wancheng7 / learning-notes Goto Github PK
View Code? Open in Web Editor NEW学习笔记
学习笔记


OSI参考模型是网络互连的七层框架,具体包含以下七层
端口号可以用来标识同一个主机上通信的不同应用程序(就是哪个应用程序在使用这个端口)。
一个进程就是一个程序的运行实例,它具体指操作系统为这个任务创建的一块内存,可以用来存放代码、数据和一个执行任务的主线程。一个进程是可以包含多个线程的。
线程可以理解为一个处理任务的机器,一个线程同时只能做一件事。但是线程不能单独存在的,它是由进程来启动和管理的。
计算机的地址就称为 IP 地址,访问任何网站实际上只是你的计算机向另外一台计算机请求信息。
下面是JavaScript的内存模型,主要分为代码空间、栈内存和堆内存:
JavaScript的数据类型一共有八种:
栈内存中存储的是7种基本数据类型,堆内存中存储的是Object这种引用类型
因为栈内存需要反复切换调用栈,所以切换上下文的高效,只能存储几种基本类型,相对比较大的复合类型就存在堆内存中。
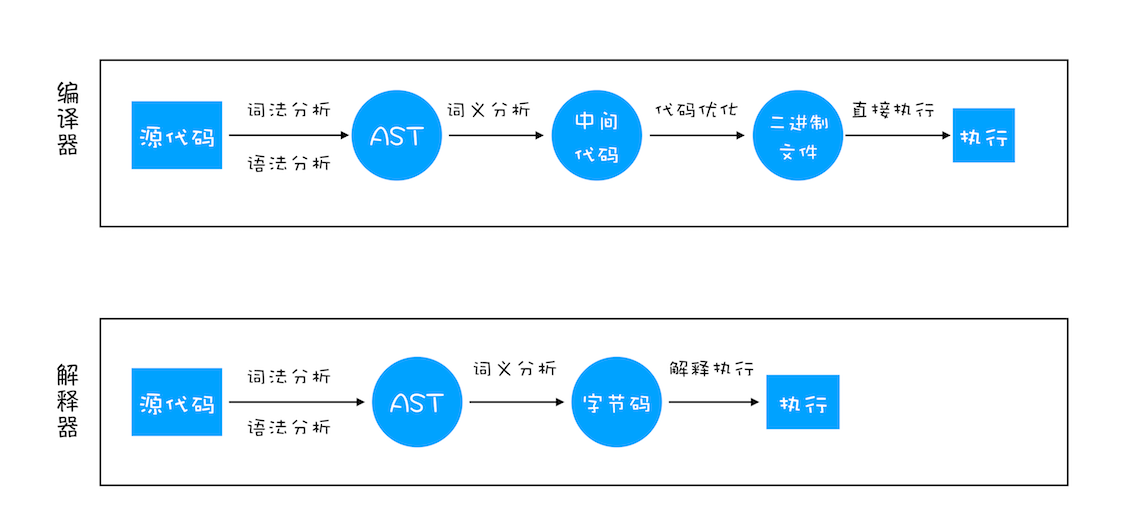
以下是关于编译器和解释器的具体介绍:
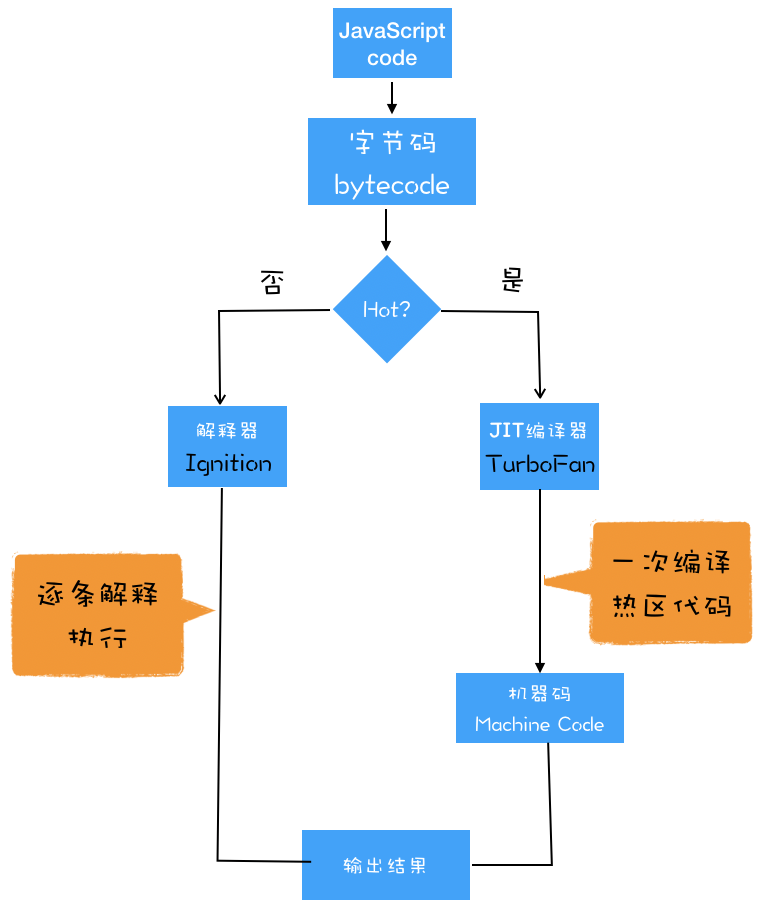
关于V8如何执行一段JavaScript代码的,答题可以分为以下步骤:
JavaScript代码 -> AST -> 字节码 -> 机器码
因为js是单线程的,主线程上只能做一件事,所以有必要引入消息队列,把待处理的消息放在一个队列中,依次执行。
但是纯粹的队列机制有个问题,就是如果等所有队列跑完再执行页面渲染,就会显得很卡,那如果队列中一个任务执行完了马上就渲染又会比较浪费性能,不够高效。
所以现在比较主流的方案就是,我们将消息队列中的任务称为宏任务,而由于某一个红任务比如对DOM的操作而产生的副作用比如UI更新和异步请求等都放到这个宏任务的微任务队列中去,每次消息队列中的某一个宏任务执行完了,并不是马上执行下一个宏任务,而是先执行它的微任务队列,如果这个宏任务操作有DOM 有变化,那么就会将该变化添加到微任务列表中,所以相应页面就会重新渲染,然后才是执行下一个宏任务。
TCP有6种标识:SYN(建立联机) ACK(确认) PSH(传送) FIN(结束) RST(重置) URG(紧急)
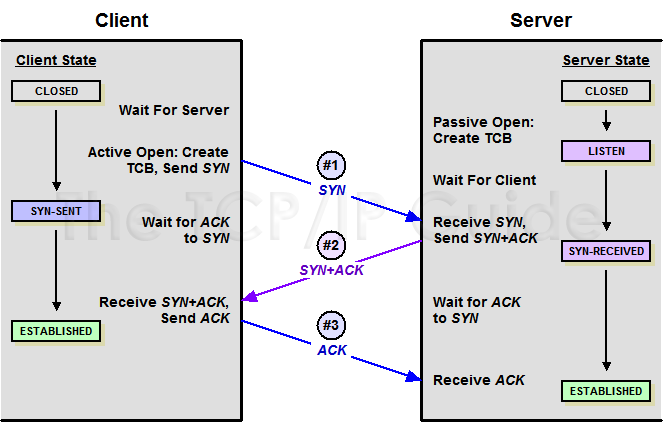
