A tiny Approximate K-Nearest Neighbours Python Vector Database specifically designed to offer high performance and be easy to read. The main ingredient is an optimized implementation of 4bit Product Quantization (PQ) which enables fast approximate distance computations, 50 times faster than NumPy/BLAS.
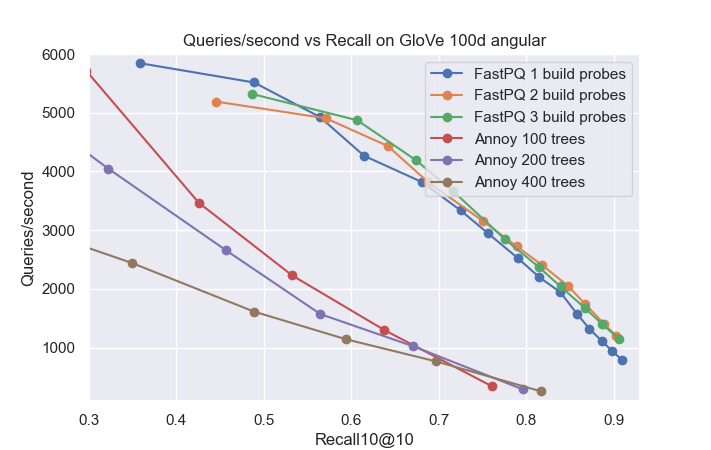
(Performance tradeoff on ANN Benchmarks. Up and to the right is better.)
FastPQ is a very lightweight index, much smaller than the dataset itself. It is also quick to build, requiring only a single pass of sklearn's KMeans over the dataset.
Let's generate some random data
import numpy as np
X = np.random.rand(10000, 128)
queries = np.random.rand(100, 128)We can use the FastPQ class to quantize the data and perform nearest neighbor search.
from tinyknn import FastPQ
# Initialize PQ with 64 columns of 2 dimensions each
pq = FastPQ(dims_per_block=2)
X_compressed = pq.fit_transform(X)
# Compute exact k-nearest neighbors, accelerated by PQ
for q in queries:
distance_table = pq.distance_table(q)
est8 = distance_table.estimate_distances(X_compressed)
print("Probably nearest neighbor:", est8.argmin())This will return the 10 nearest neighbors for each query, as well as the distances to those neighbors.
Note that we want a quite low dims_per_block compared to other Product Quantization methods, since we only use 4 bits per block.
This again can be attributed to the SSE instructions only allowing 4 bit table lookups.
We can use the IVF class to perform approximate nearest neighbor search with Inverted File Indexing.
from tinyknn import IVF
ivf = IVF("euclidean", n_clusters=100).fit(X).build(X)
neighbors = ivf.query(queries, k=10, n_probes=10)This will perform approximate nearest neighbor search using Inverted File Indexing, with 10 probes for each query. Note that we first have to call the fit method to build the codebook, and then the build method to populate the inverted file.
See also examples/ for more detailed examples of usage.
You need to build tinyknn before you can run it, as it contains Cython code.
The easiest way to do this is to simply run
$ pip install .To test it we can run an example:
$ python -m examples.example
n=16000, d=128, queries=1000, dims_per_block=2
Sampling
Computing true neighbours
Fitting PQ
Querying
Median place of true nearest neighbor: 1.0
90% quantile: 19.0
Queries/second: 7101.262693814528
Total time spent on preprocess: 0.09025406837463379
Total time spent on search: 0.05056595802307129
Scipy speed for comparison: 2.249645948410034In this example Fast PQ is about 16 times faster than optmized scipy/numpy. The reason is that Fast PQ uses a trick called Accelerated Nearest Neighbor Search with Qick ADC with which SIMD instructions are used to perform 16 inner product operations in a single instruction.
If you are helping develop tinyknn, and need to test a change to the Cython code, you can rebuild it with
$ python setup.py build_ext --inplaceThe project consists of two main classes: IVF and FastPQ. The IVF class is used to build an IVF index with cluster centers, fit a product quantizer on the data, and perform queries on the index. The FastPQ class is used to create a product quantizer that can quickly transform data and compute distance tables.
IVF: This class is responsible for creating an IVF index using clustering (either Euclidean or angular) and FastPQ for quantization. It provides methods to fit the index on data, build the index with quantized data, and query the index for nearest neighbors. Main methods:
- fit: Fit the IVF index on the given data by finding cluster centers and fitting the product quantizer.
- build: Build the IVF index by assigning data points to their nearest clusters and applying the product quantizer transformation.
- query: Query the IVF index to find the k nearest neighbors for a given query point.
FastPQ: This class implements a fast product quantization method using k-means clustering with 16 clusters. It provides methods for fitting the quantizer on data, transforming data using the quantizer, and computing distance tables for a given query. It has three main methods:
- fit: Fit the FastPQ model on the given data by applying k-means clustering on each block of dimensions.
- transform: Compress the given data using the FastPQ model.
- distance_table: Compute a distance table for the given query vector using the FastPQ model. See below.
DistanceTable: This class is initialized by calling the distance_table method on FastPQ with a query point. The distance table provides methods to estimate distances between query and data points, as well as find the top nearest neighbors. It has two methods:
-
estimate_distances: Estimate the distance from the query point to a set of quantized (PQ transformed) data points.
-
top: Finds the k data points nearest to the query, given both quantized and raw data points. The method works in two passes: First 3k or so nearest points, according to the quantized data, are retrieved. Then the raw data is used to rescore and return the best k points among those.
To benchmark on the GloVe dataset, first download and preprocess it using
examples/glove/prepare-dataset.sh
Then run
$ python3 -m examples.bench examples/glove/dataset/glove.twitter.27B.100d.npy --metric angular
Loading and shuffling...
num_points=1183514, num_dims=100, num_queries=10000, dims_per_block=2, num_clusters=1087
...
Querying
Recall10@10: 0.37403000000000003
Queries/second: 4727.144941521318
Recall10@10: 0.5021399999999999
Queries/second: 3965.6137940410995
...

















