new Food('麻辣烫',15)
console.log(text); // Food {name: '麻辣烫', price: 15, category: 'food'}考察点:递归
function isObject(obj){
return typeof obj === 'object'
}
function deepClone(obj){
if(!obj || !isObject(obj)) return obj
const cloneTarget = Array.isArray(obj) ? [] : {}
for(let key in obj){
if(obj.hasOwnProperty(key)){
cloneTarget[key] = typeof obj[key] === 'object' ? deepClone(obj[key]) : obj[key];
}
}
return cloneTarget
}这是简单版本,还不够完善,但已经能覆盖大多数应用场景。
但如果有以下的应用场景,则还需优化,现在来一步一步优化我们的代码:
1、无法解决循环引用的问题
2、无法拷贝一些特殊的对象,诸如 RegExp, Date, Set, Map等
3、无法拷贝函数(划重点)。
举个例子:
const obj = {val:2};
obj.target = obj;
deepClone(obj);//报错: RangeError: Maximum call stack size exceeded拷贝obj会出现系统栈溢出,因为出现了无限递归的情况。
如何解决?是不是只要在递归前判断这个对象是否拷贝过,那么记录下已经拷贝过的对象,如果说已经拷贝过,那直接返回它问题就解决了。
在JavaScript中,存储对象可以使用map和weakMap,在这里两种都可以作为存储对象的方法,但在使用弱引用weakMap更方便垃圾回收,性能更佳,更多可以看看了解JavaScript弱引用与垃圾回收
创建一个WeakMap用来记录拷贝过的对象
function isObject(obj){
return typeof obj === 'object'
}
const targetWeakMap = new WeakMap()
function deepClone(obj){
if(targetWeakMap.get(obj)) return obj
if(!obj || !isObject(obj)) return obj
targetWeakMap.set(obj,true)
const cloneTarget = Array.isArray(obj) ? [] : {}
for(let key in obj){
if(obj.hasOwnProperty(key)){
cloneTarget[key] = typeof obj[key] === 'object' ? deepClone(obj[key]) : obj[key];
}
}
return cloneTarget
}这样就不会报错了!
TODO
2、无法拷贝一些特殊的对象,诸如 RegExp, Date, Set, Map等
3、无法拷贝函数(划重点)。
在《JavaScript深入之执行上下文栈》中讲到,当JavaScript代码执行一段可执行代码(executable code)时,会创建对应的执行上下文(execution context)。
对于每个执行上下文都有三个重要属性:
当查找变量对象时,会先在当前的执行上下文的变量对象查找,如果没有找到就会从父级的执行上下文的变量对象中查找,一直找到全局上下文变量对象,也就是全局对象。这样由多个执行上下文的变量对象构成的链表就是作用域链。
首先认识一下什么是拷贝?
let arr = [1,2,3]
let newArr = arr
newArr[0] = 13
console.log(arr);//[100, 2, 3]这是直接赋值不涉及任何拷贝,由于进行赋值操作的是数组,而数组在javaScript中是引用值,当把引用值从一个变量赋给另一个变量时,存储在变量中的值也会被复制到新变量所在的位置。与原始值的区别在于,这里面复制的是指向变量存储位置(堆内存)的指针(地址)。实际两个变量指向的是一个地址也就是同一变量
如图:

现在进行浅拷贝
let arr = [1, 2, 3];
let newArr = arr.slice();
newArr[0] = 100;
console.log(arr);//[1, 2, 3]当修改newArr的时候,arr的值并不改变。什么原因?因为这里newArr是arr浅拷贝后的结果,newArr和arr现在引用的已经不是同一块空间啦!
let arr = [1, 2, {val: 4}];
let newArr = arr.slice();
newArr[2].val = 1000;
console.log(arr);//[ 1, 2, { val: 1000 } ]但如果改变的是引用值(数组、对象),浅拷贝只能拷贝一层对象
弄清楚浅拷贝那么现在来实现浅拷贝:
const shallowClone = (target) => {
if(typeof target === 'object' && target !== null){
const cloneTarget = Array.isArray(target) ? [] : {}
for(let key in target){
if(target.hasOwnProperty(key)){
cloneTarget[key] = target[key];
}
}
return cloneTarget;
}else{
return target
}
}除了自己造轮子外,slice、...展开运算符、concat、Object.assign这些常见的api拷贝的都是对象的属性的引用,而不是对象本身都是属于浅拷贝
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.











