torressa / cspy Goto Github PK
View Code? Open in Web Editor NEWA collection of algorithms for the (Resource) Constrained Shortest Path problem in Python / C++ / C#
Home Page: https://torressa.github.io/cspy/
License: MIT License
A collection of algorithms for the (Resource) Constrained Shortest Path problem in Python / C++ / C#
Home Page: https://torressa.github.io/cspy/
License: MIT License



![sourcery-ai[bot] avatar](https://avatars.githubusercontent.com/in/48477?v=4 "sourcery-ai[bot]")















































































Describe the bug
In preprocessing.py, the check for exceptions when where are no nodes violating the resource limit is tripped early by the "Source" or "Sink" node itself. The paths for these are necessarily 1 long, and may come up in the list comprehension before other actually resource constraint violated paths. The exception catches the index error, meaning we never add some of the violated nodes.
In large graphs, assuming a random order of keys in the dict, there is a smaller probability of this happening. But in small graphs, the chance of missing a node is much higher.
A somewhat related issue is that the node selected for removal may be wrong. By picking the next-to-last node in a path, we may be removing a node that is on some other path between the Source and the Sink. I think the correct node to remove should be the last node in the path, the one we cannot reach. There may be cases where we wouldn't even want to remove this node, I haven't examined all the possibilities.
To Reproduce
from cspy import BiDirectional
import numpy as np
import networkx as nx
from networkx import DiGraph
# make a simple graph, with labeled resource usage
# B clearly superfluous
# 1 1
# Source ---> A ----> Sink
# ^
# 10 \---->B
H = DiGraph(n_res=1)
max_res = [5]
min_res = [1]
H.add_edge('Source', 'A', res_cost=np.array([1]), weight=1)
H.add_edge('A', 'B', res_cost=np.array([10]), weight=1)
H.add_edge('B', 'A', res_cost=np.array([10]), weight=1)
H.add_edge('A', 'Sink', res_cost=np.array([1]), weight=1)
# seems to works, but error is masked
bidirec = BiDirectional(H, max_res, min_res, direction='forward', seed=42, preprocess=False)
bidirec.run()
print(bidirec.path, bidirec.total_cost, bidirec.consumed_resources)
bidirec = BiDirectional(H, max_res, min_res, direction='forward', seed=42, preprocess=True)
bidirec.run()
print(bidirec.path, bidirec.total_cost, bidirec.consumed_resources)
length_s, path_s = nx.single_source_bellman_ford(H, 'Source', weight=getw)
length_t, path_t = nx.single_source_bellman_ford(H.reverse(copy=True), 'Sink', weight=getw)
nodes_source = {}
nodes_sink = {}
# B should be identified (or rather A because of B)
# But get IndexError
try:
nodes_source.update({
path_s[key][-2]: (val, r)
for key, val in length_s.items()
if val > max_res[r] or val < min_res[r]
})
nodes_sink.update({
path_t[key][-2]: (val, r)
for key, val in length_t.items()
if val > max_res[r] or val < min_res[r]
})
except IndexError:
print(nodes_source, nodes_sink)
# Fix to check if key is already at Source or Sink
nodes_source.update({
path_s[key][-2]: (val, r) # I think this index should be -1
for key, val in length_s.items()
if key != 'Source' and (val > max_res[r] or val < min_res[r])
})
nodes_sink.update({
path_t[key][-2]: (val, r) # I think this index should be -1
for key, val in length_t.items()
if key != 'Sink' and (val > max_res[r] or val < min_res[r])
})
print(nodes_source, nodes_sink)
## But now node 'A' is slated to be removed, causing graph to be disconnected
H.remove('A')
bidirec = BiDirectional(H, max_res, min_res, direction='forward', seed=42, preprocess=False)
bidirec.run() # failureExpected behavior
preprocessing.py should ignore "Source" or "Sink" itself when checking related length keys. Further, the node to be removed should be the final node in the path, not the next to last, as that node may be required for other paths. There may be a more theoretically robust preprocessing that identifies offending edges and removes those; any nodes that become disconnected could then be safely removed.
Desktop (please complete the following information):
cspy 1.0.0a0numpy 1.19.2networkx 2.5Additional context
This bug can happen in modest size (say 25) random graphs with reasonable probability. I'd be happy to make a pull request if that's easiest, but I don't have a build system setup to run all the tests before submitting.
Describe the bug
When I am trying to use Bidirectional algorithm the REFCallback object is receiving nonexistent nodes as head and the partial path seems to be weird.
I am using the Algorithm to solve a RCSPP with capacity and time windows for a column generation problem with 1423 edges and 105 (107 with 'Source' and 'Sink') nodes. The problems arises when I try to build my own REFCallback class and using the forward direction. The REF_fwd function is receiving tail and head as numeric values even if all the nodes are strings as shown in next image:

I would assume that it is just cast problem but at some moment I receive the head 0 which does not exist in the Graph and I dont know if that zero is the Source or the sink, or just a wrong node

This didnt happened until I upgrade the package to v1.0.0 with pip, but I had to do this because the previous version was too slow to find a optimal solution which is unpractical for column generation. Am I doing something wrong?
