This project showcases essential techniques to harness the power of machine learning. Explore KNN (K-Nearest Neighbors), along with data cleaning to remove inconsistencies, feature encoding, and feature scaling.
- KNN (K-Nearest Neighbors): Understand and apply the KNN algorithm for classification and regression tasks.
- K-means Clustering: Dive into K-means clustering to group similar data points.
- Data Cleaning: Learn how to handle inconsistencies and missing values in datasets.
- Feature Encoding: Convert categorical variables into numerical format suitable for machine learning.
- Feature Scaling: Normalize or standardize features for uniformity and optimal performance.
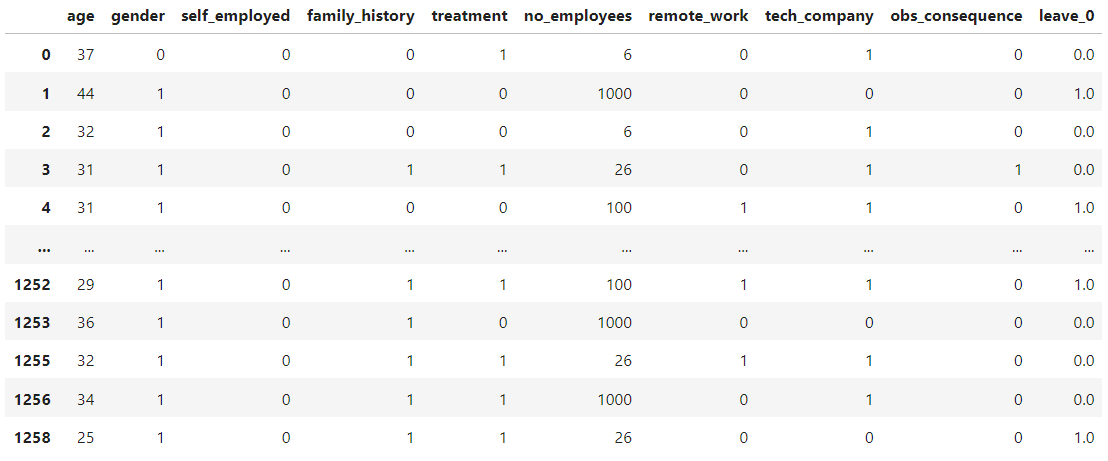
"In the realm of data cleaning, we've employed a structured approach to ensure the integrity and reliability of our datasets. Our meticulous process includes:
- Handling Missing Values: Expertly addressing missing values to prevent gaps in our analyses and ensure complete datasets.
- Editing Inconsistencies: Diligently identifying and editing inconsistencies, guaranteeing the accuracy and coherence of our data.
- Refining Labels: Carefully refining labels to provide clear and meaningful representations of our features.
- Identifying Important Columns: Making informed decisions about the most important columns, focusing our efforts on the data that truly matters.
- Finessing Data Types: Ensuring that data types are carefully adjusted to ensure compatibility and seamless processing.
Data after cleaning
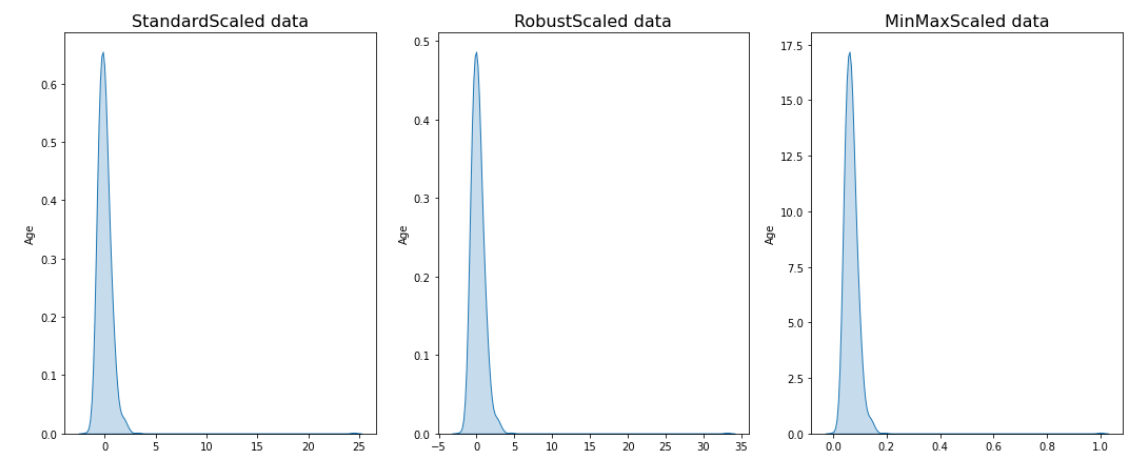
In the realm of feature scaling, we've adopted a systematic strategy to optimize the performance of our machine learning models. Our approach includes:
- Min-Max Scaling: Transforming features to a common range using the min-max scaling technique, ensuring uniformity and preventing disproportionate influence.
- Robust Scaling: Employing robust scaling to mitigate the impact of outliers, enhancing model robustness and effectiveness.
- Standard Scaling: Applying standard scaling to achieve zero mean and unit variance, promoting stable and reliable model outcomes.