ssruoyan / blog Goto Github PK
View Code? Open in Web Editor NEW随笔
随笔


Redux 是一个前端状态容器,提供可预测的状态管理,由 Flux 演变衍生而来。
Redux 的一些核心概念和使用方法可以参考官方文档:https://redux.js.org/
OK,话不多说,直接开始。
阅读版本: 4.0.4
源码地址: https://github.com/reduxjs/redux
辅助工具: Webstorm、Xmind、Terminal
PS: Redux 源码使用 Typescript 编写,涉及到比较繁琐的类型扩展,泛型等,在解析代码中会适当省略掉,保持简洁。
Xmind 确实是一个好用的工具。
先阅读工具函数,因为这是在其他的核心函数模块中会用到的东西,而且工具函数的实现方式与其他模块没有任何强关联关系,可以独立阅读。
actionTypes 定义了一些 redux 内部使用的 action 类型,供 redux 内部使用。如未识别的 action、初始化状态、替换状态。
这些类型是不能用在日常开发过程中的
const randomString = () =>
Math.random()
.toString(36)
.substring(7)
.split('')
.join('.')
const ActionTypes = {
INIT: `@@redux/INIT${randomString()}`,
REPLACE: `@@redux/REPLACE${randomString()}`,
PROBE_UNKNOWN_ACTION: () => `@@redux/PROBE_UNKNOWN_ACTION${randomString()}`
}如上定义了 INIT、REPLACE、PROBE_UNKNOWN_ACTION 三种类型。通过使用
【
@@redux前缀】+【名字】+【随机数36 进制的前7位并使用.分割】
规则生成的内部使用的 action 类型,比如使用随机生成的 PROBE_UNKNOWN_ACTION 去断言测试传入的 reducer 是否正确处理未识别的 action。
判断数据是不是一个普通对象
function isPlainObject(obj: any): boolean {
if (typeof obj !== 'object' || obj === null) return false
let proto = obj
while (Object.getPrototypeOf(proto) !== null) {
proto = Object.getPrototypeOf(proto)
}
return Object.getPrototypeOf(obj) === proto
}这个函数使用了 Object.getPrototypeOf 这个 API。这个API 可以简单理解为获取对象 __proto__ 属性。做了以下两步操作:
因为对于 JavaScript 普通对象而言,它的原型链只有一层,就是 Object。可以理解为对于普通对象 obj 满足:obj.__proto__ === Object.prototype 且 Object.prototype.__proto__ === null
一个简单的发警告消息的方法
export default function warning(message: string): void {
if (typeof console !== 'undefined' && typeof console.error === 'function') {
console.error(message)
}
try {
throw new Error(message)
} catch (e) {}
}顾名思义这个函数就是用来创建 store 的一个函数模块。由于这个函数本身包含几个部分以及一些函数体内的闭包,因此我拆成多个部分单独解释。
参数由三个部分组成:
// 如果第二个参数是函数,表示这个参数是 enhancer
if (typeof preloadedState === 'function' && typeof enhancer === 'undefined') {
enhancer = preloadedState as StoreEnhancer<Ext, StateExt>
preloadedState = undefined
}
// 如果有 enhancer,则使用 enhancer 增强 createStore
if (typeof enhancer !== 'undefined') {
if (typeof enhancer !== 'function') {
throw new Error('Expected the enhancer to be a function.')
}
return enhancer(createStore)(reducer, preloadedState as PreloadedState<S>) as Store<ExtendState<S, StateExt>, A, StateExt, Ext> & Ext
}
if (typeof reducer !== 'function') {
throw new Error('Expected the reducer to be a function.')
}内部声明保存的数据
// 保存 state 和 reducer。state 经过处理会改变,reducer 不变
let currentReducer = reducer
let currentState = preloadedState as S
// 订阅消息用的监听
let currentListeners: (() => void)[] | null = []
let nextListeners = currentListeners
// 标记是否正在 dispatch 调用过程中(准确说应该是 reducer 计算过程)。在dispatch 函数中会对这个值进行处理。在内部很多地方会使用这个变量去判断当前的状态。
let isDispatching = false获取 state 的方法。
function getState(): S {
return currentState as S
}这个方法只是简单的返回当前的状态(当然还有判断 isDispatching 被我省略了)
function subscribe(listener: () => void) {
let isSubscribed = true
ensureCanMutateNextListeners()
nextListeners.push(listener)
return function unsubscribe() {
if (!isSubscribed) {
return
}
isSubscribed = false
ensureCanMutateNextListeners()
const index = nextListeners.indexOf(listener)
nextListeners.splice(index, 1)
currentListeners = null
}
}subscribe 函数的主要功能:
除此之外,使用了一个 ensureCanMutateNextListeners 方法来避免在 dispatch 过程中进行订阅/取消订阅调用的一些问题。
function ensureCanMutateNextListeners() {
if (nextListeners === currentListeners) {
nextListeners = currentListeners.slice()
}
}创建了一个 nextListeners 的浅层副本。相当于说,每次 dispatch 执行的 listener 都是之前保存的一份快照。在这个期间发生的订阅和这取消订阅不会影响执行。
dispatch 用来触发 action 更新 state。
function dispatch(action: A) {
try {
// 修改 dispatch 状态
isDispatching = true
// 使用 reducer 处理状态
currentState = currentReducer(currentState, action)
} finally {
isDispatching = false
}
// 执行订阅的监听器
const listeners = (currentListeners = nextListeners)
for (let i = 0; i < listeners.length; i++) {
const listener = listeners[i]
listener()
}
return action
}dispatch 做的事情非常简单,包括三件:
替换 reducer。PS: 源码中这一段书写的 Typescript 类型扩展太复杂了,直接简写了。
function replaceReducer(nextReducer: Reducer): Store {
// 替换 currentReducer
currentReducer = nextReducer
// 触发一次 REPLACE 的 action
dispatch({ type: ActionTypes.REPLACE } as A)
// 返回 store
return store
}触发的 REPLACE action 没有额外的操作,只是做了一次记录。在 combineReducer 中也只是开发环境下使用做了一次判断。
这是一个留给 observable/reactive 库的一个通信或者操作接口。一个参照标准的实现 tc39
function observable() {
const outerSubscribe = subscribe
return {
subscribe(observer: unknown) {
function observeState() {
const observerAsObserver = observer as Observer<S>
if (observerAsObserver.next) {
observerAsObserver.next(getState())
}
}
observeState()
const unsubscribe = outerSubscribe(observeState)
return { unsubscribe }
},
[$$observable]() {
return this
}
}
}需要一个实现了 next 方法的 observer 对象。
dispatch({ type: ActionTypes.INIT } as A)
const store = ({
dispatch: dispatch as Dispatch<A>,
subscribe,
getState,
replaceReducer,
[$$observable]: observable
} as unknown) as Store
return store在创建 store 的时候会触发一个 INIT 的 action,然后返回创建的 store 对象。
compose 是一个比较通用的工具函数,用来组合从右到左的一系列单参数函数(最右边的函数可以使多参数)。最终返回一个函数。比如: compose(f, g, h) => (...args) => f(g(h(...args)))
function compose(...funcs: Function[]) {
if (funcs.length === 0) {
return <T>(arg: T) => arg
}
if (funcs.length === 1) {
return funcs[0]
}
return funcs.reduce((a, b) => (...args: any) => a(b(...args)))
}使用 reduce 遍历,并将上一次的处理结果返回作为下一次的输入,每次执行返回结果都是一个函数。
在讲 createStore 这个模块的时候提到了这个函数的第三个参数 enhancer 用来增强 createStore。
现在要分析的 applyMiddleware 的作用就是创建一个 enhancer 将一系列中间件应用到 redux store 的 dispatch 方法上。
function applyMiddleware(...middlewares: Middleware[]): StoreEnhancer<any> {
return (createStore: StoreCreator) => (reducer: Reducer, ...args: any[]) => {
const store = createStore(reducer, ...args)
// 声明一个空的未处理的dispatch
let dispatch: Dispatch = () => {
// 直接调用会报错
throw new Error(....)
}
// 每个 middleware 函数的参数。
// 这里比较有意思的是 dispatch 这个参数是在 compose(...chain) 这一步完成之后才有实际值。也就是说dispatch 在 middleare 这个外层函数的执行中是无意义的,仅作为参数传递。
const middlewareAPI: MiddlewareAPI = {
getState: store.getState,
dispatch: (action, ...args) => dispatch(action, ...args)
}
// 依次执行每个 middleware 并存储结果到 chain
const chain = middlewares.map((middleware) => middleware(middlewareAPI))
// middleware 的执行结果是一个单参数函数。参数就是 dispatch,并返回新的 dispatch 方法。
// 使用 compose 调用 dispatch chain 去增强 dispatch 方法。
const dispatch = compose(...chain)(store.dispatch)
}
// 返回新的 store,仅覆盖 dispatch 方法
return {
...store,
dispatch,
}
}简单来说 applyMiddleware 就是一个生成器,最终对 dispatch 进行处理增强或者说覆盖原有的 store.dispatch 功能,然后返回新的 store,可以分为一下几个步骤解释:
因此我们在写 middleware 的时候会是一个多层嵌套的函数结构:
const testMiddleware = ({ getState, dispatch }) => (next) => (action) => {
if (action.type === 'LOG') {
console.log('记录一条日志')
}
next(action)
}把匿名箭头函数换成一种具名函数的写法,比较容易看懂:
function testMiddleware({ getState, dispatch }) {
// 返回一个 dispatch 创建函数
return function dispatchCreator(oldDispatch) {
// 返回新的 dispatch 函数
return function newDispatch(action) {
if (action.type === 'LOG') {
console.log('记录一条日志')
}
oldDispatch(action)
}
}
}combineReducers 是一个辅助工具函数,通过对象字面量的方式接收多个 reducer 组合成一个新的 reducer 函数。
function combineReducers(reducers: ReducersMapObject) {
// 第一步先筛选出正确的 reducers 和 reducerKeys
const reducerKeys = Object.keys(reducers)
const finalReducers: ReducersMapObject = {}
for (let i = 0; i < reducerKeys.length; i++) {
const key = reducerKeys[i]
if (typeof reducers[key] === 'function') {
finalReducers[key] = reducers[key]
}
}
const finalReducerKeys = Object.keys(finalReducers)
// 断言测试你的 reducer 是否正确
let shapeAssertionError: Error
try {
assertReducerShape(finalReducers)
} catch (e) {
shapeAssertionError = e
}
return function combination(
state: StateFromReducersMapObject,
action: AnyAction
) {
if (shapeAssertionError) {
throw shapeAssertionError
}
let hasChanged = false
const nextState: StateFromReducersMapObject = {}
// 遍历所有的 reducer
// 通过 key 使用 reducer 处理对应的 state
for (let i = 0; i < finalReducerKeys.length; i++) {
const key = finalReducerKeys[i]
const reducer = finalReducers[key]
const previousStateForKey = state[key]
const nextStateForKey = reducer(previousStateForKey, action)
nextState[key] = nextStateForKey
// 遍历中执行多次,只要一次修改,则 hasChanged 最终结果为 true
hasChanged = hasChanged || nextStateForKey !== previousStateForKey
}
// 最后判断 reducer 中的 key 不一致是否和 state 中的 key 一致,不一致也表示已修改,使用 newState
hasChanged =
hasChanged || finalReducerKeys.length !== Object.keys(state).length
return hasChanged ? nextState : state
}
}测试你的 reducer 是否正确的断言方法
function assertReducerShape(reducers: ReducersMapObject) {
Object.keys(reducers).forEach(key => {
const reducer = reducers[key]
const initialState = reducer(
undefined,
{ type: ActionTypes.INIT }
)
// 报错。传入 undefined 应该返回一个不是 undefined 的 initialState
if (typeof initialState === 'undefined') {
throw new Error('...')
}
// 报错。警告你不要用私有的 @@redux/ 命名空间 actionType。你应该为任何未知的 actionType 返回 initialState
// PS: 其实就是你在写 reducer 的 switch case 的时候 default 返回 initialState
if (
typeof reducer(
undefined,
{
type: ActionTypes.PROBE_UNKNOWN_ACTION()
}
) === 'undefined'
) {
throw new Error('...')
}
}combineReducers 解析完成。其实简单也可以很简单的理解:
bindActionCreator 也是一个辅助函数,就是一个值是 action creator 的对象和 dispatch 绑定到一起组合成一个值是可以直接调用触发 dispatch action 的对象。
// 绑定单个函数
function bindActionCreator<A extends AnyAction = AnyAction>(
actionCreator: ActionCreator<A>,
dispatch: Dispatch
) {
// 返回一个直接调用的函数,
return function(this: any, ...args: any[]) {
return dispatch(actionCreator.apply(this, args))
}
}
// 绑定多个函数组合的 Object
function bindActionCreators(
actionCreators: ActionCreator<any> | ActionCreatorsMapObject,
dispatch: Dispatch
) {
if (typeof actionCreators === 'function') {
return bindActionCreator(actionCreators, dispatch)
}
const boundActionCreators: ActionCreatorsMapObject = {}
// 遍历这个 actionCreators 对象依次调用
for (const key in actionCreators) {
const actionCreator = actionCreators[key]
if (typeof actionCreator === 'function') {
boundActionCreators[key] = bindActionCreator(actionCreator, dispatch)
}
}
return boundActionCreators
}这个函数的实现比较简单。其原理就是实现一个新的函数把 actionCreator 的执行结果传入 dispatch 执行。
自此,redux 源码解析结束。
消耗: 2杯咖啡、一天工时 + 一个没睡够的晚上。
接下来会继续解读一下 react-redux 的源码。
JavaScript 有7中基本数据类型,而其中数字类型 Number 作为其中一种类型除了 BigInt 这类特殊对象外,Number 是 JavaScript 中唯一表示数字的方法。参考 TC39 规范
在 JavaScript 语言层面上不区分整数、浮点数、有符号和无符号的区别。所有有的数字类型都是 Number,统一应用 64 位浮点数表示和运算。很多时候我们会遇到一些莫名其妙的数字表达。比如:
// 数字精度问题
0.1 + 0.9 === 0.30000000000000004
// 数字边界问题
23333333333333333 + 1 === 23333333333333332这些问题是大多数 JavaScript 开发者都知道这个问题存在并知道一些常用的解决方法,但并不清楚造成这些问题背后的原理。这篇文章会帮助解释清楚 JavaScript 大数字危机以及四则运算中的坑。
与大多数其他语言不同,JavaScript 的数字包括无论小数和整数,表示形式只有 Number 一种。它的实现类似于 C++ 的 double 双精度浮点数类型,遵循 IEEE 754 标准,使用 64 为固定长度表示。它可以表示 53 位有效数字,其表示的数字的绝对值理论范围2^-1024 ~ 2^1024。64 位比特可分为三个部分:
sign bit(符号):用来表示正负号。0 表示正数,1 表示负数
exponent(指数):用来表示次方数。使用补码 表示,则 11 位无符号补码表示。表示整数范围为[-1024, 1023],小数范围为 (-1, 1 - 2^-10)。同时存在四种特殊情况:
fraction(分数):用来表示精确度。如:11.101 * 2^1011 可以格式化为 1.1101 * 2^1010 则此时尾数表示为 fraction = 1101。在规格化形式下整数部分默认为1;非规格化形式下整数部分默认变成为 0。

