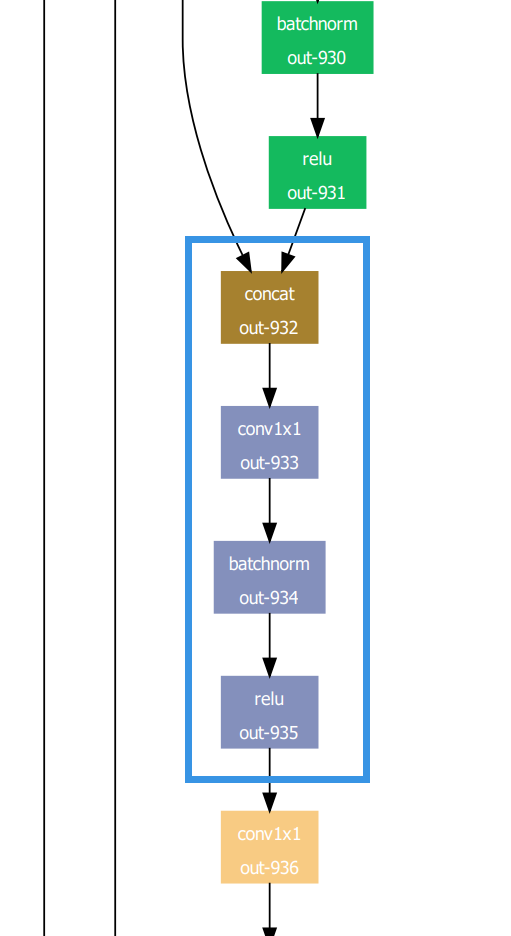
This repository is the (deprecated) Pytorch implementation of Only-Train-Once (OTO). OTO is an
Please find our series of works and bibtexs for kind citations.
- OTOv3: Automatic Architecture-Agnostic Neural Network Training and Compression from Structured Pruning to Erasing Operators preprint.
- LoRAShear: Efficient Large Language Model Structured Pruning and Knowledge Recovery preprint.
- An Adaptive Half-Space Projection Method for Stochastic Optimization Problems with Group Sparse Regularization in TMLR 2023.
- OTOv2: Automatic, Generic, User-Friendly in ICLR 2023.
- Only Train Once (OTO): A One-Shot Neural Network Training And Pruning Framework in NeurIPS 2021.

In addition, we recommend our following efficient ML works.
- DREAM: Diffusion Rectification and Estimation-Adaptive Models, efficient diffusion training, in CVPR 2024.
- DISTILLM: Towards Streamlined Distillation for Large Language Models, LLM distillation, preprint.
We recommend to run the framework under pytorch>=2.0. Use pip or git clone to install.
pip install only_train_onceor
git clone https://github.com/tianyic/only_train_once.gitWe provide an example of OTO framework usage. More explained details can be found in tutorials.
import torch
from sanity_check.backends import densenet121
from only_train_once import OTO
# Create OTO instance
model = densenet121()
dummy_input = torch.zeros(1, 3, 32, 32)
oto = OTO(model=model.cuda(), dummy_input=dummy_input.cuda())
# Create HESSO optimizer
optimizer = oto.hesso(variant='sgd', lr=0.1, target_group_sparsity=0.7)
# Train the DNN as normal via HESSO
model.train()
model.cuda()
criterion = torch.nn.CrossEntropyLoss()
for epoch in range(max_epoch):
f_avg_val = 0.0
for X, y in trainloader:
X, y = X.cuda(), y.cuda()
y_pred = model.forward(X)
f = criterion(y_pred, y)
optimizer.zero_grad()
f.backward()
optimizer.step()
# A compressed densenet will be generated.
oto.construct_subnet(out_dir='./')- Pruning Zero-Invariant Group Partition. OTO at first automatically figures out the dependancy inside the target DNN to build a pruning dependency graph. Then OTO partitions DNN's trainable variables into so-called Pruning Zero-Invariant Groups (PZIGs). PZIG describes a class of pruning minimally removal structure of DNN, or can be largely interpreted as the minimal group of variables that must be pruned together.

