was1840 / webclipper Goto Github PK
View Code? Open in Web Editor NEW存储网页的剪藏文件
存储网页的剪藏文件

子路曰:「卫君待子而为政,子将奚先?」
子曰:「必也正名乎!」
子路曰:「有是哉,子之迂也!奚其正?」
子曰:「野哉,由也!君子于其所不知,盖阙如也。名不正,则言不顺;言不顺,则事不成;事不成,则礼乐不兴;礼乐不兴,则刑罚不中;刑罚不中,则民无所措手足。故君子名之必可言也,言之必可行也。君子于其言,无所苟而已矣。 」
——《论语》 13.3
从写专栏之初我就想避免制造「黑话」,用简单明晰的话语,让每个刚刚接触科研工具或是知识管理的人可以按照专栏复刻操作过程。但我不得不花一点篇幅来输出概念。
当我们在谈论「个人知识管理」(Personal Knowledge Manage, PKM)的时候,我们不可避免地遇到了这些被刻意「制造」的「黑话」。比如「ACEPOS」、「ACTS」、「A/S」、「FF」[1]以及上面的「PKM」等等和它们的各种译名变体。
在知识管理领域(以及各类人文学科里),这种对「黑话」的高级迷信仍然像幽灵一样徘徊在我们这些爱好者的脑海里。我们沉醉于形而上学的迷狂中,从来没有思考过这些「黑话」是否能够帮助我们真正解决什么问题,或者说从来没有思考过这些「黑话」本身可能就是一种问题。
「黑话」或者说是「术语」发明之初是为了明确日常语言无法言明的概念,每个「黑话」都有明确且单义的指向。但在互联网的讨论中,使用「黑话」反而成为了语焉不详的人的避难所。
对于知识管理中的黑话,我认为:
下面我将讨论「书目」(Biblography)、「目录」(Table of Content, TOC)、「索引」(Index)和「内容地图」(Map of Content, MOC)这四个概念。
「书目」和「目录」在中文都可以用「目录」来表示。一般情况下,图书馆、情报与文献学所说的「目录」指的是前者。
目录是以图书或其他单独出版的整本文献作为著录对象,一般只著录文献的书名、作者、出版者、出版时间等外在特征。[2]
这里我根据加工对象不同进行了刻意区分。「书目」和「目录」相比,前者是文献检索工具,对象是多个文献;后者反应的是单个文献的内容组成,对象是单个文献。
「索引」同样是一种文献检索工具。
索引,这里指文献索引,旧称引得、通检、备检。索引是对某种文献或某一文献集合中所包含的各篇文章,或所讨论的各个局部主题,或所涉及的各种事项 (如地区、人物、机构、事件、生物、矿物、产品、设备、公式、数据、著作等) 以简明的方式分别著录标引,即确定其检索标识和指出其所在位置,并将款目按一定的可检顺序排列和组织,以方便查检的文献检索工具。[3]
「内容地图」蕴含了知识可视化的概念,在双链笔记领域(可能)最早由 Niko Milo 提出。
在 Nick Milo 的表述中「Map of Content」和「Table of Content」是一组相对的概念,正在生成的内容适合用 MOC 进行管理,一旦敲定 MOC 可以演变为 TOC 。
严格意义上,这里的 TOC 与上面定义的「目录」不同。 Niko Milo 指出 MOC 和 TOC 的区别在于线性和非线性。
QUESTION: What's the difference for you between MOC and TOC? They seem interchangable, am I missing something there?
ANSWER: The distinction, which serves an important purpose, is an MOC doesn’t have to follow a linear format. It can be constantly reshuffled by you to meet your needs. It’s great for compiling topic-related ideas, notes, concepts. Contrast that with a Table of Contents (TOC). It has one specific and linear order. A TOC should almost always find itself tied to a specific project. So for a book project, you have the broad MOC (like a big work table with papers spread out everywhere); and you’d be building towards the specific, linear TOC, which would be the more traditional “section 2, chapter 1” or whatever. On projects, I see the MOC and TOC as working in tandem more often than not.[4]
和很多知识管理领域概念的提出者一样,Nick Milo 的 MOC 很有吸引力,但依然存在含混的地方。 Nick Milo 将 MOC 到 TOC 的判断标准定为「敲定」(finalize),因此他认为这一过程只可能发生在项目之中。但 MOC 无法解决这些问题:
以及,Nick Milo 所说的 MOC 和 TOC 的区别是否是被**「制造」**出来的?背后的实质只是流动与固定的区别?
按照上面的讨论,我们可以认为 MOC 是「黑话」。实际上,MOC 可以模糊地归纳出以下三点特质:
[[]]组成简单来说,只要按照一定组织逻辑,在特定笔记页用双链标记相关主题的内容,依靠笔记软件的图谱就可以实现 MOC 的功能。MOC 只是双链笔记时代的一种文献检索工具的呈现形式。
一般地说:目录的著录对象是一个完整的出版单位,如一种图书、一种期刊、一种报纸、一份科技报告、一份技术标准等;而索引所著录的则是一个完整出版物的某一部分、某一内容。[5]
An index is ordered by some arbitrary method, like alphabetical or in topical sections. An MOC is like an encyclopedia article that links to a bunch of other notes. It's organized to communicate meaning, indexes are organized to find stuff quickly.[6]
沟通意义(communicate meaning)的目的还是快速定位(find stuff quickly),消除搜索的不确定性是我们结构组织的出发点,两者并不冲突(在我看来就是一回事),定位和意义都是我们想要的结果。
Roam 的成功,除了优秀的设计、到位的宣传,更因其顺应大势:天下苦层级结构久矣!作为一种有着悠久传统的组织方式,层级结构的问题日益凸显:
- 只能按照一种方式设置目录结构,无法很好地处理有多种分类方式的情况。更麻烦的是,随着生活的前进,如果发现原先的分类体系不适用,就需要重新分类。
- 如果一开始在错误的目录中寻找文件,可能需要浏览多个层级之后,才能意识到自己找错了地方,费时费力。而最坏的情况是:文件实际存在,但因为没有找到认为它不存在。
- 严格的层级结构,不利于激发灵感,发现笔记之间有趣的联系。
- 很难实现分类的 MECE 原则:相互独立、完全穷尽。[7]
不管是 RR,还是_How to Take Smart Notes_ [8]都秉承了这种自下而上的反层级结构的组织思路,它们在悄悄诱惑我们:「放心大胆地写吧!你只用关心写作,我们会帮你搭建好笔记之间的关联的!」
但是,仅仅依靠双链,或是加上标签,能够帮助我们形成一套可靠的知识管理系统嘛?我们可以轻松找到想要的笔记嘛?