因此,一个完整的二级制双精度浮点数所代表的数字表示为:
示例(数字 11):
// 11 二进制表示
sign = 0
exponent = 100000000010
fraction = 0110000000000000000000000000000000000000000000000000指数偏移值(exponent),即浮点数表示法中
指数域的编码值 = 指数的实际值 + 固定偏移值
IEEE 754 标准规定该固定值为:
其中 e 表示存储指数的比特长度。64位存储单元中 e = 11。偏移值为 1023。
如果不对浮点数的表示做出明确的规定,则同一个浮点数的表示就不是唯一的。例如:1.11 * 2^10 可以表示为 11.1 * 2^9 。为了提高数据的表示精度,如果浮点数中指数部分的编码值在 0 < exponent <= 2^e - 2 之间,且在科学表示法的表示方式下,分数 (fraction) 部分最高有效位(即整数字)是 1,那么这个浮点数将被称为规格化形式的浮点数。即指用唯一确定的浮点形式表示一个值。
如果浮点数的指数部分的编码值是0,分数部分非零,那么这个浮点数将被称为非规约形式的浮点数。一般情况下某个数字无限接近与 0 才会使用非规格化形式表示。假如全部用十进制表示,数字 0.00111 的浮点数可以表示为 1.11 * e^3 ,但是对于一些过于小的浮点数,比如 1.11e^-54,允许的阶位数(52)完全不能满足阶数的大小,这时可能在尾数前添加前导0,比如 0.0111e^52 。
有三个特殊值需要指出:
0、NAN、Infinity
| 形式 | 指数部分 | 小数部分 |
|---|---|---|
| 零 | 0 | 0 |
| 非规格化形式 | 0 | 大于 0 小于 1 |
| 规格化形式 | 1 - 2^e - 1 | 大约等于 1 小于 2 |
| 无穷 | 2^e - 1 | 0 |
| NaN | 2^e - 1 | 非 0 |
除了特殊数字(如:Infinity)和定理常数(如: Math.E)JavaScript 中存在很多常数也是基于 IEEE754 浮点数模型得出来的。比如:
MAX_VALUE、MIN_VALUE、EPSILON、MAX_SAFE_INTEGER、MIN_SAFE_INTEGER
除去特殊值外,其余数字都属于规格化浮点数的范畴,因此常数的指数部分范围为 1 <= e <= 2046。
// 11 二进制表示
11 = (-1)^{0} * 2^{1026 - 1023} * 1.375
sign = 0
exponent = 100000000010 = 1026
fraction = 0110000000000000000000000000000000000000000000000000MAX_VALUE:
指数部分的最大值为 2046 因此:
MIN_VALUE:
JS 中最小值表示最小正数
EPSILON:
表示大于 1 的最小浮点数与 1 的差值:
MAX_SAFE_INTEGER:
最大安全整数。可以准确连续的表示的整数称之为安全整数。即所有指数部分刚号把所有分数移除到小数点左侧。
因此最大安全整数是 l = 52 时,e = 1075:
同样的最小安全整数即为最大安全证书的负值
超出安全整数的数字能会存在不稳定的表示方式。比如:
// 2^53 二进制
sign=0
exponent=10000110100
fraction=0000000000000000000000000000000000000000000000000000
// 2^53 + 1 二级制
sign=0
exponent=10000110100
fraction=0000000000000000000000000000000000000000000000000000两者的表示方式一样。则
2^53 === 2^53 + 1同样的规则适用 N 位运算。比如 32 位浮点数:
// 可以根据64位的规则自行验证
2^24 === 2^24 + 1整数位超过 MAX_SAFE_INTEGER 会失去精度,选择一个就近的可以精确表示的值。如果存在两个相近的值,IEEE 754[https://en.wikipedia.org/wiki/IEEE_754] 提供了两种方式:Round to nearest, ties to even 和 Round to nearest, ties away from zero 。JavaScript 采用的是第一种。
console.log(Number.MAX_SAFE_INTEGER)
// 输出 9007199254740991
// sign=0
// exponent=1023+52
// fraction=(52 个 1)
console.log(Number.MAX_SAFE_INTEGER+1)
// 输出 9007199254740992 (这是一个精确值)
// sign=0
// exponent=1023+53
// fraction=(52 个 0)
console.log(Number.MAX_SAFE_INTEGER+2)
// 输出 9007199254740992
// sign=0
// exponent=1023+53
// fraction=(52 个 0)这样就可以得出结论:
Number.MAX_SAFE_INTEGER+2 === Number.MAX_SAFE_INTEGER+1为什么呢?对于 Number.MAX_SAFE_INTEGER+2 这个数来说,如果不存在 52 位小数位的限制。可以表示为:
Number.MAX_SAFE_INTEGER
9007199254740993
// sign=0
// exponent=1023+53
// fraction=10000.....0000(第53位)1由于只能表示 52 位小数位,最后一位 1 无法表示。这时可以选择近似数有两个:1000...01 和 1000...00 根据 Ties to even 规则选择后者则会让小数部分变成偶数。即得到与 Number.MAX_SAFE_INTEGER+1 同样额值。
52 位小数无法完全表示所有浮点数的精度,当无法精确表示时往往会取近似值。
0.1+0.2 === 0.30000000000000004计算机里面的计算最终都会转换成二进制的计算方式:
// 0.1 的二进制形式
0.1 => 2^-3 * 1.1001100110011001100110011001100110011001100110011010
// 0.2 的二进制形式
0.2 => 2^-4 * 1001100110011001100110011001100110011001100110011010
// 小数部分
1001100110011001100110011001100110011001100110011010 = 1.6
// 根据公式计算
(2^-4 + 2^-3) * 1.6 = 1.875 * 1.6 = 0.30000000000000004可以看出来计算的最终结果与实际想象的完全不一样。可以看出来二进制中 0.1 的表示是一个无穷循环,但是为什么 x = 0.1 就成立呢?实际上也不成立。JS 对 0.1 的十进制表示进行了精度处理。
JavaScript 最多能表示的精度长度为 16 位,超过 16 位精度会自动处理。
(0.1).toPrecision(19) = '0.1000000000000000056'
(0.1).toPrecision(18) = '0.100000000000000006'
(0.1).toPrecision(17) = '0.10000000000000001'1)对于数据展示的情况,建议进行精度格式化后再展示,如
(1.4000000000000001).toPrecision(12) === 1.412 的精度可以覆盖大部分使用场景。
2)对于基础运算。正确的做法是先转换小数为整数,然后再运算。如:
function add(num1, num2) {
const p1 = (num1.toString().split('.')[1] || '').length
const p2 = (num2.toString().split('.')[1] || '').length
const num = Math.pow(10, Math.max(p1, p2))
return (num1 * num + num2 * num) / num
}当然可以选择开源的第三方库进行运算。如:Numeral、mathjs 等。
https://en.wikipedia.org/wiki/Rounding#Round_half_to_even
https://zh.wikipedia.org/wiki/双精度浮点数
https://en.wikipedia.org/wiki/IEEE_754
程序 = 数据结构 + 算法
算法和数据结构的学习是所有计算机科学教学计划的基础,也是作为计算及相关专业的学生必修的一门课程。良好的算法和数据结构基础能帮助我们更好的写出优雅的程序,也能加强我们的编程**,提升工作效率。
在接下来的一段时间里,我会重温算法相关的基础知识,整理算法笔记,记录这个新的学习过程。
算法笔记的第一章,先了解一些常见的数据结构。数据结构本就是用来辅助算法实现,便于算法组织和操作数据的一种方式。
数组是有限个相同类型元素的集合。
数组中的元素存储在一个连续性的内存块中,并通过索引来访问(这一点也和结构和类中的字段不同,它们通过名称来访问)。
堆栈是一种只能在一端进行插入和删除操作的特殊线性表。遵从先进后出 (LIFO) 原则的集合。
新添加的或待删除的元素都保存在栈的末尾,称作栈顶,另一端为栈底。在栈里,新元素都靠近栈顶,旧元素都接近栈底。
在计算机中比较常见的栈应用,比如 js 的函数调用栈
每次函数调用,函数地址,参数,临时变量都会被压入栈中,调用完成后被弹出。
Javascript 模拟实现栈结构
class Stack {
private items = []
constructor(items) {
items && this.items = items
}
// 入栈
push(element) {
this.items.push(element)
}
// 出栈
pop() {
return this.items.pop()
}
// 尺寸
get size() {
return this.items.length
}
// 清空栈
clear() {
this.items = []
}
}
const stack = new Stack()
stack.push(1)
console.log(stack.size) // 1队列也是一种特殊的线性表,其特性与栈相反,一种遵循先进先出 (FIFO / First In First Out) 原则的一组有序的项;队列在尾部添加新元素,并从头部移除元素。最新添加的元素必须排在队列的末尾。
队列的 JavaScript 模拟实现:
class Queue {
private items = []
constructor(items) {
items && this.items = items
}
// 入队列
enqueue(element){
this.items.push(element)
}
// 出队列
dequeue(){
return this.items.shift()
}
// 清空队列
clear(){
this.items = []
}
// 尺寸
get size(){
return this.items.length
}
}队列在实际应用中类似于排队规则,比如 JavaScript异步任务队列。
队列的“假溢出”现象:
队列可以用数组存储,每次在队尾插入元素则 rear 指针 +1,在队头删除元素则 front 指针 +1,当 rear 指针指向连续空间之外时,队列无法再插入新的元素。但是由于队列头部删除元素导致大量空间未被占用,产生“假溢出”现象。
克服“假溢出”现象有几种办法,第一种所有队列元素向低地址;第二种动态扩容;第三种循环队列。
所有元素向尾部挪即动态的修改所以元素的位置,增加时间成本;动态扩容即增加队列空间,增加空间成本;
循环队列,即将数组的存储区看成是一个首尾相连的区域。当存放地址超出分配的空间,就让他指向连续空间的起始位置,形成一个循环的空间。
Javascript 实现:
class LoopQueue {
private items = []
private tail = 0
private head = 0
private length
constructor(length) {
this.length = length
this.items = new Array(length)
}
// 获取实际位置
private getIndex() {
return (this.head + 1) % this.length
}
// 入队列
enqueue(item) {
const newHead = this.head + 1
const index = this.getIndex(newHead)
if (this.items[index]) {
throw "Full"
}
this.items[index] = item
this.head = newHead
}
// 出队列
dequeue() {
this.items.splice(this.tail, 1)
this.tail = this.tail + 1
// 重置队列指针
if (this.head > this.tail > this.length) {
this.head = this.head % this.length
this.tail = this.tail % this.length
}
}
// 查询值
findIndex(index) {
return this.items[this.getIndex(index)]
}
isEmpty() {
return this.tail === this.head
}
}存储有序的元素集合,但不同于数组,链表中的元素在内存中并不是连续放置的;每个元素由一个存储元素本身的节点和一个指向下一个元素的引用(指针/链接)组成。
相较于传统的数组存值,链表在添加或移除元素的时候不需要移动其他元素。但是链表增加了链式结构,内存空间占用变大,同时由于灵活的管理状态,使得链表的读取变得复杂。
链表存储的信息包含一般分为数据域和指针域
// 链表节点
class Node {
constructor(element) {
this.element = element
this.next = null
}
}
// 链表
class LinkedList {
constructor() {
this.head = null
this.length = 0
}
// 追加元素
append(element) {
const node = new Node(element)
let current = null
if (this.head === null) {
this.head = node
} else {
current = this.head
while(current.next) {
current = current.next
}
current.next = node
}
this.length++
}
// 任意位置插入元素
insert(position, element) {
if (position >= 0 && position <= this.length) {
const node = new Node(element)
let current = this.head
let previous = null
let index = 0
if (position === 0) {
this.head = node
} else {
while (index++ < position) {
previous = current
current = current.next
}
node.next = current
previous.next = node
}
this.length++
return true
}
return false
}
// 移除指定位置元素
removeAt(position) {
// 检查越界值
if (position > -1 && position < length) {
let current = this.head
let previous = null
let index = 0
if (position === 0) {
this.head = current.next
} else {
while (index++ < position) {
previous = current
current = current.next
}
previous.next = current.next
}
this.length--
return current.element
}
return null
}
// 删除指定文档
remove(element) {
const index = this.indexOf(element)
return this.removeAt(index)
}
size() {
return this.length
}
}由一个或者多个不重复的确定元素组成的一个整体。集合内的元素是确定、互斥并且无序的。
U=R
A{x| 1 < x < 15}集合内的元素不能相同
const st = new Set()
const st1 = new Set([1, 2, 3, 3, 4])
st.add(12)
st.add(12)
st.size // 1
st1.size // 4集合没有元素下标,只能获取值
const st = new Set([1, 2, 3, 3, 4])
st.get(0) // undefined
st.get(1) // 树是一种抽象的数据结构,由有限个节点组成一个具有层次关系的集合。
树结构具有一下几个特点:
1)每个节点都有有限个子节点或者没有
2)只有根节点无父节点
3)每一个非根节点有且只有一个父节点
4)除了根节点外,没个子节点可以划分为多个不相交的子树
5)无闭环
用数据结构表示:
const tree = {
name: 'A',
children: [
{
name: 'B',
children: [
{
name: 'D',
children: [
{
name: 'J'
},
{
name: 'K'
}
]
},
{
name: 'E'
},
{
name: 'F',
children: [
{
name: 'L'
}
]
},
]
},
{
name: 'C',
children: [
{
name: 'G',
children: [
{
name: 'M'
}
]
},
{
name: 'H',
children: [
{
name: 'N'
},
{
name: 'O'
}
]
},
{
name: 'I'
}
]
}
]
}
对这颗树进行广度遍历,得到 ABCDEFGHIJKLMNO
function BFS(tree) {
const list = [tree]
while(list.length > 0) {
const p = list.shift()
console.log(p.name)
list.push(...(p.children || []))
}
}树有很多种类,包括红黑树,完全二叉树,满二叉树,霍夫曼树等等,同样对应的都会有不同的算法运用场景。
图通常用来表示和存储具有“多对多”关系的数据,是数据结构中比较复杂也非常重要的一种结构。现实生活中很多东西都可以用图数据结构来表示,社交网络,交通线路,互联网等等。
class Graph {
constructor() {
this.points = []
this.edges = {}
}
addPoint(p) {
this.points.push(p)
this.edges[p] = []
}
addEdge(p1, p2) {
this.edges[p1].push(p2)
this.edges[p2].push(p1)
}
}
散列表也可以称之为 Hash 表,是根据键(Key)而直接访问在内存储存位置的数据结构。即通过计算一个关于键值的函数,件查询的数据映射到表中的一个位置。
对于前端开发而言接触最多的散列表结构就是,JavaScript 中的对象。
简单实现 HashTable
function hash(str: string) {
var hash = 5381,
i = str.length;
while (i) {
hash = (hash * 33) ^ str.charCodeAt(--i);
}
return hash >>> 0;
}
class HashTable {
static hash(key: string) {
return hash(key);
}
private list: any[];
constructor() {
this.list = [];
}
put(key: string, value: any) {
const position = HashTable.hash(key);
this.list[position] = value;
}
get(key: string) {
return this.list[HashTable.hash(key)];
}
remove(key: string) {
this.list[HashTable.hash(key)] = undefined;
}
print() {
console.log(this.list);
}
}
const table = new HashTable();
table.put("name", "bob");这是一个简单实现的散列表。在散列表上插入、删除和取用数据非常快,但是查找数据却效率低下。
js散列表基于数组设计,理想情况散列函数会将每一个键值映射为唯一的数组索引,数组长度有限制,更现实的策略是将键均匀分布数组长度是预先设定的,可以随时增加,所有元素根据和该元素对应的键,保存数组特定的位置即使使用高效的散列函数,依然存在两个键值相同的情况,这种现象称为碰撞(collision)。
碰撞可以通过两种方法解决:
开链法: 两个键相同保存位置一样,开辟第二数组,也称第二个数组为链,适合空间小,数据量大
线性探测法属于开放寻址散列,查找散列位置如果当前位置没有继续寻找下一个位置。存储数据较大较适合。数组大小>=1.5数据(开链法),数组大小>=2数据(线性探测法)。
至此基本上介绍了一些常见的数据结构,后续会详细介绍这些数据结构的原理,应用场景,优缺点以及一些衍生数据结构。
https://www.cnblogs.com/zaking/p/8950607.html
https://segmentfault.com/a/1190000013132249
https://segmentfault.com/a/1190000010794621
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/Set
同一个问题往往可以用多种不同的算法解决,而一个算法的优劣将影响到算法以及程序的效率。一般来说从执行算法占用的内存空间和消耗的时间两个维度来度量一个算法的优劣程度,即时间复杂度和空间复杂度。
时间复杂度描述计算机算法的运行时间。一般来说对于一个算法,从理论上来说无法测出他的与运行时间,需要在对应真实的环境下执行计算。但是对于某一个同样的操作,比如调换两个数据的位置,重复多次执行需要耗费的时间也是同样的。因此,计算重复执行的次数即可表示
时间复杂度是一个函数,定性描述该算法的运行时间。一般用大 O 表示,不包括首项系数和低阶项。比如
n^3 + n^2 + n + 1
表示一个复杂度为 O(n^3)
如果某个基本重复的操作(比如元素交换)的次数是问题规模 n 的某个函数 T(n),同时存在某个特定的辅助函数 f(n) (一般为n^3、n^2、logN、n)。当 n 趋近于无穷大时存在:
T(n) = O(f(n))
则时间复杂度为 O(f(n))
计算方式:
1)找出算法的基本操作。如冒泡排序的比较交换位置
2)根据问题规模 n 的增长计算基本操作的次数增长
3)找到与同等数量级的辅助函数。如:
n^3 + n^2 + n 同等数量级的辅助函数为 n^3
例子
冒泡排序
func bubbleSort(data) {
len := len(data)
for (i := 0; i < len; i++) {
isChanged := false
for (j := 0; j < len - 1 - i; j++) {
// 基本交换操作
if (data[j] > data[j + 1]) {
temp := data[j]
data[j] = data[j + 1]
data[j + 1] = temp
isChanged = true
}
}
if (!isChanged) {
break
}
}
}在最坏的情况下,基本交换操作次数 n(n - 1)
空间复杂度描述计算机算法所占用的内存空间。一般包含三种
算法本身占用的存储空间。即算法的长度
输入输出占用的存储空间。如传入的数组长度
运行过程中临时占用的空间。如内部交换声明的变量
空间复杂度的度量方式和时间复杂度类似,也是问题规模 n 的函数。
对于一个算法而言,其时间复杂度和空间复杂度往往是相互影响的。同样算法的所有性能之间都存在着或多或少的相互影响,在设计算法的尤其是大型算法时应该兼顾算法的各项性能,使用频率,实际数据场景和量级,语言特性以及机器系统环境等。
原文地址:https://developers.google.com/web/fundamentals/media/eme
EME(Encrypted Media Extensions)加密媒体扩展提供了 web 应用程序和内容保护机制交互的API,允许 web 应用播放加密的音频和视频。
EME 的设计允许同样的 APP 和https://github.com/ssruoyan/blog/issues 加密文件能应用到任何的浏览器,并且可以无视浏览器的底层保护系统。前者是通过标准化的 API 实现的,后者则是通过 通用加密的概念实现。
EME 是 HTMLMediaElement 规范的一种扩展,它的名字也由此而来。作为一个扩展意味着浏览器对于 EME 的支持是可选的。如果浏览器不支持加密媒体,那么它就不能播放这个媒体资源。但是 EME 规范对于 HTML 规范而言并不是必须的。EME规范:
该方案扩展了 HTMLMediaElement 提供了控制受保护内容的 API
EME API 支持从简单的 Clear Key 解密到高价值视频(给定一个符合规范的用户代理实现)的用例。证书和密钥通过应用程序控制交换,促进强大的播放程序开发支持更多的内容加密和保护技术。
EME 规范没有实现一个内容保护或者数字版权管理(DRM)系统。相反的,它实现了一套可用与发现,选择以及和这些系统以及更简单的内容加密系统交互的通用API。实现数字版权管理并不符合EME规范的要求,只有 Clear Key 系统是必须要实现的公共基础。
通用 API 支持一套简单的内容加密功能,将一些应用程序的功能比如认证和授权保留给页面的使用者。这是通过要求内容保护系统特定的消息传递通过页面传达而不是通过假设加密系统和许可证或者其他服务器之间带外通信实现的。
EME 实现使用了以下外部的组件:
Key System: 一种内容保护机制。除了Clear Key 之外,EME 自身没有定义密钥系统。
Content Decryption Module (CDM):内容解密模块。客户端开启加密媒体播放的软件或者硬件机制。和 Key System 一样,EME 也没有定义任何内容解密模块,但是提供了和可用的内容解密模块交互的接口。
Lisence/Key server 和客户端内容解密模块交互,提供解密媒体的密钥信息。和证书服务器通信是客户端应用的责任。
Packaging server 编码和加密多媒体用来分发和消费资源
注意:应用程序使用 EME 和证书服务器进行交互获取密钥用来解密,但是用户身份信息和认证不属于 EME 的一部分,一般而言,检索密钥并开启多媒体播放应该发生在用户认证之后。Netfix等服务在他们的 Web 应用程序中必须认证用户信息:用户登录应用时,应用程序会判断当前用户的身份信息和用户权限。
这里有 EME 组件交互的原理。相应的代码示例如下:
如果各种格式和编解码器都可用,
MediaSource.isSupportType()和HTMLMediaElement.canPlayType()都能被用来选择正确的播放播放格式和编解码器。然而,内容解密模块可能仅仅支持浏览器所支持的加密内容的一部分,因此在选择格式和编解码器之前先约定多媒体密钥(MediaKeys)配置信息。如果应用等待加密事件的回调但是 MediaKey 此时不能处理被选中的格式和编解码器,那就只能中断播放,切换格式和编解码器。
推荐的流程是先协商 MediaKey,然后使用
MediaKeysSystemAccess.getConfiguration()获取协商的配置信息。
如果只存在一种格式可选择,那就不需要调用
getConfiguration()获取配置。然而最好还是先配置 MediaKey,等待加密事件的唯一理由是,如果无法知道内容是否加密。但是实际应用中这是不太可能的。
navigator.requestMediaKeySystemAccess()选择一个可用的密钥系统,检测哪一个密钥系统是可用的。然后通过MediaKeySystemAccess 为这个可用的密钥系统创建一个 MediaKeys 对象。注意 MediaKeys 对象的初始化应改在第一次加密事件之前。获取许可证服务地址应该是应用程序独立完成的,和选择可用的密钥系统无关。一个 MediaKeys 对象代表所有可用来为 audio 和 video 元素解密媒体数据的密钥。它表示一个 CDM(内容解密模块)的实例并且提供了对内容解密模块访问能力,尤其是创建密钥会话的能力。通常被用来从证书服务器获取密钥。2)一旦MediaKeys 对象创建成功,就将它分配给对应的媒体元素:setMediaKeys() 将 HTMLMediaElement 和 MediaKeys 关联起来。这样它的密钥信息就能在多媒体播放的时候(即解码的时候)被使用。createSession 创建了一个 MediaKeySession 对象,这个创建的 MediaKeySession 代表证书和密钥的生命周期。update() 方法向 CDM 中传递数据。多媒体播放简介
浏览器如何知道媒体数据是否加密
这些信息在媒体容器文件的元数据中,它的格式为ISO BMFF 或者 WebM等。对于 ISO BMFF 格式代表顶部元数据,称之为保护协议信息盒。WebM 使用 Matroska 内容加密元素,加上一些 WebM 特定的附加信息。EME 中特定的注册表为每个容器提供指南。
注意在CDM 和 证书服务器之间可能会有多条消息。在这个过程中所有通信对于浏览器和应用程序都是不透明的。所有的消息都只能被 CDM 和 Lisence 服务器识别,即使应用层可以看 CDM 发送的消息类型。许可证请求包含 CDM 合法性(和信任关系)的凭证,以及在生成许可证中加密内容密钥时使用的密钥。
一个 EME 的实现并不是在它自身提供了一种解密媒体数据的方式。它只是简单的一个 web 程序和CDM(内容解密模块)交互的 API。
CDMs 所做的并不是定义了一个 EME 规范,一个 CDM 可以处理媒体信息解码和解密。CDM 的功能支持程度从弱到强有以下几种选择:
有以下几种方式可以将CDM应用于程序中:
EME 规范没有定义如何提供CDM,在所有情况下都应该由浏览器检查和导出CDM。
EME 规范没有强行规定特定的密钥系统(KeySystem),目前的桌面浏览器和手机浏览器中,Chrome 和 IE11 分别支持 Widevine和PlayReady 密钥系统。
在典型的商用场景中,内容会被打包服务或者工具加密和编码。一旦加密媒体可用与线上服务,web 客户端能够从许可证服务器获取密钥并且使用这个密钥启用内容解码和播放。
以下的示例代码(改变自规范案例)展示了程序如何选择合适的密钥系统以及如何从许可证服务获取密钥。
var video = document.querySelector('video');
var config = [{initDataTypes: ['webm'],
videoCapabilities: [{contentType: 'video/webm; codecs="vp09.00.10.08"'}]}];
if (!video.mediaKeys) {
navigator.requestMediaKeySystemAccess('org.w3.clearkey',
config).then(
function(keySystemAccess) {
var promise = keySystemAccess.createMediaKeys();
promise.catch(
console.error.bind(console, 'Unable to create MediaKeys')
);
promise.then(
function(createdMediaKeys) {
return video.setMediaKeys(createdMediaKeys);
