- 👋 Hi, I’m @tianma630
- 👀 I’m interested in ...
- 🌱 I’m currently learning ...
- 💞️ I’m looking to collaborate on ...
- 📫 How to reach me ...
tianma630 / note-book Goto Github PK
View Code? Open in Web Editor NEWmy blog
my blog


因为Object.defineProperty()只支持对象的属性劫持,所以数组是如何实现动态响应的呢?我们看一下vue的代码
var arrayProto = Array.prototype; // 获取数组的原型,原型中包含了数组所有的属性、方法
var arrayMethods = Object.create(arrayProto); // 用数组的原型创建一个新的对象示例
var methodsToPatch = [ // 枚举了所有可能改变数组自身的方法
'push',
'pop',
'shift',
'unshift',
'splice',
'sort',
'reverse'
];
/**
* Intercept mutating methods and emit events
*/
methodsToPatch.forEach(function (method) { // 遍历枚举的方法
// cache original method
var original = arrayProto[method]; // 获取方法名称 比如push
def(arrayMethods, method, function mutator () { // 劫持数组中的方法,问题1: 为啥劫持的是arrayMethods, 而不是arrayProto
var args = [], len = arguments.length;
while ( len-- ) args[ len ] = arguments[ len ]; // 把参数放入数组args,问题2: 是否多此一举
var result = original.apply(this, args); // 执行该方法,也可以用arguments
var ob = this.__ob__; // 获取observer,里面存储了dep,dep中存储了watcher
var inserted;
switch (method) { // 获取数组中新增的元素,比如list.push(item):item即是新的元素
case 'push':
case 'unshift':
inserted = args;
break
case 'splice':
inserted = args.slice(2);
break
}
if (inserted) { ob.observeArray(inserted); } // 劫持新增的元素
// notify change
ob.dep.notify(); // 执行watcher,触发生成vdom并patch
return result // 返回数组方法执行结果
});
});在上面的代码注解中提到了2个问题:
看了问题1 的解释,既然劫持的不是Array.prototype,那我们在操作数组时是怎么进的上面的逻辑的。我们可以看一下observe方法是如何实现的
var Observer = function Observer (value) {
this.value = value; // 对象or数组
this.dep = new Dep(); // 在oberver实例中创建dep
this.vmCount = 0;
def(value, '__ob__', this); // 定义value的__ob__属性为当前的oberver实例,对应上面的代码是如何获取observer的
if (Array.isArray(value)) { // 如果是数组
if (hasProto) {
protoAugment(value, arrayMethods); // 将value的原型对象修改为arrayMethods,原来如此,进一步解释了上面的问题1
} else {
copyAugment(value, arrayMethods, arrayKeys);
}
this.observeArray(value); // 如果是数组,劫持递归劫持
} else {
this.walk(value); // 实现对象的属性劫持
}
};
function protoAugment (target, src) { // 修改原型实例方法
/* eslint-disable no-proto */
target.__proto__ = src;
/* eslint-enable no-proto */
}到这里,我们就应该就明白了,vue是如何只劫持vue环境中的数组操作,而不影响vue环境外的数组操作。
可以参考下面的视频和文章
https://zhuanlan.zhihu.com/p/122013710
https://www.bilibili.com/video/BV1E441197g5
https://www.bilibili.com/video/BV13E411B7yp
个人的几个理解
// 卡死
while(true);
// 不会卡死
function loop() {
setTimeout(() => {}, 0);
}
loop();所谓diff算法,就是给定任意两棵树,找到最少的转换步骤。传统的的Diff 算法复杂度需要O(n^3)。
react总结Web UI的特点,将diff算法的复杂度提升到O(n),主要依据以下3个策略。
基于上面的原则,react从tree diff、component diff、element diff三个方面对diff算法就行了优化。
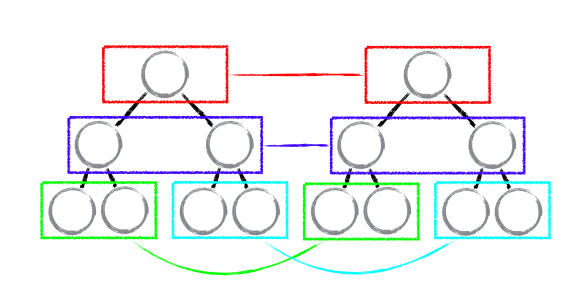
基于策略1,react对整颗树进行比对的时候,只需要将同层级的节点进行比对。
如上图所示,同颜色框中的节点才会进行比较,只要发现节点不存在,就会将该节点整个删除。
基于策略2,react会比对组件的类型,只要类型不同,就会将组件整个删除;如果发现是相同的组件,就会将组件下的节点进行比对。
统一层级下面的接口进行比对的时候,有3种情况
react会顺序对比相同位置上节点,如果节点不同则会新增节点,并删除老的节点
function enqueueInsertMarkup(parentInst, markup, toIndex) {
updateQueue.push({
parentInst: parentInst,
parentNode: null,
type: ReactMultiChildUpdateTypes.INSERT_MARKUP,
markupIndex: markupQueue.push(markup) - 1,
content: null,
fromIndex: null,
toIndex: toIndex,
});
}
function enqueueMove(parentInst, fromIndex, toIndex) {
updateQueue.push({
parentInst: parentInst,
parentNode: null,
type: ReactMultiChildUpdateTypes.MOVE_EXISTING,
markupIndex: null,
content: null,
fromIndex: fromIndex,
toIndex: toIndex,
});
}
function enqueueRemove(parentInst, fromIndex) {
updateQueue.push({
parentInst: parentInst,
parentNode: null,
type: ReactMultiChildUpdateTypes.REMOVE_NODE,
markupIndex: null,
content: null,
fromIndex: fromIndex,
toIndex: null,
});
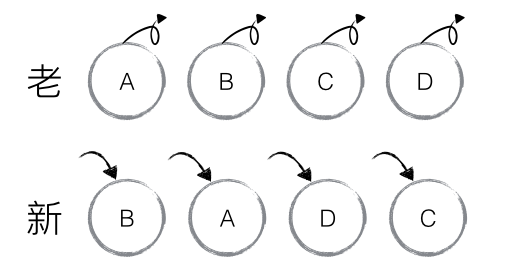
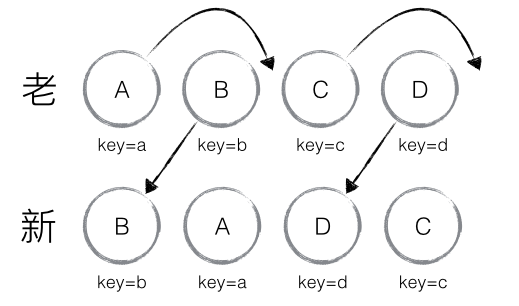
}为了实现对原有节点的重复使用,用key来表示是否是相同的节点。
_updateChildren: function(nextNestedChildrenElements, transaction, context) {
var prevChildren = this._renderedChildren;
var nextChildren = this._reconcilerUpdateChildren(
prevChildren, nextNestedChildrenElements, transaction, context
);
if (!nextChildren && !prevChildren) {
return;
}
var name;
var lastIndex = 0;
var nextIndex = 0;
for (name in nextChildren) {
if (!nextChildren.hasOwnProperty(name)) {
continue;
}
var prevChild = prevChildren && prevChildren[name];
var nextChild = nextChildren[name];
if (prevChild === nextChild) {
// 移动节点
this.moveChild(prevChild, nextIndex, lastIndex);
lastIndex = Math.max(prevChild._mountIndex, lastIndex);
prevChild._mountIndex = nextIndex;
} else {
if (prevChild) {
lastIndex = Math.max(prevChild._mountIndex, lastIndex);
// 删除节点
this._unmountChild(prevChild);
}
// 初始化并创建节点
this._mountChildAtIndex(
nextChild, nextIndex, transaction, context
);
}
nextIndex++;
}
for (name in prevChildren) {
if (prevChildren.hasOwnProperty(name) &&
!(nextChildren && nextChildren.hasOwnProperty(name))) {
this._unmountChild(prevChildren[name]);
}
}
this._renderedChildren = nextChildren;
},
// 移动节点
moveChild: function(child, toIndex, lastIndex) {
if (child._mountIndex < lastIndex) {
this.prepareToManageChildren();
enqueueMove(this, child._mountIndex, toIndex);
}
},
// 创建节点
createChild: function(child, mountImage) {
this.prepareToManageChildren();
enqueueInsertMarkup(this, mountImage, child._mountIndex);
},
// 删除节点
removeChild: function(child) {
this.prepareToManageChildren();
enqueueRemove(this, child._mountIndex);
},
_unmountChild: function(child) {
this.removeChild(child);
child._mountIndex = null;
},
_mountChildAtIndex: function(
child,
index,
transaction,
context) {
var mountImage = ReactReconciler.mountComponent(
child,
transaction,
this,
this._nativeContainerInfo,
context
);
child._mountIndex = index;
this.createChild(child, mountImage);
