vislee / leevis.com Goto Github PK
View Code? Open in Web Editor NEWBlog
Blog





























































































前段时间,花了2个多月用golang重写了我们的计费系统。利用tcpcopy把线上流量导入测试的时候,发现mysql计费测试慢了20分钟。因为存储类计费需要在计费程序里面算时长,还要根据分钟merge一次。所以,根据日志很难分析出哪个环节慢。
还好之前开发的时候已经就集成了net/http/pprof这个库的功能。提供出了http接口查看运行时的内存堆栈等。具体使用可以看下我goframe debug/pprof的实现。就不多说了。
利用go-torch这个工具,直接可以生成调用栈的火焰图。
使用说明:
go get github.com/uber/go-torchclone 该项目FlameGraphclone下来的目录加入到PATH. 我是临时使用,只加了个临时路径 export PATH=$PATH:~/work/github.com/brendangregg/FlameGraphgo-torch --time=120 --file "./mysql_1.svg" --url http://127.0.0.1:8080/debug/pprof 。 其中time是采样时长。file是火焰图文件,用浏览器打开就会看到你程序调用栈生成的漂亮的火焰图。更推荐用google/pprof,功能更强大。
注:如果你程序允许在生产环境而有bind是localhost,可以通过nc映射出去。例如: nc -l xxx.xxx.xxx.xxx 8080 -c "nc 127.0.0.1 8080" -vv
写好基准测试用例,通过执行下面的命令,会生成3个文件。
go test -bench=. -run=none -benchtime=30s -cpuprofile=cpu.pprof -memprofile=mem.pprof -blockprofile=block.pprof
安装好gvedit, brew install graphviz
go tool pprof -http=":8080" cpu.pprof
会自动在浏览器上打开地址:http://localhost:8080/ui/ ,然后就可以在浏览器上查看各种分析数据了。
# rpm -ivh kernel-debuginfo-$(uname -r).rpm
# rpm -ivh kernel-debuginfo-common-$(uname -r).rpm
# rpm -ivh kernel-devel-$(uname -r).rpm
# yum install systemtap# stap -v -e 'probe vfs.read {printf("read performed\n"); exit()}'
Pass 1: parsed user script and 471 library scripts using 244720virt/42176res/3488shr/38776data kb, in 280usr/10sys/317real ms.
Pass 2: analyzed script: 1 probe, 1 function, 7 embeds, 0 globals using 409348virt/202068res/4872shr/203404data kb, in 1550usr/400sys/2228real ms.
Pass 3: using cached /root/.systemtap/cache/22/stap_2272ccb5d03251f836e4f9ac4a5fb30c_2763.c
Pass 4: using cached /root/.systemtap/cache/22/stap_2272ccb5d03251f836e4f9ac4a5fb30c_2763.ko
Pass 5: starting run.
read performed
Pass 5: run completed in 20usr/40sys/375real ms.# cd ~/work/src/github.com/openresty
# git clone https://github.com/openresty/stapxx--depth=1
# export PATH=$PATH:~/work/src/github.com/openresty/stapxx/:~/work/src/github.com/openresty/stapxx/samples/
验证stapxx
# stap++ -e 'probe begin { println("hello") exit() }'
hello# cd ~/work/src/github.com/openresty
# git clone https://github.com/openresty/openresty-systemtap-toolkit.git --depth=1
# cd ..
# git clone https://github.com/brendangregg/FlameGraph.git --depth=1 brendangregg/FlameGraph
# lj-lua-stacks.sxx --skip-badvars -D STP_NO_OVERLOAD -D MAXMAPENTRIES=10000 --arg time=120 -x 12546 > ./data.bt
~/work/src/github.com/openresty/openresty-systemtap-toolkit/fix-lua-bt ./data.bt > ./flame.bt
~/work/src/github.com/brendangregg/FlameGraph/stackcollapse-stap.pl ./flame.bt > flame.cbt
~/work/src/github.com/brendangregg/FlameGraph/flamegraph.pl ./flame.cbt > ./flame.svg
用浏览器打开flame.svg就看到火焰图了。
ngx http日志抽样采集。
官方日志不支持抽样采集,而我们使用nginx时会有这样的需求,有的状态码的日志会全量采集,有的会需要抽样采集。所以,通过官方提供的配置实现不了这样的需求。
为了实现这样的需求,只能修改nginx的日志模块的代码,添加功能。
需要添加如下配置:sample=50%:200,304 表示对状态码为200和304做抽样采集,每100条采集50条。
代码后期会放倒github上。
如果采集的条件不止是对status,那么可以把指令修改成sample=50%$status:200,304。status可以是其它变量,后面200,304时对应的取值。
该模块通过模版和变量的支持,可订制请求日志输出格式和内容。
如下是官方文档一个例子:
log_format compression '$remote_addr - $remote_user [$time_local] '
'"$request" $status $bytes_sent '
'"$http_referer" "$http_user_agent" "$gzip_ratio"';
access_log /spool/logs/nginx-access.log compression buffer=32k;
配置解析:和其他http模块一样,在ngx_http_block函数中,调用module->create_main_conf 和 module->create_loc_conf 指向的函数ngx_http_log_create_main_conf和ngx_http_log_create_loc_conf 创建保存指令的结构体。在ngx_conf_parse解析配置文件时,会调用到log_format指令的回调函数ngx_http_log_set_format和access_log指令的回调函数ngx_http_log_set_log。解析完配置后,调用ngx_http_merge_servers函数,该函数会调用日志模块的merge_srv_conf函数指针指向的ngx_http_log_merge_loc_conf函数继承不同层级相同的配置。最后调用每个HTTP模块postconfiguration指针指向的回调函数ngx_http_log_init添加日志handler回调函数ngx_http_log_handler。
请求处理:请求结束时,调用ngx_http_log_request函数,该函数统一调用注册到NGX_HTTP_LOG_PHASE阶段所有的回调函数,就有前面注册进来的ngx_http_log_handler函数。
// 保存单独的变量
struct ngx_http_log_op_s {
size_t len; // 变量有固定长度
ngx_http_log_op_getlen_pt getlen; // 获取变量结果的长度
ngx_http_log_op_run_pt run; // 获取变量结果的回调函数
uintptr_t data; // index变量,下标。
};
// 日志格式
typedef struct {
ngx_str_t name;
ngx_array_t *flushes;
ngx_array_t *ops; /* array of ngx_http_log_op_t */
} ngx_http_log_fmt_t;
// 保存配置在http块下的日志格式,log_format指令。
typedef struct {
ngx_array_t formats; /* array of ngx_http_log_fmt_t */
ngx_uint_t combined_used; /* unsigned combined_used:1 */
} ngx_http_log_main_conf_t;
// 保存日志文件和格式引用,access_log指令。
typedef struct {
ngx_array_t *logs; /* array of ngx_http_log_t */
ngx_open_file_cache_t *open_file_cache;
time_t open_file_cache_valid;
ngx_uint_t open_file_cache_min_uses;
ngx_uint_t off; /* unsigned off:1 */
} ngx_http_log_loc_conf_t;// 编译日志格式
static char *
ngx_http_log_compile_format(ngx_conf_t *cf, ngx_array_t *flushes,
ngx_array_t *ops, ngx_array_t *args, ngx_uint_t s)
{
u_char *data, *p, ch;
size_t i, len;
ngx_str_t *value, var;
ngx_int_t *flush;
ngx_uint_t bracket, escape;
ngx_http_log_op_t *op;
ngx_http_log_var_t *v;
escape = NGX_HTTP_LOG_ESCAPE_DEFAULT;
value = args->elts;
if (s < args->nelts && ngx_strncmp(value[s].data, "escape=", 7) == 0) {
data = value[s].data + 7;
if (ngx_strcmp(data, "json") == 0) {
escape = NGX_HTTP_LOG_ESCAPE_JSON;
} else if (ngx_strcmp(data, "none") == 0) {
escape = NGX_HTTP_LOG_ESCAPE_NONE;
} else if (ngx_strcmp(data, "default") != 0) {
ngx_conf_log_error(NGX_LOG_EMERG, cf, 0,
"unknown log format escaping \"%s\"", data);
return NGX_CONF_ERROR;
}
s++;
}
for ( /* void */ ; s < args->nelts; s++) {
i = 0;
while (i < value[s].len) {
op = ngx_array_push(ops);
if (op == NULL) {
return NGX_CONF_ERROR;
}
data = &value[s].data[i];
if (value[s].data[i] == '$') {
if (++i == value[s].len) {
goto invalid;
}
if (value[s].data[i] == '{') {
bracket = 1;
if (++i == value[s].len) {
goto invalid;
}
var.data = &value[s].data[i];
} else {
bracket = 0;
var.data = &value[s].data[i];
}
for (var.len = 0; i < value[s].len; i++, var.len++) {
ch = value[s].data[i];
if (ch == '}' && bracket) {
i++;
bracket = 0;
break;
}
if ((ch >= 'A' && ch <= 'Z')
|| (ch >= 'a' && ch <= 'z')
|| (ch >= '0' && ch <= '9')
|| ch == '_')
{
continue;
}
break;
}
if (bracket) {
ngx_conf_log_error(NGX_LOG_EMERG, cf, 0,
"the closing bracket in \"%V\" "
"variable is missing", &var);
return NGX_CONF_ERROR;
}
if (var.len == 0) {
goto invalid;
}
// 日志格式特有的变量
for (v = ngx_http_log_vars; v->name.len; v++) {
if (v->name.len == var.len
&& ngx_strncmp(v->name.data, var.data, var.len) == 0)
{
op->len = v->len; // 长度固定
op->getlen = NULL;
op->run = v->run; // 获取值
op->data = 0;
goto found;
}
}
if (ngx_http_log_variable_compile(cf, op, &var, escape)
!= NGX_OK)
{
return NGX_CONF_ERROR;
}
if (flushes) {
flush = ngx_array_push(flushes);
if (flush == NULL) {
return NGX_CONF_ERROR;
}
*flush = op->data; /* variable index */
}
found:
continue;
}
i++;
// 添加常量字符串
while (i < value[s].len && value[s].data[i] != '$') {
i++;
}
len = &value[s].data[i] - data;
if (len) {
op->len = len;
op->getlen = NULL;
if (len <= sizeof(uintptr_t)) {
op->run = ngx_http_log_copy_short;
op->data = 0;
while (len--) {
op->data <<= 8;
op->data |= data[len];
}
} else {
op->run = ngx_http_log_copy_long;
p = ngx_pnalloc(cf->pool, len);
if (p == NULL) {
return NGX_CONF_ERROR;
}
ngx_memcpy(p, data, len);
op->data = (uintptr_t) p;
}
}
}
}
return NGX_CONF_OK;
invalid:
ngx_conf_log_error(NGX_LOG_EMERG, cf, 0, "invalid parameter \"%s\"", data);
return NGX_CONF_ERROR;
}
// 编译通用变量
static ngx_int_t
ngx_http_log_variable_compile(ngx_conf_t *cf, ngx_http_log_op_t *op,
ngx_str_t *value, ngx_uint_t escape)
{
ngx_int_t index;
// 获取变量在数组中的下标
index = ngx_http_get_variable_index(cf, value);
if (index == NGX_ERROR) {
return NGX_ERROR;
}
op->len = 0;
switch (escape) {
case NGX_HTTP_LOG_ESCAPE_JSON:
op->getlen = ngx_http_log_json_variable_getlen;
op->run = ngx_http_log_json_variable;
break;
case NGX_HTTP_LOG_ESCAPE_NONE:
op->getlen = ngx_http_log_unescaped_variable_getlen;
op->run = ngx_http_log_unescaped_variable;
break;
default: /* NGX_HTTP_LOG_ESCAPE_DEFAULT */
op->getlen = ngx_http_log_variable_getlen;
op->run = ngx_http_log_variable;
}
op->data = index;
return NGX_OK;
}
调用日志模块回调函数记录请求日志:
static void
ngx_http_log_request(ngx_http_request_t *r)
{
ngx_uint_t i, n;
ngx_http_handler_pt *log_handler;
ngx_http_core_main_conf_t *cmcf;
cmcf = ngx_http_get_module_main_conf(r, ngx_http_core_module);
log_handler = cmcf->phases[NGX_HTTP_LOG_PHASE].handlers.elts;
n = cmcf->phases[NGX_HTTP_LOG_PHASE].handlers.nelts;
for (i = 0; i < n; i++) {
log_handler[i](r);
}
}打包go程序的时候,报找不到第三方包。根据报错信息去打包机看了下,果然没有第三方包。明明在本地是提交了git的,为什么打包机从git clone的时候就没有呢。去git看了一下,确实也没有第三方包的文件,仅仅是个链接。
为什么会这样呢?因为第三包都是从github上clone的,clone的时候就会带着原git的信息,在.git目录下。而再提交到别的项目时,git认为git上已经有该项目了,搞个超链接连过去就可以了。
然而,项目的git上是没有github上的第三方包,只是我在提交的时候没有注意到。那问题来了,怎么解决呢?
首先,删掉本地以及git上的子模组。git rm --cached path/to/submodule。
重新把github的包copy到项目的对应目录下,把.git目录删除后重新提交。
当开始解析http这个block时,开始调用ngx_http_block函数。这个函数创建了一个ngx_http_conf_ctx_t结构体后开始调用ngx_conf_parse解析http这个block的内容,包括server这个block。
而和server同一级的还有其它配置,如client_header_timeout。那么是如何做到不通的指令传入不同的保存指令的结构体的呢?
下面是解析配置文件,指定结构体的关键逻辑:
if (cmd->type & NGX_DIRECT_CONF) {
conf = ((void **) cf->ctx)[ngx_modules[i]->index];
} else if (cmd->type & NGX_MAIN_CONF) {
conf = &(((void **) cf->ctx)[ngx_modules[i]->index]);
} else if (cf->ctx) {
confp = *(void **) ((char *) cf->ctx + cmd->conf);
if (confp) {
conf = confp[ngx_modules[i]->ctx_index];
}
}nsq 是学习golfing语言很好的项目。
nsq/apps/nsqd/nsqd.go
func main() {
//解析命令行参数
flagSet := nsqFlagset()
flagSet.Parse(os.Args[1:])
//初始化随机数
rand.Seed(time.Now().UTC().UnixNano())
if flagSet.Lookup("version").Value.(flag.Getter).Get().(bool) {
fmt.Println(version.String("nsqd"))
return
}
//注册信号
signalChan := make(chan os.Signal, 1)
signal.Notify(signalChan, syscall.SIGINT, syscall.SIGTERM)
// 解析配置文件
var cfg config
configFile := flagSet.Lookup("config").Value.String()
if configFile != "" {
_, err := toml.DecodeFile(configFile, &cfg)
if err != nil {
log.Fatalf("ERROR: failed to load config file %s - %s", configFile, err.Error())
}
}
cfg.Validate()
opts := nsqd.NewNSQDOptions()
options.Resolve(opts, flagSet, cfg)
nsqd := nsqd.NewNSQD(opts)
// 加载dat文件
// 文件内容: {"topics":[{"channels":[],"name":"hello","paused":false}],"version":"0.3.6-alpha"}
nsqd.LoadMetadata()
// 保存dat文件。把nsqd系统的主题和通道以json格式保存到磁盘
err := nsqd.PersistMetadata()
if err != nil {
log.Fatalf("ERROR: failed to persist metadata - %s", err.Error())
}
// 主要功能函数
nsqd.Main()
<-signalChan
nsqd.Exit()
}配置文件项:
nsq/nsqd/options.go
func NewNSQDOptions() *nsqdOptions {
hostname, err := os.Hostname()
if err != nil {
log.Fatal(err)
}
h := md5.New()
io.WriteString(h, hostname)
defaultID := int64(crc32.ChecksumIEEE(h.Sum(nil)) % 1024)
return &nsqdOptions{
ID: defaultID,
TCPAddress: "0.0.0.0:4150",
HTTPAddress: "0.0.0.0:4151",
HTTPSAddress: "0.0.0.0:4152",
BroadcastAddress: hostname,
MemQueueSize: 10000,
MaxBytesPerFile: 104857600,
SyncEvery: 2500,
SyncTimeout: 2 * time.Second,
QueueScanInterval: 100 * time.Millisecond,
QueueScanRefreshInterval: 5 * time.Second,
QueueScanSelectionCount: 20,
QueueScanWorkerPoolMax: 4,
QueueScanDirtyPercent: 0.25,
MsgTimeout: 60 * time.Second,
MaxMsgTimeout: 15 * time.Minute,
MaxMsgSize: 1024768,
MaxBodySize: 5 * 1024768,
MaxReqTimeout: 1 * time.Hour,
ClientTimeout: 60 * time.Second,
MaxHeartbeatInterval: 60 * time.Second,
MaxRdyCount: 2500,
MaxOutputBufferSize: 64 * 1024,
MaxOutputBufferTimeout: 1 * time.Second,
StatsdPrefix: "nsq.%s",
StatsdInterval: 60 * time.Second,
StatsdMemStats: true,
E2EProcessingLatencyWindowTime: time.Duration(10 * time.Minute),
DeflateEnabled: true,
MaxDeflateLevel: 6,
SnappyEnabled: true,
TLSMinVersion: tls.VersionTLS10,
Logger: log.New(os.Stderr, "[nsqd] ", log.Ldate|log.Ltime|log.Lmicroseconds),
}
}主要业务逻辑
nsq/nsqd/nsqd.go
func NewNSQD(opts *nsqdOptions) *NSQD {
n := &NSQD{
opts: opts,
flag: flagHealthy,
startTime: time.Now(),
topicMap: make(map[string]*Topic),
idChan: make(chan MessageID, 4096),
exitChan: make(chan int),
notifyChan: make(chan interface{}),
}
if opts.MaxDeflateLevel < 1 || opts.MaxDeflateLevel > 9 {
n.logf("FATAL: --max-deflate-level must be [1,9]")
os.Exit(1)
}
if opts.ID < 0 || opts.ID >= 1024 {
n.logf("FATAL: --worker-id must be [0,1024)")
os.Exit(1)
}
if opts.StatsdPrefix != "" {
_, port, err := net.SplitHostPort(opts.HTTPAddress)
if err != nil {
n.logf("ERROR: failed to parse HTTP address (%s) - %s", opts.HTTPAddress, err)
os.Exit(1)
}
statsdHostKey := statsd.HostKey(net.JoinHostPort(opts.BroadcastAddress, port))
prefixWithHost := strings.Replace(opts.StatsdPrefix, "%s", statsdHostKey, -1)
if prefixWithHost[len(prefixWithHost)-1] != '.' {
prefixWithHost += "."