}
).catch(
console.error.bind(console, 'Unable to set MediaKeys')
);
promise.then(
function(createdMediaKeys) {
var initData = new Uint8Array([...]);
var keySession = createdMediaKeys.createSession();
keySession.addEventListener('message', handleMessage,
false);
return keySession.generateRequest('webm', initData);
}
).catch(
console.error.bind(console,
'Unable to create or initialize key session')
);
}
);
}
function handleMessage(event) {
var keySession = event.target;
var license = new Uint8Array([...]);
keySession.update(license).catch(
console.error.bind(console, 'update() failed')
);
}
通用加密解决方案允许内容提供商对每个资源容器/编解码器尽进行一次加密或者打包,并将他们与各种密钥系统,CDM和客户端联合使用:即任何支持公共加密的CDM。例如,一个使用 Playready 打包的视频可以使用 Widevine 内容解码模块从 Widevine 许可证服务器获取密钥在浏览器播放。
这与仅仅只能工作在一个完整垂直栈中的传统解决方案形成对比。传统的解决方案还包含单个客户端,客户端通常还包含一个应用程序运行时。
通用加密是一个 ISO 标准定义的 ISO BMFF 的保护方案。类似于 WebM。
虽然 EME 没有定义 DRM 功能,但是规范要求所有支持 EME 的浏览器必须实现 Clear Key。使用这个系统,可以用一个密钥对媒体资源加密,然后可以通过提供这个加密密钥播放媒体资源。Clear Key 系统可以内置到浏览器中:不需要使用单独的解密模块。
虽然不太可能被用于许多类型的商业内容,Clear Key 完全可以与所有支持 EME 的浏览器交互。它也便于测试 EME 的实现和使用 EME 的应用程序,而且不需要从许可证服务器请求内容密钥。这里有一个简单的 Clear Key 案例simpl.info/ck。以下是代码演示,虽然没有与许可证服务器进行交互,但与上述步骤相似。
// 定义一个密钥
var KEY = new Uint8Array([
0xeb, 0xdd, 0x62, 0xf1, 0x68, 0x14, 0xd2, 0x7b,
0x68, 0xef, 0x12, 0x2a, 0xfc, 0xe4, 0xae, 0x3c
]);
var video = document.querySelector('video');
video.addEventListener('encrypted', handleEncrypted, false);
navigator.requestMediaKeySystemAccess('org.w3.clearkey', config).then(
function(keySystemAccess) {
return keySystemAccess.createMediaKeys();
}
).then(
function(createdMediaKeys) {
return video.setMediaKeys(createdMediaKeys);
}
).catch(
function(error) {
console.error('Failed to set up MediaKeys', error);
}
);
function handleEncrypted(event) {
var session = video.mediaKeys.createSession();
session.addEventListener('message', handleMessage, false);
session.generateRequest(event.initDataType, event.initData).catch(
function(error) {
console.error('Failed to generate a license request', error);
}
);
}
function handleMessage(event) {
// 如果有证书服务器,应该会发起一个异步请求
// 使用 event.message 作为请求体
// 请求返回值作为 Unit8Array 格式的密钥
// 然后传递给 session.update
// 这里我们在客户端同步生成一个许可证,使用上面的硬编码密钥
var license = generateLicense(event.message);
var session = event.target;
session.update(license).catch(
function(error) {
console.error('Failed to update the session', error);
}
);
}
// 转换 Unit8Array 为 base64格式,无填充。
function toBase64(u8arr) {
return btoa(String.fromCharCode.apply(null, u8arr)).replace(/\+/g, '-').replace(/\//g, '_').replace(/=*$/, '');
}
// 这里代替了证书服务器
// kids 是base64 编码的密钥 ID 数组
// keys 是base64 编码的密钥数组
function generateLicense(message) {
// 解析 clear key 许可证请求
var request = JSON.parse(new TextDecoder().decode(message));
// 我们只知道一个密钥,因此这里只有一个.
// 真实的许可证服务可以很简单的提供多个密钥
console.assert(request.kids.length === 1);
var keyObj = {
kty: 'oct',
alg: 'A128KW',
kid: request.kids[0],
k: toBase64(KEY)
};
return new TextEncoder().encode(JSON.stringify({keys: [keyObj]}));
}
要测试这个代码,需要提供一个加密视频。使用 Clear Key 加密一个视频以供使用可以根据每一个 webm_crypt 说明制成为WebM视频。商业服务也都可用(知道对于ISO BMFF/MP4可用)其他解决方案正在开发。
HTMLMediaElement 是一个简单美丽的东西。
使用它我们能够通过提供一个src 地址,加载,解码和播放媒体资源。
<video src='foo.webm'></video>
Media Source Extension 是对 HTMLMediaElement 的一个扩展,实现了对媒体资源更精细化的控制。通过允许 Javascript 来为视频分块的播放构建视频流。这又可以实现诸如自适应视频流和时光平移等技术。
为什么说 MSE 对于 EME 规范而言很重要呢?因为除了分发被保护的内容之外,商业化的内容提供者们必须能够让内容分发适用各种网络条件以及其他的自定义需求。比如 Netfix 公司会根据网络条件变化动态地调整视频流的比率。EME 播放由 MSE 实现提供的多媒体资源流,就像是通过 src 提供
的媒体资源一样。
关于如何分块和播放以不同比率编码的媒体资源?查看以下 Dash 部分
你可以在simpl.info/mse 查看 MSE 如何运行。在这个案例中,一个 WebM 视频通过 File API 分割成五块。在生产环境 APP 中,视频块应该通过 Ajax 检索获得。
首先创建一个 SourceBuffer
var sourceBuffer = mediaSource.addSourceBuffer('video/webm; codecs="vorbis,vp8"');
通过使用 appendBuffer 方法,附加每一个块,整个视频信息就会“流”向 video 元素:
reader.onload = function (e) {
sourceBuffer.appendBuffer(new Uint8Array(e.target.result));
if (i === NUM_CHUNKS - 1) {
mediaSource.endOfStream();
} else {
if (video.paused) {
// start playing after first chunk is appended
video.play();
}
readChunk_(++i);
}
};
关于 MSE 更多信息查看MSE Primer
多设备、多平台、移动平台 —— 无论你怎么称呼这一种现象,Web 总是在可变的网络连接条件下运行实践的。动态的,自适应的传输是应对多设备世界中的带宽限制和可变性至关重要。
DASH 被实现来完成最佳的媒体传输,包括流传输和下载。还有一些其他的技术在做类似的事情,比如苹果的 HLS(HTTP Live Streaming) 以及 微软的 Smooth Streaming。但是 DASH 是唯一一个基于 开发标注的通过 HTTP 协议实现自适应比特流的方法。DASH 已经被一些网站使用如 YouTube。
MSE 和 EME 为 DASH 提供了什么? 基于 MSE 的 DASH 实现可以解析一个清单文件,以适当的比率下载视频片段,并在必要的时候通过现有的 HTTP 技术将下载的视频片段传输给 video 元素。
换句话说,DASH 使得商业内容的提供者能够提供不同码率的被保护的内容。
DASH 的特性:
使用网络提供付费音视频正在快速的增长。似乎每一个新的设备,无论是平板电脑,游戏机,联网电视或者机顶盒,都能够通过 HTTP 传输来自主要内容提供商的流媒体信息。超过 85% 的移动端和桌面端浏览器支持 video 和 audio 标签。思科公司估计到2017年,视频将占全网互联流量的80%到90%。在这种背景下,浏览器对受保护的内容支持变得越来越重要,因为浏览器供应商削减了对大多数媒体插件的 API 支持。
HTTP2.0 即 HTTP 协议的第二个主要版本,HTTP2.0 仍然是基于 HTTP 协议的扩展,其应用的语义不变,核心功能和API相较于之前的版本都没有什么变动。其**起源于 Google 的 SPDY 协议,主要从底层做出改变,突破 HTTP1.x 在传输,TCP连接,资源优化,并发和压缩等性能上的限制,除此之外还支持服务端推送功能设置请求的优先级,让更重要的请求先一步完成连接,进一步提升性能。
二进制分帧层是 HTTP2 性能提升的核心。简单理解这就是一个编码机制,在HTTP API 从网络层端口获取的信息进行二级制编码。HTTP1.x 只是进行纯文本编码,HTTP2将传输消息分割为更小的消息和帧,并进行二进制编码。
分帧概念图
如图 HTTP2 会将首部信息封装到头部帧,请求体部分封装到数据帧
分帧机制改变了客户端和服务器之间减缓数据的方式。要理解这种机制,需要先了解几个新的概念:
1)连接
通信是基于 TCP 连接完成的,一个 TCP 连接理论上可以承载任意数量的数据流。
2)数据流
数据流即基于TCP连接内的数据流,是双向的,可以承载一条或者多条消息。负责TCP 连接中的数据传输。数据流通过 StreamID 标识。
3)消息
一条消息就是一个HTTP请求或者响应即 Request message、Response message;每条消息都包含相对应的多个帧信息,如头帧和数据帧。
4)帧
帧就是是数据传输的最小单位(HTTP1.1 用文本格式传输,最小单位应该是字符内容)承载特定类型的数据,如 HTTP 标头、消息负载。不通数据流的帧可以交错发送,然后根据帧头的数据流标识符(StreamID)重组数据。
单条数据流的内容组成如下:
数据传输连接组成图
在 HTTP1.1 中,客户端发起多个并行请求,会使用多个 TCP 连接。这是由 HTTP1.1 的交付模型决定的,该模型保证每个连接每次只交付一个响应。这种模型会导致排队阻塞,造成 TCP 传输效率低下。
HTTP2.0 中的二级制分帧层打破了这个限制,完成了请求和响应的复用。因为每个帧都带有具体流的标志符。客户端和服务端可以将消息分成多个互不相干的帧,然后交错发送在另一端组装起来。
如上图可以并行的发送多个请求和响应多个请求,每个请求对应一个流。HTTP2.0 解决了 HTTP1.1 的首部阻塞问题,消除了并行请求和响应多个的时对多个连接的依赖。速度更快,效率更高,开发更简单。
HTTP2.0 的主要连接性能在于,可以在一个拥塞受到良好控制的通道上任意进行复用。
大多数 HTTP 连接都是短暂的,而 TCP 则针对长时间的批量数据传输进行了优化。
1)重用 TCP 连接。降低协议本身的开销,减少内存占用和处理空间。
2)缩短多个完整连接的路径。提高网络的利用率,减少网络延迟。
HTTP 消息分解成多个独立帧之后,我们可以复用多个数据流中的帧。HTTP2.0 允许每个流都有一个关联的权重和依赖关系来处理这些帧的传输顺序:
用 1- 256 的整数表示数据流的权重。
依赖关系即数据流的父子结构。标明 父结构的数据流 > 子结构数据流
对于同级数据流,应该按照权重比例 分配资源。
如:
S4 = S3 = 1/2
S1 = 12/16
S2 = 4/16
S5 > S4/S3 > S1/S2即 S5 先于 S4/S3 获的完整资源,S4/S3 先于 S2/S1。 数据流 S4 和 S3 各应获得 8/16。S1/S2 同理。
数据流依赖关系和权重表示传输优先级,但是客户端并不能强制要求服务端遵循数据流优先级处理数据流。
流控制可以阻止大量数据发送,避免超出处理能力。可以用作两个个方面:1)高负载或者繁忙状态下限制或停止传输 2)为特定的数据流分配固定的资源,最大化利用率。
HTTP/2 提供了一组简单的构建块,这些构建块允许客户端和服务器实现其自己的数据流和连接级流控制。
HTTP2.0 新增的又一个强大的新功能是,服务器可以对一个客户端请求发送多个响应。即除了请求的数据之外,服务端可以响应请求之外的数据。
简单理解就是:
客户端:“我需要 /page.html”
服务端:“OK,收到。你应该还需要 /script/jq.js style.css 一起给你”
打破了严格的请求响应的语义。但是可以提前推送资源减少额外的延迟时间,获得性能优势。推送资源可以进行以下处理:
所有的服务器推送流都由 PUSH_PROMISE 帧发起,表明了服务器向客户端推送所述资源的意图,需要先于推送资源的相应数据。客户端需要先知道服务器推送的资源,以免重复请求。
因此,需要先于数据帧 发送所有 PUSH_PROMISE 帧,PUSH_PROMISE 帧 中包含所承诺资源的 HTTP 标头。
客户端接收到 PUSH_PROMISE 帧 后可以选择拒绝数据流(通过 RST_STREAM 帧)。在 HTTP2.0 连接开始时还可以通过 SETTINGS 帧 对推送资源设置优先级等。
跟多推送相关查看
每个 HTTP 请求都会有对应的请求标头用来说明传输的资源和属性。不同于 HTTP1.1 的纯文本字节形式传输,HTTP2.0 使用了 HPACK 压缩格式压缩请求和响应标头元数据。依赖于两种强大的技术:
霍夫曼编码对传输的各个值进行压缩。而利用之前传输值的索引表,可以通过传输索引值的方式对重复值编码,索引值可以有效查询和重构完整的标头键值对。简答理解就是
HTTP/2 中,请求和响应标头字段的定义保持不变。仅有一些大小写小差异:所有标头字段名称均为小写,请求行现在拆分成各个 :method、:scheme、:authority 和 :path 伪标头字段。
更多查看 IETF HPACK - HTTP/2 的标头压缩
https://developers.google.com/web/fundamentals/performance/http2/?hl=zh-cn
https://zhuanlan.zhihu.com/p/26559480
实现一个系统,统计前端页面性能、页面 JS 报错、用户操作行为、PV/UV
、用户设备等信息,并进行必要的监控报警。方案你会如何设计,用什么技术点,什么样的技术架构,难点是什么等等。
要实现统计页面信息,并监控报错。从外观上看需要五个东西:
PageTest,Puppeteer等。Nginx 服务器,存储可以简单使用物理机存储文件,也可以使用数据库存储,云端存储等。更进一步,近期数据需要持续读写,历史数据长期保存可以考虑,使用 ES 进行近期数据保存,分布式存储历史数据。Python。其他的数据分析应用 如 Hadoop 等。HighChart、Echart、AntV 等。除了整体流程之外,需要设计数据上报的数据结构: 采用 Nginx 收集,为了加快请求的过程,考虑请求接口的连接复用和资源大小 使用 1X1 GIF 图片 接收日志数据:
https://www.example.com/log.gif?log_type=日志类型&log_data=日志数据&log_token=令牌
通过三种数据区分日志数据类型:
const LOG_TYPE = {
// 错误日志
ERROR: 1,
// 页面性能
PERFOMANCE: 2,
// 用户追踪(包括PV/UV 等)
TRACK: 3
}class LogBaseInfo {
private ip string
private device string
private user_trace string[]
constructor(ip, device, user_trace) {
this.ip = ip
this.device = device
this.user_trace = user_trace
}
}其他错误类型继承这个基类实现。如:
class ErrorLogInfo extends LogBaseInfo {
constructor(info, ...props) {
super(...props)
this.info = info
}
}为了使得数据传输方便和安全,可以对数据进行编码和加密如:
encodeURLComponent 和 base64
注: 具体的数据信息需要根据不同的类型单独解析,详情看后面的每种类型的日志收集分析。
由于需要收集一些设备信息和用户硬件信息,需要配置对应的 Nginx 日志格式收集 UserAgent,IP 等信息。如:
log_format '$remote_addr-$remote-user [$time_local] $http_x_real_ip $request_uri $status $http_referer $http_user_agent' 前端性能主要关注一下几个点:
统计时间牵涉到两个 API,一般来说前端统计时间都借用 performance.timing 和 Cookie
performance.timing 可以获取页面加载过程中的所有数据信息:
{
connectEnd: 1567321999147
connectStart: 1567321999147
domComplete: 1567322000336
// 所有立即执行脚本执行完毕
domContentLoadedEventEnd: 1567321999707
// 开始发送DOMContentLoaded事件
domContentLoadedEventStart: 1567321999700
domInteractive: 1567321999700
// DOM 开始解析
domLoading: 1567321999189
domainLookupEnd: 1567321999147
domainLookupStart: 1567321999147
fetchStart: 1567321999147
loadEventEnd: 1567322000343
loadEventStart: 1567322000337
// 页面跳转过来
navigationStart: 1567321999137
redirectEnd: 0
redirectStart: 0
// 请求开始
requestStart: 1567321999182
responseEnd: 1567321999186
responseStart: 1567321999182
secureConnectionStart: 0
unloadEventEnd: 0
unloadEventStart: 0
}时间统计节点
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<link rel="stylesheet" href="./common.css" />
</head>
<body>
<div>1</div>
<script type="text/javascript">
window.firstScreen = Date.now();
</script>
</body>
</html>firstPaint - performance.navigationStart
firstScreen - performance.navigationStart
需要统计所有图片的加载时间,需要为页面中所有图片添加 onload 事件,监听加载最慢的图片得到时间 loadTime 可得:
loadTime - performance.timing.navigationStart
除此之外,如果需要进行跨页面时间统计,需要使用 Cookie 进行本地存储。
前端错误信息一般分为两种:普通错误和网络请求错误。
一般性错误可以通过监听错误事件来收集。
interface ErrorEvent {
message: string;
filename: string;
lineno: number;
colno: number;
error: Error;
}
window.addEventListener('error', (e: ErrorEvent) => {
// 上报错误信息
})通过这种方式可以捕获 JavaScript 执行错误 和 资源加载错误
网络请求错误可以通过重写内置方法来实现包括 window.XMLHTTPRequest 和 window.fetch
XMLHTTPRequest.prototype.open = function() {}
XMLHTTPRequest.prototype.send = function() {
this.addEventListener('readystatechange', () => {
if (this.readyState === 4) {
if (!this.status || this.status >= 400) {
// 错误收集
}
}
})
}const req = window.fetch
const proxyFetch = function() {
window.fetch = function fetch() {
req.apply(this, arguments).then((res) => {
// res.status > 400
// 错误上报
return res
})
}
}
proxyFetch()需要记录用户操作行为,一般用户操作行为记录包括两种:用户点击 和 发送请求。需要做到以下三点:
document 上监听所有的点击事件。send 和 fetch 方法内记录用户请求。记录用户请求如上,这里简单实现以下记录用户点击行为
document.addEventListener('click', () => (e) {
let className = "";
let placeholder = "";
let inputValue = "";
const tagName = e.target.tagName;
let innerText = "";
if (e.target.tagName != "svg" && e.target.tagName != "use") {
className = e.target.className;
placeholder = e.target.placeholder || "";
inputValue = e.target.value || "";
innerText = e.target.innerText.replace(/\s*/g, "");
}
// 将点击信息推入记录栈
})数据埋点需要记录页面的访问信息。在页面加载后上报数据即可。PV 和 UV 的区别在于是否需要对单个用户进行唯一标识。可以通过 uid、ip 等信息进行区分。
完整系统结构图如下:
需要做的事情:
performance API 统计页面性能时间 【简单】鸡蛋掉落问题是一道非常经典的动态规划面试题,本来是谷歌的面试题,由于过于经典谷歌已经不再用这道题作为面试题目了。
题目如下:
有一种神奇的鸡蛋 K 个,和一幢共 N 层的大楼。存在一个楼层 F,鸡蛋从高于 F 层的楼上扔下会碎裂,不能继续使用;从低于 F 层的楼上扔下不碎,可以继续使用。为了找到 F 的具体楼层数,需要不断的尝试,无论 F 值如何,找到最小移动次数 M 是多少?
假设楼层数量 N=100
1)只有一个鸡蛋
只有一个蛋的情况下,保证蛋不破碎还能找到结果。必须从第一层开始一层一层网上移动。因此:
M = 100
2)有无限个鸡蛋
无限个鸡蛋的情况下,鸡蛋就可以不作为参考因子。快速从 1-100 层中找出目标楼层。因此可以使用二分法
M = log2N = 6.67 ≈ 7
3)有两个鸡蛋
有两个鸡蛋的情况下,如果第一个鸡蛋破碎,则第二个鸡蛋只能一层一层移动尝试(回到第一种情况)。因此有两个鸡蛋的情况下,第一个鸡蛋的作用是为了缩小第二个鸡蛋的范围。
E1,第二个鸡蛋为 E2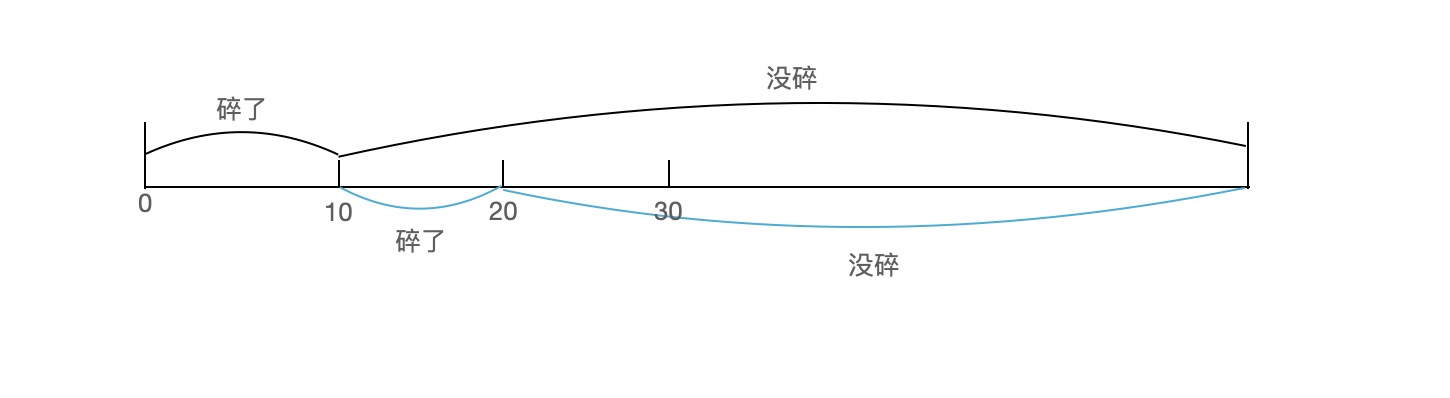
【如果 F = 10】, 则第一个鸡蛋扔 E1 = 1 次破碎,第二个鸡蛋从1 - 10 扔 E2 = 9 次。则 N = E1 + E2 = 10
【如果 F = 100】 ,则第一个鸡蛋扔 E1 = 10 次破碎,第二个鸡蛋需要扔 E2 = 9 次。则 N = E1 + E2 = 19
这种情况下,第二个鸡蛋扔的次数是恒定的 9 次,第一个鸡蛋扔的次数最多为 10 次。因此最坏情况下至少需要 M=19 次。这一个算法是不平均的。
这种情况下, 第一个鸡蛋的层数是等间隔的,因此楼层越靠后第一个鸡蛋扔的次数越多。因此需要平均这个算法,需要在 E1 的次数增加的同时 E2 的次数减少。
n 层,第二次尝试 n + n - 1 层,直到最后一层。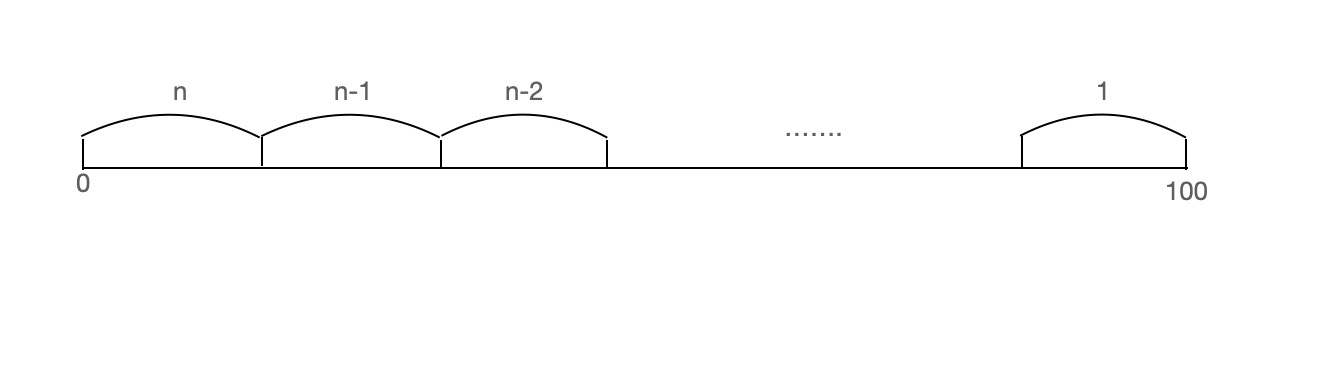
因此可以得出
(n + n - 1 + n - 2 ... + 1) >= 100
n >= 13.65 ≈ 14
可以得出对应的层数映射。
| 首次扔 | 14 | 27 | 39 | 50 | 60 | 69 | 77 | 84 | 90 | 95 | 99 | 100 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 鸡蛋 E1 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 鸡蛋 E2 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 1 | 0 |
// E1 的尝试层数和次数
14, 27, 39, 50, 60, 69, 77, 84, 90, 95, 99, 100
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12
// E2 对应次数
13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 1, 0
因此总次数在 12 ~ 14 之间,最大次数为 M=14 而且这个算法相对于平均间隔更加稳定。
假设楼层数量为 N,鸡蛋数量为 K,满足条件的移动次数 M(N, K) 为 N 和 K 的函数。这种情况下,随意找一个楼层 X 扔下鸡蛋。出现两种情况
1)如果鸡蛋碎了。 那么需要从 X 之前的楼层中查找。因此剩余 M(X - 1, K - 1) 次。
2)如果鸡蛋没碎。 那么要从 X 之后的楼层中查找。剩余M(N - X, K) 次。
需要查询最坏情况下的次数,因此取两种情况下的最大值。
M(N, K) = Max(M(N - 1, X - 1), M(N, K - X)) + 1
X 可以取 1 - N 任意值。因此需要遍历查找出所有值中的最小可能值。
M(N, K) = Min(M1, M2, M3, .... Mn)
可以看到每次计算都是在查询 M(N, K) 的子问题。同时对于边界值。 K = 1 和 N = 1 的情况下为常量。即一个鸡蛋情况下为楼层数;一层楼的情况下恒等于 1。
M(1, K) = 1
M(N, K) = N
def drop_egg(N, K):
def dp(n, k):
if k == 1 or n == 1 or n == 0:
return n
m = n
for i in range(1, n):
m1 = 1 + max(dp(i - 1, k - 1), dp(n - i, k))
m = min(m, m1)
return m
return dp(N, K)这种计算方法计算的复杂度很高,原理和斐波那契数列一样,重复计算了很多节点,每次递归都会重新计算每一个子节点。因此可以使用 Hash 表进行简单优化。
def drop_egg_hash(N, K):
memo = {}
def dp(n, k):
if (n, k) in memo:
return memo[n, k]
if k == 1 or n == 1 or n == 0:
memo[n, k] = n
return n
m = n
for i in range(1, n):
m1 = 1 + max(dp(i - 1, k - 1), dp(n - i, k))
m = min(m, m1)
memo[n, k] = m
return m
return dp(N, K)相比于第一种暴力解法,这种方式很好的解决了递归造成的重复计算问题。
M(N, K) = Max(M(N - 1, X - 1), M(N - X, K))
上面的公式是整个算法的核心部分,可以看出最主要第递归部分都在查询和比较 M(N - 1, X - 1) 和 M(N - X, K)
同样对于这两个函数都满足条件。
# 随着 X 值增大,函数值增大。X = 1 时最小,X = N 时最大
1 < M(X - 1, K - 1) < N# 随着 X 值增大,函数值减少。X = 1 时最大,X = N 时最小。
1 < M(N - X, K) < N即存在某个中间值 X1 ,满足条件:
当 X < X1 时,必定存在� M(N - X, K) > M(K - 1, X - 1)
当 X > X1 时,必定存在 M(N - X, K) < M(K - 1, X - 1)
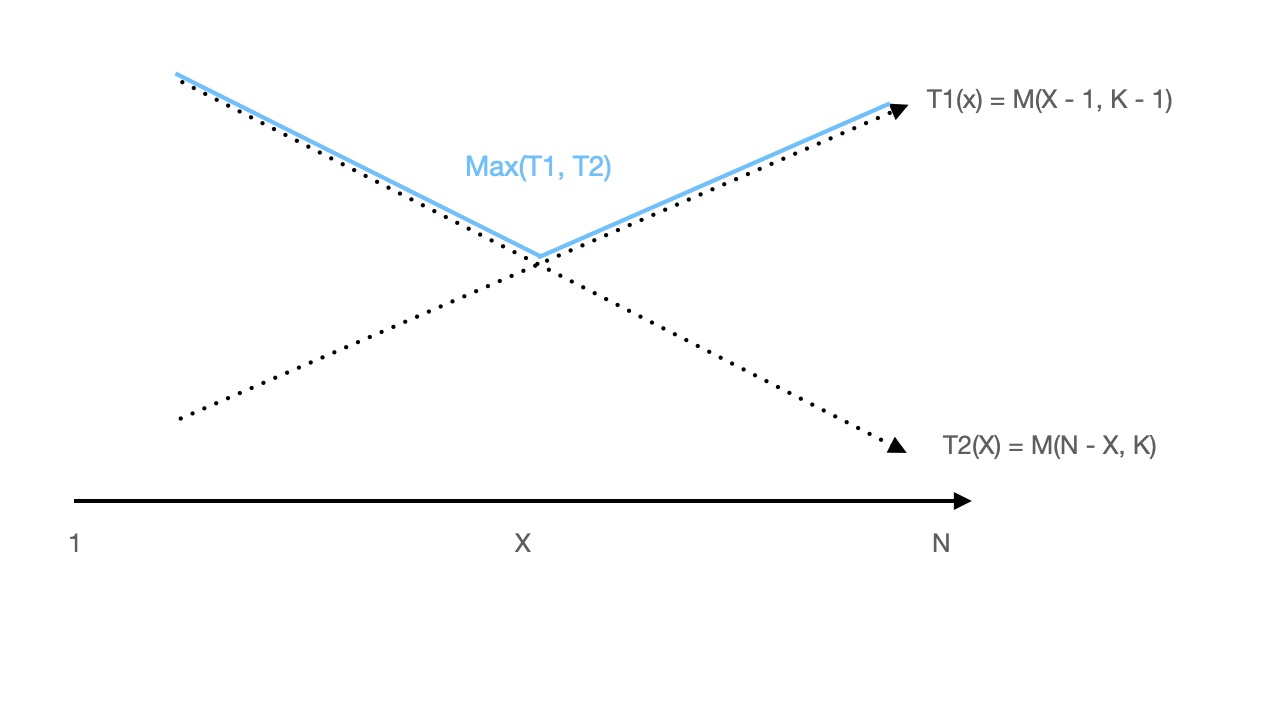
因此,我们在定位楼层 F 时不需要通过遍历所有楼层取查找,而是通过二分的方式。
def drop_egg_binary(N, K):
memo = {}
def dp(n, k):
if (n, k) in memo:
return memo[n, k]
if k == 1 or n == 1 or n == 0:
memo[n, k] = n
return n
# 二分查找开始。离散点查找 low, high, middle
low = 1
high = n
while low + 1 < high:
middle = (low + high) // 2
# 取左右两边的值比较
lValue = dp(middle - 1, k - 1)
rValue = dp(n - middle, k)
if lValue < rValue:
low = middle
elif lValue > rValue:
high = middle
else:
low = high = middle
m = 1 + min(
dp(n - low, k),
dp(high - 1, k - 1)
)
memo[n, k] = m
return m
return dp(N, K)在这个方法中利用�离散函数的单调性,分别计算出两个的内部最大值,然后在最大值中取最小值。这一方法将时间复杂度减低到了 KNLogN
更快找到最有决策点X的方法?递归的两个变量分别为鸡蛋K 和 楼层数 N。存在一个最优决策点 X。对于公式
M(N, K) = Max(M(N - X, K), M(K - 1, X - 1))是一个与楼层 N 无关的计算,M(K - 1, X - 1)。因此先固定 K, 随着 N 的增加,M(K - 1, X - 1) 的值是固定不变的, M(N - X, K) 增加。�即:

