Recognizing the type of a traffic sign automatically is a difficult challenge, but can be applied to driver assistance systems or autonomously driving cars. However, real-world traffic signs exhibit strong variations due to illumination changes, partial occlusions and plenty of other distractions. In order to show the capabilities of Keras on an important multi-class classification problem, we build multiple distinct neural network models to solve the traffic sign recognition challenge based on the German Traffic Sign Recognition Benchmark (GTSRB) [12].
The dataset contains over 50,000 colored images (RGB) of traffic signs with sizes ranging from 15×15 to 222×193 pixels. Figure 5 shows sample images taken from the original dataset. Hence, the dataset also contains rectangular-shaped images and each traffic sign is surrounded by 10% margin. The traffic sign images were collected by capturing ten hours of video material while driving on German roads, and later labeled manually. Note that each physical traffic sign occurs only once in the dataset, however, 30 images of one traffic sign instance are contained due to the fact that during video capture the car was moving. If one traffic sign instance was contained more than 30 times, an equidistant sample of 30 images was created. Overall the dataset consists of 43 different traffic signs in six categories (speed limit, prohibitory, derestriction, mandatory, danger, unique signs) and is unbalanced among the classes. We assume that some categories containing highly similar signs are more difficult to classify correctly than others.
Since the images have a high variation in size and a model requires the same input shape for all instances, we first of all resized the images to 48×48 pixels. Afterwards, we cropped the borders to remove the purposely remaining margin in the image using the supplied ROI annotations. In order to improve the visual appearance in terms of contrast, we applied several standard normalization strategies such as histogram equalization (HEQ) and adaptive histogram equalization (aHEQ), according to Ciresan et al. [1]. Note that artificially including variations such as translation, rotation and scaling in the training images, the classifier adapts to higher robustness and overfitting is reduced [9]. These are general preprocessing steps, however, some models may require additional or slightly altered preprocessing.
Since different DL architectures are quickly set up in Keras , we implemented four ar- chitectures and conducted corresponding experiments to determine the best performing model and hyperparameters. In the following we briefly described the models used to tackle the classification challenge followed by a concise evaluation.
The first investigated model is a deep feed-forward neural network (FFNN) consisting of multiple hidden layers. Note that we use the HOG (histogram of oriented gradients) features which are precomputed and supplied by for GTSRB as the input instead of the images (1,568 features). To determine good performing number of hidden layers and layer sizes, we conducted many experiments for the given problem. As activation function, we use ReLU [8] activation layer. In order to reduce overfitting and co-adaption of neurons during training, we heavily use dropout layers [11, 3] as described earlier. Since the network should determine the most probable class for an input image, we use an output layer of size 43 with softmax activation [4] generating a probability distribution over the 43 classes.
A more natural architecture for processing and analyzing images are convolutional neural networks (CNN) [10, 13]. The original tensor with shape (48,48,3) can be directly fed into the network without the need for transformation. A common convolutional neural network consists of a sequence of convolution and pooling layers and finally fully-connected layers for classification. Particularly, we use a 2D con- volution layer with filter size (3,3) followed by a maximum pool layer with pooling size of (2,2). This is followed by an additional identical pair of convolutional and pooling layer. Finally, we flatten the output tensor and input it into two fully-connected hidden layers of size 100 and fed the results into an output layer of size 43 with softmax activation. The general CNN architecture is illustrated in Figure 6.
Since the organizers of the competition also provide different kinds of precomputed features to be used with other machine learning algorithms, we can additionally exploit these features and create an ensemble of FFNN and CNN. The features they provide are HOG (Histogram of Oriented Gradients) as mentioned previously, Hue Histograms (256-bin HSV) and Haar-like features. In general the applied CNN architecture is the same as described previously. In addition, we train a multi-layer FFNN using the provided features. To produce a final result, we average the individual results using the Average layer.