To Reproduce
Steps to reproduce the behavior. Include minimal working example if available.
I will include the practical example I am using with a pickle graph that you can load with networkx, all the neccesary code is down below
`
from networkx import DiGraph
from cspy import BiDirectional, REFCallback
import networkx as nx
class MyCallback(REFCallback):
def __init__(self, arg1, arg2, max_res):
# You can use custom arguments and save for later use
REFCallback.__init__(self) # Init parent
self.G: arg1
self._arg2: bool = arg2
self.max_res = max_res
def REF_fwd(self, cumul_res, tail, head, edge_res, partial_path,cumul_cost):
res_new = list(cumul_res)
#Creciente
res_new[0] += edge_res[0]
#Capacidad
res_new[1] += edge_res[1]
print('Partial path:' + str(partial_path) + ' head:' + str(head))
new_time = max(res_new[2] + edge_res[2] + 15/60 , G.nodes[str(head)]['a'] )
res_new[2] = new_time
if new_time > G.nodes[str(head)]['b']:
res_new[3] = 1
return res_new
def REF_bwd(self, cumul_res, tail, head, edge_res, partial_path,cumul_cost):
res_new = list(cumul_res) # local copy
return res_new
def REF_join(self, fwd_resources, bwd_resources, tail, head, edge_res):
final_res = np.zeros(len(self.max_res))
return fwd_res
#Loads the pickle with networkx
G = nx.read_gpickle('graph_test.cspy')
resources = ['vstQty', 'Q', 'time', 'time-windows']
min_res = [0, 0, 0, 0]
max_res = [20, 30, 24, 1]
alg = BiDirectional(G, max_res=max_res, min_res=min_res, REF_callback=MyCallback(G, True, max_res),
direction='forward', elementary=True)
alg.run()
`
You can download the graph here
Expected behavior
A clear and concise description of what you expected to happen.
The head,tail should be string as the nodes in the graph, the partial path should have the 'Source' and 'Sink' nodes
Desktop (please complete the following information):
Suggestions
How would you suggest the problem be fixed?
Maybe the problem could be because I am using non-positive costs? maybe this is a problem with the connection to C++ backend with cpp?
The shortest path heuristic (used in both Tabu and GreedyElim) that deals with negative cycles is really slow.
Defined in
cspy/cspy/algorithms/path_base.py
Line 88 in 6ad0650
networkx.shortest_simple_paths function to filter the paths with negative reduced cost (if any) and returns the max_depth'th shortest path from this reduced set of paths.
Here are some ideas:
Every time the function is called, some sort of preprocessing can be applied to remove the negative cycles and solve the problem using a standard algorithm. Not sure how this would work or if it would remove most of the good paths.
However, this seems pretty similar to the existing version and is probably going to be slower.
Hi David,
I have noticed that if no feasible path is found, the following exception is raised:
Exception: Please call the .run() method first
This can happen in at least two situations:
min_res (or max_res) is too restrictivetime_limit)I think it would be nice to return None (in bidirec.path/bidirec.total_cost, etc), instead of raising the Exception. This way the user would know that there is nothing wrong with his data, its just that there is no feasible path. Also the current exception may be misleading as the .run() method was called, but it was just not able to find a path successfully.
@torressa @poulson I only found a couple of small issues:
pip install cspy does not automatically install the dependencies (tried on a clean pyenv)import cspy with from cspy import BiDirectionalfrom networkx import DiGraph line, replace G = nx.DiGraph(directed=True, n_res=2) with G = DiGraph(directed=True, n_res=2)n_nodes = len(self.J.nodes()) with n_nodes = len(G.nodes())cspy>=0.8 with cspy>=0.0.8. Unfortunately, I couldn't test it because it requires a proprietary package, gurobipy. @torressa is it possible to eliminate that requirement, or provide another real-world example that doesn't need that package?Inrich and Desaulniers (2005) should link to https://www.researchgate.net/publication/227142556_Shortest_Path_Problems_with_Resource_Constraints .Originally posted by @hausen in openjournals/joss-reviews#1655 (comment)
Describe the bug
For some reason, the forward direction tends to be faster than the bidirectional version.
This can be the case for some problems, but I've experienced it across several problems (Beasley and Christofides, Solomon and Augerat).
To Reproduce
Run any of the Beasley and Christofides, Solomon or Augerat instances with direction="forward" and then with direction="both" and see.
The first can be ran
cd tools/dev/
./build -b -sThe Solomon + Augerat can be ran by using vrpy (changing directions in subproblem_cspy.py) and running
python3 -m pytest -k cspy -s -v benchmarks/Suggestions
Starter
Search functionality (src/cc/search.h) into BiDirectional. I'm not entirely sure this would work, but I had the same issue when I had this structure in Python.Further
I've selected BiDirectional.init(G,max_res,min_res,U,L,direction,preprocess,REF_forward,REF_backward) for refactoring, which is a unit of 14 lines of code and 9 parameters. Addressing this will make our codebase more maintainable and improve Better Code Hub's Keep Unit Interfaces Small guideline rating! 👍
Here's the gist of this guideline:
You can find more info about this guideline in Building Maintainable Software. 📖
ℹ️ To know how many other refactoring candidates need addressing to get a guideline compliant, select some by clicking on the 🔲 next to them. The risk profile below the candidates signals (✅) when it's enough! 🏁
Good luck and happy coding! ![]() ✨ 💯
✨ 💯
Describe the bug
BiDirectional sometimes fails to find a feasible path, even in small graphs when other methods succeed. If BiDirectional is an exact method, it should be able to find the constrained shortest path (given enough time), right?