},按照本文原理,手写了个打包工具:https://github.com/tianma630/mypack
首先我编写了3个js文件
a.js
export default 1;
export const b = 2;
export const c = 3;
export const plus = function(a, b) {
return a + b;
}b.js
export default function (a) {
return a * a;
};entry.js
import a, {b, c, plus} from './a';
import d from './b';
let ret = plus(a, b) + d(c);
console.log(ret);使用webpack命令生成打包文件,结果其实是一个直接执行函数,为了方便查看,删除了多余代码
(function(modules) {
// 存储了所有模块化的信息
var installedModules = {};
// 按文件处理解析模块化信息,moduleId其实就是文件路径名称
function __webpack_require__(moduleId) {
// 检查该文件是否缓存了
if(installedModules[moduleId]) {
return installedModules[moduleId].exports;
}
// 新建一个空的
var module = installedModules[moduleId] = {
i: moduleId, // 模块id 其实就是文件路径,比如./src/b.js
l: false,
exports: {} // 这个文件中的所有export的内容,比如b.js中 {default: function(a) { return a * a; }}
};
// 处理文件中的模块化信息,并执行代码,具体逻辑在下面的参数中,先mark下
modules[moduleId].call(module.exports, module, module.exports, __webpack_require__);
// 标记文件被加载,就是是否被使用
module.l = true;
// 返回模块化的信息
return module.exports;
}
// 缓存一个模块,就是处理类似export const b = 2;的逻辑
__webpack_require__.d = function(exports, name, getter) {
if(!__webpack_require__.o(exports, name)) { // 判断下这个模块是否缓存过
Object.defineProperty(exports, name, { enumerable: true, get: getter });
}
};
// 入口执行函数,就是执行entry中的配置文件
return __webpack_require__(__webpack_require__.s = "./src/entry.js");
})
({
// 处理具体的模块代码文件,按文件区分模块,执行的入口就是上面mark的call方法
"./src/a.js": (function(module, __webpack_exports__, __webpack_require__) {
"use strict";
// 为了方便查看eval中的代码,我们在下面格式化一下
eval("__webpack_require__.r(__webpack_exports__);\n/* harmony export (binding) */ __webpack_require__.d(__webpack_exports__, \"b\", function() { return b; });\n/* harmony export (binding) */ __webpack_require__.d(__webpack_exports__, \"c\", function() { return c; });\n/* harmony export (binding) */ __webpack_require__.d(__webpack_exports__, \"plus\", function() { return plus; });\n/* harmony default export */ __webpack_exports__[\"default\"] = (1);\n\nconst b = 2;\n\nconst c = 3;\n\nconst plus = function(a, b) {\n return a + b;\n}\n\n//# sourceURL=webpack:///./src/a.js?");
}),
"./src/b.js": (function(module, __webpack_exports__, __webpack_require__) {
"use strict";
eval("__webpack_require__.r(__webpack_exports__);\n/* harmony default export */ __webpack_exports__[\"default\"] = (function (a) {\n return a * a;\n});;\n\n//# sourceURL=webpack:///./src/b.js?");
}),
"./src/entry.js": (function(module, __webpack_exports__, __webpack_require__) {
"use strict";
eval("__webpack_require__.r(__webpack_exports__);\n/* harmony import */ var _a__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__(/*! ./a */ \"./src/a.js\");\n/* harmony import */ var _b__WEBPACK_IMPORTED_MODULE_1__ = __webpack_require__(/*! ./b */ \"./src/b.js\");\n\n\n\nlet ret = Object(_a__WEBPACK_IMPORTED_MODULE_0__[\"plus\"])(_a__WEBPACK_IMPORTED_MODULE_0__[\"default\"], _a__WEBPACK_IMPORTED_MODULE_0__[\"b\"]) + Object(_b__WEBPACK_IMPORTED_MODULE_1__[\"default\"])(_a__WEBPACK_IMPORTED_MODULE_0__[\"c\"]);\n\nconsole.log(ret);\n\n\n\n// (function(a, b) {\n// let ret = a(1, 2) + b(2, 3);\n\n// console.log(ret);\n// })(\n// {a: function(a, b) {\n// return a + b;\n// }}, \n// function(a, b) {\n// return a * b;\n// }\n// )\n\n\n//# sourceURL=webpack:///./src/entry.js?");
})
});格式化eval中的代码
// function(module, __webpack_exports__, __webpack_require__)
// __webpack_require__ 上面的模块化入口方法
// __webpack_exports__ 存储模块化信息的对象, 可以理解为{}
// a.js
__webpack_require__.r(__webpack_exports__); // 标记了这个是存储模块化信息的对象,没有直接作用
__webpack_require__.d(__webpack_exports__, "b" , function() { return b; }); // 放入到模块化对象中,可以理解为{b: function() { return b; }}
__webpack_require__.d(__webpack_exports__, "c", function() { return c; });
__webpack_require__.d(__webpack_exports__, "plus", function() { return plus; });
__webpack_exports__["defalut"] = (1); // 处理export default
const b = 2;
const c = 3;
const plus = function(a, b) {
return a + b;
}
// b.js
__webpack_require__.r(__webpack_exports__);
__webpack_exports__["default"] = (function (a) {
return a * a;
});
// entry.js
// 入口文件必须放在最下面执行
__webpack_require__.r(__webpack_exports__);
var _a__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__("./src/a.js"); // 根据路径获取模块依赖,如果模块不存在,则先执行./src/a.js中的代码,如果已经执行过了,则直接获取缓存中的依赖
var _b__WEBPACK_IMPORTED_MODULE_1__ = __webpack_require__("./src/b.js");
// 将依赖对象和方法动态替换成引入的依赖
let ret = Object(_a__WEBPACK_IMPORTED_MODULE_0__["plus"])(_a__WEBPACK_IMPORTED_MODULE_0__["default"], _a__WEBPACK_IMPORTED_MODULE_0__["b"]) + _a__WEBPACK_IMPORTED_MODULE_0__["c"] * _b__WEBPACK_IMPORTED_MODULE_1__["default"];
console.log(ret);模块化整体的逻辑可以简单理解为,按js代码文件路径,将所有的export缓存到模块化对象installedModules中,在入口文件,按依赖路径从模块化对象中获取依赖并执行。
// 本文的例子生成的installedModules对象
{
"./src/entry.js": {
"i": "./src/entry.js",
"l": true,
"exports": {}
},
"./src/a.js": {
"i": "./src/a.js",
"l": true,
"exports": {
"b": function () {
return b;
},
"c": function() {
return c;
},
"plus": function (a, b) {
return a + b;
},
"default": 1
}
},
"./src/b.js": {
"i": "./src/b.js",
"l": true,
"exports": {
"default": function (a) {
return a * a;
}
}
}
}最后还有一个问题是如何把实际的代码转变成eval中的代码结构的,这就要用到ast了,有兴趣的同学可以去了解下。
查看官方指南关于代码分割的文档,我们可以知道,实现代码分割有3种方式
前2种是陪过配置实现,第3种是通过代码动态分析实现,但是最后代码生成的结果是一样的,这里我们就那第3种方式为例。
动态导入也有2种写法,一种是基于ESMA提案的import()方法,另一种是webpack提供的require.ensure方法,这里选择第一种语法,实现一个例子。
index.js
setTimeout(() => {
import(/* webpackChunkName: "print" */ './print').then((print) => {
print.log();
})
}, 3000);print.js
export function log() {
console.log('print log');
}在webpack的配置的ouput选项中需要加上chunkFilename配置,用于生成需要动态导入的文件。
module.exports = {
entry: {
app: './src/index.js'
},
...