不管是 P.A.R.A [9]还是 P.B.A.T [10],这些知识管理系统概念都摆脱不了上面提及的「黑话」悖论。
以 P.A.R.A 为例,四种分类实际上代表了四种不同的状态的文件,我将它们可以简单概括为:
P.B.A.T 同样如此:
这些知识管理系统的理念都是可以被表述得浅显而又明确的。但在实操中,除了入门太复杂以外,这些管理系统在 Notion 上似乎都表现得不错。因为 Notion 的「数据库」功能支持它们用简单的四分法来实现有效的扁平化而非多层次的组织方式。
与 RR 不同,部分中文社区的 Obsidian 使用者自觉地转向了自上而下的组织方式。
这是 Obsidian 文件夹结构设计导向的结果,但让我们重新思考卢曼(Niklas Luhmann)的「卡片盒子」(Zettelkasten)系统。很多论者在介绍「卡片盒子」时只强调卢曼写作的四类卡片,却不深入讨论卢曼为了维持这套持续增长的、非线性的系统所制作的编码、书目以及关键词索引。
What mattered to him was “what could be utilized in which way for the cards that had already been written. Hence, when reading, I always have the question in mind of how the books can be integrated into the filing system”.[11]
卢曼经过一代「卡片盒子」的积累确定了自己的阅读和研究兴趣,他的编码主题不再是简单的列表(list)或是基于分类学(taxonomy)和目录(TOC)的顺序系统,而是依靠编码确定内容的上下级关系(也就是依靠编码组织了 Nick Milo 说的「邻近度」),依靠书目和关键词索引快速定位笔记,以及展现笔记之间意义上联系的复杂系统集合。
卢曼的经验告诉我们:
编码很重要。
编码系统是一套树形结构,为追踪笔记提供了唯一性的地址。
书目和索引很重要。
书目和索引是一套网状结构,根据意义(如关键词)聚合笔记内容,这实际上也是 Nick Milo 所说的 MOC 做的工作。
笔记系统需要迭代。
我们不一定能只在一代「卡片盒子」系统内就确定自己的阅读和研究兴趣。
基于《**图书馆分类法》的分类标准,建立一套设计严密的知识管理系统对于正在确定自己知识体系的人是很有帮助的。但正如卢曼指出的:妄想一劳永逸地待在固定的分类序列里是愚蠢的。
“Defining a system of contents (resembling a book’s table of contents) would imply committing to a specific sequence once and for all (for decades to come!)”.[12]
作为一个 Obsidian 的使用者,我承认针对传统层级组织结构的批评都对这种自上而下的组织方式适用。但卢曼也花了十一年的时间(1951–1962)来打磨自己的笔记系统,确定阅读和研究兴趣点,我们需要尝试专业的图书馆分类法对新兴的双链笔记是否适用,不是嘛?
回到核心问题:代表着传统层级组织结构的文件夹是否是 Obsidian 设计理念落后的表现?
保留文件夹结构给予了我们选择的权利,我的看法和 Nick Milo 表述的一样:
不久前,文件夹还是我们的全部,它们还不够好。现在,我们有了链接。许多人对文件夹采取了强硬的立场,因为他们认为自己需要的就是链接。这样,强硬的立场转而变得脆弱。不要被教条所迷惑。一个健康数字资料库的正确工具应该包含多重的「桥梁」(relationship-builder)。[13]
用 Zotero 写卡,最后用 Scrivener 组卡是种非常新鲜的体验。
Zotero 作为一款文献管理软件,笔记书写体验一般,笔记之间的关联性差,这是个不争的事实。但使用 Zotero 就意味着我们必然选择文件夹这种传统的层级组织结构,我们不再需要考虑双链、MOC 等双链笔记带来的自由之累,专注于写作和思考本身。
“Underlying the filing technique is the experience that without writing, there is no thinking”.[14]
这个实践样本验证了卢曼的核心思路:我们的笔记系统应该是建立在有思考的写作基础之上,笔记才是知识管理系统的核心。
确定需求永远是我们进行知识管理首先要解决的问题。
以上思考的知识管理领域内的「黑话」以及四种软件背后的四类组织模式的主要目的,不仅在于批判现象、指出缺点、完全反对它们,相反我从 RR、Notion、Obsidian 或是 Zotero 的设计理念和实践者的工作流中学习到了很多。我更希望大家思考我们真正想要实现什么?
我认为编制一个自上而下的树形结构系统(编码、TOC、图书分类法或者其他)和一个自下而上的网状结构系统(书目、MOC、索引或者其他)同样重要,前者代表着我们可以快速定位笔记的空间位置,后者揭示了笔记之间内容上的关联。
一切讨论都需要回归实际,在第 4 节和第 5 节我分别会以 Obsidian 和 Zotero 为例,展示我是如何以赖氏中图法为基础建立个人知识管理系统。
我很欣赏 Nick Milo 在《如何在笔记之间形成有效的关联?》中的写作思路:当我们讨论建立个人知识管理系统的时候,我们首先需要谈论我们拥有什么「桥梁」(relationship-builder)。
文件夹 & 文件
文件夹和文件名称:二者应该采用同一套编码系统。
路径:Dataview 插件实现了对于文件夹路径的追踪,路径应该和「文件夹 & 文件」系统保持同构性。
文件夹描述页:利用插件 Folder Note 可以为文件夹增加描述笔记。
目录:在单个笔记内对应「大纲」(outline),对整个库而言根据编码系统可以编制目录。另,可以文件夹为单位在相应描述笔记内建立追踪。
标签
标签、多重标签、嵌套标签:多重标签不利于记忆,应多采用嵌套标签表示标签的层级关系。
标签数量及内容类型:标签是弱关联,应尽量减少标签数量,保持标签描述一个固定的内容类型,如#方法、#评分、#文本中的一个,其他应该在 YAML 标识。
YAML
用 YAML 替代标签:可以根据需要标识不同的内容类型。
双链[[]]
MOC:根据关键词建立意义的关联。
基于 P.A.R.A ,我对编码系统进行了调整,但依然只是归类不同状态的文件。在文件夹名中我加入了从杜威十进制分类法中吸收的分类码,但并没有实际的含义,仅是为了按文件名(A-Z)排序。这套编码系统保证了文件名和文件路径的一致性。
在实际操作中,我们可以学习卢曼的编码思路,每一条编码之间可以是并列的或者是延续的,我们可以在分类码后面无穷添加展开,保持整体结构的稳定。
理想状态的标签应该一一对应中图法中的主题词,但确定主题词在实际操作中过于繁琐,目前我认为较好的办法是自己限定主题词。
当标签对应的笔记数量过少时,我们需要考虑这个标签是否有存在的必要。当标签对应的笔记数量过多时(比如图中的「学习法」),我们需要考虑这个标签是否需要细化拆分,或者升级为 MOC ?