To Reproduce
from networkx import DiGraph
import numpy as np
from cspy import BiDirectional, GRASP
## make a small graph, only Source->3->6->Sink is feasible
max_res, min_res = [20,30], [1,0]
H = DiGraph(directed=True, n_res=2)
H.add_edge("Source", 3, res_cost=np.array([7,13]), weight=3)
H.add_edge(3, 0, res_cost=np.array([8,10]), weight=4)
H.add_edge(3, 6, res_cost=np.array([8,3]), weight=7)
H.add_edge(3, "Sink", res_cost=np.array([15,12]), weight=1)
H.add_edge(0, "Sink", res_cost=np.array([6,3]), weight=7)
H.add_edge(6, "Sink", res_cost=np.array([3,8]), weight=8)
bidirec = BiDirectional(H, max_res, min_res, seed=42)
bidirec.run()
print(bidirec.path, bidirec.total_cost, bidirec.consumed_resources) ## empty
gr = GRASP(H, max_res, min_res)
res = gr.run()
print(gr.path, gr.total_cost, gr.consumed_resources) # correctExpected behavior
Bidirectional should find the feasible path. In this case, it should print ['Source', 3, 6, 'Sink'] 18 [18. 24.].
Desktop (please complete the following information):
cspy 1.0.0a0numpy 1.19.2networkx 2.5Additional context
This occurs in many small random graphs I tried. Sometimes it seemed like removing extra edges made it able to discover the constrained shortest path. Changing the seed did not change the results of BiDirectional in 100 trials.
Compare BiDirectional implementation against Michael Drexl's 2006 implementation in the boost library.
Found here:
https://www.boost.org/doc/libs/1_62_0/libs/graph/doc/r_c_shortest_paths.html
The comparison can be done using the Beasley and Christofides (1989) benchmarks, already in the repo, along with some results.
Parsing + runner can be found in a unit test.
But they're also a bunch of other benchmarks to look at e.g. Zhu and Wilhelm.
Is your feature request related to a problem? Please describe.
The BiDirectional Algorithm does not terminate until either all the forward or backward labels have been processed. It would be good if a path joining algorithm would identify if/when two paths can be joined, hence terminating faster.
Describe the solution you'd like
Implementation of the path joining algorithm Righini and Salani (2006).
Describe alternatives you've considered
Additional context
jpath_preprocessing
A clear and concise description of what the bug is.
To Reproduce
link: https://cspy.readthedocs.io/en/latest/how_to.html#simple-example
code: from jpath_preprocessing import relabel_source_sink, add_cspy_edge_attributes
Expected behavior
Clear description on how to use the package.
Screenshots
error: ModuleNotFoundError: No module named 'jpath_preprocessing'
Is your feature request related to a problem? Please describe.
Vehicle routing problem with time-windows example.
Describe the solution you'd like
Implement Righini G. and Salani M. (2006) in examples/vrptw/.
Describe alternatives you've considered
Initial outline:
from networkx import DiGraph
from numpy import array
class VRPTW:
def __init__(self, some_args):
self.G = DiGraph(directed=True, n_res=2)
# Populate G. Resources represent
# [monotone, \tau, time-window feasibility]
# And nodes with for example
self.G.add_node(1, data={"time-window": (1, 2)})
self.G.add_node(2, data={"time-window": (1, 10)})
self.G.add_edge(1, 2, data={"travel-time": 1.5}, weight=10)
def custom_REF(self, cumulative_res, edge):
new_res = array(cumulative_res)
# your filtering criteria that changes the elements of new_res
# For example:
head_node, tail_node, egde_data = edge[0:3]
# There's a better way of doing this
head_node_w_data = list(
node for node in self.G.nodes(data=True)
if node[0] == head_node)[0]
tail_node_w_data = list(
node for node in self.G.nodes(data=True)
if node[0] == tail_node)[0]
a_j, b_j = tail_node_w_data[1]['data']['time-window'][0:]
new_res[0] += 1 # Monotone
new_res[1] += max(cumulative_res[1] + edge_data['travel-time'] +
edge_data['data']['travel-time'], a_j) # \tau
# Update time-window feasibility resource accordingly
if new_res[1] <= b_j:
new_res[2] = 0
else:
new_res[2] = 1
return new_resVersion: 0.1.2 (installed through pip)
In the following example, I expected BiDirectional to return the path Source -> A -> B -> C -> A -> Sink with cost -30. Instead, the path Source -> A -> Sink with cost 0 is returned.
The same behavior occurs with direction="forward" and elementary=False.
My best guess is that something is going on with negative cycles. In Issue #33 it is mentioned that the check was removed, and tests were done on vehicle routing problems. In vehicle routing, you typically try to avoid negative cycles anyways, so that could be a reason why everything seemed ok at that point.
from cspy import BiDirectional
from networkx import DiGraph
from numpy import array
G = DiGraph(directed=True, n_res=2)
G.add_edge("Source", "A", res_cost=array([1, 1]), weight=0)
G.add_edge("A", "B", res_cost=array([1, 1]), weight=-10)
G.add_edge("B", "C", res_cost=array([1, 1]), weight=-10)
G.add_edge("C", "A", res_cost=array([1, 1]), weight=-10)
G.add_edge("A", "Sink", res_cost=array([1, 1]), weight=0)
max_res, min_res = [5, 5], [0, 0]
bidirec = BiDirectional(G, max_res, min_res, direction="both")
bidirec.run()
print(bidirec.path)
Describe the bug
The is simply, I am trying to create my own REF_callback for a CG problem, so I need to use the REFCallback class, to create de forward, backward and join functions, but I cannot import the Class and apparently it doent exist. The docs seems outdated, I would like to know how to implement this in the 0.1.2 version thanks.