}
opts.StatsdPrefix = prefixWithHost
}
if opts.TLSClientAuthPolicy != "" && opts.TLSRequired == TLSNotRequired {
opts.TLSRequired = TLSRequired
}
tlsConfig, err := buildTLSConfig(opts)
if err != nil {
n.logf("FATAL: failed to build TLS config - %s", err)
os.Exit(1)
}
if tlsConfig == nil && n.opts.TLSRequired != TLSNotRequired {
n.logf("FATAL: cannot require TLS client connections without TLS key and cert")
os.Exit(1)
}
n.tlsConfig = tlsConfig
n.logf(version.String("nsqd"))
n.logf("ID: %d", n.opts.ID)
return n
}
//加载dat文件
func (n *NSQD) LoadMetadata() {
// 设置加载标志
n.setFlag(flagLoading, true)
defer n.setFlag(flagLoading, false)
//dat 文件名
fn := fmt.Sprintf(path.Join(n.opts.DataPath, "nsqd.%d.dat"), n.opts.ID)
data, err := ioutil.ReadFile(fn)
if err != nil {
if !os.IsNotExist(err) {
n.logf("ERROR: failed to read channel metadata from %s - %s", fn, err)
}
return
}
// 解析dat文件的内容,这个函数还要具体看下`go-simplejson`这个项目。
// 主要还是封装了json的一些方法。
js, err := simplejson.NewJson(data)
if err != nil {
n.logf("ERROR: failed to parse metadata - %s", err)
return
}
// dat 文件的主题数组
topics, err := js.Get("topics").Array()
if err != nil {
n.logf("ERROR: failed to parse metadata - %s", err)
return
}
for ti := range topics {
// 每个主题的封装的json格式
topicJs := js.Get("topics").GetIndex(ti)
// 主题名
topicName, err := topicJs.Get("name").String()
if err != nil {
n.logf("ERROR: failed to parse metadata - %s", err)
return
}
if !protocol.IsValidTopicName(topicName) {
n.logf("WARNING: skipping creation of invalid topic %s", topicName)
continue
}
// 创建一个主题
topic := n.GetTopic(topicName)
paused, _ := topicJs.Get("paused").Bool()
if paused {
topic.Pause()
}
channels, err := topicJs.Get("channels").Array()
if err != nil {
n.logf("ERROR: failed to parse metadata - %s", err)
return
}
for ci := range channels {
channelJs := topicJs.Get("channels").GetIndex(ci)
channelName, err := channelJs.Get("name").String()
if err != nil {
n.logf("ERROR: failed to parse metadata - %s", err)
return
}
if !protocol.IsValidChannelName(channelName) {
n.logf("WARNING: skipping creation of invalid channel %s", channelName)
continue
}
channel := topic.GetChannel(channelName)
paused, _ = channelJs.Get("paused").Bool()
if paused {
channel.Pause()
}
}
}
}
// GetTopic performs a thread safe operation
// to return a pointer to a Topic object (potentially new)
func (n *NSQD) GetTopic(topicName string) *Topic {
n.Lock()
t, ok := n.topicMap[topicName]
if ok {
n.Unlock()
return t
}
deleteCallback := func(t *Topic) {
n.DeleteExistingTopic(t.name)
}
t = NewTopic(topicName, &context{n}, deleteCallback)
n.topicMap[topicName] = t
n.logf("TOPIC(%s): created", t.name)
// release our global nsqd lock, and switch to a more granular topic lock while we init our
// channels from lookupd. This blocks concurrent PutMessages to this topic.
t.Lock()
n.Unlock()
// if using lookupd, make a blocking call to get the topics, and immediately create them.
// this makes sure that any message received is buffered to the right channels
if len(n.lookupPeers) > 0 {
channelNames, _ := lookupd.GetLookupdTopicChannels(t.name, n.lookupHTTPAddrs())
for _, channelName := range channelNames {
if strings.HasSuffix(channelName, "#ephemeral") {
// we don't want to pre-create ephemeral channels
// because there isn't a client connected
continue
}
t.getOrCreateChannel(channelName)
}
}
t.Unlock()
// NOTE: I would prefer for this to only happen in topic.GetChannel() but we're special
// casing the code above so that we can control the locks such that it is impossible
// for a message to be written to a (new) topic while we're looking up channels
// from lookupd...
//
// update messagePump state
select {
case t.channelUpdateChan <- 1:
case <-t.exitChan:
}
return t
}作为一个云计算平台,对用户是分了多个等级的。不同的等级首先在流量限额上是不同的。对于超出的用户会采用限流措施。整个流量控制系统粗略的分为两个模块:预警模块和限流模块。
流量预警一般有两种形式:滑窗模式和响应模式(细节请谷歌)。而响应模式对用户来说不太友好,也有误报情况。流量可能出现一个峰值导致流量报警被限制也不是我们的目的,所以我们是采用滑窗模式来做流量监控。把每个时间片内的流量进行汇总监控,只有连续两个时间片都超过阈值才会通知限流模块。限流模块根据预警模块报告的用户和超配额度进行限制。
限流在用户体验上大概可分为两种,一种是让一部分用户请求变慢(epoll有读事件了加个定时器先忙别的定时器到期再读等)。另一种是拒绝一部分用户请求(直接close连接,或返回一个固定的页面。大鲸鱼有映像吧)。 第一种方案的话,用户请求变慢不太明显,给用户的感觉是可能网络变慢而不是等级太低。第二种方案是对于超配的应用随机拒绝一部分用户的请求返回一个固定的页面,能很明显的告诉开发者和用户流量超配,可能需要升等级(当然我们也会发通知、体现到控制台)。
限流又大概分为两种策略:漏桶策略和令牌桶策略。漏桶策略对于用户来说体验比临牌桶策略要好一些。漏桶策略会让流量满满流入不会中断。而令牌桶策略,如果令牌桶空了就会导致流量中断。我们之前采用的就是令牌桶策略,每2分钟把令牌桶填满。现在我们采用的是漏桶策略,超配了会随机的让部分请求漏过来,随机的拒绝掉部分的请求。
随机拒绝部分用户的请求是有个难题的,用户的代码有可能静态动态不是分开的。如果拒绝掉的是个子请求,请求的是css,那么用户看到的页面就乱了。后期会说下大概的实现。
在ngx上需要开发一个业务防火墙的功能,并且能在被拦截的时候输出被哪种策略拦截。
我们的做法是在NGX_HTTP_PREACCESS_PHASE阶段添加一个module。根据业务规则判断后设置一个错误码,如: r->err_status = 603; 。然后用 error_page 603 =603 /afw.html; 这样的配置命令输出一个错误的页面(当然:error_page 的status 不允许小于300 大于599的值if (err->status < 300 || err->status > 599) 。你可以把这句注掉,或者重写一个模块,我们是重写了一个模块)。把拦截的策略输出一个变量,通过在日志中配置,就可以得到被哪种策略拦截了。
原本这个模块其实挺简单的。一个下午就搞出来了。不配置 error_page 的时候一切测试正常。当配置了以后随机限制请求这个策略不准确了,拦截的策略这个变量没值了。
gdb看了一下,这两个问题都由内部重定向(internal redirect)这个问题导致。
问题一:变量
ngx的变量会在这个模块生成内容,保存到请求的上下文中。例如:$proxy_host(把内容通过调用这个函数 ngx_http_set_ctx(r, ctx, ngx_http_proxy_module); 保存到了r->ctx数组中,获取变量的时候再通过 ctx = ngx_http_get_module_ctx(r, ngx_http_proxy_module); 函数取出来 )。在日志模块取出来输出到日志中,然而在内部重定向给清空了( ngx_memzero(r->ctx, sizeof(void *) * ngx_http_max_module); )。内部重定向阶段是在日志阶段之前的,所以日志阶段取到的变量就是空了。
解决这个问题用了个黑魔法,到现在重看了几次代码都没想到其它办法。什么黑魔法呢?就是把拦截的策略以一组key:value 的形似写到请求的headers里。如: ngx_http_afw_set_headers(r, &reason, blk);
下面给出这个函数的实现:
static ngx_table_elt_t*
ngx_http_afw_get_header(ngx_list_part_t *part, ngx_str_t *var) {
ngx_table_elt_t *header;
ngx_uint_t i, n;
u_char ch;
header = part->elts;
for (i = 0; /* void */ ; i++) {
if (i >= part->nelts) {
if (part->next == NULL) {
break;
}
part = part->next;
header = part->elts;
i = 0;
}
if (header[i].hash == 0) {
continue;
}
for (n = 0; n < var->len && n < header[i].key.len; n++) {
ch = header[i].key.data[n];
if (ch >= 'A' && ch <= 'Z') {
ch |= 0x20;
} else if (ch == '-') {
ch = '_';
}
if (var->data[n] != ch) {
break;
}
}
if (n == var->len && n == header[i].key.len) {
return &header[i];
}
}
return NULL;
}
static ngx_int_t
ngx_http_afw_set_headers(ngx_http_request_t *r, ngx_str_t *key, ngx_str_t *val) {
ngx_table_elt_t *h;
h = ngx_http_afw_get_header(&r->headers_in.headers.part, key);
if (h == NULL) {
h = ngx_list_push(&r->headers_in.headers);
}
if (h == NULL) {
return NGX_HTTP_INTERNAL_SERVER_ERROR;
}
h->hash = r->header_hash;
h->key.len = key->len;
h->key.data = ngx_palloc(r->pool, h->key.len);
if (h->key.data == NULL) {
return NGX_HTTP_INTERNAL_SERVER_ERROR;
}
ngx_memcpy(h->key.data, key->data, key->len);
h->value.len = val->len;
h->value.data = ngx_palloc(r->pool, h->value.len);
if (h->value.data == NULL) {
return NGX_HTTP_INTERNAL_SERVER_ERROR;
}
ngx_memcpy(h->value.data, val->data, val->len);
h->lowcase_key = ngx_pnalloc(r->pool, h->key.len);
if (h->lowcase_key == NULL) {
return NGX_HTTP_INTERNAL_SERVER_ERROR;
}
ngx_strlow(h->lowcase_key, h->key.data, h->key.len);
return NGX_OK;
}
问题二:规则
模块内部对触发了该规则,按照比例随机拒绝请求。既然有比例,就需要有计数。而配置了 error_page
就导致了计数不准确。看下面的代码,假如ratio设置了50,就是按照50%的比例随机拒绝请求。当满足条件返回 NGX_ERROR 后,返回错误码,error_page 配置发生了内部重定向,原本接下来的请求不会满足条件被拒绝。结果这次机会被内部重定向给占用了。所以即使设置了50%的拒绝,测试的结果却是100%拒绝。
static ngx_int_t
ngx_limit_act_parse(ngx_http_request_t *r, ngx_http_random_limit_node_t *lint, ngx_time_t *nt)
{
ngx_int_t chk_type_res;
ngx_int_t res = NGX_OK;
if (NULL != lint && lint->expire > nt->sec) {
lint->total_count += 1;
chk_type_res = ngx_limit_check_type(r);
if (chk_type_res == NGX_OK && (lint->limit_count * 100 < lint->total_count * lint->ratio)) {
lint->limit_count += 1;
res = NGX_ERROR;
}
if (lint->total_count > 100) {
lint->total_count = 0;
lint->limit_count = 0;
}
}
return res;
}
解决:
只需要在这个handler开始的地方判断一下,如果是内部重定向直接退出。
if (r->internal) {
return NGX_DECLINED;
}
有时候会需要把纵表转成横表。如下:
成绩A
| 姓名 | 科目 | 成绩 |
|---|---|---|
| 张三 | 语文 | 80 |
| 张三 | 数学 | 90 |
| 张三 | 英语 | 90 |
| 李四 | 语文 | 90 |
| 李四 | 数学 | 89 |
| 李四 | 英语 | 100 |
| 姓名 | 语文 | 数学 | 英语 |
|---|---|---|---|
| 张三 | 80 | 90 | 90 |
| 李四 | 90 | 89 | 100 |
select 姓名,
max(case 科目 when '语文' then 成绩 end) 语文,
max(case 科目 when '数学' then 成绩 end) 数学,
max(case 科目 when '英语' then 成绩 end) 英语
from 成绩A group by 姓名;
list和map设计了这个带实效时间的lru缓存代码。map用来存放应用名和应用等级用户等级的对应关系,list存放应用名的热数据和被lru剔除的数据的顺序。考虑到并不是所有的数据都是热点,把list分成三部分。前1/3是热点数据,后1/3是将被淘汰的数据,中间1/3是刚生成的数据。也就是说新的数据是插入到列表的1/3以后,不是直接插入列表头部。只有列表中已经存在的数据才会被插入到前1/3。而实效时间是通过查询的时候检查的,如果查询map`取到了该数据,且该数据已经过期,如果过期很久,直接删掉缓存返回空,如果刚过期那么删掉缓存返回该数据。根据业务的情况,刚过期的数据也是有效的。memcached。无论是存到哪里,都会有逃不掉的跨天问题。因为免费配额是按天来计算的,即每天自动补充。且免费配额分了两种一种是有个免费的量,用点就减少点,到第二天自动充满。还有一种就是一个阀值,超了阀值超过的收费。大概大家也猜到了,前面的是请求的量,后面的是存储的量。很显然存储的阀值根本不用缓存。首先有两个原则必须不能出错,1.用户今天的资源只能消费今天的免费配额。2.第二天必需补充满免费配额。否则的话就会有用户投诉了。有的用户没有费用,就靠着免费配额活着,如果在每天的第一条资源计费前没有补充了免费配额,用户应用可能就会被停掉。还有的用户每天恰好使用免费配额,如果今天的资源消费了昨天的免费配额,而昨天的免费配额恰好仅够昨天使用,如果今天的资源消耗了明天的免费配额,那么明天的免费配额就不够明天使用。怎么会有这种情况呢,开始我也没想到会出现这种情况。结果就会出现了,因为资源是从多台服务器推送过来的,资源的时间也就取的所属服务器的时间,而计费系统取得是计费服务器的时间,有的时候难免会有几秒几分的差异。就会在跨天的那几分钟出现上述的情况。还有就是处理数据的延迟性,计费的服务器已经是第二天了,推过来的数据还是前一天的。所以无论是以资源的时间为主还是以计费服务器的时间为主去更新免费配额缓存都会在跨天的时候出现问题。其实上述问题有个简单的方案就是在mc缓存的key加上资源的时间。就是说在每天的23:30到第二天的0:30这段时间,大部分的应用在mc里有两份数据。其实这样搞的话也没什么不可,无非就是多加点内存,mc在清理的时候消耗点资源。还有一个问题,就是很大一部分的应用量非常的大,在每天的前几十分钟就会用光所有的免费资源,而这天的剩下的二十多个小时再查mc已经变的毫无意义且还会拖慢计费程序的处理速度。还是有解决办法的,通过在mc的flag设置免费配额的时间,以减少mc缓存数据的量。在程序中根据当前计费系统的时间,以及mc中的flag还有资源的时间判断是否是真正的跨天还是资源数据抖动。通过在计费系统设置缓存,把以及用完免费配的用户的应用名缓存来解决这部分应用再随后的20多个小时不必再查mc缓存。当我们在代码里面curl一个url的时候,有时候会遇到一些奇葩的设计,url里有中文需要对url进行编码。如果直接调用url.QueryEscape转码,http.Get()时候会报错"unsupported protocol scheme"。如果不转码那么又会报http status 400.