UID(User Identification,用户身份证明)实际上是没有必要的,因为 UID 本身没有可读性,它提供了唯一的时间代码来确定笔记的唯一性,但这一功能和分类号重复了。不过分类号提供的是具有唯一性的地点代码,可以考虑舍弃 UID 或者保留两者。UID 提供的时间在 Dataview 插件中,可以用 file.ctime代替。
status(状态)默认为 unfinished,阅读完后根据我会内容的重要成都更新为 important 或者 complete。status 有且只有这三种状态。
archive(存档位置)对应赖氏中图法分类。只需要记住常用分类号,然后利用 Keyboard Maestro 设置打字触发,输入分类号就可以自动完成输入内容。
我收集并制作的赖永祥中图法资源如下,你可以根据「基本大纲」或者「简表」先确定感兴趣的领域,再利用「纲目表」细化你的研究领域。
keywords(关键词):存放一些零散的、数量过少、不能升级为标签的关键词。
aliases(别名):Obsidian 的特色,可以根据别名检索。
cssclass:某个表格 css 的样式选择器。
如常用页 MOC :
Q:如何追踪标签、YAML、文件夹等内容呢?
A:利用 Dataview、Query Language 等插件,推荐阅读这篇专栏:
在 Zotero 里,我们可以用到的「桥梁」只有三种:
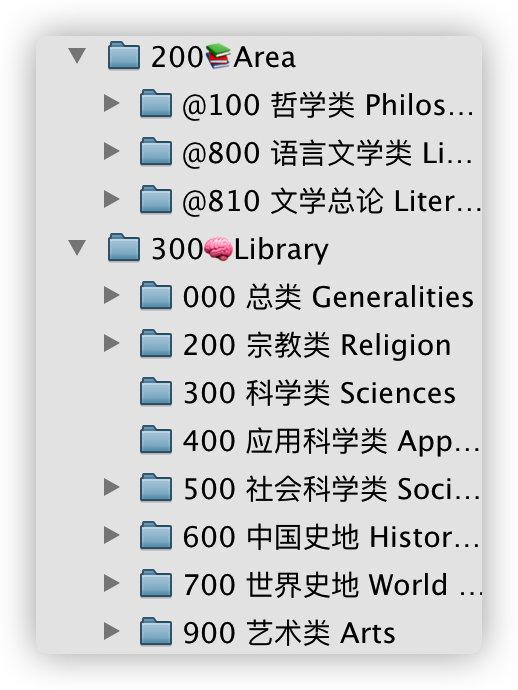
Zotero 内的编码系统我依然选择用 P.A.R.A 的变形,但在「200 Area」和「300 Library」内我按照中图法分类号的知识结构来组织文件夹。
如何将文件夹所表示的分类号与条目联系起来?我选择把分类号储存在「存档位置」内。
如果使用的是 CLC 中图法,可以用「道格学社」提供的「翻译器」和「油猴脚本」:
如果你对我 Zotero 的知识管理系统感兴趣,可以将**「Zotero Library.rdf」**导入你的 Zotero 内,我根据「简表」分类号创建好了文件夹。
此外,你还可以使用 Zotero 插件 Zutilo 的「Copy item fileds」功能,快速填入分类号。提取码: 4f4m
关于理想的笔记系统是什么样的,众说纷纭。不过私以为,明确原则,理清期许,设计最小可用系统(MVP),然后在使用中,不断优化迭代,或许就是笔记系统的理想构建方法了吧。[15]
我认为一篇好的个人知识管理系统文章不是在灌输什么「黑话」,而是提供一种思考的角度。你不必照搬我的系统,希望我的尝试能够给你带来启发。
感谢你宝贵的时间!
欢迎大家关注我的 Notion 个人主页,我会在那里存档专栏内容、分享实用工具、网站、课程和其他资源。
感谢社区用户对我的一而再再而三的明里暗里催更。
如果你问我之前 Obsidian 中哪个插件在索引以及展示上更强,我会说 Obsidian Query Language 更强;但是如果你现在问我,那我只能跟你说,是 Dataview,而今天也将介绍这款目前在 Obsidian 插件社区中被 Star 最多的插件,如果说 Obsidian 是你的**汇聚基地,那么 Dataview 就是你的仪表盘。
Obsidian 原本是基于纯文本的,它只设计了基础的数据查询功能(也就是你打开 Obsidian 后能看到的搜索框),它本不支持将这些数据动态展示以及动态更替;不过事情在今年的 1 月 11 日~ 13 日这短短三天发生了变化,Obsidian 社区先后迎来了 Obsidian Query Language 插件以及 Dataview 插件,如果你曾经使用过这两者中的其一,你就会发现他们对数据都是动态索引、动态展示的,而这种方式就是我们所熟知的结构化查询语言,不过目前并不支持在查询后对对应的文本进行删改,因此只能说是 50% 结构化查询,侧重于执行查询、取回数据以及创建视图三大方面。
通过利用 Dataview 插件,你可以且轻易地实现倒计时功能、表格创建功能、任务查询功能等(当然还有各种聚合功能);而随着 Dataview 的更新,它在原来只能使用已经封装好的函数的基础上,加上了对利用 Obsidian API 的支持,也就是说如果你懂或者照抄别人的 Javascript 代码,你就可以基于 Javascript 的代码逻辑对 Obsidian 的数据进行改动后展示,你可以任意删改其中的数据后再展示,例如,你发现自己获取的文字有一些想要标注拼音的,那么你可以利用 Dataview 对这些字符做专门的匹配后输出(只要利用 Markdown Furigana 插件就可以实现任意的字符串标注):
Dataview 插件目前支持多种索引方案,现在我们先来介绍其中最简单的一种,你只需要在任意笔记中插入下方内容即可生成相对应的列表,
例如,如果你想要根据 Games 文件夹生成一个表格,而且表格的内容基于你这个文件夹中的每个文件的 YAML 进行索引,已知你设置了一些笔记的 YAML 为
---
time-played: All the time.
