Dalam proyek machine learning ini domain yang saya pilih adalah mengenai keuangan (cryptocurrency) dengan judul "Etherium Price Predictive Analytics".
https://www.kaggle.com/datasets/sudalairajkumar/cryptocurrencypricehistory?select=coin_Ethereum.csv
Dalam beberapa tahun ini anda pasti sudah sering mendengar perihal cryptocurrency bukan? Secara sederhana, cryptocurrency ialah sebuah mata uang digital. Cryptocurrency tidak tersedia dalam bentuk fisik seperti koin atau uang tunai yang digunakan secara umum di seluruh dunia. Dalam cryptocurrency, seluruhnya benar-benar virtual. Meskipun demikian, uang digital tersebut memiliki nilai yang cukup tinggi.
Cryptocurrency dapat disimpan dalam ‘dompet digital’ yang tersedia dalam telepon genggam atau perangkat komputer lainnya. Selain itu, pemilik cryptocurrency juga dapat menggunakan mata uang digital untuk keperluan transaksi jual-beli.
salah satu mata uang kripto yang pupuler adalah Etherium (ETH), Ethereum adalah platform perangkat lunak terdesentralisasi yang memungkinkan Smart Contracts and Distributed Applications (DApps) dibangun dan dijalankan tanpa waktu henti (downtime), penipuan, kontrol, atau gangguan dari pihak ketiga. Definisi ini tercantum dalam buku Ekonomi dan Bisnis Digital.
Mengutip Dasar Investasi dan Trading Cryptocurrency, Ethereum sendiri membangun sebuah jaringan blockchain yang berfokus pada koin Ethereum. Para developer koin bisa membuat koinnya masing-masing di atas jaringan Ethereum.
karena populernya koin Etherium dalam dunia Cryptocurrency Tersebut juga banyak orang yang mempertimbangkan dan menganalisa untuk membeli koin tersebut, maka dengan adanya model machine learning ini diharapkan bisa membantu memudahkan analisa serta dapat mengambil keputusan yang tepat agar bisa bermanfaat bagi banyak orang dimasa depan, aamiin.
Berdasarkan pada latar belakang di atas, permasalahan yang dapat diselesaikan pada proyek ini adalah sebagai berikut:
- Bagaimana cara membangun model machine learning untuk memprediksi data harga Etherium di masa mendatang?
- bagaimana cara membuat pra pemrosesan data?
Tujuan dibuatnya proyek ini adalah sebagai berikut:
- membuat pra pemrosesan data
- Membangun model machine learning untuk memprediksi data harga di masa mendatang dengan tingkat akurasi > 70%.
Solusi yang dapat dilakukan untuk memenuhi tujuan dari proyek ini di antaranya:
-
Pra-pemrosesan Data. Pada pra-pemrosesan data dapat dilakukan beberapa tahapan, antara lain:
- Melakukan perhitungan rerata berdasarkan data Open, Close, High dan Low.
- Melakukan pembagian dataset.
- Mengatasi data pencilan (outliers) dengan Metode IQR.
- Standardisasi data fitur numerik pada dataset.
-
Pembangunan Model. Pada pembangunan model terdapat beberapa algoritma yang digunakan, antara lain:
- K-Nearest Neighbor
- Random Forest
- Boosting Algorithm
-
Informasi Dataset Dataset yang digunakan pada proyek ini yaitu dataset lengkap dengan riwayat harga Etherium yang saya temukan di kaggle dengan lik dihalaman atas laporan ini.
Setelah melakukan observasi pada dataset yang diunduh melalui link Kaggle yaitu
https://www.kaggle.com/datasets/sudalairajkumar/cryptocurrencypricehistory?select=coin_Ethereum.csv, didapatkan informasi sebagai berikut :- Terdapat 2160 baris.