那么,该怎么转码呢?go里貌似也没有一个现成的函数供直接转url的参数的。那就需要我们自己封装一个:
func UrlEncode(u string) (string, error) {
uary := strings.SplitAfterN(u, "?", 2)
if len(uary) == 2 {
m, e := url.ParseQuery(uary[1])
if e != nil {
return "", e
}
uary[1] = m.Encode()
}
return strings.Join(uary, ""), nil
}
补充16进制解码函数和2进制解码函数
package main
import (
"encoding/hex"
"fmt"
"strconv"
"strings"
)
func hexDecode(str string) string {
s := strings.TrimPrefix(strings.TrimPrefix(str, "0x"), "0X")
data, err := hex.DecodeString(s)
if err != nil {
return str
}
return string(data)
}
func binDecode(str string) string {
var sb strings.Builder
bt := []byte(strings.TrimPrefix(strings.TrimPrefix(str, "0b"), "0B"))
l := len(bt)
sb.Grow(l + 7)
for b, e := 0, (l-1)%8+1; e <= l; e += 8 {
c, err := strconv.ParseUint(string(bt[b:e]), 2, 32)
if err != err {
return str
}
sb.WriteString(string(c))
b = e + 1
}
return sb.String()
}
func main() {
fmt.Println(binDecode("0b01100001") == "a")
fmt.Println(binDecode("0B01100001") == "a")
fmt.Println(binDecode("01100001") == "a")
fmt.Println(binDecode("0b1100001") == "a")
fmt.Println(binDecode("0B1100001") == "a")
fmt.Println(binDecode("1100001") == "a")
fmt.Println(hexDecode(binDecode("0b001100100110011000110010001100000011011000110010")) == "/ b")
fmt.Println(hexDecode(binDecode("0B001100100110011000110010001100000011011000110010")) == "/ b")
fmt.Println(hexDecode(binDecode("001100100110011000110010001100000011011000110010")) == "/ b")
fmt.Println(hexDecode(binDecode("0b01100100110011000110010001100000011011000110010")) == "/ b")
fmt.Println(hexDecode(binDecode("0B01100100110011000110010001100000011011000110010")) == "/ b")
fmt.Println(hexDecode(binDecode("01100100110011000110010001100000011011000110010")) == "/ b")
fmt.Println(hexDecode(binDecode("0b1100100110011000110010001100000011011000110010")) == "/ b")
fmt.Println(hexDecode(binDecode("0B1100100110011000110010001100000011011000110010")) == "/ b")
fmt.Println(hexDecode(binDecode("1100100110011000110010001100000011011000110010")) == "/ b")
}优化2进制解码函数
func binDecode(str string) string {
var sb bytes.Buffer
bt := []byte(strings.TrimPrefix(strings.TrimPrefix(str, "0b"), "0B"))
l := len(bt)
sb.Grow(l + 7)
for b, e := 0, (l-1)%8+1; e <= l; e += 8 {
c, err := strconv.ParseUint(string(bt[b:e]), 2, 32)
if err != err {
return str
}
sb.WriteByte(byte(c))
b = e + 1
}
return sb.String()
}最近,越看别人写的go项目,越觉得要把go写的简洁易懂不是一件简单的事情,需要多看好的开源项目,多琢磨。以下会记录etcd项目里,个人感觉写的好的代码片段,供以后漫漫琢磨。
for _, u := range cfg.lpurls {
if u.Scheme == "http" && !cfg.peerTLSInfo.Empty() {
plog.Warningf("The scheme of peer url %s is http while peer key/cert files are presented. Ignored peer key/cert files.", u.String())
}
var l net.Listener
l, err = rafthttp.NewListener(u, cfg.peerTLSInfo)
if err != nil {
return nil, err
}
urlStr := u.String()
plog.Info("listening for peers on ", urlStr)
//下面这段代码,每次往栈里加一个函数,直到函数返回(包括出错返回),出栈函数执行,如果是因为失败返回,关闭所有的监听。
defer func() {
if err != nil {
l.Close()
plog.Info("stopping listening for peers on ", urlStr)
}
}()
plns = append(plns, l)
}PaaS平台提供了很多的服务,而各个服务的计费策略和计费项都有所不同,并且根据用户等级还会对某些服务的某些资源项有优惠啊,免费配额啊,分钟配额啊等等的需求。
因此,对计费服务是个大挑战,既要满足各种服务的计费策略,又要能够实时处理数据给用户展示和限制使用。具体的来说就是,计费服务需要根据用户的等级,应用的等级,用户的服务资源数据采取对应的优惠策略和计费策略,也需要检查用户的分钟使用量是否超出对应等级的配额,超过的还需要限制服务几分钟的使用。同时,又要对将来可能的计费策略和计费项做出可扩展。而云平台又有众多的应用跑在上面,每个服务的数据量有很大。
if-else。根据上述的特点,最终决定用golang写计费服务。整个计费服务分为4个业务逻辑子服务共10个环节和一个http子服务。每个子服务运行在一个goroutine中。逻辑子服务之间通过channel通信,计费逻辑子服务和http子服务之间通过共享内存通信。计费逻辑子服务完成计费的一些功能,http子服务提供一个运行时的查询。每个原始的子服务放在一个package中。所有的子服务的struct都要继承自一个baseSrv的服务,用以标准化子服务。
item的一个status状态表示还在套餐内,不需要计费,同时修改套餐已使用量。如果超出套餐用量,就修改item上一个status表示超出套餐用量,需要按照资源单价计费。item上的标签,计费没个计费项的费用,并填充bill成账单。inbyte 和 outbyte都要计费,而他们的单价不同,日免费配额不同。所以每项的费用也不同,因为有日免费配额的存在,每天早上和晚上的费用也不同。整个环节都是流式打标签的处理,即使不计费的数据,只要是合理的资源都会最终落地。在几个环节加入了锚点,通过在配置文件配置,可以实现不同服务资源映射、计费策略的差异
go tool pprof 来分析内存情况。示例配置文件:
/tmp/bill目录下,debug使用。ResDataCleaningV002方法特殊处理。mysql服务需要在资源映射环节调用BillingItemMappingV001方法特殊处理。http都在所有环节都调用默认的处理函数。mapping中配置了资源的格式。mysql的资源格式和其他的不一样,需要特殊配置。push和http的资源都使用默认的格式。### 通过在以下配置文件不同的环节配置funcs的数组,可以对指定的服务配置处理函数。
#bakPath 是资源备份路径,如果配置了该路径,就会把该环节接受到的资源备份,debug使用。
[cycle]
[cycle. PullResDataCycle]
bakPath = "/tmp/bill"
[cycle. ResDataCleaningCycle]
bakPath = "/tmp/bill/"
funcs = ["push:ResDataCleaningV002"]
[cycle.BillingItemMappingCycle]
bakPath = "/tmp/bill"
funcs = ["mysql:BillingItemMappingV001"]
[cycle.BillingCycle]
bakPath = "/tmp/bill"
funcs = []
[mapping]
[mapping.00000000]
mapFreq = ["Version", "App", "Service", "Inbyte", "Outbyte", "Request", "Nil", "Timestamp"]
mapStor = ["Version", "App", "Service", "Mem", "Disk", "Timestamp"]
[mapping.mysql]
mapFreq = ["Version", "App", "Service", "Inbyte", "Outbyte", "Request", "Timestamp"]
mapStor = ["Version", "App", "Service", "Disk", "Timestamp"]用go写了计费程序在本地起了个docker跑,跑几天就不行了。看了一下资源使用情况,发现有内存泄漏问题。
htop看这个进程,发现内存使用一直在慢慢增长。于是使用go提供的pprof来排查,发现程序自己写的几个方法的内存有增长,但增到一定程度就停止了。而go的time.NewTicker的内存却是始终增长稳定增长稳定。
排查了程序调用的几处NewTicker,发现有一处写在了for循环( 没有逻辑错误 )。写在循环外面再测试还存在泄漏的问题。把NewTicker换成Tick还有NewTicker的泄漏,看了下代码,Tick内部本身会调用NewTicker。
最后,把能改成After的都改成After,不能改的都加了ticker.Stop()。再测试就好了。
无论我再写多么简单的代码去重现这个问题,都未果。所以可能也不是调用了NewTicker没有Stop的问题。
我们fetchurl是用nginx正向代理功能来实现的。有开发者通过工单反馈请求api.sandbox.paypal.com/v1/oauth2/token 返回400。
找了paypal的官方实例测试。在fetchurl机器curl了一下返回200. 用fetchurl请求了一下返回400.
curl https://api.sandbox.paypal.com/v1/oauth2/token -v -H "Accept: application/json" -H "Accept-Language: en_US" -u "EOJ2S-Z6OoN_le_KS1d75wsZ6y0SFdVsY9183IvxFyZp:EClusMEUk8e9ihI7ZdVLF5cZ6y0SFdVsY9183IvxFyZp" -d "grant_type=client_credentials"
在测试环境修改/etc/hosts 添加 127.0.0.1 api.sandbox.paypal.com。
在测试环境用nc监听127.0.0.1的80 nc -l 127.0.0.1 80
用curl 和fetchurl分别请求一下这个url。
在nc捕获请求信息,对比发现除了fetchurl添加的两个请求头外还有http协议版本也不一样。
用curl请求https://api.sandbox.paypal.com/v1/oauth2/token 分别添加请求头和修改http协议版本,发现使用http1.0协议请求paypal会返回400.
可能是paypal不支持http1.0协议。通过修改测试环境fetchurl配置添加proxy_http_version 1.1; 重启测试,返回200了。
修改fetchurl配置添加:
proxy_http_version 1.1;
有开发者通过工单系统向我们反馈https外网访问返回502,而他本地访问是好的。通常这种情况一般是对端限制了我们的出口IP。
通分析发现是我们不支持SNI导致。对端的网站也是部署在云上的,各云计算公司为了节省资源,都是通过浏览器支持SNI实现多域名虚拟主机的SSL/TLS认证的。
外网http访问是通过我们的一个内部服务叫 fetchURL 来实现的。而当前我们 fetchURL 并不支持SNI。所以访问这类站点的时候会出现502。
最终,我们通过修改升级 fetchURL 支持了这个特性。
首先,在出口服务器上curl了一下这个url,看下是否被对端限制了我们的访问。通过 curl 的结果(如下)来看,
显示已经建立了tcp连接,是在ssl handshake的时候close connect。好像也并不是对端限制了我们的出口IP。同时看了下 fetchURL 的日志
SSL_do_handshake() failed (SSL: error:14077438:SSL routines:SSL23_GET_SERVER_HELLO:tlsv1 alert internal error),同样也是ssl handshake时发生了问题,同时我们可以更清晰的看到是在get server hello的时候出错的。
#出口服务器的curl:
$ curl -v 'https://aa.com/'
* About to connect() to aa.com port 443 (#0)
* Trying 104.24.1.1... connected
* Connected to aa.com (104.24.1.1) port 443 (#0)
* Initializing NSS with certpath: sql:/etc/pki/nssdb
* CAfile: /etc/pki/tls/certs/ca-bundle.crt
CApath: none
* NSS error -12286
* Closing connection #0
* SSL connect error
curl: (35) SSL connect error
GET_SERVER_HELLO 是什么意思?我们来看下ssl/tls握手。tls握手时,client先发出请求(ClientHello)把支持的tls版本、加密算法等发送到server。server确认应答(ServerHello)确认要使用的tls版本以及加密算法,如果client没有匹配的tls版本和加密算法,server就关闭加密通信。了解了tls握手协议后再看这个错误 SSL23_GET_SERVER_HELLO:tlsv1 alert internal error 就好解释了。为了验证是不是client不支持服务端的tls版本和加密协议,再来我本地的机器上curl看下,发现是用了这么一个加密算法 TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256。 我们不妨在出口服务器上指定该加密算法再 curl 一下,发现成功返回结果。
#本机的curl结果:
$ curl -v 'https://aa.com/'
* Rebuilt URL to: https://aa.com/
* Trying 104.24.1.1...
* Connected to aa.com (104.24.1.1) port 443 (#0)
* TLS 1.2 connection using **TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256**
* Server certificate: sni161691.aa.com
* Server certificate: COMODO ECC Domain Validation Secure Server CA 2
* Server certificate: COMODO ECC Certification Authority
* Server certificate: AddTrust External CA Root
> GET / HTTP/1.1
> Host: aa.com
> User-Agent: curl/7.43.0
> Accept: */*
# 出口服务器指定加密算法curl:
$ curl --ciphers ECDHE_ECDSA_AES_128_SHA -v 'https://aa.com'
* About to connect() to aa.com port 443 (#0)
* Trying 104.24.113.140... connected
* Connected to aa.com (104.24.113.140) port 443 (#0)
* Initializing NSS with certpath: sql:/etc/pki/nssdb
* CAfile: /etc/pki/tls/certs/ca-bundle.crt
CApath: none
* SSL connection using TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA
* Server certificate:
* subject: CN=sni161691.aaa.com,OU=PositiveSSL Multi-Domain,OU=Domain Control Validated
* start date: May 24 00:00:00 2016 GMT
* expire date: Nov 27 23:59:59 2016 GMT
* common name: sni161691.aa.com
* issuer: CN=COMODO ECC Domain Validation Secure Server CA 2,O=COMODO CA Limited,L=Salford,ST=Greater Manchester,C=GB
> GET / HTTP/1.1
> User-Agent: curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.19.1 Basic ECC zlib/1.2.3 libidn/1.18 libssh2/1.4.2
> Host: aa.com
> Accept: */*
通过修改并重新编译 fetchURL 添加tls版本和椭圆曲线公共密钥(ECC)加密算法。部署到测试环境后,抓该url依然返回502. 看了下错误日志还报 SSL_do_handshake() failed 。结合错误日志理了一下 fetchURL 的逻辑,fetchURL 是解析了域名后直接访问IP:PORT。dig 了一下这个域名,解析后的IP也是正确的。在我本机通过IP:PORT curl 了一下,发现有这么个警告 using IP address, SNI is being disabled by the OS。 看了下该网站是部署在了一个云计算平台上,可能用到了SNI支持多域名虚拟主机的SSL/TLS认证。因为我们就是这么搞的,在ClientHello阶段把Host带到server,server再加载对应host的证书在ServerHello阶段把证书和公钥等信息发给client。继续通过修改 fetchURL 在ClientHello同时发送host,编译后部署到测试环境,成功了。
# 在本地指定IP:PORT curl结果:
$ curl -vv 'https://104.24.1.1:443/' -H'host:aa.com'
* Trying 104.24.1.1...
* Connected to 104.24.1.1 (104.24.1.1) port 443 (#0)
* WARNING: using IP address, SNI is being disabled by the OS.
* Unknown SSL protocol error in connection to 104.24.1.1:-9838
* Closing connection 0
curl: (35) Unknown SSL protocol error in connection to 104.24.1.1:-9838
ay := make([]string, 3)
ay := append(ay, "0")
ay := append(ay, "1")
ay := append(ay, "2")
如果你没注意,像上面这段代码是有问题的, 你可以通过cap函数看下,你可以通过strings.Join(ay, "=")打出来看看。
上面的语句等价于make([]string, 3, 3) 第一个3表示的数组的长度,第二个3表示的是数组的容量。所以,你定义数组的时候应该是这样的make([]string, 0, 3),当然也可以不在定义的时候分配空间,像这样var ay []string,在append的时候分配空间,这样会有个问题就是append的时候,并不知道你有多少元素,因此append的时候,会在一定范围内把cap的值扩大二倍(这个得看append的源码),所以,如果你知道有多少元素,那么就建议你这样定义数组make([]string, 0, 3)。
它和map的定义不一样。如果像下面这样定义一个map,按照上面的逻辑,循环应该执行3次,只不过都是空而已。其实不是。
mm := make(map[string]int, 3)
fmt.Println(len(mm))
for k, v := range mm {
fmt.Println(k, v)
}
liwq:~/work$ sudo docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
35ca50e24dfa wenqianglee/billingd:s4 "/bin/sh -c '/etc/ini" 2 weeks ago Up 5 hours 0.0.0.0:8088->8088/tcp, 0.0.0.0:8099->8099/tcp gloomy_hawking
liwq:~/work$
liwq:~/work$ sudo docker cp 35ca50e24dfa:/usr/local/sae/billing/bin/rcdMerge ./.
liwq:~/work$ sudo docker inspect -f '{{.Id}}' 35ca50e24dfa
35ca50e24dfa9ac89c14c77cfc77682e67f27166eaac4a3b7847b1d0d69ec30b
liwq:~/work$ sudo cp rcdMerge_new /var/lib/docker/aufs/mnt/35ca50e24dfa9ac89c14c77cfc77682e67f27166eaac4a3b7847b1d0d69ec30b/usr/local/sae/billing/bin/.