As a final model, we implemented an architecture called multi-scale convolutional networks (MSCNN) [9]. That is, instead of feeding only the output of the second pooling layer into the fully-connected layer, we also feed the pooled output of the first convolution layer into the classifier. Here, we need to use the Model, to create the DAG structure. This allows the classifier to exploit not only high-level features of the second stage but also low-level features from the first convolution stage. Figure 7 illustrates the MSCNN architecture.
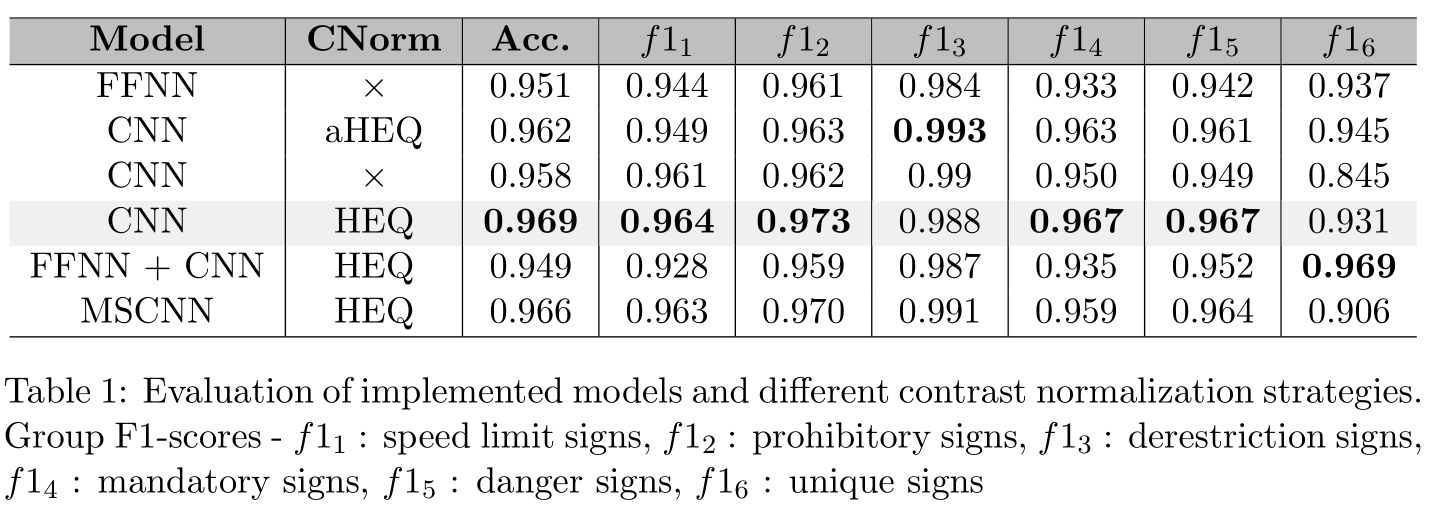
There is an official split between training (39,207 images) and test set (12,630 images) which is used to train and evaluate the models. Table 1 shows an evaluation summary of all four architectures (overall accuracy and F1-scores per traffic sign group) and addition- ally the CNN model results for different contrast normalization strategies. The CNN with HEQ outperforms all other models, however, the MSCNN with HEQ shows similar results. Note that HEQ performs best compared to aHEQ or missing contrast normalization. Par- ticular traffic sign groups such as the unique signs benefit especially by applying contrast normalization, as the f1 6 score increases by approximately 0.1. Hence, we conclude that unique traffic signs suffer considerably from significant illumination variation. However, derestriction signs are classified best with aHEQ. We assume that for these traffic signs there must be higher variation differences in the images. Since the FFNN and CNN clas- sify identical instances similarly, employing an ensemble of both architectures is not able of increasing the individual FFNN or CNN result. Overall the image specific architectures such as CNN and MSCNN tend to outperform FFNN using feature-based (e.g. HOG or Haar-like) representations of the images.