length: 2000h
rating: 9.5
---然后你有一大堆类似的游戏笔记,那么你可以用下列的 Dataview 生成式来生成对应的表格
```dataview
table time-played, length, rating
from "games"
sort rating desc
```
如图:
如果你问,如果你不想这个表头显示成英文,也很简单,你可以用 AS 来修改对应的表格头,例如:
```dataview
table time-played AS "啥时候玩的", length AS "玩了多久", rating AS "多好玩"
from "games"
sort rating desc
```
备注,其中的 SORT 命令可以是单个参数,例如 sort rating desc 指的就是以 rating 为参数降序,类似地,当你用 sort rating asc 的时候,代表的就是基于 rating 升序;那么也许你会想知道,那么怎么实现多个区域分别排序升序呢,很简单,参考下边的官方例子:
SORT rating [ASCENDING/DESCENDING/ASC/DESC], ..., time-played [ASC/DESC]
也是用 , 将多个排序命令分割开来即可。
而表格的所有设置可以看下边的代码以及对应的解释:
```dataview
[list|table|task] field1, (field2 + field3) as myfield, ..., fieldN
from #tag or "folder" or [[link]] or outgoing([[link]])
where field [>|>=|<|<=|=|&|'|'] [field2|literal value] (and field2 ...) (or field3...)
sort field [ascending|descending|asc|desc] (ascending is implied if not provided)
```
list 、table 、task 分别对应 dataview 的列表、表格以及任务内容;
from 指的是从哪里获取数据,可以从 #tag 标签获取、 从 folder 文件夹获取、从 [[link]] 链接获取,或者从链接了 link 的文件获取 outgoing([[link]]) ;
where 指的是上边获取的数据,要符合怎样的规则,也就是筛选;
sort 指的是排序,默认升序。
上边说完表格,现在来简单说一下列表,列表的生成更简单,只需要两行
```dataview
list from #game/moba or #game/crpg
```
然后就可以基于这两个标签来生成对应的列表了,如下:
其它与表格的设置类似,也可以排序以及筛选。
任务是 Dataview 单独支持的功能,可以让你从这些笔记中抽取任务且形成列表生成出来,如下:
```dataview
task from #projects/active
```
然后就可以生成:
基于以上的代码,你其实就已经可以实现下图的效果了:
而如果你想要实现类似的效果,你只需要在你的 Markdown 文件中设置对应的数据,例如上图中的:
#knowledgeTopic //用于获取数据的标签
Status:: Active
Importance::
Goals::
Pillars::
Habits and Routines::
Courses and Training::
然后使用下列的 Dataview 检索式进行索引:
```dataview
table importance, file.mtime as Last_Modified__, pillars as Pillars__________________, habitsRoutines as Habits_and_Routines___, courses-and-training
from #knowledgeTopic
sort file.mtime desc
```
当然你也可以用中文来添加:
#knowledgeTopic //用于获取数据的标签
状态:: 活跃中
重要性::
目标::
基于::
习惯::
课程::
然后用类似的检索式进行检索。不过为了避免出现奇奇怪怪的问题,建议还是使用英文字符进行标注,对应的数值可以采用中文,但是参数尽量采用英文。
当然,你也可以仅在 YAML 中添加,注意 Dataview 支持行内参数获取,例如 参数:: 数值 。如果你喜欢一个表格空内可以显示多个参数,那么如果你在使用行内参数,你需要用逗号分隔开来,例如 重要性:: 非常重要, 很重要, 挺重要 ;要注意的是,需要用英文的逗号。以上你已经可以实现一个很不错的动态索引页面了。接下来我们将开始高级用法的简述,对于不想折腾的人可以直接跳到下一个章节的末尾自取对应的代码进行运用。
Dataview 其实有两种可以称得上高级的用法,一种是采用行内代码块,也就是 `` 内填入对应的运算代码,一种是采用 Dataviewjs 来实现高级运算逻辑(以及高级显示逻辑)。
Dataview 目前支持的行内代码块主要是对于日期以及本页信息的显示,例如:
你可以用行内代码块计算出任意的时间差,如下:
`=(date(2021-12-31)-date(today))`
你就可以获得相关的时间差值,如下:
例如标签:
进入渲染模式后就会自动在对应的位置上显示你的当前文件的所有标签了。
以上就是基于行内代码块实现的高级用法,接下来开始介绍基于 DataviewJS 的高级用法。
正如它后边附带的 JS 所言,DataviewJS 在扩展了本身的函数能力的基础上,获得了所有 API 相关的操作权限以及几乎完全的 Javascript 能力。接下来先介绍 DataviewJS 已经封装好的几个主要显示函数(目前仅能通过这些函数来显示对应的参数)。
注意,DataviewJS 代码块用 dataviewjs 而不是 dataview
dv.pages(source)根据标签或者文件夹返回页面参数,代码参考如下:
```dataviewjs
dv.pages("#books") //返回所有带有标签 books 的页面
dv.pages('"folder"') //返回所有在 folder 文件夹的页面
dv.pages("#yes or -#no") //返回所有带有标签 yes 或者没有标签 no 的页面
dv.pages("") //返回所有页面
```
dv.pagePaths(source)和上边类似,但是这个会返回文件路径作为参数
```dataviewjs
dv.pagePaths("#books") //返回所有带有标签 books 的页面路径
dv.pagePaths('"folder"') //返回所有在 folder 文件夹的页面路径
dv.pagePaths("#yes or -#no") //返回所有带有标签 yes 或者没有标签 no 的页面路径
```
dv.page(path)用于返回单个页面作为参数
```dataviewjs
dv.page("Index") //返回名称为 Index 的页面
dv.page("books/The Raisin.md") //返回所有在 books 文件夹下的 The Raisin 文件的页面
```
dv.header(level, text)用于渲染特定的文本为标题,其中 level 为层级,text 为文本。
dv.paragraph(text)用于渲染为段落,你可以理解成普通文本。
```dataviewjs
dv.list([1, 2, 3]) //生成一个1,2,3的列表
dv.list(dv.pages().file.name) //生成所有文件的文件名列表
dv.list(dv.pages().file.link) //生成所有文件的文件链接列表,即双链
dv.list(dv.pages("").file.tags.distinct()) //生成所有标签的列表