output: {
filename: '[name].bundle.js',
chunkFilename: '[name].bundle.js',
path: path.resolve(__dirname, 'dist')
}
};执行webpack打包命令,可以看到最终生成了2个文件
在chrome中运行可以发现,先引入了app.bundle.js,3秒钟后引入了print.bundle.js。下面我们看下这个过程是怎么实现的。
先看下app.bundle.js的代码,删减后的代码
(function(modules) { // webpackBootstrap
// 动态引入的方法
__webpack_require__.e = function requireEnsure(chunkId) {
// 因为动态引入的过程是异步的,所以promise化
var promises = [];
var installedChunkData = installedChunks[chunkId];
// 是否已经引入过, 0表示已经引入
if(installedChunkData !== 0) { // 0 means "already installed".
// 是否已经创建了promise
if(installedChunkData) {
promises.push(installedChunkData[2]);
} else {
// 创建一个promise
var promise = new Promise(function(resolve, reject) {
installedChunkData = installedChunks[chunkId] = [resolve, reject];
});
promises.push(installedChunkData[2] = promise);
// 通过动态创建script引入js文件
var script = document.createElement('script');
var onScriptComplete;
script.charset = 'utf-8';
script.timeout = 120;
if (__webpack_require__.nc) {
script.setAttribute("nonce", __webpack_require__.nc);
}
script.src = jsonpScriptSrc(chunkId);
// create error before stack unwound to get useful stacktrace later
var error = new Error();
// 回掉函数
onScriptComplete = function (event) {
// avoid mem leaks in IE.
script.onerror = script.onload = null;
clearTimeout(timeout);
var chunk = installedChunks[chunkId];
if(chunk !== 0) {
if(chunk) {
var errorType = event && (event.type === 'load' ? 'missing' : event.type);
var realSrc = event && event.target && event.target.src;
error.message = 'Loading chunk ' + chunkId + ' failed.\n(' + errorType + ': ' + realSrc + ')';
error.name = 'ChunkLoadError';
error.type = errorType;
error.request = realSrc;
chunk[1](error);
}
installedChunks[chunkId] = undefined;
}
};
var timeout = setTimeout(function(){
onScriptComplete({ type: 'timeout', target: script });
}, 120000);
script.onerror = script.onload = onScriptComplete;
document.head.appendChild(script);
}
}
return Promise.all(promises);
};
// Load entry module and return exports
return __webpack_require__(__webpack_require__.s = "./src/index.js");
})
/************************************************************************/
({
"./src/index.js":
(function(module, exports, __webpack_require__) {
eval(```
setTimeout(() => {
// 动态引入print文件
__webpack_require__.e("print")
// 引入之后执行__webpack_require__,模块化处理(print文件是app文件的一个模块,具体逻辑可以参考之前的文章:https://github.com/tianma630/note-book/issues/9)
.then(__webpack_require__.bind(null,"./src/print.js"))
// 执行代码
.then((print) => {
print.log();
})
}, 3000);
```
)
})
});最后可以总结出,代码分割的执行流程可以分为3个步骤
scheduler模块react为了实现fiber架构新增的一个模块,主要用来实现任务的拆分和调度执行。
scheduler是一个独立的模块,暴露了一些任务调度相关的方法,可以直接调用。
我们可以从npm仓库直接安装使用:
const scheduler = require('scheduler')
scheduler.unstable_scheduleCallback(scheduler.unstable_ImmediatePriority, () => {
console.log(111)
})
scheduler.unstable_scheduleCallback(scheduler.unstable_NormalPriority, () => {
console.log(222)
})
scheduleCallback可以认为是 scheduler 的入口方法,用于添加任务。这个方法主要有2个参数
scheduler 根据重要程度给任务分成了5个优先级
除了 NoPriority表示最低的优先级外,剩余的5个数值越小优先级越高。
下面看一下scheduleCallback方法
function unstable_scheduleCallback(priorityLevel, callback, options) {
var currentTime = getCurrentTime(); // 通过performance.now()获取当前时间
// 判断 options 参数中是否有延迟字段( delay ),有的话把 currentTime 和 delay 相加
var startTime;
if (typeof options === 'object' && options !== null) {
var delay = options.delay;
if (typeof delay === 'number' && delay > 0) {
startTime = currentTime + delay;
} else {
startTime = currentTime;
}
} else {
startTime = currentTime;
}
// 根据不同的优先级获取对应的超时时间,优先级越高,超时时间就越小,表示执行的越早
var timeout;
switch (priorityLevel) {
case ImmediatePriority:
timeout = IMMEDIATE_PRIORITY_TIMEOUT;
break;
case UserBlockingPriority:
timeout = USER_BLOCKING_PRIORITY_TIMEOUT;
break;
case IdlePriority:
timeout = IDLE_PRIORITY_TIMEOUT;
break;
case LowPriority:
timeout = LOW_PRIORITY_TIMEOUT;
break;
case NormalPriority:
default:
timeout = NORMAL_PRIORITY_TIMEOUT;
break;
}
// 这里需要说一下延迟时间(delay)和超时时间(timeout)的区别,延迟时间是业务定义的必须执行等待的;
// 而超时时间是根据任务优先级映射的时间,主要作用是给任务按优先级排序执行,只要没有高优先级的任务了,低优先级的任务也会立即执行。
// 当前时间(currentTime) + 延迟时间(delay) + 超时时间(timeout) = 任务的过期时间
var expirationTime = startTime + timeout;
// 新建一个任务
var newTask = {
id: taskIdCounter++, // 递增的id
callback, // 业务逻辑
priorityLevel, // 优先级
startTime, // 任务开始执行时间 currentTime + delay
expirationTime, // 过期时间 currentTime + delay + timeout
sortIndex: -1, // 排序索引
};
// 所有profile相关的都是用于代码调试,可忽略
if (enableProfiling) {
newTask.isQueued = false;
}
if (startTime > currentTime) { // 有延迟(delay)的情况
// This is a delayed task.
newTask.sortIndex = startTime; // 设置排序索引为开始时间,通过开始时间来给任务的执行排序
push(timerQueue, newTask); // 把任务放入到timerQueue,先简单任务是把任务放入数组中
if (peek(taskQueue) === null && newTask === peek(timerQueue)) { // 如果没有可执行的任务,并且上面新创建的任务是下一次待执行的任务
// 如果最近的一个任务需要延迟执行,则通过setTimeout方法,暂停delay时间后执行任务。主要用于性能优化,在没有任务时暂停代码运行
// All tasks are delayed, and this is the task with the earliest delay.
if (isHostTimeoutScheduled) {
// Cancel an existing timeout.
cancelHostTimeout();
} else {
isHostTimeoutScheduled = true;
}
// Schedule a timeout.
requestHostTimeout(handleTimeout, startTime - currentTime);
}
} else { // 没有延迟(delay)的情况,说明当前肯定有任务需要执行
newTask.sortIndex = expirationTime;
push(taskQueue, newTask);
if (enableProfiling) {
markTaskStart(newTask, currentTime);
newTask.isQueued = true;
}
// Schedule a host callback, if needed. If we're already performing work,
// wait until the next time we yield.