/var/lib/docker/aufs/mnt. 该目录下有你曾经运行过的docker容器的文件系统。liwq:~/work$ sudo ls -l /var/lib/docker/aufs/mnt/35ca50e24dfa9ac89c14c77cfc77682e67f27166eaac4a3b7847b1d0d69ec30b/
总用量 76
dr-xr-xr-x 2 root root 4096 8月 11 12:03 bin
drwxr-xr-x 4 root root 4096 8月 20 19:08 dev
drwxr-xr-x 85 root root 4096 9月 8 14:37 etc
drwxr-xr-x 2 root root 4096 9月 23 2011 home
dr-xr-xr-x 9 root root 4096 6月 16 03:21 lib
dr-xr-xr-x 8 root root 4096 8月 11 12:03 lib64
drwx------ 2 root root 4096 6月 16 03:19 lost+found
drwxr-xr-x 2 root root 4096 9月 23 2011 media
drwxr-xr-x 2 root root 4096 9月 23 2011 mnt
drwxr-xr-x 2 root root 4096 9月 23 2011 opt
drwxr-xr-x 2 root root 4096 6月 16 03:19 proc
dr-xr-x--- 3 root root 4096 8月 25 19:58 root
dr-xr-xr-x 2 root root 4096 8月 11 12:03 sbin
drwxr-xr-x 3 root root 4096 6月 16 03:21 selinux
drwxr-xr-x 2 root root 4096 9月 23 2011 srv
drwxr-xr-x 2 root root 4096 6月 16 03:19 sys
drwxrwxrwt 3 root root 4096 9月 8 14:45 tmp
drwxr-xr-x 25 root root 4096 8月 21 20:45 usr
drwxr-xr-x 34 root root 4096 8月 25 18:49 var
上一篇学习docker的博文,介绍了一种生成image的方法:
docker run -ti wenqianglee/billingd:s1yum install sae-billingdexit后。docker commit [OPTIONS] CONTAINER [REPOSITORY[:TAG]]docker ps查看上述第三步完成后,环境就又多了一个docker image。可以用docker images 来查看。
那么,Dockerfile 有什么作用呢?也是生成image的一种方式,并且也是比较常用的一种。那我们把上述步骤转换为一个文件。
more Dockerfile
FROM wenqianglee/billingd:latest
RUN yum install sae-billingd
ENTRYPOINT /etc/init.d/billing start > /dev/null 2>&1 && /bin/bash
sudo docker build -t "wenqianglee/billingd:start" .docker images查看多了一个wenqianglee/billingd:start镜像Dockerfile支持的语法命令格式
INSTRUCTION argument
指令不区分大小写,但是约定大写。# 开始的行为注释。
一般的,Dockerfile 分为四部分:基础镜像信息、维护者信息、镜像操作指令和容器启动时执行指令。
FROM <image name>[:<tag>]MAINTAINER <author name>RUN <command>ADD <src> <destination>CMD command param1 param2EXPOSE <port>[ <port2> <port3> ...]ENTRYPOINT command param1 param2WORKDIR /path/to/workdirENV <key> <value>USER <uid>VOLUME ["/data"]参考:
Dockerfile指令
docker通过不同的网络命名空间实现网络栈的隔离。而不同的容器又需要通信。那docker是怎么实现的呢?docker进程启动的时候在root空间创建一个网桥。每个容器被隔离在不同的命名空间,root命名空间和容器命名空间之间通过veth对来通信。下面来模拟实现:
# 新建网桥并设置ip。
$brctl addbr brtest0
$ip addr add 172.17.42.11/16 dev brtest0
# 新建网络命名空间。
$ ip netns add ct0
$ ip netns add ct1
# 在root空间创建veth设备对。
$ ip link add vetht00 type veth peer name vetht01
$ ip link add vetht10 type veth peer name vetht11
# 把两个veth设备对的一端抛给新建的网络命名空间。
$ ip link set vetht01 netns ct0
$ ip link set vetht11 netns ct1
# 为网络命名空间的设备添加ip,并启动。
$ ip netns exec ct0 ip addr add 172.17.0.8/16 dev vetht01
$ ip netns exec ct1 ip addr add 172.17.0.9/16 dev vetht11
$ ip netns exec ct0 ip link set vetht01 up
$ ip netns exec ct1 ip link set vetht11 up
# 启动root空间的veth设备。
$ ip link set vetht00 up
$ ip link set vetht10 up
# 为新建的网络空间添加默认路由。
$ ip netns exec ct0 ip route add default via 172.17.42.11 dev vetht01
$ ip netns exec ct1 ip route add default via 172.17.42.11 dev vetht11
# 把root空间veth设备的一端设置到网桥上。
$ brctl addif docker0 vetht00
$ brctl addif docker0 vetht10docker container 的默认时间是utc的。不符合我们的习惯。修改时区不外乎就是修改/etc/localtime这个文件。
rm /etc/localtime && ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime-v /etc/localtime:/etc/localtimefunc (c *Client) onItem(item *Item, fn func(*Client, *bufio.ReadWriter, *Item) error) error {
addr, err := c.selector.PickServer(item.Key)
if err != nil {
return err
}
cn, err := c.getConn(addr)
if err != nil {
return err
}
defer cn.condRelease(&err)
if err = fn(c, cn.rw, item); err != nil {
return err
}
return nil
}
// Set writes the given item, unconditionally.
func (c *Client) Set(item *Item) error {
return c.onItem(item, (*Client).set)
}
func (c *Client) set(rw *bufio.ReadWriter, item *Item) error {
return c.populateOne(rw, "set", item)
}看memcache client 的代码 中的Set Add等好几个函数都是通过调用onItem传递一个函数实现的。看了onItem参数中函数,需要传三个参数,而传入的函数紧紧有两个参数。如果是c语言就会报错了。而go里在调用结构体的方法是可以的。看下面的例子,(*Hello).hi(hh, &s) 和 hh.hi(&s) 是等价的。
package main
import (
"fmt"
)
type Hello struct {
}
func (h *Hello) hi(s *string) error {
fmt.Println("hi", *s)
return nil
}
func main() {
var hh *Hello
var s = "liwq"
(*Hello).hi(hh, &s)
}苹果公司的编程语言,可以用来编写iOS OS X程序。基于Cocoa 和 Cocoa Touch 框架。支持面向过程和面面向对象编程。
不需要为了输入输出或者字符串处理导入一个单独的库。全局作用域中的代码会被自动当做程序的入口点,所以也不需要main函数。也不需要在每个语句结尾写上分号。
swift 包含了Int Float Double String 等基础类型,以及Array Set Dictionary 等集合类型。除此之外还提供了可以用来函数返回多个值的元组类型Tuple,还有可用来处理缺失情况的可选类型Optional。
和C语言一样使用// 作为单行注释。使用/* */作为块注释,块注释和C语言有一点不同就是可以嵌套。
另一个和C语言不同的地方是分号(;)的使用,swift不强制在每条语句后加分号,但是要在一行写多条语句时,中间必须用分号分割。
用let声明一个常量,用var声明一个变量。一个常量在编译的时候并不一定需要赋值,但是在使用前一定要赋值且只能赋值一次。常量和变量的类型必须和赋给他们的值的类型一致。声明时赋值可以不用指定类型,编译器可以自行根据值推导。如果声明时不能进行正确的推导出类型,需要显式的指定类型,在变量后加冒号加上空格然后加上一个类型(变量: 类型)。可以在一行中声明多个变量或常量,用逗号隔开。
如:
let a = 3
let a: Float64 = 4
var b: Int
var x = 1, y = 2, z = 3可以显式的转换类型。如:String(a) "I have \(a) apple"
使用[]来创建数组和字典。
如:
var emptyArray = String[]()
var shopArray = ["apple", "water"]使用if switch来进行条件操作,使用for-in for while do-while来进行循环。包裹条件和循环变量的括号可以省略,但是循环体的大括号必须不能省(和golang有点类似)。在if语句,条件语句必须是个布尔表达式(和c语言不同)。
a...b) 定义一个包含从a到b的所有值的区间。a..<b) 定义一个从a到b但是不包含b的区间。数组
append可以向数组中添加一个元素。+=可以加一个数组。isEmpty判断数组是否为空,使用count获取数组中元素的个数。insert(atIndex:x)可以在索引x前添加元素。removeAtIndex(x)可以移除索引为x的元素。使用removeLast方法可以移除数组最后一个元素。for-in遍历数组中的元素。var strArray: [String] = ["hello", "liwq"]
或者
var strArray = ["hello", "liwq"]例如:
import Foundation
var strArray: [String] = ["hello", "lee"]
println("\(strArray) count \(strArray.count)")
strArray += ["by", "zhouzhou"]
println(strArray)
strArray.append("lin")
strArray.insert("wenqiang", atIndex: 1)
println(strArray)
strArray.removeAtIndex(2)
println(strArray)
strArray.removeAll()
if strArray.isEmpty {
println("strarray is empty. count: \(strArray.count)")
}
结果:
[hello, lee] count 2
[hello, lee, by, zhouzhou]
[hello, wenqiang, lee, by, zhouzhou, lin]
[hello, wenqiang, by, zhouzhou, lin]
strarray is empty. count: 0Dictionary<KeyType, ValueType>定义,其中KeyType是字典中键的数据类型,ValueType是字典中对应于这些键所存储值的数据类型。for-in可以遍历字典的元素。import Foundation
var strDict: [String:String] = ["it1":"liwq", "it2":"zhouzhou", "it3":"dong"]
if !strDict.isEmpty {
println("dict: \(strDict) cout: \(strDict.count)")
}
for (k,v) in strDict {
println("\(k): \(v)")
}
结果:
dict: [it2: zhouzhou, it3: dong, it1: liwq] cout: 3
it2: zhouzhou
it3: dong
it1: liwqtime.Parse()time.Now().Format("20060102 15:04:05")time.Now().Unix()看个例子:
package main
import (
"fmt"
"time"
)
func main() {
const TF = "2006-01-02 15:04:05"
t, _ := time.Parse(TF, "2015-08-07 14:18:46")
fmt.Println(t.Local())
tt := time.Now().Format("20060102 15:04:05")
fmt.Println(tt)
ts := time.Now().Unix()
fmt.Println(ts)
}
运行结果:
$go run tTime.go
2015-08-07 22:18:46 +0800 CST
20150806 15:51:45
1438847505
这三种定时器,除了第一种有些区别,可以用在一些特殊的场合,其他两种基本一样。
看个例子:
package main
import (
"fmt"
"time"
)
func main() {
tk := time.NewTicker(1 * time.Second)
var i = 0
for i < 5 {
select {
case <-time.After(3 * time.Second):
fmt.Println("time after")
case <-time.Tick(5 * time.Second):
fmt.Println("time tick")
case <-tk.C:
fmt.Println("time new tick. stop")
tk.Stop()
}
i += 1
}
}
运行结果:
$go run tTick.go
time new tick. stop
time after
time after
time after
time after
time.NewTicker有个函数Stop,可以停掉这个定时器。
同事有个问题,go的定时器没有按时执行。
package main
import (
"fmt"
"time"
)
func main() {
ch := time.NewTicker(3 * time.Second)
defer ch.Stop()
for {
select {
case <-ch.C:
func() {
t := time.Now().String()
fmt.Println(t, "hello hello hello")
time.Sleep(5 * time.Second)
t2 := time.Now().String()
fmt.Println(t2, "sleep done")
}()
}
}
}
hello hello hello呢? 是5秒,不耍8秒也不是3秒。程序的任务会阻塞再次从channel取定时。但是不会阻塞定时的协程。func 前加上go 就是说任务是跑在协程里的。又是几秒打印一次hello hello hello呢,是3秒。R (TASK_RUNNING),可执行状态
S (TASK_INTERRUPTIBLE),可中断的睡眠状态
D (TASK_UNINTERRUPTIBLE),不可中断的睡眠状态
T (TASK_STOPPED or TASK_TRACED),暂停状态或跟踪状态
Z (TASK_DEAD – EXIT_ZOMBIE),退出状态,进程成为僵尸进程
X (TASK_DEAD – EXIT_DEAD),退出状态,进程即将被销毁
W 进入内存交换(从内核2.6开始无效)
< 高优先级
N 低优先级
L 有些页被锁进内存
s 包含子进程
开辟数组插入数据使用,如果有这样重复的动作,为了减少gc,应该使用缓存池。不过也可能gc优化不用这么写了。
package main
import (
"fmt"
"sync"
)
func main() {
var bytBuffPool = sync.Pool{New: func() interface{} { return make([]string, 0, 7) }}
ss := bytBuffPool.Get().([]string)
ss = append(ss, "hello")
ss = append(ss, "liwq")
ss = append(ss, "by")
ss = append(ss, "lee")
bytBuffPool.Put(ss)
s1 := bytBuffPool.Get().([]string)[:0]
s1 = append(s1, "test")
fmt.Println(s1, len(s1), cap(s1))
}最近同事碰到一个网络上的问题,简化后就是:发第一个包后会等待一小段时间再发第二个包,导致整个过程响应变慢。通过服务调用n次后,直接不能忍了。是由nagle算法引起的。
那么什么是nagle算法呢,为什么nagle算法会发完第一个包等待一小段时间再发第二个包呢,怎么解决这个问题呢?