函数 M(N - X, K) 会随着 N 增加不断往右移动,两条线的交叉点位置也会不断增大。
即对于最优点 X,随着 N 单调递增。
def drop_egg_func(n, k):
# dp[x] = drop_egg_func(x, 1) 一个鸡蛋情况
dp = list(range(n + 1)) # t1
dp2 = [0] * (n + 1) # t2
# 从第二个鸡蛋开始
for i in range(2, k + 1):
# 开始楼层
x = 1
for j in range(1, n + 1):
# max(t1(x - 1), t2(x - 1) > max(t1(x), t2(x)))
while x < j and max(dp[x - 1], dp2[j - x]) > max(dp[x], dp2[j - x - 1]):
x += 1
dp2[j] = 1 + max(dp[x - 1], dp2[j - x])
dp = dp2[:]
return dp[-1]时间复杂度:O(kn)。我们需要计算 O(kn)个状态,同时对于每个 k,最优解指针只会从 0 到 n 走一次,复杂度也是 O(kn)。因此总体复杂度为 O(kn)。
空间复杂度:O(n)。因为 dp 每一层的解只依赖于上一层的解,因此我们每次只保留一层的解,需要的空间复杂度为 O(n)。
https://www.bilibili.com/video/BV1KE41137PK
https://leetcode-cn.com/problems/super-egg-drop
https://leetcode-cn.com/tag/dynamic-programming
https://zh.wikipedia.org/wiki/%E5%8A%A8%E6%80%81%E8%A7%84%E5%88%92
KMP(Knuth-Morris-Pratt)算法是一个线性时间的高效字符串匹配算法。这个算法是由 Knuth 和 Pratt 在1974年构思,同年 Morris 独立地设计出该算法,最终由三人于1977年联合发表。KMP 算法的核心是通过已匹配的子串构建部分匹配表,减少匹配次数优化时间。这与动态规划的概念如出一辙,KMP 的状态机构建更加具体和规范,也更容易通过 ”死记硬背“ 的方式记住 KMP 的模型。
举个例子看一下正常匹配和KMP算法的直观区别:在字符串 T 中查找是否存在字符串 W 。
T: Do You See A Dog Here(忽略大小写)
W:Dog
比较粗暴的办法就是比较 T 和 W 字符串的每一个字符,遇到不匹配的情况则将 W 右移一次,然后再开始比较。