客户端向服务端发出请求连接报文,这时报文首部中的同部位SYN=1,同时随机生成初始序列号 seq=x,客户端进入SYN-SENT(同步已发送状态),表示客户端想要和服务端建立连接
服务器收到请求报文之后如果同意连接,则发出确认报文,应答报文中也会包含自身的数据通讯初始序号,发送完成后便进入 SYN-RECEIVED (同步收到) 状态。
当客户端收到同意连接的报文之后,还要向客户端发送一个确认报文,确认报文的ACK=1,ack=y+1,此时,TCP连接建立,客户端发送这个报文之后进入ESTABLISHED(已建立连接)状态。
我们先来看看一种极端情况,客户端发送了第一次握手的请求报文,但是由于网络不好等原因,这个请求没有立即到达服务器,而是滞留了一段时间之后才到达服务器
对于这个已经失效的报文,服务端还是会做回应,这个时候,如果两次就建立了TCP连接,那接下来服务端就要一直等待客户端的数据,可是对客户端来说这早已是一条失效的请求,所以不会有数据,所以会浪费服务端的资源。
但是三次握手就不存在这个问题了,第二次握手时,客户端就不会对这个无效请求进行回应了,就不会建立TCP连接了。
所以,总体来说,之所以要三次握手,是为了让服务端通过第三次握手最后确认建立TCP连接,避免造成服务端资源的浪费,避免上面这种情况发生。
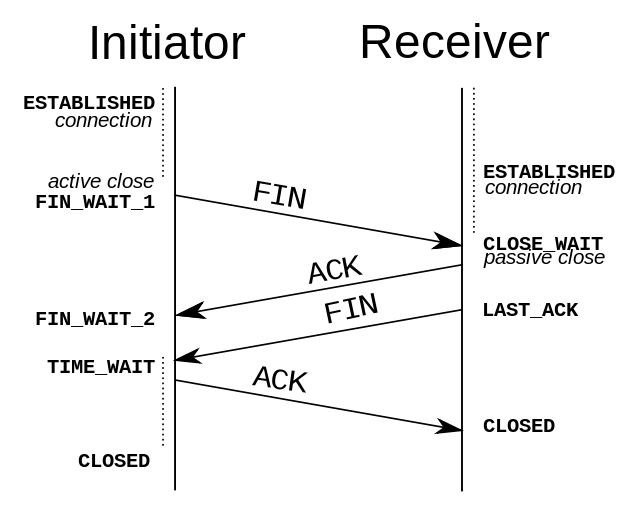
客户端认为数据发送完成,它就向服务端发起连接释放请求,此时,客户端进入FIN-WAIT-1(终止等待1)状态。
服务端收到连接释放请求后,会告诉应用层释放TCP连接,人庵后会发送ACK包,并进入CLOSE_WAIT 状态,表示客户端到服务端的连接已经释放,服务端不再接受客户端发的数据了,但是TCP是双向连接的,所以服务端仍然可以向客户端发送数据。
服务端如果还有没发完的数据会继续发送,完毕后服务端发送一个FIN(结束)到客户端,服务端关闭客户端的连接,服务端进入 LAST-ACK 状态。
客户端收到释放请求后,向服务端发送确认应答,此时客户端进入TIME-WAIT 状态。当服务端收到确认应答之后进入CLOSED 状态。
参考:
1、落地的必要条件
2、基建与业务的关系
3、团队意义
1、基建和业务的关系
业务支撑是-活在当下
技术基建是-活在未来
2、研发流程闭环中去寻找需要基建的点
3、用工具抹平差异点(cli)
4、可视化工程辅助
5、模板、组件库
6、不能为了学而学,误区是:从方案出发找场景,为了做而做,应该从问题出发去解决
7、业务阶段匹配性,要根据自己团队的具体情况来做东西,在不同的时期,基建与业务要是匹配的
8、打破职业思维惯性--如何将我们工程化的收益转化为业务收益,一切都是为了业务,不能为了做技术而做技术