To Reproduce
Steps to reproduce the behavior:
pip install cspyfrom cspy import REFCallbackI've selected preprocessing.py:check(G,max_res,min_res,direc_in) for refactoring, which is a unit of 48 lines of code. Addressing this will make our codebase more maintainable and improve Better Code Hub's Write Short Units of Code guideline rating! 👍
Here's the gist of this guideline:
You can find more info about this guideline in Building Maintainable Software. 📖
ℹ️ To know how many other refactoring candidates need addressing to get a guideline compliant, select some by clicking on the 🔲 next to them. The risk profile below the candidates signals (✅) when it's enough! 🏁
Good luck and happy coding! ![]() ✨ 💯
✨ 💯
Describe the bug
I pip to install the 1.0.0-alpha version of cspy. It shows the installation is successful. But when I import cspy, I receive this:
ImportError: cannot import name '_pyBiDirectionalCpp' from 'cspy.algorithms'
Running on Mac with Python 3.8. Please let me know what do I need to do? Thank you!
Describe the bug
PSOLGENT is unable to recover paths when the node order taken (i.e. the edges) is not in the sorted order of the node names themselves. This is because when we convert the node scores to a path, there is a single fixed order or nodes (the sorted one). So pattern [1, 0, 0, 1, 1, 1] always refers to path Source -> 3 -> 4-> Sink, and never Source -> 4 -> 3 -> Sink. This severely limits what constrained paths can be found.
From the PSOLGENT paper, it's not clear that they address this. At the end of section 4.1, they mention that different orders "could be examined", but it's as though it's not a major concern to them. I might be missing some understanding of what exactly their variable neighborhood search accomplishes.
Either way, the cspy implementation doesn't seem to address this. Given a particular activation of nodes, there is a fixed set of edges produced, even if another ordering would be better (or feasible at all).
To Reproduce
from networkx import DiGraph
import numpy as np
from cspy import BiDirectional, PSOLGENT
## make a small graph, only Source->B->A->Sink is feasible
max_res, min_res = [10], [0]
H = DiGraph(directed=True, n_res=1)
H.add_edge("Source", 'A', res_cost=np.array([1]), weight=1)
H.add_edge('A', 'B', res_cost=np.array([9]), weight=1)
H.add_edge('A', 'Sink', res_cost=np.array([1]), weight=1)
H.add_edge('Source', 'B', res_cost=np.array([1]), weight=1)
H.add_edge('B', 'Sink', res_cost=np.array([1]), weight=1)
H.add_edge('B', 'A', res_cost=np.array([1]), weight=8)
bidirec = BiDirectional(H, max_res, min_res, seed=42, preprocess=False)
bidirec.run()
print(bidirec.path, bidirec.total_cost, bidirec.consumed_resources) ## ok
pso = PSOLGENT(H, max_res, min_res, seed=42, preprocess=False)
pso.run() # works ok here
print(pso.path, pso.total_cost, pso.consumed_resources) ## ok
# change only name of a node
nx.relabel_nodes(H, {'A':'C'}, copy=False)
bidirec = BiDirectional(H, max_res, min_res, seed=42, preprocess=False)
bidirec.run()
print(bidirec.path, bidirec.total_cost, bidirec.consumed_resources) ## still fine
pso = PSOLGENT(H, max_res, min_res, seed=42, preprocess=False)
pso.run() # unable to find path!Expected behavior
PSOLGENT should be able to find paths where nodes occur out of their sorted order.
Desktop (please complete the following information):
cspy 1.0.1Suggestions
One approach would be to add another "position" to each node in the PSO. This second position would be use to determine the order of nodes when converting to a path. It could be arbitrary reals just like the "node activation" position value, and we would sort the nodes according to this 2nd learned value.
While I think this could work, this is just a hypothesis. The PSOLGENT paper doesn't mention anything like this. We'd be doubling the number of dimensions, which will slow things down.
I'm not sure how other PSO-type path finding schemes address this issue. It might be in the neighborhood search part of the paper that I haven't thought through fully. If there's an existing methodology, perhaps we should do that. If my above idea is untested in the literature, that might be an interesting research problem.
Is your feature request related to a problem? Please describe.
There is no time limit for the algorithms.
Describe the solution you'd like
I would like a new parameter time_limit in the algorithms that forces the current solution to be the final one.
Given that the heuristics (Tabu and GreedyElim) stop as soon as a resource feasible path has been found, it makes more sense to include it for the others.
Linked to Kuifje02/vrpy#19
From openjournals/joss-reviews#1655 (comment)
Hi, first I'd like to say, thank you so much for your wonderful work.
I've been using cspy by pip install cspy (Mac OS version 11.5.2, python 3.8) and it works great.
I am trying the bidirectional functions and want to change the weight of the graph more flexibly, during the labeling algorithm itself.