dv.list(dv.pages("#book").where(p => p.rating > 7)) //生成在标签 book 内所有评分大于 7 的书本列表
```
默认为 dv.taskList(tasks, groupByFile) 其中任务需要用上文获取 pages 后,再用 pages.file.tasks 来获取,例如 dv.pages("#project").file.tasks。 而当 groupByFile 为 True 或者 1 的时候,会按照文件名分组。
```dataviewjs
// 从所有带有标签 project 的页面中获取所有的任务生成列表
dv.taskList(dv.pages("#project").file.tasks)
// 从所有带有标签 project 的页面中获取所有的未完成任务生成列表
dv.taskList(dv.pages("#project").file.tasks
.where(t => !t.completed))
// 从所有带有标签 project 的页面中获取所有的带有特定字符的任务生成列表
// 可以设置为特定日期
dv.taskList(dv.pages("#project").file.tasks
.where(t => t.text.includes("#tag")))
// 将所有未完成且带有字符串的任务列出
dv.taskList(
dv.pages("").file.tasks
.where(t => t.text.includes("#todo") && !t.completed),1)
```
默认为 dv.table(headers, elements) ,提供表头和元素内容即可生成对应的表格。
例如:
```dataviewjs
// 根据标签 book 对应的页面的 YAML 生成一个简单的表格,其中 map 为对应的内容所对应的表头,按顺序填入即可。
// b 可以是任意值,只是代表当前传入的文件为 b
dv.table(["File", "Genre", "Time Read", "Rating"], dv.pages("#book")
.sort(b => b.rating)
.map(b => [b.file.link, b.genre, b["time-read"], b.rating]))
```
看完以上的内容以后,如果你对表格或者获取的数据操作感兴趣的话,那你应该去查看官方提供的数据操作 API ,请查阅:Data Arrays | Dataview
以下的方案目前已经经过一部分人的使用,大呼已经满足,而如果你还有其它的需求的话,可以去请教对 Javascript 熟悉的人,或者去官方论坛请教。此处感谢提供脚本的 @tzhou 以及在官方社区的 @shabegom
```dataviewjs
// 生成所有的标签且形成列表
dv.list(dv.pages("").file.tags.distinct())
```
```dataviewjs
// 生成所有的标签且以 | 分割,修改时只需要修改 join(" | ") 里面的内容。
dv.paragraph(
dv.pages("").file.tags.distinct().map(t => {return `[${t}](${t})`}).array().join(" | ")
)
```
```dataviewjs
// 基于文件夹聚类所有的标签。
for (let group of dv.pages("").filter(p => p.file.folder != "").groupBy(p => p.file.folder.split("/")[0])) {
dv.paragraph(`## ${group.key}`);
dv.paragraph(
dv.pages(`"${group.key}"`).file.tags.distinct().map(t => {return `[${t}](${t})`}).array().sort().join(" | "));
}
```
效果如下:
```dataviewjs
//使用时修改关键词即可
const term = "关键词"
const files = app.vault.getMarkdownFiles()
const arr = files.map(async ( file) => {
const content = await app.vault.cachedRead(file)
const lines = content.split("\n").filter(line => line.contains(term))
return lines
})
Promise.all(arr).then(values =>
dv.list(values.flat()))
```
如下:
```dataviewjs
// 修改标签
const tag = "#active"
// 获取 Obsidian 中的所有 Markdown 文件
const files = app.vault.getMarkdownFiles()
// 将带有标签的文件筛选出来
const taggedFiles = new Set(files.reduce((acc, file) => {
const tags = app.metadataCache.getFileCache(file).tags
if (tags) {
let filtered = tags.filter(t => t.tag === tag)
if (filtered) {
return [...acc, file]
}
}
return acc
}, []))
// 创建带有标签的行数组
const arr = Array.from(taggedFiles).map(async(file) => {
const content = await app.vault.cachedRead(file)
const lines = await content.split("\n").filter(line => line.includes(tag))
return [file.name, lines]
})
// 生成表格
Promise.all(arr).then(values => {
dv.table(["file", "lines"], values)
})
```
```dataviewjs
// 获取 Obsidian 中的所有 Markdown 文件
const files = app.vault.getMarkdownFiles()
// 将带有标签的文件以及行筛选出来
let arr = files.map(async(file) => {
const content = await app.vault.cachedRead(file)
//turn all the content into an array
let lines = await content.split("\n").filter(line => line.includes("#tag"))
return ["[["+file.name.split(".")[0]+"]]", lines]
})
// 生成表格,如果要将当前的文件排除的话,请修改其中的排除文件
Promise.all(arr).then(values => {
console.log(values)
//filter out files without "Happy" and the note with the dataview script
const exists = values.filter(value => value[1][0] && value[0] != "[[排除文件]]")
dv.table(["file", "lines"], exists)
})
```
如下:
输出所有带有标签 todo 以及未完成的任务
```dataviewjs
// 修改其中的标签 todo
dv.taskList(
dv.pages("").file.tasks