if (!isHostCallbackScheduled && !isPerformingWork) { // 没有暂停任务,也没有正在执行任务
isHostCallbackScheduled = true; // 暂停调度
requestHostCallback(flushWork); // 在下一个 event loop 执行 flushWork 方法
}
}
return newTask;
}
下面我们看一下 requestHostCallback 方法
function requestHostCallback(callback) {
scheduledHostCallback = callback; // 把 flushWork 方法赋给 scheduledHostCallback
if (!isMessageLoopRunning) { // 是否有任务正在执行
isMessageLoopRunning = true;
port.postMessage(null); // Scheduler 首选用 MessageChannel 调度下一个 event loop,在不支持 MessageChannel 的环境,或 nodejs 环境也 polyfill 了 setTimeout 的实现版本。主要的原因是 setTimout 方法自带了几毫秒的延时,在有大量的任务时会有比较大的性能问题
}
}
具体的 MessageChannel 的应用
const channel = new MessageChannel();
const port = channel.port2;
channel.port1.onmessage = performWorkUntilDeadline; // 当收到 postMessage 方法时会调用 performWorkUntilDeadline
每次 event loop 在 performWorkUntilDeadline 方法中处理
const performWorkUntilDeadline = () => {
if (scheduledHostCallback !== null) { // scheduledHostCallback 表示 flushWork
const currentTime = getCurrentTime(); // 获取当前时间
// Yield after `yieldInterval` ms, regardless of where we are in the vsync
// cycle. This means there's always time remaining at the beginning of
// the message event.
deadline = currentTime + yieldInterval; // yieldInterval 表示每个时间片可以执行任务的时间长度,默认5毫秒,可以通过 forceFrameRate 方法动态计算;在每个时间片内还会有多次 postMessage
const hasTimeRemaining = true; // 是否还有剩余时间
try {
const hasMoreWork = scheduledHostCallback(hasTimeRemaining, currentTime); // 执行 flushWork 方法
if (!hasMoreWork) { // 如果没有可执行的任务了
isMessageLoopRunning = false;
scheduledHostCallback = null;
} else {
// If there's more work, schedule the next message event at the end
// of the preceding one.
port.postMessage(null); // 如果还有可执行的任务 postMessage 递归调用 performWorkUntilDeadline 和 flushWork 方法
}
} catch (error) {
// If a scheduler task throws, exit the current browser task so the
// error can be observed.
port.postMessage(null);
throw error;
}
} else {
isMessageLoopRunning = false;
}
// Yielding to the browser will give it a chance to paint, so we can
// reset this.
needsPaint = false;
};
下面看一下 flushWork 方法
function flushWork(hasTimeRemaining, initialTime) {
if (enableProfiling) {
markSchedulerUnsuspended(initialTime);
}
// We'll need a host callback the next time work is scheduled.
isHostCallbackScheduled = false; // 取消暂停调度
if (isHostTimeoutScheduled) { // 把延迟暂停取消
// We scheduled a timeout but it's no longer needed. Cancel it.
isHostTimeoutScheduled = false;
cancelHostTimeout();
}
isPerformingWork = true; // 标识正在执行任务
const previousPriorityLevel = currentPriorityLevel; // 缓存当前的优先级
try {
if (enableProfiling) {
try {
return workLoop(hasTimeRemaining, initialTime);
} catch (error) {
if (currentTask !== null) {
const currentTime = getCurrentTime();
markTaskErrored(currentTask, currentTime);
currentTask.isQueued = false;
}
throw error;
}
} else {
// No catch in prod code path.
return workLoop(hasTimeRemaining, initialTime); // 具体执行任务
}
} finally {
currentTask = null;
currentPriorityLevel = previousPriorityLevel;
isPerformingWork = false; // 标识执行任务结束
if (enableProfiling) {
const currentTime = getCurrentTime();
markSchedulerSuspended(currentTime);
}
}
}
看 workLoop 方法
function workLoop(hasTimeRemaining, initialTime) {
let currentTime = initialTime; // 执行任务开始时间
advanceTimers(currentTime); // 把不再有延迟的任务(delay时间到了)从 timerQueue 放入到 taskQueue
currentTask = peek(taskQueue); // 从 taskQueue 按排序取下一个需要执行的任务
while (
currentTask !== null && // 任务不为空
!(enableSchedulerDebugging && isSchedulerPaused) // 这2个参数用于debug
) {
if (
currentTask.expirationTime > currentTime &&
(!hasTimeRemaining || shouldYieldToHost()) // 任务未过期 && (没有剩余时间 || 因为其他原因必须暂停)
) {
// This currentTask hasn't expired, and we've reached the deadline.
break; // 跳出不执行任务
}
const callback = currentTask.callback;
if (typeof callback === 'function') { // 回调必须是函数
currentTask.callback = null;
currentPriorityLevel = currentTask.priorityLevel;
const didUserCallbackTimeout = currentTask.expirationTime <= currentTime; // 任务过期了
markTaskRun(currentTask, currentTime); // 用于调试
const continuationCallback = callback(didUserCallbackTimeout); // 执行任务, 任务有一个参数,表示任务是否过期
currentTime = getCurrentTime(); // 获取当前时间
if (typeof continuationCallback === 'function') { // 如果任务会返回一个函数
currentTask.callback = continuationCallback; // 把返回的函数赋值给当前任务的回调
markTaskYield(currentTask, currentTime); // 用于调试
} else { // 否则,删除该次任务
if (enableProfiling) {
markTaskCompleted(currentTask, currentTime);
currentTask.isQueued = false;
}
if (currentTask === peek(taskQueue)) {
pop(taskQueue);
}
}
advanceTimers(currentTime); // 再次执行: 把不再有延迟的任务(delay时间到了)从 timerQueue 放入到 taskQueue
} else {
pop(taskQueue);
}
currentTask = peek(taskQueue); // 取出下一个任务
}
// Return whether there's additional work
if (currentTask !== null) { // 如果存在下一个任务,结束调用,进入下一次 event loop
return true;
} else {
// 如果不存在下一个任务,并且存在延迟的任务,暂停delay时间后再执行任务
const firstTimer = peek(timerQueue);
if (firstTimer !== null) {
requestHostTimeout(handleTimeout, firstTimer.startTime - currentTime);
}
return false;
}
}
最后一个没有仔细讲到的点是任务的排序,我们可以看一下 在 SchedulerMinHeap 文件中定义的几个方法
// 把任务放入到队列中,并执行 siftUp 方法
export function push(heap: Heap, node: Node): void {
const index = heap.length;
heap.push(node);
siftUp(heap, node, index);
}
// 取出第一个任务
export function peek(heap: Heap): Node | null {
const first = heap[0];
return first === undefined ? null : first;
}
// 返回第一个任务,把最后一个任务放到第一个位置,调用siftDown
export function pop(heap: Heap): Node | null {
const first = heap[0];
if (first !== undefined) {
const last = heap.pop();
if (last !== first) {
heap[0] = last;
siftDown(heap, last, 0);
}
return first;
} else {
return null;
}
}
// siftUp 方法,push 后调用
function siftUp(heap, node, i) {
let index = i; // i 是 push 后的任务的位置,也就是列表的最后一个位置
while (true) {
const parentIndex = (index - 1) >>> 1;// 把位置做位移操作,比如1 >>> 1 = 0, 2 >>> 1 = 1, , 4 >>> 1 = 2
const parent = heap[parentIndex]; // 获取位移后的位置的任务
if (parent !== undefined && compare(parent, node) > 0) { // 根据任务的sortIndex比较任务的大小,如果sortIndex相同,就根据任务的id比较;sortIndex就是任务的开始时间(currentTime + delay)。
// The parent is larger. Swap positions.