So I'd love to debug things, except the cspy wheel doesn't really build successfully with CMake.
Specifically, this line cmake --build build --config Release --target all -v doesn't work and outputs
ERROR: Could not find a version that satisfies the requirement cspy (from versions: none)
ERROR: No matching distribution found for cspy
I just saw a comment that says "os: [macos-latest] # 10.14 and 11 don't work" in release.yml.
Is there anything I can do to make a wheel work please?
I would really appreciate your help!
Soomin
No longer working as the build process is more complex
For the local best value only one of the first three particles are taken
I am not good in Python and so I am not sure about this, but from what I can see in the source code and my examples:
neighbourhood_size = 3
self.local_best = array([self.pos[argmin(self.fitness[bottom:top])]] *
self.swarm_size)
The line above takes in that case 3 fitness values (depending on the iteration) and then takes from the minimum the index. But NOT the index from self.pos for this fitness value, but for me, this always leads to the index 0, 1 or 2, depending on which fitness value is the lowest. But then from the array self.pos the index 0, 1 or 2 is taken as local best value. Even if one has considered the fitness values with higher index.
Regardless of this, I don't quite understand the way to tie the neighborhood to the iteration. Should not actually (according to Marinakis) the neighborhood of each particle be considered separately? In the PSOLGENT variant this also increases depending on whether an improvement takes place or not. With a static neighborhood, this would then be the PSOLGNT variant.
Please enlighten me and help me to find my thinking error :)
Describe the bug
A clear and concise description of what the bug is.

Desktop (please complete the following information):
When there are only 3 nodes including Source and Sink, the birectional algorithm (I have not tried the other ones) does not run.
Example :
G = DiGraph(directed=True, n_res=2)
G.add_edge("Source", "A", res_cost=array([1, 2]), weight=0)
G.add_edge("A", "Sink", res_cost=array([1, 10]), weight=0)
max_res, min_res = [4, 20], [1, 0]
bidirec = BiDirectional(G, max_res, min_res, direction="both")
bidirec.run()
print(bidirec.path)
The following exception is raised : Exception: Please call the .run() method first
Is your feature request related to a problem? Please describe.
I don't like that the algorithms only return the path in a list, I would like the path cost and total resource consumption.
Describe the solution you'd like
I would like the option to get the total_cost attribute, and the consumed_resources attribute.
I would like to access them as for e.g.
algorithm(args).run()
# Finds shortest path with resource constraints
algorithm.path
algorithm.total_cost
algorithm.consumed_resourcesDescribe alternatives you've considered
Adding them as class attributes would mean implementing an appropriate destructor __del__ operator to avoid weird behaviour.
Additional context
Similar to networkx's shortest_path and shortest_path_length
Write input checks for grasp.py and psolgent.py
Describe the bug
When running the BiDirectional algorithm in both directions and using custom REFs, the resulting consumed_resources attribute is wrong.
Is your feature request related to a problem? Please describe.
I'd like an interface for
Describe the solution you'd like (For Julia)
Julia interface file that directly calls the shared object.
Describe the solution you'd like (For C#/Java)
The cmake of this project is based on cmake-swig.
So it shouldn't be too hard to repeat the process of the python interface with C# and Java.
Update cmake/:
I left the includes in the main cmake file:
Lines 122 to 124 in f506650
dotnet.cmake and java.cmake files in the cmake/ folder.
Add SWIG interface files.
The swig and cmake files that would build these would be placed in src/cc/[java|dotnet] in a similar fashion as the original repo.
Language specific tests under test/[java|dotnet]. Should include unittests for BiDirectional, some issue specific tests and the custom REF callback test (similar to the python one in test/python/tests_issue32.py)
Update the docker file and github workflows to run these tests and make sure everything works as expected.
PSOLGENT has a check for prospective paths that demands they involve at least 3 nodes. This misses the edge case where the Source has an edge connecting directly to the Sink. Is this just a typo, and len(path) >= 2 was intended? Strictly speaking, even length 1 shouldn't throw an error, since one could access both path[0] and path[-1], though obviously they can't both match.
cspy/src/python/algorithms/psolgent.py
Line 333 in 083f25c
I've selected BiDirectional.algorithm(direc) for refactoring, which is a unit of 48 lines of code. Addressing this will make our codebase more maintainable and improve Better Code Hub's Write Short Units of Code guideline rating! 👍
Here's the gist of this guideline:
You can find more info about this guideline in Building Maintainable Software. 📖
ℹ️ To know how many other refactoring candidates need addressing to get a guideline compliant, select some by clicking on the 🔲 next to them. The risk profile below the candidates signals (✅) when it's enough! 🏁
Good luck and happy coding! ![]() ✨ 💯
✨ 💯
For some real cases, the BiDirectional algorithm is slow and sometimes stalls.
Here are some thing that can be done to speed things up.
best_labels so that dominance rules don't have to be applied twice.How often dominated labels are checked affects the algorithm, checking it after every iteration is probably not the best idea.
In the non-elementary case, the dominated label and all of its extensions can be discarded, providing a significant speed up. In the elementary case a similar rule can be applied.
See Irnich and Desaulniers (2005) page 15.
If a threshold cost is given, the joining procedure can be stopped early if the resulting path has a total cost under the threshold. In the column generation setting, the threshold would be 0.
A possibility is to translate the algorithm into C++ and call it from python.