再介绍上述问题前,先让我们再简单的复习一下tcp协议。
详细的介绍可以看陈皓的tcp的那些事儿(上) 和tcp的那些事儿(下)。 再详细的可以看《tcp/ip协议详解》。在此就不再累述了。
那么详细还是要说一下nagle算法。因为tcp是基于ip传输的,每次tcp传输要加上20字节的tcp头再加上20字节的ip头。所以如果我没次发一个字节就组成一个tcp包发送,额外需要发40个字节,还没有算链路层的剥头。发1KB的内容的小包,就额外发了4MB的包头,蛋疼的还不是多发了额外的4MB内容,而是,在整个网络中发了1000个小包。如果在广域网大部分机器都这么干,那么整个广域网有多少这样的小包,这么多小包难免会造成网络拥堵。而nagle算法就是为了避免这种小包而设计的一个合并算法。该算法要求一个tcp连接上最多只能有一个未被确认的未完成的小包,再该包的ack包到达之前不能发送其他的小包,除非超时或者是FIN包。具体的实现可以看代码tcp_nagle_check
那么上述现象就可以解释的通了。
首先发送端发送SYN, 接收端回SYN+ACK
发送端回ACK. 至此tcp连接成功。
发送端发了个小包到接收端。而接收端没立即回ACK.(为什么没立即回ACK,这和tcp协议实现有关系叫累积ack或者捎带ack,接收端在回ACK也等待了一段时间,等待发送端再发过来包一起回复ACK)
接收端没有给发送端回ACK,发送端也不知道这个包是否还在网络上。
而此时,发送端还要发送包,而这个包又是个小包,那么根据nagle算法,发送端就要等待合并。而发送端这是最后一个包再没有数据要发送了,所以发送端内核等待超时了,把这个小包发出去了。
接收端在收到这两个包以后,是个完整的内容了。应用层处理后给发送端回复结果,内核顺便把ACK带上回给发送端。
那这个问题怎么解决呢?通过下面的这个函数调用关闭nagle算法。
setsockopt(sock_fd, IPPROTO_TCP, TCP_NODELAY, (char *)&value,sizeof(int));
但是,在《unix网络编程卷1:套接字联网API》P173 推荐调用writev。
我个人还是觉得得看应用层的程序怎么写,是什么用途的。nagle算法为了防止广域网的小分组数目,在局域网应该并没什么卵用。
-- lua 类的定义
local _M = {}
function _M.New()
local o = {}
setmetatable(o, _M)
_M.__index = _M
return o
end
-- lua 类成员变量定义
_M.x = "lee"
-- lua 类方法定义
function _M:prt()
print("M:print")
end
-- lua 带参数的类方法定义
function _M:ppt(a)
print("M:ppt", self.x, a)
end
-- 实例化一个对象
local x = _M.New()
x:prt()
--[[ 为什么会输出lee呢,lee是类的成员变量x的值。
和前面总结的一样,首先会找该对象的x成员变量,而该对象没有该成员变量,
就会找其元表的__index方法,如果该方法是函数,就把函数的结果返回,如果该函数是类,就从
该类找对应的变量。
]]
x:ppt(2) -- M:ppt lee 2
-- 该对象定义了x成员变量,就输出了该对象的x成员变量了
x.x = "chou"
x:ppt(5) -- M:ppt chou 5
c语言实现:
#include <stdio.h>
#include <stdlib.h>
// 二分查找
int binary_search(int array[], int l, const int value) {
int left = 0;
int right = l - 1;
int middle = -1;
while (left <= right) {
middle = left + ((right - left) >> 1);
if (value > array[middle]) {
left = middle + 1;
}else if (value < array[middle]) {
right = middle - 1;
} else {
return middle;
}
}
return -1;
}
// 快速排序
void quick_sort(int array[], int left, int right) {
int i = left;
int j = right;
int x = array[left];
if (i < j) {
while (i < j) {
while (i<j && array[j] > x) {
j--;
}
if (i < j) {
array[i] = array[j];
}
while (i<j && array[i] < x) {
i++;
}
if (i < j) {
array[j] = array[i];
}
}
array[i] = x;
quick_sort(array, left, i-1);
quick_sort(array, i+1, right);
}
}
int main(int argc, char const *argv[])
{
int array[] = {4,5,3,1,2,6};
quick_sort(array, 0, 5);
int idx = binary_search(array, 6, 5);
printf("%d\n", idx);
return 0;
}go语言实现:
package main
import (
"fmt"
)
// 二分查找
func binary_search(array []int, l, value int) int {
left, right := 0, l-1
middle := -1
for left <= right {
middle = left + (right-left)>>1
if array[middle] > value {
right = middle - 1
} else if array[middle] < value {
left = middle + 1
} else {
return middle
}
}
return -1
}
// 快速排序
func quick_sort(array []int, left, right int) {
i, j, x := left, right, array[left]
if i < j {
for i < j {
for i < j && array[j] > x {
j--
}
if i < j {
array[i] = array[j]
i++
}
for i < j && array[i] < x {
i++
}
if i < j {
array[j] = array[i]
j--
}
}
array[i] = x
quick_sort(array, left, i-1)
quick_sort(array, i+1, right)
}
}
func main() {
test := []int{5, 3, 2, 4, 1, 6, 7}
quick_sort(test, 0, 6)
fmt.Println(test)
idx := binary_search(test, len(test), 3)
fmt.Println(idx)
}lua 实现:
function binary_serarch(t, l, v)
local i, j = 1, l
local m = -1
while i <= j do
m = math.ceil(i + (j - i) / 2)
if t[m] > v then
j = m - 1
elseif t[m] < v then
i = m + 1
else
return m
end
end
return -1
end
function quick_sort(t, l, r)
local i, j, x = l, r, t[l]
if i < j then
while i < j do
while i < j and t[j] > x do
j = j - 1
end
if i < j then
t[i] = t[j]
i = i + 1
end
while i < j and t[i] < x do
i = i + 1
end
if i < j then
t[j] = t[i]
j = j - 1
end
end
t[i] = x
quick_sort(t, l, i-1)
quick_sort(t, i+1, r)
end
end
t = {8,1,7,2,6,3,9,4,5,0}
quick_sort(t, 1, 10)
for _, v in ipairs(t) do
print(v)
end
print("search index:", bin_serarch(t, #t, 3))
二分查找的一个变种
从一个有序的数组中,把一部分数据和另一部分数据颠倒。查找出颠倒了数据的最大的值
就是从7,8,9,0,1,2,3,4,5,6这个数组中找到9
#include <stdio.h>
int search(int x[], int l, int r) {
int tl, tr, tm;
if (r == 0) return -1;
if (l == r && l > 0) {
return x[l-1];
}
tl = l;
tr = r;
tm = tl + (tr-tl-1)/2;
if (x[tl] > x[tm]) {
return search(x, l, tm-1);
} else {
return search(x, tm+1, r);
}
return -1;
}
int main() {
// int x[10] = {7, 8, 9, 0, 1, 2, 3, 4, 5, 6};
int x[1]={2};
int t = search(x, 0 , 1);
printf("%d\n", t);
return 0;
}二分法另一个变种用途:
一个排好序的数组,从该数组中找出某一个元素重复的次数。
例如:int a[10] = {0,1,2,3,3,3,3,3,4,5}; 从a数组中找出3重复的次数。
思路:利用二分查找找出3开始元素的下标和结束元素的下标,相减。
#include <stdio.h>
#include <stdlib.h>
int binSearch(int array[], int len, int islast, int x) {
int l = 0;
int r = len;
int m = - 1;
while (l <= r) {
m = (l + r) >> 1;
if (array[m] > x) {
r = m - 1;
} else if (array[m] < x) {
l = m + 1;
} else {
if (islast == 0) {
r = m - 1;
} else {
l = m + 1;
}
}
}
return m;
}
int main() {
int a[10] = {0,1,2,3,3,3,3,3,4,5};
int m = binSearch(a, 10, 0, 3);
int m2 = binSearch(a, 10, 1, 3);
printf("times: %d\n", m2 - m + 1);
return 0;
}线上环境用rsyslog把各服务的日志推到日志中心。有个别服务跑一段时间就会出现丢日志的情况。
问题是一同事排查的,我根据邮件整理记录以下:
从服务端rsyslog日志中查出了这个报错rsyslogd: received oversize message: size is N bytes max msg size is M, truncating...
分析发现每次丢日志都是因为size特别的大,超出了max msg size被截断。 而client发的日志没这么大的,也并没有多条合并。原因是因为日志的巧合而造成的。
client端没有设置EscapeControlCharactersOnReceive 参数,所以没有escape。
server端也没设置SupportOctetCountedFraming 参数,默认是开启的。那么服务端就会接受多条日志合并的,合并发送的格式大概是这样的size msg\nmsg\nmsg\n。
client没有escape,这样一条日志中如果有回车,如:hello world\n222223333 hello by lee就会造成服务端丢日志。服务端恰好错误的把日志的回车认为一条日志已经结束,而222223333认为是一条合并日志的长度,而服务端是设置了日志最大长度的。所以服务端会把合并的222223333日志截取前一段输出,其余的都丢弃。
如果222223333 后没有空格,认为日志格式错误,又会报这个错误Nov 19 16:03:13 Framing Error in received TCP message: delimiter is not SP but has ASCII value 45. 同样也会造成日志丢失。
解决方法:
开启客户端的escape。
最近在看nginx的源码的时候,看到调用ngx_events_block函数的一个参数是这样的conf = &(((void **) cf->ctx)[ngx_modules[i]->index]);.有点不解(为什么要取那个数组某个元素的地址呢),看了ngx_events_block函数的实现才明白。原来在函数内是要开辟一块内容付给conf这个变量的。
林锐博士在《高质量c、c++编程》中就已经指出这类容易犯错的地方。
如下面这段代码:
void GetMemory(char *p, int num) {
p = (char *)malloc(sizeof(char) * num);
}
void Test(void) {
char *str = NULL;
GetMemory(str, 100); // str 仍然为 NULL
strcpy(str, "hello"); // 运行错误
}如果函数的参数是一个指针,不要指望用该指针去申请动态内存。Test函数的语句GetMemory(str, 200)并没有使str获得期望的内存,str依旧是NULL,为什么?
毛病出在函数GetMemory中。编译器总是要为函数的每个参数制作临时副本,指针参数p的副本是 _p,编译器使 _p = p。如果函数体内的程序修改了_p的内容,就导致参数p的内容作相应的修改。这就是指针可以用作输出参数的原因。在本例中,_p申请了新的内存,只是把_p所指的内存地址改变了,但是p丝毫未变。所以函数GetMemory并不能输出任何东西。事实上,每执行一次GetMemory就会泄露一块内存,因为没有用free释放内存。
如果非得要用指针参数去申请内存,那么应该改用“指向指针的指针:
void GetMemory2(char **p, int num) {
*p = (char *)malloc(sizeof(char) * num);
}
void Test2(void) {
char *str = NULL;
GetMemory2(&str, 100); // 注意参数是 &str,而不是str strcpy(str, "hello");
cout<< str << endl;
free(str);
} awk是取自发明她的三位科学家的名字,擅长于文本处理。因最近又摊上计费这档子事情了。动不动就要给开发者查云豆消耗啊查云豆消耗。免不了要分析计费的日志。
awk 'BEGIN{ print "start" } pattern { commands } END{ print "end" }' file
也可以通过管道输入, 例如: cat file | awk 'BEGIN{ print "start" } pattern { commands } END{ print "end" }'
awk程序由三部分组成,BEGIN语句块,END语句块,能使用模式匹配的通用语句块。这三部分任何一部分都可以省略。BEGIN语句块完成一些初始化的工作,END语句块完成一些结果输出。模式匹配,逐行的读取匹配,如果匹配成功执行后面的commands
NR: 表示记录的数量(number of record),在执行过程中,相当于当前行号,是不断累加的。
NF: 表示当前行的字段数量(number of fields)
$0 这个标量包含执行过程中当前行的文本内容
$1~$n 当前记录的第n个字段,字段间由FS分隔
RS 输入的记录分隔符, 默认为换行符
OFS 输出字段分隔符, 默认也是空格
ORS 输出的记录分隔符,默认为换行符
FILENAME 当前输入文件的名字
| 格式符 | 说明 |
|---|---|
| %d | 十进制有符号整数 |
| %u | 十进制无符号整数 |
| %f | 浮点数 |
| %s | 字符串 |
| %c | 字符 |
| %p | 指针 |
| %e | 指数形式的浮点数 |
| %g | 自动选择合适的表达方式 |
$seq 5 |awk 'BEGIN{print "begin"}(NR > 2){print "command", $0}END{print "end"}'
begin
command 3
command 4
command 5
end
$seq 3 |awk 'BEGIN{print "begin"}{for (i=0; i<3; ++i) print "command", i}END{print "end"}'
begin
command 0
command 1
command 2
command 0
command 1
command 2
command 0
command 1
command 2
end
$awk 'BEGIN{msg="hello liwq"; print index(msg,"liwq")? "ok": "null"}'
ok
$cat ./test.log
hello liwq
hello zhoul
$awk '/liwq/{print}' ./test.log
hello liwq
$awk '!/liwq/{print}' ./test.log
hello zhoul
公司一组服务器,通过ping网关进行飘IP。然而自从加上以后就会在每天凌晨疯狂切换。从系统日志业务日志来看,业务访问是正常的。好像就丢ICMP回显应答包。大家也一致认为就丢ICMP回显应答包。
我记得这种ping应答已经内核回复了,即使网关不知道是哪家的,这个ping的处理差别不会太大。随后翻了下内核代码,如下。
只有下面这三种情况下是网络正常的。而这个程序一直运行,只有凌晨会出这个问题,而在这个过程中组装包是没问题的,目标ip就是网关ip也没问题,唯一不可确定的就是3了,网关是否关闭了ping回显应答。
- icmp 请求包错误。
- dst ip 是任播、广播地址。
- 关闭了icmp回显。
int icmp_rcv(struct sk_buff *skb)
{
struct icmphdr *icmph;
struct rtable *rt = skb_rtable(skb);
struct net *net = dev_net(rt->dst.dev);
bool success;
if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) {
struct sec_path *sp = skb_sec_path(skb);
int nh;
if (!(sp && sp->xvec[sp->len - 1]->props.flags &
XFRM_STATE_ICMP))
goto drop;
if (!pskb_may_pull(skb, sizeof(*icmph) + sizeof(struct iphdr)))
goto drop;
nh = skb_network_offset(skb);
skb_set_network_header(skb, sizeof(*icmph));
if (!xfrm4_policy_check_reverse(NULL, XFRM_POLICY_IN, skb))
goto drop;
skb_set_network_header(skb, nh);
}
__ICMP_INC_STATS(net, ICMP_MIB_INMSGS);
if (skb_checksum_simple_validate(skb))
goto csum_error;
if (!pskb_pull(skb, sizeof(*icmph)))
goto error;
icmph = icmp_hdr(skb);
ICMPMSGIN_INC_STATS(net, icmph->type);
/*
* 18 is the highest 'known' ICMP type. Anything else is a mystery
*
* RFC 1122: 3.2.2 Unknown ICMP messages types MUST be silently
* discarded.
*/
if (icmph->type > NR_ICMP_TYPES)
goto error;
/*
* Parse the ICMP message
*/
if (rt->rt_flags & (RTCF_BROADCAST | RTCF_MULTICAST)) {
/*
* RFC 1122: 3.2.2.6 An ICMP_ECHO to broadcast MAY be
* silently ignored (we let user decide with a sysctl).
* RFC 1122: 3.2.2.8 An ICMP_TIMESTAMP MAY be silently
* discarded if to broadcast/multicast.
*/
if ((icmph->type == ICMP_ECHO ||
icmph->type == ICMP_TIMESTAMP) &&
net->ipv4.sysctl_icmp_echo_ignore_broadcasts) {
goto error;
}
if (icmph->type != ICMP_ECHO &&
icmph->type != ICMP_TIMESTAMP &&
icmph->type != ICMP_ADDRESS &&
icmph->type != ICMP_ADDRESSREPLY) {
goto error;
}
}
//这个地方会掉下面那个函数
success = icmp_pointers[icmph->type].handler(skb);
if (success) {
consume_skb(skb);
return 0;
}
drop:
kfree_skb(skb);
return 0;
csum_error:
__ICMP_INC_STATS(net, ICMP_MIB_CSUMERRORS);
error:
__ICMP_INC_STATS(net, ICMP_MIB_INERRORS);
goto drop;
}
// sysctl_icmp_echo_ignore_all 内核这个参数设置为1不发ping回显
static bool icmp_echo(struct sk_buff *skb)
{
struct net *net;
net = dev_net(skb_dst(skb)->dev);
if (!net->ipv4.sysctl_icmp_echo_ignore_all) {
struct icmp_bxm icmp_param;
icmp_param.data.icmph = *icmp_hdr(skb);
icmp_param.data.icmph.type = ICMP_ECHOREPLY;
icmp_param.skb = skb;
icmp_param.offset = 0;
icmp_param.data_len = skb->len;
icmp_param.head_len = sizeof(struct icmphdr);
icmp_reply(&icmp_param, skb);
}
/* should there be an ICMP stat for ignored echos? */
return true;
}网关在那个时刻零时关闭ping回显应答的可能性不大。除此之外的情况,网络绝对是有问题的。而我什么业务没有问题呢?
go语言struct的tag,我没见其他语言有这个特性。这个特性在解析struct的时候非常有用。例如json的一些方法。
package main
import (
"encoding/json"
"fmt"
)
func main() {
response, err := json.Marshal(struct {
StatusCode int `json:"status_code,string"`
StatusTxt string `json:"status_txt"`
Data interface{} `json:"data,omitempty"`
}{
200,
"ok",
nil,
})
if err != nil {
fmt.Println(err.Error())
return
}
fmt.Println(string(response))
}
结果:
[23:15:39]liwq:~/Work/test $go run tJson.go
{"status_code":"200","status_txt":"ok"}tag的json后的第一个字符串是json显示的key。后面的string是要把数字转换为字符串。后面的omitempty表示如果为空,该值不输出。
如果把上述的tag都去掉,那么输出是这样的:{"StatusCode":200,"StatusTxt":"ok","Data":null}
是怎么通过tag实现上述功能的呢?请参考go的json.Marshal源码(src/encoding/json/encode.go)
原本计划使用自己开发的ngx_http_limit_ip_module来防攻击。最后运维组同事测试iptables要比在ngx做限制性能要好。遂决定用iptables。
封禁的规则是,如果数据分析系统或者计费系统分析出来某个域名被攻击,就在iptables加规制drop掉原攻击ip且访问的域名是攻击域名的数据包。这样一来,攻击者和服务器的tcp链接其实是已经建立的。只有在http协议发送host的时候才会drop掉对应的包。而发现攻击者的行为时发现发出去的包没有应答就一直发送直到超时,这样也大大延时了攻击者的攻击成本。但是不是最好的,因为服务器的tcp链接还是存在的。
把iptables的drop规则改为-j REJECT --reject-with tcp-reset在测试环境测试了几天,没出现异常。恰巧,当初有个攻击行为已经攻击了好几天了,遂上到了生产环境。不一会儿服务器500错误。登陆服务器查看文件描述符超限。分析一下原因是攻击者建好tcp链接发送host时,服务端的iptables把包drop掉且回了一个reset包,攻击端认为该请求被服务器关闭,遂立即重新发起新的链接。而服务器传输层的愿tcp链接其实并没有销毁。所以导致服务器文件描述符超出限制。
最后的策略是,应该让iptables把服务端的tcp链接reset掉,而不给客户端回包。这样攻击者就会等待超时而增加攻击成本,而服务器和攻击者的tcp链接也会有效的清除掉。
那怎么实现,原生的iptables是不支持这种策略的,无奈只能自己增加程序处理。而我们的做法是,使用ip_queue把拦截到的包从内核传到用户态,用户态程序拿到这个包把标志改为rst后再送回协议栈。
[MySQL] 2015/09/07 18:20:22 packets.go:32: unexpected EOF
[MySQL] 2015/09/07 18:20:22 statement.go:27: Invalid Connection
用go开发了个数据汇总的程序,每次执行总会报上述错误,然而业务处理程序并没这个问题,数据好像倒是正确的。看着这个报错总是不爽,怕是万一哪天抽疯可麻烦了。gihub上也有人问这样的问题,见 issues 。 试了各种go的版本,更新到最新的go-sql-driver也不行。
根据报错初步猜测可能是重建链接了,按照我碰到问题的代码写了个测试用例,然后在几个点设置断点观察和数据库的tcp链接。发现刚建好的链接状态就成了CLOSE_WAIT了。看了mysql的超时时间,wait_timeout 是10s。
调整了mysql的wait_timeout 也没管用。但是可以初步确定是这个问题导致了,接下来就看怎么设置这个 超时时间了。
DSN的说明 找到了答案。在dsn上添加wait_timeout=1000 后修改下面测试程序,问题解决了。
package main
import (
"database/sql"
"fmt"
_ "github.com/go-sql-driver/mysql"
"log"
"os"
"os/signal"
"syscall"
)
type TestMysql struct {
swsDb *sql.DB
sigCh chan os.Signal
}
func (tm *TestMysql) init() {
var err error
swsDsn := "liwq:liwq@tcp(127.0.0.1:11608)/user?timeout=15s&strict=true&allowOldPasswords=1"
tm.swsDb, err = sql.Open("mysql", swsDsn)
if err != nil {
log.Fatalf("open mysql error. error: %s", err.Error())
}
tm.swsDb.SetMaxOpenConns(5)
tm.sigCh = make(chan os.Signal)
signal.Notify(tm.sigCh, syscall.SIGINT, syscall.SIGTERM)
}
func (tm *TestMysql) query() {
sql := fmt.Sprintf("INSERT INTO Record_Merge_Test(Ak, Uid, Day, Type, ServiceCode, TotalBean) VALUES(?, ?, ?, ?, ?, ?)")
stmt, e := tm.swsDb.Prepare(sql)
if e != nil {
log.Fatalf("prepare sql error. error: %s", e.Error())
}
defer stmt.Close()
for i := 0; i < 2; i++ {
fmt.Println("crl+c goon...")