9、技术的价值,在于解决业务问题,业务支撑永远是优先的,基建是其次的
10、问自己:因为你,什么事会变得不一样?
11、活下去,才能活的更好,所以做好本职业务优先,基建由团队主动完成
1、基建的真正价值是提效降本与成长
2、一切有利于研发效率提升,直接间接助力于业务开展的能力建设皆为基建
1、不仅仅局限于前端,服务端、客户端
当操作错误覆盖了别人的代码的时候就需要撤回。关于撤回,有两个命令:reset和revert。他们都可以完成撤回的操作,但是作用原理是不同的。
git reset命令可以回到之前的某一次提交。如果想回到上次提交,可以使用命令:
git reset --hard head
如果是上上次就是head^,多次可以用head~n,例如前五次head~5,或者知道commit id的话可以直接用这个id重置到这次提交:
git reset (复制的commitId)--hard
关于hard这种修饰符可以参考下面的解释,详情查看官网相关参数
--soft 回退后a分支修改的代码被保留并标记为add的状态(git status 是绿色的状态)
--mixed 重置索引,但不重置工作树,更改后的文件标记为未提交(add)的状态。默认操作。
--hard 重置索引和工作树,并且a分支修改的所有文件和中间的提交,没提交的代码都被丢弃了。
--merge 和--hard类似,只不过如果在执行reset命令之前你有改动一些文件并且未提交,merge会保留你的这些修改,hard则不会。【注:如果你的这些修改add过或commit过,merge和hard都将删除你的提交】
--keep 和--hard类似,执行reset之前改动文件如果是a分支修改了的,会提示你修改了相同的文件,不能合并。如果不是a分支修改的文件,会移除缓存区。git status还是可以看到保持了这些修改。
git revert回到某一次提交的原理是在已有提交记录的最后面新添加一个commit,而这个commit的内容就是目标提交的内容。例如
git revert (复制的commitId)
git reset会改变已有的提交记录,而git revert只是会在已有的提交记录上添加一条提交记录,所以后者是一种相对安全的回退方式。
我们再自己的个人分支上可以使用git reset,在公共分支上最好使用git revert。也可以这样区分,用git revert撤销已经推送的更改,用git reset撤销还没推送的更改。
1、只要目标服务器上开启了Nginx,符合匹配规则的请求都会进!