I have a terrible implementation in parallel using ray that works for some toy cases. However, as soon as you start passing custom REFs everything starts exploding. Even though I don't like the extra dependency it's pretty convenient as there are some shared arrays between the forward and backward processes.
speedups branch.Some profiling with line_profiler (cspy.BiDirectional) :
~77% of the time is consumed by self._algorithm(direct)
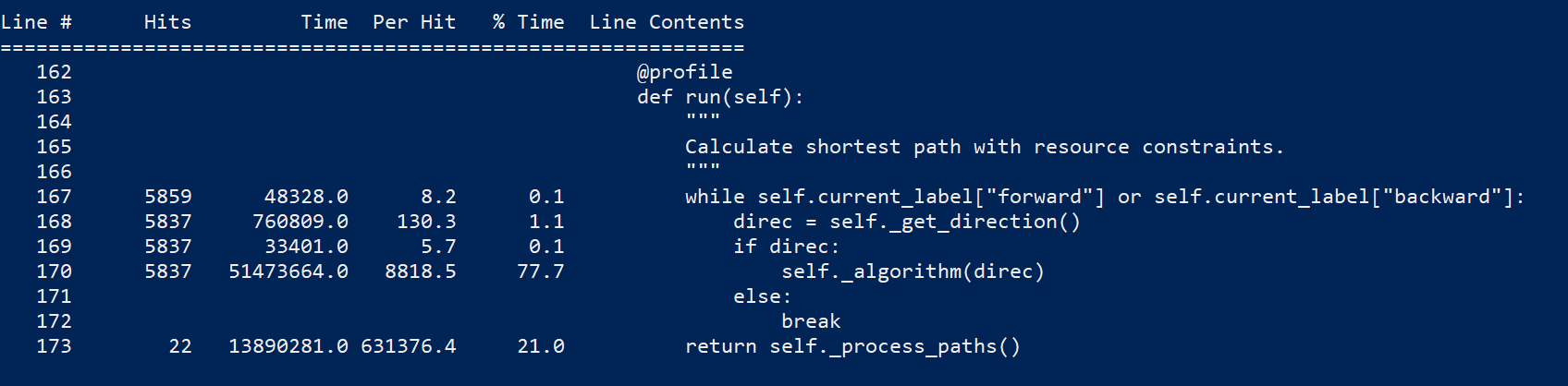
~50% consumed by deque(map(self._propagate_label, edges, repeat(direc, len(edges))))
~20% consumed by self._check_dominance(next_label, direc)
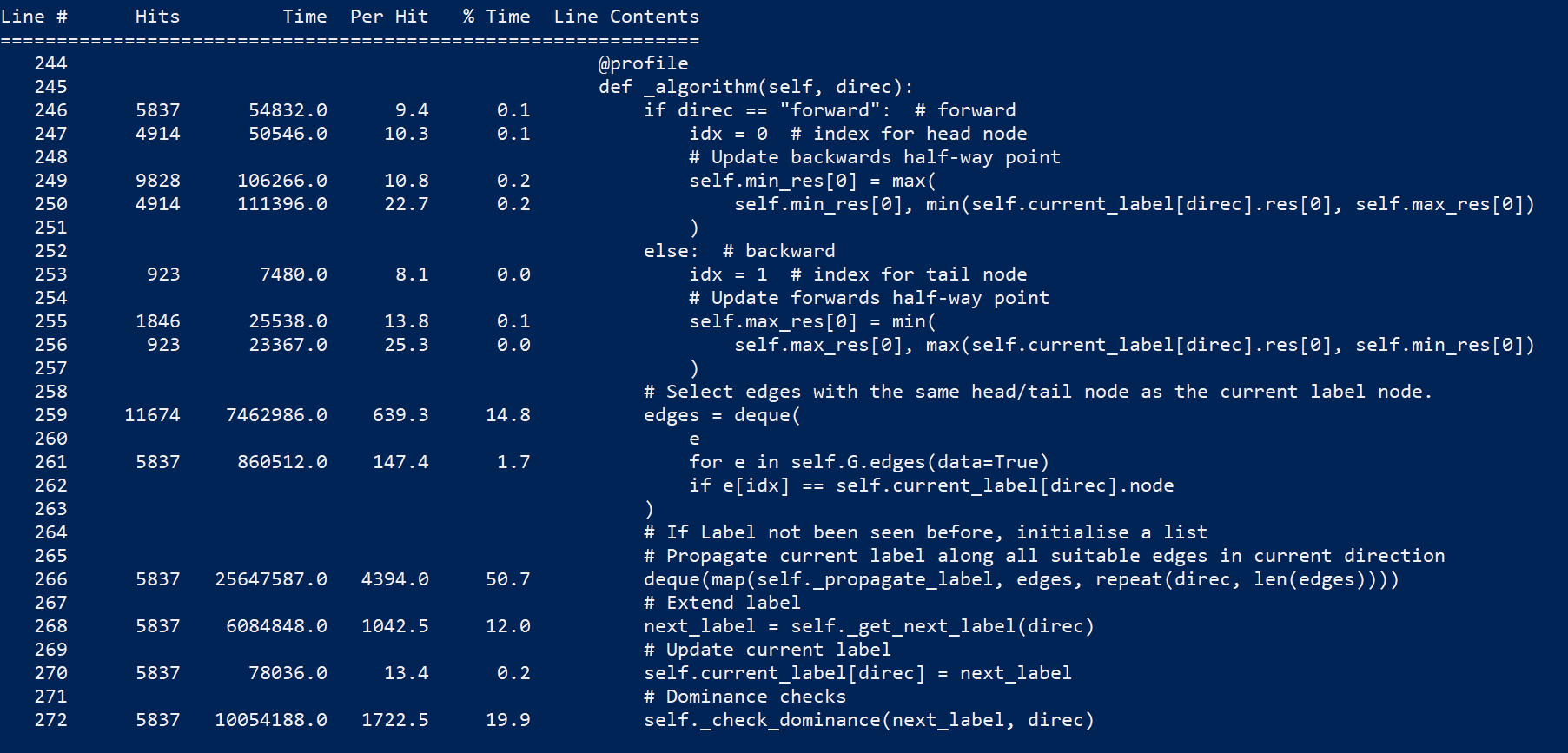
deque(map())Originally posted by @Kuifje02 in Kuifje02/vrpy#9 (comment)
I've disabled method="random" option as it is a bit unstable.
