📖 这个仓库主要是自己正在学习的东西的汇总 👏👏👏
一些读书笔记:pencil2:
正在学习的课程的总结和课后习题 🎒
The-Missing-Semester-of-Your-CS-Education
主要有几个主题 具体文章可以点进去看:books:
学习的总结和博客:book:
📖 这个仓库主要是自己正在学习的东西的汇总 👏👏👏
一些读书笔记:pencil2:
正在学习的课程的总结和课后习题 🎒
The-Missing-Semester-of-Your-CS-Education
主要有几个主题 具体文章可以点进去看:books:



多种编程语言打卡剑指offer 👏
| 题目 | 链接 | 分类 | 备注 |
|---|---|---|---|
| 队列的最大值 | 队列的最大值 |
class Solution {
public int duplicateInArray(int[] nums) {
int n = nums.length;
if(n == 0){
return -1;
}
for(int i = 0; i < n; i ++){
if(nums[i] < 0 || nums[i] > n - 1)
return -1;
}
for(int i = 0; i < n; i ++){
while(nums[i] != i){
if(nums[i] == nums[nums[i]]){
return nums[i];
}
int temp = nums[i];
nums[i] = nums[temp];
nums[temp] = temp;
}
}
return -1;
}
}class Solution {
public:
int duplicateInArray(vector<int>& nums) {
int n = nums.size();
if(n == 0) return -1;
for(int i = 0; i < n; i ++){
if(nums[i] < 0 || nums[i] > n - 1){
return -1;
}
}
for(int i = 0; i < n; i ++){
while(nums[i] != i){
if(nums[i] == nums[nums[i]]){
return nums[i];
}
swap(nums[i], nums[nums[i]]);
}
}
return -1;
}
};class Solution(object):
def duplicateInArray(self, nums):
"""
:type nums: List[int]
:rtype int
"""
if not nums:
return -1
length = len(nums)
for n in nums:
if n < 0 or n > length - 1:
return -1
for i in range(length):
while nums[i] != i:
if nums[i] == nums[nums[i]]:
return nums[i]
temp = nums[i]
nums[i], nums[temp] = nums[temp], nums[i]
return -1class Solution {
public:
int duplicateInArray(vector<int>& nums) {
int l = 1;
int r = nums.size() - 1;
while(l < r){
int mid = l + r >> 1;
int s = 0;
for(auto x : nums) s += (x >= l && x <= mid ? 1 : 0);
if(s > mid -l + 1){
r = mid;
} else {
l = mid + 1;
}
}
return r;
}
};class Solution {
public int duplicateInArray(int[] nums) {
int l = 1;
int r = nums.length - 1;
while(l < r){
int mid = l + r >> 1;
int s = 0;
for(int x : nums) s += x >= l && x <= mid ? 1 : 0;
if(s > mid - l + 1){
r = mid;
} else {
l = mid + 1;
}
}
return l;
}
}class Solution {
public boolean searchArray(int[][] array, int target) {
int maxRow = array.length;
if(array == null || maxRow == 0){
return false;
}
int maxCol = array[0].length;
int row = 0;
int col = array[0].length - 1;
while(row >= 0 && row < maxRow && col >= 0 && col < maxCol){
if(array[row][col] == target)
return true;
else if(array[row][col] > target)
col--;
else if(array[row][col] < target)
row++;
}
return false;
}
}class Solution {
public:
bool searchArray(vector<vector<int>> array, int target) {
int rows = array.size();
if(rows == 0) return false;
int cols = array[0].size();
int row = 0;
int col = cols - 1;
while(row < rows && col >= 0){
if(array[row][col] > target){
col --;
} else if(array[row][col] < target){
row ++;
} else {
return true;
}
}
return false;
}
};
public String replaceSpaces(StringBuffer str) {
// 先计算替换后的字符串的长度
int bef = str.length();
for(int i = 0; i < bef; i++){
if(str.charAt(i) == ' '){
str.append(" ");
}
}
int aft = str.length();
int i = bef - 1;
int j = aft - 1;
// 从后往前 对于每个空格进行替换
while(j >= 0){
char ch = str.charAt(i --);
if(ch != ' '){
str.setCharAt(j --, ch);
} else {
str.setCharAt(j --, '0');
str.setCharAt(j --, '2');
str.setCharAt(j --, '%');
}
}
return str.toString();
}二叉树
// 从中序遍历得到左右子树的长度
// 从前序遍历得到根节点
private Map<Integer, Integer> map = new HashMap<>();
public TreeNode buildTree(int[] preorder, int[] inorder) {
// 将 下标 - 值 记录
for(int i = 0; i < inorder.length; i++){
map.put(inorder[i], i);
}
return build(preorder, 0, preorder.length - 1, 0);
}
public TreeNode build(int[] preorder, int prel, int prer, int inl){
// 边界
if(prel > prer)
return null;
// 根节点
int val = preorder[prel];
TreeNode root = new TreeNode(val);
// 中序遍历 inl - index 求出左树的长度
int index = map.get(val);
int len = index - inl;
// 左右递归 求出 left right
root.left = build(preorder, prel + 1, prel + len, inl);
root.right = build(preorder, prel + len + 1, prer, index + 1);
return root;
}```python
class Solution(object):
def buildTree(self, preorder, inorder):
map = {}
def build(preL, preR, inL):
if preL > preR:
return
# preorder root
# 根节点
val = preorder[preL]
root = TreeNode(val)
index = map.get(val)
length = index - inL
root.left = build(preL + 1, preL + length, inL)
root.right = build(preL + length + 1, preR, index + 1)
return root
for i in range(len(inorder)):
map[inorder[i]] = i
return build(0, len(preorder) - 1, 0)
```
```
public TreeNode inorderSuccessor(TreeNode p) {
// 特别判断一下
if(p == null)
return p;
// 如果右子树不为空 则结果一定是右树的最左子结点
if(p.right != null){
TreeNode q = p.right;
while(q != null){
p = q;
q = q.left;
}
return p;
} else {
// 如果右子树为空 则结果一定为其整个子树的父节点000
TreeNode par = p.father;
while(par != null && par.right == p){
p = par;
par = par.father;
}
return par;
}
}
class MyQueue {
Deque<Integer> in;
Deque<Integer> out;
/** Initialize your data structure here. */
public MyQueue() {
in = new ArrayDeque<>();
out = new ArrayDeque<>();
}
/** Push element x to the back of queue. */
public void push(int x) {
in.push(x);
}
// 假如out是空 则调用此函数填充in
public void clearIn(){
while(!in.isEmpty()){
out.push(in.pop());
}
}
/** Removes the element from in front of queue and returns that element. */
public int pop() {
if(out.isEmpty()){
clearIn();
}
return out.pop();
}
/** Get the front element. */
public int peek() {
if(out.isEmpty()){
clearIn();
}
return out.peek();
}
/** Returns whether the queue is empty. */
public boolean empty() {
return out.isEmpty() && in.isEmpty();
}
}class MyQueue(object):
def __init__(self):
"""
Initialize your data structure here.