.where(t => t.text.includes("#todo") && !t.completed),1)
```
输出所有带有标签 todo 以及未完成的任务,且不包含当前文件
```dataviewjs
// 修改其中的标签 todo 以及修改 LOLOLO
dv.taskList(
dv.pages("").where(t => { return t.file.name != "LOLOLO" }).file.tasks
.where(t => t.text.includes("#todo") && !t.completed),1)
```
```dataviewjs
// 修改其中的时间,可以输出当前离倒计时的时间差。
const setTime = new Date("2021/8/15 08:00:00");
const nowTime = new Date();
const restSec = setTime.getTime() - nowTime.getTime();
const day = parseInt(restSec / (60*60*24*1000));
const str = day + "天"
dv.paragraph(str);
```
如下:
```dataviewjs
// 只要在任务后边加上时间(格式为 2020-01-01 ,就会在显示所有的任务的同时对应生成对应的倒计时之差
dv.paragraph(
dv.pages("").file.tasks.array().map(t => {
const reg = /\d{4}\-\d{2}\-\d{2}/;
var d = t.text.match(reg);
if (d != null) {
var date = Date.parse(d);
return `- ${t.text} -- ${Math.round((date - Date.now()) / 86400000)}天`
};
return `- ${t.text}`;
}).join("\n")
)
```
如果你同时安装了 Templater 以及 Dataview 那么你可以用上边的 Templater 脚本快速输出你想要查询的字符串,且生成表格,对应的视频操作如下:
对应的代码为,将代码放在模板文件中,用 Templater 调用这个模板即可。
const files = app.vault.getMarkdownFiles()
const prompt = "<% tp.system.prompt("Query for") %>"
const fileObject = files.map(async (file) => {
const fileLink = "[["+file.name.split(".")[0]+"]]"
const content = await app.vault.cachedRead(file)
return {fileLink, content}
})
Promise.all(fileObject).then(files => {
let values = new Set(files.reduce((acc, file) => {
const lines = file.content.split("\n").filter(line => line.match(new RegExp(prompt, "i")))
if (lines[0] && !file.fileLink.includes("<% tp.file.title %>")) {
if (acc[0]) {
return [...acc, [file.fileLink, lines.join("\n")]]
} else {
return [[file.fileLink, lines.join("\n")]]
}
}
return acc
}, []))
dv.header(1, prompt)
dv.table(["file", "lines"], Array.from(values))
})
如果说你想要追求动态展示的极致,那么 Dataview 是你的永远好朋友,但是它目前还没有将易用性提高到极限,而根据它未来的 Roadmap 来看,还会支持 Timeline、卡片视图等,也许在未来开发者会进一步加强 DataviewJs 的易用性,这样也许可以让更多不想写代码的人受益。不过对于是小白的用户来说,也可以考虑学会一点 JS, 这种学习过程也可以在 Obsidian 中即时得到反馈,而且说不定将来也可以基于 Templater 写脚本。
谢谢阅读,下次再见。
https://zhuanlan.zhihu.com/p/373623264
原文请移步我的博客:TCMalloc 解密
本文首先简单介绍 TCMalloc 及其使用方法,然后解释 TCMalloc 替代系统的内存分配函数的原理,然后从宏观上讨论其内存分配的策略,在此之后再深入讨论实现细节。
有几点需要说明:
TCMalloc 全称 Thread-Caching Malloc,即线程缓存的 malloc,实现了高效的多线程内存管理,用于替代系统的内存分配相关的函数(malloc、free,new,new[]等)。
TCMalloc 是 gperftools 的一部分,除 TCMalloc 外,gperftools 还包括 heap-checker、heap-profiler 和 cpu-profiler。本文只讨论 gperftools 的 TCMalloc 部分。
git 仓库:https://github.com/gperftools/gperftools.git
官方介绍:https://gperftools.github.io/gperftools/TCMalloc.html(里面有些内容已经过时了)
以下是比较常规的安装步骤,详细可参考 gperftools 中的INSTALL。
bash # apt install autoconf automake libtool
bash $ ./autogen.sh
bash $ ./configure
bash $ make
bash # make install
默认安装在/usr/local/下的相关路径(bin、lib、share),可在 configure 时以--prefix=PATH指定其他路径。
在 64 位 Linux 环境下,gperftools 使用 glibc 内置的 stack-unwinder 可能会引发死锁,因此官方推荐在配置和安装 gperftools 之前,先安装libunwind-0.99-beta,最好就用这个版本,版本太新或太旧都可能会有问题。
即便使用 libunwind,在 64 位系统上还是会有问题,但只影响 heap-checker、heap-profiler 和 cpu-profiler,TCMalloc 不受影响,因此不再赘述,感兴趣的读者可参阅 gperftools 的INSTALL。
如果不希望安装 libunwind,也可以用 gperftools 内置的 stack unwinder,但需要应用程序、TCMalloc 库、系统库(比如 libc)在编译时开启帧指针(frame pointer)选项。
在 x86-64 下,编译时开启帧指针选项并不是默认行为。因此需要指定-fno-omit-frame-pointer编译所有应用程序,然后在 configure 时通过--enable-frame-pointers选项使用内置的 gperftools stack unwinder。
安装之后,通过-ltcmalloc或-ltcmalloc_minimal将 TCMalloc 链接到应用程序即可。
#include <stdlib.h>
int main( int argc, char *argv[] )
{
malloc(1);
}
$ g++ -O0 -g -ltcmalloc test.cc && gdb a.out
(gdb) b test.cc:5
Breakpoint 1 at 0x7af: file test.cc, line 5.