However, would like to fix
Implement generic resource extension functions for all algorithms
The BiDirectional algorithm with direction='both' (default) path join and checking functions are inconsistent, sometimes resulting in invalid paths (final paths with edges not it the graph).
How this can be fixed
The path joining function (https://github.com/torressa/cspy/blob/master/cspy/algorithms/bidirectional.py#L278) and path checking (https://github.com/torressa/cspy/blob/master/cspy/algorithms/bidirectional.py#L290) have to be altered to only join the forward and backward paths if they are not disconnected.
Quick Fix
For a quick fix, specify direction='forward'/'backward' when calling the BiDirectional algorithm.
Describe the bug
A non optimal solution is returned in the following small example (for BiDirectional and Tabu)
To Reproduce
Steps to reproduce the behavior:
#create graph
G = nx.DiGraph(directed = True,n_res=2)
G.add_edge("Source", 1, weight=10, res_cost=np.array([1,1]))
G.add_edge("Source", 2, weight=10, res_cost=np.array([1,1]))
G.add_edge("Source", 3, weight=10, res_cost=np.array([1,1]))
G.add_edge(1, "Sink", weight=-10, res_cost=np.array([1,0]))
G.add_edge(2, "Sink", weight=-10, res_cost=np.array([1,0]))
G.add_edge(3, "Sink", weight=-10, res_cost=np.array([1,0]))
G.add_edge(3, 2, weight=-5, res_cost=np.array([1,1]))
G.add_edge(2, 1, weight=-10, res_cost=np.array([1,1]))
#resource limits
max_res, min_res = [len(G.edges()),2], [0,0]
#run algorithms
path_1 = cspy.Tabu(G, max_res, min_res).run()
path_2 = cspy.BiDirectional(G, max_res, min_res, direction="both").run()
#print paths
print(path_1)
print(path_2)
Expected behavior
Both algorithms return
['Source', 1, 'Sink']
which has cost 0, and which consumes only 1 resource, while path Source-2-1-Sink is feasible (2 resources are consumed) and cheaper (cost -10).
I've selected BiDirectional.init(G,max_res,min_res,direction,preprocess,REF_forward,REF_backward) for refactoring, which is a unit of 20 lines of code and 7 parameters. Addressing this will make our codebase more maintainable and improve Better Code Hub's Keep Unit Interfaces Small guideline rating! 👍
Here's the gist of this guideline:
You can find more info about this guideline in Building Maintainable Software. 📖
ℹ️ To know how many other refactoring candidates need addressing to get a guideline compliant, select some by clicking on the 🔲 next to them. The risk profile below the candidates signals (✅) when it's enough! 🏁
Good luck and happy coding! ![]() ✨ 💯
✨ 💯
Given there's a fair few extensions to make, I think it's worth changing the structure a bit so that working on them is a bit easier.
Improvements/Features/Bugs include:
min_res bug (raised in #41)The current structure doesn't lend itself that well to all of the above, therefore, I propose to split the current BiDirectional object into two.
A Search helper object (for both backward and forward searches) and a modified BiDirectional object which will just orchestrate the searches and output the results.
Search objectPurposes:
Individual Attributes (not shared)
direction - direction of searchunprocessed_labels nested dict with labels to help with label elimination.BiDirectional objectPurposes:
Individual Attributes:
From openjournals/joss-reviews#1655 (comment)
I think the "statement of need" could use work, in the paper and especially in the documentation. I don't see any motivating reasons on why I, a grad student studying optimization (but not an expert on shortest path problems) should pick up cspy.
Possibly relevant questions: When is the constrained shortest path problem relevant? What concrete problems can it be applied to? What features does cspy provide, and why is it unique?
The provided statement of need is a lot clearer in paper than the documentation.
Is your feature request related to a problem? Please describe.
Would like a decent precessing routine, kind off like by the authors mentioned in #67
As an inital task, fixing the use of the shortest paths to bound the search would be useful (sometimes works)
Write valid Greedy elimination algorithm unit tests
Is your feature request related to a problem? Please describe.
Some applications have an integer monotone primary resource (e.g. # of stops).
A more efficient data structure to store labels is a bucket heap.