下面是暴力搜索的简单实现:
def naiveTextSearch(T, W):
if W == "" or W is None:
return -1
tLen = len(T)
wLen = len(W)
i = 0 while i < (tLen - wLen + 1):
matched = True
# 循环 W 匹配
for j in range(0, wLen):
# 一旦发现不匹配则跳出当前匹配循环
if (W[j] != T[i + j]):
matched = False
break
if matched:
return i
# 指针右移一位
i = i + 1
return -1可以比较明显的看出来,这种暴力搜索的算法实现的时间复杂度为 O(mn),m 和 n 分别为单词 W 和文本 T 的长度。
再看一个古怪的案例:
T:deadElephant
W:deadEye

再上图所示的案例中。左边绿色的框中的子串和右边绿色框中的子串相等。实际上是单词 “deadEye” 的 index = 4 子串的最大前缀的等于最大后缀。
按照这个规律,来看一下抽象的例子(N 表示任意字符)。

str2 === str3 & str3 === str1 当匹配到 str3 后检测到未匹配。如图所示,可以直接移动匹配位置到 str2 之后。绿色的标注部分会比较明确的展示出来下一次开始比较的地方。
实际上,为单词 W 的每个单词前缀寻找”绿色部分”, 则可以跳过不必要的匹配提高算法的效率。这也就是 KMP 算法背后的逻辑。
使用 aux 数组存储这些索引位置。与暴力匹配不同的是:暴力匹配每次移动时会比较所有的字符,而 KMP 算法使用 aux 中的值来确认要匹配的下一个字符。
如字符:ACABACACD

m 和 i 定义了算法的状态。以此表示子串i - 1,m之前的前缀等于子串的后缀。即W[m-1] = W[i - m - 1]。对于上述状态,将两个 m 的值存储在 aux 的数组中,知道索引i - 1`。
def creatAux(W):
第一个位置始终为 0,从 1 开始计算
aux = [0] * len(W)
i = 1
m = 0
循环所有子串
while i < len(W):
# 如果发现符合的数据则 m + 1,
if W[i] == W[m]:
m += 1
aux[i] = m
i = i + 1
# 不匹配的时候 m 回退一位索引
elif W[i] != W[m] and m != 0:
m = aux[m - 1]
else:
aux[i] = 0
i = i + 1
return aux接下来可以借助 aux 来实现查询字符串了。
def smartTextSearch(T, W):
aux = creatAux(W)
i = 0
j = 0
while j < len(T):
# 处理不匹配的情况
if W[i] != T[j]:
# 首位不处理
if i == 0:
j += 1
# 非首位则可以通过 aux 获取下一次匹配的开始位置
else:
i = aux[i - 1]
else:
i = i + 1
j = j + 1
if i == len(W):
return j - i下面是一些计算过程的快照。T = "ACFACABACABACACDK" W = "ACABACACD"

对于 KMP 算法而言。创建表增加了空间复杂度 O(n),除去一些初始化的工作,所有的工作都是在 while 循环中完成,循环的上限次数为 2n 次迭代。因此时间复杂度为 O(n)。
好了。你已经掌握了 KMP 算法 O(∩_∩)O
https://zh.wikipedia.org/wiki/KMP算法
https://medium.com/@giri_sh/string-matching-kmp-algorithm-27c182efa387
https://medium.com/@niralipatel047/the-knuth-morris-pratt-algorithm-kmp-9e8f466cfbdf
给定两个单词 word1 和 word2 计算出 word1 转换成 word2 所使用的的最少操作次数。
可以进行一下操作:
1) 删除一个字符
2)插入一个字符
3)替换一个字符
示例:world => word 结果: 1
只需要删除 l 字符串
解题思路
1)使用 D[i][j] 表示单词长度为 i 和 j 之间的编辑距离。
2)D[i][j] = 上一步操作 + 1;上一步操作可以使删除 删除,替换,插入
3)当插入最后一个字符到 word1 即可得到 word2;则 D[i][j] = D[i][j - 1] + 1
4)当替换 word1 最后一个字符即可得到 word2;则D[i][j] = D[i - 1][j - 1] + 1。如果最后一个操作字符串相等,则 D[i][j] = D[i - 1][j - 1]
5)当删除 word 最后一个字符即可得到 word2;则 D[i][j] = D[i - 1][j] + 1
6)D[i][j] = min(D[i][j], D[i - 1], [j - 1], D[i - 1][j]) + 1
7)对于边界值 D[0][j] = j; D[i][0] = i
func minDistance(s1 string, s2 string) int {
s1Len := len(s1)
s2Len := len(s2)
D := tool.Make2DArr(s1Len + 1, s2Len + 1)
for i := 0; i <= s1Len; i ++ {
for j := 0; j <= s2Len; j ++ {
// 判断边界情况
if i == 0 {
D[i][j] = i
} else if j == 0 {
D[i][j] = j
} else {
// 如果最后一个操作字符串相等,则不需要任何操作
if s1[i - 1] == s2[j - 1] {
D[i][j] = D[i - 1][j - 1]
} else {
D[i][j] = tool.Min(D[i - 1][j - 1], D[i - 1][j], D[i][j - 1]) + 1
}
}
}
}
return D[s1Len][s2Len]
}
前缀树(Trie 树)是一种哈希树形变种结构,多用于检索字符串数据集中的键,是一种有序树。

与二叉查找树不同,键并不是直接保存在节点中,而是由节点树种的位置决定的(图中标注完整的单词只是为了方便演示)。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串(根节点对应空字符串)。
Trie 可以看做是一个 DFA(确定有限状态自动机)。即对于一个属于该自动机的状态(如t)和一个属于改自动机的字母表的字符(如e),能根据实现给定的转移函数转移到下一个状态(te)。
Trie 这一种数据结构多用于检索字符串几种的键,常用语搜索引擎系统用于文本词频统计,搜索提示等。如:


3)IP 路由(最长前缀匹配)

除此之外还有九宫格打字预测、单词游戏等等。
之前讲过散列表查找和平衡树查找,使得我们能够实现快速查询。为什么还需要 Trie 树呢?不同的数据结构有其所匹配的真实场景,使得查询更加的高效。尽管散列表可以实现 O(1) 级的查询速度,却无法高效的完成以下操作:
除此之外,随着字符串的增加,重复的键值会加剧 Hash 表的冲突也会使得 Hash 表的空间加大。与之相比 Trie 前缀树只需要较少稳定的空间,以及 O(m) 的复杂度(m 为键长)。
Trie 树是一个有根的树结构。其节点具有一下特点:
1)最多 R 个指向子节点的连接。R 表示字符集合个数。比如 26个英文字母,固定的中文字符集合。
2)结尾标识。指定节点是对应的键结尾还是只是前缀。
【Trie 节点结构】
class TrieNode:
def __init__(self, ch):
self.char = ch
self.links = {}
self.word_end = False
self.count = 0
def contains(self, ch):
return self.links.get(ch) is not None
def get(self, ch):
return self.links.get(ch)
def put(self, ch, node):
self.links[ch] = node
return self.links[ch]【Trie 树插入】
Trie 树种最常见的操作就是插入和查找。Trie 树的插入和普通的树形结构插入基本一致,遵循特定的规则逐级插入。
class Trie:
def __init__(self):
self.root = TrieNode('')
def insert(self, word):
node = self.root
for ch in word:
if node.contains(ch):
node = node.get(ch)
else:
node = node.put(ch, TrieNode(ch))
node.word_end = True
node.count += 11)时间复杂度:O(m)。其中 m 为插入的键长度。在迭代过程中创建或者转移到下一个节点知道键遍历完。
2)空间复杂度:O(m)。插入过程中最坏情况新插入的键无公共前缀,需要创建 m 个节点。
【Trie 树查找】
从根部节点开始搜索,查询当前节点中与键字符对应的链接。存在或者不存在。
def searchPrefix(self, prefix):
node = self.node
for ch in word:
if node.contains(ch):
node = node.get(ch)
else:
return None
return node
def search(self, word):
node = self.searchPrefix(word)
if node is not None
return node.word_end
return False
def startsWith(self, prefix):
node = self.searchPrefix(prefix)
return node is not None1)时间复杂度: O(m)。迭代次数为键长度,稳定复杂度。
2)空间复杂度:O(1)。查询过程不创建额外空间。
tree = Trie()
tree.insert('two')
tree.insert('tom')
tree.insert('tea')
tree.insert('ten')
tree.insert('ted')
tree.insert('inner')
tree.insert('in')
tree.insert('intel')
tree.startsWith('tn') // False单词搜索【简单】:https://leetcode-cn.com/problems/add-and-search-word-data-structure-design/
单词搜索2【困难】:https://leetcode-cn.com/problems/word-search-ii/
https://zh.wikipedia.org/wiki/Trie
https://leetcode-cn.com/problems/implement-trie-prefix-tree/
https://towardsdatascience.com/implementing-a-trie-data-structure-in-python-in-less-than-100-lines-of-code-a877ea23c1a1
https://zh.wikipedia.org/wiki/DFA
随着编程经验的增长我,程序员们在使用计算机解决问题是不在局限于 “这个功能该怎么实现?”,更多是是会追求 这个功能有什么更优实现?。在解决困难问题或者处理大量数据复杂场景的情况下,我们不可避免的会遇到两个问题:
1) 为什么我的程序运行时间这么长?
2) 为什么我的程序占用了大量的内存?
在数据量不大的情况下,我们只需要考虑能否实现功能。但随着程序的复杂度、各种业务数据量的增长哪些仅仅满足功能的代码就不得不考虑其运行效率。效率可以简单用从两个方面来概括,时间和空间。也可以通过这两个概念来对算法进行平衡和转换达到最优。
一个算法执行所耗费的时间,从理论上老说是不能算出来的。实际开发中有很多的因素影响着我们对算法时间的评估和理解,如计算机性能,数据模型,软件程序等。我们只需要构造出一个数据模型来描述任意程序的运行时间的增长规律,对比多个算法的计算工作量。
根据 D.E Knuth 的观点,一个程序运行的总时间主要和两点有关:
每条语句的执行耗时取决于计算机、程序编译器和操作系统。而执行语句的频率取决于程序本身,包括数据模型以及输入等。因此要客观的分析一个程序的运行总时间,最大的挑战就是判定执行频率。
几个解释时间复杂度的定义:
f(n) * c >= T(n)f(n) * c <= T(n)
对于实际需求。我们总是在为算法找到一个上限,即算法最多花费多少时间。因此常用大 O 来描述时间复杂度。
举个栗子:冒泡排序
function bubbleSort(arr) {
for (let i = 0; i < len - 1; i ++) { // #1
let flag = false #2
for (let j = 0; j < len - 1 - i; j ++) { // #3
if (arr[j] > arr[j + 1]) { // #4
const temp = arr[j+1] // #5
arr[j+1] = arr[j] // #6
arr[j] = temp // #7
flag = true #8
}
}
if (flag === false) return
}
}冒泡排序就是比较相邻元素,并将小的数据项往前调或者往后调。
1)最好的时间复杂度。正序数组
对于已经排好序的数组,只需要执行 #4 的比较 n - 1 次。因此最好的时间复杂度为 O(n)
2)最坏的时间复杂度。倒序数组
对于倒序数组,每次遍历都需要判断并进入 #5 - #7 的数据交换操作。执行频次为 n + (n - 1) + (n - 2) + ... + 1,即 n * (n - 1) / 2。因此最坏的时间复杂度为 O(n^2)
3)平均时间复杂度。任意数据加权平均值
平均复杂度需要考虑到所有出现情况的概率进行加权平均求和。
平均复杂度为:O(n^2)
上诉算法中有很多地方都包含有语句执行,但是没必要精确定量。只需要把握基本原则,抛弃 常数项 和 低阶项。可以遵循一些通用方法:
For 循环运行时间之多是 循环内语句的运行时间 * 迭代次数,即 O(n)。如:let sum = 0
for (let i = 0; i < n; i ++) {
sum = sum + i
}
let sum = 0
for (let i = 0; i < n; i++) {
for (let j = 0; j < n; j ++) {
sum = sum + i * j
}
}
function factorial(n) {
if (n <= 1) {
return 1
} else {
return n * factorial(n - 1)
}
}
if 语句 O(1), else 语句 O(n)。实际复杂度 O(n)。
| 复杂度 | 术语 | 常见算法 |
|---|---|---|
| O(1) | 常数阶 | Hash 表索引 |
| O(n) | 线性阶 | 数组搜索 |
| O(logn) | 对数 | 比较排序 |
| O(nlogn) | 线性对数阶 | 堆排序 |
| O(n^2) | 平方阶 | 冒泡排序 |
| O(n^3) | 立方阶 | 矩阵乘法 |
| O(2^n) | 指数阶 | 动态规划 |
| O(n!) | 阶乘 | 暴力搜索 |
算法的内存占用分析也就是常说的算法空间复杂度分析。空间复杂度表示算法的存储空间和数据规模之间的关系。大多数情况下我们会忽略空间复杂度,或者选择以空间换取更快的时间。如缓存数据、建索引表等。
空间复杂度的度量同样用 大 O 表示。一般包含三个维度:
冒泡排序的例子:
function bubbleSort(arr) {
for (let i = 0; i < len - 1; i ++) { // #1
for (let j = 0; j < len - 1 - i; j ++) { // #2
if (arr[j] > arr[j + 1]) { // #3
const temp = arr[j+1] // #4
arr[j+1] = arr[j] // #5
arr[j] = temp // #6
}
}
}
}变量 i 声明一次。变量 j, temp 声明多次,但是每次循环结束后回收。因此空间复杂度为 O(1)
对比快速排序:
function partition2(arr, low, high) {
let pivot = arr[low];
while (low < high) {
while (low < high && arr[high] > pivot) {
--high;
}
arr[low] = arr[high];
while (low < high && arr[low] <= pivot) {
++low;
}
arr[high] = arr[low];
}
arr[low] = pivot;
return low;
}
function quickSort2(arr, low, high) {
if (low < high) {
let pivot = partition2(arr, low, high);
quickSort2(arr, low, pivot - 1);
quickSort2(arr, pivot + 1, high);
}
return arr;
}递归调用每次会分配一个存储指针指向数组实参。最好情况下,每次递归二分数组,调用 logn 次,最坏情况下调用 n 次。因此空间复杂度为 O(n)
算法分析是对程序的运行效率有一个客观的基础认识,避免经验式的评估算法的优劣。通过一定的模型快速发现程序的问题所在,提升代码质量。
https://zh.wikipedia.org/wiki/%E5%A4%A7O%E7%AC%A6%E5%8F%B7
https://zh.wikipedia.org/wiki/%E5%A4%A7%CE%A9%E7%AC%A6%E5%8F%B7
创造型模式一般提供一种创建对象的同时隐藏创建逻辑的一种方法。
定义一个创建对象的接口,让子类决定实例化哪一个工厂类,具体创作过程延续到子类进行。
创建工厂类
function Maserati(options) {
this.name = options.name || 'Maserati'
this.doors = options.doors || 4
this.color = options.color || 'black'
}
function Cadillac(options) {
this.name = options.name || 'Cadillac'
this.doors = options.doors || 4
this.color = options.color || 'five-six'
}
function Audi(options) {
this.name = options.name || 'Audi'
this.doors = options.doors || 2
this.color = options.color || 'yellow'
}
function CarFactoty() {}
CarFactory.prototype.instanceClass = Audi
CarFactory.prototype.create = function(options){
if (options.name === 'Audi') {
return new Audi(options)
} else if (options.name === 'Cadillac') {
return new Cadillac(options)
} else {
return new Maserati(options)
}
}使用工厂类创建实例
const factory = new CarFactory()
const car1 = factory.create({
name: 'Audi',
color: 'yellow',
doors: 6
})
car1.name // Audi保证一个类只有一个实例,并提供它的全局访问点。主要解决一个全局访问的类,不停的创建和销毁的问题。
function Singleton = (function() {
let instance;
function init() {
let name = 'user'
return {
setName(n) {
name = n
},
getName() {
return name
}
}
}
return {
getInstance() {
if (!instance) {
instance = init()
}
return instance
}
}
})();const single = Singleton.getInstance()
single.setName('test')
single.getName() // test通过多个简单的对象一步步创建一个复杂的对象类似于“组合套餐”。与工厂模式类似,但是更关注子对象的组合方式。
在软件开发中通常会将多个简单子对象通过一定的算法组合成一个复杂的对象,建造者只需要管理组合之间的关系。
class Human {
constructor(options) {
this.sex = options.sex || '保密'
this.age = options.age || '保密'
}
getAge() {
return this.age
}
getSex() {
return this.sex
}
}
class Named {
constructor(name) {
this.wholeName = name
const spaceIndex = name.indexOf(' ')
if (spaceIndex > -1) {
this.firstName = name.slice(0, spaceIndex)
this.lastName = name.slice(spaceIndex)
}
}
}
class Health {
constructor(weight) {
this.weight = weight
this.state = this.getState(weight)
}
private getState(weight) {
if (weight >= 300) {
return '大肥肥'
} else if (weight >= 250) {
return '小肥肥'
} else if (weight >= 180) {
return '大壮'
} else if (weight >= 130) {
return '中等'
} else {
return '瘦弱'
}
}
getWeight() {
return this.weight
}
changeWeight(weight) {
this.weight = weight
this.state = this.getState(weight)
}
}
/**
* 建造者
* @param { string } name
* @param { number } weight
*/
class Person() {
constructor(name, wieght) {
const _person = new Human();
_person.name = new Named(name)
_person.health = new Health(weight)
return _person
}
}
const p = new Person('Michael Jackson', 200)
console.log(p.name.firstName) // Michael
console.log(p.health.state) // 大壮创建一个对象原型,通过拷贝这些原型创建新的对象。用于创建重复的对象,提升性能。
Javascript 通过原型继承去实现原型模式,即创建一个对象作为新对象的 prototype 值。
const car = {
drive() {},
brand: 'Audi',
country: 'German'
}
const newCar = Object.create(car, {
brand: {
value: 'BMW',
enumrable: true
}
})
newCar.brand // BMW或者可以通过手动实现
function create(proto) {
function F() {}
F.prototype = proto
f = new F()
return f
}
const newCar = create(car)
car.brand // Audi查找算法即在大量的信息中心寻找特定的信息。现代计算机网络是一个复杂的海量数据的集合体,高效的检索处理这些信息的能力是现代计算机网络发展的重要能力。
计算机进行查找的方法一般是根据数据集合的组织结构确定。一般来说包括顺序查询,二分查询,分块查询,二叉树查询,Hash表查询等方法。
顺序查找属于枚举算法的一种实现。是一种按照原有的数据顺序进行遍历查询的基本查找方法。
#!/usr/bin/python
list = ['a', 'b', 'c', 'd', 'e', 'f', 'z']
def search(arr, target):
i = 0
while i < len(arr):
if target == list[i]:
return i
i += 1
print(search(list, 'd')) # 3复杂度分析:顺序查找查找到任意值的概率相等,复杂度为 O(n)。
二分查找也称之为折半查找。是一种对有序数组中特定元素的查找算法。二分法根据数组的索引大大减少每次查询所需要比较的次数,时间复杂度为对数复杂度logn,一般情况下比顺序查找更加快速,也是众多应用程序的最佳选择。