<-tm.sigCh
table := fmt.Sprintf("Record_%03d_20150828", i)
fmt.Println(table)
sql := fmt.Sprintf(`SELECT Uid, Ak, ServiceCode, Type, SUM(TotalBean) FROM %s GROUP BY Uid, Ak, ServiceCode, Type;`, table)
rows, err := tm.swsDb.Query(sql)
if err != nil {
log.Fatalf("query error. error: %s", err.Error())
}
defer rows.Close()
fmt.Println("begin to scan rows ...")
for rows.Next() {
var uid int
var ak string
var servicecode string
var typ string
var totalBean float64
err := rows.Scan(&uid, &ak, &servicecode, &typ, &totalBean)
if err != nil {
log.Fatalf("scan result error. err: %s", err.Error())
}
_, err = stmt.Exec(ak, uid, 20150828, typ, servicecode, totalBean)
if err != nil {
log.Fatalf("exec sql error. error: %s", err.Error())
}
}
err = rows.Err()
if err != nil {
log.Fatalf("scan result error. err: %s", err.Error())
}
}
}
func (tm *TestMysql) stop() {
tm.swsDb.Close()
}
func main() {
var tt TestMysql
tt.init()
tt.query()
fmt.Println("ctl+c stop")
<-tt.sigCh
tt.stop()
}
春哥(@agenzh)在今年开放出来ssl for lua的代码,支持在配置文件中修改证书,再加上浏览器支持sni,那么好玩的就多了.目前为止还没merge到master.
https://github.com/openresty/lua-nginx-module/tree/ssl-cert-by-lua
以下介绍源码安装:
Nginx的源码和ssl-cert-by-lua分支的lua-nginx-module的源码. git clone https://github.com/openresty/lua-nginx-module.git
git checkout ssl-cert-by-lua
git clone https://github.com/nginx/nginx.git
ssl-cert-by-lua用到了openssl库的新特新,所以需要openssl1.0.2版本以上的库. wget https://www.openssl.org/source/openssl-1.0.2a.tar.gz
tar -zxvf openssl-1.0.2a.tar.gz
echo等配置,所以还需要下载echo-nginx-module模块git clone https://github.com/openresty/echo-nginx-module.gitssl,修改了/src/event/ngx_event_openssl.c源码,所以需要先合并patch cd ./nginx/src/event/
patch -p3 < /home/liwq/work/git/lua-nginx-module/patches/nginx-ssl-cert.patch
configure开始编译./configure --prefix=/home/liwq/work/sbin/nginx --with-debug --with-http_addition_module --with-http_dav_module --with-http_flv_module --with-http_geoip_module --with-http_gzip_static_module --with-http_realip_module --with-http_secure_link_module --with-http_stub_status_module --with-http_ssl_module --with-http_sub_module --add-module=../ngx_devel_kit --add-module=../echo-nginx-module --add-module=../lua-nginx-module --with-openssl=../openssl-1.0.2a
make & make installserver{}结构配置中添加: location /test {
set $hi hello;
echo "$hi liwq";
}
nginx:sudo ./sbin/nginx -c ./conf/nginx.confcurl 'http://localhost/test'
hello liwq
设置了set_real_ip_from 以后proxy_add_x_forwarded_for 可能是有缺陷的。
set_real_ip_from是模块ngx_http_realip_module 的指令。 proxy_add_x_forwarded_for 是模块ngx_http_proxy_module的指令。
设置了set_real_ip_from ngx的 ngx_http_realip_module 模块 会按照set的信任ip修改remote ip。而proxy_add_x_forwarded_for 变量又会把remote ip添加到xfwf中。所以,过多层代理有时候X-Forwarded-For 会看到一样的ip被添加了多次,而没有中间代理的ip,就是这个原因造成的。
proxy_set_header 的val是可以设置多个变量拼接的。那么最简单的方法就是在ngx_http_realip_module模块提供一个和ngx连接的直接对端的变量(假如叫:conn_remote_addr),通过在代理配置proxy_set_header X-Forwarded-For "$http_x_forwarded_addr, $conn_remote_addr" 来替代proxy_add_x_forwarded_for变量。
local Base = {
name = "lee"
}
function Base.WakeUp(self, a)
print("base wake up ", self, a)
end
-- “:”定义的函数比“.”定义的函数多了一个self的隐藏形参,并且是作为第一个隐藏形参
function Base:Walk(a)
print("base walk ", self , a)
end
local Obj = {}
setmetatable(Obj, Base)
Base.__index = Base
print("-----1----")
Base.WakeUp(Base)
-- “:” 调用的函数比“.”调用的函数多隐藏的传递了自己
Base:WakeUp()
print("-----2----")
Obj.WakeUp(Obj)
Obj:WakeUp()
print("-----3----")
Base.Walk(Base)
Base:Walk()
print("-----4----")
Obj.Walk(Obj)
Obj:Walk()
结果:
-----1----
base wake up table: 0x000443e8 nil
base wake up table: 0x000443e8 nil
-----2----
base wake up table: 0x00044020 nil
base wake up table: 0x00044020 nil
-----3----
base walk table: 0x000443e8 nil
base walk table: 0x000443e8 nil
-----4----
base walk table: 0x00044020 nil
base walk table: 0x00044020 nil
今天看了下某个线上服务fd的使用情况,发现和mysql连接的有很多CLOSE-WAIT。
看了下tcp状态图,这个CLOSE-WAIT状态是已经建立好连接了,但是对端主动断开连接,而本端没有响应,所以产生的。就是说,这条连接的状态已经是ESTAB的,对端程序调用了socket.close()后,对端底层发送了FIN包,本端也回了ACK包。出现这个状况,说明对端已经没有消息再发送到本端了,如果本端也没有消息再发送到对端,本端也应该调用socket.close()。然而对于mysql这样的服务来说,服务端已经关闭连接了,无论你发送查询还是更新服务,他都不会给你回复消息。对于客户端来说已经无意义了,所以应该关闭这个链接再新建一个链接。
虽然实际上mysql客户端也是重建了链接的,但是却没有彻底关闭以前的链接,而这个CLOSE-WAIT会保留2个小时(默认,可以配置)后由系统再回收。
通过上述现象的产生就知道,调用socket.close(),那么问题来了,怎么判断对端已经关闭连接了呢,判断read的返回,该函数返回<=0。
至于,mysql怎么解决呢?网上说了几种方案,感觉调整系统参数靠谱一些,其他的都没试过。因为mysql断线重链是这样的,不知道是否有别的参数可以解决。
my_bool bopt = true;
mysql_options(mysql_, MYSQL_OPT_RECONNECT, &bopt);
__index
__newindex
__newindex元方法与__index类似,__newindex用于更新table中的数据,而__index用于查询table中的数据
__tostring
tostring会调用
__call
table作为方法调用时会调用该元方法。
--[[lua表,
找函数是找的该表的元表的__function,
找变量是先找该表的变量,如果没有则再找该表的元表的__index,如果该index是table,则从该table里找对应的变量,如果该index是function,直接返回该function的值。
]]
local y = {}
function y.__tostring()
return "i am y"
end
y.a = "yy-a"
local x = {}
setmetatable(x, y)
---0----
print(x)
----1----
y.__index = y
print(x.a)
-----2---
y.__index = function() return 300 end
print(x.a)
-----3---
x.a = "xx-a"
print(x.a)
结果
i am y
yy-a
300
xx-a
local t1, t2 = {}, {}
local t3, t4 = {}, {}
local arr = setmetatable({}, {__mode = "v"}) --可以k或v或kv
arr[1] = t1
arr[2] = t2
arr[t3] = "t3"
arr[t4] = "t4"
t1 = nil
t3 = nil
collectgarbage()
for k, v in pairs(arr) do
print(k, v)
end输出
#__mode = "k"
$ luajit ./t_test.lua
1 table: 0x0002d220
2 table: 0x0002d248
table: 0x000273a8 t4
#__mode = "v"
luajit ./t_test.lua
2 table: 0x00027438
table: 0x00027460 t3
table: 0x0002d220 t4function setmt__gc(t, mt)
local prox = newproxy(true)
getmetatable(prox).__gc = function() mt.__gc(t) end
t[prox] = true --关键,实际上是当t被回收时,prox也没有引用被回收。prox回收时会调用他元表的gc方法
return setmetatable(t, mt)
end
local iscollected = false
function gctest(self)
iscollected = true
print("cleaning up:", self)
end
local test = setmt__gc({}, {__gc = gctest})
collectgarbage()
assert(not iscollected)
test = nil
collectgarbage()
assert(iscollected)
function setmt__gc(t, mt)
local prox = newproxy(true)
getmetatable(prox).__gc = function() mt.__gc(t) end
--让t的生命周期关联到prox。当t被回收时,prox也没有引用被回收。prox被回收时调用他元表的gc。
t[prox] = true
return setmetatable(t, mt)
end
local iscollected = false
function gctest(self)
iscollected = true
print("cleaning up:", self)
end
local test = setmt__gc({}, {__gc = gctest})
collectgarbage()
assert(not iscollected)
test = nil
collectgarbage()
assert(iscollected)
nginx进程在启动后,ps看到的是每个进程的功能而不是启动时的命令行参数。那么nginx是如何做到的呢?
简单的说就是复写**argv。那我们也知道elf文件在最高地址处存放着命令行参数和环境变量。也就是说全局变量**argv和**environ是指向这个地方的字符数组的(在c里没有字符串)。那我们在复写argv的时候,如果内存不够长就会把环境变量也覆盖掉,甚至可能出现内存访问越界导致程序core掉。
肯定是要修改argv[0]达到修改进程名的,那nginx是怎么做的到呢?看代码。在nginx主函数调用了ngx_os_init函数,在ngx_os_init函数又调用了ngx_init_setproctitle函数。这个函数中先计算出环境变量的长度,在堆上分配这么大的一块内存,然后把环境变量的内容拷贝过去,修改*environ指针指向分配的堆内存。这样做就是不让set的title复写了环境变量。
nginx程序需要修改进程名时调用ngx_setproctitle函数,把title复写到argv[0]指向的内存。当然复写的时候也是调用了snprintf的,就是防止内存越界。
今天碰到一个问题,程序运行时找不到动态库libxxx.so.0。而这个动态库是我们自己写的,所以:
/etc/ld.so.conf文件中有配置,查看是否有LD_LIBRARY_PATH环境变量。最后,看了下我们自己的动态库,装的是libxxx.so,而需要的是libxxx.so.0。如果打包动态库的时候没有指定soname(简单共享名,Short for shared object name)那就需要手动加个软连接。很显然是没有指定,因为如果指定了的话,ldconfig -n . 就会自动生成。
具体看下是否指定了呢?
可以用readelf -d libxxx.so.1.0.1 命令看下,如果有SONAME这一行,说明是指定了的。没有则没有指定。
Dynamic section at offset 0x670 contains 21 entries:
Tag Type Name/Value
0x0000000000000001 (NEEDED) Shared library: [libc.so.6]
0x000000000000000e (SONAME) Library soname: [libxxx.so.0]
0x000000000000000c (INIT) 0x468
0x000000000000000d (FINI) 0x5d8
那么,明明有libxxx.so 我什么要找libxxx.so.0呢?
看下程序依赖的动态库,是libxxx.so.0 not found。
ldd xxx
linux-vdso.so.1 => (0x00007fff73bbb000)
libxxx.so.0 => not found
可以说,程序在编译的时候就确定让调用libxxx.so.0。看下程序编译时候的选项,也只能指定xxx呀-lxxx呀。我什么编译后的动态库需要libxxx.so.0,理论上应该是libxxx.so呀。猫腻在这个动态库,这个动态库指定了noname。让我们做个测试:
$ more hello.*
::::::::::::::
hello.c
::::::::::::::
#include <stdio.h>
#include "hello.h"
void hello(const char *s) {
printf("%s\n", s);
}
::::::::::::::
hello.h
::::::::::::::
void hello(const char *s);
编译,编译后也可以readelf -d libhello.so.1.0.1 看下。
gcc -fPIC -shared -Wl,-soname,libhello.so.1 -o libhello.so.1.0.1 hello.c
测试用例:
$ more test.c
#include <stdio.h>
#include "hello.h"
void main(void) {
char *s = "hello liwq";
hello(s);
return;
}
编译:
gcc -L./ -lhello -o test test.c
会报错:/usr/bin/ld: cannot find -lhello,因为-l指定的是hello,只能会找libhello.so。所以需要添加个软链接$ ln -s libhello.so.1.0.1 libhello.so
ldd test 看下,libhello.so.1 => not found 就是动态库的soname。
为了支持网络协议栈的多个实例,linux在网络协议栈引入了网络命名空间,这些独立的协议栈被隔离到不同 的命名空间中,处于不同的命名空间的网络协议栈事完全隔离的,彼此之间无法通信。docker 就是通过这种实现了不同容器之间的隔离。Veth这个设备对可以联通两个不同的命名空间,使得两个命名空间可以通信。
下面来模拟实现一下:
1. 创建一个命名空间。必须root用户。
$ ip netns add test0
查看命名空间
$ ip netns show
test0
查看命名空间下的设备,目前只有回环地址。
$ip netns exec test0 ip addr show
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2. 创建Veth设备对。
$ ip link add veth0 type veth peer name veth1
查看Veth设备对,成功创建了一对Veth。
$ ip link show
84: veth1@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT qlen 1000
link/ether ce:47:38:33:e6:91 brd ff:ff:ff:ff:ff:ff
85: veth0@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT qlen 1000
link/ether 72:cf:5b:14:f0:b5 brd ff:ff:ff:ff:ff:ff
3. 将其中的一个Veth设置到另个命名空间。
$ ip link set veth1 netns test0
再观察发现少了一组Veth设备
$ ip link show
85: veth0@if84: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT qlen 1000
link/ether 72:cf:5b:14:f0:b5 brd ff:ff:ff:ff:ff:ff
4. 设置ip并启动
设置命名空间test0的
$ ip netns exec test0 /bin/bash
$ ip link show
84: veth1@if85: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT qlen 1000
link/ether ce:47:38:33:e6:91 brd ff:ff:ff:ff:ff:ff
$ ip addr add 192.168.5.3/24 dev veth1
$ ip link set dev veth1 up
$ ip addr show
84: veth1@if85: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state LOWERLAYERDOWN qlen 1000
link/ether ce:47:38:33:e6:91 brd ff:ff:ff:ff:ff:ff
inet 192.168.5.3/24 scope global veth1
valid_lft forever preferred_lft forever
设置默认命名空间的
$ ip addr add 192.168.5.2/24 dev veth0
$ ip link set veth0 up
$ ip addr show
85: veth0@if84: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP qlen 1000
link/ether 72:cf:5b:14:f0:b5 brd ff:ff:ff:ff:ff:ff
inet 192.168.5.2/24 scope global veth0
valid_lft forever preferred_lft forever
inet6 fe80::70cf:5bff:fe14:f0b5/64 scope link
valid_lft forever preferred_lft forever
$ ping 192.168.5.3
PING 192.168.5.3 (192.168.5.3) 56(84) bytes of data.