-
Hybrid Structured Sparse Optimizer. A structured sparsity optimization problem is formulated. A hybrid structured sparse optimizer, including HESSO, DHSPG, LSHPG, is then employed to find out which PZIGs are redundant, and which PZIGs are important for the model prediction. The selected hybrid optimizer explores group sparsity more reliably and typically achieves higher generalization performance than other sparse optimizers.

-
Construct pruned model. The structures corresponding to redundant PZIGs (being zero) are removed to form the pruned model. Due to the property of PZIGs, the pruned model returns the exact same output as the full model. Therefore, no further fine-tuning is required.

The sanity check provides the tests for pruning mode in OTO onto various DNNs from CNN to LLM. The pass of sanity check indicates the compliance of OTO onto target DNN.
python sanity_check/sanity_check.py
Note that some tests require additional dependency. Comment off unnecessary tests. We highly recommend to proceed a sanity check over a new customized DNN for testing compliance.
The visual_examples provides the visualization of pruning dependency graphs and erasing dependency graphs. Visualization serves as a frequently used tool for employing OTO onto new unseen DNNs if meets errors.
-
Add more explanations into the current repository.
-
Release a technical report regarding the HESSO optimizer which is not discussed yet in our papers.
-
Release refactorized DHSPG and LHSPG.
-
Release the full pipeline of LoRAShear (upon business administration).
-
Provide more tutorials to cover the experiments in the pruning mode. Main experiments in OTOv2 can be found at otov2_branch.
-
Release official erasing mode after the review process of OTOv3.
-
Provide documentations of the OTO API.
We would greatly appreciate the contributions in any form, such as bug fixes, new features and new tutorials, from our open-source community.
We are humble to provide benefits for the AI community. We look forward to working with the community together to make DNN's training and compression to be more automatic and convinient.
We are open and happy for collabrations. Feel free to reach out [email protected] if have any interesting idea.
The previous OTOv2 repo has been moved into legacy_branch for academic replication.
If you find the repo useful, please kindly star this repository and cite our papers:
For OTOv3 preprint
@article{chen2023otov3,
title={OTOv3: Automatic Architecture-Agnostic Neural Network Training and Compression from Structured Pruning to Erasing Operators},
author={Chen, Tianyi and Ding, Tianyu and Zhu, Zhihui and Chen, Zeyu and Wu, HsiangTao and Zharkov, Ilya and Liang, Luming},
journal={arXiv preprint arXiv:2312.09411},
year={2023}
}
For LoRAShear preprint
@article{chen2023lorashear,
title={LoRAShear: Efficient Large Language Model Structured Pruning and Knowledge Recovery},
author={Chen, Tianyi and Ding, Tianyu and Yadav, Badal and Zharkov, Ilya and Liang, Luming},
journal={arXiv preprint arXiv:2310.18356},
year={2023}
}
For AdaHSPG+ publication in TMLR (theoretical optimization paper)
@article{dai2023adahspg,
title={An adaptive half-space projection method for stochastic optimization problems with group sparse regularization},
author={Dai, Yutong and Chen, Tianyi and Wang, Guanyi and Robinson, Daniel P},
journal={Transactions on machine learning research},
year={2023}
}
For OTOv2 publication in ICLR 2023
@inproceedings{chen2023otov2,
title={OTOv2: Automatic, Generic, User-Friendly},
author={Chen, Tianyi and Liang, Luming and Tianyu, DING and Zhu, Zhihui and Zharkov, Ilya},
booktitle={International Conference on Learning Representations},
year={2023}
}
For OTOv1 publication in NeurIPS 2021
@inproceedings{chen2021otov1,
title={Only Train Once: A One-Shot Neural Network Training And Pruning Framework},
author={Chen, Tianyi and Ji, Bo and Tianyu, DING and Fang, Biyi and Wang, Guanyi and Zhu, Zhihui and Liang, Luming and Shi, Yixin and Yi, Sheng and Tu, Xiao},
booktitle={Thirty-Fifth Conference on Neural Information Processing Systems},
year={2021}
}