// 如果parent任务的开始时间比较晚,则和当前任务进行交互
// 其实就是个排序算法,按任务开始时间进行排序
heap[parentIndex] = node;
heap[index] = parent;
index = parentIndex;
} else {
// The parent is smaller. Exit.
return;
}
}
}
// siftDown 方法,pop 后调用
// 这个方法一开始很不理解,为什么要把最后一个任务放到第一个任务位置上,再给它排序
// 后来想了想,个人感觉是为了避免优先级较低的任务长时间不执行
function siftDown(heap, node, i) {
let index = i;
const length = heap.length;
while (index < length) {
const leftIndex = (index + 1) * 2 - 1;
const left = heap[leftIndex];
const rightIndex = leftIndex + 1;
const right = heap[rightIndex];
// If the left or right node is smaller, swap with the smaller of those.
if (left !== undefined && compare(left, node) < 0) {
if (right !== undefined && compare(right, left) < 0) {
heap[index] = right;
heap[rightIndex] = node;
index = rightIndex;
} else {
heap[index] = left;
heap[leftIndex] = node;
index = leftIndex;
}
} else if (right !== undefined && compare(right, node) < 0) {
heap[index] = right;
heap[rightIndex] = node;
index = rightIndex;
} else {
// Neither child is smaller. Exit.
return;
}
}
}
function compare(a, b) {
// Compare sort index first, then task id.
const diff = a.sortIndex - b.sortIndex;
return diff !== 0 ? diff : a.id - b.id;
}
原文:https://medium.com/@ryardley/react-hooks-not-magic-just-arrays-cd4f1857236e
我是 hooks api 的粉丝,但是,在使用 hooks 的时候,它会有一些奇怪的约束。如果你很难理解这些规则,不妨看看这篇文章。
先让大家能简单的理解新的hooks API的提案。
react 核心小组在提案文档指出,有2个使用规则是开发者必须去遵守的
第2个规则是很容易理解的,因为 hooks 本来设计的目的就是为了扩展函数式组件。
但是,第1个规则就相对不好理解了,也是这篇文章想去深入探讨的。
为了更好的理解,我们来看个简单的hooks的实现
注意:这个只是 hooks 的其中一种可能的实现,而不是 hooks 内部真正的实现
先看个简单的 state hook 的例子
function RenderFunctionComponent() {
const [firstName, setFirstName] = useState("Rudi");
const [lastName, setLastName] = useState("Yardley");
return (
<Button onClick={() => setFirstName("Fred")}>Fred</Button>
);
}你可以让 useState 返回一个 setter 函数,作为返回结果数组的第2个元素,这个 setter 函数会控制这个有 hook 生成的 state。
我们先标记下 React 内部可能是怎么实现。在渲染一个组件时会执行下图的逻辑。意思是说,数据是被存储在渲染组建之外。其他组件不共享 state,但是 state 可以响应特定组件随后的渲染。
创建2个空的数组:setters 和 state
光标指向0
初始化:2个空的数组,光标是0
第一次只想组件函数
每个 setState 第一次执行,推送一个 setter 函数(绑定一个光标位置)到 setters 数组中,推送一个 state 到 state 数组中
首次渲染:随着光标增加,各项被写入到数组中
随后的每次渲染,就是光标的重置,从各个数组中读值
随后的渲染:随着光标增加,各项从数组中被读取
每个 setter 都有一个光标位置的引用,所以每次调用 setter,都会改变对应的 state 的值。
setters 会记住他们的位置,根据位置去修改存储
下面是一个简单的代码示例实现
注意:这并不是 hooks 的完整实现,而是给你一个好的思路去思考 hooks 是怎么工作的。
let state = [];
let setters = [];
let firstRun = true;
let cursor = 0;
function createSetter(cursor) {
return function setterWithCursor(newVal) {
state[cursor] = newVal;
};
}
// This is the pseudocode for the useState helper
export function useState(initVal) {
if (firstRun) {
state.push(initVal);
setters.push(createSetter(cursor));
firstRun = false;
}
const setter = setters[cursor];
const value = state[cursor];
cursor++;
return [value, setter];
}
// Our component code that uses hooks
function RenderFunctionComponent() {
const [firstName, setFirstName] = useState("Rudi"); // cursor: 0
const [lastName, setLastName] = useState("Yardley"); // cursor: 1
return (
<div>
<Button onClick={() => setFirstName("Richard")}>Richard</Button>
<Button onClick={() => setFirstName("Fred")}>Fred</Button>
</div>
);
}
// This is sort of simulating Reacts rendering cycle
function MyComponent() {
cursor = 0; // resetting the cursor
return <RenderFunctionComponent />; // render
}
console.log(state); // Pre-render: []
MyComponent();
console.log(state); // First-render: ['Rudi', 'Yardley']
MyComponent();
console.log(state); // Subsequent-render: ['Rudi', 'Yardley']
// click the 'Fred' button
console.log(state); // After-click: ['Fred', 'Yardley']如果我们改变 hooks 的顺序,当外部因素或组件state变化导致重新渲染时,会发生什么?
让我们试试看
let firstRender = true;
function RenderFunctionComponent() {
let initName;
if(firstRender){
[initName] = useState("Rudi");
firstRender = false;
}
const [firstName, setFirstName] = useState(initName);
const [lastName, setLastName] = useState("Yardley");
return (
<Button onClick={() => setFirstName("Fred")}>Fred</Button>
);
}破坏了规则
这里我们在一个条件分支中使用了 useState,这导致了很大的问题。
渲染了一个错误的 hook,这个 hook 在后续的渲染会消失
这里我们说明了 firstName 和 lastName 2个变量,数据也是正确的。但是让我们看下第2次渲染
糟糕的第二次渲染
在渲染的时候去掉了一个 hook,导致了错误
state 存储变得不一致,firstName 和 lastName 都被设置成了 Rudi,这很明显是错误的,但是也让我们明白了 hooks 的规则要这样制定。
不遵守 react team 制定的规则,会导致数据不一致
现在应该明白了为什么 hooks 不能在条件分支和循环中。因为我们处理的是数据集合的光标,要是你改变了调用顺序,光标会对应不上,从而指向错误的数据或处理器。
关于 hooks api 的运行原理,希望我已经讲的比较明白了。最重要的是把这些重要的点组合起来,注意顺序,使用 hooks api 会得到很大的回报。
hooks 是为 react 组件设计的高效的插件式 api。只要你把 state 当成是数组集的模型,你就不会违反他的规则。
一天晚上,我姐给我发了一堆微信,大概意思是给我介绍了个对象,长得挺漂亮,学历很高,工作很好,让我抓紧点,一把年纪了;我敷衍着答应了。
第二天八点多到公司后,用手机号在微信上搜了一下,微信名里有个‘bao’,我想应该就是了,就发送了好友请求。过了一会微信显示好友提过了,我发了句:“hi你好”,“你好”她恢复到。我问:“上班了吗”;“上班了,我们九点上班”她又恢复到。我看已经九点了,就没有再发消息了。
晚上下班到家后,我拿起主机联系了对方,她挺热情友好的介绍了她的工作、学校以及到杭州的经历,过程比较轻松愉快友好;感觉还不错,沟通的挺顺畅的,有个不错的印象。
第二天下班后,我问她:“平常有什么爱好吗?”,过了许久,她回复到:“看书 地球 刷剧 (还有一个忘了,好像是旅行)”。她可能有事在忙,我突然有点语塞,不知如何回复,就匆匆结算了。
过了2天,快到周末了,我想要不约下一起见个面吃个饭。交付交换了一下时间地点,顺利的确定了。
大概提前了十几分钟,我到达了吃饭点滴,找了个角落的位置;过了10几分钟,她匆匆的过来了,穿着羽绒服,个子小小的,披散这头发,摘了口罩后,相视一笑,气氛略显尴尬。幸好服务员来上菜了,边吃边问一些有的没的家长里短的话,气氛稍显缓和。在灯光的映衬下,她带着笑容,说话不紧不慢,语气平缓,如同一位老师再将一个故事娓娓道来,我听得津津有味,不时笑着点头附和。时间流逝,不知不觉8点多了,吃的也差不多了,就一起买单下楼了,我问:“要不要送你回家?”;“不用了,我家离的不远,我坐车几站就到了”,她回复到。第一次见面,也还不是很熟,也不好勉强,不然返回生厌,就没有多说,说了再见后就开车回家了。到家后,礼貌性的问她:“到家没”;“骑车回去的,10几分钟就到了”,她说道。“下次还能再约一起吗”,我又问;过了一会,她回复到“可以啊(带个笑脸)”;我回复以笑脸。