(gdb) r
Starting program: /home/wanglong/test/https://wallenwang.com/tcmalloc/a.out
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
Breakpoint 1, main (argc=1, argv=0x7fffffffddd8) at test.cc:5
5 malloc(1);
(gdb) s
tc_malloc (size=1) at src/tcmalloc.cc:1892
1892 return malloc_fast_path<tcmalloc::malloc_oom>(size);
(gdb)
通过 gdb 断点可以看到对malloc()的调用已经替换为 TCMalloc 的实现。
gperftools 的README中说静态库应该使用libtcmalloc_and_profiler.a库而不是libprofiler.a和 libtcmalloc.a,但简单测试后者也是 OK 的,而且在实际项目中也是用的后者,不知道是不是文档太过老旧了。
$ g++ -O0 -g -pthread test.cc /usr/local/lib/libtcmalloc_and_profiler.a
如果使用了 libunwind,需要指定-Wl,--eh-frame-hdr选项,以确保 libunwind 可以找到编译器生成的信息来进行栈回溯。
eh-frame(exception handling frame)参考资料:
为什么指定-ltcmalloc或者与libtcmalloc_and_profiler.a连接之后,对 malloc、free、new、delete 等的调用就由默认的 libc 中的函数调用变为 TCMalloc 中相应的函数调用了呢?答案在libc_override.h中,下面只讨论常见的两种情况:使用了 glibc,或者使用了 GCC 编译器。其余情况可自行查看相应的 libc_override 头文件。
在 glibc 中,内存分配相关的函数都是弱符号(weak symbol),因此 TCMalloc 只需要定义自己的函数将其覆盖即可,以 malloc 和 free 为例:
libc_override_redefine.h
extern "C" {
void* malloc(size_t s) { return tc_malloc(s); }
void free(void* p) { tc_free(p); }
} // extern "C"
可以看到,TCMalloc 将malloc()和free()分别定义为对tc_malloc()和tc_free()的调用,并在tc_malloc()和tc_free()中实现具体的内存分配和回收逻辑。
new 和 delete 也类似:
void* operator new(size_t size) { return tc_new(size); }
void operator delete(void* p) CPP_NOTHROW { tc_delete(p); }
如果使用了 GCC 编译器,则使用其支持的函数属性:alias。
libc_override_gcc_and_weak.h:
#define ALIAS(tc_fn) __attribute__ ((alias (#tc_fn), used))
extern "C" {
void* malloc(size_t size) __THROW ALIAS(tc_malloc);
void free(void* ptr) __THROW ALIAS(tc_free);
} // extern "C"
将宏展开,__attribute__ ((alias ("tc_malloc"), used))表明 tc_malloc 是 malloc 的别名。
具体可参阅 GCC 相关文档:
alias ("target") The alias attribute causes the declaration to be emitted as an alias for another symbol, which must be specified. For instance,
void __f () { /* Do something. */;}void f () __attribute__ ((weak, alias ("__f"))); definesfto be a weak alias for__f. In C++, the mangled name for the target must be used. It is an error if__fis not defined in the same translation unit. Not all target machines support this attribute.
used This attribute, attached to a function, means that code must be emitted for the function even if it appears that the function is not referenced. This is useful, for example, when the function is referenced only in inline assembly. When applied to a member function of a C++ class template, the attribute also means that the function will be instantiated if the class itself is instantiated.
TCMalloc 定义了一个类TCMallocGuard,并在文件 tcmalloc.cc 中定义了该类型的静态变量module_enter_exit_hook,在其构造函数中执行 TCMalloc 的初始化逻辑,以确保 TCMalloc 在main()函数之前完成初始化,防止在初始化之前就有多个线程。
static TCMallocGuard module_enter_exit_hook;
如果需要确保 TCMalloc 在某些全局构造函数运行之前就初始化完成,则需要在文件顶部创建一个静态 TCMallocGuard 实例。
TCMallocGuard 的构造函数实现:
static int tcmallocguard_refcount = 0; // no lock needed: runs before main()
TCMallocGuard::TCMallocGuard() {
if (tcmallocguard_refcount++ == 0) {
ReplaceSystemAlloc(); // defined in libc_override_*.h
tc_free(tc_malloc(1));
ThreadCache::InitTSD();
tc_free(tc_malloc(1));
// Either we, or debugallocation.cc, or valgrind will control memory
// management. We register our extension if we're the winner.
#ifdef TCMALLOC_USING_DEBUGALLOCATION
// Let debugallocation register its extension.
#else
if (RunningOnValgrind()) {
// Let Valgrind uses its own malloc (so don't register our extension).
} else {
MallocExtension::Register(new TCMallocImplementation);
}
#endif
}
}
可以看到,TCMalloc 初始化的方式是调用tc_malloc()申请一字节内存并随后调用tc_free()将其释放。至于为什么在 InitTSD 前后各申请释放一次,不太清楚,猜测是为了测试在 TSD(Thread Specific Data,详见后文)初始化之前也能正常工作。
那么 TCMalloc 在初始化时都执行了哪些操作呢?这里先简单列一下,后续讨论 TCMalloc 的实现细节时再逐一详细讨论:
总之一句话,创建 TCMalloc 自身的一些元数据,比如划分小对象的大小等等。
TCMalloc 的官方介绍中将内存分配称为_Object Allocation_,本文也沿用这种叫法,并将 object 翻译为对象,可以将其理解为具有一定大小的内存。
按照所分配内存的大小,TCMalloc 将内存分配分为三类:
简要介绍几个概念,Page,Span,PageHeap:
与操作系统管理内存的方式类似,TCMalloc 将整个虚拟内存空间划分为 n 个同等大小的Page,每个 page 默认 8KB。又将连续的 n 个 page 称为一个Span。
