Information Retrieval Pipeline composed by a Corpus Reader, a Tokenizer and an Indexer.
In this project it is possible to limit the maximum amount of memory the program can use while indexing the collection.
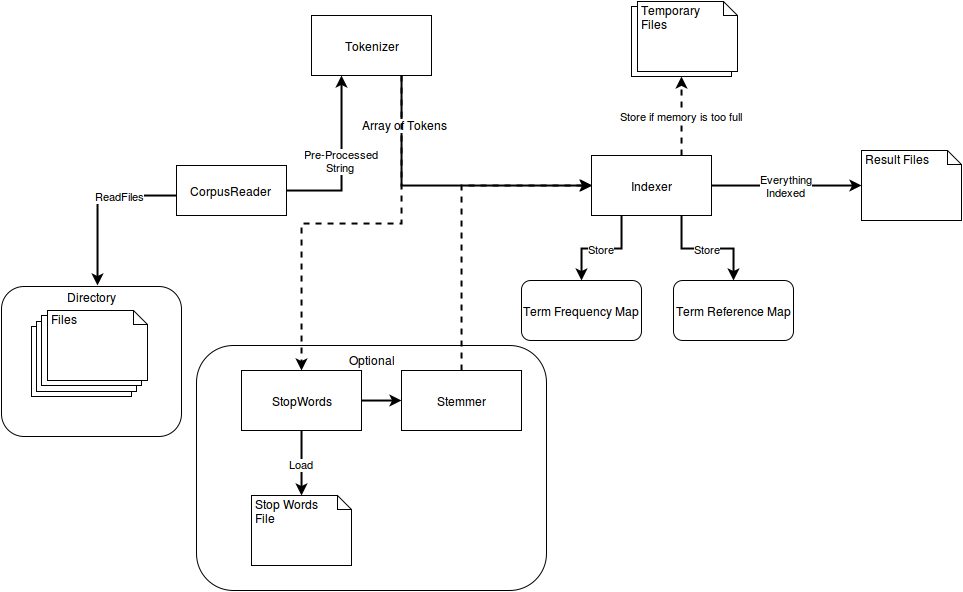
The Project has to be compiled before starting the execution.
(1) Index a document collection without a Stopwords filter and with no Porter Stemmer
java -Xmx512M -jar dist/ri_p2_63832_64191.jar -m 512 -i [collection_url]
(2) Index a document collection with Stopwords filter and Porter Stemmer:
java -Xmx512M -jar dist/ri_p2_63832_64191.jar -m 512 -i [collection_url] -dsw -ps
(3) Search Pipeline
java -Xmx512M -jar dist/ri_p2_63832_64191.jar -m 512 -dsw -ps -q
Netbeans project developed for Information Retrieval course with Miguel Vicente.