看了一下公司的项目,从源代码角度看到了一些可优化的部分,有些比较典型,列举如下
/**
* 获取 browser 信息
*/
export function getBrowser() {
const ua = window.navigator.userAgent || "";
const isAndroid = /android/i.test(ua);
const isIos = /iphone|ipad|ipod/i.test(ua);
const isWechat = /micromessenger\/([\d.]+)/i.test(ua);
const isWeibo = /(weibo).*weibo__([\d.]+)/i.test(ua);
const isQQ = /qq\/([\d.]+)/i.test(ua);
const isQQBrowser = /(qqbrowser)\/([\d.]+)/i.test(ua);
const isQzone = /qzone\/.*_qz_([\d.]+)/i.test(ua);
// 安卓 chrome 浏览器,很多 app 都是在 chrome 的 ua 上进行扩展的
const isOriginalChrome = /chrome\/[\d.]+ Mobile Safari\/[\d.]+/i.test(ua) && isAndroid;
// chrome for ios 和 safari 的区别仅仅是将 Version/<VersionNum> 替换成了 CriOS/<ChromeRevision>
// ios 上很多 app 都包含 safari 标识,但它们都是以自己的 app 标识开头,而不是 Mozilla
const isSafari =
/safari\/([\d.]+)$/i.test(ua) &&
isIos &&
ua.indexOf("Crios") < 0 &&
ua.indexOf("Mozilla") === 0;
return {
isAndroid,
isIos,
isWechat,
isWeibo,
isQQ,
isQQBrowser,
isQzone,
isOriginalChrome,
isSafari
};
}getBrowser 方法是用于环境信息的方法,获取的方式本身没什么问题,但是有些信息有个特点:是不可变的,多次调用的结果其实是一样的。
这种情况,我们其实可以把这些环境信息缓存下来,避免重复获取。
const env = (function() {
return getBrowser();
})()就是通过自执行函数,预执行 getBrowser 方法,并将结果缓存在 env 变量中,这样就解决了多次调用重复执行的问题。但是这种方式有个问题:会延长加载脚本的时间,而且有可能自始至终都没用到这些信息,这样也是资源的浪费。
我们可以用单例模式的**做进一步优化。
const getEvn = (function() {
let env;
return function() {
if (!env) {
env = getBrowser();
}
return env;
}
})()这样的话,只有第一次执行时会调用 getBrowser 方法,后续调用都是用的第一次缓存的结果。上面的代码其实就是典型的单例模式的抽象实现,getBrowser 方法完全可以替换成其他方法。
const getSingle = function(fn) {
let ret;
return function() {
if (!ret) {
result = fn.apply(this, arguments)
}
return ret;
}
}
const getEnv = getSingle(getBrowser);/**
* 判断两个版本
* 比如:'1.5.5','1.5.0'进行比较,返回的是5,前面的版本大于后面5个版本
* @param {*} preV
* @param {*} nextV
*/
export const compareVersion = (preV, nextV) => {
const pvs = preV.split(".");
const nvs = nextV.split(".");
const rv = pvs[0] - nvs[0];
return rv === 0 && preV !== nextV
? compareVersion(pvs.splice(1).join("."), nvs.splice(1).join("."))
: rv;
};上面的主要是通过递归的方式判断2个版本号的大小。主要有2个问题
第一个问题很容易解决,只需要把递归方法的参数统一用数组即可。
const compareVersion = (preV, nextV) => {
const pvs = preV.split(".");
const nvs = nextV.split(".");
function _compare(pvs, nvs) {
const rv = pvs[0] - nvs[0];
return rv === 0 && pvs.length > 1 && nvs.length > 1
? _compare(pvs.slice(1), nvs.slice(1))
: rv;
}
return _compare(pvs, nvs);
};考虑到这个逻辑其实就是2个数组值大小的比对,用遍历可容易实现。
const compareVersion = (preV, nextV) => {
const pvs = preV.split(".");
const nvs = nextV.split(".");
let ret, i = 0;
for (; i < pvs.length && i < nvs.length; i++) {
ret = pvs[i] - nvs[i];
if (ret !== 0) {
break;
}
}
return ret;
};另外举个比较典型的遍历 > 递归的例子就是斐波那契数列 F(n) = F(n - 1) + F(n - 2)。如果用递归去解斐波那契数列,会造成大量的计算冗余,性能很低。
当然也可以通过缓存的方式避免重复计算,但是用遍历的方式是更好的选择。
function fib(n) {
if (n === 1) {
return 0;
}
if (n === 2) {
return 1;
}
let t1 = 0, t2 = 1, i = 3;
for (; i <= n; i++) {
if (i === n) {
return t1 + t2;
}
[t1, t2] = [t2, t1 + t2];
}
}/**
* 十进制数字精度转换
* @param {待转换数字} num
* @param {保留小数位数}} decimals
* @param {是否返回“+”符号} withSign
* 对于null, undefined, NaN均返回0.00
*/
function toFixed(num, decimals = 2, withSign, isOmitZero) {
let number = num;
if (typeof decimals !== "number") {
throw new TypeError("传入toFixed的decimals参数类型不正确");
}
if (typeof num !== "number") {
number = Number(num);
if (Number.isNaN(number)) {
return (0).toFixed(decimals);
}
}
if (Number.isNaN(number)) {
return (0).toFixed(decimals);
}
let result = number.toFixed(decimals);
if (isOmitZero) {
result = result.replace(/(?:\.0*|(\.\d+?)0+)$/, "$1");
}
if (withSign && num > 0) {
result = `+${result}`;
}
return result;
}当我们要实现一个比较复杂的功能时,我们需要对逻辑进行拆封和排序。以上面的 toFixed 方法为例,它实现的是数据格式化的功能,有4个参数
因为不同的数据类型格式化的方式是不同的,所以我们可以按数据的类型将这个功能分为3个部分:
尽量将特殊情况判断放在前面,这样可以使后面的分支中少很多的特殊情况判断,提取出可抽象的公共的代码逻辑
function toFixed(num, decimals = 2, withSign, isOmitZero) {
function zs(num, decimal) {
return num + '.' + '0'.repeat(decimal);
}
function xs(num, decimal) {
return parseFloat((num + '0'.repeat(decimal) + '1')).toFixed(decimal);
}
function isInt(n){
return parseInt(n) == parseFloat(n)
}
function isFloat(n) {
return parseInt(n) < parseFloat(n)
}
let ret = num;
if (num == 0 && num !== 0 && num !== '0') {
if (isOmitZero) {
return '0.00';
}
} else if (typeof num === 'string' || typeof num === 'number') {
if (isInt(num)) {
ret = zs(num, decimals);
} else if (isFloat(num)) {
ret = xs(num, decimals);
}
if (withSign && ret > 0) {
ret = '+' + ret;
}
}
return ret;
}这样可以让代码的层次更加的清晰、易读。
还可以用策略模式进一步减少分支判断:
const formats = {
zs: function(num, decimal) {
return num + '.' + '0'.repeat(decimal);
},
xs: function(num, decimal) {
return parseFloat((num + '0'.repeat(decimal) + '1')).toFixed(decimal);
},
default: function(num, decimal) {
return num;
},
}
function whichFormat(n){
const i = parseInt(n);
const f = parseFloat(n);
if (i == f) {
return 'zs';
} else if (i < f) {
return 'xs';
} else {
return 'default';
}
}
function toFixed(num, decimals = 2, withSign, isOmitZero) {
let ret = num;
if (num == 0 && num !== 0 && num !== '0') {
if (isOmitZero) {
return '0.00';
}