TCMalloc 定义了PageHeap类来处理向 OS 申请内存相关的操作,并提供了一层缓存。可以认为,PageHeap 就是整个可供应用程序动态分配的内存的抽象。
PageHeap 以 span 为单位向系统申请内存,申请到的 span 可能只有一个 page,也可能包含 n 个 page。可能会被划分为一系列的小对象,供小对象分配使用,也可能当做一整块当做中对象或大对象分配。
对于 256KB 以内的小对象分配,TCMalloc 按大小划分了 85 个类别(官方介绍中说是 88 个左右,但我个人实际测试是 85 个,不包括 0 字节大小),称为Size Class,每个 size class 都对应一个大小,比如 8 字节,16 字节,32 字节。应用程序申请内存时,TCMalloc 会首先将所申请的内存大小向上取整到 size class 的大小,比如 18 字节之间的内存申请都会分配 8 字节,916 字节之间都会分配 16 字节,以此类推。因此这里会产生内部碎片。TCMalloc 将这里的内部碎片控制在 12.5% 以内,具体的做法在讨论 size class 的实现细节时再详细分析。
对于每个线程,TCMalloc 都为其保存了一份单独的缓存,称之为ThreadCache,这也是 TCMalloc 名字的由来(Thread-Caching Malloc)。每个 ThreadCache 中对于每个 size class 都有一个单独的FreeList,缓存了 n 个还未被应用程序使用的空闲对象。
小对象的分配直接从 ThreadCache 的 FreeList 中返回一个空闲对象,相应的,小对象的回收也是将其重新放回 ThreadCache 中对应的 FreeList 中。
由于每线程一个 ThreadCache,因此从 ThreadCache 中取用或回收内存是不需要加锁的,速度很快。
为了方便统计数据,各线程的 ThreadCache 连接成一个双向链表。ThreadCache 的结构示大致如下:
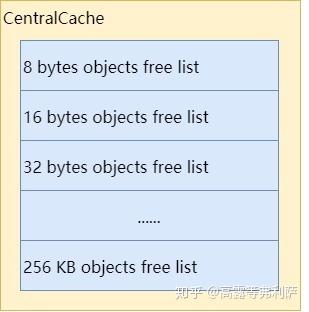
那么 ThreadCache 中的空闲对象从何而来呢?答案是CentralCache——一个所有线程公用的缓存。
与 ThreadCache 类似,CentralCache 中对于每个 size class 也都有一个单独的链表来缓存空闲对象,称之为CentralFreeList,供各线程的 ThreadCache 从中取用空闲对象。
由于是所有线程公用的,因此从 CentralCache 中取用或回收对象,是需要加锁的。为了平摊锁操作的开销,ThreadCache 一般从 CentralCache 中一次性取用或回收多个空闲对象。
CentralCache 在 TCMalloc 中并不是一个类,只是一个逻辑上的概念,其本质是CentralFreeList类型的数组。后文会详细讨论 CentralCache 的内部结构,现在暂且认为 CentralCache 的简化结构如下:
CentralCache 中的空闲对象又是从何而来呢?答案是之前提到的PageHeap——TCMalloc 对可动态分配的内存的抽象。
当 CentralCache 中的空闲对象不够用时,CentralCache 会向 PageHeap 申请一块内存(可能来自 PageHeap 的缓存,也可能向系统申请新的内存),并将其拆分成一系列空闲对象,添加到对应 size class 的 CentralFreeList 中。
PageHeap 内部根据内存块(span)的大小采取了两种不同的缓存策略。128 个 page 以内的 span,每个大小都用一个链表来缓存,超过 128 个 page 的 span,存储于一个有序 set(std::set)。讨论 TCMalloc 的实现细节时再具体分析,现在可以认为 PageHeap 的简化结构如下:
上面说的都是内存分配,内存回收的情况是怎样的?
应用程序调用 free() 或 delete 一个小对象时,仅仅是将其插入到 ThreadCache 中其 size class 对应的 FreeList 中而已,不需要加锁,因此速度也是非常快的。
只有当满足一定的条件时,ThreadCache 中的空闲对象才会重新放回 CentralCache 中,以供其他线程取用。同样的,当满足一定条件时,CentralCache 中的空闲对象也会还给 PageHeap,PageHeap 再还给系统。
内存在这些组件之间的移动会在后文详细讨论,现在先忽略这些细节。
总结一下,小对象分配流程大致如下:
将要分配的内存大小映射到对应的 size class。
查看 ThreadCache 中该 size class 对应的 FreeList。
如果 FreeList 非空,则移除 FreeList 的第一个空闲对象并将其返回,分配结束。
如果 FreeList 是空的:
从 CentralCache 中 size class 对应的 CentralFreeList 获取一堆空闲对象。
如果 CentralFreeList 也是空的,则:
向 PageHeap 申请一个 span。
拆分成 size class 对应大小的空闲对象,放入 CentralFreeList 中。
将这堆对象放置到 ThreadCache 中 size class 对应的 FreeList 中(第一个对象除外)。
返回从 CentralCache 获取的第一个对象,分配结束。
超过 256KB 但不超过 1MB(128 个 page)的内存分配被认为是中对象分配,采取了与小对象不同的分配策略。
首先,TCMalloc 会将应用程序所要申请的内存大小向上取整到整数个 page(因此,这里会产生 1B~8KB 的内部碎片)。之后的操作表面上非常简单,向 PageHeap 申请一个指定 page 数量的 span 并返回其起始地址即可:
Span* span = Static::pageheap()->New(num_pages);
result = (PREDICT_FALSE(span == NULL) ? NULL : SpanToMallocResult(span));
return result;
问题在于,PageHeap 是如何管理这些 span 的?即PageHeap::New()是如何实现的。
前文说到,PageHeap 提供了一层缓存,因此PageHeap::New()并非每次都向系统申请内存,也可能直接从缓存中分配。
对 128 个 page 以内的 span 和超过 128 个 page 的 span,PageHeap 采取的缓存策略不一样。为了描述方便,以下将 128 个 page 以内的 span 称为小 span,大于 128 个 page 的 span 称为大 span。
先来看小 span 是如何管理的,大 span 的管理放在大对象分配一节介绍。
PageHeap 中有 128 个小 span 的链表,分别对应 1~128 个 page 的 span:
假设要分配一块内存,其大小经过向上取整之后对应 k 个 page,因此需要从 PageHeap 取一个大小为 k
个 page 的 span,过程如下:
超过 1MB(128 个 page)的内存分配被认为是大对象分配,与中对象分配类似,也是先将所要分配的内存大小向上取整到整数个 page,假设是 k 个 page,然后向 PageHeap 申请一个 k 个 page 大小的 span。
对于中对象的分配,如果上述的 span 链表无法满足,也会被当做是大对象来处理。也就是说,TCMalloc 在源码层面其实并没有区分中对象和大对象,只是对于不同大小的 span 的缓存方式不一样罢了。
大对象分配用到的 span 都是超过 128 个 page 的 span,其缓存方式不是链表,而是一个按 span 大小排序的有序 set(std::set),以便按大小进行搜索。
假设要分配一块超过 1MB 的内存,其大小经过向上取整之后对应 k 个 page(k>128),或者是要分配一块 1MB 以内的内存,但无法由中对象分配逻辑来满足,此时 k <= 128。不管哪种情况,都是要从 PageHeap 的 span set 中取一个大小为 k 个 page 的 span,其过程如下:
以上讨论忽略了很多实现上的细节,比如 PageHeap 对 span 的管理还区分了 normal 状态的 span 和 returned 状态的 span,接下来会详细分析这些细节。
在此之前,画张图概括下 TCMalloc 的管理内存的策略:
可以看到,不超过 256KB 的小对象分配,在应用程序和内存之间其实有三层缓存:PageHeap、CentralCache、ThreadCache。而中对象和大对象分配,则只有 PageHeap 一层缓存。
https://zhuanlan.zhihu.com/p/51432385
https://zhuanlan.zhihu.com/p/51432385
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.