"""
self.com = []
self.out = []
def push(self, x):
"""
Push element x to the back of queue.
:type x: int
:rtype: void
"""
self.com.append(x)
def pop(self):
"""
Removes the element from in front of queue and returns that element.
:rtype: int
"""
if not self.out:
while len(self.com):
self.out.append(self.com.pop())
return self.out.pop()
def peek(self):
"""
Get the front element.
:rtype: int
"""
if not self.out:
while len(self.com):
self.out.append(self.com.pop())
return self.out[len(self.out) - 1]
def empty(self):
"""
Returns whether the queue is empty.
:rtype: bool
"""
return len(self.com) == 0 and len(self.out) == 0;// a b (c)
public int Fibonacci(int n) {
int a = 0, b = 1, c = 0;
while(n -- > 0){
c = a + b;
a = b;
b = c;
}
return a;
}二分查找
public int findMin(int[] nums) {
int n = nums.length - 1;
if(n < 0) return -1;
// 去除nums[n] == nums[0] 的部分
while(n > 0 && nums[n] == nums[0]) n --;
if(nums[n] >= nums[0]) return nums[0];
int l = 0, r = n;
while(l < r){
int mid = l + r >> 1;
// 二分的性质选取的是 左边的都 >= nums[0] 右边的都 < nums[0]
if(nums[mid] >= nums[0]){
l = mid + 1;
} else {
r = mid;
}
}
return nums[r];
}dfs
class Solution {
public boolean hasPath(char[][] matrix, String str) {
int rows = matrix.length;
if(rows == 0) return false;
int cols = matrix[0].length;
for(int i = 0; i < rows; i ++)
for(int j = 0; j < cols; j ++){
if(matrix[i][j] == str.charAt(0)){
if(dfs(rows, cols, str, 0, matrix, i, j))
return true;
}
}
return false;
}
public boolean dfs(int rows, int cols, String str, int l, char[][] matrix, int row, int col){
if(l == str.length() - 1) return true;
char ch = matrix[row][col];
// 标记为走过
matrix[row][col] = '*';
int[] pathx = {0, 1, 0, -1};
int[] pathy = {1, 0, -1, 0};
for(int i = 0; i < 4; i++){
int x = row + pathx[i];
int y = col + pathy[i];
if(x >= 0 && x < rows && y >= 0 && y < cols && matrix[x][y] == str.charAt(l + 1)){
if(dfs(rows, cols, str, l + 1, matrix, x, y))
return true;
}
}
// 将原来的矩阵复位
matrix[row][col] = ch;
return false;
}
}dfs
class Solution {
// dfs 搜索 看能搜索多少个格子
private int rows;
private int cols;
private int threshold;
private boolean[][] reach;
private int num;
private int[][] path = {{0, 1}, {0, -1}, {1, 0}, {-1, 0}};
public int movingCount(int threshold, int rows, int cols)
{
this.rows = rows;
this.cols = cols;
if(rows <= 0 || cols <= 0) return 0;
this.threshold = threshold;
// 标记是否走过
reach = new boolean[rows][cols];
dfs(0, 0);
return num;
}
public void dfs(int row, int col){
num ++;
reach[row][col] = true;
for(int i = 0; i < 4; i ++){
int x = row + path[i][0];
int y = col + path[i][1];
if(x >= 0 && x < rows && y >=0 && y < cols && !reach[x][y] && get_sum(x, y) <= threshold){
dfs(x, y);
}
}
}
// 算出行坐标和列坐标的数位之和
public int get_sum(int a, int b){
return get_num(a) + get_num(b);
}
public int get_num(int a){
int sum = 0;
while(a > 0){
sum += a % 10;
a /= 10;
}
return sum;
}
} public void reOrderArray(int [] array) {
int l = -1, r = array.length;
if(r == 0) return;
// 其实就是快排的**
while(l < r){
do l ++; while(array[l] % 2 != 0);
do r --; while(array[r] % 2 == 0);
if(l < r){
int temp = array[l];
array[l] = array[r];
array[r] = temp;
}
}
} public List<Integer> printFromTopToBottom(TreeNode root) {
List<Integer> res = new LinkedList<>();
Queue<TreeNode> queue = new LinkedList<>();
if(root == null)
return res;
queue.add(root);
while(!queue.isEmpty()){
TreeNode tree = queue.poll();
res.add(tree.val);
if(tree.left != null) queue.add(tree.left);
if(tree.right != null) queue.add(tree.right);
}
return res;
} public List<List<Integer>> printFromTopToBottom(TreeNode root) {
Queue<TreeNode> queue = new LinkedList<>();
List<List<Integer>> res = new ArrayList<>();
if(root == null){
return res;
}
queue.add(root);
while(!queue.isEmpty()){
int size = queue.size();
List<Integer> l = new ArrayList<>();