} else if (typeof num === 'string' || typeof num === 'number') {
ret = formats[whichFormat(num)](num, decimals);
if (withSign && ret > 0) {
ret = '+' + ret;
}
}
return ret;
}可以看到主要的逻辑实现已经从原方法中进行了拆封,而且该逻辑是可扩展的,原方法中只剩下一些特殊情况的处理逻辑。
本文基于《javascript数据结构与算法》一书
动态规划(Dynamic Programming,DP)是一种将复杂问题分解成更小的子问题来解决的优化技术。用动态规划解决问题时,要遵循三个重要步骤:
插入排序就是动态规划的**
贪心算法遵循一种近似解决问题的技术,期盼通过每个阶段的局部最优选择(当前最好的 解),从而达到全局的最优(全局最优解)。它不像动态规划那样计算更大的格局。
vue的template是支持表达式赋值的,比如
{{'hello ' + name}}:{{age}}解析表达式之前,我们先解析出{{}}的内容
let data = {
abc: 2,
efg: 3
}
let expr = '{{1 + abc / 2}} - {{efg * 2 }} + \'abc\'';
const exprReg1 = /{{([^{{}}]+)}}/g;
expr.replace(exprReg1, (r, $1) => {
console.log($1);
})我们可以看到打印出来的结果
1 + abc / 2
efg * 2 然后再对上面解析出来的结果做表达式解析
const exprReg2 = /[\s|\+|-|\*|/]?([^\s|\+|-|\*|/]+)[\s|\+|-|\*|/]?/g;
let expr = '1 + abc / 2';
expr.replace(exprReg2, (r, $1) => {
if (/^[a-zA-Z\$].*/.test($1)) { //
console.log($1);
}
})查看结果
abc汇总成一个方法
function renderExpr(expr) {
function renderParam(expr) {
return expr.replace(exprReg2, (r, $1) => {
if (/^[a-zA-Z\$].*/.test($1)) {
return 'data.' + $1
}
return $1;
})
}
return expr.replace(exprReg1, (r, $1) => {
return renderParam($1)
})
}但是还有个问题,我们每次调用renderExpr方法的时候都会新创建renderParam方法,我们可以用闭包缓存下
function createRenderExpr() {
function renderParam(expr) {
return expr.replace(exprReg2, (r, $1) => {
if (/^[a-zA-Z\$].*/.test($1)) {
return 'data.' + $1
}
return $1;
})
}
return function renderExpr(expr) {
return expr.replace(exprReg1, (r, $1) => {
return renderParam($1)
})
}
}
const renderExpr = createRenderExpr();
let data = {
abc: 2,
efg: 3
}
let expr = '{{ 1 + abc / 2}} - {{efg * 2 }} + \'abc\'';
console.log(renderExpr(expr));执行结果
1+data.abc/2 - data.efg*2 + 'abc'
从上图的vue初始化完整的流程图中,可以看到vue的一些核心能力,后面会详细解析
原文:https://medium.com/@deathmood/how-to-write-your-own-virtual-dom-ee74acc13060
构建你自己的虚拟DOM,你需要知道2个事情。你不需要理解 React,或者深入其他虚拟DOM的实现源码。他们太过庞大和复杂,事实上,虚拟DOM的核心代码的实现甚至可以少于50行代码。
下面是2个原则:
下面让我们深入上面的2个原则。
首先,我们需要一种方式来存储dom树。我们可以使用 javascript 对象。假设我们有下面这样一颗树:
<ul class=”list”>
<li>item 1</li>
<li>item 2</li>
</ul>
看起来是不是很简单,我们如何用 javascript 对象表示这棵树呢?
{
"type":"ul",
"props":{
"class":"list"
},
"children":[
{
"type":"li",
"props":{
},
"children":[
"item 1"
]
},
{
"type":"li",
"props":{
},
"children":[
"item 2"
]
}
]
}
我们可以注意到2个事情:
{ type: ‘…’, props: { … }, children: [ … ] }
但是用这种方式编写一棵很大的树会很困难,所我们需要一个帮助方法,这样可以使我们很容易理解DOM树的结构。
function h(type, props, …children) {
return { type, props, children };
}
现在我们可以这样编写我们的DOM树:
h(‘ul’, { ‘class’: ‘list’ },
h(‘li’, {}, ‘item 1’),
h(‘li’, {}, ‘item 2’),
);
看起来清晰多了,但是我们可以更进一步。你应该听说过 JSX ,我想在这样用到它。它是怎么工作的呢?
如果你读了 Babel JSX 文档 ,你会知道 Babel 把下面的代码:
<ul className=”list”>
<li>item 1</li>
<li>item 2</li>
</ul>
转化成:
React.createElement(‘ul’, { className: ‘list’ },
React.createElement(‘li’, {}, ‘item 1’),
React.createElement(‘li’, {}, ‘item 2’),
);
是不是很相似?如果把 React.createElement(…) 替换为 h(…),我们就可以使用 jsx 语法。我们只需要在文件头部添加一行注释。
/** @jsx h */
<ul className=”list”>
<li>item 1</li>
<li>item 2</li>
</ul>
它会告诉 Babel 把 React.createElement(…) 替换为 h(…)。当然,h 也可以用其他任意的方法。
做个总结,我会这样写 DOM:
/** @jsx h */
const a = (
<ul className=”list”>
<li>item 1</li>
<li>item 2</li>
</ul>
);
Babel 会把它翻译为:
const a = (
h(‘ul’, { className: ‘list’ },
h(‘li’, {}, ‘item 1’),
h(‘li’, {}, ‘item 2’),
);
);
当 h 方法执行时,它会返回 js 对象 - 虚拟DOM:
const a = (
{ type: ‘ul’, props: { className: ‘list’ }, children: [
{ type: ‘li’, props: {}, children: [‘item 1’] },
{ type: ‘li’, props: {}, children: [‘item 2’] }
] }
);
现在我们有了根据我们的要求用 js 对象表达的 DOM 树。但是我们需要根据 DOM 树创建真实的 DOM。因为我们不能直接追加表达式到真实的DOM中。
首先我们做一些假设,制定一下术语:
真实DOM节点的变量我会以 $ 开头,因此 $parent 就是一个真实的DOM元素
虚拟DOM表达式将在名为node的变量中
比如在 React 中,你只会有一个根节点(one root node),其他所有的节点都在根节点下
入上文所说,让我们创建 createElement(…),函数会把一个虚拟DOM节点转化为一个真实DOM节点。暂时忘记 props 和 children,我们会在后面设置。
function createElement(node) {
if (typeof node === ‘string’) {
return document.createTextNode(node);
}
return document.createElement(node.type);
}
我们支持 文本节点 (就是js字符串) 和 元素节点 (就是js对象)。
{ type: ‘…’, props: { … }, children: [ … ] }
这样,我们可以同时传递文本节点和元素节点。
现在我们考虑一下 children,children 的每个元素要么是文本节点,要么是元素节点。所以我们也可以通过 createElement(…) 方法创建。有没有感觉就是个递归,我们可以未元素 children 的调用 createElement(…) 方法,appendChild() 他们到元素中。
function createElement(node) {
if (typeof node === ‘string’) {
return document.createTextNode(node);
}
const $el = document.createElement(node.type);
node.children
.map(createElement)
.forEach($el.appendChild.bind($el));
return $el;
}
我们暂时把 props 放到一边,后面再讨论。理解虚拟DOM的基础原则不需要用到它们, 而且它们会增加复杂度。
现在我们可以把一个虚拟DOM转化为真实的DOM,是时候取考虑比对我们的虚拟DOM树。就是说,我们需要实现一个算法,算法会比对2棵虚拟DOM树 - 新的和旧的,真实的DOM只做必要的更新。
如何比较2棵树?我们需要处理下一个例子:




让我们创建一个函数 updateElement(…),函数有3个参数-$parent, newNode and oldNode。$parent 是真实的DOM节点,虚拟DOM的父亲节点。现在让我们看看怎么处理上面提到的所有例子。
这个很简单,我都不用注释:
function updateElement($parent, newNode, oldNode) {
if (!oldNode) {
$parent.appendChild(
createElement(newNode)
);
}
}
如果新的虚拟DOM树的当前位置没有节点,我们需要从真实DOM中删除对应的节点。我们知道父亲节点,这样就可以调用 *$parent.removeChild(…)*方法,传递真实的DOM节点引用。但是我们没有这个引用。但是如果我们知道节点在夫妻节点中的位置,我们可以通过 $parent.childNodes[index] 拿到这个引用,inex 是节点在父亲节点中的位置。
假设 index 会传递到我们的方法中。代码如下:
function updateElement($parent, newNode, oldNode, index = 0) {
if (!oldNode) {
$parent.appendChild(