Describe the solution you'd like
Detect if such a resource exists in which use LEMON's BucketHeap, instead of the current max/min heap
In the example:
from cspy import BiDirectional
from networkx import DiGraph
from numpy import array
G = DiGraph(directed=True, n_res=2)
G.add_edge("Source", "A", res_cost=array([1, 2]), weight=0)
G.add_edge("A", "B", res_cost=array([1, 0.3]), weight=0)
G.add_edge("A", "C", res_cost=array([1, 0.1]), weight=0)
G.add_edge("B", "C", res_cost=array([1, 3]), weight=-10)
G.add_edge("B", "Sink", res_cost=array([1, 2]), weight=10)
G.add_edge("C", "Sink", res_cost=array([1, 10]), weight=0)
max_res, min_res = [4, 20], [1, 0]
bidirec = BiDirectional(G, max_res, min_res, direction="both")
bidirec.run()
print(bidirec.path)
The result should be:
#["Source", "A", "B", "C", "Sink"]
But it is:
['Source', 'A', 'C', 'Sink']
From openjournals/joss-reviews#1655 (comment)
One question I have: how are constraints from real problems coded in cspy? I know cspy can be used in the vehicle routing problem with time windows (desaulniers2008tabu), but don't know how to code the time constraints in cspy.
Answer: Will be clear with a working example
Generalise algorithms for nx.MultiGraph() instances
Is your feature request related to a problem? Please describe.
Attempt to implement the RC-EBBA* algorithm by Ahmadi et al. (forthcoming).
A detailed implementation can be found in the author's repo:
https://bitbucket.org/s-ahmadi/biobj/src/master/
Describe the solution you'd like
The implementation includes many tricks, so an initial attempt would be to have the bare-bones algorithm (without the label compression or bucket queue) by modifying the bidirectional labelling algorithm.
Describe the bug
The tabu algorithm violates resource constraints
To Reproduce
# graph definition :
G = nx.DiGraph(directed = True,n_res=2)
G.add_edge("Source", 1, weight=10, res_cost=np.array([1,1]))
G.add_edge("Source", 2, weight=10, res_cost=np.array([1,1]))
G.add_edge("Source", 3, weight=10, res_cost=np.array([1,1]))
G.add_edge(1, "Sink", weight=-10, res_cost=np.array([1,0]))
G.add_edge(2, "Sink", weight=-10, res_cost=np.array([1,0]))
G.add_edge(3, "Sink", weight=-10, res_cost=np.array([1,0]))
G.add_edge(3, 2, weight=-5, res_cost=np.array([1,1]))
G.add_edge(2, 1, weight=-10, res_cost=np.array([1,1]))
# resource limits
max_res, min_res = [len(G.edges()),2], [0,0]
# solve with tabu
path = cspy.Tabu(G, max_res, min_res).run()
print(path)
# solve with BiDirectional
path = cspy.BiDirectional(G, max_res, min_res, direction="both").run()
print(path)
Expected behavior
# Tabu path :
['Source', 3, 2, 1, 'Sink']
# Bidirectional path
['Source', 2, 1, 'Sink']
In other words, the Tabu path seems to violate the second resource constraint, as path Source-3-2-1-Sink consumes 3 units of the second resource, and max_res = [M,2]. The bidirectional version seems to work.
Describe the bug
I can't the github Windows workflow to work. See .github/workflows/win*.
Expected behavior
Windows building and tests passing both in Cpp and Python.
Hi,
I am experiencing an issue concerning the minimum resources provided to the bidirectional algorithms. According to the documentation min_res is the minimum resource usage to be enforced for the resulting path. However, if I implement a min_res that is higher than 0, it is just added to the consumed resource instead of enforcing the resulting path to use this as lower bound. An example:
from cspy import BiDirectional
from networkx import DiGraph
from numpy import array
G = DiGraph(directed=True, n_res=2)
G.add_edge("Source", "A", res_cost=array([1, 1]), weight=10)
G.add_edge("A", "B", res_cost=array([1, 0]), weight=3)
G.add_edge("A", "C", res_cost=array([1, 1]), weight=10)
G.add_edge("B", "C", res_cost=array([1, 0]), weight=3)
G.add_edge("B", "Sink", res_cost=array([1, 1]), weight=5)
G.add_edge("C", "Sink", res_cost=array([1, 1]), weight=0)
max_res, min_res = [4, 20], [0, 3]
bidirec = BiDirectional(G, max_res, min_res, direction="forward")
bidirec.run()
print(bidirec.path)
print(bidirec.consumed_resources)
the output is:
[Source', 'A', 'B', 'C', 'Sink']
[4 5]
It seems like it is just adding min_res to the consumed resources. To satisfy the minimum resources it should pick edge (A,C). Now it picks edges (A,B) and (B,C) instead.
My operating system is macOS Mojave 10.14.6.
Can anyone help me solving this problem?
I've selected PSOLGENT.init(G,max_res,min_res,max_iter,swarm_size,member_size,neighbourhood_size,c1,c2,c3) for refactoring, which is a unit of 19 lines of code and 10 parameters. Addressing this will make our codebase more maintainable and improve Better Code Hub's Keep Unit Interfaces Small guideline rating! 👍
Here's the gist of this guideline:
You can find more info about this guideline in Building Maintainable Software. 📖
ℹ️ To know how many other refactoring candidates need addressing to get a guideline compliant, select some by clicking on the 🔲 next to them. The risk profile below the candidates signals (✅) when it's enough! 🏁
Good luck and happy coding! ![]() ✨ 💯
✨ 💯
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.