- Terdapat 10 kolom yaitu
SNo, Name, Symbol, Date, High, Low, Open, Close, Volume, Marketcapyang merupakan variabel - variabel pada data - Dari kolom-kolom tersebut terdapat 6 kolom numerik dengan tipe data float64, yaitu
High, Low, Open, Close, Volume, Marketcapdan terdapat 1 kolom numerik dengan tipe data int64 yaituSNoyang merupakan fitur numerik. - Terdapat 2 kolom dengan tipe object yaitu
Name, Symbol - Tidak terdapat missing value pada dataset.
Untuk penjelasan mengenai variabel-variabel pada dataset dapat dilihat pada poin-poin berikut ini:
- Date : Tanggal pencatatan data
- Open : harga ketika dibuka yang dihitung perhari
- Close : harga ketika ditutup yang dihitung perhari
- Low : harga terendah perhari
- High : harga tertinggi perhari
- Volume : volume transaksi perhari
- Market Cap : Kapitalisasi Pasar berdasarkan USD
-
Sebaran atau Distribusi Data pada Setiap Fitur
sebelum masuk ke tahap distribusi data, persiapan awal yang dilakukan yaitu perlu membuat dua variabel baru yaitu variabel OHLC_Average untuk menampung rata-rata harga dan Price_After_Month untuk harga setelah sebulan.
Berikut merupakan visualisasi data yang menunjukkan sebaran/distribusi data pada setiap fitur-fitur numerik (High, Low, Open, Close, OHLC_Average, Price_After_Month) :-
Mengidentifikasi Missing Value dan Outlier

Gambar 1.Mengidentifikasi outlier
Terlihat jika di atas banyak terdapat outlier pada setiap variabel, lalu untuk mengatasinya nantinya penulis akan menerapkan batas bawah dan batas atas menggunakan metode IQR. Hal pertama yang perlu Anda lakukan adalah membuat batas bawah dan batas atas. Untuk membuat batas bawah, kurangi Q1 dengan 1,5 * IQR. Kemudian, untuk membuat batas atas, tambahkan 1.5 * IQR dengan Q3. -
Univariate Analysis

Gambar 2.Univariate Analysis
Terlihat pada grafik bahwa semua data cenderung distribusi nilainya miring ke kanan (right-skewed). Hal ini akan berimplikasi pada model nantinya. -
Multivariate Analysis

Gambar 3.Multivariate Analysis
Terlihat bahwa pada grafik kebanyakan bernilai positif karena kebanyakan grafik pada sumbu y dan x mengalami peningkatan yang cukup signifikan membentuk sebuah garis lurus.
Gambar 4.korelasi matrix
Terlihat pada matriks korelasi di atas dapat disimpulkan bahwa semua variabel memiliki keterikatan dan korelasi yang kuat antar variabel lainnya, dimana nilai korelasi antar variabel bernilai lebih dari 0.8 atau mendekati 1.
-
Berikut ini merupakan tahapan-tahapan dalam melakukan pra-pemrosesan data:
- Melakukan Penanganan Missing Value dan Outlier
setelah di cek ternyata tidak terdapat missing value pada data set, akan tetapi terdapat data outlier pada dataset, penulis menggunakan penentuan batas atas dan bawah nilai kuartil pada data dengan menggunakan metode IQR. - Melakukan pembagian dataset
seperti biasa dataset dibagi menjadi 2 yaitu data latih (train) dan data uji (test) dengan rasio yang digunakan yaitu data uji dengan rasio 80% untuk data latih dan 20% untuk data uji. - Standardisasi data pada semua fitur numerik pada dataset
Standardisasi adalah teknik transformasi yang paling umum digunakan dalam tahap persiapan pemodelan. Untuk fitur numerik, kita tidak akan melakukan transformasi dengan one-hot-encoding seperti pada fitur kategori. Kita akan menggunakan teknik StandarScaler dari library Scikitlearn,
Pada proyek ini, Proses modeling dalam proyek ini menggunakan 3 algoritma machine learning yaitu K-Nearest Neighbor, Random Forest dan Boosting Algorithm kemudian membandingkan performanya.
-
K-Nearest Neighbor
KNN adalah algoritma yang relatif sederhana dibandingkan dengan algoritma lain. Algoritma KNN menggunakan ‘kesamaan fitur’ untuk memprediksi nilai dari setiap data yang baru. Dengan kata lain, setiap data baru diberi nilai berdasarkan seberapa mirip titik tersebut dalam set pelatihan.