while(size -- > 0){
TreeNode tree = queue.poll();
l.add(tree.val);
if(tree.left != null)
queue.add(tree.left);
if(tree.right != null)
queue.add(tree.right);
}
res.add(l);
}
return res;
}给定一个数组和窗口大小,求滑动窗口的最大值
可以用单调队列求解
所有元素只会进队一次,出队一次,所以时间负责度是O(N)
for(){
1. 如果超出滑动窗口范围,则弹出队头
if(队头 <= i - k)
队头弹出
2. 维护单增的队列
while(队尾元素 <= 当前元素)
队尾弹出
3. 把当前元素的下标放入队尾
}
class Solution {
public int[] maxInWindows(int[] nums, int k) {
int n = nums.length;
if(n == 0)
return new int[] {};
List<Integer> res = new ArrayList<>();
int[] q = new int[n];
int hh = 0;
int tt = -1;
for(int i = 0; i < n; i ++){
// 如果超出滑动窗口范围 则弹出队头
if(hh <= tt && q[hh] < i - k + 1){
hh ++;
}
// 如果当前元素 >= 队列头元素 则弹出
while(hh <= tt && nums[q[tt]] <= nums[i]){
tt --;
}
// 将元素如队尾
q[++ tt] = i;
// 每次打印队头
if(i >= k - 1){
res.add(nums[q[hh]]);
}
}
// ArrayList to []
return res.stream().mapToInt(i -> i).toArray();
}
}class Solution(object):
def maxInWindows(self, nums, k):
"""
:type nums: List[int]
:type k: int
:rtype: List[int]
"""
from collections import deque
res = []
q = deque()
if not nums:
return res
for i in range(len(nums)):
if q and q[0] <= i - k:
q.popleft()
while q and nums[q[-1]] <= nums[i]:
q.pop()
q.append(i)
if i >= k - 1:
res.append(nums[q[0]])
return resclass Solution {
public:
vector<int> maxInWindows(vector<int>& nums, int k) {
vector<int> res;
int n = nums.size();
int q[n], hh = 0, tt = -1;
if(n == 0){
return res;
}
for(int i = 0; i < n; i++){
if(hh <= tt && q[hh] <= i - k){
hh ++;
}
while(hh <= tt && nums[q[tt]] < nums[i]){
tt --;
}
q[++ tt] = i;
if(i >= k - 1){
res.push_back(nums[q[hh]]);
}
}
return res;
}
};var maxInWindows = function(nums, k) {
var res = [];
var q = [];
for(var i = 0; i < nums.length; i ++){
if(q.length !== 0 && q[0] <= i - k){
q.shift();
}
while(q.length !== 0 && nums[q[q.length - 1]] <= nums[i]){
q.pop();
}
q.push(i);
if(i >= k - 1){
res.push(nums[q[0]]);
}
}
return res;
};其实 redo 日志主要是为 MySQL 提供了异常情况下恢复数据的功能。MySQL 为了性能考虑,所以在更新一条数据时,只会将内存中的数据更新,并不会更新磁盘中的数据。但是如果此时 MySQL 出现了崩溃,那内存中的数据就丢了,这是不可接受的。但是每次都把更新刷新到磁盘又实在是太慢了,所以就出现了 redo 日志。redo 日志记录的是对数据库的修改,如果遇到系统崩溃,那直接按照 redo 日志,重新更新一下数据库就好了。
一条 redo 日志占用空间不是很大
顺序 IO 的性能是好于随机 IO 的(如果直接更新磁盘中的数据页,则是随机 IO)
这就是 crash-safe 能力
当一条更新数据库的语句执行之后,首先会写入 redo 日志,更新内存,之后在适当的时间才会将此次更新刷新到磁盘
https://time.geekbang.org/column/article/68633
https://juejin.im/book/6844733769996304392/section/6844733770063626253
职位: 后端开发实习生
时间:2020.8.11
结果: 一面通过
**2021 秋招面经汇总 ** : 📚
巴拉巴拉巴拉
合并两个有序数组
就是归并排序的一部分, 直接写算法模板
while(i <= mid && j <= r){
if(q[i] <= q[j]){
t[k ++] = q[i ++];
} else {
t[k ++] = q[j ++];
}
}
while(i <= mid){
t[k ++] = q[i ++];
}
while(j <= r){
t[k ++] = q[j ++];
}
for(int i = l, j = 0; i <= r; i ++, j ++){
q[i] = t[j];
}说一下归并排序的过程
1. 确定分界点 mid = (l + r) / 2 [l, mid] [mid + 1, r]
2. 递归排序左右
3. 合并两个有序数组
时间复杂度 O(NlogN) 因为会递归 logN 层 每层都是 O(N) 的
是稳定的
说一下快排的过程
1. 确定分界点 x
2. 调整区间 是得左边区间都小于等于 x 右边区间都大于等于 x
3. 递归排序左右区间
说一下快排的最坏情况是什么,快排稳定嘛
不稳定
时间复杂度 O(NlogN)
最坏情况是每次取的都是最大或者最小元素
哈希表由逻辑上一系列可以存放词条的单元组成,这些单元被称为桶,底层可以由数组实现。
散列函数是将关键码映射到数组地址空间的函数。
装填因子是非空桶的数目与桶单元总数的比值
哈希冲突: 1. 开散列 2. 闭散列
当装填因子达到了阈值之后,会扩容。redis 中是会开辟另一个两倍大小的哈希表,然后将原哈希表中第一个非空元素插入到第二个哈希表中,之后每次插入一个元素的时候,都将原表中的第一个非空元素插入到第二个表中。
协程是一种用户态的轻量级线程,协程的调度完全由用户控制。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。
就知道会让整个程序同一时间只有一个线程在运行
会导致 CPU 密集型的多线程程序并不能有很好的性能,但是对 IO 密集型的程序影响不大
不了解。。。
同步 所谓同步就是一个任务的完成需要依赖另外一个任务时,只有等待被依赖的任务完成后,依赖的任务才能算完成,这是一种可靠的任务序列
异步 所谓异步是不需要等待被依赖的任务完成,只是通知被依赖的任务要完成什么工作,依赖的任务也立即执行,只要自己完成了整个任务就算完成了,所以它是不可靠的任务序列
阻塞 阻塞调用是指调用结果返回之前,当前线程会被挂起,一直处于等待消息通知,不能够执行其他业务
同步阻塞 用户线程发起IO读/写操作之后,线程阻塞,直到可以开始处理数据;对CPU资源的利用率不够
同步非阻塞 发起IO请求之后可以立即返回,如果没有就绪的数据,需要不断地发起IO请求直到数据就绪;不断重复请求消耗了大量的CPU资源
异步 用户线程发出IO请求之后,继续执行,由内核进行数据的读取并放在用户指定的缓冲区内,在IO完成之后通知用户线程直接使用
res = [n for n in arr if n > 3]静态语言编译时就知道变量的类型,动态语言运行时才做类型检查。
动态语言因为编译前类型不确定,所以比较难维护。