createElement(newNode)
);
} else if (!newNode) {
$parent.removeChild(
$parent.childNodes[index]
);
}
}
首先我们创建一个方法用于比较2个节点(新的和旧的),告诉我们哪个节点有变化。我们需要同时考虑元素节点和文本节点。
function changed(node1, node2) {
return typeof node1 !== typeof node2 ||
typeof node1 === ‘string’ && node1 !== node2 ||
node1.type !== node2.type
}
有了 index,我们很容易用新节点替换它:
function updateElement($parent, newNode, oldNode, index = 0) {
if (!oldNode) {
$parent.appendChild(
createElement(newNode)
);
} else if (!newNode) {
$parent.removeChild(
$parent.childNodes[index]
);
} else if (changed(newNode, oldNode)) {
$parent.replaceChild(
createElement(newNode),
$parent.childNodes[index]
);
}
}
最好,我们需要遍历节点的子节点并且进行比对。我们把这个过程叫 *updateElement(…) *。就是个递归。
在写代码之前我们需要考虑到:
undefined,我们的方法也可以处理。children 数组中的索引。function updateElement($parent, newNode, oldNode, index = 0) {
if (!oldNode) {
$parent.appendChild(
createElement(newNode)
);
} else if (!newNode) {
$parent.removeChild(
$parent.childNodes[index]
);
} else if (changed(newNode, oldNode)) {
$parent.replaceChild(
createElement(newNode),
$parent.childNodes[index]
);
} else if (newNode.type) {
const newLength = newNode.children.length;
const oldLength = oldNode.children.length;
for (let i = 0; i < newLength || i < oldLength; i++) {
updateElement(
$parent.childNodes[index],
newNode.children[i],
oldNode.children[i],
i
);
}
}
}
/** @jsx h */
function h(type, props, ...children) {
return { type, props, children };
}
function createElement(node) {
if (typeof node === 'string') {
return document.createTextNode(node);
}
const $el = document.createElement(node.type);
node.children
.map(createElement)
.forEach($el.appendChild.bind($el));
return $el;
}
function changed(node1, node2) {
return typeof node1 !== typeof node2 ||
typeof node1 === 'string' && node1 !== node2 ||
node1.type !== node2.type
}
function updateElement($parent, newNode, oldNode, index = 0) {
if (!oldNode) {
$parent.appendChild(
createElement(newNode)
);
} else if (!newNode) {
$parent.removeChild(
$parent.childNodes[index]
);
} else if (changed(newNode, oldNode)) {
$parent.replaceChild(
createElement(newNode),
$parent.childNodes[index]
);
} else if (newNode.type) {
const newLength = newNode.children.length;
const oldLength = oldNode.children.length;
for (let i = 0; i < newLength || i < oldLength; i++) {
updateElement(
$parent.childNodes[index],
newNode.children[i],
oldNode.children[i],
i
);
}
}
}
// ---------------------------------------------------------------------
const a = (
<ul>
<li>item 1</li>
<li>item 2</li>
</ul>
);
const b = (
<ul>
<li>item 1</li>
<li>hello!</li>
</ul>
);
const $root = document.getElementById('root');
const $reload = document.getElementById('reload');
updateElement($root, a);
$reload.addEventListener('click', () => {
updateElement($root, b, a);
});
恭喜,我们做到了。我们实现了虚拟DOM。通过这个文章,我们读者能理解虚拟DOM的基本原则,以及 React 底层是怎么工作的。
然而有一些这里没有提到的:
ReactjQuery 和它的插件基于《javascript数据结构预算法》一书的5大排序算法
/**
* 冒泡排序比较任何两个相邻的项,如果第一个比第二个大,则交换它们。元素项向上移动至 正确的顺序,就好像气泡升至表面一样,冒泡排序因此得名
*/
function bubbleSort(arr = []) {
if (arr.length <= 1) {
return;
}
for(let i = 0; i < arr.length; i ++) {
for (let j = 0; j < arr.length - i; j++) {
if (arr[j] > arr[j + 1]) {
[arr[j], arr[j + 1]] = [arr[j + 1], arr[j]];
}
}
}
}
/**
* 选择排序算法是一种原址比较排序算法。选择排序大致的思路是找到数据结构中的最小值并 2 将其放置在第一位,接着找到第二小的值并将其放在第二位,以此类推。
*/
function selectionSort(arr = []) {
if (arr.length <= 1) {
return;
}
for (let i = 0; i < arr.length; i++) {
let min;
let minIdx;
for (let j = i; j < arr.length; j++) {
if (!min || arr[j] < min) {
minIdx = j;
min = arr[j];
}
}
if (i !== minIdx) {
[arr[i], arr[minIdx]] = [arr[minIdx], arr[i]]
}
}
}
/**
* 插入排序是依次将将后面的元素插入到已经排好序的前面的元素中
*/
function insertionSort(arr = []) {
if (arr.length <= 1) {
return;
}
for (let i = 1; i < arr.length; i++) {
for (let j = i; j >= 0; j--) {
if (arr[j] < arr[j - 1]) {
[arr[j], arr[j - 1]] = [arr[j - 1], arr[j]];
} else {
break;
}
}
}
}
/**
* 归并排序是一种分治算法。其**是将原始数组切分成较小的数组,直到每个小数组只有一 个位置,接着将小数组归并成较大的数组,直到最后只有一个排序完毕的大数组。
*/
function mergeSort(arr = []) {
if (arr.length <= 1) {
return arr;
}
function merge(left, right) {
const ret = [];
let i = 0, j = 0;
while (i < left.length && j < right.length) {
if (left[i] < right[j]) {
ret.push(left[i ++]);
} else {
ret.push(right[j ++]);
}
}
while (i < left.length) {
ret.push(left[i ++]);
}
while (j < right.length) {
ret.push(right[j ++]);
}
return ret;
}
function sliceArr(arr) {
if (arr.length <= 1) {
return arr;
}
const midInx = Math.floor(arr.length / 2);
const left = arr.slice(0, midInx);
const right = arr.slice(midInx, arr.length);
return merge(sliceArr(left), sliceArr(right));
}
return sliceArr(arr);
}
/**
* 快速排序也使用分治的方法,将原始数组分 为较小的数组(但它没有像归并排序那样将它们分割开)。
*/
function quickSort(arr = []) {
function sort(arr = []) {
if (arr.length <= 1) {
return arr;
}
if (arr.length == 2) {
if (arr[0] > arr[1]) {
return [arr[1], arr[0]];
} else {
return arr;
}
}
let tmp = arr[0], left = [], right = [], i = 0;
while (i < arr.length) {
if (arr[i] < tmp) {
left.push(arr[i]);
} else {
right.push(arr[i]);
}
i++;
}
return [...sort(left), ...sort(right)];
}
return sort(arr);
}A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.