KNN bekerja dengan membandingkan jarak satu sampel ke sampel pelatihan lain dengan memilih sejumlah k tetangga terdekat (dengan k adalah sebuah angka positif). Nah, itulah mengapa algoritma ini dinamakan K-nearest neighbor (sejumlah k tetangga terdekat). KNN bisa digunakan untuk kasus klasifikasi dan regresi.
Meskipun algoritma KNN mudah dipahami dan digunakan, ia memiliki kekurangan jika dihadapkan pada jumlah fitur atau dimensi yang besar. Permasalahan ini sering disebut sebagai curse of dimensionality (kutukan dimensi). Pada dasarnya, permasalahan ini muncul ketika jumlah sampel meningkat secara eksponensial seiring dengan jumlah dimensi (fitur) pada data. Jadi, jika Anda menggunakan model KNN, pastikan data yang digunakan memiliki fitur yang relatif sedikit, ya!
Kita menggunakan k = 10 tetangga dan metric Euclidean untuk mengukur jarak antara titik. Pada tahap ini kita hanya melatih data training dan menyimpan data testing untuk tahap evaluasi yang akan dibahas di Modul Evaluasi Model. -
Random Forest
Algoritma random forest adalah salah satu algoritma supervised learning. Ia dapat digunakan untuk menyelesaikan masalah klasifikasi dan regresi. Random forest juga merupakan algoritma yang sering digunakan karena cukup sederhana tetapi memiliki stabilitas yang mumpuni.
Random forest merupakan salah satu model machine learning yang termasuk ke dalam kategori ensemble (group) learning. Apa itu model ensemble? Sederhananya, ia merupakan model prediksi yang terdiri dari beberapa model dan bekerja secara bersama-sama. Ide dibalik model ensemble adalah sekelompok model yang bekerja bersama menyelesaikan masalah. Sehingga, tingkat keberhasilan akan lebih tinggi dibanding model yang bekerja sendirian. Pada model ensemble, setiap model harus membuat prediksi secara independen. Kemudian, prediksi dari setiap model ensemble ini digabungkan untuk membuat prediksi akhir.
Parameter yang digunakan pada proyek ini adalah : -
n_estimator: jumlah trees (pohon) di forest. Di sini kita set n_estimator=50.
-
max_depth: kedalaman atau panjang pohon. Ia merupakan ukuran seberapa banyak pohon dapat membelah (splitting) untuk membagi setiap node ke dalam jumlah pengamatan yang diinginkan.
-
random_state: digunakan untuk mengontrol random number generator yang digunakan.
-
n_jobs: jumlah job (pekerjaan) yang digunakan secara paralel. Ia merupakan komponen untuk mengontrol thread atau proses yang berjalan secara paralel. n_jobs=-1 artinya semua proses berjalan secara paralel.
-
Boosting Algorithm
Seperti namanya, boosting, algoritma ini bertujuan untuk meningkatkan performa atau akurasi prediksi. Caranya adalah dengan menggabungkan beberapa model sederhana dan dianggap lemah (weak learners) sehingga membentuk suatu model yang kuat (strong ensemble learner). Algoritma boosting muncul dari gagasan mengenai apakah algoritma yang sederhana seperti linear regression dan decision tree dapat dimodifikasi untuk dapat meningkatkan performa.
Algoritma boosting telah ada sejak puluhan tahun lalu. Namun, baru beberapa tahun ini ramai dibicarakan. Mengapa algoritma ini begitu populer akhir-akhir ini?
Salah satu alasannya adalah peningkatan algoritma boosting dalam kompetisi machine learning atau data science. Algoritma ini sangat powerful dalam meningkatkan akurasi prediksi. Algoritma boosting sering mengungguli model yang lebih sederhana seperti logistic regression dan random forest. Beberapa pemenang kompetisi di platform Kaggle menyatakan bahwa mereka menggunakan algoritma boosting atau kombinasi beberapa algoritma boosting dalam modelnya. Meskipun demikian, hal ini tetap bergantung pada kasus per kasus, ruang lingkup masalah, dan dataset yang digunakan.