SYN COOKIES 策略
操作系统会维护两个队列,一个时 SYN 队列, 一个时 ACCEPT 队列,当服务端收到一个 SYN 之后,会将其假如 SYN 队列,收到了 ACK 之后,会假如 ACCEPT 队列。如果 SYN 队列满,则将 SYNACK 的 seq 设置为 cookies , 之后如果收到了 ACK 并且 ack=cookies + 1, 则直接假如 ACCEPT队列
B+ 树
特点
优点
有三个业务场景,请设计一下数据库表结构,并给出 SQL 语句
| user 表 | ||
|---|---|---|
| id | ||
| name |
| follow 表 | ||
|---|---|---|
| id | ||
| followed_id | ||
| follower_id |
判断 用户 a 是否关注了用户 b
SELECT COUNT(*) FROM follow WHERE followed_id=(SELECT id FROM user WHERE name="a") AND follower_id=(SELECT id FROM user WHERE name="b")查询 用户 a 的粉丝数和关注数
关注数
SELECT COUNT(*) FROM follow INNER JOIN user ON follower_id=user.id WHERE user.name="a"粉丝数
SELECT COUNT(*) FROM follow INNER JOIN user ON followed_id=user.id WHERE user.name="a"查询 用户 a 的粉丝列表和关注列表
同 2
允许服务器只发送给客户端一部分资源
断点续传
多线程下载
视频播放器实时拖动
Accept-Range 表示服务器是否支持Range请求
Range 表示客户端发起的是Range请求
Content-Range字段表示返回的包体的范围,包体总大小
只请求开头的4个字节
root@:~# curl http://protocol.taohui.tech/app/letter.txt -H 'Range: bytes=0-3'
abcdroot先获得签名
root@iZ2zeeq1jai7e7ypku5kakZ:~# curl http://protocol.taohui.tech/app/letter.txt -I
HTTP/1.1 200 OK
Server: openresty/1.15.8.3
Date: Fri, 10 Jul 2020 11:40:46 GMT
Content-Type: text/plain; charset=utf-8
Content-Length: 27
Last-Modified: Sat, 27 Apr 2019 06:51:31 GMT
Connection: keep-alive
ETag: "5cc3fbf3-1b"
Set-Cookie: protocol=cookieA
Accept-Ranges: bytes请求时候附上签名
root@iZ2zeeq1jai7e7ypku5kakZ:~# curl http://protocol.taohui.tech/app/letter.txt -H 'Range: bytes=0-4' -H 'If-Match: "5cc3fbf3-1b"'
abcde签名不匹配的情况
root@iZ2zeeq1jai7e7ypku5kakZ:~# curl http://protocol.taohui.tech/app/letter.txt -H 'Range: bytes=0-4' -H 'If-Match: "5cc3fbf3-2b"' -I
HTTP/1.1 412 Precondition Failed
Server: openresty/1.15.8.3
Date: Fri, 10 Jul 2020 11:42:18 GMT
Content-Type: text/html; charset=utf-8
Content-Length: 179
Connection: keep-alive正常进行了范围查询
root@iZ2zeeq1jai7e7ypku5kakZ:~# curl http://protocol.taohui.tech/app/letter.txt -H 'Range: bytes=0-3' -I
HTTP/1.1 206 Partial Content
Server: openresty/1.15.8.3
Date: Fri, 10 Jul 2020 11:42:54 GMT
Content-Type: text/plain; charset=utf-8
Content-Length: 4
Last-Modified: Sat, 27 Apr 2019 06:51:31 GMT
Connection: keep-alive
ETag: "5cc3fbf3-1b"
Set-Cookie: protocol=cookieA
Content-Range: bytes 0-3/27查询的范围超出了包体范围
root@iZ2zeeq1jai7e7ypku5kakZ:~# curl http://protocol.taohui.tech/app/letter.txt -H 'Range: bytes=30-40' -I
HTTP/1.1 416 Requested Range Not Satisfiable
Server: openresty/1.15.8.3
Date: Fri, 10 Jul 2020 11:45:15 GMT
Content-Type: text/html; charset=utf-8
Content-Length: 203
Connection: keep-alive
Set-Cookie: protocol=cookieA
Content-Range: bytes */27📅打卡 🆕 Java版本
分析和题目::point_up_2::
import java.io.*;
import java.util.*;
class Main{
public static final int N = 310;
public static int n;
public static char[][] str = new char[N][N];
public static int[][] g = new int[N][N];
public static int[][] path = new int[][] {{0, 1}, {0, -1}, {1, 0}, {-1, 0}, {1, 1}, {1, -1}, {-1, -1}, {-1, 1}};
public static void dfs(int i, int j){
int c = g[i][j];
g[i][j] = -1;
if(c != 0){
return;
}
for(int k = 0; k < 8; k ++){
int nx = i + path[k][0];
int ny = j + path[k][1];
if(nx >= 0 && nx < n && ny >= 0 && ny < n && g[nx][ny] != -1){
dfs(nx, ny);
}
}
}
public static void main(String[] args) throws IOException{
int T = 0;
// Scanner in = new Scanner(new BufferedInputStream(System.in));
// T = in.nextInt();
AReader in = new AReader(System.in);
T = in.nextInt();
for(int I = 1; I <= T; I ++){
n = in.nextInt();
for(int i = 0; i < n; i ++){
String s = in.nextLine();
for(int j = 0; j < n; j ++){
// str[i][j] = in.nextChar();
str[i][j] = s.charAt(j);
}
}
// 先将每个点标记周围又多少个雷
for(int i = 0; i < n; i ++){
for(int j = 0; j < n; j ++){
if(str[i][j] == '*'){
g[i][j] = -1;
} else {
int cnt = 0;
for(int k = 0; k < 8; k ++){
int nx = i + path[k][0];
int ny = j + path[k][1];