题目: 数字的平方根。实现 sqrt 函数计算输入数字 num 的平方根,结果保留整数。
#!/usr/bin/python
def sqrt(num):
l, r, ans = 0, num, -1
while l <= r:
mid = (l + r) // 2
if mid * mid <= x:
ans = mid
l = mid + 1
else:
r = mid - 1
return ans
binary_search(8) # 2复杂度分析:二分查找的前提条件是静态顺序存储数据,对于动态插入数据的结构来说效率并不高。复杂度为 O(log2n)。

除此之外二分查找还有许多其他的变种算法,比如:分层散叠,指数搜索,二叉树搜索 等。
二叉查找树也可以成为二叉排序树,二叉搜索树,是一个表达特殊结构二叉树,具有一下性质:它的左子树的所有节点小于根节点;右子树的所有节点大于根节点。二叉查找树是一个比较经典的数据结构,凭借它可以实现快速插入和删除,同时能够快速查找,应用十分广泛。比如文件系统和数据库系统。

#!/usr/bin/python
class BinTreeNode(object):
def __init__(self, data, left=None, right=None):
self.data = data
self.left = left
self.right = right
class BinTree(object):
def __init__(self, root=None):
self.root = root
@classmethod
def build_from(cst, node_list):
dict = {}
for d in node_list:
data = d['data']
dict[data] = BinTreeNode({ 'value': data, 'data': d })
for d in node_list:
data = d['data']
node = dict[data]
if d['is_root']:
root = node
node.left = dict.get(d['left'])
node.right = dict.get(d['right'])
return cst(root)
def search(self, data):
sub = self.root
while sub is not None:
if sub.data['value'] == data:
return sub.data
elif sub.data['value'] > data:
sub = sub.left
else:
sub = sub.right
return nil
node_list = [
{'data': 8, 'left': 3, 'right': 10, 'is_root': True},
{'data': 3, 'left': 1, 'right': 6, 'is_root': False},
{'data': 6, 'left': 4, 'right': 7, 'is_root': False},
{'data': 4, 'left': None, 'right': None, 'is_root': False},
{'data': 7, 'left': None, 'right': None, 'is_root': False},
{'data': 10, 'left': None, 'right': 14, 'is_root': False},
{'data': 14, 'left': 13, 'right': 16, 'is_root': False},
{'data': 1, 'left': None, 'right': None, 'is_root': False},
{ 'data': 16, 'left': None, 'right': None, 'is_root': False }
]
tree = BinTree.build_from(node_list)
tree.search(14) # {'data': 14, 'left': 13, 'right': 16, 'is_root': False}复杂度分析:不管是插入,删除还是查找所有操作都是沿着树的一条或者两条路径进行,因此所花费的时间和树的高度成正比。平均复杂度为 O(logn);在极端情况下的情况下,二叉树会退化成线性表,复杂度变为 O(n)。
二叉树支持动态查询,为了保持最坏情况下的高效查询,二叉查找树设计了很多进化版本,即二叉查找平衡树。如 AVL树,红黑树等。
红黑树二叉平衡树的一种,能保证在最坏的情况下保持稳定的复杂度。这是一个每个节点都带有颜色的二叉查找树,颜色为 红色或者黑色。实现一个红黑树一般有一下几点要求:
1)节点是红色或者黑色
2)根是黑色
3)所有叶子(Nil 节点)都是黑色
4)每个红色节点必须有两个黑色的子节点。即保证每个叶子到跟的所有路径上不会出现两个连续的红色节点。
5)任一节点到其每个叶子的简单路径都包含相同数目的黑色节点。

同时,当我们在对红黑树进行插入和删除等操作时,对树做了修改,那么可能会违背红黑树的性质。为了保持红黑树的性质,我们可以对相关节点做一系列的调整,通过对树进行旋转(例如左旋和右旋操作),即修改树中某些结点的颜色及指针结构,以达到对红黑树进行插入、删除结点等操作时,红黑树依然能保持它特有的性质(五点性质)

#!/usr/bin/python
class RBNode:
def __init__(self, key, value):
self.key = key
self.value = value
self.left = None
self.right = None
self.color = None
class RBTree:
def __init__(self):
self.root = None
self.N = 0
def is_red(node):
if node:
return str(node.color).lower() == 'red'
else:
return False
# 左旋
def rotate_left(self, node):
h = node
x = node.right
h.right = x.left
x.left = h
x.color = h.color
h.color = 'Red'
return x
# 右旋
def rotate_right(self, node):
h = node
x = node.left
h.left = x.right
x.right = h
x.color = h.color
h.color = 'Red'
return x
# 设置叶子
def alter_color(self, node):
node.color = 'Red'
node.left.color = 'Black'
node.right.color = 'Black'
def append(self, key, val):
def put_into(node, key, val):
if not node:
return RBNode(key, val)
if key < node.key:
node.left = put_into(node.left, key, val)
elif key > node.key:
node.right = put_into(node.right, key, val)
else:
node.value = val
return node
if self.is_red(node.right) and not self.is_red(node.left):
self.rotate_left(node)
if self.is_red(node.left) and self.is_red(node.left.left):
self.rotate_right(node)
if self.is_red(node.left) and self.is_red(node.right):
self.alter_color(node)
self.N += 1
return node
self.root = put_into(self.root, key, val)
self.root.color = 'Black'
return self.root
def get(self, key):
def get_value(node, key):
if not node:
return
if key < node.key:
return get_value(node.left, key)
elif key > node.key:
return get_value(node.right, key)
else:
return node.value
val = get_value(self.root, key)
return val
RBT = RBTree()
RBT.append(1, 'G')
RBT.append(2, 'K')
RBT.append(3, 'C')
RBT.append(3, 'D')
print(RBT.search(2)) # K红黑树是一种自平衡二叉搜索树,作为签署是数据库的索引机制和已获得更好的性能。多用于系统任务调度,进程管理,数据库索引等。除此之外还有其他平衡树如:AVL, SBT,伸展树等。
散列表是通过建立数组索引的方式实现快速查询的方式。最核心的**就是构建一个构建一个数组索引和键之间的联系,即散列函数。使用散列查找的算法分为两步:
1)用散列函数将被查找的键转换为数组索引,理想情况下不同的键对应的不同索引值。当然这是理想情况,因此需要处理多个键散列到多个索引值的情况。
2)第二部就是处理碰撞冲突。一般分为开链法和线性探测法