Dapat disimpulkan model terbaik yang digunakan untuk dataset ini ialah model KNN di mana KNN memiliki nilai error terkecil dan nilai akurasi yang tinggi ketimbang kedua model lainnya(cek pada bagian Evaluasi)
Berikut merupakan parameter-parameter yang digunakan pada potongan kode di atas: -
learning_rate: bobot yang diterapkan pada setiap regressor di masing-masing proses iterasi boosting.
-
random_state: digunakan untuk mengontrol random number generator yang digunakan.
Pada proyek ini, metrik evaluasi yang digunakan untuk mengukur kinerja model yaitu menggunakan metrik akurasi dan MSE. Akurasi di sini merupakan tingkat keakuratan data prediksi yang didasarkan dari data latih pada model, tingkat akurasi tertinggi ialah pada model KNN sebesar 89.16% dan ini menunjukkan bahwasannya KNN merupakan model terbaik dari kedua model lainnya dalam memprediksi nilai Bitcoin di masa mendatang. MSE sendiri merupakan Mean Squared Error yang menghitung jumlah selisih kuadrat rata-rata nilai sebenarnya dengan nilai prediksi. MSE didefinisikan dalam persamaan berikut:
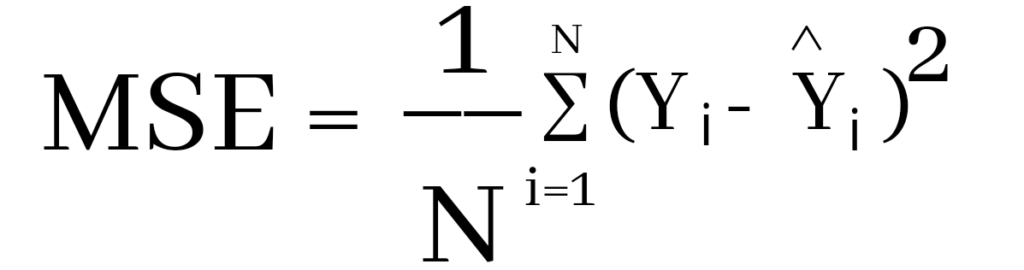
Keterangan:
- N = jumlah dataset
- yi = nilai sebenarnya
- yi^ = nilai prediksi
Sebelum menggunakan metrik MSE, harus dilakukan scaling fitur numerik terlebih dahulu pada data uji untuk menghindari kebocoran data. Setelah melakukan evaluasi berdasarkan metrik MSE dan tingkat akurasi prediksi pada model, penulis mencoba memprediksi harga untuk 30 hari ke depan dengan model KNN dan hasilnya cukup memuaskan karena nilainya tidak jauh berbeda dengan data sebelumnya.
Berikut ini perbandingan grafik metrik MSE pada ketiga model:

Selain akurasi untuk menentukan model terbaik dapat dilihat juga berdasarkan tingkat eror pada grafik di atas, semakin kecil tingkat eror maka semakin baik model tersebut memprediksi data. jika dilihat dari gambar di atas KNN lah model yang memiliki tingkat eror terendah dibandingkan dengan model lainnya.
berikut perbandingan nilai error MSE yaitu :
- KNN : 5.385045 (train), 7.326169(uji)
- RF : 1.02805(train), 49.738891(uji)
- BA : 6.116459(train), 115.669911(uji)
https://www.kaggle.com/datasets/sudalairajkumar/cryptocurrencypricehistory?select=coin_Ethereum.csv https://www.pajakku.com/read/627b5434a9ea8709cb189f93/Cryptocurrency:-Definisi-Karakterisik-Fungsi-dan-Legitimasinya-Dalam-Pajak https://katadata.co.id/safrezi/digital/61b170f652225/apa-itu-ethereum-memahami-sejarah-cara-kerja-dan-komponennya

{kind=link}