if(nx >= 0 && nx < n && ny >= 0 && ny < n && str[nx][ny] == '*'){
cnt ++;
}
}
g[i][j] = cnt;
}
}
}
int res = 0;
//
for(int i = 0; i < n; i ++){
for(int j = 0; j < n; j ++){
if(g[i][j] == 0){
dfs(i, j);
res ++;
}
}
}
for(int i = 0; i < n; i ++){
for(int j = 0; j < n; j ++){
if(g[i][j] != -1){
res ++;
}
}
}
System.out.println("Case #" + I + ": " + res);
}
}
}
// 输入输出模板来自 https://www.rainng.com/java-acm-fast-io/
class AReader implements Closeable {
private BufferedReader reader;
private StringTokenizer tokenizer;
public AReader(InputStream inputStream) {
reader = new BufferedReader(new InputStreamReader(inputStream));
tokenizer = new StringTokenizer("");
}
private String innerNextLine() {
try {
return reader.readLine();
} catch (IOException ex) {
return null;
}
}
public boolean hasNext() {
while (!tokenizer.hasMoreTokens()) {
String nextLine = innerNextLine();
if (nextLine == null) {
return false;
}
tokenizer = new StringTokenizer(nextLine);
}
return true;
}
public String nextLine() {
tokenizer = new StringTokenizer("");
return innerNextLine();
}
public String next() {
hasNext();
return tokenizer.nextToken();
}
public int nextInt() {
return Integer.parseInt(next());
}
@Override
public void close() throws IOException {
reader.close();
}
}
class AWriter implements Closeable {
private BufferedWriter writer;
public AWriter(OutputStream outputStream) {
writer = new BufferedWriter(new OutputStreamWriter(outputStream));
}
public void print(Object object) throws IOException {
writer.write(object.toString());
}
public void println(Object object) throws IOException {
writer.write(object.toString());
writer.write("\n");
}
@Override
public void close() throws IOException {
writer.close();
}
}分享汇总 📚 文章汇总
HTTP 协议基本都是面试必考,除了一些经典面试题外,对于 HTTP 2.0 这种新兴事物 🌱 ,也应该有所了解
HTTP 1.1 的问题主要是性能低下
重复传输一些 HTTP 头部
因为 REST 架构要求无状态,每次 HTTP 请求之间都是独立的,所以每个 HTTP 请求都要带着巨大的头部
HTTP 1.1 的交互模式是请求应答模式,只能客户端给服务端发送请求,服务端应答。服务端是不能主动推送消息的。
二进制传输
例如一个数字 10000 如果使用 ASCII 编码需要 5 字节
标头压缩
标头压缩主要是通过 HPACK 算法对头部压缩
多路复用允许多次请求并发的使用同一连接进行,主要好处有:
HTTP 2.0 主要是性能的提升,大家可以通过这个 Demo 感受一下 Demo
我的其他文章 📚 文章汇总
本文的其他地址 GitHub
URL URI URN 都是为了解决 怎么找到网络中的资源? 怎么标识资源?这两个问题,才抽象出来的概念,总的来说 URI 是 URL URN的超集
URL
RFC1739 定义, Uniform Resource Locator 表示资源的位置
URN
RFC2141 定义,Uniform Resource Name 为资源提供的持久的位置无关的标识方式。
URI
URL URN 的超集,用来区分资源
Uniform Resource Identifier 统一资源标识符
格式:URI = scheme ":" hier-part ["?" query][#fragment]
scheme 协议名: http https
hier-part = "//" userinfo host port
query 查询参数
fragment 段落名
https://github.com/wangzitiansky/Learning#%E5%8D%9A%E5%AE%A2
这个 URI 中
scheme = https
host = github.com
path = /wangzitiansky/Learning
fragment = #%E5%8D%9A%E5%AE%A2
原文地址(更好的阅读体验): 📖
保证一个类只有一个实例,并提供一个该实例的全局访问点
类的定义
class Singleton{
private:
Singleton();
Singleton(const Singleton& other);
public:
static Singleton* getInstance();
static Singleton* m_instance;
};
Singleton* Singleton::m_instance=nullptr;线程非安全版本
Singleton* Singleton::getInstance() {
if (m_instance == nullptr) {
m_instance = new Singleton();
}
return m_instance;
}线程安全 但是锁代价过高的版本
//线程安全版本,但锁的代价过高
Singleton* Singleton::getInstance() {
Lock lock;
if (m_instance == nullptr) {
m_instance = new Singleton();
}
return m_instance;
}双检查锁,由于内存读写指令重排序不安全
在 m_instance = new Singleton()中,指令流分为三部分
1.分配内存
2.调用构造器,将内存初始化
3.将内存地址赋值给 m_instance
但是在 CPU 级别,可能有指令重排序,可能顺序为
1.分配内存
2.将内存地址赋值给 m_instance
3.调用构造器,初始化内存
在重排序的顺序中,如果 TreadA 执行到了 m_instance = new Singleton()的第二步骤
此时 m_instance 不为 nullptr
如果此时有另一个线程执行了 if(m_instance==nullptr) 此判断,则认为m_instance可以使用,其实不能使用
Singleton* Singleton::getInstance() {
if(m_instance==nullptr){
Lock lock;
if (m_instance == nullptr) {
m_instance = new Singleton();
}
}
return m_instance;
}public final class Singleton {
// The field must be declared volatile so that double check lock would work
// correctly.