2、域名 -> IP -> 如果此IP的服务器上开启了Nginx并且请求符合匹配规则就会进代理
3、所以要想本地Nginx代理生效,前提是域名dns解析到本地。
4、所以Nginx代理处于请求到达服务器的环节,前面经历了DNS解析等
不加async和defer的script标签
当html文档加载过程中遇到了<script>标签,会停止html的渲染,然后开始加载<script>内容并执行。所以页面会出现短暂的卡顿或白屏。
async
当async为true时,会异步加载js文件,等文件加载完毕之后立即执行,在执行过程中还是会阻塞html文档的渲染。
defer
当defer为true时,同样会异步加载js文件,但是并不会马上执行,而是会等html文档渲染完之后才执行,作用有点类似于把<script>标签放在<body>下面。
引用一张网上的加载示意图:
从图中可以很清晰地看出async和defer的区别,他们都是异步加载的js文件,能够一定程度上减少页面渲染的阻塞时间,不同点就是js执行的时间点不一样。而且,当多个<script>标签都加了defer标签时,会按照先后顺序执行,而多个<script>标签都加了async标签时不一定会按顺序执行,因为是根据加载时间决定的。所以,对于有依赖关系的js文件,async加载方式可能会出问题。
相对于react-redux,最大的变化就是引入了model,相当于对之前的action和reducer做了一个封装,并且将一部操作和一些副作用的操作抽离到了effects中。然后要注意,effects中的函数是generater函数。
然后注意一下namespace命名空间问题,每一个model都有一个单独的命名空间,在本model调用reducer或者effects时,不需要写命名空间,但是调用其他model时一定记得要加上,格式是命名空间/方法名
对于可以按需加载的组件,可以使用dva内置的dynamic按需加载
import dynamic from 'dva/dynamic';
model中的方法要加载成功之后才能被别的地方调用。
dva 提供多个 effect 函数内部的处理函数,比较常用的是 call 和 put。
大家都知道,call, apply, bind都是用来改变一个方法的this指向的,只是参数和调用方式有区别而已,如果对这一块还不了解的可以自己查一下。
那不知道大家想过没有,这几个方法内部是如何实现的呢,我们试着用原生js来实现一下。
首先看一段代码:
var myObj = {
name: 'wan',
sayHello: function(age) {
console.log('hello, my name is ' + this.name + ', I`m ' + age + ' years old');
}
}
var test = {
name: 'cheng'
}
myObj.sayHello(25); // hello, my name is wan, I`m 25 years old
// 使用call和apply改变this指向
myObj.sayHello.call(test, 25); // hello, my name is cheng, I`m 25 years old
myObj.sayHello.apply(test, [25]); // hello, my name is cheng, I`m 25 years old查文档可知,call和apply的语法分别是:
function.call(thisArg, arg1, arg2, ...)