#!/usr/bin/python
class HashTable:
def __init__(self, size):
self.list = [None] * size
def hash(self, key):
sum = 0
for v in key:
sum << 3
sum += ord(v)
return sum % len(self.list)
def insert(self, data):
addr = self.hash(data.key)
# 地址被占用解决冲突
while self.list[addr] is not None:
addr += 1
if addr >= len(self.list):
addr = 0
else:
self.list[addr] = data
def search(self, key):
addr = self.hash(key)
data = self.list[addr]
while data and data['key'] == key:
return self.list[addr]
else:
addr += 1
if addr >= len(self.list):
return nil
hs = HashTable(8)
hs.insert({'key': 'AB', 'name': '狗蛋'})
hs.insert({'key': 'BC', 'name': '全蛋'})
hs.insert({'key': 'AC', 'name': '六福'})
hs.insert({'key': 'AD', 'name': '旺财'})
hs.insert({'key': 'DC', 'name': '小强'})
hs.insert({'key': 'DE', 'name': '9527'})
hs.search('AC') #{key: 'AB', name: '狗蛋'}散列表是算法在时间和空间上做出权衡的经典。如果没有内存限制可以将键映射到一个超大的数组索引,避免冲突。使用散列表需要在时间和空间上找到平衡。
https://python-data-structures-and-algorithms.readthedocs.io/zh/latest/14_%E6%A0%91%E4%B8%8E%E4%BA%8C%E5%8F%89%E6%A0%91/tree/#_1
https://zh.wikipedia.org/wiki/%E4%BA%8C%E5%85%83%E6%90%9C%E5%B0%8B%E6%A8%B9
https://zh.wikipedia.org/wiki/%E7%BA%A2%E9%BB%91%E6%A0%91
经常性的会看到一些金融新闻说“**股市投机氛围严重,不利于价值投资”、“投机倒把形成市场泡沫”等一些言论。在97年以前甚至有一条投机倒把罪,至今为止,投机仍然是一种为人诟病的金融行为。
所以,到底什么是投机呢,它和投资有什么关键或者本质的区别吗。
一般来说批评投机的言论都是以下一些方面:
1)投机只关注价格,不关注价值。
2)投机是为了短期套利,利用或者误导大家的行为从中获利。
3)投机资金流动快速,资金频繁进出造成市场波动。
先从动机上看。不管是投机还是投资,其目的都是为了赚取投资品的未来价值,低买高卖赚取利润。就拿楼盘房价而言,不管你是想乘着现在房价低迷,把房子买下来以后转手给那些刚好需要的人,从中牟取暴利;还是你分析整体的房产走势,实现资产增值。目的其实都是为了赚钱,没有好坏之分。就好比《潜伏》里面的一句话:“这里有两根金条,你能分清楚哪一根是高尚的,哪一根是卑鄙的吗?”。
技术上的区别。不管是长期投资也好还是短期投资牟取暴利也行,都需要精确的分析市场的走势,以及价值分析,精准把握入场退场的时间。如果仅仅因为入市时间短,就判断是投机行为,总不能为了价值投资而自身破产罢。
投资和投机从本质上看无论动机还是评率都是一样的,投资可能会被做成投机,投机也有可能转变成投资。完全看市场反应和个人对市场的分析决策。
无论是投资还是投机都要做对四件事情:
1)对宏观大势的正确判断,资产配置独到合理
2)对投资标的把握精准,证券选择正确。
3)入场和退场的时间把握准确。
4)克服自己再任性上的人弱点。正如巴菲特说:“别人贪婪时我恐惧,别人恐惧时我贪婪”
最后借用一句“投机大师”巴鲁克的话:在我年轻的时候,人们称呼我为投机客,现在称呼我为银行家、慈善家。其实,从始至终,我都是在做同样的事情。
无论做什么,做对就好。
行为型的设计模式更关注对象之间的通信。
职责链为请求创建了一个接收者的链,每一个接收者都包含下一个接收者的引用。如果当前接收者不处理,则传递给下一个接收者处理,以此类推。
使用职责链模式,客户端只需要发送请求到职责链上即可,无需关心处理细节逻辑。职责链将发送者和接收者解耦。
function tDay(time) {
const STAMP_IN_DAY = 24 * 60 * 60 * 1000
if (time >= STAMP_IN_DAY) {
console.log(`${~~(time / STAMP_IN_DAY)}天前`)
} else {
return 'next'
}
}
function tHour(time) {
const STAMP_IN_HOUR = 60 * 60 * 1000
if (time >= STAMP_IN_HOUR) {
console.log(`${~~(time / STAMP_IN_HOUR)}小时前`)
} else {
return 'next'
}
}
function tMinute(time) {
const STAMP_IN_MINUTE = 60 * 1000
if (time >= STAMP_IN_MINUTE) {
console.log(`${~~(time / STAMP_IN_MINUTE)}分钟前`)
} else {
return 'next'
}
}
class Chain {
constructor(fn) {
this.fn = fn
this.next = null
}
setNext(next) {
return this.next = next
}
passRequest() {
const rtn = this.fn.apply(this, arguments)
if (rtn === 'next') {
return this.next && this.next.passRequest.apply(this.next, arguments)
}
return rtn
}
}
const chainDay = new Chain(tDay)
const chainHour = new Chain(tHour)
const chainMinute = new Chain(tMinute)
chainDay.setNext(chainHour)
chainHour.setNext(chainMinute)
chainDay.passRequest(360000) // 6 分钟前如果需要添加一个小于1分钟时输出"刚刚"
function tNow(time) {
const STAMP_IN_MINUTE = 60 * 1000
if (time < STAMP_IN_MINUTE) {
console.log('刚刚')
} else {
return 'next'
}
}
chainMinute.setNext(tNow)职责链模式降低了代码的耦合度,简化对象,并且使得新增处理类更加便捷。但是不能保证请求一定会被接收者处理,不便于调试。
请求以命令的方式包裹在对象中 Command,并传递给调用者 Receiver。调用对象寻找可以处理该命令的合适对象 Invoker,并把该命令传给相应的对象,该对象执行命令。
function setCommand(button, command) {
button.onclick = function() {
command.excute()
}
}interface Command {
excute() {}
}
class AddCommand implements Command {
constructor(receiver) {
this.receiver = reciever
}
excute() {
this.receiver.add()
}
}
class DelCommand implements Command {
constructor(receiver) {
this.receiver = reciever
}
excute() {
this.receiver.del()
}
}
class RefreshCommand implements Command {
constructor(receiver) {
this.receiver = reciever
}
excute() {
this.receiver.refresh()
}
}
const menu = {
add() {
console.log('add')
},
del() {
console.log('del')
},
refresh() {
console.log('refresh')
}
}
setCommand(button1, new AddCommand(menu))
setCommand(button2, new DelCommand(menu))
setCommand(button3, new RefreshCommand(menu))备忘录模式即在不破坏封装性的情况下,捕获对象的状态,并保存对象外,以便在适当的时候恢复对象。
编辑器内容恢复 DEMO 实现
实现需要保存的对象状态 Memento
class Memento {
private content: string
constructor(content) {
this.content = content
}
getContent() {
return this.content
}
}实现备忘录列表 CareTaker
class CareTaker {
private list: []Memento = []
public add(memento Memento): number {
return this.list.push(memento)
}
public get(index: number): Memento {
this.list[index]
}
public getList(): []Memento {
return this.list
}
}实现编辑器对象 Editor
type EditorContent = string|null
class Editor {
private content: EditorContent = null
setContent(content: EditorContent) {
this.content = content
}
getContent(): EditorContent {
return this.content
}
saveContentToMemento() {
return new Memento(this.content)
}
getContentFromMemento(m: Memento) {
this.content = m.getContent()
}
}实际应用DEMO
const editor = new Editor()
const careTaker = new CareTaker()
editor.setContent('111')
editor.setContent('223')
// 保存223
careTaker.add(editor.saveContentToMemento())
editor.setContent('333')
// 保存 333
careTaker.add(editor.saveContentToMemento())
// 恢复到223
editor.getContentFromMemento(careTaker.get(0))备忘录模式为用户提供了一个可恢复的机制,实现了信息的封装。但是由于需要外部存储备忘信息,成员变量过多,会消耗较多的资源。
解释器提供了评估语言语法和表达式的方式。给定一个语言,定义其文法表示,并定义一个解释器。
实现表达式类
interface Expression {
interpret: (context: string) => boolean
}
class TerminalExpression implements Expression {
private data: string
constructor(data: string) {
this.data = data
}
interpret(context): boolean {
if (context.indexOf(this.data)) {
return true
}
return false
}
}
class OrExpression implements Expression {
private expr1: Expression = null
private expr2: Expression = null
constructor(expr1: Expression, expr2: Expression) {
this.expr1 = expr1
this.expr2 = expr2
}
interpret(context: string): boolean {
return this.expr1.interpret(context) || this.expr2.interpret(context)
}
}
class AndExpression implements Expression {
private expr1: Expression = null
private expr2: Expression = null
constructor(expr1: Expression, expr2: Expression) {
this.expr1 = expr1
this.expr2 = expr2
}
interpret(context: string): boolean {
return this.expr1.interpret(context) && this.expr2.interpret(context)
}
}使用DEMO
const robert = new TerminalExpression("Robert");
const john = new TerminalExpression("John");
const male = new OrExpression(robert, john);
male.interpret("John") // true迭代器模式用于顺序访问集合对象的元素。
class Iterator {
constructor(itObj) {
this.obj = itObj
this.current = 0
this.len = itObj.length
}
next() {
if (this.current < this.len) {
this.current++
}
}
getCurrent() {
return this.obj[this.current]
}
isDone(): boolean {
return this.len <= this.current
}
}
const iter = new Iterator([1, 2, 3])
iter.getCurrent() // 1
iter.next()
iter.getCurrent() // 2中介模式提供一个中介类来降低多个对象和类之间的通信复杂性。该类通常处理不同类之间的通信,降低复杂度易于维护。
实现聊天室DEMO
class User {
private name: string
constructor(name: string) {
this.name = name
}
getName(): string {
return this.name
}
setName(name: string) {
this.name = name
}
sendMessage(msg: string) {
ChatRoom.showMessage(this, msg)
}
}
class ChatRoom {
showMessage(user: User, msg: string) {
console.log(`${new Date().toString()} [${user.getName()}]: ${msg}`)
}
}使用
const bob = new User('bob')
const jason = new User('jason')
bob.sendMessage('Hi, jason')
jason.sendMessage('Hellow, bob')定义对象之间一对多的依赖关系,当被观察者发生变化时,所有依赖于它的对象都得到通知并更新。
关键代码实现:在抽象类里有一个 list 存放观察者们
interface Observer {
update: (msg: string) => void;
}
class AObserver implements Observer {
update(msg: string) {
// 操作
}
}
class BObserver implements Observer {
update(msg: string) {
// 操作
}
}
class CObserver implements Observer {
update(msg: string) {
// 操作
}
}class Subject {
private list: []Observer = []
setMessage(msg: string) {
notifyAll(msg)
}
addDep(obs: Observer) {
this.list.push(obs)
}
notifyAll(msg: string) {
this.list.forEach((obs) => {
obs.update(msg)
})
}
}const sub = new Subject()
const ao = new AObserver()
const bo = new BObserver()
const co = new CObserver()
sub.addDep(ao)
sub.addDep(bo)
sub.addDep(co)
sub.setMessage('receive msg')观察者模式下观察者和被观察者是抽象耦合的,他们之间建立了一种触发机制。如果一个观察者有多个被观察者的话,通知所有观察者会耗费很多时间。同步状态下,某个观察者失败会导致后续全部失败。
状态模式下,类的行为是基于它状态改变的。消除基于状态的 if-else 判断语句。
interface State {
open: (ctx: Context) => void
close: (ctx: Context) => void
}
class OpenState implements State {
open() {}
close(ctx: Context) {
ctx.setState(new CloseState())
console.log('close')
}
}
class CloseState implements State {
open(ctx: Context) {
ctx.setState(new OpenState())
console.log('open')
}
close() {}
}
class Context {
private state: State
setState(state: State) {
this.state = state
}
getState(): State {
return this.state
}
open() {
this.getState().open(this)
}
close() {
this.getState().close(this)
}
}
const context = new Context()
// 初始设置为开始
context.setState(new OpenState())
// 切换为关闭
context.close()
// 切换为打开
context.open()状态模式根据对象的状态创建不同的类,与命令模式类似都可以消除 if-else 等条件分支语句
策略模式中创建表示各种策略的对象,各个策略对象可以相互替换。
计算策略DEMO:
interface Strategy {
op: (num1: number, num2: number) => number
}
class Plus implements Strategy {
op(num1: number, num2: number):number {
return num1 + num2
}
}
class Multi implements Strategy {
op(num1: number, num2: number):number {
return num1 * num2
}
}
class Minus implements Strategy {
op(num1: number, num2: number):number {
return num1 - num2
}
}
class Context {
private strategy: Strategy
constructor(st: Strategy) {
this.strategy = new st()
}
exec(num1: number, num2: number) {
this.strategy.op(num1, num2)
}
}
cxt1 = new Context(Plus)
ctx2 = new Context(Multi)
ctx3 = new Context(Minus)
ctx1.exec(3, 2) // 5
ctx2.exec(3, 2) // 6
ctx3.exec(3, 2) // 1访问者模式通过在被访问的类中对外提供接待访问者的接口,实现访问者修改元素类的执行。
关键实现:在数据基础类里面有一个方法接受访问者,将自身引用传入访问者。
class Visitor {
visit(concreteObj) {
concreteObj.log()
}
}
class ConcreteClass {
log() {
console.log('This is a concrete object')
}
accept(visitor: Visitor) {
visitor.visit(this)
}
}
const vis = new Visitor()
const cc = new ConcreteClass()
cc.accept(vis)《见识》这本书是吴军博士在得到专栏《硅谷来信》中的整理以及补充部分。由于我已经订阅了他的另一期专栏《吴军的Google方法论》,对于吴军博士看待事情,解决问题以及思考的方式由衷的钦佩。在这本书中他提出 与其他外部资源或者个人因素相比,个人的成就首先取决于“见识”。
这让我想起鲁迅先生在《人话》里面说的一段话:
是大热天的正午,一个农妇做事做得正苦,忽而叹道:"皇后娘娘真不知道多么快活。这时还不是在床上睡午觉,醒过来的时候,就叫道:拿个柿饼来"
鲁迅先生的文笔一致都是那么简洁干练。
《见识》这本书中,吴军博士将自己身边的经历,以及身边那些时代领航者的经验,以一种睿智的方式阐述出来,为你提供一个与众不同的看待世界,思考问题的视角。不仅谈及工作,更是对生活、学习、人生道路、个人修养的一次全方位的思维盛宴。
幸福是目的,成功是手段。
1)拒绝伪工作
效率的高低不在于你开始了多少事情,而在于你完成了多少事情。很多事情看上去很重要,很紧急,其实真的没有那么的重要,大多数情况下人都在完成一些伪工作或者称之为尝试性工作。因此,开展一个新的工作需要认真思考确认它的必要性
2)少做选择
少做选择最好的方法就是减少可选项。很多时候我们把大多数经历花费在了选择上而不是经营以及提升。大多数时候专心把2件事情做到100%永远比分心做10件事情到80%带来的价值更大。
”吾生也有涯,而知也无涯“,这是庄子在《养生主》中的一段话,大意是生命是短暂的,而知识是无限的,庄子的哲学观”至知/无知“,是对学习的一种思考,同样适用于做事情。
3)做人同样也要作诗
人之所以为人而不可取代,在于复杂的情绪,丰富的创造力以及无法琢磨的艺术及想象力。
很多时候人的成败与否取决于见识的高低,而不是简单的努力。互联网的发展让我们增长见识的门槛以及变得极低,但在我们心中任然有一道围墙阻隔了我们的见识。
1)你和天才之间的差距
凡天才必有过人之处。事实上每个人都有自己的天赋,记忆力好,善于思考,善于侃谈等等。很多东西无法用很具体的数字去衡量,于是有人发明了IQ、EQ、AQ、MQ、DQ等一大堆指标,就是因为人的天赋并不是全方位的,也不是单一的。但这些指标其实也并不准确,因为天赋是可以经过锻炼获得或者增长和的,因此也无法知道一个人的天赋到底是后天还是先天而生。事实上经过这么多年,无数科学家研究还是没有发现爱因斯坦的大脑跟平常人有什么打的区别。很多时候我们和他人的差距并不是在生理上,而是其他方面,比如知识积累,认知,见识,勇气,方法论上。所以学习他们的做事和思考问题的方法这是我们可以做到的。
2)论起跑线
父母常常有一句话一致挂在嘴边:”不能让孩子输在起跑线上“。为此现在**的小孩儿,每天都在疲于学习各种各样的新东西。但是其实无论怎么样,在一个群体里面,就某个方面的能力做排名,总会有一个先后顺序,有人好有人差。况且,人的一生是一个漫长的赛道,需要练习的应该是如何在这条赛道上一直坚持下去,而不是如何在起步的时候超过别人。
家长总想着给自己的孩子创造最好的条件,就好比马拉松比赛中,孩子摔倒了,你立马上去扶起来,又是检查又是关心安慰。但总有一个时候,他跑出了你的视线,摔倒了,可能就永远爬不起来了。
3)比贫穷更可怕的
应该承认的一个事实是,贫穷带来的毛病确实存在,小时候的贫穷和将来的发展不顺利确实有很大的相关性。但是相关并不能构成因果关系。因此找到贫穷影响发展的根本原因,那么即便是小时候贫穷,将来一样有机会,相反也是成立。一般来说诸事不顺之人都有诸多毛病:
1)缺乏见识
”夏虫不可语冰,曲士不可语道“。对于见识上没有什么长进,认知不在一个水平线的人。尽量不要与之多费口舌,更不要争论。
2)缺乏爱
经常会有人说某某人小家子,难成大事。比如曹操评价袁绍”色厉胆薄,好谋无断,干大事而惜身,见小利而忘命“。缺乏关爱的人往往也难懂得关爱他人,现在很多小孩从小就没有把好东西分享给人的习惯或者说没人可分享,父母基本忙于工作很少与之交流,而长辈对他又是有求必应。以致于长大之后特别的小家子气。目前的**社会很难说因为贫穷而造成生存或者说温饱的问题,大多数情况下都是社会关系和家庭关系的问题。
3)缺乏规矩
现在很多新闻报道”熊孩子“,”熊老人“的问题,这些人的特点就是“缺乏规矩”。其实并不能用好坏去评判他们,也并不是因为他们没有常识,因为在他们眼里他们所做的事情稀疏平常,没有一把尺子去衡量事情所造成的后果。这即是缺乏规矩。小时候缺乏规矩,长大了就很难有守规矩的习惯,如此以来就会给自己和别人带来更多的麻烦。
鲁迅先生讲人”一要生存,二要温饱,三要发展;我之所谓生存,并不是苟活 ;所谓温保,并不是奢侈;所谓发展,也不是放纵“。金钱是对社会上绝大多数资源的所有权和使用权的一种标准量化,因此没有钱是万万不能的。但是对于金钱,需要有一个比较清晰的认识和考虑:
1)钱只有花出去才是自己的
2)钱或者任何东西都是为了让生活过的更好,而不是带来麻烦
3)钱是靠挣出来的,而非省出来的。但是一味的消耗无度,奢侈成性也是不可取。挣钱的效率取决于你的气度以及你对这个社会带来的价值。想要多挣钱就需要掌握一些大部分人都不会的技能,。
4)钱很难说花光,但是很容易消耗光。
但是世界上任何东西得到都是要付出代价的,钱也是如此。因此在获得这些东西之前,需要好好思考一下,他们带给你的生活上的提升还是麻烦的增加。
对于投资这件事情,其实绝大部分人甚至所有人都在参与,比如存银行,买房等等。绝大部分人,无论多有钱,总是希望自己能够用”钱“获取更多的回报,这就是投资的**。因此无论是否学习过投资相关的知识,都会身不由己的参与到各种投资中去。
除此之外,学习投资另一个作用就是帮助自己在生活中用一种理性的态度、量化的方法看待各种事情以及解决问题。
投资的三个基本问题
1) 投资的行为围绕目的进行。其实就是明确自己投资的目的是为了什么,财富的回报,还是资产的保值,了解资本市场或者仅仅是为了博取一个好的名头。除此之外,还需要定制一个合理的投资目标,一个不合理的投资选择可能让人倾家荡产。
比如每年拿出2万投资,每年通胀率大约3%左右,投资增长率每年8%。20年之后的财富积累按照投资时的物价计算大约可以达到 68.3万,扣除40万本金,大约有28.3万元的回报,但是投资并不是持续稳定增长的,如果在股市中遇跌导致投资率只有4%,那么投资回报就只剩4.3万元,还不如存在银行的增长。因此制定合理且可行的投资目标计划。
同样如果目标需要30年完成,投资计划也会有所改变。
2)投资工具
个人投资基本分为几个地方,刨除门槛较高的货币基金等基本包括一下几点:
大部分投资只关注两个点:风险和回报。一般规律是高风险高回报,但是也不一定完全正确。夏普比率是一个综合考量风险和回报的量化指标:
夏普比率 = (投资回报 - 无风险回报)/ 波动性的标准差
除此之外个人投资还要结合自身情况考虑:流动性和准入成本。流动性就是变现的能力,一般来说存款 > 股票 > 债券。如**房地产回报很高,但是流动性相对较差。准入成本即投资的人买东西需要交手续费。
3)投资的误区
4)合理分配自己的投资金额
语言能力是我们祖先现代智人区别于其他类人的最明显特征。通过讲话交流的水平很容易确认一个人能否成功。需要避免以下坑:
1)缺乏对听众的针对性 2)为了在有限时间内讲完跟多事情 3)哗众取宠,危言耸听
任何人讲话时都要确保自己传达的消息按时,准确的送达对方,而对方也确实明白了他的意思。同样作为接收方也一样,要确保自己确实理解了对方所要传达的意思。才能做到有效沟通。
如何讲理
并不是说气壮则理直,理直则声高。以理服人往往在于让对方明白他们自己的观点是错误的,而非是要压过对方。
如何服人
以理服人固然可以,但是真理很多时候并非大家认可的道理。很多时候我们只是提出了一个”理“,而不是完全证实了它,这是无法站住脚的。要想让人无法辩驳,看的见得事实是最有说服力的东西。
如何演讲
明确自己的听众是谁,他们想要从你这场演讲中获取什么信息。
明确自己需要传达的信息的层次结构或者时间轴或者树状图关联图等等
控制自己的演讲时间,人的专注力是会随着时间衰减的,在尽可能短的时间内讲清楚一个观点
JavaScript 的类继承是基于**原型继承。**类表达式类似于函数表达式,实际上就是一个“特殊的函数”。
接下来通过解析继承需要实现的功能一步步展示 JavaScript 实现继承的步骤,实现继承以下的父类:
function SuperType(name) {
this.name = name
this.hobbies = ['sing', 'dance', 'rap', 'basketball']
}
SuperType.prototype.sayName = function() {
console.log(this.name)
}
function SubType() {}通过在子类构造器中调用父类的构造方法继承
function SubType(name, englishName) {
SuperType.call(this, name)
this.englishName = englishName
}通过拷贝父类原型,指定构造器的方式构建新的原型对象。
const prototype = {
__proto__: {...SuperType.prototype},
constructor: subType
}
subType.prototype = prototypeSubType.prototype.sayEnglishName = function() {
console.log(this.englishName)
}这样就实现了一个基于原型的 JavaScript 类的通用继承。
const sbt = new SubType("菜虚鲲", "Green Virtual KarKen")
sbt.sayName() // 菜虚鲲由于东西方的大学发展历程不同。对于大多数东方人而言,大学是进入社会阶层必经之路,也是过去高收入,高地位的必不可少的途径和手段。**教育的发展历程从隋代开始实行科举考试制度,就已经和社会地位升官发财紧密联系在一起了。这种观点在**这片土地上延续了几千年,到现在为止很多人还是会把上大学,考试成绩和社会地位联系起来。
对于大多数西方人而言,上大学意味着学习一些需要高度专业的技能和知识,从事一些比较专业的职业,比如医生,律师,园艺工人,工程师等等。其他情况则没有很强的上大学意愿。
西方的大学起源其实和**孔子时期有些类似,起初是由一些智者,学者带领一群学生,如毕达哥拉斯。组成的一个团体,受到领主的保护,拥有言论约束自由的权利,免于教会或者是领主的管辖。拥有高度的自由权。西方大学的起源源于罗马神权时期的一份签署文件,里面规定:
1)大学人员拥有与神职人员同等的自由权和豁免权
2)拥有为了学习的目的自由迁徙的权利3)免于因为学术观点而遭受报复
4)有权要求学校和教会裁决而不是地方政府。
这一份文件给与了学者高度的学术和言论自由权。西方大学的初衷本就是为了学习神学和自然科学知识,而非为了升官发财。同样这种**也延续了成百上千年。
学生上大学除了学习知识之外,主要是为了认识更多志同道合的人,彼此互相交流学习,彼此成为朋友。 不能被局限于某个具体的问题和具体的专业里面,需要有广泛的知识,独到的见解。培养服务于社会的通识型人才。
纽曼式的教育对学生和学校的要求都非常高,需要学生有充分的自主学习能力,沟通能力,自我管理能力。同样的需要学校有足够广泛的资源,足够的课程满足学生多样化的需求。
专才教育,强调专业化职业化的教学方式和十分精深的技能教学自己实践条件。强调大学就需要学习,毕业之后马上就能为社会服务在某个行业和领域做出贡献,创造价值。这种教学理念为工业革命时期的西方国家提供了大批的专业化的优秀人才。加速了工业化的进程。
现代顶尖的大学多是按照这两种教学理念办学。去麻省理工属于专才教育,哈弗商学院属于通才教学。但是无论是通才还是专才,大学里面开设的课程很多都是与专业与工作无关的,这说明大学生活本身和高等教育同样重要,在大学中无论你学习的什么课程,只要学的东西足够多,时间足够长,学习深度足够深,那就是受到教育。就如同通才教育的理念,在大学里,和一群足够聪明,求知欲足够强,具有同情心的人聚在一起,就算是没有人教也能相互学习,孔子亦言三人行必有我师。所以大可不必纠结于教育形式,只要本着学习的态度上完大学,那大学本身就是很好的教育。
**【终身教职】**为了实现学术自由。
【教授治校】 全面**管理,管理小事,无法跨系。
【校董管理】 解决学校层次的问题,解决资金问题,重大事物决策,对外联系。如选校长,学校发展规划。
原文地址:https://itnext.io/ast-for-javascript-developers-3e79aeb08343
文长;慎读。这片文章是我最近一次在 Stockholm 的 ReactJS 分享会中的演讲。你可以在下面地址中查看对应的 PPT:
https://www.slideshare.net/BohdanLiashenko/ast-for-javascript-developers
AST Abstract Syntax Tree 抽象语法树
如果你检查任何现代项目的 devDependencies 结构,你会看到它在近几年增长了很多很多。这里我罗列了以下几组工具:JavaScript 转换,代码压缩,CSS 预处理,eslint,pretitter 等等。这些 JavaScript 模块我们都不会发布到生产环境,但是他们在我们生产进程中扮演着极其重要的角色。所有的这些工具都是通过某种方式处理 AST 构建实现的。
我有一个演讲计划。从“什么是 AST 以及如何从普通的代码构建它” 开始讲起。然后,我会略微触及一些基于 AST 处理程序的构建的最流行的用例和工具。然后,我打算以我自己的项目 js2flowchart 结束演讲,这是一个使用 AST 构建的优秀的示例。那么,和我一起开始吧。
它是一种分级的程序展示根据程序语言的语法呈现编码结构,每一个
AST节点都对应到源码中的一条。
那么好的,让我们看一下它在示例中的具体表现。
非常的简单,但这是最主要的**。从纯文本中,我们得到了一个类似树形的数据结构。
怎么从普通文本代码生成 AST 数据结构?当然,我们知道编译器已经可以做到了。让我们来开一下一个普通编译器的运行。
幸运的是,我们不需要经历所有阶段,将高级语言代码转换到位运算。我们只对词法和语法分析感兴趣。这两个步骤在根据代码生成 AST 结构时扮演者重要的角色。
词法分析,也被称之为扫描器。它读取我们代码的字符流,并使用定义好的规则将他们转换成 令牌。此外,它还会删除空格,注释等等。最后,整串代码会被分割成一个 令牌 列表。
当词法分析器读取源代码时,它会逐个字符的扫描代码。当它遇到空格,操作符或者特殊字符时,它将决定一个单词完成。
语法分析,也被称之为解析器。将会在词法分析之后获取一个简单的 令牌 列表并且将其转换成树形结构表示。验证程序语言语法,如果发生错误则抛出语法错误。
在生成树形数据结构时,一些解析器会省略掉部分 令牌(比如说冗余的括号)所以他们创建的 AST 并不是 100% 与代码匹配,但足以知道如何正确处理代码。另一方面,完全覆盖所有代码结构的解析器生成的树被称之为 “具体语法树(Concrete Syntax Tree)”
The-super-tiny-compiler。你可以从这个仓库入手研究。它是一个用 JavaScript 写的一个编译器的所有主要部分的超简单示例。它有总共 200 行实际代码(除去注释等),背后的**是将 Lisp 语法转换成 C 语言。所有的代码都包含注释和解释。
LangSandbox。另一个更棒的项目。它演示了如何构建一门编程语言。还提供了一个文章或者书籍列表解释如何去做(如果你感兴趣)。因此,它的知识会更深入一点。因为在这个项目你可以编写你自己的语言并转换成 C/字节编码并在转换之后执行,而不是仅仅是将 Lisp 转换成 C(就像上一个例子中一样)。
我可以使用一个第三方库吗?当然,有非常丰富的第三方库资源。你可以访问 AST explorer 选择一个你喜欢的库。还附带有一个在实时编辑器你可以使用其中的 AST 解析器。除了 JavaScript 外,还包含许多其他语言。
我想特别的强调他们中的一个。在我看来,这是一个非常棒的库,被称为 Babylon。
Babylon 被使用在 Babel 中,这也许也是他受欢迎的原因。因为它背靠 Babel 项目,你可以预见它会一直与最新的 JS 特性保持同步,我们在过去的几年经常这样。因此,当你使用新的东西比如“异步迭代”(无论什么),解析器不会展示 “Unexpected token”的错误。此外,它还有相当好的 API 而且通常易于使用。
好了,你现在知道如何为代码生成 AST 了。让我们继续讨论真实的用例。
第一个我想讨论的用例是代码转换,显然,使用 Babel 完成这个用例。
Babel 不是一个 “拥有 ES6 支持的工具”。嗯,确实是一个 ES6 工具,但是 Babel 的意义远不只此。
许多人将 Babel 和 ES 6/7/8 的特性联系到一起。同样,事实上这也是我们经常会使用它的原因。但是它只是一组插件。我们也可以将它用作代码压缩,React 相关的语法转换(比如JSX),Flow 的插件等等。
Babel 是一个 JS 编译器。在顶层设计上,他有三个阶段,执行代码:解析,转换和生成。你向 Babel 输入一些 JavaScript 代码,它修改这些代码并且生成新的代码返回。那它如何修改这些代码呢?准确的讲!它构建 AST 结构,然后遍历 AST,根据应用的插件修改它,然后从修改后的 AST 结构生成新的代码。
让我们在一个简单的代码例子中来查看一下:
就像我之前提到的,Babel 使用 Babylon 库,因此,第一件事先解析代码,然后遍历 AST 并翻转所有变量名称。最后一步生成代码。完成。如你所见,第一步(解析)和第三步(代码生成)看起来非常具有普适性,这是你每次都会去做的操作。所以,Babel 会关注这两步,因为你唯一真正感兴趣的是,AST 转换。
当你开发 Babel 插件时,你只需要描述会转换你 AST 结构的节点 “访客”。
添加到 Babel 插件列表中,在 Webpack 配置中设置 babel-loader
如果你想了解更多关于如何构建你的第一个 Babel 插件的信息,你可能需要查看 Babel 手册。
继续,接下来的用例,我想提一下自动化代码和 JSCodeshift
假设你想使用简短且漂亮的箭头函数替换所有过时的匿名函数。
你的代码编辑器很有可能无法做到这一点。因为这不是简单的查找-替换操作。这就是 jscodeshift 发挥作用的地方。
如果你听说过 jscodeshift, 你很有可能和 codemods 一起听到。这可能会让你第一时间赶到困惑。 JScodeshift 是一个运行 codemods 的工具包。一个 codemod 表示一段具体描述对 AST 进行那种转换的代码。所以,这个**和 Babel 和他的插件非常相似。
所以,如果你想创建一个“自动化方式”迁移你的代码库到新的框架版本,这是一个方法。例如,以下是 react 16 属性类型重构:
试试看,有许多不通的 codemodes 已经被创建。你可以通过不需要手动操作来节省你的时间。
https://github.com/facebook/jscodeshift
https://github.com/reactjs/react-codemod
最后一个我想略微提及的案例是 Prettier,因为可能每个人都在日常工作中使用它。
Prettier 格式化我们的代码。它会使长代码换行,清理空格,括号等等。因此它接收代码作为输入并返回修改后的代码输出。听起来很熟悉是吧?
**还是一样的。首先,接收代码生成 AST。然后 pettier 魔法开始生效,AST 会被转换成 中介码(IR) 或者 文档。在顶层,AST 节点将会被扩展他们在格式化方面如何相互关联的信息。例如,函数的参数列表应该被视为一组项。因此,如果这个列表足够长并且不适合一行展示,将每个参数分割成单独的一行等。然后,主要的算法被称之为 “printer”,它将通过 LLVM IR 并给予整个 图片决定如何格式化代码。
再说一句,如果你要学习更多关于美化输出背后的理论,推荐可以深入阅读的书籍http://homepages.inf.ed.ac.uk/wadler/papers/prettier/prettier.pdf
继续往下,今天我想分享的最后一个东西是我自己的代码库名字是js2flowchart
这是一个很好的例子,因为它告诉你,当你有 AST 代码表达式时你可以做任何你想做的事情。没必要将它放回源码字符串中,你可以绘制他的一个流程图。
用例是什么呢?你可以通过流程图解释或者文档化你的代码,通过视觉理解学习其他代码,为通过有效 JS 语法简单描述的任何进程创建流程图。
现在尝试它的最简单的办法——使用实时编辑器
试试看。你也可以在代码中使用它或者他也提供了 CLI 工具,因此你可以仅指向你想要的每个文件生成 SVG 文件。此外,还有 VS Code 扩展(在 README 的链接中)。
那么,它还能做些什么呢?首先,除了生成所有代码的大体系之外,你还可以指定抽象级别的详细体系应当如何。
这意味着,例如你可以只绘制出哪个导出模块,或者只绘制类定义,或者函数定义和他们的调用。然后你可以生成一个演示,其中每一条都深入细节。
还有一大堆方便的工具可以修改树。例如,看一下 .forEach 方法调用,仅仅是方法调用,但是我们能指定它们应该被视为循环,因为我们知道 .forEach 就是一个循环,所以我们就让它以一个循环的方式正确渲染。
好吧,它是如何在引擎下工作的
第一件事,将代码解析成 AST,然后遍历 AST 并生成另一棵树,我称之为FlowTree。它省略了许多小的,不重要的 tokens,但将关键的代码块放在一起,比如 函数,循环,条件等。
之后,我们遍历 FlowTree 并根据它创建 ShapesTree。ShapesTree 的每个节点都包含有关其在树中的可视类型,定位,连接的信息。最后一步,遍历所有形状并为每个形状生成 SVG 表示,将所有形状组合成一个 SVG 文件。
在此处查看https://github.com/Bogdan-Lyashenko/js-code-to-svg-flowchart
JavaScript 的执行是单线程这是总所周知的事情,“单线程” 即每次只能完成一件任务,多个任务要依次完成,前面的必须处理完成之后,后面的才开始处理。
单线程的优点就是简单,稳定,容易维护,而且容易处理同步任务。但是对于文件读写等耗时较长的任务,应用程序可能会卡死。为了解决这个问题 JavaScript 语言将任务的执行模式分为两种:同步(Synchronous)和异步(Asynchronous)。
异步对于 JavaScript 应用程序来说尤为重要。JavaScript 执行环境是单线程的,但是整个浏览器的运行环境是多线程多进程的。在 JavaScript 引擎执行过程中会有另外的异步线程去处理异步程序。例如事件触发线程,HTTP 请求线程等。
下面总结了几种常见的 JavaScript 处理异步的编程的模式:
function fn1(callback) {
setTimeout(() => {
callback('timeout')
}, 200)
}
function fn2(message) {
console.log(message)
}
fn1(fn2)
使用这种方案 fn1 并不会阻塞程序运行,延迟执行 fn2。回调的方案比较简单、容易理解。但是函数调用比较混乱不容易维护,甚至易出现回调地狱
Promise 以 pending、fulfilled、rejected 三种状态来管理异步操作,并收集异步结果值。
const promise = new Promsie(function executor(resolve, reject) {
setTimeout(() => {
resolve(300)
}, 300)
})
promise.then((number) => {
console.log(number) //300
})
executor 中使用resolve 和 reject 处理成功和失败的状态,分别将 Promise 的状态改为 fullfilled 和 rejected ,如果 executor 中程序抛出错误,同样 rejected
除此之外 Promise 提供了处理多个 Promise 封装成一个 Promise 的语法。Promise.all 和 Promise.race
Promise.all 接受一个 Promise 数组( 如果不是Promise 则使用 Promise.resolve 包装一下),在数组所有的 Promise 结束之后执行 then 或者 catch 的回调。数组中只要有一个 Promise 状态为 rejected,则这个组合的 Promise 执行状态为 rejected。
如果数组内的 Promise 定义了 调用了catch,则返回一个新的 resolved Promise,Promise.all 不会再触发catch
const p1 = new Promise((resolve) => {
setTimeout(() => {
resolve('p1')
}, 100)
})
const p2 = new Promise((resolve, reject) => {
setTimeout(() => {
reject('p2')
}, 200)
})
const p3 = new Promise((resolve) => {
setTimeout(() => {
resolve('p3')
}, 300)
})
const p4 = new Promise((resolve, reject) => {
setTimeout(() => {
reject('p4')
}, 400)
}).catch(() => {
return 'p4e'
})
Promise.all([p1, p2, p3]).then((value) => {
console.log(value)
}).catch((value) => {
console.log(value) // p2
})
Promise.all([p1, p4, p3]).then((value) => {
console.log(value) // ['p1', 'p4e', 'p3']
}).catch((value) => {
console.log(value)
})
Promise.race Promise.race 和 Promise.all 一样,但是 Promise.race 中任意一个 reject 或者 resolve 都会调用 Promise 集合的相应回调,同时修改父 Promise 的状态。
const p1 = new Promise((resolve) => {
setTimeout(() => {
resolve('p1')
}, 100)
})
const p2 = new Promise((resolve, reject) => {
setTimeout(() => {
reject('p2')
}, 200)
})
const p3 = new Promise((resolve) => {
setTimeout(() => {
resolve('p3')
}, 300)
})
const p4 = new Promise((resolve, reject) => {
setTimeout(() => {
reject('p4')
}, 400)
}).catch(() => {
return 'p4e'
})
Promise.race([p1, p2, p3]).then((val1) => {
console.log(val1) // p1
}).catch((value) => {
console.log(value)
})
Promise.race([p1, p4, p3]).then((value) => {
console.log(value) // p1
}).catch((value) => {
console.log(value)
})
ES6 的异步编程解决方案,写法与传统函数有所差异。使用 function* 进行声明,指定为 generator 函数。调用该函数并不会直接执行,也不会返回值
function* 进行声明,指定为 generator 函数{ value: any, done: boolean } 结构的对象。当 done = true 的时候表示遍历结束 function* gen() {
yield 'y1'
yield 'y2'
return 'y3'
}
const g = gen()
g.next() // {value: "y1", done: false}
g.next() // {value: "y2", done: false}
g.next() // {value: "y3", done: true}
g.next() // {value: undefined, done: true}
setTimeout(() => {
g.next()
}, 1000)
function* gen1(x) {
const a = yield x / 3
const b = yield a * 2
const c = yield a + b + x
return 'y3'
}
const g1 = gen1(6)
g1.next() // {value: 2, done: false}
g1.next(4) // {value: 8, done: false}
g1.next(8) // {value: 18, done: true}
g1.next() // {value: 'y3', done: true}
g1.next() // {value: undefined, done: true}
Generator 应用
function run(fn) {
const gen = fn()
const next = (cb) => {
const result = gen.next(cb)
if (result.done) {
return
}
result.value().then(next)
}
next()
}
function p1() {
return new Promise((resolve) => {
setTimeout(() => {
resolve(111)
}, 100)
})
}
function p2() {
return new Promise((resolve) => {
setTimeout(() => {