// 必须使用 volatile 关键字修饰来避免指令重排序
private static volatile Singleton instance;
public String value;
private Singleton(String value) {
this.value = value;
}
public static Singleton getInstance(String value) {
if(instance == null){
synchronized(Singleton.class) {
if (instance == null) {
instance = new Singleton(value);
}
}
}
return instance;
}
}有一个文件分割器类和一个 Form 类,Form 类中需要新建一个文件分割器的对象
// 文件分割器基类
class ISplitter{
public:
virtual void split()=0;
virtual ~ISplitter(){}
};
// 具体的文件分割器类
class BinarySplitter : public ISplitter{
};
// Form 类
class MainForm : public Form
{
TextBox* txtFilePath;
TextBox* txtFileNumber;
ProgressBar* progressBar;
public:
void Button1_Click(){
// 紧密耦合
// 面向接口编程 变量声明为抽象基类
ISplitter * splitter=
new BinarySplitter();//依赖具体类 不好
splitter->split();
}
};采用工厂模式的代码
//抽象类
class ISplitter{
public:
virtual void split()=0;
virtual ~ISplitter(){}
};
//工厂基类
class SplitterFactory{
public:
virtual ISplitter* CreateSplitter()=0;
virtual ~SplitterFactory(){}
};
//具体类
class BinarySplitter : public ISplitter{
};
//具体工厂
class BinarySplitterFactory: public SplitterFactory{
public:
virtual ISplitter* CreateSplitter(){
return new BinarySplitter();
}
};
class MainForm : public Form
{
// 工厂类的抽象类的引用
SplitterFactory* factory;//工厂
public:
MainForm(SplitterFactory* factory){
this->factory=factory;
}
void Button1_Click(){
ISplitter * splitter=
factory->CreateSplitter(); //多态new
splitter->split();
}
};这里新建对象的时候,运行时究竟调用了哪个工厂方法新建了哪个对象,是由 MainForm 的 SplitterFactory 的类型决定的,是一种多态的**。而且对于 MainForm 来说,并不知道具体的工厂类,是面向接口编程,是一种抽象的**。