func.apply(thisArg, [argsArray])经过观察可知,call和apply的作用实际上就是在目标thisArg里运行了一遍function,然后将这个方法删除了。所以我们模拟实现一个自己的call的思路可以是在目标上下文环境的thisArg里 添加一个唯一属性,指向我们调用的方法,执行之后再删除。
先实现一个自己的call,callOne,因为call是function原型对象上的一个方法,所以可以依据上面的思路重写一个自己的call:
第一个版本:
Function.prototype.callOne = function(context) {
context.fn = this;
context.fn();
delete context.fn
}
myObj.sayHello.callOne(test, 25); // hello, my name is cheng, I`m undefined years old好,经过第一个版本,我们成功改变了this的指向,可是参数还没做处理,那下个版本就对参数处理一下吧。
第二个版本:
var myObj = {
name: 'wan',
sayHello: function(age, color) {
console.log(this.name, age, color);
}
}
var test = {
name: 'cheng'
}
Function.prototype.callTwo = function(context) {
context.fn = this;
var args = arguments;
var len = args.length;
var fnStr = 'context.fn(';
for (var i = 1; i < len; i++) {
fnStr += (i == len-1) ? 'args[' + i + ']' : 'args['+i+']' + ',';
}
fnStr += ')';
eval(fnStr)
delete context.fn
}
myObj.sayHello.callTwo(test, 25, "red"); // cheng 25 red特别注意一下,循环里面之所以要用string,是为了在eval中最后再执行,不然参数传字符串时会有问题。
第三个版本:
经过对参数的处理,好像差不多了呢,现在传多个不同类型的参数也是可以的了。那接下来据解决一下极端情况吧:
thisArg这个参数时可以不传或者传null的,这种情况下'thisArg'是指向window的。context中的fn属性,并且还删除了,这是有隐患的,万一本来它就有这个属性那就修改了context的值了,这肯定是不行的。所以我们可以自己造一个类似于ES6中的symbol类型的唯一属性作为context的过渡属性。所以针对上面两个问题进行一下优化:
var myObj = {
name: 'wan',
sayHello: function(age, color) {
console.log(this.name, age, color);
}
}
var test = {
name: 'cheng'
}
function getSymbolProperty(obj) {
var uniquePro = '__' + Math.random().toFixed(5);
if(obj.hasOwnProperty(uniquePro)) {
getSymbolProperty(obj)
}
else{
return uniquePro;
}
}
Function.prototype.callThree = function(context) {
var context = context || window;
var fn = getSymbolProperty(context);
context[fn] = this;
var args = arguments;
var len = args.length;
var fnStr = 'context[fn](';
for (var i = 1; i < len; i++) {
fnStr += (i == len-1) ? 'args['+i+']' : 'args['+i+']' + ',';
}
fnStr += ')';
eval(fnStr)
delete context[fn]
}
myObj.sayHello.callThree(test, 25, "red"); // cheng 25 red到这一步,对于call的模拟实现就基本完成了。
apply跟call差不多,只是参数不同而已,所以唯一的区别就是对于参数的处理改变一下就行了。
var myObj = {
name: 'wan',
sayHello: function(age, color) {
console.log(this.name, age, color);
}
}
var test = {
name: 'cheng'
}
function getSymbolProperty(obj) {
var uniquePro = '__' + Math.random().toFixed(5);
if(obj.hasOwnProperty(uniquePro)) {
getSymbolProperty(obj)
}
else{
return uniquePro;
}
}
Function.prototype.applyThree = function(context, arr) {
var context = context || window;
var fn = getSymbolProperty(context);
context[fn] = this;
var result;
if(arr && arr.length) {
var args = [];
for (let i = 0; i < arr.length; i++) {
args.push('arr[' + i + ']');
}
result = eval('context[fn](' + args + ')');
}
else{
result = context[fn]();
}
delete context[fn]
return result
}
myObj.sayHello.applyThree(test, [25, 'red']); // cheng 25 redbind与call最大的区别就是不会立即运行,返回的是一个函数。
高阶组件实际上是一个纯函数,可以将一些公共的功能抽离成一个高阶组件。高阶组件可以传入多个组件,然后根据条件返回。
分为基本数据类型和引用类型
基本数据类型包括6种:string、number、boolean、null、undefined、symbol
除了这几种基本类型,其他的都是引用类型,也可以说都是对象。
基本类型的值都是存在栈内存中的,引用类型得值是存在堆内存中的,因为引用类型的值可能很大,所以我们赋值的时候实际上只是一串存在栈内存中的指针。
基本数据类型的比较是值的比较
var a = 1;
var b = 1;
console.log(a === b);//true
引用数据类型的比较是引用的比较。
var a = [1,2,3];
var b = [1,2,3];
console.log(a == b); // false
当我们给基本数据类型赋值时,实际上是在传值,也就是在栈内存中开辟出一块新的内存存这个新变量,例如:
var a = 7;
var b = a;
a++;
console.log(a, b); //8 7
基本数据类型的两个变量是两个互不影响的变量。
而当我们在给引用数据类型赋值时,实际上赋值的是指针地址。例如下面的代码:
var a = {name: 'wan'};
var b = a;
a.name = 'cheng';
console.log(a); //{name: "cheng"}
console.log(b); //{name: "cheng"}
由于a和b两个变量存的都是指向同一个对象的指针,所以这两个对象之间就能够相互影响了。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.