64 bytes from 192.168.5.3: icmp_seq=1 ttl=64 time=0.084 ms
64 bytes from 192.168.5.3: icmp_seq=2 ttl=64 time=0.044 msgolang中提供了pprof的包用来查看go程序运行时的一些状态,比如:协程的数量、线程的数量、heap、block等等。
golang中提供了两个pprof包,一个是runtime/pprof,另一个是net/http/pprof。后者其实是封装了前者,用以web服务的性能监控。
下面是web服务的监控的一个例子:
package main
import (
"fmt"
"net/http"
httpprof "net/http/pprof"
"runtime"
"time"
)
type TT struct {
Name string
Age int
}
func handler(w http.ResponseWriter, r *http.Request) {
w.Header().Set("Content-Type", "text/plain")
httpprof.Handler("heap").ServeHTTP(w, r)
}
func index(w http.ResponseWriter, r *http.Request) {
w.Header().Set("Content-Type", "text/html")
httpprof.Index(w, r)
}
func test(cc chan *TT) {
for {
t := new(TT)
t.Name = "benz"
t.Age = 3
tt := time.NewTicker(1 * time.Second)
resend:
select {
case cc <- t:
case <-tt.C:
t.Age += 2
goto resend
}
}
}
func test2(c chan *TT) {
for {
head:
select {
case stu := <-c:
s := fmt.Sprintf("name: %s, age: %d", stu.Name, stu.Age)
fmt.Println(s)
time.Sleep(2 * time.Second)
case <-time.Tick(2 * time.Second):
fmt.Println("call times call")
goto head
}
}
}
func main() {
cc := make(chan *TT, 2)
runtime.GOMAXPROCS(runtime.NumCPU())
go test(cc)
go test2(cc)
http.HandleFunc("/debug", index)
http.HandleFunc("/debug/pprof/heap", handler)
http.ListenAndServe(":11181", nil)
}run 起来以后,可以通过访问http://127.0.0.1:11181/debug获得运行时的一些信息。
/debug/pprof/
profiles:
0 block
9 goroutine
1 heap
7 threadcreate
full goroutine stack dump目前,很多服务端程序都需要多个进程协作处理。然进程间通信就非常重用。
linux系统的进程间通信继承了unix的,即:AT&T的System V IPC和 BSD的socket IPC和最初的unix IPC。
IEEE还制定了POSIX标准的IPC,而linux在一开始就遵循该标准。那么POSIX的IPC有哪些呢?
pipe mkfifosignal sigactionmq_open mq_closeshm_opensem_opensocket具体使用可以参考后面列举的函数的man手册。 😄
git是一个版本控制软件。起初是为linux开发而设计的。
git 只关心文件数据的整体是否发生变化。git更像是把变化的文件作快照记录在一个微型的文件系统中。每次提交更新它会纵览一遍所有文件的指纹信息并对文件作一个快照,然后保存一个指向文件快照的索引。若文件没有变化,git不会再次保存,只是对上次的快照做个链接。
git 大多数的操作只需要访问本地文件和资源,因为git在本地磁盘保存了所有当前项目的历史更新。即使是提交更新也可以在没网的情况下执行,等到有网的时候在push到远程仓库。
在保存到git之前,所有的数据都要进行内容的校验和(checksum)计算,并将结果作为数据的唯一标识和索引。
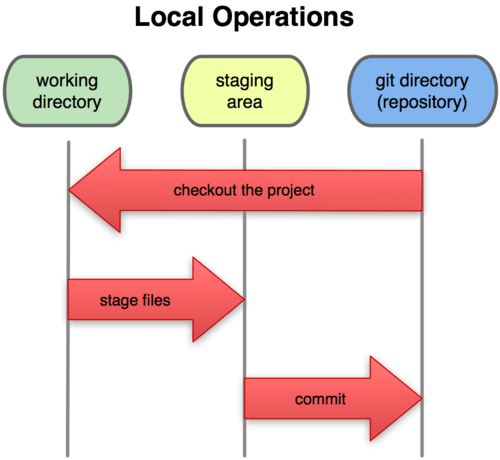
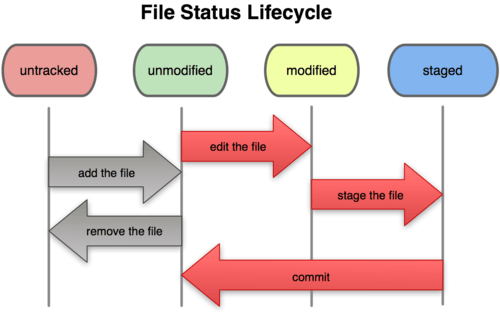
对于任何一个文件,在git内部只有三种状态:已提交(committed) ,已修改(modified) ,已暂存(staged) 。 已提交 表示该文件已经被安全的保存在本地数据库中了; 已修改 表示已经修改了该文件还没有提交保存; 已暂存 表示把已修改的文件放在下次要提交保存的清单中。
因此,git在管理项目时需要三个工作区域:git工作目录 , 暂存区域 ,本地仓库 。
每个项目都有个git目录,他是用来保存元数据和对象数据库的地方。每次克隆镜像仓库的时候其实就是拷贝的这个目录里的数据。
从项目中取出某个版本的所有文件和目录(这些文件其实是从git目录中的压缩对象文件中提取出来的),用于后续工作编辑的叫工作目录。
所谓的暂存区域其实只是一个简单的文件,一般放在git目录中。有时候也称为索引文件。
最基本的git工作流程:
所以,如果是 Git 目录中保存着的特定版本文件,就属于已提交状态;如果作了修改并已放入暂存区域,就属于已暂存状态;如果自上次取出后,作了修改但还没有放到暂存区域,就是已修改状态。
ubuntu下:sudo apt-get install git
git提供了一个命令git config用来修改或读取相应的工作环境变量。正是这些环境变量,决定了git在各个环节的工作方式和行为。这些变量可以存在这几个位置:
/etc/gitconfig 文件:系统中对所有用户都适用。使用git config --system读取的就是这个文件。
~/gitconfig文件: 适用于当前用户。使用git config --global读取的就是这个文件。
.git/gitconfig文件: 工作目录的这个文件,仅仅使用于当前项目。
一般配置一下几条就足矣:
git config --global user.name "liwq"
git config --global user.email [email protected]
git config --global core.editor vim
配置好了查看:git config --list
mkdir test
cd test
git init
echo "" > README.md
git add README.md
git commit -m 'add readme files'
执行完git init后就会在当前目录下生成一个.git的目录,所有git需要的数据资源都放在这个目录中。
如果是已经存在的项目,可以使用git clone [url] 把远端服务器的项目克隆到本地。执行完git clone url后,服务器上该项目的所有资源都已经在本地有了。git clone支持三种协议:https ssh 和 git
工作目录下的文件仅两种状态:已跟踪,未跟踪。
已跟踪的文件指本来已经纳入版本管理,在上次快照有该文件的记录,只不过可能他们的状态是未更新、已修改或已放入暂存区域。除此之外的其他文件都属于未跟踪。
git add 把新的未跟踪的文件加入暂存区域、把已跟踪已修改的文件加入暂存区域。
git status 查看git下的状态。Untracked files下的文件表示未跟踪。 Changes to be committed下的文件表示已经提交到暂存区域的文件。 Changes not staged for commit 表示已跟踪的文件已修改,但是还未放入暂存区域。
git commit -m 'commit message' 可以把暂存区域的更新提交到仓库。
git commit -a -m 'commit message' 可以把不在暂存区域的更新和在暂存区域的更新都提交到仓库。
一般有些文件不需要纳入git管理,比如:编译的中间文件或者日志文件等。只需要在项目目录下新建文件.gitignore, 把不需要纳入git管理的文件写到这个文件中。
格式规范如下:
要从git中移除一个文件,必需要从暂存区域移除然后提交到仓库。
git rm files 后 git commit -m 'commit msg' 如果文件已修改过且已经提交到暂存区域,删除的时候需要加强制的选项-f。 如果只是想删除暂存区域的文件,而并不想删除工作目录下的文件,删除的时候需要加--cached
git mv file_from file_to git commit -m 'commit message'
git log在项目中使用该命令,可以查看提交的所有历史信息。
会按照提交的时间列出所有的更新,最新提交的列在开始。每次提交都有一个SHA1的校验和提交人和邮箱还有提交的日志以及提交的说明信息。
git log有很多选项,可以用git help log查看,下面说明几个最常用的选项。-p:展开每次提交的内容差异。-n: n是数字,展示提交的个数。--word-diff 展示单词层面的差异,默认是行差异。新增加的单词被 {+ +} 括起来,被删除的单词被 [- -] 括起来。在进行单词层面的对比的时候,你可能希望上下文( context )行数从默认的 3 行,减为 1 行,那么可以使用 -U1 选项。--author 选项显示指定作者的提交。
有时候提交了,发现少提交了一些文件或者提交信息写错了,可以使用--amend 选项重新覆盖上次提交。
例如:
git commit --amend -m "new commit message"
当文件被git add当暂存区域时,可以使用git reset HEAD <file>来撤销。
git checkout --<file>
git remote [-v]
git remote add [shortname] [url]
git fetch [remote-name]
git fetch只是把远端的数据拉取到本地仓库,并不自动合并到前分支。
如果设置了本地某个分支自动跟踪远程仓库的分支,git pull可以自动同步远端的数据到本地。
git push [remote-name] [branch-name]
git remote rename 修改某个远程仓库在本地的简称。修改以后对应的分支也会发生变化。
git remote rm 删掉对应的远程仓库。
要彻底理解git分支,就得先了解一下git实现。在前面说过,git保存的是一些列文件的快照。在git提交时会保存一个commit对象,commit对象保存或指向了本次提交的一些信息(包括作者信息,校验和,提交目录等),还有一个或多个指向提交父对象的指针。多次提交以后,大概是下图这个样子的。
其实分支实际上就是指向commit对象的可变指针。git会使用master作为分支的默认的名字。
那么git是如何创建新的分支呢?使用git branch [branch-name] ,这会在当前commit对象新建一个分支指针。
这么多分支 ,git又是如何区分当前工作在哪个分支上呢?git保存着一个名为HEAD的特别指针,它指向正在工作的本地分支指针。可以通过使用git checkout [branch-name]来切换HEAD指针的指向。而在不同的分支上提交,只有对应的分支指针和HEAD指针会跟着移动,其他分支指针不动。如下图:
新建:
git checkout -b [new-branch-name]
或
git branch [new-branch-name]
git checkout new-branch-name
合并:
git merge [branch-name]
删除:
git branch -d [branch-name]
git branch 列出本地所有分支 。 加*的表示当前所在的分支。git branch -r 列出远程所有分支。git branch -v 列出分支最有一次commit的对象信息。git branch --[no-]merge 列出已经与当前分支合并(或未合并)的其他分支。远程分支(remote branch)是对远程仓库中的分支的索引。它们是一些无法移动的本地分支;只有在 Git 进行网络交互时才会更新。我们用 (远程仓库名)/(分支名) 这样的形式表示远程分支。
git checkout -b [分支名] [远程名]/[分支名] 跟踪远端分支
git push (远程仓库名) (本地分支名)[:(远端分支名)] 推送一个分支到远程仓库。如果是推送一个空的分支,就会把远程仓库的分支覆盖,这也是用来删掉远程分支的一个方法。例如:git push origin :test 删掉远端test分支。
参考:
pro git 教程
最近,又再重复着看nginx的代码。越看越激动,设计的如此精妙。代码写的也非常的好。
nginx是个非常强大的web服务器、反向代理服务器。他的强大之处离不开他的配置文件。那么配置文件是如何解析的呢?又是通过什么数据结构存放的呢?
首先,c函数从main开始执行,在main函数调用了ngx_init_cycle函数。在该函数中初始化了一个conf_ctx指针数组用来存放各个模块的配置文件结构体指针,随后又调用了所有NGX_CORE_MODULE模块的create_conf创建核心模块配置结构体。最后通过调用两个方法来解析命令行配置和文件配置指令。这两个函数分别是:ngx_conf_param和 ngx_conf_parse。前面是解析命令行配置参数,后面是解析文件配置参数。前面的函数最终还是调用了后面的,那我们直接看后面的函数,如果传入配置文件结构体指针不为空,那么打开配置文件读取配置文件指令。最后调用ngx_conf_handler解析配置指令,该方法才是解析配置文件最核心的方法,会根据配置指令遍历所有模块找到能解析该指令的方法,找到后调用对应模块的set方法。
上述从整体流程介绍了一下解析配置文件的过程。本节通过具体的函数说明一下。
./core/nginx.c:main
......
//根据编译生成的模块数组初始化每个模块的序号index。同时把模块的个数赋值给ngx_max_module
ngx_max_module = 0;
for (i = 0; ngx_modules[i]; i++) {
ngx_modules[i]->index = ngx_max_module++;
}
cycle = ngx_init_cycle(&init_cycle);
if (cycle == NULL) {
if (ngx_test_config) {
ngx_log_stderr(0, "configuration file %s test failed",
init_cycle.conf_file.data);
}
return 1;
}
......./core/ngx_cycle.c:ngx_init_cycle
......
//为所有模块建立一个指针数组,没个模块根据序号index对应一个指针
cycle->conf_ctx = ngx_pcalloc(pool, ngx_max_module * sizeof(void *));
if (cycle->conf_ctx == NULL) {
ngx_destroy_pool(pool);
return NULL;
}
......
//为核心模块(NGX_CORE_MODULE)分配结构体,具体有哪些核心模块呢?
//通过grep代码就可以知道。我们不解释了。解释关键的几个就可以说明问题了。
//第一个模块就是ngx_core_module 在nginx.c文件中。
//第二个模块是`ngx_events_module` 在ngx_event.c文件中。
//第三个模块是`ngx_http_module` 在ngx_http.c文件中。
for (i = 0; ngx_modules[i]; i++) {
if (ngx_modules[i]->type != NGX_CORE_MODULE) {
continue;
}
//指向核心模块的上下文
module = ngx_modules[i]->ctx;
//如果上下文中create_conf函数指针不为空,就执行该指针指向的函数,分配核心模块配置结构体。
//实际上我们要说的这三个模块,只有`ngx_core_module`模块设置了函数。
if (module->create_conf) {
rv = module->create_conf(cycle);
if (rv == NULL) {
ngx_destroy_pool(pool);
return NULL;
}
//把分配的结构体放到数组的对应下标中。实际上该数组的类型是void,你可以放入任何类型的值。
//实际上也确实是放入不同类型的值,只不过都是指针,有的是指针的指针的指针而已。
cycle->conf_ctx[ngx_modules[i]->index] = rv;
}
}看下核心模块上下文定义
core/ngx_conf_file.h
typedef struct {
ngx_str_t name;
void *(*create_conf)(ngx_cycle_t *cycle);
char *(*init_conf)(ngx_cycle_t *cycle, void *conf);
} ngx_core_module_t;上面说到只有ngx_core_module模块设置了函数指针,那来看下该函数:
static void *
ngx_core_module_create_conf(ngx_cycle_t *cycle)
{
ngx_core_conf_t *ccf;
ccf = ngx_pcalloc(cycle->pool, sizeof(ngx_core_conf_t));
if (ccf == NULL) {
return NULL;
}
/*
* set by ngx_pcalloc()
*
* ccf->pid = NULL;
* ccf->oldpid = NULL;
* ccf->priority = 0;
* ccf->cpu_affinity_n = 0;
* ccf->cpu_affinity = NULL;
*/
ccf->daemon = NGX_CONF_UNSET;
ccf->master = NGX_CONF_UNSET;
ccf->timer_resolution = NGX_CONF_UNSET_MSEC;
ccf->worker_processes = NGX_CONF_UNSET;
ccf->debug_points = NGX_CONF_UNSET;
ccf->rlimit_nofile = NGX_CONF_UNSET;
ccf->rlimit_core = NGX_CONF_UNSET;
ccf->user = (ngx_uid_t) NGX_CONF_UNSET_UINT;
ccf->group = (ngx_gid_t) NGX_CONF_UNSET_UINT;
if (ngx_array_init(&ccf->env, cycle->pool, 1, sizeof(ngx_str_t))
!= NGX_OK)
{
return NULL;
}
return ccf;
}我们回到ngx_init_cycle接着往下看。
ngx_cycle.c:ngx_init_cycle
......