https://www.bilibili.com/video/BV1kW411P7KS?from=search&seid=13066287095511349570
这是一道经典的面试题,秋招面试的时候被问过无数次 💥 ,所以觉得值得好好复盘一下这道题。
我的回答其实也就是很粗略的说一下这个问题 🌱
因为这道题完全可以写一本书,其实也确实有一本书,这本书也主要讲了这个问题 网络是怎样连接的 📚
我的其他文章 : 分享汇总 🔖
这题主要考察的就是计算机网络,特别是各个层次的协议是什么进行交互的,从最上层往下,主要涉及 DNS,HTTP, HTTPS,TCP, IP,ARP 协议
浏览器解析 URL 生成 HTTP 请求报文
DNS 解析
ARP 解析
TCP 三次握手
IP 路由
输入 URL 之后,浏览器会对输入的 URL 进行解析,解析出服务器名,端口号,文件路径等信息之后,用于构造 HTTP 请求,并且对于 URL 中的中文,或者保留字符,也要进行相应的编码
有关 URL 的一些知识在我的另一篇文章中有涉及:URL URN 与 URI
因为发送 HTTP 请求报文需要依赖下层 TCP 协议,TCP 建立连接并通信是需要 IP 地址 + 端口号 这一对二元组的,端口号可以直接从 URL 中获得,但是 IP 地址需要由 DNS 解析域名来获得。DNS 服务主要功能就是将 URL 中的域名,解析为 IP 地址。
DNS 的过程大致为:
(假设要访问的域名为 aaa.bbb.ccc)
ccc 域,所以会将消息转发到 ccc 域的 DNS 服务器上。ccc域的 DNS 服务器会将请求转发到 bbb.ccc 域的服务器中,bbb.ccc域的服务器会转发到 aaa.bbb.ccc 域服务器中,此服务器中一定有相关的信息,所以直接返回即可。刚才说了 DNS 解析是将 域名映射为 IP 地址,而 ARP 协议是什么呢?ARP 协议是将 IP 地址映射为 MAC 地址。IP 地址和 MAC 地址是什么关系呢?这里就体现了计算机网络的分层的设计哲学。IP 地址是网络层的概念,而 MAC 地址是数据链路层的概念。假如有 N 个主机,通过一个交换机连接起来,那么这就是一个局域网,而局域网之间通过发送 MAC 帧进行通信,互相识别的都是 MAC 地址。而 N 个局域网通过路由器连接在一起就形成了一个互联网,这时候主要假如主机之间跨局域网,通过互联网来通信,就需要 IP 地址来发挥作用了。**那 ARP 地址解析和咱们的这道题又有什么关系呢。**是这样的,如果一台主机,新加入了一个局域网,那他会知道自己的 IP 地址和 MAC 地址,他也会知道自己网关路由器的 IP 地址,但是他不知道网关路由器的 MAC 地址。这就导致了比如咱们的主机发送 DNS 请求的时候,有可能会无法发送 MAC 帧给网关路由器,咱们的 DNS 请求根本就无法发出。这时候就需要 ARP 协议了。
ARP 解析的过程:
主机会先检查自己的 ARP 缓存中有没有相关信息,如果没有则准备发送 ARP 请求
主机发送一个 ARP 请求,里面有自己的 IP 地址和 MAC 地址和目标主机的 IP 地址。此主机会对局域网的所有主机发送一个广播 MAC 帧
每个主机收到 ARP 请求之后,将会比较自己的 IP 地址是不是和 ARP 请求报文中的 IP 地址一致,如果一致,则需要发送一个 ARP 回应报文