resolve(121)
}, 200)
})
}
function* pGen() {
const r1 = yield p1;
const r2 = yield p2;
console.log(r1, r2)
}
run(pGen)
async / await 是 es2017 的标准,使用同步的方式书写异步调用。
async function async1() {
const a = await new Promise((resolve) => {
setTimeout(() => { resolve(222) }, 200)
})
return a
}
// 错误处理
async function async0() {
try {
const a = await new Promise(() => {
throw new Error('error message')
})
return a
} catch(err) {
console.log(err)
}
}
async function async2() {
const a1 = await async1()
const a2 = a1 + 33
console.log(a2)
}
async1().then((val) => {console.log(val)}) // 222
async2() //255
async0().then((val) => {console.log('resolve: ', val) }) // resolve: undefinedhttps://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/Generator
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/Promise
https://developer.mozilla.org/zh-CN/docs/learn/JavaScript/%E5%BC%82%E6%AD%A5/Async_await
ES6 引入了一种新的函数表达式,即箭头函数表达式。箭头函数的语法比一般的函数表达式更加纯粹和简洁,同时在表现和使用上也和普通函数有所差异。
// 一般用法
const arrow1 = (a, b, c) => { console.log(a) }
// 省略表达式括号表示直接返回结果
const arrow2 = (a, b, c) => a + b + c
// 单一参数可以不使用 ()
const arrow3 = a => a * 2
// 无参数直接使用()
const arrow4 = () => 15初次之外箭头函数与普通函数一样,支持默认参数,参数解构赋值等。
箭头函数不会创建自己的this,它只会从自己的作用域链的上一层继承this
箭头函数会捕获定义阶段所处的外层环境的 this 值,并保持不变。
const func1 = () => {
console.log(this)
}
function func2() {
(() => {
console.log(this)
})()
}
const obj = {
name: 'n',
func1: func1,
func2: func2,
func3() {
(() => {
console.log(this)
})()
}
}
func1() // window 对象
func2() // window 对象
obj.func1() // window 对象
obj.func2() // obj 对象
obj.func3() // obj 对象由于箭头函数没有 this 指针,通过 call, apply, bind 之类的方法绑定作用域只能传递参数,不能绑定 this。第一个参数会被忽略。
const obj = {
name: 'bob',
sayName(a) {
function f(v) { return v + this.name }
let b = {
name: 'henli'
}
return f.call(b, a)
},
sayNameWithArrowFunction(a) {
let f = v => v + this.name
let b = {
name: 'henli'
}
return f.call(b, a)
}
}
obj.sayName('hello ') // 输出 hello henli
obj.sayNameWithArrowFunction('hello ') // 输出 hello bob箭头函数不绑定 arguments,因此无法通过 arguments 这种方式获取到函数的参数。由于 this 作用域的关系,arguments 或获取到作用域链上对应的作用域下的 arguments
function func() {
// 这里的 arguments 会获取到外层函数的 arguments
const f = () => arguments[0]
return f()
}
func('haha') // haha箭头函数没有原型。
let Foo = () => {}
Foo.prototype // undefined箭头函数不能用作构造器,因此不能使用 new 关键字实例化箭头函数,也不能用作类。
let Foo = () => {}
new Foo() // TypeError: Foo is not a constructoryield 不能使用在箭头函数中,除非在生成器函数中定义的箭头函数。箭头函数本身不能作为生成器函数。
function* gen(index) {
yield (() => index ++ )()
yield index ++
yield index ++
}
g = gen(12)
g.next() // {value: 12, done: false}
g.next() // {value: 13, done: false}
g.next() // {value: 14, done: false}除了上面的一些细节点之外,箭头函数还有一些写法上的细节点,比如换行、返回对象字面量等,需要多运用才会更加熟练。
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Functions/Arrow_functions
https://juejin.im/post/5c979300e51d456f49110bf0
正则表达式的要诀。找规律,划边界,定区域,写规则。
\ 转义字符。将下一个字符标记为特殊符、原字符、进制字符等。
\n表示换行符;\t表示水平制表符;\1表示匹配上一个括号组
^ 开始位置。匹配输入字符串开始位置。 ^[0-9] 匹配数字开始
$ 结束位置。匹配输入字符串结束位置。[0-9]$ 匹配数字结束
*匹配前面的字符多次或者0次,等价于
{0,}。[0-9]* 匹配任意数字。
+匹配前面的字符多次或者一次,等价于
{1,}。 [0-9]+ 匹配一个数字以上。
?匹配前面的表达式 0 次或者 1 次,等价于
{0,1}。 .jpe?g 匹配 jpg 或者 jpeg
{n} 匹配 n 次,n ≥ 0 | [0-9]{2} 匹配两个连续数字。{n,}匹配 n 次及以上,n ≥ 0 | [0-9]{2,}。匹配两个及以上连续数字。
{n,m}匹配 n 到 m 次,n ≤ m [0-9]{1,3} 匹配一个到三个数字
(*,+,?,{n},{n,},{n,m}) + ?。 限制匹配+?对前面的限制字符串指定非贪婪模式。| 尽可能少的匹配,如[0-9]+? 匹配一个数字
const str = 'A12sSDsas23'
str.match(/[0-9]+/g) // ["12", "23"]
str.match(/[0-9]+?/g) // ["1","2","2","3"].匹配除了
\n符之外的所有字符
(pattern)匹配并获取,可以从匹配到的 Matches 集合获取。Javascript 中可以通过 $1....$9 获取
/(a)(b)\1\2/.test('ab') // false
/(a)(b)\1\2/.test('abab') // true
'abab'.replace(/(a)(b)/g, '$2$1') //baba(?:pattern)非匹配获取。匹配
pattern但是不记住,不作为匹配捕获内容。
'abab'.replace(/(a)(?:b)/g, '$2$1') // $2a$2a(?=pattern)正向预查。从匹配到 pattern 开始处匹配查找字符串,即匹配 pattern 前面的内容。
'Win98'.match(/Win(?=2000|98)/g) // ['Win']
'98Win'.match(/(?=2000|98)Win/g) // null(?!pattern)正向否定预查。从任何不匹配pattern 的地方开始查找
(?<=pattern)反向预查。匹配 pattern 后面的内容
'Win98'.match(/Win(?<=2000|98)/g) // null
'98Win'.match(/(?<=2000|98)Win/g) //['Win'](?<!pattern)反向否定预查。
x|y选择匹配。匹配
x或者y
'a898c88z002j22'.match(/(a|z)[0-9]+/g) // ['a898', 'z002'][xyz] | [^xyz]匹配或者不匹配字符集合。
\b 单词边界匹配单词的边界,就是后面和前面没有有效的”字“字符。
'esdsasffserscsaer'.match(/[a-z]{4}(?=er\b)/) // ['scsa']\B 非单词边界与
\b相反
\cX 匹配由 X 指定的控制字符。如 \cM 匹配Control-M或回车符
\d 数字字符。等价于 [0-9]
\D 非数字字符。等价于 [^0-9]
\f 分页符。等价于 \cL
\n 换行符。等价于 \cJ
\r 回车符。等价于 \cM
\t 水平制表符。等价于 \cl
\v 垂直制表符。等价于 \cK
\s 任何空白字符。等价于 [\f\n\r\t\v]
\S 任何非空白字符。
\w 单词字符,包括下划线。等价于 [a-z0-9A-Z_]
\W 非单词字符
\Xn 匹配十六进制 n
\num 对获取匹配的引用。如 \1 表示 $1
\u 匹配 unicode 字符。如 \u00A9 匹配 ©
#24252C, #F8F9E1^#[a-fA-F0-9]{6}$
^https?/:\/\/[\da-z]+.^[\u2E80-\u9FFF]$\w[-\w.+]*@([a-zA-Z0-9][-a-zA-Z0-9]+\.)+[a-zA-Z]{2,14}
^1[1-9][0-9]{9}$
hh:mm:ss[0-1]?\d|2[0-3]:[0-5]?\d:[0-5]?\d
关于安全的重要性就不赘述了。做一些关于XSS、CSRF、CSP的一些介绍和相关防护手段的总结和记录。理论上来说,所有发生在浏览器端,网页应用中的安全问题都算是“前端安全问题”。
XSS攻击即跨站脚本攻击(Cross-site scripting)属于注入型攻击,本质原因就是浏览器或者接收方相信了来自输入方注入的指令。
XSS 攻击具有比较大的破坏性,因为注入型的脚本执行在正常的上下文,可以获取到更高的权限,用来盗窃用户私密信息身份信息,修改页面,代替用户执行各种操作比如发消息、参与投票等等。
如何防御
针对 XSS 攻击常用的方法就是 对数据进行严格编码,过滤特殊字符串
如常见的评论信息:
const xssText = '<strong>我</strong>要发布一条带脚本的评论信息<script> alert("弹窗警告!!") </script>'
// 这样不经过过滤直接添加就会弹出警告框
const comment = dom.create('div', {
className: 'content',
innerHTML: xssText
})
//输出
// <div class="content"><strong>我</strong>要发布一条带脚本的评论信息<script> alert("弹窗警告!!") </script></div>
浏览器不会分辨<script> alert("弹窗警告!!") </script>是否是恶意代码,直接解析执行。
面对这种情况只需要对文本信息进行过滤编码处理能修复:
import xss from 'xss'
const comment = dom.create('div', {
className: 'content',
innerHTML: xss(xssText)
})
// 对 script 标签进行转译
// 输出
// <div class="content"><strong>我</strong>要发布一条带脚本的评论信息<script> alert("弹窗警告!!") </script></div>
当然,除了直接注入之外还有其他很多地方可以加以利用,实现注入代码,比如:
// 从URL 获取参数
http://www.xssattach.com?redirect_url=javascript:alert('xss')
const url = getParam('redirect_url')
<a href={`javascript:${url}`}>点击跳转</a>
location.href = `javscript:${url}`
setTimeout('alert("xss")')
setInterval('alert("xss")')
eval('alert("xss")')
需要完全避免或者预防 XSS 攻击需要注意一下几点:
1)输入过滤,不要完全相信用户输入的任何东西
2)前端渲染避免 innerHTML;如果是React/Vue 避免 使用v-html 和 dangerouslySetInnerHTML。动态 DOM 插入数据校验。
3)setTimeout、setInterval、eval 等方法避免执行动态脚本
4)href 标签、location.href 等数据校验
5)设置关键 cookie http-only 防止窃取 cookie 信息
6)关键路径使用验证码校验(如支付)
CSRF 攻击即跨站请求伪造(Cross-site request forgery)。本质即利用用户在已经登录的环境下,点击执行非本意的操作。简单说就是欺骗用户点击一个链接去访问自己曾经认证过的网站,并运行操作。
比如,你刚登录了工行网页查看余额,逛累了打开新页面看小说,然后收到一天弹窗消息告诉你中了100万,你点了进去,然后你的钱就被转走了。
假设工行的转账请求为:http://www.xxx.com/cash?from=11&to=111
那么恶意图片链接:<a href="http://www.xxx.com/cash?from=yourAccount&to=hackerAccount">中奖100万!!</a>
攻击者并没有获取你的任何信息,也没有获取你的账号控制权,只是利用你之前授权的信息,欺骗浏览器和服务,以你的名义操作。
一般来说 CSRF 攻击都是从一些不安全的第三方地址通过HTTP劫持的方式发起,如一些小说阅读、情色网站等。受害者在访问之前授权过被攻击网站的登录凭证。攻击者通过图片地址、超链接、表单等方式。
如何防御
1)检查 Referer 信息、Origin 同源检测;屏蔽不明来源的域名,增加Referrer Policy
在某些情况下,无法获取 Refeerer 如直接打开地址、HTTPS 跳转 HTTP、使用window.open等。
可以使用 CSRF Token 校验
2)token 验证
CSRF 的特点就是冒充用户,但是无法获取用户的详细信息。因此在访问页面的时候服务端生成一个加密的 token 放在 session 中避免被获取或者通过程序手动拼接 如http://www.xx.com/getname?token=*****
DNS劫持
DNS的作用就是将域名和真实的IP地址相互映射到一个分布式数据库中,使人更方便的访问网络。DNS劫持即域名解析劫持,在网络范围内拦截域名解析请求,分析请求的域名。用户访问一个正常的站点,可能返回恶意的钓鱼站点的IP地址,用户被劫持到恶意站点,然后被获取到各种账号密码信息。
这种问题一般发生在小范围呢,电脑中病毒被篡改路由器的DNS解析地址或者运营商和广告商勾结发送广告。
这种情况旧查看本机的DNS设置,运营商的问题就投诉。
HTTP劫持
HTTP劫持本质上就是访问网页经过不法运营商,被获取到请求内容并篡改内容,实现页面劫持。一般就是插入广告,或者设置钓鱼网站欺骗消费者。能实现这个根本原因就是因为HTTP无法对通信方的身份进行校验以及对数据进行校验。因此一般都是用SSL将传输内容加密防止篡改,即HTTPS
CSP 浏览器一个额外的安全层,用于检测并削弱一些特定类型的攻击。
主要减少和报告 XSS 的攻击,通过指定有效域减少或者消除 XSS 攻击所以依赖的脚本。CSP 配置完成后浏览器只会信任执行白名单获取的脚本文件。
CSP 使用一个新的HTTP协议头信息配置,即设置访问白名单,明确哪些资源可以加载执行,需要浏览器支持。配置方式跟普通一些头信息一样,也可以使用 meta 标签设置 http-equiv 配置。
CSP 的基本配置项如下:
default-src
script-src //外部脚本
style-src
img-src
media-src
font-src
object-src
child-src
referer
connect-src
worker-src
minifest-src
object-src
frame-src
使用 SSL 对传输信息进行非对称加密 查看【图解HTTPS】
https://tech.meituan.com/2018/09/27/fe-security.html
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/CSP
H5InNative方案不可避免在日常业务中使用,而且随着H5规范的日益完善,Webview引擎快速迭代发展使得h5的性能也逐渐的增强。通过两个方面阐述形成一个 hybrid 方案
| 平台/方案 | JavaScript 调用 Native | Native调用Javascript |
|---|---|---|
| Android | 伪装拦截请求弹窗拦截请求(prompt、alert、confirm)addJavascriptInterface | evaluateJavaScriptloadUrl |
| iOS | 伪装拦截请求弹窗拦截请求(prompt、alert、confirm)(WKWebview)JavaScriptCoreAPIScriptMessageHandler (WKWebview) | evaluateJavaScript |
通过网页发送一段新的跳转请求,跳转到一个自定义协议,路径的目的地如:
slbridge://op/modal?text=sada
协议: slbridge
路径: op/modal
参数: text=sada
通过webview进行请求拦截解析标准URL执行相应的操作,只有匹配到的url地址才会被拦截当做指令调用原生的代码执行。这是一种客户端与前端共同约定维护的通行方式,参考URL标准实现就行。
JS调用假跳转的方式有很多,理论上只要能够发起地址请求都可以被客户端拦截,如:
// A标签
<a href="slbridge://op/modal?text=sada">打开Modal</a>
// location
location.href = "slbridge://op/modal?text=sada"
客户端拦截方式Android 需要通过重写 shouldOverrideURLLoading 方法;
iOS UIWebview需要重写shouldStartLoadWithRequest 方法;
iOS WKWebview 需要重写 decidePolicyForNavigationAction 方法。
==注意:== Android 重写 shouldOverrideURLLoading 方法后会覆盖原生标准支持的 H5 调起发送邮件和拨打电话等功能,需要重新实现
前端可以调用原生的API弹窗,包括alert,confirm,prompt,每个弹窗都可以传递相应的参数展示。
var data = {
action: 'showLoading',
data: {
text: '这是一个客户端弹窗'
},
callback: 'showLoadingCallbak'
}
prompt(JSON.stringify(data))
客户端可以拦截这个弹窗信息,解析参数执行对应的操作。
iOS通过重写 runJavaScriptTextInputPanelWithPrompt
Android 重写 onJsPrompt
不通过拦截,直接注入 Native 方法到 JS 执行环境中,注入的方法可以直接通过 JS 调用。
iOS UIWebview JavaScriptCore
iOS WKWebview APIScriptMessageHandler
Android JavaScriptInterface
JavaScriptCore 引擎是一个广泛应用的iOS framework,诸如JSPatch,ReactNative等都在使用。通过
documentView.webview.manFrame.javaScriptContext 注入到 对应web 的JSContext(在浏览器环境JSContext 就是 window 对象)。
注入之后浏览器即可通过 window 直接获取注入的对象
APIScriptMessageHandler 通过 addScriptMessageHandler: name 方法添加 handler
添加之后的方法可以通过window.webkit.messageHandler..postMessage(messageBody) 调用这个添加的handler,这个方法执行后会调用到指定的一个delegate didReceiveScriptMessage 在这里处理调用参数指令。
Android Webview 通过 addJavascriptInterface 方法使用一个自定义的名称注入一个Java对象到Javascript JSContext 中,从而允许Javascript通过 JSContext 调用 Java 对象的方法
==注意:== JavascriptInterface 4.4 版本之前有一个安全漏洞 ,4.2 版本之后可以通过@JavscriptInterface 注解避免漏洞。4.2版本之前可以不纳入考虑范围
iOS: evaluateJavaScript
Android 4.2:loadUrl
Android 4.4:evaluateJavaScript
注:对于Android 而言 loadUrl 和 evaluateJavaScript 实际差别不大
小结
比较而言,使用拦截的方式调用客户端方法会存在两个问题:
通过上面提供的技术方案,实现基本的 JSBridge 功能设计,以及js native 通信的规范和约束。此处采用注入的方案实现 JS 调用 Native 的功能。
1. 实现JSBridge 对象
JSBridge 暴露三个方法,分别对应 初始化 init、调用客户端方法 callHandler、注册客户端调用的方法 registerHandler
2. 调用
addJavascriptInterface(WebAppInterface, bridgeName)
public class WebAppInterface {
public void showToast(String stringifyData) {
}
public void preSign(String StringifyData) {
}
public void getUserId() {
}
}
window[bridgeName].showToast(JSON.stringify(text: '12121212'))
window[bridgeName].getUserId('', (res) => {
console.log(res)
})
class H5ToNativeActivity {
public void showToast() {
}
}
public class WebAppInterface {
public void callHandler(String handlerName, String stringifyData) {
H5ToNativeActivity activity = new H5ToNativeActivity()
Method m = Class.forName(H5ToNativeActivity).getMethod(handlerName)
m.invoke(activity, stringifyData)
}
}
window[bridgeName].callHandler('showToast', JSON.stringify({text: '12121212'}))
window[bridgeName].callHandler('preSign')
总结:
JSContext是一个浏览器环境的全局变量,直接注入到JSContext下面相当于暴露所有的API
同时会污染全局变量,如果开发者不小心声明了一个同名的全局方法会导致API调用失效或者错误。
iOS借助于 WebviewJavascriptBridge 提供的回调功能
Android 通过注册一个JS 方法执行回调,如
window.TTBridgeCallbacks = {
preSignCallback() {
console.log(1)
}
}
window[BridgeName].callHandler('preSign', {
goodsId: 12,
skuId: 111
}, 'preSignCallback')
webView.evaluateJavascript('javascript:TTBridgeCallbacks.preSignCallback()')
Nginx简单来说就是一个代理服务器,http和反向代理服务器,邮件服务器,通用TCP和UDP代理服务器。
1)静态资源文件代理,文件摘要缓存
2)基于缓存的快速反向代理,负载均衡和容错处理
3)模块化支持
4)安全传输支持SSL & TSL SNI
5)HTTP/2 支持
6)基于名称和IP 的虚拟主机(就是server)
7)长连接(keepalive)和流水线处理请求(pipelined)
8)日志系统
9)错误重定向
10)URI rewrite
11)识别来源(根据客户端地址分别执行不通的操作)
12)身份验证
13) referer 验证
14)WebDAV 远程文件处理服务
15)视频流服务FLV/MP4
16)响应速度限制
17)请求节流
18)IP 地址定位
19)A/B test (split client module 根据remote 分流)
20)请求镜像
21)Perl 支持
22)njs 支持
23)邮件服务
24)UDP/TCP 服务
-【增加一个虚拟服务器】
server {
server_name stale.finger66.com
location / {
root /home/admin/root;
}
# 支持正则
server_name ~^(stable\\.)?(?finger66.+)$;
location / {
root /home/$1
}
}
-)Nginx反向代理配置
server {
server_name stable.fingerapp.cn
# 代理stable.fingerapp.cn/web => <https://www.baidu.com/web>
location /web {
proxy_pass <https://www.baidu.com>
}
# 代理stable.fingerapp.cn/web => <https://www.baidu.com/web2>
location /web {
proxy_pass <https://www.baidu.com/web2>
# proxy_set_header 设置被代理服务器的请求头信息解决多级代理信息传递问题
proxy_set_header X-Request-ID $http_x_request_id;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $remote_addr;
# 设置反向代理协议版本
proxy_http_version 1.1;
# proxy_redirect
}
}
-)【server 支持websocket】
普通请求链接如果代理服务器60s内没有发送数据就会被关闭掉,超时时间通过proxy_read_timeout设置;相对应的还有proxy_connect_timeout 和 proxy_send_timeout
除此之外,也可以设置这个请求为定期发送 socket 帧去重置这个超时时间并且检查这个请求是否还处于 alive 状态
map $http_upgrade $connection_upgrade {
default upgrade;
'' close;
}
server {
location / {
proxy_pass <http://127.0.0.1>;
# 设置链接升级支持socket
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection $connection_upgrade;
}
}
-)重定向和重写
重定向(redirect)发生之后会告诉客户端,地址改了,你重新请求或者访问一下
重写(rewrite)发生之后,服务器直接重写这个请求地址,请求另一个地址的资源,然后返回给客户端。
关于代理,重写,重定向 注:
代理:你要买套儿,委托我代购
重定向:你要买套儿,我告诉你我没货了,但是我告诉你旁边自动贩卖机有
重写:你要买套儿,我自己没货了,但是我从贩卖机买了再卖给你
location / {
rewrite ^/user/([0-9]+)/.*$ /show?userId=$1 last;
rewrite .* https:// www.finger66.com break;
rewrite .* <https://www.baidu.com> redirect;
rewrite .* <https://www.finger66.com> permanent;
}
-)配置SSL
nginx 默认支持ssl 配置,ssl 配置需要先准备好私钥 ssl.key 和 证书 ssl.crt 文件。
server {
listen 443 ssl;
server_name stable.fingerapp.cn;
ssl_certificate ssl.crt;
ssl_certificate_key ssl.key;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
}
-)日志
nginx 默认支持日志,access_log 和 error_log。并提供 info、notice、error等默认格式
server {
access_log /root/logs/access.log <log-format>;
}
-) 设置 referer 防盗链
ngx_http_referer_module 提供了 referer 的校验机制。referer 头信息即请求来源
通过设置 valid_referers 设置允许的请求来源。可以设置为
location /upload {
valid_referers *.finger66.com;
if ($invalid_referer) {
return 403;
}
}
结构型的设计模式,更多的关注类和对象的职责划分以及类和对象之间的组合。组合接口和定义组合对象以获得新的功能。
将对象或者类的接口转换成与特定的系统兼容的接口。
声明一个电脑读卡的类
interface Card {
read(): string {};
write(msg: string): void {};
}实现 SDCard 类
class SDCard implements Card {
msg: string = 'This is a sd-card'
read(): string {
return this.msg
}
write(msg: string): void {
this.msg = msg
}
}声明另一种 TFCard 类
class TFCard {
msg: string = 'This is a tf-card',
readTF(): string {
return this.msg
}
writeTF(msg: string) {
this.msg = msg
}
}声明电脑类,提供读卡功能只能读取 sd 卡类型
class Computer() {
readSD(card: Card) {
return card.read()
}
}TFCard 适配器适配电脑读取
class TFCardAdapter implements Card {
private tfcard: TFCard
SDAdapterTF(tfcard: TFCard) {
this.tfcard = tfcard
}
read(): string {
return this.tfcard.readTF()
}
write(msg: string): void {
this.tfcard.writeTF(msg)
}
}使用 Computer 读卡
const computer = new Computer()
const sdcard = new SDCard()
const tfcard = new TFCardAdapter()
computer.readSD(sdcard)
computer.readSD(tfcard)外观模式隐藏系统的复杂性,对外提供客户端可访问的接口。定义更高层次的接口,便于访问。
比如:电脑启动程序,涵盖了CPU启动,SSD装载,启动内存。但是实际表现出来就是一键启动。
interface Computer {
open(): void {}
}
class SSD implements Computer {
open(): void {
console.log('ssd start....')
}
}
class ROM implements Computer {
open(): void {
console.log('rom start....')
}
}
class CPU implements Computer {
open(): void {
console.log('cpu start....')
}
}
class Facade {
cpu() {
const cpu = new CPU()
cpu.open()
}
rom() {
const rom = new ROM()
rom.open()
}
ssd() {
const ssd = new SSD()
ssd.open()
}
}
class Computer {
open() {
const facade = new Facade()
facade.cpu()
facade.ssd()
facade.rom()
}
}
const com = new Computer()
com.open()
// cpu start....
// ssd start....
// rom start....桥接模式的主要特点就是将实现层与抽象逻辑层分离,使得二者可以独立变化。通过提供实现化和抽象化之间的接口,实现二者的解耦。
简单实际应用的理解就是:抽象化类的公共特性,再针对抽象化进行具体的实现。
比如:为元素添加字体色和背景
function changeColor(dom, color, bgColor) {
dom.style.color = color
dom.style.backgroundColor = bgColor
}
changeColor(document.body, '#FFF', '#000')抽象了修改样式的方法,具体的实现通过参数控制。
用一组相似对象当做单一的对象,依据树形结构来组合对象,用来表示部分和整体的层次。因此组合模式的关键就是一个可以既可以表示父节点也可以表示子节点的抽象类。
比如:公司组织架构
实现一个 Employee 类,所有人都是公司员工
class Employee {
private name: string
private salary: number
private dept: string
private postion: string
private subordinates: Array<Employee>
constructor(name, dept, pos, sal) {
this.name = name
this.dept = dept
this.salary = sal
this.position = pos
this.subordinates = []
}
add(emp) {
this.subordinates.push(emp)
}
remove(name: string) {
this.subordinates = this.subordinates.filter((sub) => {
return sub.getName() !== name
})
}
getName() {
return this.name
}
getSubordinates() {
return this.subordinates
}
toString() {
return `Employee: ${this.name} - ${this.dept} - ${this.position} - ${this.salary}`
}
}使用 Employee 类
const CEO = new Employee('Jhonson', '', 'CEO', 100000)
const headSales = new Employee('Michale', 'Sale', 'Head Sale', 30000)
const headMarket = new Employee('Jack', 'Market', 'Head Market', 30000)
const sale1 = new Employee('Rob', 'Sale', 'Sale Special', 10000)
const sale2 = new Employee('Robort', 'Sale', 'Sale Special', 10000)
CEO.add(headSales)
CEO.add(headMarket)
headSales.add(sale1)
headSales.add(sale2)装饰器模式允许向一个现有的对象添加新的功能而又不改变其结构。创建一个装饰类包装现有对象,提供额外功能。在使用继承扩展子类的情况下增强类。
例子:对任意输入框添加 focus 和 blur 状态
function decorator(input) {
input.addEventListener('focus', () => {
input.style.border = 'solid 1px #e54e5c';
})
input.addEventListener('blur', () => {
input.style.border = 'none';
})
}享元模式通过共享状态,减少内存中对象的数量,提升程序性能。享元模式外部状态相对独立,不会影响内部状态,从而使得享元对象可以在不同环境**享。主要由以下部分构成:
1)抽象享元类 Flyweight
2)具体享元类 ConcreteFlyweight
3)非共享具体享元类 UnsharedConcreteFlyweight
4)享元工厂类 FlyweightFactory
例子:创建20个分布不同位置的圆
圆形类
class Circle {
constructor(color) {
this.color = color
}
setX(x) {
this.x = x
}
setY() {
this.y = y
}
setRadius(radius) {
this.radius = radius
}
draw() {
console.log(`Circle:color: ${this.color}, x: ${this.x} y: ${this.y} radius: ${this.radius}`)
}
}圆形工厂
function circleFactory = (function() {
const circleMap = {}
return {
create(color) {
if (circleMap[color]) {
return circleMap[color]
}
circle = new Circle(color)
circleMap[color] = circle
return circle
}
}
})()使用享元工厂
const colors = ['green', 'red', 'yellow', 'blue', 'black']
for(let i = 0; i < 20; i ++) {
const color = colors[Math.floor(Math.random() * colors.length)]
const x = Math.random()*20
const y = Math.random()*20
const radius = Math.random()*20
const circle = circleFactory.create(color)
circle.setX(x)
circle.setY(x)
circle.setRadius(x)
circle.draw()
}代理模式简单理解就是在访问对象时加一层访问控制。即提供一种代理来实现对对象的控制而不是直接调用。
例子:数据统计
const Count = (function() {
var img = new Image()
return function(param) {
const str = 'http://test.com/a.gif?'
for (let p in param) {
str += `${i}=${param[i]}`
}
img.src = str
}
})()
Count({ uid: 12333 })不断用变量的旧值递推新值的过程。迭代过程中需要确定三个关键点:
1)迭代变量;即不断迭代变动的值
2)迭代关系;即旧值递推到新值的计算方式
3)控制条件;迭代开始结束的条件
例子: Fibonacci 数列求值
使用迭代方式求值
func fibonacci(n int) int {
if n == 0 {
return 0
}
if n == 1 {
return 1
}
f0, f1, fc := 0, 1, 0
for i := 1; i < n; i++ {
fc = f0 + f1
f0 = f1
f1 = fc
}
return fc
}将问题拆分成同类的重复子问题的方法,一般通过函数自调用来实现。递归是迭代的一种特殊情况。
例子: Fibonacci 数列求值
func fibonacci(n int) int {
if n == 0 {
return 0
}
if n == 1 {
return 1
}
fib := fibonacci(n-1) + fibonacci(n-2)
return fib
}递归调用每次执行都会开辟栈空间来存储,如果次数过多会造成调用栈溢出。可以使用存储来避免无用的递归多次执行。
补充: 尾递归
所有递归形式的调用都出现在最后,则称之为尾递归。即递归调用是整个函数最后执行的语句,且不包含在表达式里面。对于这种递归,编辑器可以覆盖当前的活动记录,缩减空间栈,提升运行效率。
通过把原问题分解为相对简单的子问题的方式求解复杂问题的方法。大致上,若要解一个给定问题,我们需要解其不同部分(即子问题),再根据子问题的解得出原问题的解。为了减少计算量,一旦某个子问题已经算出,则记忆化存储该问题的解。动态规划问题基本要素:
1)子问题。整个大问题可以分解子问题,子问题可以继续分解。子问题代表某个状态下的决策结果。
2)子问题独立。子问题一旦确定就不在更改,每个子问题的解独立且唯一的。
3)子问题重叠。每个子问题并不是相互隔离的,可能存在计算上的依赖关系;子问题计算结果需要保存以便后续计算。
4)最优子结构。如果问题为最优解,则其中子问题也为最优解。
例子: Fibonacci 数列求值
func fibonacci(n int) int {
if n == 0 {
return 0
}
if n == 1 {
return 1
}
var arr []int
arr[0] = 0
arr[1] = 1
for i := 2; i <= n; i ++ {
arr[i] = arr[i - 1] + arr[i - 2]
}
return arr[n]
}例子: 莱文斯坦距离。即两个字符串之间的编辑距离
func levenshteinDistcance(s1 string, s2 string) int {
len1 := len(s1)
len2 := len(s2)
D := tool.Make2DArr(len1 + 1, len2 + 1)
for i := 0; i <= len1; i++ {
for j := 0; j <= len2; j ++ {
// 字符相等则不需要操作
cost := 0
if s1[i - 1] != s2[j - 1] {
cost = 1
}
D[i][j] = tool.Min(
D[i - 1][j] + 1, // 删除
D[i][j - 1] + 1, // 插入
D[i - 1][j - 1] + cost // 替换
)
}
}
return D[len1][len2]
}滑动窗口算法用以解决数组/字符串的子元素问题。可以将嵌套的循环问题,解析成单循环问题,降低时间复杂度。
例子: 给定一个整数数组,计算长度为 k 的连续子数组的最大总和。
输入:[1,2,3,4,5,9,10,13,8,1,40] k = 2
输出: 41
即当长度为 k 时维护一个长度为 k 的滑块,保存滑块窗口的值。不断的向后移动滑块,保存最大值。
func maxium(arr []int, k int) int {
if len(arr) < k {
return 0
}
maxSum := 0
for i := 0; i < len(arr) - k + 1; i++ {
temp := 0
for j := i; j < i + k; j++ {
temp += arr[j]
}
maxSum = tool.Max(maxSum, temp)
}
return maxSum
}贪心算法与动态规划类似,也是最有子结构问题。
在每一步中都采用当前状态下的最优解,而导致最终结果最优的一种算法。解决的问题一般来说可以分成多个子问题,子问题的最有解能递推到最终问题的最优解。
贪心算法基本要素:
1)创建数据模型描述问题
2)拆分若干个子问题
3)每个子问题分别求解,得到子问题的局部最优解
4)子问题解合成原问题解
回溯法采用试错的**,分步尝试解决问题。主要步骤如下:
1)取出一个当前状态的可用解 A1,得到下一步解 B1...Bn
2)取一个可用解 B1。如果所有 B1...Bn 都不存在下一步解,则回溯到 A1...An,取 A2 继续求解;否则进入下一步
3)尝试完所有步骤后,得到该问题的最终有效解或者无解。
例子: 八皇后问题
func solveNQueens(n int) [][]string {
// 有皇后的行
rowUsed := make(map[int]bool)
// 有皇后的列
colUsed := make(map[int]bool)
// 有皇后的反对角
oppoAngleUsed := make(map[int]bool)
// 有皇后的正对角
posAngleUsed := make(map[int]bool)
// 存储结果
result := [][]string{}
list := []string{}
searchQueens(rowUsed, colUsed, oppoAngleUsed, posAngleUsed, &result, &list, n)
return result
}
func searchQueens(rowUsed map[int]bool, colUsed map[int]bool, oppoAngleUsed map[int]bool, posAngleUsed map[int]bool, result *[][]string, list *[]string, n int) {
for i := 0; i < n; i ++ {
if i == len(*list) {
for j := 0; j < n; j++ {
// 判断当前位置是否可用
canUse := !(rowUsed[i] == true || colUsed[j] == true || posAngleUsed[j-i] == true || oppoAngleUsed[i+j] == true)
if canUse {
str := combineString(j, n)
*list = append(*list, str)
rowUsed[i] = true
colUsed[j] = true
posAngleUsed[j-i] = true
oppoAngleUsed[i+j] = true
if len(*list) == n {
arr := copySlice(*list)
*result = append(*result, arr)
}
searchQueens(rowUsed, colUsed, oppoAngleUsed, posAngleUsed, result, list, n)
*list = (*list)[0:len(*list) - 1]
rowUsed[i] = false
colUsed[j] = false
posAngleUsed[j-i] = false
oppoAngleUsed[i+j] = false
}
}
}
}
}
func copySlice(slice []T) []T {
arr := make([]string, len(*list))
for k := 0; k < len(slice); k ++ {
arr[k] = slice[k]
}
return arr
}
func combineString(pos int, n int) string {
str := ""
for i := 0; i < n; i ++ {
if i == pos {
str += "Q"
} else {
str += "."
}
}
return str
}n 个非负整数 a1, a2 ....... an,每个数代表坐标轴上的点(i,ai)。在坐标轴内画 n 条垂直的线,线的两个端点分别是 (i, 0) 和 (i, ai)。找出两个坐标点 ai 和 aj 使得这两条先围成的区域面积最大。
如下图:

解题思路
两条线之间的面积(A) = 最短的高度(H) * 线之间距离(W)。即面积受制于长度和最小高度两个条件。可以使用双指针发不断缩小横向方位获取最大面积值。移动指针时,由于 W 缩短,因此应当移动高度较低的指针位置并且移动后 H 增加。
1)从坐标轴左右两边开始使用双指针。分别为 i,j
2)双指针保证 i < j
2)判断左右高度移动高度较低的指针位置。移动指针时判断下一个指针位置高度是否高于当前指针,即 a[i + 1] > a[i] 或者 a[j - 1] > a[j] 满足则计算面积,进行比较更新;否则继续移动指针i ++ 或者 j --。
func maxArea(height []int) int {
if height == nil || len(height) < 2 {
return 0
}
i, j, area := 0, len(height) - 1, 0
for i < j {
h := height[i]
if height[i] > height[j] { h = height[j] }
newArea := (j - i) * h
if newArea > area {
area = newArea
}
if height[i] < height[j] {
for i < j && height[i] > height[i + 1] {
i ++
}
i ++
} else {
for i < j && height[j] > height[j - 1] {
j --
}
j --
}
}
return area
}
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.






