ngx_memzero(&conf, sizeof(ngx_conf_t));
/* STUB: init array ? */
conf.args = ngx_array_create(pool, 10, sizeof(ngx_str_t));
if (conf.args == NULL) {
ngx_destroy_pool(pool);
return NULL;
}
conf.temp_pool = ngx_create_pool(NGX_CYCLE_POOL_SIZE, log);
if (conf.temp_pool == NULL) {
ngx_destroy_pool(pool);
return NULL;
}
conf.ctx = cycle->conf_ctx;
conf.cycle = cycle;
conf.pool = pool;
conf.log = log;
//注意下面这两个参数,一个是模块类型,一个是指令类型。
//从核心模块开始解析配置文件
conf.module_type = NGX_CORE_MODULE;
conf.cmd_type = NGX_MAIN_CONF;
#if 0
log->log_level = NGX_LOG_DEBUG_ALL;
#endif
//解析命令行配置,该函数还是调用了下面解析配置文件的函数。
if (ngx_conf_param(&conf) != NGX_CONF_OK) {
environ = senv;
ngx_destroy_cycle_pools(&conf);
return NULL;
}
//解析配置文件,第二个参数是通过命令行传入的配置文件
if (ngx_conf_parse(&conf, &cycle->conf_file) != NGX_CONF_OK) {
environ = senv;
ngx_destroy_cycle_pools(&conf);
return NULL;
}
......看下ngx_conf_parse函数的实现。该函数调用了ngx_conf_read_token和ngx_conf_handler。ngx_conf_read_token看起来很复杂,其作用就是解析配置文件中的指令,把指令存入cf->args数组中,例如:usr liwq;就会解析成[usr,liwq]。cf->args->elts[0]就是指令,cf->args->elts[1...]是指令的值。感兴趣的童鞋可以自己看一下源码,在此就不说明了。重点说下ngx_conf_handler,这才是解析配置文件核心调度函数。
为什么说是核心调度函数呢?看代码:
ngx_conf_file.c
static ngx_int_t
ngx_conf_handler(ngx_conf_t *cf, ngx_int_t last)
{
char *rv;
void *conf, **confp;
ngx_uint_t i, found;
ngx_str_t *name;
ngx_command_t *cmd;
name = cf->args->elts;
found = 0;
// 遍历所有的模块
for (i = 0; ngx_modules[i]; i++) {
cmd = ngx_modules[i]->commands;
if (cmd == NULL) {
continue;
}
//遍历每个模块的每个指令数组,找哪个模块的哪个指令能处理配置文件该指令。
for ( /* void */ ; cmd->name.len; cmd++) {
//指令名匹配
if (name->len != cmd->name.len) {
continue;
}
if (ngx_strcmp(name->data, cmd->name.data) != 0) {
continue;
}
found = 1;
//模块类型检查
if (ngx_modules[i]->type != NGX_CONF_MODULE
&& ngx_modules[i]->type != cf->module_type)
{
continue;
}
/* is the directive's location right ? */
//指令类型检查
if (!(cmd->type & cf->cmd_type)) {
continue;
}
if (!(cmd->type & NGX_CONF_BLOCK) && last != NGX_OK) {
ngx_conf_log_error(NGX_LOG_EMERG, cf, 0,
"directive \"%s\" is not terminated by \";\"",
name->data);
return NGX_ERROR;
}
if ((cmd->type & NGX_CONF_BLOCK) && last != NGX_CONF_BLOCK_START) {
ngx_conf_log_error(NGX_LOG_EMERG, cf, 0,
"directive \"%s\" has no opening \"{\"",
name->data);
return NGX_ERROR;
}
/* is the directive's argument count right ? */
//指令值的个数检查
if (!(cmd->type & NGX_CONF_ANY)) {
if (cmd->type & NGX_CONF_FLAG) {
if (cf->args->nelts != 2) {
goto invalid;
}
} else if (cmd->type & NGX_CONF_1MORE) {
if (cf->args->nelts < 2) {
goto invalid;
}
} else if (cmd->type & NGX_CONF_2MORE) {
if (cf->args->nelts < 3) {
goto invalid;
}
} else if (cf->args->nelts > NGX_CONF_MAX_ARGS) {
goto invalid;
} else if (!(cmd->type & argument_number[cf->args->nelts - 1]))
{
goto invalid;
}
}
/* set up the directive's configuration context */
//根据指令的类型,选择解析出的配置文件存放在哪,其实都是存在cycle->conf_ctx指针数组中,但是存在哪个数组的那一层中是不同的。
conf = NULL;
if (cmd->type & NGX_DIRECT_CONF) {
conf = ((void **) cf->ctx)[ngx_modules[i]->index];
} else if (cmd->type & NGX_MAIN_CONF) {
conf = &(((void **) cf->ctx)[ngx_modules[i]->index]);
} else if (cf->ctx) {
confp = *(void **) ((char *) cf->ctx + cmd->conf);
if (confp) {
conf = confp[ngx_modules[i]->ctx_index];
}
}
//调用具体的解析指令函数
rv = cmd->set(cf, cmd, conf);
if (rv == NGX_CONF_OK) {
return NGX_OK;
}
if (rv == NGX_CONF_ERROR) {
return NGX_ERROR;
}
ngx_conf_log_error(NGX_LOG_EMERG, cf, 0,
"\"%s\" directive %s", name->data, rv);
return NGX_ERROR;
}
}
if (found) {
ngx_conf_log_error(NGX_LOG_EMERG, cf, 0,
"\"%s\" directive is not allowed here", name->data);
return NGX_ERROR;
}
ngx_conf_log_error(NGX_LOG_EMERG, cf, 0,
"unknown directive \"%s\"", name->data);
return NGX_ERROR;
invalid:
ngx_conf_log_error(NGX_LOG_EMERG, cf, 0,
"invalid number of arguments in \"%s\" directive",
name->data);
return NGX_ERROR;
}其中定义在ngx_init_cycle 函数中,为核心模块分配了结构体,在ngx_conf_handler 函数中引用的。
// ngx_init_cycle 部分代码
for (i = 0; cycle->modules[i]; i++) {
if (cycle->modules[i]->type != NGX_CORE_MODULE) {
continue;
}
module = cycle->modules[i]->ctx;
if (module->create_conf) {
rv = module->create_conf(cycle);
if (rv == NULL) {
ngx_destroy_pool(pool);
return NULL;
}
cycle->conf_ctx[cycle->modules[i]->index] = rv;
}
}
// ngx_conf_handler 部分,
其中 NGX_DIRECT_CONF flag的,都使用了上述分配的结构体。
ctx不为空的情况,需要hanlder函数内部分配结构体。无论是框架分配还是主模块分配,实际上分配的都是一个数组(有的是一个数组,例如event模块。有的是多个数组,例如stream模块和http模块),数组每一项是对应模块的配置的结构体。
conf = NULL;
if (cmd->type & NGX_DIRECT_CONF) {
conf = ((void **) cf->ctx)[cf->cycle->modules[i]->index]; // 数组
} else if (cmd->type & NGX_MAIN_CONF) {
conf = &(((void **) cf->ctx)[cf->cycle->modules[i]->index]); // 数组
} else if (cf->ctx) {
confp = *(void **) ((char *) cf->ctx + cmd->conf);
if (confp) {
conf = confp[cf->cycle->modules[i]->ctx_index]; // 数组
}
}
rv = cmd->set(cf, cmd, conf);例如event core模块,分配的就是一个数组,然后再遍历event所有模块
static char *
ngx_events_block(ngx_conf_t *cf, ngx_command_t *cmd, void *conf)
{
char *rv;
void ***ctx;
ngx_uint_t i;
ngx_conf_t pcf;
ngx_event_module_t *m;
if (*(void **) conf) {
return "is duplicate";
}
/* count the number of the event modules and set up their indices */
ngx_event_max_module = ngx_count_modules(cf->cycle, NGX_EVENT_MODULE);
ctx = ngx_pcalloc(cf->pool, sizeof(void *));
if (ctx == NULL) {
return NGX_CONF_ERROR;
}
*ctx = ngx_pcalloc(cf->pool, ngx_event_max_module * sizeof(void *));
if (*ctx == NULL) {
return NGX_CONF_ERROR;
}
*(void **) conf = ctx;
for (i = 0; cf->cycle->modules[i]; i++) {
if (cf->cycle->modules[i]->type != NGX_EVENT_MODULE) {
continue;
}
m = cf->cycle->modules[i]->ctx;
if (m->create_conf) {
(*ctx)[cf->cycle->modules[i]->ctx_index] =
m->create_conf(cf->cycle);
if ((*ctx)[cf->cycle->modules[i]->ctx_index] == NULL) {
return NGX_CONF_ERROR;
}
}
}
......例如stream core模块,分配的就是一个结构体,该结构体包含的是2个数组,最后再调用stream模块回调函数分配对应模块的配置结构体,保存到数组中。
static char *
ngx_stream_block(ngx_conf_t *cf, ngx_command_t *cmd, void *conf)
{
char *rv;
ngx_uint_t i, m, mi, s;
ngx_conf_t pcf;
ngx_array_t ports;
ngx_stream_listen_t *listen;
ngx_stream_module_t *module;
ngx_stream_conf_ctx_t *ctx;
ngx_stream_core_srv_conf_t **cscfp;
ngx_stream_core_main_conf_t *cmcf;
if (*(ngx_stream_conf_ctx_t **) conf) {
return "is duplicate";
}
/* the main stream context */
ctx = ngx_pcalloc(cf->pool, sizeof(ngx_stream_conf_ctx_t));
if (ctx == NULL) {
return NGX_CONF_ERROR;
}
*(ngx_stream_conf_ctx_t **) conf = ctx;
/* count the number of the stream modules and set up their indices */
ngx_stream_max_module = ngx_count_modules(cf->cycle, NGX_STREAM_MODULE);
/* the stream main_conf context, it's the same in the all stream contexts */
ctx->main_conf = ngx_pcalloc(cf->pool,
sizeof(void *) * ngx_stream_max_module);
if (ctx->main_conf == NULL) {
return NGX_CONF_ERROR;
}
/*
* the stream null srv_conf context, it is used to merge
* the server{}s' srv_conf's
*/
ctx->srv_conf = ngx_pcalloc(cf->pool,
sizeof(void *) * ngx_stream_max_module);
if (ctx->srv_conf == NULL) {
return NGX_CONF_ERROR;
}
/*
* create the main_conf's and the null srv_conf's of the all stream modules
*/
for (m = 0; cf->cycle->modules[m]; m++) {
if (cf->cycle->modules[m]->type != NGX_STREAM_MODULE) {
continue;
}
module = cf->cycle->modules[m]->ctx;
mi = cf->cycle->modules[m]->ctx_index;
if (module->create_main_conf) {
ctx->main_conf[mi] = module->create_main_conf(cf);
if (ctx->main_conf[mi] == NULL) {
return NGX_CONF_ERROR;
}
}
if (module->create_srv_conf) {
ctx->srv_conf[mi] = module->create_srv_conf(cf);
if (ctx->srv_conf[mi] == NULL) {
return NGX_CONF_ERROR;
}
}
}
......写个类似的c函数模拟这几种情况
int test_nginx_conf(void) {
void *conf = NULL;
void ****conf_ctx = malloc(3 * sizeof(void*));
// NGX_DIRECT_CONF
conf_ctx[0] = malloc(sizeof(int));
// use
conf = ((void **) conf_ctx)[0];
*(int*)conf = 0;
// NGX_MAIN_CONF|BLOCK
conf = &((void **)conf_ctx)[1];
void ***ctx;
ctx = malloc(sizeof(void*));
*ctx = malloc(1 * sizeof(int*));
*(void **) conf = ctx;
(*ctx)[0] = malloc(sizeof(int));
// use
void **confp;
confp = *(void **)ctx;
conf = confp[0];
*(int*)conf = 1;
return 0;
}nsq 是个实时的分布式消息平台,每天可以处理上亿级别的消息。代码托管在github上,用go语言开发。
单个nsqd可以有多个topic,每个topic可以有多个channel。channel接受这个topic所有消息的副本,从而实现了消息的多播分发。而channel上每个消息被分发给它的订阅者,从而实现负载均衡。
Docker是开源引擎,可以为任何应用创建轻量级、可以移植的、自给自足的容器。
Docker的目标是实现轻量级的操作系统虚拟化解决方案。Docker的基础是Linux虚拟化(LXC)技术。
秒级启动;对系统资源利用率高,容器除了要运行应用外,基本不消耗额外的系统资源;强大的可移植性;更简单的管理。
Docker Images 是一个只读的模版,用来运行docker容器。
Docker Containers 负责应用程序的运行,包括操作系统、用户添加的文件以及原数据等。
Docker Index **registry,支持拥有私有公有访问权限docker容器的备份。
DockerFile 文件指令集,用来说明如何自动创建docker镜像。
Docker Daemon 运行在主机上,处理服务请求。
Docker Client 用户界面,支持与Daemon通信。
这些步骤都是从docker clinet开始的,client告诉docker daemon。daemon接受到任务后会构建一个镜像并运行容器。
构建镜像
Docker Images 是构建容器的一个只读模版,它包含了容器启动的所有信息,包括运行程序和配置数据。
每个镜像都源于一个基本的镜像,然后根据DockerFile中的指令创建,对于每条指令在镜像上创建一个新的层面。镜像创建完成后就可以推送到Docker Index了。
运行容器
当容器启动后,一个读写层被加添到镜像顶层,分配好合适的IP后,需要的应用就可以在容器中运行了。
看下图:

ubuntu 14.04
sudo apt-get update
sudo apt-get install -y docker.io
sudo ln -sf /usr/bin/docker.io /usr/local/bin/docker
sudo sed -i '$acomplete -F _docker docker' /etc/bash_completion.d/docker.io
sudo docker pull centos
sudo docker images
sudo docker run -t -i centos /bin/bash
sudo docker commit -m "added golang runtime" -a "wenqianglee" 8fa9c7f0265c wenqianglee/golang
完整示例
sudo docker images 22:55:58
REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
wenqianglee/golang beego 6749474ba1d6 4 hours ago 519 MB
wenqianglee/golang godoc 265268eb0d5e 5 hours ago 519 MB
wenqianglee/golang latest fca6aed9f9e6 7 hours ago 427.3 MB
centos
# 本机端口:docker容器端口。 可以制定监听的ip地址。
sudo docker run -i -t -p 80:6060 wenqianglee/golang:beego 22:56:06
[root@fdc81fb1ccf3 /]#
[root@fdc81fb1ccf3 /]#
[root@fdc81fb1ccf3 /]# godoc -http=:6060
这样在浏览器中访问本地ip地址,就可以访问到docker启动的go文档了。
同时,你可以用docker commit创建镜像,git push把镜像提交到仓库。这样其他人可以docker pull使用你的镜像。而不用在做安装godoc等操作。
是一个通过启动时-v映射的特殊目录,可以供一个或多个容器同时使用。可以提供很多特性
数据卷可以在多个容器之间共享和重用。
对数据卷的修改会立即生效。
对数据卷的更新不会影响容器。
数据卷默认会一直存在,即使容器被删掉。
在运行docker run命令时,可以通过 -v创建一个数据卷并挂在到容器里,多次使用可以挂载多个。
docker rm -v 删除容器的同时,添加-v可以同步删掉。
容器中运行了一些网络应用,例如“mysql”,“redis”等。要让外部的应用可以访问这些应用,可以通过参考-P或-p指定端口映射。多次使用可以绑定多个端口。
使用-P标记时,docker会随机映射一个49000~49900端口到内部开放的网络端口上。
使用-p标记时,可以指定映射的端口且在一个端口上只能绑定一个容器。支持的格式有:ip:hostPort:containerPort ip::containerPort hostPort:containerPort
容器互联(liking)是除端口映射外,另一种和容器中应用交互的方式。可以在源容器和接受容器之间建立一个隧道。
docker run添加--name 容器名来自定义容器名,如果没有该选项,docker会自动取一个名字。每个容器唯一对应一个名字。docker run添加--link another_container_name:alias_name 来实现和另一个容器互联。例如:
sudo docker run -ti --name db centos:redis /bin/sh
sudo docker run -ti -P --name web --link db:redis cents:web /bin/sh
ping redis
在终端创建一个容器,名字为db
在另一个终端创建另一个容器,名字为web。并让web连接db,重命名为redis。
在容器web中,可以ping一下redis这个容器,是有返回的。
docker启动时,会自动在宿主机上创建一个docker0的虚拟网桥。实际上是Linux的bridge,可以理解为一个软交换机。同时,docker会随机分配一个本地未占用网段中的一个地址给docker0接口。此后,启动的容器内的网口也会自动分配一个同网段的地址。
当创建一个docker容器时,同时会创建一对veth pair接口,这对接口一端在容器内(即:eth0),另一端在宿主机并被挂载到docker0网桥上,名字以vethXXXX格式命名。通过这种方式,容器可以和主机通信,docker之间也可以互相通信。docker就创建了主机和所有容器之间的一个虚拟共享网络。
其实,可以把docker0看成一个交换机,container看成一台电脑。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.