回应报文中会写入自己的 MAC 地址,这样主机收到 ARP 回应之后,就知道网关路由器的 MAC 地址,就可以发送 MAC 帧了
HTTP 协议是基于 TCP 的,在生成了 HTTP 请求报文之后,就会通过 TCP socket 对报文进行传输。这样我们就从应用层来到了传输层,其实就是 HTTP 报文会在应用层加上 TCP 头。因为 TCP 协议是面向连接,所以要先进行 TCP 三次握手建立连接,之后才可以进行数据的传输。
TCP 三次握手又是另外一个经典问题了,这个问题值得再写另外一篇文章,我之后会在另一篇文章中讨论这个问题。
// to-do 三次握手的过程
传输层的下一层是网络层,网络层负责将 TCP 报文加上 IP 头,生成 IP 数据包。并且在数据链路层加上帧头帧尾,发送到路由器,路由器去掉帧头帧尾得到 IP 数据包,并且根据目的 IP 地址,对数据包进行路由。
服务端拿到 IP 数据包之后,向上剥离,得到 HTTP 请求报文。之后根据请求报文,发送回应报文,再一步步发送到客户端。
文章汇总 : 分享汇总 📚 (计算机网络系列文章持续更新)
三次握手主要指 TCP 在建立连接时候的一系列过程
🔌 Sequence 序列号是什么?因为 TCP 需要有确认,并且需要防止上次连接的迟到的报文被接收,所以需要对每个报文打上一个标记,用来防止失序的,或者上一次连接的报文被接收
假设两台主机 A 和 B,A 首先建立连接
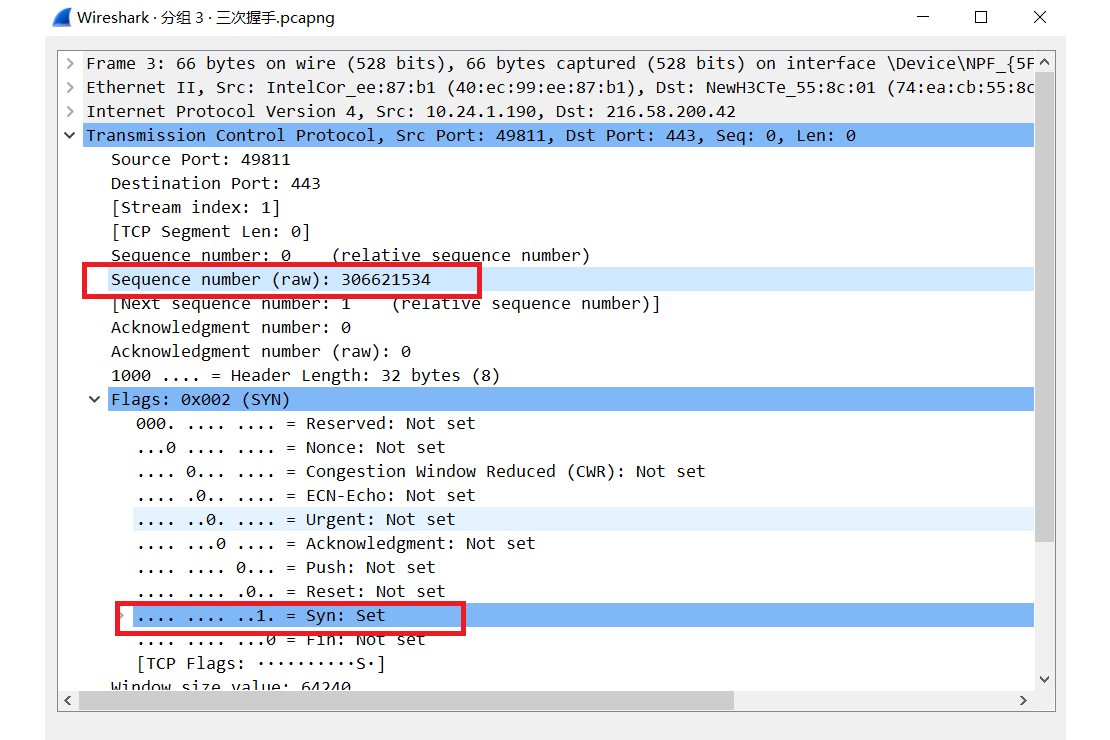
这是我用 Wireshark 抓到的三次握手的数据包,绿色 🌱 框起来的是三次握手相关的报文。我们来具体分析一下这三个报文
下面图片里的红色框起来的是关键字段 :triangular_flag_on_post:
这就是主动连接的一方发送的 SYN 报文,注意这个报文的 Flags 的 Syn 字段被设置为 1,并且带了一个初始的 Sequence number:306621534,记住这个数字, 这样 A 就将自己的序列号发送给了 B
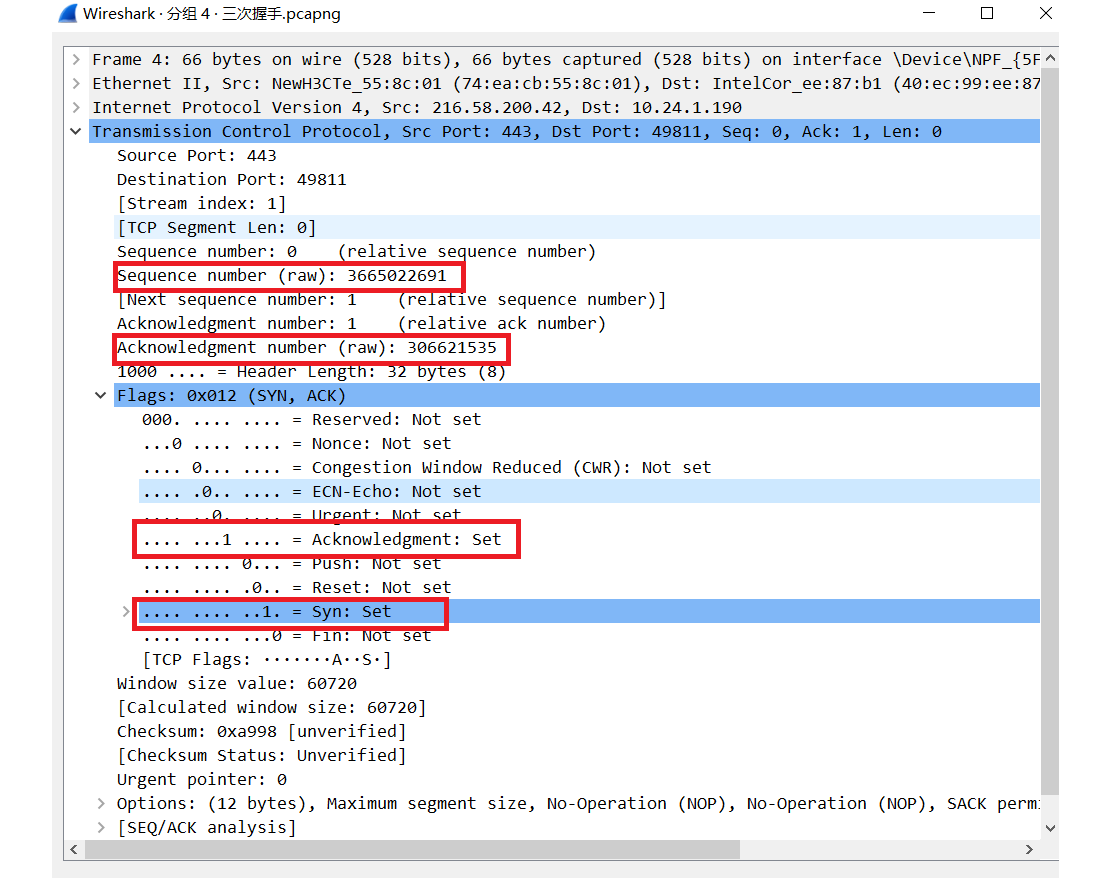
这个报文是 B 在收到 SYN 之后,对 A 的回应。作用是确认 A 发送来的 SYN,并将自己的序列号同步给 A 。
注意这里的 Acknowledgment number 是 306621535, 正好是 A 发来的 SYN 的序列号 + 1,这不是巧合,ACK 报文的确认号是 x ,意味着 序列号小于 x 的报文都收到了。
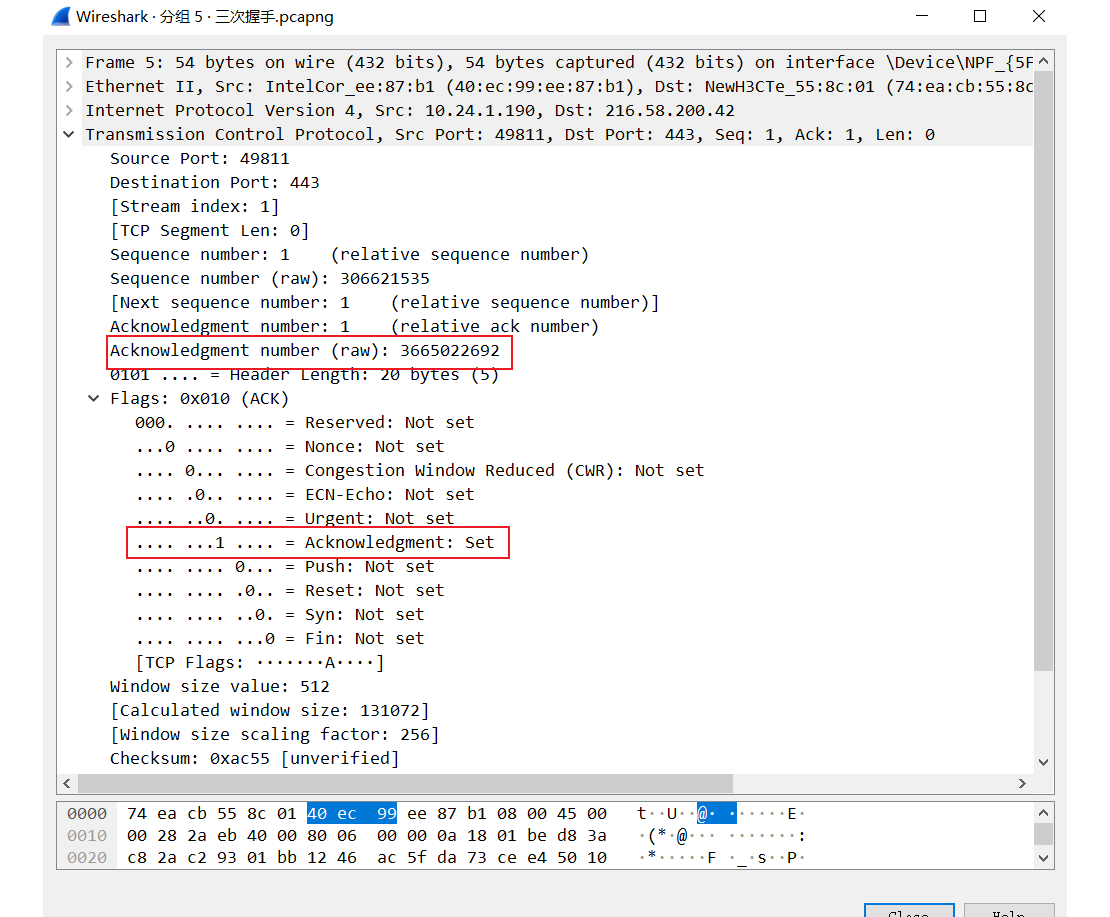
这个报文是 A 对收到的 SYN+ACK 的确认。这里的 Acknowledgment number 也正好是 B 发送的报文的序号 + 1。
现在三次握手相关知识都基本讲完了,来看几道面试题吧。
可以两次握手吗
不可以,因为会导致已经失效的连接请求的报文段又传到了服务端。并且两次握手也不能保证双方都互换了序列号
如果 A 发送给 B 的 ACK 中途丢失,会怎么样?
如果双方都没有数据发送, B 会周期重传 SYN + ACK ,直到 A 确认。如果 A 又数据发送,B 收到 A 的 Data + ACK ,会直接进入 ESTABLISHED 状态
📅 算法题打卡
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.